Beberapa minggu yang lalu dalam percakapan saat makan malam, seorang kolega mengeluh tentang semacam proses yang lambat. Dia menghitung jumlah byte yang dihasilkan, jumlah siklus pemrosesan, dan akhirnya, jumlah RAM. Seorang kolega mengatakan bahwa GPU modern dengan bandwidth memori lebih dari 500 GB / s akan menghabiskan tugasnya dan tidak tersedak.Tampak bagi saya bahwa ini adalah pendekatan yang menarik. Secara pribadi, saya belum pernah mengevaluasi tujuan kinerja dari perspektif ini. Ya, saya tahu tentang perbedaan kinerja prosesor dan memori. Saya tahu cara menulis kode yang banyak menggunakan cache. Saya tahu perkiraan angka keterlambatan. Tetapi ini tidak cukup untuk segera menilai bandwidth memori.Ini adalah eksperimen pemikiran. Bayangkan dalam memori array terus menerus dari satu miliar bilangan bulat 32-bit. Ini 4 gigabytes. Berapa lama untuk mengulangi array ini dan menambahkan nilainya? Berapa banyak byte per detik yang dapat dibaca CPU dari RAM? Data kontinu? Akses acak? Seberapa baik proses ini dapat diparalelkan?Anda akan mengatakan bahwa ini adalah pertanyaan yang tidak berguna. Program nyata terlalu kompleks untuk membuat tengara naif seperti itu. Dan disana! Jawaban sebenarnya adalah "tergantung pada situasinya."Namun, saya pikir masalah ini perlu ditelusuri. Saya tidak berusaha menemukan jawabannya . Tapi saya pikir kita bisa mendefinisikan beberapa batas atas dan bawah, beberapa poin menarik di tengah dan belajar sesuatu dalam proses.
Saya tahu cara menulis kode yang banyak menggunakan cache. Saya tahu perkiraan angka keterlambatan. Tetapi ini tidak cukup untuk segera menilai bandwidth memori.Ini adalah eksperimen pemikiran. Bayangkan dalam memori array terus menerus dari satu miliar bilangan bulat 32-bit. Ini 4 gigabytes. Berapa lama untuk mengulangi array ini dan menambahkan nilainya? Berapa banyak byte per detik yang dapat dibaca CPU dari RAM? Data kontinu? Akses acak? Seberapa baik proses ini dapat diparalelkan?Anda akan mengatakan bahwa ini adalah pertanyaan yang tidak berguna. Program nyata terlalu kompleks untuk membuat tengara naif seperti itu. Dan disana! Jawaban sebenarnya adalah "tergantung pada situasinya."Namun, saya pikir masalah ini perlu ditelusuri. Saya tidak berusaha menemukan jawabannya . Tapi saya pikir kita bisa mendefinisikan beberapa batas atas dan bawah, beberapa poin menarik di tengah dan belajar sesuatu dalam proses.Angka yang harus diketahui oleh setiap programmer
Jika Anda membaca blog pemrograman, Anda mungkin menemukan "angka yang harus diketahui oleh setiap programmer." Mereka terlihat seperti ini:Tautan ke L1 cache 0,5 ns
Prediksi 5 ns salah
Tautan ke L2 cache 7 ns 14x ke L1 cache
Menangkap / Melepaskan Mutex 25 ns
Tautan ke memori utama 100 ns 20x ke L2 cache, 200x ke L1 cache
Kompres 1000 byte dengan Zippy 3000 ns 3 μs
Mengirim 1000 byte melalui jaringan 1 Gbps 10.000 ns 10 μs
Baca Acak 4000 dengan SSD 150.000 ns 150 μs ~ 1GB / s SSD
Baca 1 MB secara berurutan dari 250.000 ns 250 μs
Paket pulang-pergi di dalam pusat data 500.000 ns 500 μs
1 MB dibaca berurutan dalam SSD 1.000.000 ns 1.000 μs 1 ms ~ 1 GB / s SSD, memori 4x
Pencarian disk 10.000.000 ns 10.000 μs 10 ms 20x ke pusat data
Baca 1 MB secara berurutan dari disk 20.000.000 ns 20.000 μs 20 ms 80x ke memori, 20x ke SSD
Paket Mengirim CA-> Belanda-> CA 150.000.000 ns 150.000 μs 150 ms
Sumber:Daftar hebat Jonas Boner . Dia muncul di HackerNews setidaknya setahun sekali. Setiap programmer harus mengetahui angka-angka ini.Tetapi angka-angka ini adalah tentang sesuatu yang lain. Latensi dan bandwidth bukan hal yang sama.Keterlambatan pada tahun 2020
Daftar itu disusun pada tahun 2012, dan artikel ini tahun 2020, waktunya telah berubah. Berikut adalah angka untuk Intel i7 dengan StackOverflow .Hit dalam cache L1, ~ 4 siklus (2.1 - 1.2 ns)
Hit di cache L2, ~ 10 siklus (5,3 - 3,0 ns)
Tekan dalam cache L3, untuk satu inti ~ 40 siklus (21,4 - 12,0 ns)
Hit dalam cache L3, bersama-sama untuk kernel lain ~ 65 siklus (34,8 - 19,5 ns)
Tekan L3 cache, dengan perubahan untuk kernel lain ~ 75 siklus (40.2 - 22.5 ns)
RAM lokal ~ 60 ns
Menarik! Apa yang berubah?- L1 menjadi lebih lambat;
0,5 → 1,5
- L2 lebih cepat;
7 → 4,2
- Rasio L1 dan L2 jauh berkurang;
2,5x 14(Wow!)
- L3 cache kini telah menjadi standar;
12 40
- RAM menjadi lebih cepat;
100 → 60
Kami tidak akan menarik kesimpulan yang luas. Tidak jelas bagaimana angka-angka asli dihitung. Kami tidak akan membandingkan apel dengan jeruk.Berikut adalah beberapa angka dari wikichip pada bandwidth dan ukuran cache prosesor saya.Memory Bandwidth: 39,74 Gigabytes per detik
Cache L1: 192 kilobyte (32 KB per inti)
L2 Cache: 1,5 megabytes (256 KB per core)
L3 Cache: 12 megabyte (dibagi; 2 MB per inti)
Apa yang ingin saya ketahui:- Batas atas kinerja RAM
- batasan yang lebih rendah
- Batas Cache L1 / L2 / L3
Benchmark naif
Mari kita lakukan beberapa tes. Untuk mengukur bandwidth, saya menulis program C ++ sederhana. Sangat kira-kira dia terlihat seperti ini.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
Beberapa detail dihilangkan. Tapi Anda mengerti idenya. Buat array besar elemen yang berkelanjutan. Bagilah array menjadi fragmen yang terpisah. Proses setiap fragmen dalam utas terpisah. Akumulasi hasil.Anda juga perlu mengukur akses acak. Ini sangat sulit. Saya mencoba beberapa cara, akhirnya memutuskan untuk mencampur indeks yang sudah dihitung sebelumnya. Setiap indeks ada tepat satu kali. Kemudian loop dalam berulang atas indeks dan menghitung sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
Dalam menghitung throughput, saya tidak mempertimbangkan memori array indeks. Hanya byte yang berkontribusi terhadap total yang dihitung sum. Saya tidak membuat tolok ukur perangkat keras saya, tetapi menilai kemampuan untuk bekerja dengan kumpulan data ukuran yang berbeda dan dengan skema akses yang berbeda.Kami akan melakukan tes dengan tiga tipe data:int- integer 32-bit utamamatri4x4- berisi int[16]; cocok dalam garis cache 64-bytematrix4x4_simd- menggunakan alat bawaan__m256iBlok besar
Tes pertama saya bekerja dengan blok memori yang besar. Blok 1 GB Nitem disorot dan diisi dengan nilai acak kecil. Perulangan sederhana berulang di atas array N kali, sehingga mengakses memori dengan volume N untuk menghitung jumlah int64_t. Beberapa utas memecah array, dan masing-masing mendapat akses ke jumlah elemen yang sama.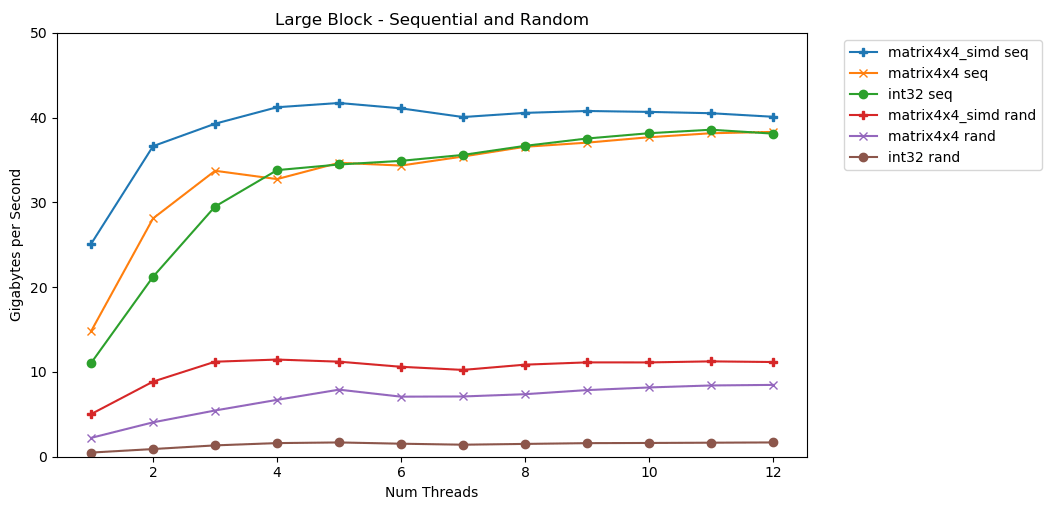 TA-dah! Dalam grafik ini, kami mengambil waktu eksekusi rata-rata operasi penjumlahan dan mengubahnya dari
TA-dah! Dalam grafik ini, kami mengambil waktu eksekusi rata-rata operasi penjumlahan dan mengubahnya dari runtime_in_nanosecondsmenjadi gigabytes_per_second.Hasil yang cukup bagus. int32secara berurutan dapat membaca 11 GB / s dalam satu aliran. Timbangan ini linier hingga mencapai 38 GB / s. Tes matrix4x4dan matrix4x4_simdlebih cepat, tetapi bersandar pada langit-langit yang sama.Ada batas yang jelas dan jelas tentang berapa banyak data yang dapat kita baca dari RAM per detik. Di sistem saya, ini sekitar 40 GB / s. Ini sesuai dengan spesifikasi terkini yang tercantum di atas.Dilihat oleh tiga grafik terbawah, akses acak lambat. Sangat, sangat lambat. Kinerja single-threaded int32dapat diabaikan 0,46 GB / s. Ini 24 kali lebih lambat dari susun berurutan pada 11,03 GB / s! Tes ini matrix4x4menunjukkan hasil terbaik, karena ini berjalan pada baris cache penuh. Tetapi masih empat sampai tujuh kali lebih lambat dari akses berurutan, dan mencapai puncaknya hanya 8 GB / s.Blok kecil: baca berurutan
Di sistem saya, ukuran cache L1 / L2 / L3 untuk setiap aliran adalah 32 KB, 256 KB, dan 2 MB. Apa yang terjadi jika Anda mengambil blok elemen 32-kilobyte dan mengulanginya sebanyak 125.000 kali? Ini adalah memori 4 GB, tetapi kami akan selalu pergi ke cache.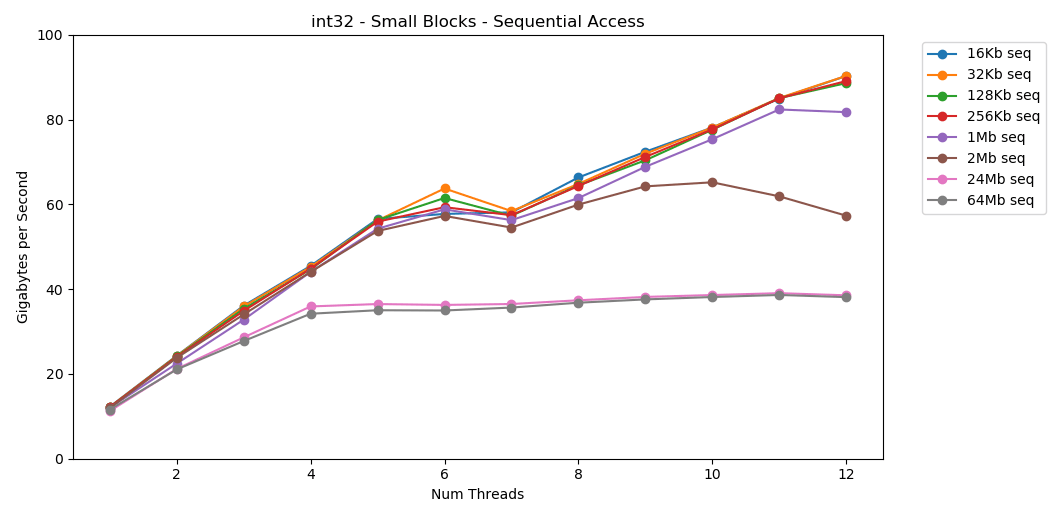 Luar biasa! Kinerja single-threaded mirip dengan membaca blok besar, sekitar 12 GB / s. Kecuali saat ini, multithreading menerobos langit-langit 40 GB / s. Masuk akal. Data tetap dalam cache, sehingga bottleneck RAM tidak muncul. Untuk data yang tidak cocok dengan L3 cache, batas yang sama sekitar 38 GB / s berlaku.Tes ini
Luar biasa! Kinerja single-threaded mirip dengan membaca blok besar, sekitar 12 GB / s. Kecuali saat ini, multithreading menerobos langit-langit 40 GB / s. Masuk akal. Data tetap dalam cache, sehingga bottleneck RAM tidak muncul. Untuk data yang tidak cocok dengan L3 cache, batas yang sama sekitar 38 GB / s berlaku.Tes ini matrix4x4menunjukkan hasil yang serupa dengan sirkuit, tetapi bahkan lebih cepat; 31 GB / s dalam mode single-threaded, 171 GB / s dalam multi-threaded.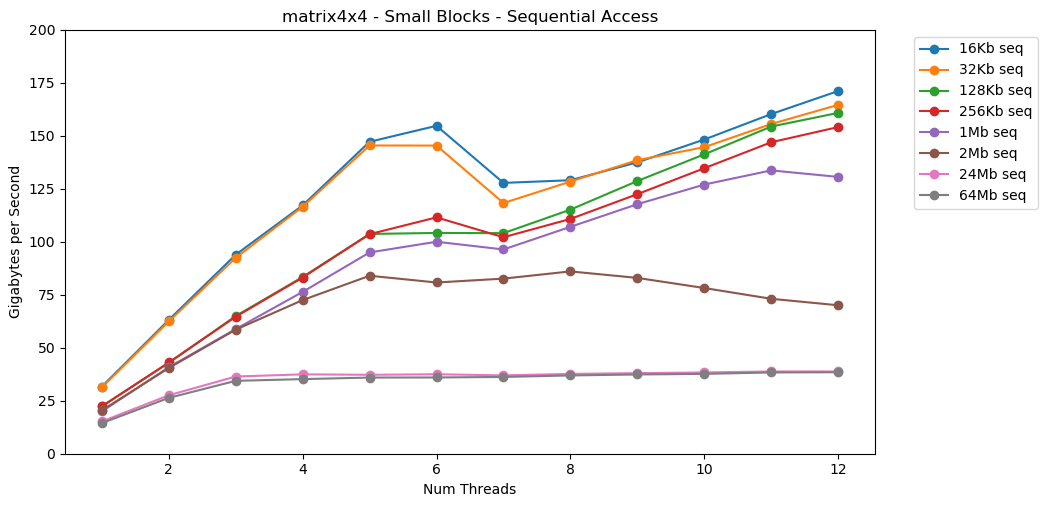 Sekarang mari kita lihat
Sekarang mari kita lihat matrix4x4_simd. Perhatikan sumbu y.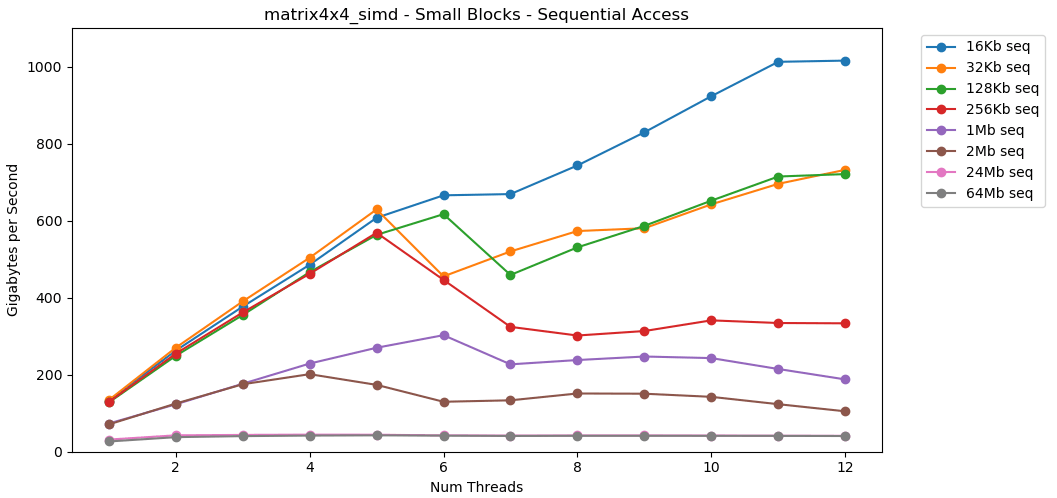
matrix4x4_simddilakukan dengan sangat cepat. Ini 10 kali lebih cepat dari int32. Pada blok 16 KB, bahkan dapat menembus 1000 GB / s!Jelas, ini adalah tes sintetis permukaan. Sebagian besar aplikasi tidak melakukan operasi yang sama dengan data yang sama jutaan kali berturut-turut. Tes tidak menunjukkan kinerja di dunia nyata.Tapi pelajarannya jelas. Di dalam cache, data diproses dengan cepat . Dengan plafon yang sangat tinggi saat menggunakan SIMD: lebih dari 100 GB / s dalam mode single-threaded, lebih dari 1000 GB / s dalam multi-threaded. Menulis data ke cache lambat dan dengan batas keras sekitar 40 GB / s.Blok kecil: baca acak
Mari kita lakukan hal yang sama, tetapi sekarang dengan akses acak. Ini adalah bagian favorit saya dari artikel ini.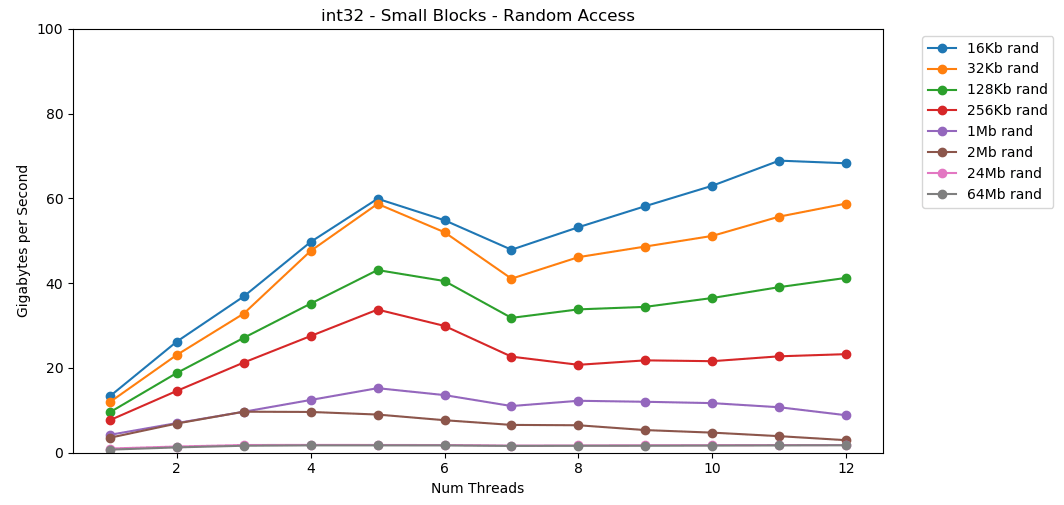 Membaca nilai acak dari RAM lambat, hanya 0,46 GB / s. Membaca nilai acak dari cache L1 sangat cepat: 13 GB / s. Ini lebih cepat daripada membaca data serial
Membaca nilai acak dari RAM lambat, hanya 0,46 GB / s. Membaca nilai acak dari cache L1 sangat cepat: 13 GB / s. Ini lebih cepat daripada membaca data serial int32dari RAM (11 GB / s).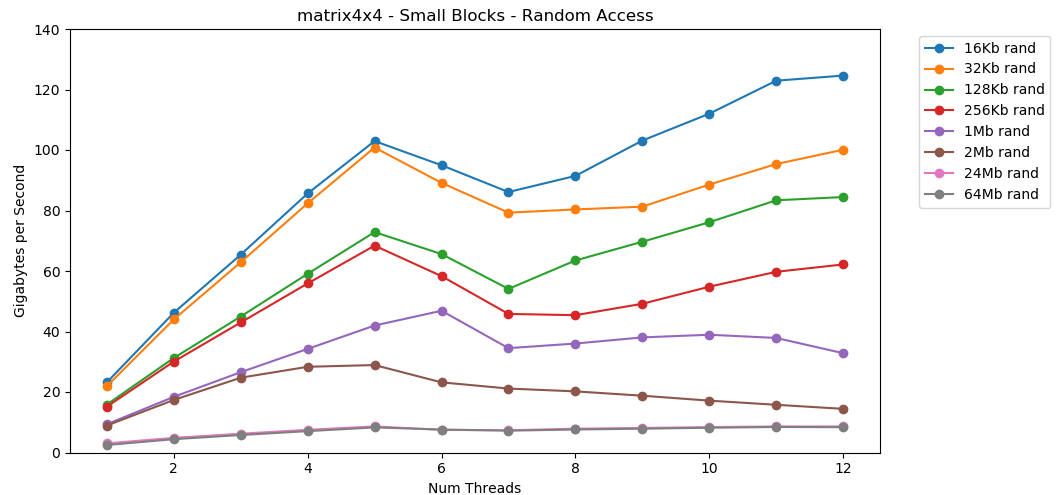 Tes
Tes matrix4x4menunjukkan hasil yang sama untuk templat yang sama, tetapi sekitar dua kali lebih cepat int.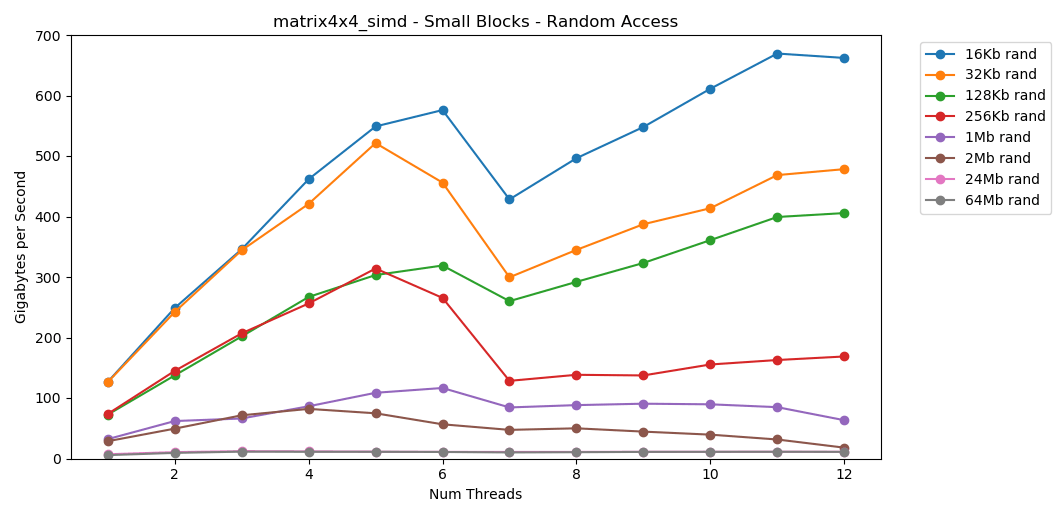 Akses acak
Akses acak matrix4x4_simdsangat cepat.Temuan Akses Acak
Membaca bebas dari memori lambat. Sangat lambat. Kurang dari 1 GB / s untuk kedua kasus uji int32. Pada saat yang sama, pembacaan acak dari cache sangat cepat. Ini sebanding dengan pembacaan berurutan dari RAM.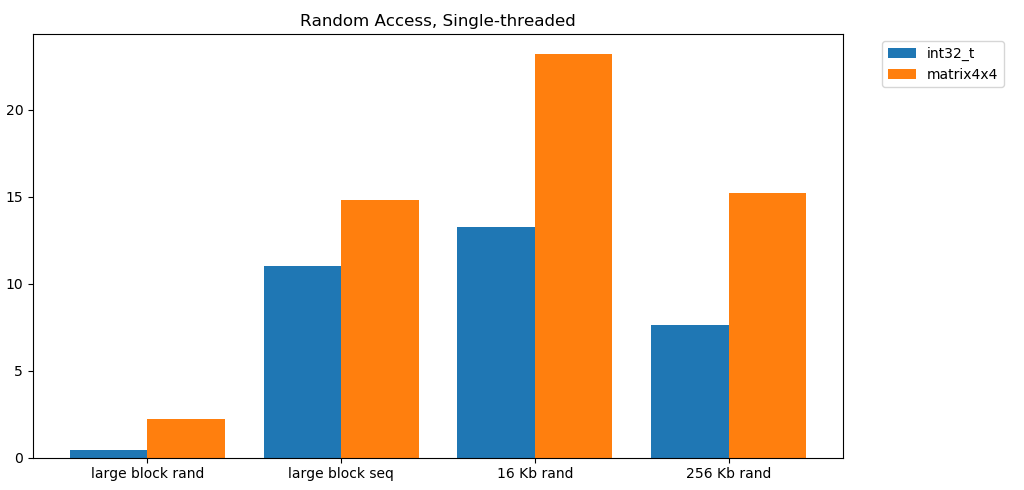 Perlu dicerna. Akses acak ke cache sebanding dalam kecepatan dengan akses sekuensial ke RAM. Penurunan dari L1 16 KB ke L2 256 KB hanya setengah atau kurang.Saya pikir ini akan memiliki konsekuensi besar.
Perlu dicerna. Akses acak ke cache sebanding dalam kecepatan dengan akses sekuensial ke RAM. Penurunan dari L1 16 KB ke L2 256 KB hanya setengah atau kurang.Saya pikir ini akan memiliki konsekuensi besar.Daftar tertaut dianggap berbahaya
Mengejar pointer (melompat pada pointer) buruk. Sangat sangat buruk. Berapa penurunan kinerja? Lihat diri mu sendiri. Saya melakukan tes tambahan yang membungkus matrix4x4di std::unique_ptr. Setiap akses melewati pointer. Ini adalah hasil yang mengerikan, hanya bencana. 1 utas | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Blok Besar - Seq | 14,8 GB / s | 0,8 GB / s | 19x |
16 KB - Seq | 31,6 GB / s | 2.2 GB / s | 14x |
256 KB - Seq | 22.2 GB / s | 1.9 GB / s | 12x |
Large Block - Rand | 2.2 GB / s | 0,1 GB / s | 22x |
16 KB - Rand | 23.2 GB / s | 1,7 GB / s | 14x |
256 KB - Rand | 15.2 GB / s | 0,8 GB / s | 19x |
6 utas | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Blok Besar - Seq | 34,4 GB / s | 2,5 GB / s | 14x |
16 KB - Seq | 154,8 GB / s | 8.0 GB / s | 19x |
256 KB - Seq | 111,6 GB / s | 5,7 GB / s | 20x |
Large Block - Rand | 7.1 GB / s | 0,4 GB / s | 18x |
16 KB - Rand | 95.0 GB / s | 7,8 GB / s | 12x |
256 KB - Rand | 58,3 GB / s | 1,6 GB / s | 36x |Penjumlahan berurutan dari nilai-nilai di belakang pointer dilakukan pada kecepatan kurang dari 1 GB / s. Kecepatan akses acak cache ganda hanya 0,1 GB / s.Mengejar pointer memperlambat eksekusi kode 10-20 kali. Jangan biarkan teman Anda menggunakan daftar tertaut. Tolong pikirkan cache.Estimasi Anggaran untuk Bingkai
Sudah umum bagi pengembang game untuk menetapkan batas (anggaran) untuk beban pada CPU dan memori. Tapi saya belum pernah melihat anggaran bandwidth.Dalam game modern, FPS terus berkembang. Sekarang berada di 60 FPS. VR beroperasi pada frekuensi 90 Hz. Saya memiliki monitor gaming 144 Hz. Ini luar biasa, jadi 60 FPS sepertinya omong kosong. Saya tidak akan pernah kembali ke monitor lama. Esports dan pita monitor Twitch 240 Hz. Tahun ini, Asus memperkenalkan monster 360 Hz di CES.Prosesor saya memiliki batas atas sekitar 40 GB / s. Itu sepertinya jumlah yang besar! Namun, pada frekuensi 240 Hz, hanya 167 MB per frame diperoleh. Aplikasi realistis dapat menghasilkan lalu lintas 5 GB / s pada 144 Hz, yang hanya 69 MB per frame.Ini adalah tabel dengan beberapa angka. | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 GB / s | 40 GB | 4 GB | 1,3 GB | 667 MB | 444 MB | 278 MB | 167 MB | 111 MB |
10 GB / s | 10 GB | 1 GB | 333 MB | 166 MB | 111 MB | 69 MB | 42 MB | 28 MB |
1 GB / s | 1 GB | 100 MB | 33 MB | 17 MB | 11 MB | 7 MB | 4 MB | 3 MB |
Menurut saya berguna untuk menilai masalah dari perspektif ini. Ini memperjelas bahwa beberapa ide tidak layak. Mencapai 240 Hz tidak mudah. Ini tidak akan terjadi dengan sendirinya.Angka yang harus diketahui oleh setiap programmer (2020)
Daftar sebelumnya kedaluwarsa. Sekarang perlu diperbarui dan dipatuhi pada tahun 2020.Berikut adalah beberapa angka untuk komputer di rumah saya. Ini adalah campuran dari AIDA64, Sandra dan tolok ukur saya. Angka-angka tidak memberikan gambaran lengkap dan hanya titik awal.Latency L1: 1 ns
L2 Delay: 2,5 ns
Keterlambatan L3: 10 ns
RAM Latency: 50 ns
(per utas)
L1 band: 210 GB / s
L2 band: 80 GB / s
L3 Band: 60 GB / s
(sistem keseluruhan)
Pita RAM: 45 GB / s
Akan menyenangkan untuk membuat tolok ukur sumber terbuka kecil dan sederhana. Beberapa file C yang dapat dijalankan di komputer desktop, server, perangkat seluler, konsol, dll. Tapi saya bukan tipe orang yang menulis alat seperti itu.Penolakan tanggung jawab
Mengukur bandwidth memori sulit. Sangat sulit. Mungkin ada kesalahan dalam kode saya. Banyak faktor yang tidak terhitung. Jika Anda memiliki kritik untuk teknik saya, Anda mungkin benar.Pada akhirnya, saya pikir ini normal. Artikel ini bukan tentang kinerja tepat desktop saya. Ini adalah pernyataan masalah dari sudut pandang tertentu. Dan tentang cara belajar bagaimana melakukan perhitungan matematika kasar.Kesimpulan
Seorang kolega berbagi pendapat menarik dengan saya tentang bandwidth memori GPU dan kinerja aplikasi. Ini mendorong saya untuk mempelajari kinerja memori pada komputer modern.Untuk perkiraan perhitungan, berikut adalah beberapa angka untuk desktop modern:- Kinerja RAM
- Maksimum:
45 / - Rata-rata, sekitar:
5 / - Minimum:
1 /
- Performa Cache L1 / L2 / L3 (per inti)
- Maksimum (c simd):
210 // 80 //60 / - Rata-rata, sekitar:
25 // 15 //9 / - Minimal:
13 // 8 //3,5 /
Peringkat sampel terkait dengan kinerja matrix4x4. Kode nyata tidak akan pernah sesederhana itu. Tetapi untuk perhitungan pada serbet, ini adalah titik awal yang masuk akal. Anda perlu menyesuaikan angka ini berdasarkan pola akses memori dalam program Anda, karakteristik peralatan dan kode Anda.Namun, yang terpenting adalah cara baru untuk memikirkan masalah. Menyajikan masalah dalam byte per detik atau byte per frame adalah lensa lain untuk dilihat. Ini adalah alat yang berguna untuk berjaga-jaga.Terima kasih sudah membaca.Sumber
Benchmark C ++Python Graphdata.jsonPenelitian lebih lanjut
Artikel ini hanya sedikit menyentuh topik. Saya mungkin tidak akan membahasnya. Tetapi jika dia melakukannya, maka dia dapat mencakup beberapa aspek berikut:Spesifikasi sistem
Tes dilakukan di PC rumah saya. Hanya pengaturan stok, tidak ada overclocking.- OS: Windows 10 v1903 build 18362
- CPU: Intel i7-8700k @ 3,70 GHz
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 MHz)
- Motherboard: Asus TUF Z370-Plus Gaming