HighLoad ++, Mikhail Tyulenev (MongoDB): Konsistensi sebab-akibat: dari teori ke praktik
Konferensi HighLoad ++ berikutnya akan diadakan pada 6 dan 7 April 2020 di St. Petersburg.Detail dan tiket di sini . HighLoad ++ Siberia 2019. Aula "Krasnoyarsk". 25 Juni 12:00. Abstrak dan presentasi . Kebetulan persyaratan praktis bertentangan dengan teori di mana aspek-aspek penting untuk produk komersial tidak diperhitungkan. Laporan ini menyajikan proses memilih dan menggabungkan berbagai pendekatan untuk menciptakan komponen konsistensi Kausal berdasarkan penelitian akademik berdasarkan persyaratan produk komersial. Siswa akan belajar tentang pendekatan teoritis yang ada untuk jam logis, pelacakan ketergantungan, keamanan sistem, sinkronisasi jam, dan mengapa MongoDB berhenti pada ini atau solusi tersebut.Mikhail Tyulenev (selanjutnya - MT): - Saya akan berbicara tentang konsistensi Kausal - ini adalah fitur yang kami kerjakan di MongoDB. Saya bekerja dalam kelompok sistem terdistribusi, kami melakukannya sekitar dua tahun lalu.
Kebetulan persyaratan praktis bertentangan dengan teori di mana aspek-aspek penting untuk produk komersial tidak diperhitungkan. Laporan ini menyajikan proses memilih dan menggabungkan berbagai pendekatan untuk menciptakan komponen konsistensi Kausal berdasarkan penelitian akademik berdasarkan persyaratan produk komersial. Siswa akan belajar tentang pendekatan teoritis yang ada untuk jam logis, pelacakan ketergantungan, keamanan sistem, sinkronisasi jam, dan mengapa MongoDB berhenti pada ini atau solusi tersebut.Mikhail Tyulenev (selanjutnya - MT): - Saya akan berbicara tentang konsistensi Kausal - ini adalah fitur yang kami kerjakan di MongoDB. Saya bekerja dalam kelompok sistem terdistribusi, kami melakukannya sekitar dua tahun lalu. Dalam prosesnya, saya harus berkenalan dengan banyak Penelitian akademis, karena fitur ini dipelajari dengan baik. Ternyata tidak ada satu artikel yang cocok dengan apa yang diperlukan dalam produksi, database mengingat persyaratan yang sangat spesifik, mungkin, dalam aplikasi produksi.Saya akan berbicara tentang bagaimana kita, sebagai konsumen Riset akademis, menyiapkan sesuatu darinya yang kemudian dapat kita presentasikan kepada pengguna sebagai hidangan siap pakai yang nyaman, aman untuk digunakan.
Dalam prosesnya, saya harus berkenalan dengan banyak Penelitian akademis, karena fitur ini dipelajari dengan baik. Ternyata tidak ada satu artikel yang cocok dengan apa yang diperlukan dalam produksi, database mengingat persyaratan yang sangat spesifik, mungkin, dalam aplikasi produksi.Saya akan berbicara tentang bagaimana kita, sebagai konsumen Riset akademis, menyiapkan sesuatu darinya yang kemudian dapat kita presentasikan kepada pengguna sebagai hidangan siap pakai yang nyaman, aman untuk digunakan.Konsistensi kausal. Mari mendefinisikan konsep
Untuk mulai dengan, saya ingin menguraikan secara umum apa konsistensi Kausal. Ada dua karakter - Leonard dan Penny (seri "The Big Bang Theory"):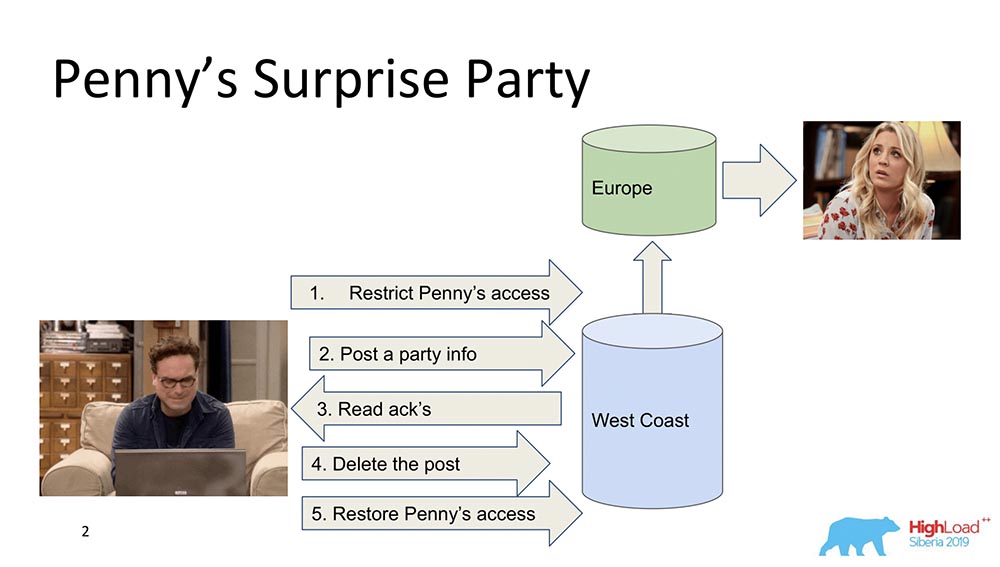 Misalkan Penny ada di Eropa, dan Leonard ingin membuat semacam kejutan baginya, sebuah pesta. Dan dia tidak menghasilkan sesuatu yang lebih baik daripada membuangnya keluar dari daftar teman, mengirimkan pembaruan untuk memberi makan semua teman: "Ayo buat Penny bahagia!" (dia di Eropa, saat tidur, tidak melihat ini semua dan tidak bisa melihat, karena dia tidak ada di sana). Pada akhirnya, ia menghapus posting ini, menghapusnya dari "Feed" dan mengembalikan akses sehingga tidak melihat apa-apa dan tidak ada skandal.Ini semua baik-baik saja, tetapi mari kita asumsikan bahwa sistemnya terdistribusi, dan acara berjalan agak salah. Mungkin, misalnya, kebetulan bahwa pembatasan akses Penny terjadi setelah posting ini muncul, jika acara tidak terhubung oleh hubungan sebab akibat. Sebenarnya, ini adalah contoh ketika konsistensi Kausal diperlukan untuk memenuhi fungsi bisnis (dalam hal ini).Faktanya, ini adalah properti non-sepele dari database - sangat sedikit orang yang mendukungnya. Mari kita beralih ke model.
Misalkan Penny ada di Eropa, dan Leonard ingin membuat semacam kejutan baginya, sebuah pesta. Dan dia tidak menghasilkan sesuatu yang lebih baik daripada membuangnya keluar dari daftar teman, mengirimkan pembaruan untuk memberi makan semua teman: "Ayo buat Penny bahagia!" (dia di Eropa, saat tidur, tidak melihat ini semua dan tidak bisa melihat, karena dia tidak ada di sana). Pada akhirnya, ia menghapus posting ini, menghapusnya dari "Feed" dan mengembalikan akses sehingga tidak melihat apa-apa dan tidak ada skandal.Ini semua baik-baik saja, tetapi mari kita asumsikan bahwa sistemnya terdistribusi, dan acara berjalan agak salah. Mungkin, misalnya, kebetulan bahwa pembatasan akses Penny terjadi setelah posting ini muncul, jika acara tidak terhubung oleh hubungan sebab akibat. Sebenarnya, ini adalah contoh ketika konsistensi Kausal diperlukan untuk memenuhi fungsi bisnis (dalam hal ini).Faktanya, ini adalah properti non-sepele dari database - sangat sedikit orang yang mendukungnya. Mari kita beralih ke model.Model Konsistensi
Apa yang dimaksud dengan model konsistensi dalam database secara umum? Ini adalah beberapa jaminan yang diberikan oleh sistem terdistribusi mengenai data apa dan dalam urutan apa klien dapat menerima.Pada prinsipnya, semua model konsistensi datang ke bagaimana sistem terdistribusi seperti sistem yang bekerja, misalnya, pada anggukan yang sama pada laptop. Dan ini adalah seberapa banyak sistem, yang bekerja pada ribuan "Nodes" yang didistribusikan secara geografis, mirip dengan laptop, di mana semua properti ini dilakukan secara otomatis pada prinsipnya.Oleh karena itu, model konsistensi hanya berlaku untuk sistem terdistribusi. Semua sistem yang sebelumnya ada dan bekerja pada penskalaan vertikal yang sama tidak mengalami masalah seperti itu. Ada satu Buffer Cache, dan semuanya selalu terbaca darinya.Model yang kuat
Sebenarnya, model pertama adalah Strong (atau garis kemampuan naik, seperti yang sering disebut). Ini adalah model konsistensi yang memastikan bahwa setiap perubahan, segera setelah konfirmasi diterima bahwa itu telah terjadi, dapat dilihat oleh semua pengguna sistem.Ini menciptakan tatanan global semua peristiwa dalam database. Ini adalah properti konsistensi yang sangat kuat, dan umumnya sangat mahal. Namun, itu dipelihara dengan sangat baik. Ini sangat mahal dan lambat - mereka jarang digunakan. Ini disebut kemampuan naik.Ada properti lain yang lebih kuat yang didukung di "Spanner" - disebut Konsistensi Eksternal. Kami akan membicarakannya nanti.Kausal
Berikut ini adalah Penyebab, hanya apa yang saya bicarakan. Ada beberapa sublevel antara Strong dan Causal yang tidak akan saya bicarakan, tetapi semuanya turun ke Causal. Ini adalah model yang penting karena ini adalah yang terkuat dari semua model, konsistensi terkuat di hadapan jaringan atau partisi.Kausal sebenarnya adalah situasi di mana peristiwa dihubungkan oleh hubungan sebab akibat. Sangat sering mereka dianggap sebagai Baca hak Anda dari sudut pandang klien. Jika klien mengamati beberapa nilai, ia tidak bisa melihat nilai-nilai yang ada di masa lalu. Dia sudah mulai melihat pembacaan awalan. Semuanya bermuara pada hal yang sama.Kausal sebagai model konsistensi adalah pengurutan sebagian acara di server, di mana acara dari semua klien diamati dalam urutan yang sama. Dalam hal ini, Leonard dan Penny.Akhirnya
Model ketiga adalah Konsistensi Akhir. Inilah yang benar-benar mendukung semua sistem terdistribusi, model minimal yang secara umum masuk akal. Ini berarti yang berikut: ketika kami memiliki beberapa perubahan dalam data, mereka menjadi konsisten di beberapa titik.Pada saat seperti itu, dia tidak mengatakan apa-apa, kalau tidak dia akan berubah menjadi Konsistensi Eksternal - akan ada cerita yang sama sekali berbeda. Meskipun demikian, ini adalah model yang sangat populer, yang paling umum. Secara default, semua pengguna sistem terdistribusi menggunakan Konsistensi Akhir.Saya ingin memberikan beberapa contoh komparatif: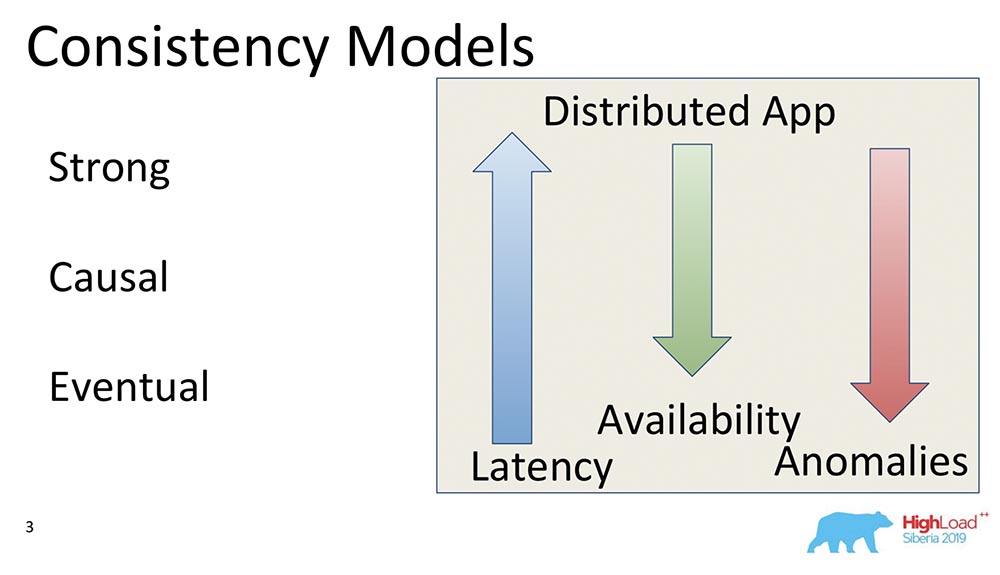 Apa arti panah-panah ini?
Apa arti panah-panah ini?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
Ketika Anda melihat kata-kata konsistensi, ketersediaan - apa yang terlintas dalam pikiran? Kanan - teorema CAP! Sekarang saya ingin menghilangkan mitos ... Ini bukan saya - ada Martin Kleppman, yang menulis artikel yang bagus, buku yang bagus. Teorema CAP adalah prinsip yang dirumuskan pada tahun 2000-an bahwa Konsistensi, Ketersediaan, Partisi: ambil dua, dan Anda tidak dapat memilih tiga. Itu adalah prinsip tertentu. Itu terbukti sebagai teorema beberapa tahun kemudian, oleh Gilbert dan Lynch. Kemudian menjadi mantra - sistem mulai dibagi menjadi CA, CP, AP dan sebagainya.Teorema ini sebenarnya dibuktikan karena alasan berikut ... Pertama, Ketersediaan dianggap bukan sebagai nilai kontinu dari nol hingga ratusan (0 - sistem "mati", 100 - jawaban cepat; kita sudah terbiasa mempertimbangkannya), tetapi sebagai properti algoritma , yang memastikan bahwa dengan semua eksekusi itu mengembalikan data.Tidak ada sepatah kata pun tentang waktu respons! Ada algoritma yang mengembalikan data setelah 100 tahun - algoritma yang tersedia dengan sangat baik, yang merupakan bagian dari teorema CAP.Kedua: teorema terbukti untuk perubahan nilai-nilai kunci yang sama, meskipun fakta bahwa perubahan ini adalah garis resizable. Ini berarti bahwa pada kenyataannya mereka praktis tidak digunakan, karena model-model itu berbeda, Konsistensi Akhir, Konsistensi Kuat (mungkin).Kenapa ini semua? Lebih lanjut, teorema CAP dalam bentuk yang dibuktikan secara praktis tidak berlaku jarang digunakan. Dalam bentuk teoretis, entah bagaimana membatasi segalanya. Ternyata prinsip tertentu yang secara intuisi benar, tetapi sama sekali tidak terbukti secara umum.
Teorema CAP adalah prinsip yang dirumuskan pada tahun 2000-an bahwa Konsistensi, Ketersediaan, Partisi: ambil dua, dan Anda tidak dapat memilih tiga. Itu adalah prinsip tertentu. Itu terbukti sebagai teorema beberapa tahun kemudian, oleh Gilbert dan Lynch. Kemudian menjadi mantra - sistem mulai dibagi menjadi CA, CP, AP dan sebagainya.Teorema ini sebenarnya dibuktikan karena alasan berikut ... Pertama, Ketersediaan dianggap bukan sebagai nilai kontinu dari nol hingga ratusan (0 - sistem "mati", 100 - jawaban cepat; kita sudah terbiasa mempertimbangkannya), tetapi sebagai properti algoritma , yang memastikan bahwa dengan semua eksekusi itu mengembalikan data.Tidak ada sepatah kata pun tentang waktu respons! Ada algoritma yang mengembalikan data setelah 100 tahun - algoritma yang tersedia dengan sangat baik, yang merupakan bagian dari teorema CAP.Kedua: teorema terbukti untuk perubahan nilai-nilai kunci yang sama, meskipun fakta bahwa perubahan ini adalah garis resizable. Ini berarti bahwa pada kenyataannya mereka praktis tidak digunakan, karena model-model itu berbeda, Konsistensi Akhir, Konsistensi Kuat (mungkin).Kenapa ini semua? Lebih lanjut, teorema CAP dalam bentuk yang dibuktikan secara praktis tidak berlaku jarang digunakan. Dalam bentuk teoretis, entah bagaimana membatasi segalanya. Ternyata prinsip tertentu yang secara intuisi benar, tetapi sama sekali tidak terbukti secara umum.Konsistensi sebab akibat - model terkuat
Apa yang terjadi sekarang - Anda bisa mendapatkan ketiga hal: Konsistensi, Ketersediaan dapat diperoleh dengan menggunakan Partisi. Secara khusus, konsistensi kausal adalah model konsistensi terkuat, yang, di hadapan Partisi (istirahat jaringan), masih berfungsi. Karena itu, ini sangat menarik, dan karena itu kami terlibat di dalamnya. Pertama, ini menyederhanakan pekerjaan pengembang aplikasi. Secara khusus, ada banyak dukungan dari server: ketika semua catatan yang terjadi di dalam satu klien dijamin akan tiba dalam urutan ini pada klien lain. Kedua, tahan partisi.
Pertama, ini menyederhanakan pekerjaan pengembang aplikasi. Secara khusus, ada banyak dukungan dari server: ketika semua catatan yang terjadi di dalam satu klien dijamin akan tiba dalam urutan ini pada klien lain. Kedua, tahan partisi.Dapur Interior MongoDB
Mengingat makan siang itu, kami pindah ke dapur. Saya akan berbicara tentang model sistem, yaitu, apa itu MongoDB bagi mereka yang pertama kali mendengar tentang database seperti itu.
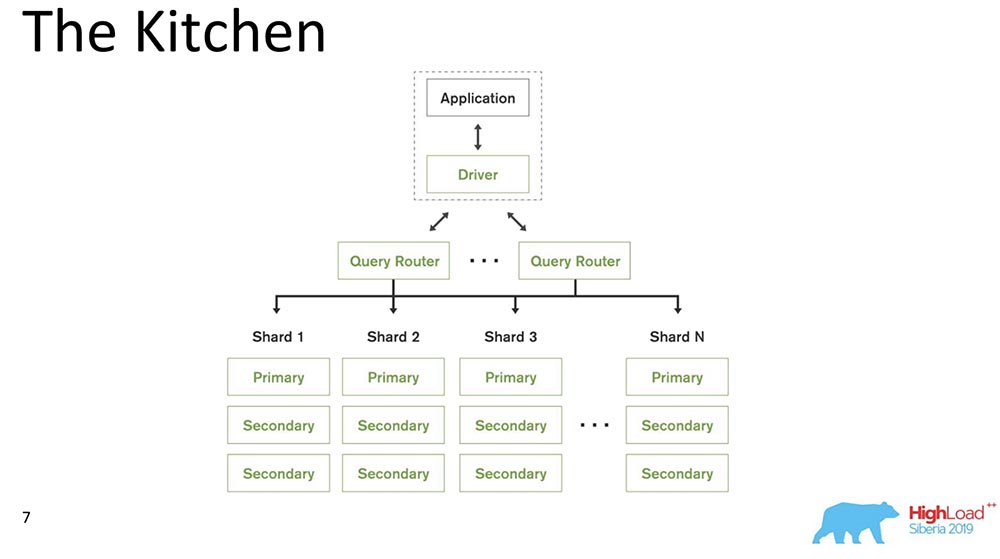 MongoDB (selanjutnya disebut "MongoBD") adalah sistem terdistribusi yang mendukung penskalaan horizontal, yaitu sharding; dan di dalam setiap beling, ia juga mendukung redundansi data, yaitu replikasi.Sharding dalam "MongoBD" (database non-relasional) melakukan penyeimbangan otomatis, yaitu, setiap kumpulan dokumen (atau "tabel" dalam hal data relasional) menjadi potongan-potongan, dan sudah server secara otomatis memindahkan mereka di antara pecahan.Router Kueri yang mendistribusikan kueri untuk klien adalah beberapa klien yang digunakannya. Dia sudah tahu di mana dan data apa yang berada, mengirim semua permintaan ke beling yang benar.Poin penting lainnya: MongoDB adalah master tunggal. Ada satu Pratama - dapat mengambil catatan yang mendukung kunci yang dikandungnya. Anda tidak dapat menulis multi-master.Kami membuat rilis 4.2 - hal-hal menarik baru muncul di sana. Secara khusus, mereka memasukkan Lucene - pencarian - itu adalah executable java langsung di "Mongo", dan di sana menjadi mungkin untuk mencari melalui Lucene, sama seperti di "Elastic".Dan mereka membuat produk baru - Bagan, itu juga tersedia di Atlas (Mongo sendiri Cloud). Mereka memiliki Tier Gratis - Anda dapat bermain-main dengan ini. Saya sangat menyukai grafik - visualisasi data sangat intuitif.
MongoDB (selanjutnya disebut "MongoBD") adalah sistem terdistribusi yang mendukung penskalaan horizontal, yaitu sharding; dan di dalam setiap beling, ia juga mendukung redundansi data, yaitu replikasi.Sharding dalam "MongoBD" (database non-relasional) melakukan penyeimbangan otomatis, yaitu, setiap kumpulan dokumen (atau "tabel" dalam hal data relasional) menjadi potongan-potongan, dan sudah server secara otomatis memindahkan mereka di antara pecahan.Router Kueri yang mendistribusikan kueri untuk klien adalah beberapa klien yang digunakannya. Dia sudah tahu di mana dan data apa yang berada, mengirim semua permintaan ke beling yang benar.Poin penting lainnya: MongoDB adalah master tunggal. Ada satu Pratama - dapat mengambil catatan yang mendukung kunci yang dikandungnya. Anda tidak dapat menulis multi-master.Kami membuat rilis 4.2 - hal-hal menarik baru muncul di sana. Secara khusus, mereka memasukkan Lucene - pencarian - itu adalah executable java langsung di "Mongo", dan di sana menjadi mungkin untuk mencari melalui Lucene, sama seperti di "Elastic".Dan mereka membuat produk baru - Bagan, itu juga tersedia di Atlas (Mongo sendiri Cloud). Mereka memiliki Tier Gratis - Anda dapat bermain-main dengan ini. Saya sangat menyukai grafik - visualisasi data sangat intuitif.Bahan konsistensi kausal
Saya menghitung sekitar 230 artikel yang diterbitkan tentang topik ini - dari Leslie Lampert. Sekarang dari ingatan saya, saya akan membawa kepada Anda beberapa bagian dari materi ini. Semuanya dimulai dengan sebuah artikel oleh Leslie Lampert, yang ditulis pada tahun 1970-an. Seperti yang Anda lihat, beberapa penelitian tentang topik ini masih berlangsung. Sekarang konsistensi Kausal sedang mengalami minat sehubungan dengan pengembangan sistem terdistribusi.
Semuanya dimulai dengan sebuah artikel oleh Leslie Lampert, yang ditulis pada tahun 1970-an. Seperti yang Anda lihat, beberapa penelitian tentang topik ini masih berlangsung. Sekarang konsistensi Kausal sedang mengalami minat sehubungan dengan pengembangan sistem terdistribusi.Keterbatasan
Apa batasannya? Ini sebenarnya adalah salah satu poin utama, karena pembatasan yang diberlakukan sistem produksi sangat berbeda dari pembatasan yang ada dalam artikel akademik. Seringkali mereka cukup buatan.
- Pertama, "MongoDB" adalah master tunggal, seperti yang telah saya katakan (ini sangat disederhanakan).
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- Poin lain umumnya anti-akademik: kompatibilitas versi sebelumnya dan masa depan. Driver lama harus mendukung pembaruan baru, dan database harus mendukung driver lama.
Secara umum, semua ini memberlakukan batasan.Komponen konsistensi kausal
Sekarang saya akan berbicara tentang beberapa komponen. Jika kita mempertimbangkan konsistensi Kausal umum, kita dapat membedakan blok. Kami memilih dari karya-karya yang termasuk blok tertentu: Pelacakan Ketergantungan, pilihan jam, bagaimana jam tangan ini dapat disinkronkan satu sama lain, dan bagaimana kami memastikan keamanan - ini adalah rencana perkiraan dari apa yang akan saya bicarakan:
Pelacakan Ketergantungan Penuh
Mengapa itu dibutuhkan? Agar ketika data direplikasi - setiap catatan, setiap perubahan data berisi informasi tentang perubahan yang bergantung padanya. Perubahan pertama dan naif adalah ketika setiap pesan yang berisi catatan berisi informasi tentang pesan sebelumnya: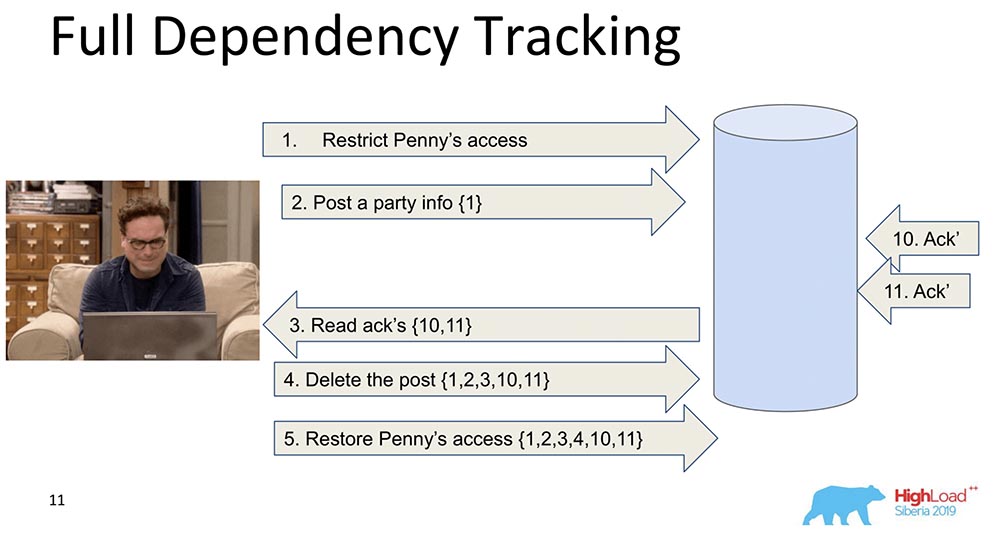 Dalam contoh ini, nomor dalam kurung adalah jumlah rekaman. Kadang-kadang catatan dengan nilai ini bahkan ditransfer secara keseluruhan, kadang-kadang beberapa versi ditransfer. Intinya adalah bahwa setiap perubahan berisi informasi tentang yang sebelumnya (jelas itu membawa semuanya dengan sendirinya).Mengapa kami memutuskan untuk tidak menggunakan pendekatan ini (pelacakan lengkap)? Jelas, karena pendekatan ini tidak praktis: setiap perubahan di jejaring sosial tergantung pada semua perubahan sebelumnya di jejaring sosial ini, mentransmisikan, katakanlah, Facebook atau Vkontakte di setiap pembaruan. Namun demikian, ada banyak penelitian yaitu Pelacakan Ketergantungan Penuh - ini adalah jejaring sosial, untuk beberapa situasi ini benar-benar berfungsi.
Dalam contoh ini, nomor dalam kurung adalah jumlah rekaman. Kadang-kadang catatan dengan nilai ini bahkan ditransfer secara keseluruhan, kadang-kadang beberapa versi ditransfer. Intinya adalah bahwa setiap perubahan berisi informasi tentang yang sebelumnya (jelas itu membawa semuanya dengan sendirinya).Mengapa kami memutuskan untuk tidak menggunakan pendekatan ini (pelacakan lengkap)? Jelas, karena pendekatan ini tidak praktis: setiap perubahan di jejaring sosial tergantung pada semua perubahan sebelumnya di jejaring sosial ini, mentransmisikan, katakanlah, Facebook atau Vkontakte di setiap pembaruan. Namun demikian, ada banyak penelitian yaitu Pelacakan Ketergantungan Penuh - ini adalah jejaring sosial, untuk beberapa situasi ini benar-benar berfungsi.Pelacakan Ketergantungan Eksplisit
Yang berikutnya lebih terbatas. Di sini juga, transmisi informasi dipertimbangkan, tetapi hanya yang jelas tergantung. Apa yang tergantung pada apa, sebagai suatu peraturan, sudah ditentukan oleh Aplikasi. Ketika data direplikasi, hanya respons yang dikembalikan ketika permintaan dibuat, ketika dependensi sebelumnya terpenuhi, yaitu, ditampilkan. Ini adalah inti dari bagaimana konsistensi kausal bekerja.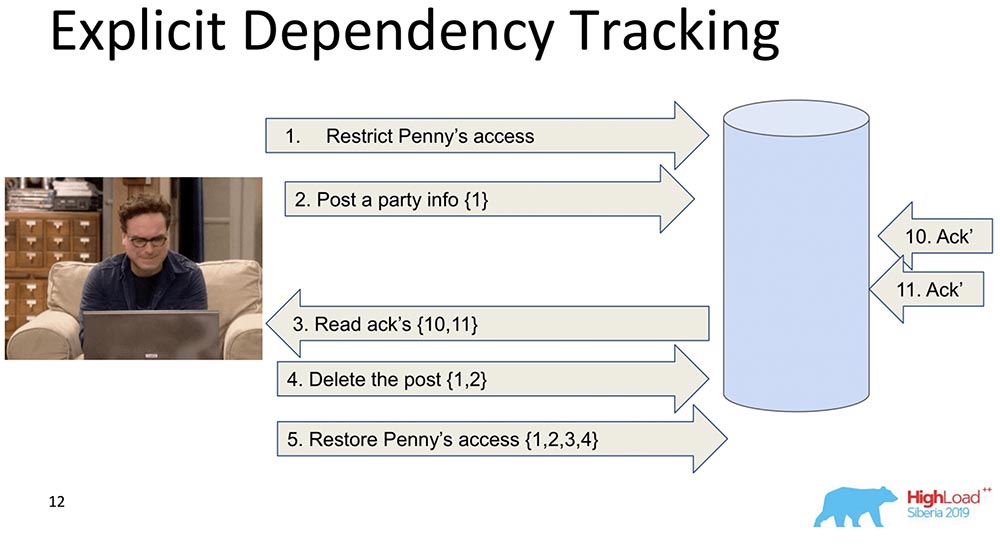 Dia melihat bahwa catatan 5 tergantung pada catatan 1, 2, 3, 4 - masing-masing, dia menunggu sebelum klien mendapatkan akses ke perubahan yang dibuat oleh keputusan akses Penny ketika semua perubahan sebelumnya telah diteruskan ke database.Ini juga tidak cocok untuk kita, karena bagaimanapun juga ada terlalu banyak informasi, dan ini akan melambat. Ada pendekatan yang berbeda ...
Dia melihat bahwa catatan 5 tergantung pada catatan 1, 2, 3, 4 - masing-masing, dia menunggu sebelum klien mendapatkan akses ke perubahan yang dibuat oleh keputusan akses Penny ketika semua perubahan sebelumnya telah diteruskan ke database.Ini juga tidak cocok untuk kita, karena bagaimanapun juga ada terlalu banyak informasi, dan ini akan melambat. Ada pendekatan yang berbeda ...Jam Lamport
Mereka sudah sangat tua. Lamport Clock menyiratkan bahwa ketergantungan ini runtuh menjadi fungsi skalar yang disebut Lamport Clock.Fungsi skalar adalah angka abstrak. Sering disebut waktu logis. Di setiap acara, penghitung ini bertambah. Penghitung, yang saat ini diketahui prosesnya, mengirim setiap pesan. Jelas bahwa proses dapat tidak sinkron, mereka dapat memiliki waktu yang sama sekali berbeda. Namun demikian, sistem entah bagaimana menyeimbangkan jam dengan pesan seperti itu. Apa yang terjadi dalam kasus ini?Saya membagi pecahan besar itu menjadi dua sehingga jelas: Teman-teman dapat hidup dalam satu simpul yang berisi sepotong koleksi, dan Feed dapat hidup di simpul lain yang berisi sepotong koleksi ini. Sudah jelas bagaimana mereka bisa keluar dari belokan? Pertama, Feed berkata, "Replicated," dan kemudian Friends. Jika sistem tidak memberikan jaminan bahwa Umpan tidak akan ditampilkan sampai dependensi Teman di koleksi Teman juga dikirimkan, maka kami hanya akan memiliki situasi yang saya sebutkan.Anda melihat bagaimana penghitung waktu meningkat secara logis pada Umpan: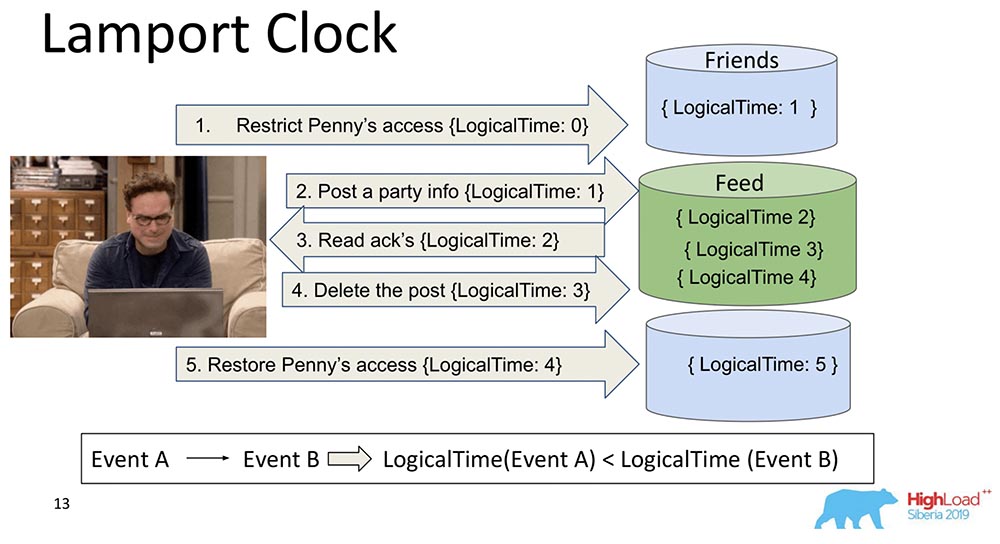 Dengan demikian, properti utama dari Lamport Clock ini dan konsistensi kausal (dijelaskan melalui Lamport Clock) adalah sebagai berikut: jika kita memiliki event A dan B, dan event B tergantung pada event A *, maka itu mengikuti bahwa LogicalTime dari Event A kurang daripada LogicalTime dari Peristiwa B.* Kadang-kadang mereka bahkan mengatakan bahwa A terjadi sebelum B, yaitu, A terjadi sebelum B - ini adalah jenis hubungan yang sebagian memerintahkan seluruh rangkaian peristiwa yang umumnya terjadi.Kebalikannya salah. Ini sebenarnya salah satu kelemahan utama dari Lamport Clock - pemesanan parsial. Ada konsep peristiwa simultan, yaitu peristiwa di mana tidak ada (A terjadi sebelum B) maupun (A terjadi sebelum B). Contohnya adalah penambahan paralel oleh Leonard ke teman-teman orang lain (bahkan bukan Leonard, tetapi Sheldon, misalnya).Ini adalah properti yang sering digunakan ketika bekerja dengan jam tangan Lamport: mereka melihat fungsinya dengan tepat dan menarik kesimpulan dari ini - mungkin acara ini tergantung. Karena dalam satu arah ini benar: jika LogicalTime A kurang dari LogicalTime B, maka B tidak dapat terjadi sebelum A; dan jika lebih, maka mungkin.
Dengan demikian, properti utama dari Lamport Clock ini dan konsistensi kausal (dijelaskan melalui Lamport Clock) adalah sebagai berikut: jika kita memiliki event A dan B, dan event B tergantung pada event A *, maka itu mengikuti bahwa LogicalTime dari Event A kurang daripada LogicalTime dari Peristiwa B.* Kadang-kadang mereka bahkan mengatakan bahwa A terjadi sebelum B, yaitu, A terjadi sebelum B - ini adalah jenis hubungan yang sebagian memerintahkan seluruh rangkaian peristiwa yang umumnya terjadi.Kebalikannya salah. Ini sebenarnya salah satu kelemahan utama dari Lamport Clock - pemesanan parsial. Ada konsep peristiwa simultan, yaitu peristiwa di mana tidak ada (A terjadi sebelum B) maupun (A terjadi sebelum B). Contohnya adalah penambahan paralel oleh Leonard ke teman-teman orang lain (bahkan bukan Leonard, tetapi Sheldon, misalnya).Ini adalah properti yang sering digunakan ketika bekerja dengan jam tangan Lamport: mereka melihat fungsinya dengan tepat dan menarik kesimpulan dari ini - mungkin acara ini tergantung. Karena dalam satu arah ini benar: jika LogicalTime A kurang dari LogicalTime B, maka B tidak dapat terjadi sebelum A; dan jika lebih, maka mungkin.Vektor Jam
Perkembangan logis dari jam tangan Lamport adalah Vector Clock. Mereka berbeda karena setiap node yang ada di sini berisi jam tersendiri, dan mereka ditransmisikan sebagai vektor.Dalam hal ini, Anda melihat bahwa indeks nol vektor bertanggung jawab untuk Umpan, dan indeks pertama vektor adalah untuk Teman (masing-masing node ini). Dan sekarang mereka akan meningkat: indeks nol "Umpan" meningkat saat merekam - 1, 2, 3: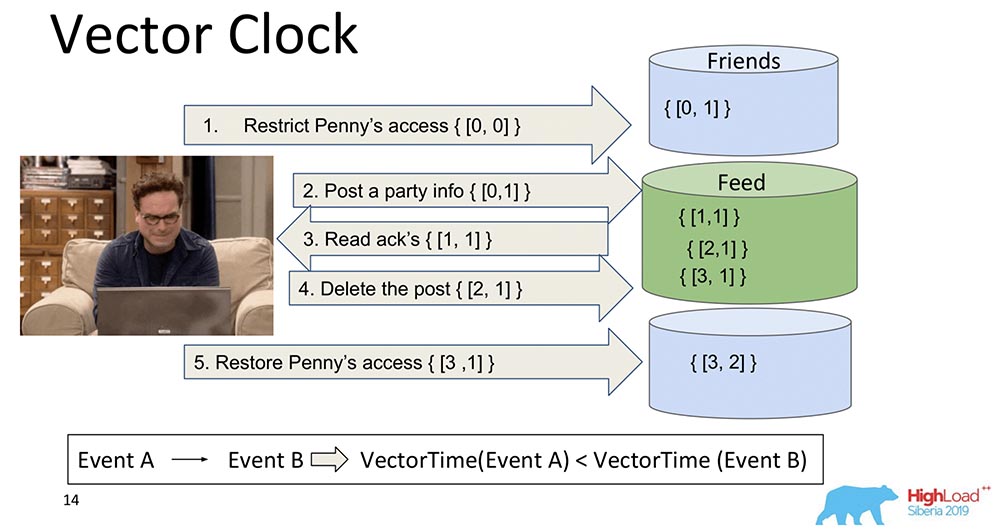 Bagaimana Jam Vektor lebih baik? Fakta bahwa mereka dapat mengetahui peristiwa mana yang simultan dan kapan mereka terjadi pada node yang berbeda. Ini sangat penting untuk sistem sharding seperti MongoBD. Namun, kami tidak memilih ini, meskipun ini adalah hal yang luar biasa, dan ini berfungsi dengan baik, dan mungkin akan cocok untuk kami ...Jika kita memiliki 10 ribu pecahan, kita tidak dapat mentransfer 10 ribu komponen, bahkan jika kita kompres, kita memikirkan sesuatu yang lain - semua sama, muatannya akan beberapa kali lebih sedikit dari volume seluruh vektor ini. Karena itu, menggerogoti hati dan gigi kami, kami meninggalkan pendekatan ini dan pindah ke yang lain.
Bagaimana Jam Vektor lebih baik? Fakta bahwa mereka dapat mengetahui peristiwa mana yang simultan dan kapan mereka terjadi pada node yang berbeda. Ini sangat penting untuk sistem sharding seperti MongoBD. Namun, kami tidak memilih ini, meskipun ini adalah hal yang luar biasa, dan ini berfungsi dengan baik, dan mungkin akan cocok untuk kami ...Jika kita memiliki 10 ribu pecahan, kita tidak dapat mentransfer 10 ribu komponen, bahkan jika kita kompres, kita memikirkan sesuatu yang lain - semua sama, muatannya akan beberapa kali lebih sedikit dari volume seluruh vektor ini. Karena itu, menggerogoti hati dan gigi kami, kami meninggalkan pendekatan ini dan pindah ke yang lain.Spanner TrueTime. Jam atom
Saya mengatakan bahwa akan ada cerita tentang Spanner. Ini adalah hal yang keren, tepat abad ke-21: jam atom, sinkronisasi GPS.Ide apa? Spanner adalah sistem Google yang baru-baru ini bahkan menjadi tersedia untuk orang-orang (mereka telah melampirkan SQL ke dalamnya). Setiap transaksi di sana memiliki cap waktu. Karena waktu disinkronkan *, setiap peristiwa dapat ditetapkan waktu tertentu - jam atom memiliki waktu tunggu, setelah itu dijamin bahwa waktu lain akan terjadi. Jadi, hanya menulis ke database dan menunggu periode waktu tertentu, serialisasi acara dijamin secara otomatis. Mereka memiliki model Konsistensi yang terkuat, yang pada prinsipnya dapat dibayangkan - itu adalah Konsistensi Eksternal.* Ini adalah masalah utama jam tangan Lampart - mereka tidak pernah sinkron pada sistem terdistribusi. Mereka dapat menyimpang, bahkan dengan NTP, mereka masih tidak bekerja dengan baik. "Spanner" memiliki jam atom dan sinkronisasi tampaknya menjadi mikrodetik.Kenapa kita tidak memilih? Kami tidak menganggap bahwa pengguna kami memiliki jam atom bawaan. Ketika mereka muncul, dimasukkan ke dalam setiap laptop, akan ada semacam sinkronisasi GPS yang sangat keren - lalu ya ... Sementara itu, yang terbaik yang mungkin adalah Amazon, Base Station untuk fanatik ... Oleh karena itu, kami menggunakan jam tangan lain.
Jadi, hanya menulis ke database dan menunggu periode waktu tertentu, serialisasi acara dijamin secara otomatis. Mereka memiliki model Konsistensi yang terkuat, yang pada prinsipnya dapat dibayangkan - itu adalah Konsistensi Eksternal.* Ini adalah masalah utama jam tangan Lampart - mereka tidak pernah sinkron pada sistem terdistribusi. Mereka dapat menyimpang, bahkan dengan NTP, mereka masih tidak bekerja dengan baik. "Spanner" memiliki jam atom dan sinkronisasi tampaknya menjadi mikrodetik.Kenapa kita tidak memilih? Kami tidak menganggap bahwa pengguna kami memiliki jam atom bawaan. Ketika mereka muncul, dimasukkan ke dalam setiap laptop, akan ada semacam sinkronisasi GPS yang sangat keren - lalu ya ... Sementara itu, yang terbaik yang mungkin adalah Amazon, Base Station untuk fanatik ... Oleh karena itu, kami menggunakan jam tangan lain.Jam Hibrid
Inilah sebenarnya yang menandai "MongoBD" sambil memastikan konsistensi Kausal. Apa itu hibrida? Hibrida adalah nilai skalar, tetapi terdiri dari dua komponen:
- Yang pertama adalah era unix (berapa detik telah berlalu sejak "awal dunia komputer").
- Yang kedua adalah beberapa kenaikan, juga int 32-bit unsigned.
Itu saja, sebenarnya. Ada pendekatan semacam itu: bagian yang bertanggung jawab atas waktu disinkronkan dengan jam sepanjang waktu; setiap kali pembaruan terjadi, bagian ini disinkronkan dengan jam dan ternyata waktu selalu lebih atau kurang benar, dan kenaikan memungkinkan Anda untuk membedakan antara peristiwa yang terjadi pada waktu yang sama.Mengapa ini penting untuk MongoBD? Karena ini memungkinkan Anda untuk membuat semacam restorant cadangan pada titik waktu tertentu, yaitu acara tersebut diindeks berdasarkan waktu. Ini penting ketika beberapa acara dibutuhkan; untuk database, peristiwa adalah perubahan pada database yang terjadi pada waktu-waktu tertentu.Saya hanya akan memberi tahu Anda alasan paling penting (tolong, jangan beri tahu siapa pun)! Kami melakukan ini karena data terurut dan terindeks di MongoDB OpLog terlihat seperti ini. OpLog adalah struktur data yang benar-benar mengandung semua perubahan dalam basis data: mereka pertama-tama pergi ke OpLog, dan kemudian mereka sudah diterapkan ke Penyimpanan itu sendiri dalam kasus ketika itu adalah tanggal atau beling yang direplikasi.Itulah alasan utama. Namun, ada juga persyaratan praktis untuk mengembangkan database, yang artinya harus sederhana - hanya ada sedikit kode, sesedikit mungkin kerusakan yang perlu ditulis ulang dan diuji. Fakta bahwa oplog kami diindeks oleh arloji hybrid sangat membantu, dan memungkinkan kami untuk membuat pilihan yang tepat. Ini benar-benar terbayar dan entah bagaimana ajaibnya, pada prototipe pertama. Itu sangat keren!Sinkronisasi jam
Ada beberapa metode sinkronisasi yang dijelaskan dalam literatur ilmiah. Saya berbicara tentang sinkronisasi ketika kami memiliki dua pecahan yang berbeda. Jika ada satu set replika, tidak perlu sinkronisasi di sana: itu adalah "master tunggal"; kami memiliki OpLog di mana semua perubahan masuk - dalam hal ini semuanya sudah dipesan secara berurutan di "Oplog" itu sendiri. Tetapi jika kita memiliki dua pecahan yang berbeda, sinkronisasi waktu adalah penting di sini. Di sini jam vektor lebih membantu! Tetapi kita tidak memilikinya. Yang kedua adalah Detak Jantung. Anda dapat bertukar beberapa sinyal yang muncul setiap satuan waktu. Tapi Hartbit terlalu lambat, kami tidak bisa memberikan latensi kepada klien kami.Waktu yang sebenarnya, tentu saja, adalah hal yang luar biasa. Tapi, sekali lagi, ini mungkin masa depan ... Meskipun Atlas sudah dapat dilakukan, sudah ada sinkronisasi waktu cepat "Amazon". Tetapi itu tidak akan tersedia untuk semua orang.Gosip adalah saat semua pesan menyertakan waktu. Ini kira-kira yang kita gunakan. Setiap pesan antara node, driver, router dari node data, benar-benar segalanya untuk "MongoDB" - ini adalah beberapa elemen, komponen database yang berisi jam yang mengalir. Di mana-mana mereka memiliki arti waktu hibrid, itu ditransmisikan. 64 bit? Itu memungkinkan, itu mungkin.
Yang kedua adalah Detak Jantung. Anda dapat bertukar beberapa sinyal yang muncul setiap satuan waktu. Tapi Hartbit terlalu lambat, kami tidak bisa memberikan latensi kepada klien kami.Waktu yang sebenarnya, tentu saja, adalah hal yang luar biasa. Tapi, sekali lagi, ini mungkin masa depan ... Meskipun Atlas sudah dapat dilakukan, sudah ada sinkronisasi waktu cepat "Amazon". Tetapi itu tidak akan tersedia untuk semua orang.Gosip adalah saat semua pesan menyertakan waktu. Ini kira-kira yang kita gunakan. Setiap pesan antara node, driver, router dari node data, benar-benar segalanya untuk "MongoDB" - ini adalah beberapa elemen, komponen database yang berisi jam yang mengalir. Di mana-mana mereka memiliki arti waktu hibrid, itu ditransmisikan. 64 bit? Itu memungkinkan, itu mungkin.Bagaimana semuanya bekerja bersama?
Di sini saya melihat satu set replika untuk membuatnya sedikit lebih mudah. Ada Pratama dan Sekunder. Sekunder melakukan replikasi dan tidak selalu sepenuhnya disinkronkan dengan Pratama.Ada sisipan (insert) di "Primaries" dengan nilai waktu tertentu. Sisipan ini menambah penghitung internal sebesar 11, jika maksimum. Atau akan memeriksa nilai jam dan menyinkronkan jam jika jam lebih besar. Ini memungkinkan Anda untuk mengurutkan berdasarkan waktu.Setelah dia membuat catatan, momen penting terjadi. Jamnya berada di "MongoDB" dan bertambah hanya jika dicatat dalam "Oplog". Ini adalah peristiwa yang mengubah keadaan sistem. Benar-benar di semua artikel klasik, suatu peristiwa dianggap sebagai pesan yang memasuki sebuah simpul: pesan telah tiba - itu berarti sistem telah mengubah kondisinya.Hal ini disebabkan oleh fakta bahwa selama penelitian tidak sepenuhnya mungkin untuk memahami bagaimana pesan ini akan ditafsirkan. Kita tahu pasti bahwa jika itu tidak tercermin dalam "Oplog", maka itu tidak akan ditafsirkan dengan cara apa pun, dan hanya entri dalam "Oplog" adalah perubahan dalam status sistem. Ini menyederhanakan segalanya bagi kita: model menyederhanakan dan memungkinkan kita untuk mengatur dalam kerangka satu set replika, dan banyak hal berguna lainnya.Ini mengembalikan nilai yang telah direkam dalam "Oplog" - kita tahu bahwa dalam "Oplog" nilai ini sudah ada, dan waktunya adalah 12. Sekarang, katakanlah, pembacaan dimulai dari node lain (Sekunder), dan sudah ditransfer setelahClusterTime sendiri pesan. Dia mengatakan, "Aku butuh semua yang terjadi setelah setidaknya 12 atau selama dua belas" (lihat gbr. Di atas).Inilah yang disebut Kausal a konsisten (CAT). Ada semacam teori dalam teori bahwa itu adalah sepotong waktu, yang konsisten dalam dirinya sendiri. Dalam hal ini, kita dapat mengatakan bahwa ini adalah keadaan sistem yang diamati pada waktu 12.Sekarang tidak ada apa-apa di sini, karena tampaknya meniru situasi ketika Sekunder perlu mereplikasi data dari Pratama. Dia sedang menunggu ... Dan sekarang data telah datang - mengembalikan nilai-nilai ini kembali.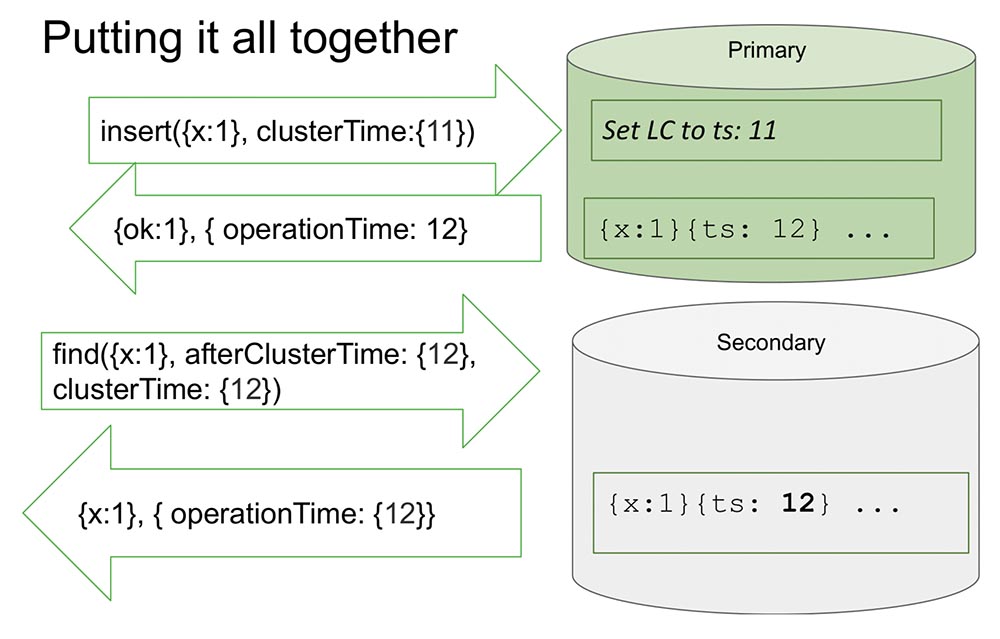 Begitulah cara kerjanya. Hampir.Apa artinya "hampir"? Mari kita asumsikan bahwa ada beberapa orang yang telah membaca dan memahami bagaimana semua ini bekerja. Saya menyadari bahwa setiap kali ClusterTime terjadi, itu memperbarui jam logis internal, dan kemudian catatan berikutnya meningkat satu. Fungsi ini membutuhkan 20 baris. Misalkan orang ini mentransmisikan kemungkinan nomor 64-bit terbesar, minus satu.Mengapa minus satu? Karena jam internal diganti dengan nilai ini (jelas, ini adalah kemungkinan terbesar dan lebih dari waktu saat ini), maka akan ada entri di "Olog", dan jam akan bertambah satu lagi - dan akan ada nilai maksimum (hanya ada semua unit, tidak ada tempat untuk pergi , int yang tidak ditandatangani).Jelas bahwa setelah ini sistem menjadi sepenuhnya tidak dapat diakses dengan sia-sia. Itu hanya dapat dibongkar, dibersihkan - banyak pekerjaan manual. Ketersediaan penuh:
Begitulah cara kerjanya. Hampir.Apa artinya "hampir"? Mari kita asumsikan bahwa ada beberapa orang yang telah membaca dan memahami bagaimana semua ini bekerja. Saya menyadari bahwa setiap kali ClusterTime terjadi, itu memperbarui jam logis internal, dan kemudian catatan berikutnya meningkat satu. Fungsi ini membutuhkan 20 baris. Misalkan orang ini mentransmisikan kemungkinan nomor 64-bit terbesar, minus satu.Mengapa minus satu? Karena jam internal diganti dengan nilai ini (jelas, ini adalah kemungkinan terbesar dan lebih dari waktu saat ini), maka akan ada entri di "Olog", dan jam akan bertambah satu lagi - dan akan ada nilai maksimum (hanya ada semua unit, tidak ada tempat untuk pergi , int yang tidak ditandatangani).Jelas bahwa setelah ini sistem menjadi sepenuhnya tidak dapat diakses dengan sia-sia. Itu hanya dapat dibongkar, dibersihkan - banyak pekerjaan manual. Ketersediaan penuh: Selain itu, jika ini direplikasi di tempat lain, maka seluruh kluster hanya berbaring. Situasi yang benar-benar tidak dapat diterima yang dapat diatur siapa pun dengan sangat cepat dan sederhana! Karena itu, kami menganggap momen ini sebagai salah satu momen terpenting. Bagaimana cara mencegahnya?
Selain itu, jika ini direplikasi di tempat lain, maka seluruh kluster hanya berbaring. Situasi yang benar-benar tidak dapat diterima yang dapat diatur siapa pun dengan sangat cepat dan sederhana! Karena itu, kami menganggap momen ini sebagai salah satu momen terpenting. Bagaimana cara mencegahnya?Cara kami adalah menandatangani clusterTime
Jadi itu dikirim dalam pesan (sebelum teks biru). Tetapi kami juga mulai membuat tanda tangan (teks biru): Tanda tangan dihasilkan oleh kunci yang disimpan di dalam basis data, di dalam perimeter yang dilindungi; itu dihasilkan, diperbarui (pengguna tidak melihat apa-apa). Hash dihasilkan, dan setiap pesan ditandatangani selama pembuatan, dan divalidasi setelah diterima.Mungkin, muncul pertanyaan pada orang: "Berapa lambatnya?" Saya mengatakan bahwa itu harus bekerja dengan cepat, terutama karena tidak adanya fitur ini.Apa artinya menggunakan konsistensi kausal dalam kasus ini? Ini akan menampilkan parameter afterClusterTime. Dan tanpa itu, itu hanya akan memberikan nilai. Gosip, sejak versi 3.6, selalu berhasil.Jika kita meninggalkan generasi tanda tangan yang konstan, ini akan memperlambat sistem bahkan tanpa adanya fitur, yang tidak memenuhi pendekatan dan persyaratan kami. Dan apa yang telah kita lakukan?
tangan dihasilkan oleh kunci yang disimpan di dalam basis data, di dalam perimeter yang dilindungi; itu dihasilkan, diperbarui (pengguna tidak melihat apa-apa). Hash dihasilkan, dan setiap pesan ditandatangani selama pembuatan, dan divalidasi setelah diterima.Mungkin, muncul pertanyaan pada orang: "Berapa lambatnya?" Saya mengatakan bahwa itu harus bekerja dengan cepat, terutama karena tidak adanya fitur ini.Apa artinya menggunakan konsistensi kausal dalam kasus ini? Ini akan menampilkan parameter afterClusterTime. Dan tanpa itu, itu hanya akan memberikan nilai. Gosip, sejak versi 3.6, selalu berhasil.Jika kita meninggalkan generasi tanda tangan yang konstan, ini akan memperlambat sistem bahkan tanpa adanya fitur, yang tidak memenuhi pendekatan dan persyaratan kami. Dan apa yang telah kita lakukan?Lakukan itu dengan cepat!
Suatu hal yang cukup sederhana, tetapi triknya menarik - Saya akan membagikannya, mungkin seseorang akan tertarik.Kami memiliki hash yang menyimpan data yang ditandatangani. Semua data melewati cache. Cache tidak secara spesifik menandatangani waktu, tetapi Range. Ketika nilai tertentu datang, kami menghasilkan Range, menutupi 16 bit terakhir, dan kami menandatangani nilai ini: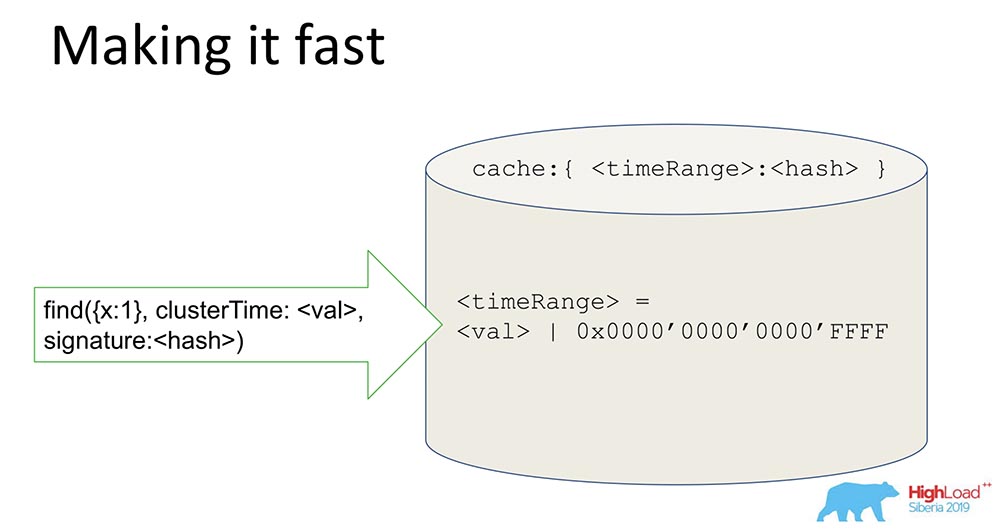 Dengan menerima tanda tangan seperti itu, kami mempercepat sistem (kondisional) sebanyak 65 ribu kali. Ini berfungsi dengan baik: ketika mereka melakukan percobaan, waktu ketika kami memiliki pembaruan yang konsisten benar-benar berkurang di sana sebanyak 10 ribu kali. Jelas bahwa ketika mereka berselisih, ini tidak berhasil. Tetapi dalam kebanyakan kasus praktis ini berhasil. Kombinasi tanda tangan Range dengan tanda tangan menyelesaikan masalah keamanan.
Dengan menerima tanda tangan seperti itu, kami mempercepat sistem (kondisional) sebanyak 65 ribu kali. Ini berfungsi dengan baik: ketika mereka melakukan percobaan, waktu ketika kami memiliki pembaruan yang konsisten benar-benar berkurang di sana sebanyak 10 ribu kali. Jelas bahwa ketika mereka berselisih, ini tidak berhasil. Tetapi dalam kebanyakan kasus praktis ini berhasil. Kombinasi tanda tangan Range dengan tanda tangan menyelesaikan masalah keamanan.Apa yang telah kita pelajari?
Pelajaran yang kami pelajari dari ini:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- Yang terakhir adalah kami harus mempertimbangkan ide-ide yang berbeda dan menggabungkan beberapa artikel yang umumnya berbeda menjadi satu pendekatan, bersama-sama. Gagasan penandatanganan, misalnya, berasal dari sebuah artikel yang meneliti protokol Paxos, yang untuk non-Bizantium Faylor di dalam protokol otorisasi, untuk yang Bizantium di luar protokol otorisasi ... Secara umum, ini persis seperti yang kami lakukan pada akhirnya.
Sama sekali tidak ada yang baru di sini! Tapi begitu kita mencampur semuanya ... Ini seperti mengatakan bahwa resep salad Olivier itu omong kosong, karena telur, mayones dan mentimun telah muncul dengan ... Ini tentang cerita yang sama.
 Tentang ini saya akan berakhir. Terima kasih!
Tentang ini saya akan berakhir. Terima kasih!Pertanyaan
Pertanyaan dari hadirin (selanjutnya - B): - Terima kasih, Michael atas laporannya! Tema waktu itu menarik. Anda menggunakan gosip. Mereka mengatakan bahwa setiap orang memiliki waktu mereka sendiri, semua orang tahu waktu setempat mereka. Seperti yang saya pahami, kami memiliki driver - mungkin ada banyak klien dengan driver, permintaan-perencana juga, banyak pecahan ... Tapi apa sistem akan jika kita tiba-tiba memiliki perbedaan: seseorang memutuskan bahwa dia sebentar depan, seseorang - satu menit di belakang? Di mana kita akan menemukan diri kita sendiri?MT: - Pertanyaan bagus kok! Saya hanya ingin mengatakan tentang pecahan. Jika saya memahami pertanyaan dengan benar, kita memiliki situasi ini: ada beling 1 dan beling 2, bacaan terjadi dari dua pecahan ini - mereka memiliki perbedaan, mereka tidak berinteraksi satu sama lain, karena waktu yang mereka tahu berbeda, terutama waktu yang Mereka ada di oplog.Misalkan pecahan 1 membuat sejuta catatan, pecahan 2 tidak melakukan apa-apa, dan permintaan datang dalam dua pecahan. Dan yang pertama memiliki afterClusterTime lebih dari satu juta. Dalam situasi seperti itu, seperti yang saya jelaskan, beling 2 tidak akan pernah merespons sama sekali.T: - Saya ingin tahu bagaimana mereka mensinkronkan dan memilih satu waktu yang logis?MT: - Sangat mudah disinkronkan. Shard, ketika afterClusterTime datang kepadanya, dan dia tidak menemukan waktu di "Tangkapan" - inisiat tidak disetujui. Artinya, dia mengangkat tangannya ke nilai ini dengan tangannya. Ini berarti tidak ada acara yang cocok dengan kueri ini. Dia menciptakan acara ini secara artifisial dan dengan demikian menjadi Konsisten Kausal.T: - Dan jika setelah itu beberapa peristiwa lain yang hilang di suatu tempat di jaringan masih datang kepadanya?MT:- Beling itu diatur sedemikian rupa sehingga mereka tidak akan datang lagi, karena itu adalah tuan tunggal. Jika dia sudah mencatat, maka mereka tidak akan datang, tetapi akan mengejar. Tidak dapat terjadi bahwa di suatu tempat ada sesuatu yang macet, maka dia tidak akan menulis, dan kemudian peristiwa ini tiba - dan konsistensi Kausal dilanggar. Ketika dia tidak menulis, mereka semua harus datang berikutnya (dia akan menunggu mereka). DI:- Saya punya beberapa pertanyaan tentang garis. Konsistensi sebab akibat mengasumsikan bahwa ada antrian tindakan tertentu yang perlu dilakukan. Apa yang terjadi jika kami kehilangan satu paket? Jadi tanggal 10 pergi, tanggal 11 ... tanggal 12 menghilang, dan semua orang menunggu untuk dipenuhi. Dan tiba-tiba mobil kami mati, kami tidak bisa melakukan apa-apa. Apakah ada panjang antrian maksimum yang terakumulasi sebelum dieksekusi? Kegagalan fatal apa yang terjadi ketika satu negara hilang? Selain itu, jika kita menuliskan bahwa ada semacam keadaan sebelumnya, maka kita harus entah bagaimana memulainya? Dan mereka tidak mendorong darinya!MT:- Juga pertanyaan yang bagus! Apa yang kita lakukan? MongoDB memiliki konsep catatan kuorum, membaca kuorum. Kapan pesan bisa hilang? Ketika catatan tidak kuorum atau ketika bacaan tidak kuorum (beberapa sampah juga bisa menempel).Mengenai konsistensi Kausal, kami melakukan tes eksperimental besar, yang menghasilkan fakta bahwa ketika rekaman dan bacaan tidak kuorum, pelanggaran konsistensi Kausal terjadi. Apa yang Anda katakan!Kiat kami: Gunakan setidaknya membaca kuorum saat menggunakan konsistensi Kausal. Dalam hal ini, tidak ada yang akan hilang, bahkan jika catatan kuorum hilang ... Ini adalah situasi ortogonal: jika pengguna tidak ingin data hilang, Anda perlu menggunakan catatan kuorum. Konsistensi kausal tidak menjamin ketahanan. Jaminan ketahanan disediakan oleh replikasi dan mesin yang terkait dengan replikasi.T: - Ketika kita membuat contoh yang sharding lakukan untuk kita (bukan master, tetapi budak, masing-masing), ia bergantung pada waktu unix dari mesinnya sendiri atau pada waktu "master"; disinkronkan untuk pertama kalinya atau secara berkala?MT:- Sekarang saya akan membuatnya jelas. Shard (mis., Partisi horizontal) - selalu ada Pratama. Dan di beling mungkin ada "tuan" dan mungkin ada replika. Tetapi beling selalu mendukung penulisan, karena harus mendukung domain tertentu (Pratama ada di beling).T: - Artinya, semuanya tergantung murni pada "tuan"? Selalu menggunakan "master" -waktu?MT: - Ya. Secara kiasan Anda bisa mengatakan: jam terus berdetak ketika ada rekaman di "master", di "Olog".T: - Kami memiliki klien yang terhubung, dan dia tidak perlu tahu apa-apa tentang waktu?MT:- Secara umum, Anda tidak perlu tahu apa-apa! Jika kita berbicara tentang cara kerjanya pada klien: di klien, ketika dia ingin menggunakan konsistensi Kausal, dia perlu membuka sesi. Sekarang semuanya ada di sana: baik transaksi dalam sesi dan mengambil hak ... Sesi adalah urutan peristiwa logis yang terjadi dengan klien.Jika dia membuka sesi ini dan mengatakan di sana bahwa dia menginginkan konsistensi Kausal (jika secara default sesi mendukung konsistensi Kausal), semuanya secara otomatis berfungsi. Pengemudi ingat kali ini dan meningkatkannya ketika menerima pesan baru. Itu mengingat jawaban mana yang mengembalikan yang sebelumnya dari server yang mengembalikan data. Permintaan berikut akan berisi afterCluster ("waktu lebih besar dari ini").Klien tidak perlu tahu apa-apa! Ini benar-benar buram baginya. Jika orang menggunakan fitur ini, apa yang bisa saya lakukan? Pertama, Anda dapat dengan aman membaca sekunder: Anda dapat menulis di Pratama, dan membaca dari sekunder yang direplikasi secara geografis dan pastikan itu berfungsi. Pada saat yang sama, sesi yang direkam pada Pratama dapat ditransfer bahkan ke Sekunder, yaitu, Anda dapat menggunakan tidak hanya satu sesi, tetapi beberapa sesi.T: - Topik konsistensi akhir sangat terkait dengan lapisan ilmu Komputasi baru - Jenis Data Replika bebas-Konflik). Sudahkah Anda mempertimbangkan integrasi tipe data ini ke dalam basis data dan apa yang dapat Anda katakan tentangnya?MT: - Pertanyaan bagus! CRDT masuk akal untuk konflik tulis: di MongoDB - master tunggal.DI:- Saya punya pertanyaan dari para devops. Di dunia nyata, ada situasi Yesuit seperti ketika Kegagalan Bizantium terjadi, dan orang-orang jahat di dalam perimeter yang dilindungi mulai menempel pada protokol, mengirim paket kerajinan dengan cara khusus?
DI:- Saya punya beberapa pertanyaan tentang garis. Konsistensi sebab akibat mengasumsikan bahwa ada antrian tindakan tertentu yang perlu dilakukan. Apa yang terjadi jika kami kehilangan satu paket? Jadi tanggal 10 pergi, tanggal 11 ... tanggal 12 menghilang, dan semua orang menunggu untuk dipenuhi. Dan tiba-tiba mobil kami mati, kami tidak bisa melakukan apa-apa. Apakah ada panjang antrian maksimum yang terakumulasi sebelum dieksekusi? Kegagalan fatal apa yang terjadi ketika satu negara hilang? Selain itu, jika kita menuliskan bahwa ada semacam keadaan sebelumnya, maka kita harus entah bagaimana memulainya? Dan mereka tidak mendorong darinya!MT:- Juga pertanyaan yang bagus! Apa yang kita lakukan? MongoDB memiliki konsep catatan kuorum, membaca kuorum. Kapan pesan bisa hilang? Ketika catatan tidak kuorum atau ketika bacaan tidak kuorum (beberapa sampah juga bisa menempel).Mengenai konsistensi Kausal, kami melakukan tes eksperimental besar, yang menghasilkan fakta bahwa ketika rekaman dan bacaan tidak kuorum, pelanggaran konsistensi Kausal terjadi. Apa yang Anda katakan!Kiat kami: Gunakan setidaknya membaca kuorum saat menggunakan konsistensi Kausal. Dalam hal ini, tidak ada yang akan hilang, bahkan jika catatan kuorum hilang ... Ini adalah situasi ortogonal: jika pengguna tidak ingin data hilang, Anda perlu menggunakan catatan kuorum. Konsistensi kausal tidak menjamin ketahanan. Jaminan ketahanan disediakan oleh replikasi dan mesin yang terkait dengan replikasi.T: - Ketika kita membuat contoh yang sharding lakukan untuk kita (bukan master, tetapi budak, masing-masing), ia bergantung pada waktu unix dari mesinnya sendiri atau pada waktu "master"; disinkronkan untuk pertama kalinya atau secara berkala?MT:- Sekarang saya akan membuatnya jelas. Shard (mis., Partisi horizontal) - selalu ada Pratama. Dan di beling mungkin ada "tuan" dan mungkin ada replika. Tetapi beling selalu mendukung penulisan, karena harus mendukung domain tertentu (Pratama ada di beling).T: - Artinya, semuanya tergantung murni pada "tuan"? Selalu menggunakan "master" -waktu?MT: - Ya. Secara kiasan Anda bisa mengatakan: jam terus berdetak ketika ada rekaman di "master", di "Olog".T: - Kami memiliki klien yang terhubung, dan dia tidak perlu tahu apa-apa tentang waktu?MT:- Secara umum, Anda tidak perlu tahu apa-apa! Jika kita berbicara tentang cara kerjanya pada klien: di klien, ketika dia ingin menggunakan konsistensi Kausal, dia perlu membuka sesi. Sekarang semuanya ada di sana: baik transaksi dalam sesi dan mengambil hak ... Sesi adalah urutan peristiwa logis yang terjadi dengan klien.Jika dia membuka sesi ini dan mengatakan di sana bahwa dia menginginkan konsistensi Kausal (jika secara default sesi mendukung konsistensi Kausal), semuanya secara otomatis berfungsi. Pengemudi ingat kali ini dan meningkatkannya ketika menerima pesan baru. Itu mengingat jawaban mana yang mengembalikan yang sebelumnya dari server yang mengembalikan data. Permintaan berikut akan berisi afterCluster ("waktu lebih besar dari ini").Klien tidak perlu tahu apa-apa! Ini benar-benar buram baginya. Jika orang menggunakan fitur ini, apa yang bisa saya lakukan? Pertama, Anda dapat dengan aman membaca sekunder: Anda dapat menulis di Pratama, dan membaca dari sekunder yang direplikasi secara geografis dan pastikan itu berfungsi. Pada saat yang sama, sesi yang direkam pada Pratama dapat ditransfer bahkan ke Sekunder, yaitu, Anda dapat menggunakan tidak hanya satu sesi, tetapi beberapa sesi.T: - Topik konsistensi akhir sangat terkait dengan lapisan ilmu Komputasi baru - Jenis Data Replika bebas-Konflik). Sudahkah Anda mempertimbangkan integrasi tipe data ini ke dalam basis data dan apa yang dapat Anda katakan tentangnya?MT: - Pertanyaan bagus! CRDT masuk akal untuk konflik tulis: di MongoDB - master tunggal.DI:- Saya punya pertanyaan dari para devops. Di dunia nyata, ada situasi Yesuit seperti ketika Kegagalan Bizantium terjadi, dan orang-orang jahat di dalam perimeter yang dilindungi mulai menempel pada protokol, mengirim paket kerajinan dengan cara khusus? MT: - Orang jahat di dalam perimeter seperti kuda Troya! Orang jahat di dalam perimeter dapat melakukan banyak hal buruk.T: - Jelas bahwa meninggalkan lubang di server, secara kasar, di mana Anda dapat menempelkan kebun binatang gajah dan meruntuhkan seluruh cluster selamanya ... Ini akan memakan waktu untuk pemulihan manual ... Ini, untuk membuatnya lebih halus, salah. Di sisi lain, ini aneh: dalam kehidupan nyata, dalam praktik, ada situasi ketika serangan internal serupa terjadi?MT:- Karena saya jarang menemukan pelanggaran keamanan dalam kehidupan nyata, saya tidak bisa mengatakan - mungkin itu terjadi. Tetapi jika kita berbicara tentang filosofi pembangunan, maka kita berpikir demikian: kita memiliki batas yang menyediakan orang-orang yang membuat keamanan - itu adalah kastil, tembok; dan di dalam perimeter Anda dapat melakukan apa pun yang Anda inginkan. Jelas bahwa ada pengguna dengan kemampuan hanya melihat, dan ada pengguna dengan kemampuan untuk menghapus direktori.Bergantung pada haknya, kerusakan yang dapat dilakukan pengguna mungkin adalah mouse, atau mungkin gajah. Jelas bahwa pengguna dengan hak penuh dapat melakukan apa saja. Seorang pengguna yang tidak memiliki hak bahaya yang luas dapat menyebabkan lebih sedikit. Secara khusus, ia tidak dapat merusak sistem.DI:- Dalam perimeter aman, seseorang naik untuk membentuk protokol yang tidak terduga untuk server untuk mengatur server dengan kanker, dan jika Anda beruntung, maka seluruh cluster ... Apakah itu pernah terjadi begitu "baik"?MT: - Saya belum pernah mendengar hal seperti itu. Fakta bahwa cara ini Anda dapat mengisi server bukanlah rahasia. Untuk mengisi di dalam, karena dari protokol, menjadi pengguna yang berwenang yang dapat menulis sesuatu seperti itu dalam pesan ... Sebenarnya, itu tidak mungkin, karena bagaimanapun itu akan diverifikasi. Dimungkinkan untuk menonaktifkan otentikasi ini untuk pengguna yang tidak ingin - ini adalah masalah mereka; secara kasar, mereka sendiri menghancurkan dinding dan Anda dapat menjejalkan seekor gajah di sana, yang akan menginjak-injak ... Secara umum, Anda dapat berpakaian sebagai tukang reparasi, datang dan dapatkan!DI:- Terima kasih atas laporannya. Sergey (Yandex). Dalam "Mong" ada konstanta yang membatasi jumlah anggota pemilih dalam Set Replika, dan konstanta ini adalah 7 (tujuh). Mengapa ini konstan? Mengapa ini bukan semacam parameter?MT: - Set Replika kami juga memiliki 40 node. Selalu ada mayoritas. Saya tidak tahu versi mana ...T: - Di Perangkat Replika, Anda dapat menjalankan anggota yang tidak memberikan suara, tetapi memilih - maksimum 7. Bagaimana, dalam hal ini, mengalami penutupan jika kami memiliki Set Replika ditarik ke 3 pusat data? Satu pusat data dapat dengan mudah dimatikan, dan mesin lain jatuh.MT: - Ini sudah agak di luar ruang lingkup laporan. Ini pertanyaan umum. Mungkin dengan begitu aku bisa memberitahunya.
MT: - Orang jahat di dalam perimeter seperti kuda Troya! Orang jahat di dalam perimeter dapat melakukan banyak hal buruk.T: - Jelas bahwa meninggalkan lubang di server, secara kasar, di mana Anda dapat menempelkan kebun binatang gajah dan meruntuhkan seluruh cluster selamanya ... Ini akan memakan waktu untuk pemulihan manual ... Ini, untuk membuatnya lebih halus, salah. Di sisi lain, ini aneh: dalam kehidupan nyata, dalam praktik, ada situasi ketika serangan internal serupa terjadi?MT:- Karena saya jarang menemukan pelanggaran keamanan dalam kehidupan nyata, saya tidak bisa mengatakan - mungkin itu terjadi. Tetapi jika kita berbicara tentang filosofi pembangunan, maka kita berpikir demikian: kita memiliki batas yang menyediakan orang-orang yang membuat keamanan - itu adalah kastil, tembok; dan di dalam perimeter Anda dapat melakukan apa pun yang Anda inginkan. Jelas bahwa ada pengguna dengan kemampuan hanya melihat, dan ada pengguna dengan kemampuan untuk menghapus direktori.Bergantung pada haknya, kerusakan yang dapat dilakukan pengguna mungkin adalah mouse, atau mungkin gajah. Jelas bahwa pengguna dengan hak penuh dapat melakukan apa saja. Seorang pengguna yang tidak memiliki hak bahaya yang luas dapat menyebabkan lebih sedikit. Secara khusus, ia tidak dapat merusak sistem.DI:- Dalam perimeter aman, seseorang naik untuk membentuk protokol yang tidak terduga untuk server untuk mengatur server dengan kanker, dan jika Anda beruntung, maka seluruh cluster ... Apakah itu pernah terjadi begitu "baik"?MT: - Saya belum pernah mendengar hal seperti itu. Fakta bahwa cara ini Anda dapat mengisi server bukanlah rahasia. Untuk mengisi di dalam, karena dari protokol, menjadi pengguna yang berwenang yang dapat menulis sesuatu seperti itu dalam pesan ... Sebenarnya, itu tidak mungkin, karena bagaimanapun itu akan diverifikasi. Dimungkinkan untuk menonaktifkan otentikasi ini untuk pengguna yang tidak ingin - ini adalah masalah mereka; secara kasar, mereka sendiri menghancurkan dinding dan Anda dapat menjejalkan seekor gajah di sana, yang akan menginjak-injak ... Secara umum, Anda dapat berpakaian sebagai tukang reparasi, datang dan dapatkan!DI:- Terima kasih atas laporannya. Sergey (Yandex). Dalam "Mong" ada konstanta yang membatasi jumlah anggota pemilih dalam Set Replika, dan konstanta ini adalah 7 (tujuh). Mengapa ini konstan? Mengapa ini bukan semacam parameter?MT: - Set Replika kami juga memiliki 40 node. Selalu ada mayoritas. Saya tidak tahu versi mana ...T: - Di Perangkat Replika, Anda dapat menjalankan anggota yang tidak memberikan suara, tetapi memilih - maksimum 7. Bagaimana, dalam hal ini, mengalami penutupan jika kami memiliki Set Replika ditarik ke 3 pusat data? Satu pusat data dapat dengan mudah dimatikan, dan mesin lain jatuh.MT: - Ini sudah agak di luar ruang lingkup laporan. Ini pertanyaan umum. Mungkin dengan begitu aku bisa memberitahunya.
Sedikit iklan :)
Terima kasih untuk tetap bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda, cloud VPS untuk pengembang mulai $ 4,99 , analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang Cara Membangun Infrastruktur Bldg. kelas c menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen? Source: https://habr.com/ru/post/undefined/
All Articles