HighLoad ++, Anastasia Tsymbalyuk, Stanislav Tselovalnikov (Sberbank): bagaimana kami menjadi MDA
Konferensi HighLoad ++ berikutnya akan diadakan pada 6 dan 7 April 2020 di St. Petersburg.Rincian dan tiket di sini . HighLoad ++ Siberia 2019. Aula "Krasnoyarsk". 25 Juni, 2 malam Abstrak dan presentasi .Mengembangkan manajemen data industri dan sistem penyebaran dari awal bukanlah tugas yang mudah. Terutama ketika ada jaminan yang lengkap, waktu untuk bekerja adalah seperempat, dan persyaratan produk adalah turbulensi abadi. Kami akan memberi tahu contoh membangun sistem manajemen metadata, bagaimana membangun sistem yang dapat diukur industri dalam waktu singkat, yang meliputi penyimpanan dan penyebaran data.Pendekatan kami mengambil keuntungan penuh dari metadata, kode SQL dinamis, dan pembuatan kode berdasarkan kode Swagger dan setang. Solusi ini mengurangi waktu pengembangan dan konfigurasi ulang sistem, dan menambahkan objek manajemen baru tidak memerlukan satu baris kode baru.Kami akan memberi tahu Anda cara kerjanya di tim kami: aturan apa yang kami patuhi, alat apa yang kami gunakan, kesulitan apa yang kami temui dan bagaimana kami dengan gagah mengatasinya.Anastasia Tsymbalyuk (selanjutnya - AC): - Nama saya Nastya, dan ini adalah Stas!Stas Tselovalnikov (selanjutnya - SC): - Halo semuanya!AC: - Hari ini kami akan memberi tahu Anda tentang MDA, dan bagaimana, menggunakan pendekatan ini, kami mengurangi waktu pengembangan dan memperkenalkan dunia pada sistem manajemen metadata yang dapat diukur industri. Hore!SC: - Nastya, apa itu MDA?AC: - Stas, saya pikir kita akan lancar beralih ke ini sekarang. Lebih tepatnya, saya akan membicarakan ini sedikit di akhir presentasi. Mari kita bicara tentang kita terlebih dahulu:
Kami akan memberi tahu contoh membangun sistem manajemen metadata, bagaimana membangun sistem yang dapat diukur industri dalam waktu singkat, yang meliputi penyimpanan dan penyebaran data.Pendekatan kami mengambil keuntungan penuh dari metadata, kode SQL dinamis, dan pembuatan kode berdasarkan kode Swagger dan setang. Solusi ini mengurangi waktu pengembangan dan konfigurasi ulang sistem, dan menambahkan objek manajemen baru tidak memerlukan satu baris kode baru.Kami akan memberi tahu Anda cara kerjanya di tim kami: aturan apa yang kami patuhi, alat apa yang kami gunakan, kesulitan apa yang kami temui dan bagaimana kami dengan gagah mengatasinya.Anastasia Tsymbalyuk (selanjutnya - AC): - Nama saya Nastya, dan ini adalah Stas!Stas Tselovalnikov (selanjutnya - SC): - Halo semuanya!AC: - Hari ini kami akan memberi tahu Anda tentang MDA, dan bagaimana, menggunakan pendekatan ini, kami mengurangi waktu pengembangan dan memperkenalkan dunia pada sistem manajemen metadata yang dapat diukur industri. Hore!SC: - Nastya, apa itu MDA?AC: - Stas, saya pikir kita akan lancar beralih ke ini sekarang. Lebih tepatnya, saya akan membicarakan ini sedikit di akhir presentasi. Mari kita bicara tentang kita terlebih dahulu: Saya dapat menggambarkan diri saya sebagai pencari sinergi dalam solusi TI industri.SC: - Dan saya?
Saya dapat menggambarkan diri saya sebagai pencari sinergi dalam solusi TI industri.SC: - Dan saya?Apa yang dilakukan tim SberData?
AC: - Dan Anda hanya mastodon industri, karena Anda membawa lebih dari satu solusi ke prom!SC: - Faktanya, kami bekerja bersama di Sberbank dalam tim yang sama dan mengelola metadata SberData: AC: - SberData, jika dengan cara yang sederhana - ini adalah platform analitis di mana semua trek digital dari setiap aliran klien. Jika Anda adalah klien Sberbank, semua informasi tentang Anda mengalir persis di sana. Banyak dataset disimpan di sana, tetapi kami memahami bahwa jumlah data tidak berarti kualitasnya. Dan data tanpa konteks terkadang sama sekali tidak berguna, karena kita tidak dapat menerapkan, menafsirkan, melindungi, memperkayanya.Hanya tugas-tugas ini diselesaikan oleh metadata. Mereka menunjukkan kepada kita konteks bisnis dan komponen teknis dari data, yaitu, di mana mereka muncul, bagaimana mereka diubah, pada titik deskripsi minimal, markup sekarang. Ini sudah cukup untuk mulai menggunakan data dan mempercayainya. Inilah tepatnya tugas yang diselesaikan metadata.SC: - Dengan kata lain, misi tim kami adalah untuk meningkatkan efisiensi platform analitis informasi Sberbank karena fakta bahwa informasi yang baru saja Anda bicarakan harus dikirim ke orang yang tepat pada waktu yang tepat di tempat yang tepat. Dan ingat, Anda juga mengatakan bahwa jika data adalah minyak modern, maka metadata adalah peta simpanan minyak ini.AC:- Memang, ini adalah salah satu pernyataan brilian saya, yang sangat saya banggakan. Secara teknis, tugas ini direduksi menjadi fakta bahwa kami harus membuat alat manajemen metadata di dalam platform kami dan memastikan siklus hidupnya sepenuhnya.Tetapi untuk terjun ke masalah bidang subjek kami dan memahami apa yang kita hadapi, saya sarankan mundur 9 bulan yang lalu.Jadi, bayangkan: di luar jendela adalah bulan November, burung-burung semua terbang ke selatan, kami sedih ... Dan pada saat itu kami memiliki pilot yang sukses bersama tim, ada pelanggan - kami semua tinggal di zona nyaman sampai titik tidak bisa kembali terjadi.
AC: - SberData, jika dengan cara yang sederhana - ini adalah platform analitis di mana semua trek digital dari setiap aliran klien. Jika Anda adalah klien Sberbank, semua informasi tentang Anda mengalir persis di sana. Banyak dataset disimpan di sana, tetapi kami memahami bahwa jumlah data tidak berarti kualitasnya. Dan data tanpa konteks terkadang sama sekali tidak berguna, karena kita tidak dapat menerapkan, menafsirkan, melindungi, memperkayanya.Hanya tugas-tugas ini diselesaikan oleh metadata. Mereka menunjukkan kepada kita konteks bisnis dan komponen teknis dari data, yaitu, di mana mereka muncul, bagaimana mereka diubah, pada titik deskripsi minimal, markup sekarang. Ini sudah cukup untuk mulai menggunakan data dan mempercayainya. Inilah tepatnya tugas yang diselesaikan metadata.SC: - Dengan kata lain, misi tim kami adalah untuk meningkatkan efisiensi platform analitis informasi Sberbank karena fakta bahwa informasi yang baru saja Anda bicarakan harus dikirim ke orang yang tepat pada waktu yang tepat di tempat yang tepat. Dan ingat, Anda juga mengatakan bahwa jika data adalah minyak modern, maka metadata adalah peta simpanan minyak ini.AC:- Memang, ini adalah salah satu pernyataan brilian saya, yang sangat saya banggakan. Secara teknis, tugas ini direduksi menjadi fakta bahwa kami harus membuat alat manajemen metadata di dalam platform kami dan memastikan siklus hidupnya sepenuhnya.Tetapi untuk terjun ke masalah bidang subjek kami dan memahami apa yang kita hadapi, saya sarankan mundur 9 bulan yang lalu.Jadi, bayangkan: di luar jendela adalah bulan November, burung-burung semua terbang ke selatan, kami sedih ... Dan pada saat itu kami memiliki pilot yang sukses bersama tim, ada pelanggan - kami semua tinggal di zona nyaman sampai titik tidak bisa kembali terjadi.Model Sistem Manajemen Metadata
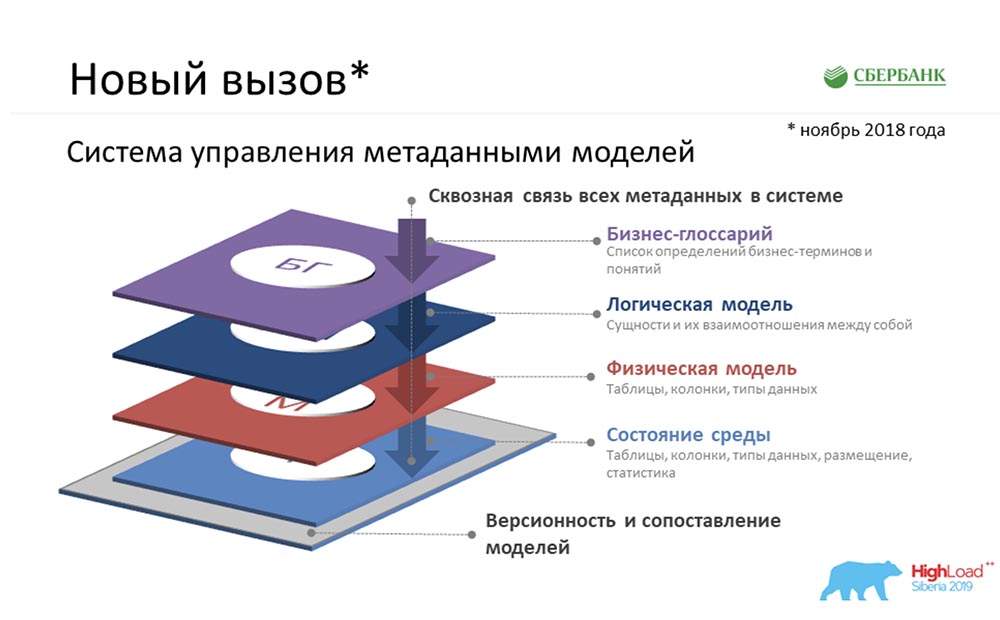 SC: - Ada hal lain yang Anda miliki tentang berada di zona nyaman ... Bahkan, kami menetapkan tugas untuk menciptakan Metadata Broker, yang seharusnya memberi kesempatan untuk berkomunikasi dengan pelanggan, program, sistem kami. Klien kami seharusnya memiliki kesempatan di tingkat backend untuk mengirim semacam paket metadata atau menerimanya. Dan kami, menyediakan fungsi ini, di tingkat kami harus mengumpulkan informasi yang paling konsisten dan relevan tentang metadata di empat tingkat logis:
SC: - Ada hal lain yang Anda miliki tentang berada di zona nyaman ... Bahkan, kami menetapkan tugas untuk menciptakan Metadata Broker, yang seharusnya memberi kesempatan untuk berkomunikasi dengan pelanggan, program, sistem kami. Klien kami seharusnya memiliki kesempatan di tingkat backend untuk mengirim semacam paket metadata atau menerimanya. Dan kami, menyediakan fungsi ini, di tingkat kami harus mengumpulkan informasi yang paling konsisten dan relevan tentang metadata di empat tingkat logis:- Tingkat Glosarium Bisnis.
- Tingkat model logis.
- Tingkat model fisik.
- Keadaan lingkungan yang kami terima karena kebalikan dari lingkungan industri.
Dan semua ini harus konsisten.AC: - Ya benar. Tetapi di sini saya juga akan menjelaskan dengan cara yang sederhana, karena saya tidak mengecualikan bahwa area subjeknya tidak jelas dan tidak dapat dipahami ...Glosarium bisnis adalah tentang apa yang dihasilkan oleh orang pintar berjas selama berjam-jam ... bagaimana menyebutkan istilah, bagaimana membuat formula perhitungan. Mereka berpikir lama, dan pada akhirnya mereka hanya memiliki glosarium bisnis.Model logisnya adalah tentang bagaimana analis melihat dirinya di dunia, yang mampu berkomunikasi dengan orang-orang pintar ini dalam pakaian dan dasi, tetapi pada saat yang sama memahami bagaimana hal itu mungkin untuk mendarat. Jauh dari detail realisasi fisik.Model fisik adalah tentang kapan giliran para programmer, arsitek yang benar-benar mengerti bagaimana cara mendaratkan benda-benda ini - di mana tabel harus diletakkan, bidang mana yang harus dibuat, indeks mana yang akan digantung ...Keadaan lingkungan adalah semacam pemeran. Ini seperti kesaksian dari sebuah mobil. Seorang programmer terkadang ingin memberi tahu mesin itu satu hal, tetapi dia salah paham. Keadaan lingkungan menunjukkan kepada kita keadaan sebenarnya, dan kita terus-menerus membandingkan semuanya; dan kami memahami bahwa ada perbedaan antara apa yang dikatakan programmer dan keadaan lingkungan sebenarnya.Kasus untuk menggambarkan metadata
SC: - Mari kita jelaskan dengan contoh konkret. Misalnya, kita memiliki empat level yang ditunjuk ini. Misalkan kita memiliki orang-orang serius ini yang bekerja di tingkat glosarium bisnis - mereka tidak mengerti sama sekali bagaimana dan apa yang diatur di dalam. Tetapi mereka mengerti bahwa mereka perlu membuat formulir pelaporan wajib, mereka perlu mendapatkan, katakanlah, saldo rata-rata pada akun pribadi: Untuk tingkat ini, seseorang harus sudah memiliki glosarium bisnis (syarat pelaporan wajib) atau memilikinya (saldo rata-rata pada akun pribadi). Berikutnya adalah analis yang mengerti dia dengan sempurna, dapat berbicara bahasa yang sama dengannya, tetapi dia dapat berbicara bahasa yang sama dengan programmer juga.Dia berkata: "Dengar, di sini kamu memiliki seluruh cerita dibagi menjadi akun terpisah sebagai entitas, dan mereka memiliki atribut - saldo rata-rata."Berikutnya adalah arsitek dan berkata: “Kami akan melakukan showcase pinjaman ini kepada badan hukum. Karenanya, kami akan membuat tabel fisik dari akun pribadi, kami akan membuat tabel fisik saldo harian pada akun pribadi (karena mereka diterima setiap hari pada penutupan hari perdagangan). Dan sebulan sekali pada tenggat waktu kami akan menghitung rata-rata (tabel saldo bulanan), seperti yang diminta. "Tidak lebih cepat dikatakan daripada dilakukan. Dan kemudian parser kami datang, yang pergi ke sirkuit industri dan berkata: "Ya, saya melihat - ada meja yang diperlukan ..." Apa lagi yang memperkaya tabel ini? Di sini (sebagai contoh) - partisi dan indeks, meskipun, sebenarnya, partisi dan indeks bisa berada pada tingkat desain model fisik, tetapi mungkin ada hal lain (misalnya, volume data).
Untuk tingkat ini, seseorang harus sudah memiliki glosarium bisnis (syarat pelaporan wajib) atau memilikinya (saldo rata-rata pada akun pribadi). Berikutnya adalah analis yang mengerti dia dengan sempurna, dapat berbicara bahasa yang sama dengannya, tetapi dia dapat berbicara bahasa yang sama dengan programmer juga.Dia berkata: "Dengar, di sini kamu memiliki seluruh cerita dibagi menjadi akun terpisah sebagai entitas, dan mereka memiliki atribut - saldo rata-rata."Berikutnya adalah arsitek dan berkata: “Kami akan melakukan showcase pinjaman ini kepada badan hukum. Karenanya, kami akan membuat tabel fisik dari akun pribadi, kami akan membuat tabel fisik saldo harian pada akun pribadi (karena mereka diterima setiap hari pada penutupan hari perdagangan). Dan sebulan sekali pada tenggat waktu kami akan menghitung rata-rata (tabel saldo bulanan), seperti yang diminta. "Tidak lebih cepat dikatakan daripada dilakukan. Dan kemudian parser kami datang, yang pergi ke sirkuit industri dan berkata: "Ya, saya melihat - ada meja yang diperlukan ..." Apa lagi yang memperkaya tabel ini? Di sini (sebagai contoh) - partisi dan indeks, meskipun, sebenarnya, partisi dan indeks bisa berada pada tingkat desain model fisik, tetapi mungkin ada hal lain (misalnya, volume data).Registrasi dan penyimpanan di tingkat metadata
AC: - Bagaimana semuanya disimpan bersama kami? Ini adalah bentuk super sederhana dari contoh yang dilukis Stas sebelumnya! Bagaimana semua ini akan berbohong pada kita?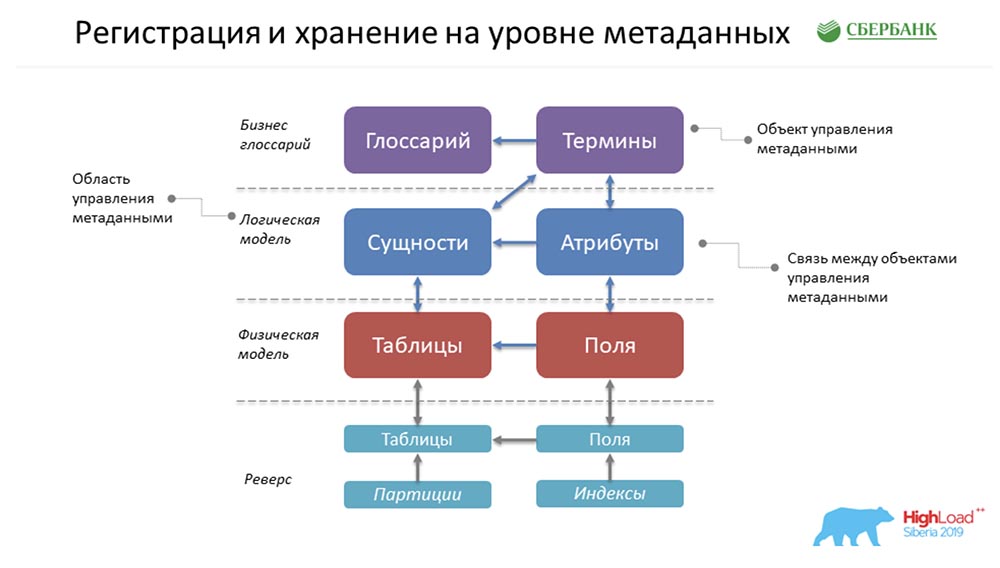 Bahkan, itu akan menjadi satu baris di objek Daftar Istilah, satu di objek Ketentuan, satu di Entitas, satu di Atribut, dan sebagainya. Pada gambar di atas, setiap persegi panjang adalah objek dalam sistem kontrol kami, yang mewakili informasi ini atau itu yang tersimpan di sana.Untuk secara perlahan memperkenalkan Anda pada terminologi, saya meminta Anda untuk mencatat yang berikut ... Apa itu objek manajemen metadata? Secara fisik, ini disajikan dalam bentuk tabel, tetapi pada kenyataannya, informasi tertentu disimpan di sana pada istilah, glosarium, entitas, atribut, dll. Istilah ini, "objek," kami akan terus menggunakan dalam presentasi kami.SC: - Di sini harus dikatakan bahwa setiap kubus hanyalah sebuah tabel di sistem kami tempat kami menyimpan metadata, dan kami menyebutnya objek kontrol.
Bahkan, itu akan menjadi satu baris di objek Daftar Istilah, satu di objek Ketentuan, satu di Entitas, satu di Atribut, dan sebagainya. Pada gambar di atas, setiap persegi panjang adalah objek dalam sistem kontrol kami, yang mewakili informasi ini atau itu yang tersimpan di sana.Untuk secara perlahan memperkenalkan Anda pada terminologi, saya meminta Anda untuk mencatat yang berikut ... Apa itu objek manajemen metadata? Secara fisik, ini disajikan dalam bentuk tabel, tetapi pada kenyataannya, informasi tertentu disimpan di sana pada istilah, glosarium, entitas, atribut, dll. Istilah ini, "objek," kami akan terus menggunakan dalam presentasi kami.SC: - Di sini harus dikatakan bahwa setiap kubus hanyalah sebuah tabel di sistem kami tempat kami menyimpan metadata, dan kami menyebutnya objek kontrol.Persyaratan metadata
Apa yang kita punya di pintu masuk? Di pintu masuk kami menerima persyaratan yang cukup menarik. Ada banyak dari mereka, tetapi di sini kami ingin menunjukkan tiga yang utama: Persyaratan pertama cukup klasik. Kita diberitahu: "Teman-teman, segala sesuatu yang datang kepadamu harus datang selamanya." Historisasi selesai, dan setiap perubahan dalam sistem metadata Anda yang telah mendatangi Anda (tidak masalah jika paket 100 bidang telah tiba (100 perubahan) atau satu bidang telah berubah dalam satu tabel) memerlukan pendaftaran baru metadata. Mereka juga memerlukan respons untuk dikembalikan:
Persyaratan pertama cukup klasik. Kita diberitahu: "Teman-teman, segala sesuatu yang datang kepadamu harus datang selamanya." Historisasi selesai, dan setiap perubahan dalam sistem metadata Anda yang telah mendatangi Anda (tidak masalah jika paket 100 bidang telah tiba (100 perubahan) atau satu bidang telah berubah dalam satu tabel) memerlukan pendaftaran baru metadata. Mereka juga memerlukan respons untuk dikembalikan:- secara default - kondisi saat ini;
- tanggal;
- dengan nomor revisi.
Persyaratan kedua lebih menarik: kami diberitahu bahwa mereka dapat bekerja dengan kami pada objek, tetapi mereka harus banyak memprogram di Jawa, tetapi mereka tidak mau. Mereka menyarankan agar kami mencampur 100 objek (atau 10) sekaligus, dan kami harus menangani bisnis ini (karena kami bisa). Apa arti pencampuran itu? Misalnya, 10 kolom muncul. Mereka memiliki tautan ke pengidentifikasi tabel, tetapi kami tidak memiliki tabel itu sendiri - tabel itu berada di ujung JSON. "Kamu berfikir dan memproses - perlu kamu bisa"!Dalam rangka meningkatkan minat - yang ketiga: "Kami ingin tidak hanya dapat menggunakan API yang Anda akan buat kami, tetapi ingin memahami diri kita sendiri ..." Dan dalam urutan sewenang-wenang mengatakan: "Beri kami penyatuan dari objek ini ke objek melalui objek ketiga. Dan biarkan sistem Anda sendiri mengerti bagaimana melakukan semuanya, tanyakan database dan kembalikan hasilnya dalam JSON. "Kami punya cerita seperti itu di pintu masuk.Taksiran Taksiran
 AC: - Menurut perhitungan perkiraan kami, untuk menerapkan seluruh konsep ini, setiap objek kontrol diperlukan untuk berpartisipasi dalam tujuh antarmuka: sederhana (sederhana), untuk objek-oleh-tulis / baca dan hapus ...Tiga lagi - untuk universal tulis / baca / hapus, t Artinya, kita bisa membuang semuanya dalam urutan apa pun dan cara mentransfer set sup ke sistem, dan dia akan mencari tahu bagaimana cara menghapus, meletakkan, membaca.Satu hal lagi - untuk membangun hierarki sehingga kita dapat menunjukkan ke sistem - "Beri kami kembali dari objek ke objek"; dan mengembalikan pohon objek bersarang.
AC: - Menurut perhitungan perkiraan kami, untuk menerapkan seluruh konsep ini, setiap objek kontrol diperlukan untuk berpartisipasi dalam tujuh antarmuka: sederhana (sederhana), untuk objek-oleh-tulis / baca dan hapus ...Tiga lagi - untuk universal tulis / baca / hapus, t Artinya, kita bisa membuang semuanya dalam urutan apa pun dan cara mentransfer set sup ke sistem, dan dia akan mencari tahu bagaimana cara menghapus, meletakkan, membaca.Satu hal lagi - untuk membangun hierarki sehingga kita dapat menunjukkan ke sistem - "Beri kami kembali dari objek ke objek"; dan mengembalikan pohon objek bersarang.Kompleksitas implementasi
SC: - Selain persyaratan teknis yang datang kepada kami pada saat awal cerita ini, kami memiliki kesulitan tambahan. Pertama, ini adalah beberapa ketidakpastian persyaratan. Tidak setiap tim tidak dapat selalu mengartikulasikan dengan jelas apa yang mereka butuhkan dari layanan, dan seringkali saat kebenaran lahir pada saat membuat prototipe cerita di sirkuit def. Dan ketika mencapai prom, mungkin ada beberapa siklus.AC: - Ini adalah turbulensi yang diumumkan di awal.SC: - Selanjutnya ...Ada batas waktu yang terlarang, karena bahkan pada saat peluncuran lebih dari lima tim bergantung pada kita. Klasik genre: hasilnya diperlukan kemarin. Opsi pekerjaan dalam mode kuda melepuh, itulah yang kami lakukan.Yang ketiga adalah sejumlah besar pembangunan. Nastya pada slide-nya menunjukkan bahwa ketika kami melihat persyaratan apa dan bagaimana melakukannya, kami menyadari: 1 objek membutuhkan tujuh API (baik untuk itu, atau partisipasi dalam tujuh API). Ini berarti bahwa jika kita memiliki tambalan (6 objek, model, 42 API) berjalan dalam seminggu ...
Pertama, ini adalah beberapa ketidakpastian persyaratan. Tidak setiap tim tidak dapat selalu mengartikulasikan dengan jelas apa yang mereka butuhkan dari layanan, dan seringkali saat kebenaran lahir pada saat membuat prototipe cerita di sirkuit def. Dan ketika mencapai prom, mungkin ada beberapa siklus.AC: - Ini adalah turbulensi yang diumumkan di awal.SC: - Selanjutnya ...Ada batas waktu yang terlarang, karena bahkan pada saat peluncuran lebih dari lima tim bergantung pada kita. Klasik genre: hasilnya diperlukan kemarin. Opsi pekerjaan dalam mode kuda melepuh, itulah yang kami lakukan.Yang ketiga adalah sejumlah besar pembangunan. Nastya pada slide-nya menunjukkan bahwa ketika kami melihat persyaratan apa dan bagaimana melakukannya, kami menyadari: 1 objek membutuhkan tujuh API (baik untuk itu, atau partisipasi dalam tujuh API). Ini berarti bahwa jika kita memiliki tambalan (6 objek, model, 42 API) berjalan dalam seminggu ...Pendekatan standar
AC: - Ya, sebenarnya 42 API per minggu hanyalah puncak gunung es. Kami sangat menyadari bahwa untuk memastikan bahwa 42 API ini berfungsi, kami membutuhkan:- pertama, buat struktur penyimpanan untuk objek;
- kedua, untuk memastikan logika pemrosesannya;
- ketiga, tuliskan API tempat objek berpartisipasi (atau dikonfigurasikan secara khusus untuknya);
- Keempat, alangkah baiknya jika mencakup semua ini dengan kontur pengujian, uji dan katakan bahwa semuanya baik-baik saja;
- kelima (ceri yang sama pada kue), untuk mendokumentasikan seluruh cerita ini.
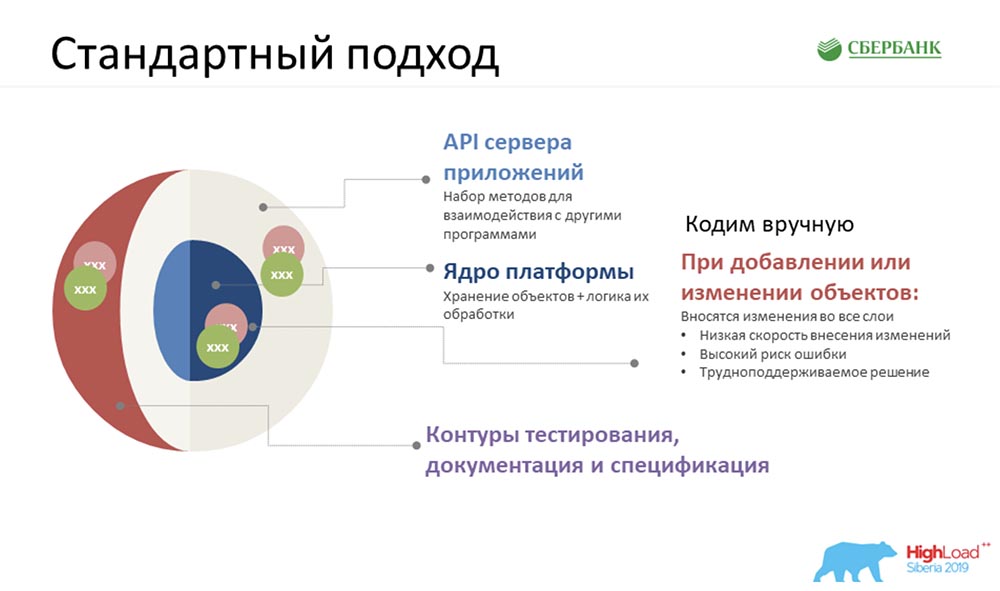 Secara alami, hal pertama yang terjadi pada kami (pada awalnya kami menunjukkan kepada Anda diagram perkiraan) - kami memiliki sekitar 35 objek. Sesuatu harus dilakukan dengan mereka, semua ini harus disimpulkan, dan hanya ada sedikit waktu. Dan ide pertama yang terpikir oleh kami adalah untuk duduk, menyingsingkan lengan baju kami dan mulai coding.Bahkan setelah bekerja dalam mode ini selama beberapa hari (kami memiliki tiga tim), kami mencapai suhu yang sangat cerah ... Semua orang gugup ... Dan kami menyadari bahwa kami perlu mencari pendekatan yang berbeda.
Secara alami, hal pertama yang terjadi pada kami (pada awalnya kami menunjukkan kepada Anda diagram perkiraan) - kami memiliki sekitar 35 objek. Sesuatu harus dilakukan dengan mereka, semua ini harus disimpulkan, dan hanya ada sedikit waktu. Dan ide pertama yang terpikir oleh kami adalah untuk duduk, menyingsingkan lengan baju kami dan mulai coding.Bahkan setelah bekerja dalam mode ini selama beberapa hari (kami memiliki tiga tim), kami mencapai suhu yang sangat cerah ... Semua orang gugup ... Dan kami menyadari bahwa kami perlu mencari pendekatan yang berbeda.Pendekatan khusus
Kami mulai memperhatikan apa yang kami lakukan. Gagasan pendekatan ini selalu ada di depan mata kita, karena kita telah terlibat dalam metadata sejak lama. Entah bagaimana, segera, itu tidak terjadi pada kami ...Seperti yang Anda duga, inti dari ide ini adalah menggunakan metadata. Itu terdiri dari fakta bahwa kami mengumpulkan struktur repositori kami (ini adalah metadata tertentu), setelah kami membuat templat untuk beberapa kode (misalnya, beberapa API atau prosedur untuk memproses logika, skrip untuk membuat struktur). Setelah kami membuat templat ini, dan kemudian jalankan melalui semua metadata. Dengan tag, properti disubstitusi ke dalam kode (nama objek, bidang, karakteristik penting), dan kode yang dihasilkan siap. Artinya, cukup bingung sekali - buat template, dan kemudian gunakan semua informasi ini untuk objek yang ada dan yang baru. Di sini kami memperkenalkan konsep lain - #META_META. Saya akan jelaskan mengapa, agar tidak membingungkan Anda.Sistem kami terlibat dalam manajemen metadata, dan pendekatan yang kami gunakan menggambarkan sistem manajemen metadata, yaitu dua meta. "MetaMeta" - kami menyebutnya di rumah, di dalam tim. Agar tidak membingungkan yang lain, kami akan menggunakan istilah ini.
Artinya, cukup bingung sekali - buat template, dan kemudian gunakan semua informasi ini untuk objek yang ada dan yang baru. Di sini kami memperkenalkan konsep lain - #META_META. Saya akan jelaskan mengapa, agar tidak membingungkan Anda.Sistem kami terlibat dalam manajemen metadata, dan pendekatan yang kami gunakan menggambarkan sistem manajemen metadata, yaitu dua meta. "MetaMeta" - kami menyebutnya di rumah, di dalam tim. Agar tidak membingungkan yang lain, kami akan menggunakan istilah ini.Mekanisme untuk memastikan historisisasi dan revisi
SC: - Anda merangkum seluruh pidato kami. Kami akan memberi tahu lebih detail.Saya harus mengatakan bahwa ketika kami sedang mempersiapkan pidato, kami diminta untuk memberikan informasi teknis yang mungkin menarik bagi rekan kerja. Kami akan melakukannya. Selanjutnya, slide akan menjadi lebih teknis - mungkin seseorang akan melihat sesuatu yang menarik untuk diri mereka sendiri.Pertama, bagaimana kita memecahkan masalah historisisasi dan revisi. Mungkin ini mirip dengan berapa banyak. Pertimbangkan ini menggunakan metadata sebagai contoh, yang menggambarkan satu bidang dalam tabel posting (sebagai contoh):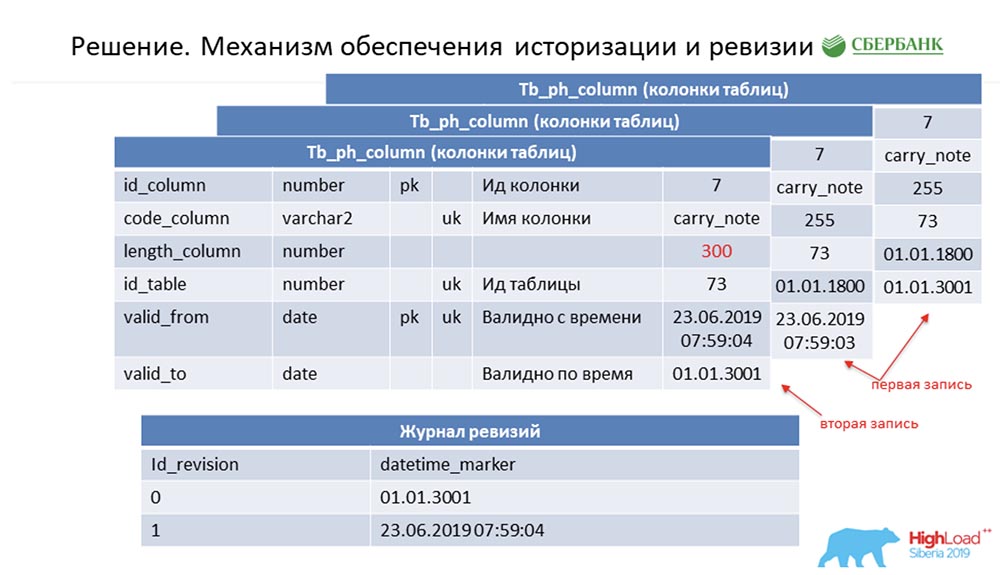 Ia memiliki id - "7", nama - carry_note, tautan id_table 73, dan bidang - 255. Kami memasukkan kunci primer dan alternatif bidang (bertipe tanggal) dari titik waktu dari mana entri ini menjadi valid - valid_from. Dan satu bidang lagi - pada tanggal berapa catatan ini valid (valid_to). Dalam hal ini, mereka diisi secara default - jelas bahwa entri ini selalu berlaku secara prinsip. Dan ini terjadi sampai kita ingin mengubah, katakanlah, panjang bidang.Segera setelah kami ingin melakukan ini, kami menutup catatan valid_to (kami memperbaiki cap waktu di mana peristiwa itu terjadi). Pada saat yang sama, kami membuat rekor baru ("300"). Sangat mudah untuk memperhatikan bahwa dalam situasi ini, jika Anda melihat database dari beberapa titik waktu oleh "pertempuran" (antara) antara valid_from dan valid_to, kami akan mendapatkan catatan tunggal, tetapi relevan pada saat itu. Dan pada saat yang sama, kami secara bersamaan menyimpan beberapa log revisi:
Ia memiliki id - "7", nama - carry_note, tautan id_table 73, dan bidang - 255. Kami memasukkan kunci primer dan alternatif bidang (bertipe tanggal) dari titik waktu dari mana entri ini menjadi valid - valid_from. Dan satu bidang lagi - pada tanggal berapa catatan ini valid (valid_to). Dalam hal ini, mereka diisi secara default - jelas bahwa entri ini selalu berlaku secara prinsip. Dan ini terjadi sampai kita ingin mengubah, katakanlah, panjang bidang.Segera setelah kami ingin melakukan ini, kami menutup catatan valid_to (kami memperbaiki cap waktu di mana peristiwa itu terjadi). Pada saat yang sama, kami membuat rekor baru ("300"). Sangat mudah untuk memperhatikan bahwa dalam situasi ini, jika Anda melihat database dari beberapa titik waktu oleh "pertempuran" (antara) antara valid_from dan valid_to, kami akan mendapatkan catatan tunggal, tetapi relevan pada saat itu. Dan pada saat yang sama, kami secara bersamaan menyimpan beberapa log revisi: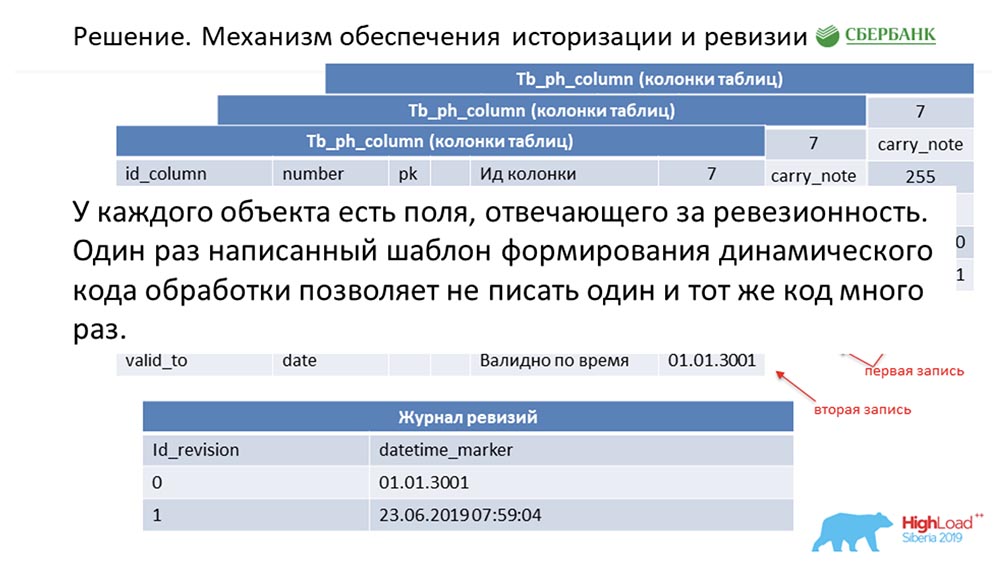 Di dalamnya kami mencatat revisi yang meningkat dalam urutan (sequence) id, dan titik waktu yang sesuai dengan id revisi ini. Jadi kami bisa menutup permintaan pertama.AC:- Saya rasa iya! Di sini pendekatannya sama. Kami memahami bahwa setiap objek dalam sistem memiliki dua bidang yang diperlukan ini, dan setelah kami bingung - menyandikan logika pemrosesan template ini, dan kemudian (saat membuat kode dinamis) kami cukup mengganti nama-nama objek yang sesuai. Jadi setiap objek di sistem kami menjadi revisi, dan semua ini dapat diproses - kami biasanya tidak menulis satu baris kode pun.
Di dalamnya kami mencatat revisi yang meningkat dalam urutan (sequence) id, dan titik waktu yang sesuai dengan id revisi ini. Jadi kami bisa menutup permintaan pertama.AC:- Saya rasa iya! Di sini pendekatannya sama. Kami memahami bahwa setiap objek dalam sistem memiliki dua bidang yang diperlukan ini, dan setelah kami bingung - menyandikan logika pemrosesan template ini, dan kemudian (saat membuat kode dinamis) kami cukup mengganti nama-nama objek yang sesuai. Jadi setiap objek di sistem kami menjadi revisi, dan semua ini dapat diproses - kami biasanya tidak menulis satu baris kode pun.Pembaruan batch
SC: - Persyaratan kedua bagi saya sedikit lebih menarik. Jujur, ketika sampai di pintu masuk, pada awalnya saya hanya menjadi pingsan. Namun keputusan telah datang!Saya mengingatkan Anda, ini adalah kasus yang sama ketika, katakanlah, JSON dengan paket datang kepada kami untuk jumlah objek ke-n yang perlu dimasukkan ke dalam sistem. Pada saat yang sama, di awal kami memiliki 10 kolom yang mengacu pada tabel tidak ada, dan tabel masuk dalam ekor JSON. Apa yang harus dilakukan? Kami menemukan jalan keluar dalam menggunakan mekanisme kueri hierarki rekursif - ini pasti terhubung dengan konstruksi sebelumnya. Kami melakukannya sebagai berikut: ini adalah bagian dari kode produksi kami:
Kami menemukan jalan keluar dalam menggunakan mekanisme kueri hierarki rekursif - ini pasti terhubung dengan konstruksi sebelumnya. Kami melakukannya sebagai berikut: ini adalah bagian dari kode produksi kami: Pada titik ini (bagian kode yang dilingkari dalam oval merah) adalah titik utama yang memberikan gagasan. Dan di sini objek dihubungkan ke objek lain yang dihubungkan oleh kunci asing, yang ada dalam sistem.Untuk memahami: jika seseorang menulis kode dalam Oracle, ada tabel All_columns, All_all_, All_constraint - ini adalah kamus yang diproses oleh skrip (seperti yang ditunjukkan pada slide di atas).Pada output, kami mendapatkan bidang yang memberi kami prioritas memproses objek, dan juga memberikan deskriptor - ini pada dasarnya pengenal string unik untuk catatan metadata apa pun. Kode dimana deskriptor diterima juga ditunjukkan pada slide di atas.Misalnya, bidang - seperti apa bentuknya? Ini adalah kode platform: oracle KP., Production. KP, my_scheme. KP, my_table. KP, dll., Di mana KP adalah kode bidang. Jadi akan ada deskriptor seperti itu.AC: - Apa masalah di sini? Kami memiliki objek dalam sistem dan urutan penyisipannya sangat penting bagi kami. Misalnya, kami tidak dapat menyisipkan kolom di depan tabel, karena kolom harus merujuk ke tabel tertentu. Seperti yang kita lakukan sebagai standar: pertama kita menyisipkan tabel, sebagai tanggapan kita mendapatkan array id, dengan ID ini kita melempar kolom dan melakukan operasi memasukkan kedua.Pada kenyataannya, seperti yang ditunjukkan Stas, panjang rantai ini mencapai 8-9 objek. Pengguna, menggunakan pendekatan standar, perlu melakukan semua operasi ini pada gilirannya (semua 9 operasi ini) dan dengan jelas memahami pesanan mereka sehingga tidak ada kesalahan terjadi.Sejauh saya menginterpretasikan Stas dengan benar, kita dapat mentransfer semua objek ini ke sistem dalam urutan apa pun dan tidak perlu repot tentang bagaimana kita perlu memasukkan ini - kita hanya melempar set sup ke dalam sistem, dan itu semua ditentukan di mana urutan untuk memasukkan.Satu-satunya yang saya miliki adalah pertanyaan: bagaimana jika kita memasukkan objek untuk pertama kalinya? Kami memasukkan tabel sebelumnya, kami tidak tahu idnya. Bagaimana kita menunjukkan (contoh murni hipotetis) bahwa kita perlu memasukkan dua tabel, yang masing-masing memiliki kolom? Bagaimana kami menunjukkan bahwa dalam kolom JSON ini merujuk ke table1, bukan table2?SC: - Seorang deskriptor! Pegangan yang kami tunjukkan pada slide itu (sebelumnya).Dan pada slide ini, solusinya diberikan:
Pada titik ini (bagian kode yang dilingkari dalam oval merah) adalah titik utama yang memberikan gagasan. Dan di sini objek dihubungkan ke objek lain yang dihubungkan oleh kunci asing, yang ada dalam sistem.Untuk memahami: jika seseorang menulis kode dalam Oracle, ada tabel All_columns, All_all_, All_constraint - ini adalah kamus yang diproses oleh skrip (seperti yang ditunjukkan pada slide di atas).Pada output, kami mendapatkan bidang yang memberi kami prioritas memproses objek, dan juga memberikan deskriptor - ini pada dasarnya pengenal string unik untuk catatan metadata apa pun. Kode dimana deskriptor diterima juga ditunjukkan pada slide di atas.Misalnya, bidang - seperti apa bentuknya? Ini adalah kode platform: oracle KP., Production. KP, my_scheme. KP, my_table. KP, dll., Di mana KP adalah kode bidang. Jadi akan ada deskriptor seperti itu.AC: - Apa masalah di sini? Kami memiliki objek dalam sistem dan urutan penyisipannya sangat penting bagi kami. Misalnya, kami tidak dapat menyisipkan kolom di depan tabel, karena kolom harus merujuk ke tabel tertentu. Seperti yang kita lakukan sebagai standar: pertama kita menyisipkan tabel, sebagai tanggapan kita mendapatkan array id, dengan ID ini kita melempar kolom dan melakukan operasi memasukkan kedua.Pada kenyataannya, seperti yang ditunjukkan Stas, panjang rantai ini mencapai 8-9 objek. Pengguna, menggunakan pendekatan standar, perlu melakukan semua operasi ini pada gilirannya (semua 9 operasi ini) dan dengan jelas memahami pesanan mereka sehingga tidak ada kesalahan terjadi.Sejauh saya menginterpretasikan Stas dengan benar, kita dapat mentransfer semua objek ini ke sistem dalam urutan apa pun dan tidak perlu repot tentang bagaimana kita perlu memasukkan ini - kita hanya melempar set sup ke dalam sistem, dan itu semua ditentukan di mana urutan untuk memasukkan.Satu-satunya yang saya miliki adalah pertanyaan: bagaimana jika kita memasukkan objek untuk pertama kalinya? Kami memasukkan tabel sebelumnya, kami tidak tahu idnya. Bagaimana kita menunjukkan (contoh murni hipotetis) bahwa kita perlu memasukkan dua tabel, yang masing-masing memiliki kolom? Bagaimana kami menunjukkan bahwa dalam kolom JSON ini merujuk ke table1, bukan table2?SC: - Seorang deskriptor! Pegangan yang kami tunjukkan pada slide itu (sebelumnya).Dan pada slide ini, solusinya diberikan: Deskriptor digunakan dalam sistem sebagai semacam bidang mnemonik yang tidak ada, tetapi menggantikan id. Pada saat itu, ketika pada awalnya sistem memahami bahwa perlu memasukkan tabel - masukkan, ia akan menerima id; dan sudah pada tahap menghasilkan query SQL untuk memasukkan dan kolom, itu akan beroperasi pada id. Pengguna tidak dapat mandi uap: "Berikan pegangan dan eksekusi!". Sistem akan melakukannya.
Deskriptor digunakan dalam sistem sebagai semacam bidang mnemonik yang tidak ada, tetapi menggantikan id. Pada saat itu, ketika pada awalnya sistem memahami bahwa perlu memasukkan tabel - masukkan, ia akan menerima id; dan sudah pada tahap menghasilkan query SQL untuk memasukkan dan kolom, itu akan beroperasi pada id. Pengguna tidak dapat mandi uap: "Berikan pegangan dan eksekusi!". Sistem akan melakukannya.Permintaan universal pada sekelompok objek terkait
Mungkin kasus favorit saya. Ini adalah persyaratan teknis favorit yang kami miliki. Mereka mendatangi kami dan berkata, “Guys, lakukan itu supaya sistem bisa melakukan semuanya! Dari objek ke objek, silakan. Coba tebak bagaimana semuanya bergabung di antara mereka sendiri. Kembalikan kami, JSON. Kami tidak ingin banyak memprogram menggunakan layanan Anda "...Pertanyaan:" Bagaimana?! "Kami sebenarnya pergi dengan cara yang sama. Konstruksi yang persis sama: Itu digunakan untuk menyelesaikan masalah ini. Satu-satunya perbedaan adalah bahwa ada filter yang valid, yang mencabut pohon hierarki ini hanya untuk cerita-cerita di mana deskriptor diperlukan. Secara relatif, itu unik untuk setiap objek. Di sini, semua koneksi yang mungkin dalam sistem tidak terpilin (kami memiliki sekitar 50 objek).Semua koneksi yang mungkin antar objek dipersiapkan sebelumnya. Jika kita memiliki objek yang terlibat dalam tiga hubungan, masing-masing, tiga baris akan disiapkan sehingga algoritme dapat dipahami. Dan segera setelah permintaan JSON datang kepada kami, kami pergi ke tempat di mana cerita ini disiapkan sebelumnya di MeteMet, kami sedang mencari cara yang kami butuhkan. Jika kami tidak menemukannya, ini adalah satu cerita, jika kami menemukannya, kami membentuk kueri dalam basis data. Menjalankan - mengembalikan JSON (seperti yang diminta).AC: - Sebagai hasilnya, kita dapat mentransfer ke sistem objek yang ingin kita terima. Dan jika Anda dapat menguraikan koneksi yang jelas antara dua objek, maka sistem itu sendiri akan mencari tahu tingkat bersarang objek yang akan kembali kepada Anda di pohon:Sangat fleksibel! Sekali lagi, pengguna kami berada dalam "turbulensi": hari ini mereka membutuhkan satu hal, besok mereka membutuhkan yang lain. Dan solusi ini memungkinkan kita untuk menyesuaikan struktur dengan sangat fleksibel. Ini adalah tiga kasus utama yang digunakan pada sisi inti kami.SC: - Mari kita simpulkan beberapa. Jelas bahwa sekarang kami tidak akan memberi tahu semua chip karena waktu yang terbatas. Tiga kasus, menurut pendapat kami, kami lakukan dan katakan. Kami berhasil, kami dapat menempatkan semua logika yang paling kompleks, dan yang harus bekerja secara seragam untuk setiap objek manajemen metadata, ke dalam kode kernel.Kami tidak dapat membuat kode ini 100% dinamis, yang berarti bahwa dengan objek apa pun yang dibuat (tidak masalah apakah mereka sudah dibuat atau yang akan dibuat nanti; yang utama harus dibuat sesuai dengan aturan), sistem dapat bekerja - tidak ada yang perlu ditambahkan, ditulis ulang. Pengujian saja sudah cukup. Kami memarkir keseluruhan cerita ini menjadi tiga metode universal. Menurut pendapat saya, ada cukup banyak dari mereka untuk menyelesaikan hampir semua masalah bisnis:
Itu digunakan untuk menyelesaikan masalah ini. Satu-satunya perbedaan adalah bahwa ada filter yang valid, yang mencabut pohon hierarki ini hanya untuk cerita-cerita di mana deskriptor diperlukan. Secara relatif, itu unik untuk setiap objek. Di sini, semua koneksi yang mungkin dalam sistem tidak terpilin (kami memiliki sekitar 50 objek).Semua koneksi yang mungkin antar objek dipersiapkan sebelumnya. Jika kita memiliki objek yang terlibat dalam tiga hubungan, masing-masing, tiga baris akan disiapkan sehingga algoritme dapat dipahami. Dan segera setelah permintaan JSON datang kepada kami, kami pergi ke tempat di mana cerita ini disiapkan sebelumnya di MeteMet, kami sedang mencari cara yang kami butuhkan. Jika kami tidak menemukannya, ini adalah satu cerita, jika kami menemukannya, kami membentuk kueri dalam basis data. Menjalankan - mengembalikan JSON (seperti yang diminta).AC: - Sebagai hasilnya, kita dapat mentransfer ke sistem objek yang ingin kita terima. Dan jika Anda dapat menguraikan koneksi yang jelas antara dua objek, maka sistem itu sendiri akan mencari tahu tingkat bersarang objek yang akan kembali kepada Anda di pohon:Sangat fleksibel! Sekali lagi, pengguna kami berada dalam "turbulensi": hari ini mereka membutuhkan satu hal, besok mereka membutuhkan yang lain. Dan solusi ini memungkinkan kita untuk menyesuaikan struktur dengan sangat fleksibel. Ini adalah tiga kasus utama yang digunakan pada sisi inti kami.SC: - Mari kita simpulkan beberapa. Jelas bahwa sekarang kami tidak akan memberi tahu semua chip karena waktu yang terbatas. Tiga kasus, menurut pendapat kami, kami lakukan dan katakan. Kami berhasil, kami dapat menempatkan semua logika yang paling kompleks, dan yang harus bekerja secara seragam untuk setiap objek manajemen metadata, ke dalam kode kernel.Kami tidak dapat membuat kode ini 100% dinamis, yang berarti bahwa dengan objek apa pun yang dibuat (tidak masalah apakah mereka sudah dibuat atau yang akan dibuat nanti; yang utama harus dibuat sesuai dengan aturan), sistem dapat bekerja - tidak ada yang perlu ditambahkan, ditulis ulang. Pengujian saja sudah cukup. Kami memarkir keseluruhan cerita ini menjadi tiga metode universal. Menurut pendapat saya, ada cukup banyak dari mereka untuk menyelesaikan hampir semua masalah bisnis:- pertama, "pembaru" universal yang sama ini adalah metode yang dapat melakukan pembaruan / masukkan / hapus (hapus adalah penutupan catatan) pada satu atau sekelompok objek yang ditransfer dalam urutan acak.
- yang kedua adalah metode yang dapat mengembalikan informasi universal hanya pada satu objek;
- yang ketiga adalah metode yang sama yang dapat mengembalikan informasi Bergabung yang dihubungkan oleh kelompok objek.
Begitulah yang terjadi, dan kami membuat intinya. Dan kemudian kita akan beralih ke bagian favorit Anda.Titik Masuk Aplikasi
AC: - Ya, ini adalah bagian favorit saya, karena ini adalah area tanggung jawab saya - Server Aplikasi. Untuk memahami situasi apa yang saya alami, saya akan mencoba menjerumuskan Anda ke masalah lagi.Stas melakukan pekerjaan dengan baik dan memberikan saya tiga metode standar yang memanipulasi objek-objek ini. Ini adalah deskripsi yang murni samar - dalam kenyataannya ada banyak lagi: Mari kita kembali ke awal untuk membenamkan Anda ... Bagaimana metadata dalam sistem disajikan di sini?
Mari kita kembali ke awal untuk membenamkan Anda ... Bagaimana metadata dalam sistem disajikan di sini?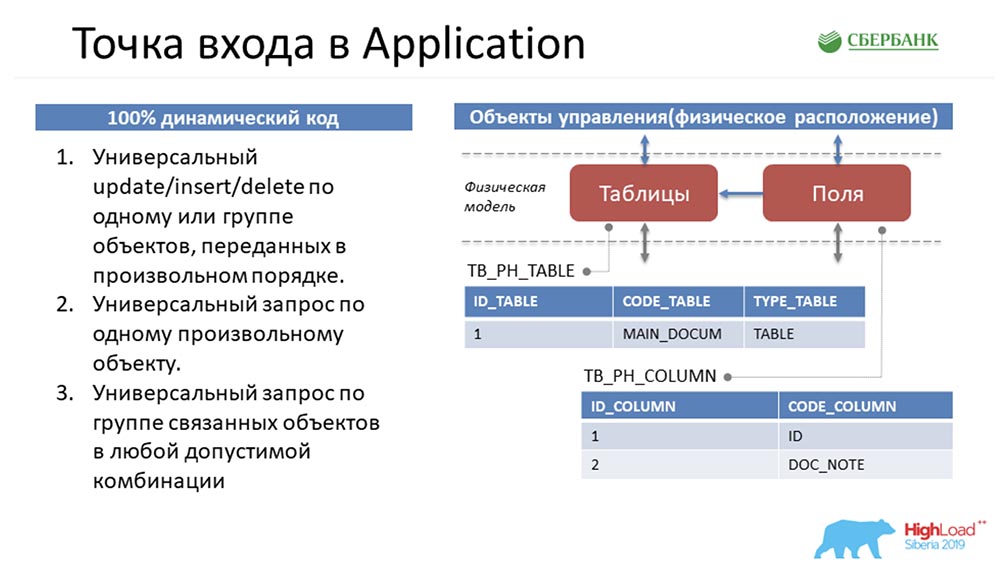 Jika kita melihat bahwa ada tabel di lingkungan, itu akan jatuh ke sistem kita sebagai satu catatan dalam objek tabel dan beberapa catatan dalam objek bidang. Pada dasarnya, kami telah menyusun struktur.Kita dapat memperhatikan bahwa jumlah benda-benda ini berbeda. Kemudian, untuk memanipulasi objek-objek ini, untuk membawa semuanya ke struktur universal, sehingga ketiga metode memahami apa yang sedang dibahas, Stas bergerak dengan kuda. Dibutuhkan, dan membalik semua objek, yaitu, ia merepresentasikan objek apa pun dalam sistem manajemen metadata kami sebagai empat baris:
Jika kita melihat bahwa ada tabel di lingkungan, itu akan jatuh ke sistem kita sebagai satu catatan dalam objek tabel dan beberapa catatan dalam objek bidang. Pada dasarnya, kami telah menyusun struktur.Kita dapat memperhatikan bahwa jumlah benda-benda ini berbeda. Kemudian, untuk memanipulasi objek-objek ini, untuk membawa semuanya ke struktur universal, sehingga ketiga metode memahami apa yang sedang dibahas, Stas bergerak dengan kuda. Dibutuhkan, dan membalik semua objek, yaitu, ia merepresentasikan objek apa pun dalam sistem manajemen metadata kami sebagai empat baris: Karena objek apa pun dalam sistem manajemen metadata kami secara fisik adalah sebuah tabel, objek apa pun dapat diuraikan menurut empat tanda berikut: nomor baris , tabel, bidang dan nilai bidang. Itu Stas yang datang dengan semua ini, dan saya perlu entah bagaimana mengimplementasikannya dan memberikannya kepada pengguna.SC:- Maaf, tetapi bagaimana saya bisa menyampaikan kepada Anda dalam kolom jawaban datar, misalnya, yang belum pernah dibuat, akan dibuat kapan-kapan, dan Tuhan tahu apa itu? ... Oleh karena itu, satu-satunya pilihan dalam kondisi kode dinamis adalah mengkonfigurasi interaksi antara inti dan aplikasi, untuk mengirimkan informasi ini kepada Anda - hanya seperti yang kita lihat. Saya percaya bahwa dari sudut pandang saya, keputusan ini cerdik, karena itu datang hanya dari Anda.AC: - Sekarang kita tidak akan berdebat tentang ini. Dua minggu sebelum batas waktu berakhir, saya tetap dengan fakta bahwa saya memiliki tiga metode ini di tangan saya (di sebelah kiri pada slide sebelumnya) yang memanipulasi struktur universal (di sebelah kanan pada slide yang sama).Pikiran pertama saya adalah hanya membungkus semuanya pada tingkat API dan pergi ke pengguna dengan ini, mengatakan: "Lihat, betapa hebatnya! Anda dapat melakukan apapun! Transfer objek apa pun, atau bahkan objek yang tidak ada. Keren, ya "?!
Karena objek apa pun dalam sistem manajemen metadata kami secara fisik adalah sebuah tabel, objek apa pun dapat diuraikan menurut empat tanda berikut: nomor baris , tabel, bidang dan nilai bidang. Itu Stas yang datang dengan semua ini, dan saya perlu entah bagaimana mengimplementasikannya dan memberikannya kepada pengguna.SC:- Maaf, tetapi bagaimana saya bisa menyampaikan kepada Anda dalam kolom jawaban datar, misalnya, yang belum pernah dibuat, akan dibuat kapan-kapan, dan Tuhan tahu apa itu? ... Oleh karena itu, satu-satunya pilihan dalam kondisi kode dinamis adalah mengkonfigurasi interaksi antara inti dan aplikasi, untuk mengirimkan informasi ini kepada Anda - hanya seperti yang kita lihat. Saya percaya bahwa dari sudut pandang saya, keputusan ini cerdik, karena itu datang hanya dari Anda.AC: - Sekarang kita tidak akan berdebat tentang ini. Dua minggu sebelum batas waktu berakhir, saya tetap dengan fakta bahwa saya memiliki tiga metode ini di tangan saya (di sebelah kiri pada slide sebelumnya) yang memanipulasi struktur universal (di sebelah kanan pada slide yang sama).Pikiran pertama saya adalah hanya membungkus semuanya pada tingkat API dan pergi ke pengguna dengan ini, mengatakan: "Lihat, betapa hebatnya! Anda dapat melakukan apapun! Transfer objek apa pun, atau bahkan objek yang tidak ada. Keren, ya "?! Dan mereka berkata: "Tetapi Anda mengerti bahwa layanan Anda sama sekali tidak terspesialisasi? Sebagai pengguna, saya tidak mengerti benda apa yang bisa saya transfer ke sistem, bagaimana saya bisa memanipulasi mereka ... Bagi saya itu adalah kotak hitam, saya umumnya takut bahwa saya akan mengirimkan data; Saya bisa salah - saya takut. Buat agar saya dapat dengan jelas mengikuti instruksi dan melihat objek apa yang ada di sistem dan metode manipulasi apa yang bisa saya gunakan. "
Dan mereka berkata: "Tetapi Anda mengerti bahwa layanan Anda sama sekali tidak terspesialisasi? Sebagai pengguna, saya tidak mengerti benda apa yang bisa saya transfer ke sistem, bagaimana saya bisa memanipulasi mereka ... Bagi saya itu adalah kotak hitam, saya umumnya takut bahwa saya akan mengirimkan data; Saya bisa salah - saya takut. Buat agar saya dapat dengan jelas mengikuti instruksi dan melihat objek apa yang ada di sistem dan metode manipulasi apa yang bisa saya gunakan. "Bintik. Pendekatan
Kemudian menjadi jelas bagi kami bahwa itu keren untuk membuat spesifikasi untuk layanan kami. Singkatnya, untuk membuat daftar objek dari sistem kita, daftar poin, manipulasi dan objek apa yang mereka juggle satu sama lain. Kebetulan di perusahaan kami, kami menggunakan Swagger untuk tujuan ini sebagai semacam solusi arsitektur. Setelah melihat struktur Swagger, saya menyadari bahwa saya perlu mengambil suatu tempat struktur objek yang ada di sistem. Dari kernel, saya hanya menerima tiga metode standar dan pengubah tabel. Tidak ada lagi. Bagi saya, sepertinya tugas yang mustahil untuk mendapatkan seluruh struktur yang ada di repositori dari empat bidang standar ini. Saya dengan tulus tidak mengerti di mana mendapatkan semua deskripsi objek, semua nilai yang diizinkan, semua logika ...SC:- Apa artinya dimana? Anda dan saya memiliki MetaMeta, yang menyediakan kernel dalam mode real-time. Kernel dalam eksekusi real-time menghasilkan query SQL yang berkomunikasi dengan database. Semuanya ada di sana, bukan hanya yang Anda butuhkan. Ada juga tautan antar objek.AC: - Atas saran Stas, kemudian saya pergi ke MetaMetu dan terkejut, karena semua kit pria yang diperlukan untuk menghasilkan spesifikasi standar ada di sana. Kemudian muncul ide bahwa Anda perlu membuat template dan mengecat semuanya sesuai dengan tujuh skenario yang mungkin - 7 API standar untuk setiap objek.
Setelah melihat struktur Swagger, saya menyadari bahwa saya perlu mengambil suatu tempat struktur objek yang ada di sistem. Dari kernel, saya hanya menerima tiga metode standar dan pengubah tabel. Tidak ada lagi. Bagi saya, sepertinya tugas yang mustahil untuk mendapatkan seluruh struktur yang ada di repositori dari empat bidang standar ini. Saya dengan tulus tidak mengerti di mana mendapatkan semua deskripsi objek, semua nilai yang diizinkan, semua logika ...SC:- Apa artinya dimana? Anda dan saya memiliki MetaMeta, yang menyediakan kernel dalam mode real-time. Kernel dalam eksekusi real-time menghasilkan query SQL yang berkomunikasi dengan database. Semuanya ada di sana, bukan hanya yang Anda butuhkan. Ada juga tautan antar objek.AC: - Atas saran Stas, kemudian saya pergi ke MetaMetu dan terkejut, karena semua kit pria yang diperlukan untuk menghasilkan spesifikasi standar ada di sana. Kemudian muncul ide bahwa Anda perlu membuat template dan mengecat semuanya sesuai dengan tujuh skenario yang mungkin - 7 API standar untuk setiap objek.Bintik. OAS + Setang
Jadi, mudah untuk melihat apa yang menjadi spesifikasi: Anda dapat pergi ke situs web OAS dan Handlebars (di bagian bawah slide) dan melihat apa yang seharusnya terdiri dari - ada satu set Endpoints, satu set metode, dan pada akhirnya ada model. Kode diulangi dari waktu ke waktu. Untuk setiap objek, kita harus menulis get, put. menghapus; untuk sekelompok objek, kita harus menulis ini dan seterusnya.Caranya adalah dengan menulis keseluruhan cerita sekali dan tidak lagi mandi. Slide menunjukkan contoh kode nyata. Objek biru adalah tag di Setang, ini adalah mesin templat; cukup fleksibel, saya menyarankan semua orang - Anda dapat menyesuaikannya sendiri, menulis penangan tag khusus ...Di tempat dari tag biru ini, ketika templat ini dijalankan di atas semua metadata semua, semua properti signifikan diganti - nama objek, deskripsi, semacam logika (misalnya, kita perlu menambahkan parameter tambahan, tergantung pada properti) dan seterusnya. Pada akhirnya adalah tautan ke model yang ia tafsirkan.
Anda dapat pergi ke situs web OAS dan Handlebars (di bagian bawah slide) dan melihat apa yang seharusnya terdiri dari - ada satu set Endpoints, satu set metode, dan pada akhirnya ada model. Kode diulangi dari waktu ke waktu. Untuk setiap objek, kita harus menulis get, put. menghapus; untuk sekelompok objek, kita harus menulis ini dan seterusnya.Caranya adalah dengan menulis keseluruhan cerita sekali dan tidak lagi mandi. Slide menunjukkan contoh kode nyata. Objek biru adalah tag di Setang, ini adalah mesin templat; cukup fleksibel, saya menyarankan semua orang - Anda dapat menyesuaikannya sendiri, menulis penangan tag khusus ...Di tempat dari tag biru ini, ketika templat ini dijalankan di atas semua metadata semua, semua properti signifikan diganti - nama objek, deskripsi, semacam logika (misalnya, kita perlu menambahkan parameter tambahan, tergantung pada properti) dan seterusnya. Pada akhirnya adalah tautan ke model yang ia tafsirkan.Kode aplikasi. Swagger Codegen + Setang
Semua ini kami disandikan, direkam, dibuat spec. Semuanya sangat keren dan bagus. Kami mendapatkan semua 7 skenario yang mungkin untuk setiap objek.Berikan ke pengguna. Dia berkata: “Wow! Keren! Sekarang kami ingin menggunakannya! " Apa masalahnya lagi?Kami memiliki spesifikasi yang menjelaskan setiap metode secara terperinci, apa yang harus dilakukan dengannya, objek apa yang akan dimanipulasi. Dan ada tiga metode kernel standar yang mengambil tabel terbalik yang dijelaskan di atas sebagai input.Maka Anda hanya harus menyeberang satu dengan yang lain (sekarang sepertinya mudah bagi saya). Artinya, ketika seorang pengguna memanggil metode di antarmuka, kami harus benar dan benar meneruskannya ke kernel, mengubah model (di mana kami memiliki spesifikasi yang indah) menjadi empat bidang standar ini. Hanya itu yang harus dilakukan. Untuk mempraktekkan semua ini, kami membutuhkan transformasi "nominatif" ...
Untuk mempraktekkan semua ini, kami membutuhkan transformasi "nominatif" ...Konversi
Swagger pada awalnya memiliki alat seperti itu - Swagger Codegen. Jika Anda pernah masuk ke spesifikasi, dibuat-buat, maka ada tombol "Hasilkan bagian server". Klik, pilih bahasa - proyek selesai dibuat untuk Anda.Ini dihasilkan secara luar biasa: ada semua deskripsi kelas, semua deskripsi titik akhir ... - itu berfungsi. Anda dapat menjalankannya secara lokal - ini akan berhasil. Masalahnya adalah satu: ia mengembalikan stubs - setiap metode tidak bertambah.Idenya adalah untuk menambahkan logika berdasarkan tujuh skenario ini di generator kode - "merusak" salah satu templat standar, konfigurasikan sendiri. Berikut ini hanya contoh kode nyata yang kami gunakan di mesin templat dan daftar tindakan yang perlu kami lakukan untuk mengonfigurasi pembuat kode ini untuk diri sendiri: Hal terpenting yang mereka lakukan adalah menghubungkan pustaka yang diperlukan, menulis kelas untuk berkomunikasi dengan kernel, dan menafsirkan (tergantung pada skenario) panggilan satu atau lebih metode di sisi kernel. Model itu juga dibalik: dari yang cantik yang ditunjukkan dalam spec ke empat bidang, dan kemudian diubah kembali.Mungkin kasus yang paling sulit di sini adalah memberikan pohon kepada pengguna, karena kernel juga mengembalikan empat baris kepada kami - pergi dan lihat level hirarki apa. Kami menggunakan mekanisme hubungan eksternal, yang ada dalam IDE, yaitu, kami pergi ke MetaMetu, melihat semua jalur dari satu ke yang lain dan secara dinamis menghasilkan pohon melalui mereka. Pengguna dapat meminta kami dari objek apa pun untuk apa pun yang diinginkannya - pohon yang indah akan dikembalikan kepadanya di pintu keluar, di mana semuanya sudah ditata secara struktural.SC: - Saya akan menghentikan Anda sebentar, karena saya sudah mulai tersesat. Saya akan bertanya kepada Anda dengan gaya "Apakah saya memahaminya dengan benar" ...Anda ingin mengatakan bahwa kami telah menghitung semua kode yang paling rumit, paling rumit yang harus ditulis untuk beberapa objek baru. Dan untuk menghemat waktu, bukan untuk melakukannya, kami berhasil memasukkan semuanya ke dalam kernel dan menjadikan cerita ini dinamis ... Tapi API ini (saat mereka bercanda, "keras kepala") adalah "apa saja" yang menakutkan untuk dibagikan: penanganan yang tidak tepat: menangani dengan tidak tepat dengan itu, Anda dapat merusak metadata. Ini di satu sisi.Di sisi lain, kami menyadari bahwa kami tidak dapat berkomunikasi dengan klien pelanggan kami kecuali kami memberikan mereka API, yang akan menjadi proyeksi unik dari objek manajemen metadata yang tertanam dalam sistem (pada kenyataannya, melaksanakan kontrak tertentu untuk layanan kami). Tampaknya semua - kita tekan: jika objek tidak ada - itu belum ada, dan ketika muncul - ekstensi kontrak muncul, sudah kode baru.Kami sepertinya telah masuk ke dalam pengkodean manual yang dapat dihindari, tetapi di sini Anda mengusulkan untuk melakukan kode ini dengan tombol. Sekali lagi, kita berhasil keluar dari sejarah ketika kita perlu menulis sesuatu dengan tangan kita. Ini benar?AC: - Ya, benar. Secara umum, ide saya adalah memulai pemrograman sekali dan untuk semua, setidaknya dengan bantuan mesin template. Tulis kode satu kali, lalu rileks. Dan bahkan jika objek baru muncul di sistem - dengan tombol kita memulai pembaruan, semuanya diperketat, kita memiliki struktur baru, metode baru dihasilkan, semuanya baik-baik saja.
Hal terpenting yang mereka lakukan adalah menghubungkan pustaka yang diperlukan, menulis kelas untuk berkomunikasi dengan kernel, dan menafsirkan (tergantung pada skenario) panggilan satu atau lebih metode di sisi kernel. Model itu juga dibalik: dari yang cantik yang ditunjukkan dalam spec ke empat bidang, dan kemudian diubah kembali.Mungkin kasus yang paling sulit di sini adalah memberikan pohon kepada pengguna, karena kernel juga mengembalikan empat baris kepada kami - pergi dan lihat level hirarki apa. Kami menggunakan mekanisme hubungan eksternal, yang ada dalam IDE, yaitu, kami pergi ke MetaMetu, melihat semua jalur dari satu ke yang lain dan secara dinamis menghasilkan pohon melalui mereka. Pengguna dapat meminta kami dari objek apa pun untuk apa pun yang diinginkannya - pohon yang indah akan dikembalikan kepadanya di pintu keluar, di mana semuanya sudah ditata secara struktural.SC: - Saya akan menghentikan Anda sebentar, karena saya sudah mulai tersesat. Saya akan bertanya kepada Anda dengan gaya "Apakah saya memahaminya dengan benar" ...Anda ingin mengatakan bahwa kami telah menghitung semua kode yang paling rumit, paling rumit yang harus ditulis untuk beberapa objek baru. Dan untuk menghemat waktu, bukan untuk melakukannya, kami berhasil memasukkan semuanya ke dalam kernel dan menjadikan cerita ini dinamis ... Tapi API ini (saat mereka bercanda, "keras kepala") adalah "apa saja" yang menakutkan untuk dibagikan: penanganan yang tidak tepat: menangani dengan tidak tepat dengan itu, Anda dapat merusak metadata. Ini di satu sisi.Di sisi lain, kami menyadari bahwa kami tidak dapat berkomunikasi dengan klien pelanggan kami kecuali kami memberikan mereka API, yang akan menjadi proyeksi unik dari objek manajemen metadata yang tertanam dalam sistem (pada kenyataannya, melaksanakan kontrak tertentu untuk layanan kami). Tampaknya semua - kita tekan: jika objek tidak ada - itu belum ada, dan ketika muncul - ekstensi kontrak muncul, sudah kode baru.Kami sepertinya telah masuk ke dalam pengkodean manual yang dapat dihindari, tetapi di sini Anda mengusulkan untuk melakukan kode ini dengan tombol. Sekali lagi, kita berhasil keluar dari sejarah ketika kita perlu menulis sesuatu dengan tangan kita. Ini benar?AC: - Ya, benar. Secara umum, ide saya adalah memulai pemrograman sekali dan untuk semua, setidaknya dengan bantuan mesin template. Tulis kode satu kali, lalu rileks. Dan bahkan jika objek baru muncul di sistem - dengan tombol kita memulai pembaruan, semuanya diperketat, kita memiliki struktur baru, metode baru dihasilkan, semuanya baik-baik saja.Tuning MetaMeta
Untuk membuat layanan kami lebih baik, kami memperkaya MetaMeta standar. Di pintu masuk, kami memiliki apa yang tersisa dari inti. Kami juga menambahkan deskripsi tambahan ke objek, objek dikelompokkan dalam area. Kami menampilkan semua ini dalam spesifikasi sehingga pengguna memahami apa yang ia manipulasi dan dengan objek apa yang sedang ia komunikasikan.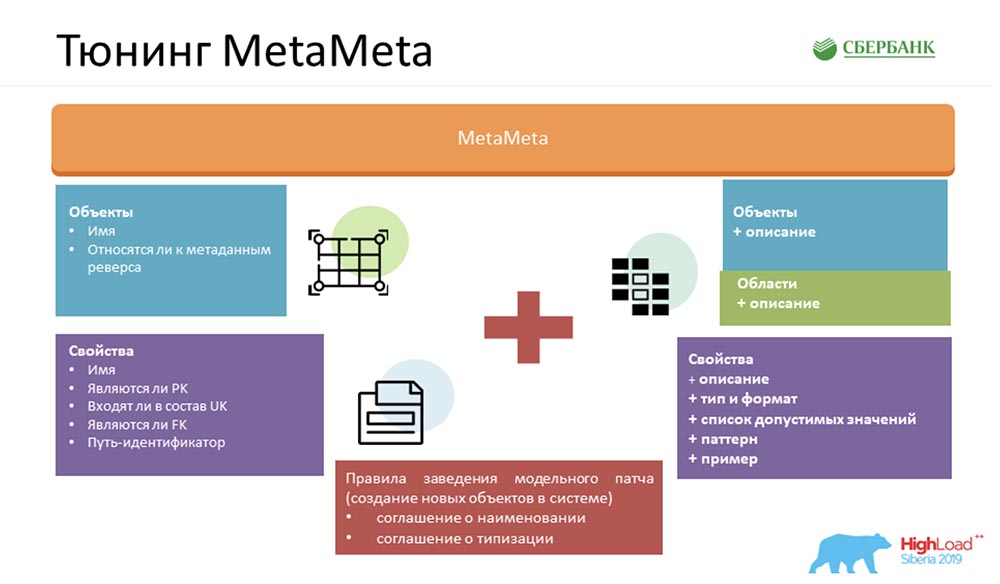 Hanya kami menambahkan beberapa hal kecil di sana - jenis, format, daftar nilai yang dapat diterima, pola, contoh. Ini juga menyenangkan pengguna - mereka sudah mengerti dengan jelas apa yang bisa dimasukkan, apa yang tidak bisa. Kami juga menyediakan artefak klien kepada pengguna, yang memungkinkan kami menangkap kesalahan saat berkomunikasi dengan layanan kami (tepatnya dengan format, sudah pada tahap kompilasi).Tetapi yang paling penting, agar semua keajaiban ini berhasil, kami perlu menyepakati bagian dalam: membuat seperangkat aturan tertentu. Tidak banyak dari mereka - saya hitung tiga (ada dua di slide, jadi harus diingat):
Hanya kami menambahkan beberapa hal kecil di sana - jenis, format, daftar nilai yang dapat diterima, pola, contoh. Ini juga menyenangkan pengguna - mereka sudah mengerti dengan jelas apa yang bisa dimasukkan, apa yang tidak bisa. Kami juga menyediakan artefak klien kepada pengguna, yang memungkinkan kami menangkap kesalahan saat berkomunikasi dengan layanan kami (tepatnya dengan format, sudah pada tahap kompilasi).Tetapi yang paling penting, agar semua keajaiban ini berhasil, kami perlu menyepakati bagian dalam: membuat seperangkat aturan tertentu. Tidak banyak dari mereka - saya hitung tiga (ada dua di slide, jadi harus diingat):- Konvensi penamaan. Kami secara khusus memberi nama objek dalam sistem untuk membuatnya lebih mudah untuk mengenali skenario untuk penggunaan lebih lanjut.
- Perjanjian pengetikan. Ini untuk menentukan dengan benar jenis, format, dan sehingga mereka bertarung antara kernel dan server aplikasi, kami menggunakan sistem pemeriksaan, yang dengannya kami memahami format milik properti ini atau itu.
- Kunci asing yang valid. Jika objek diberi tautan yang tidak valid ke objek lain, maka semua keajaiban ini akan bekerja secara tidak benar.
Hasil
SC: - Keren, tapi banyak teori. Bisakah Anda memberikan beberapa contoh praktis?AC: - Ya, saya khusus menyiapkannya. Sebelum berangkat ke konferensi, pada Jumat malam, secara harfiah 5 menit sebelum akhir hari kerja, Stas mengatakan kepada saya: “Oh, lihat! Saya merilis model patch - keren sekali! Akan menyenangkan untuk memperbarui layanan kami. " Patch hanya berisi dua objek, tetapi saya mengerti bahwa dengan pendekatan lama saya harus bingung dan menulis atau menambahkan 7 API.Segera saya hanya memiliki klik tombol untuk membuat semua pekerjaan ajaib ini. Saya secara khusus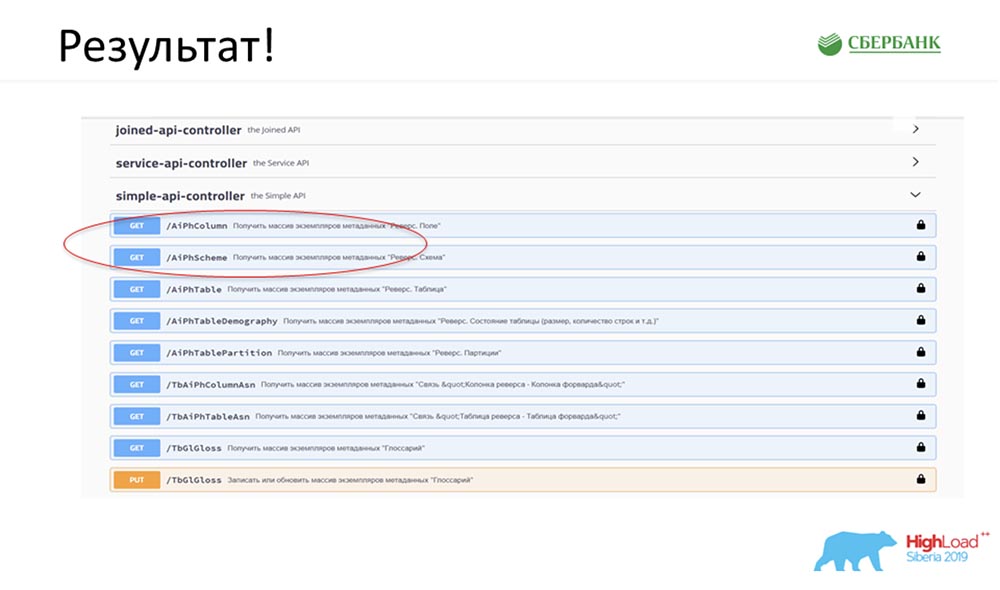 melingkari merah di tempat keajaiban itu akan terjadi: Saya mengklik tombol ... Ini tentu saja screenshot, tetapi dalam kenyataannya semuanya bekerja seperti ini:
melingkari merah di tempat keajaiban itu akan terjadi: Saya mengklik tombol ... Ini tentu saja screenshot, tetapi dalam kenyataannya semuanya bekerja seperti ini: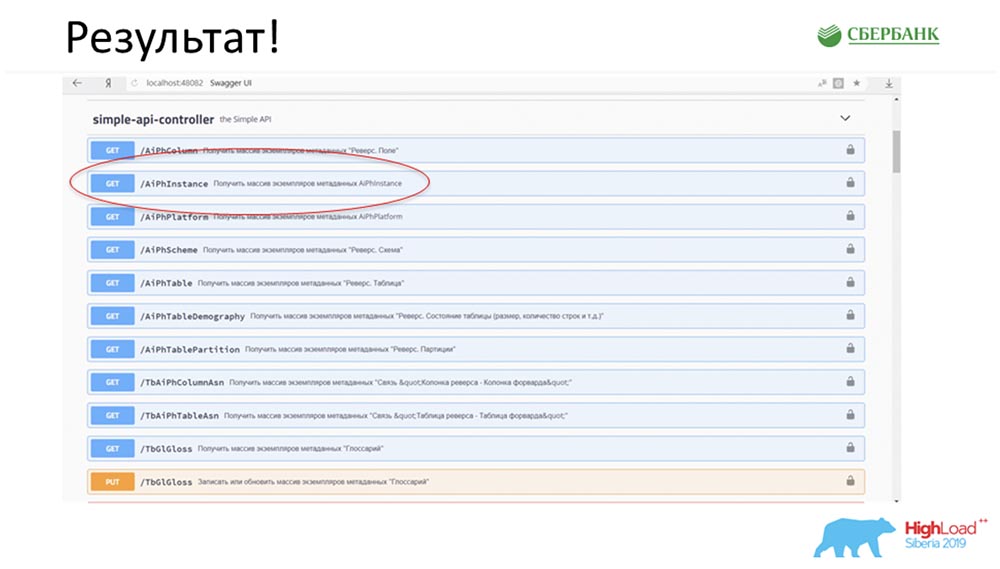 Kami memiliki metode baru (di antara keduanya) yang sudah memberikan data, yang dengannya kami dalam hierarki dapat meminta seluruh struktur, semua objek bersarang:
Kami memiliki metode baru (di antara keduanya) yang sudah memberikan data, yang dengannya kami dalam hierarki dapat meminta seluruh struktur, semua objek bersarang: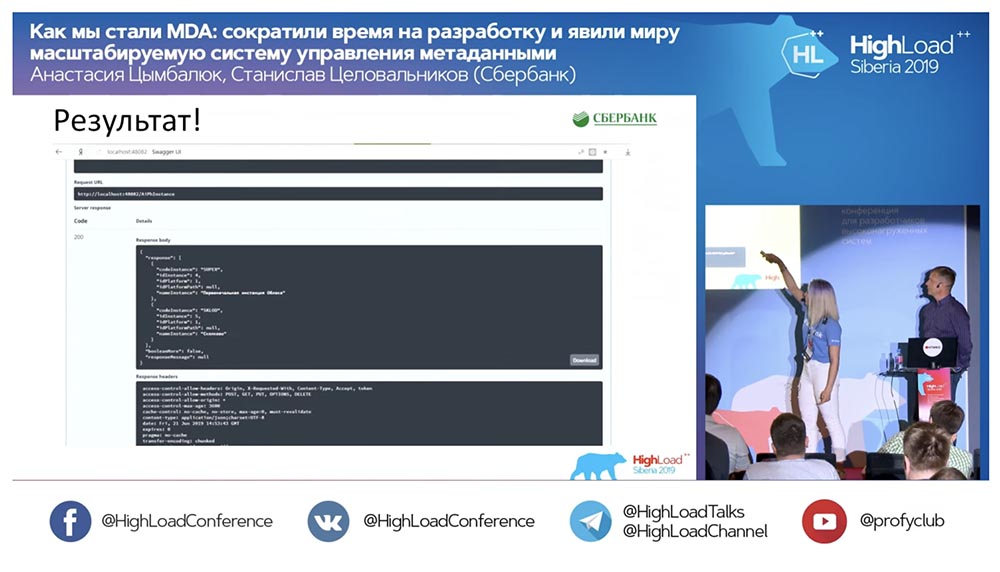
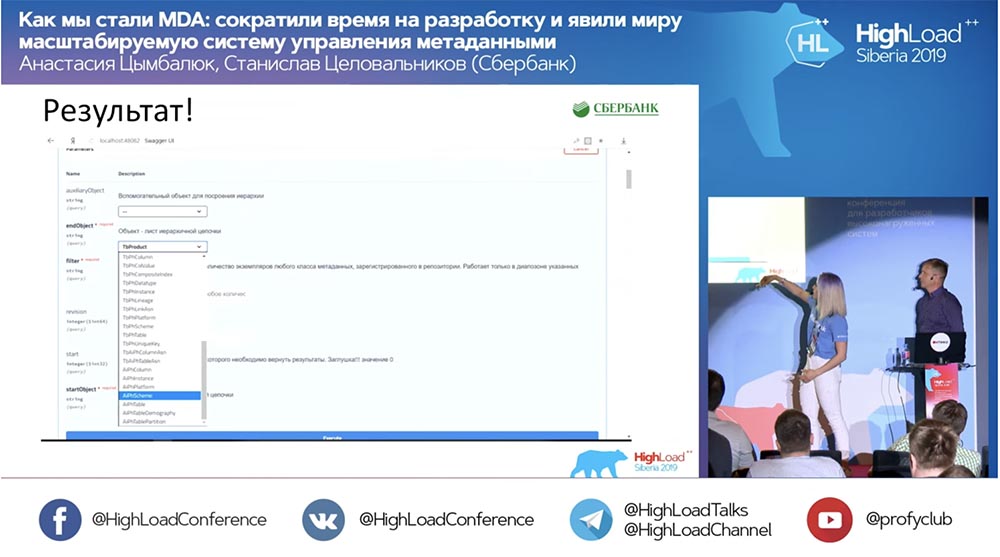
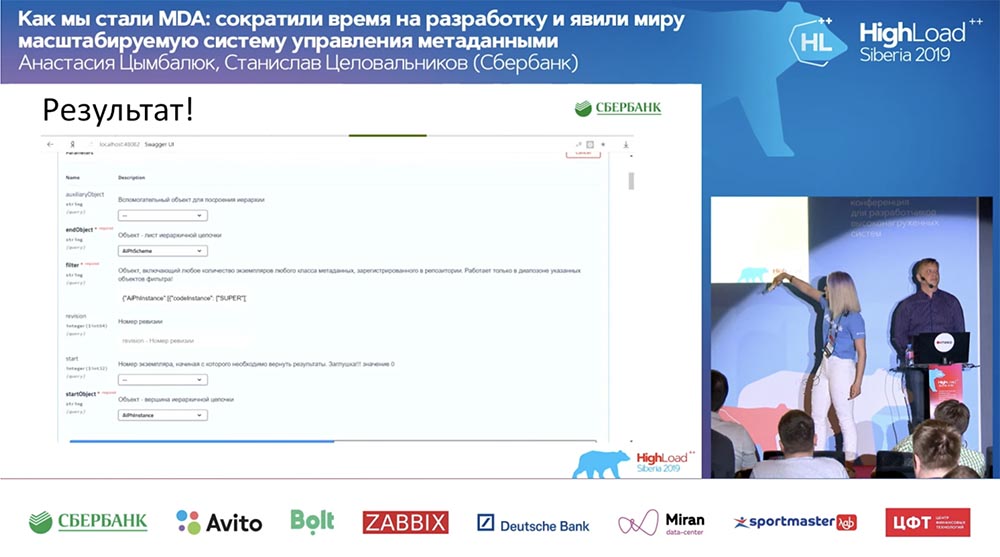 Dan semuanya bekerja! Saya belum menulis satu baris kode sama sekali.
Dan semuanya bekerja! Saya belum menulis satu baris kode sama sekali.Ringkasan
SC: - Pertama, apa faktanya? Kami mengelola logika yang paling kompleks, yang akan memakan waktu paling banyak bagi programmer kami, untuk mengemas 100% kode kernel dinamis yang dapat bekerja dengan objek - objek yang ada dan yang akan menjadi: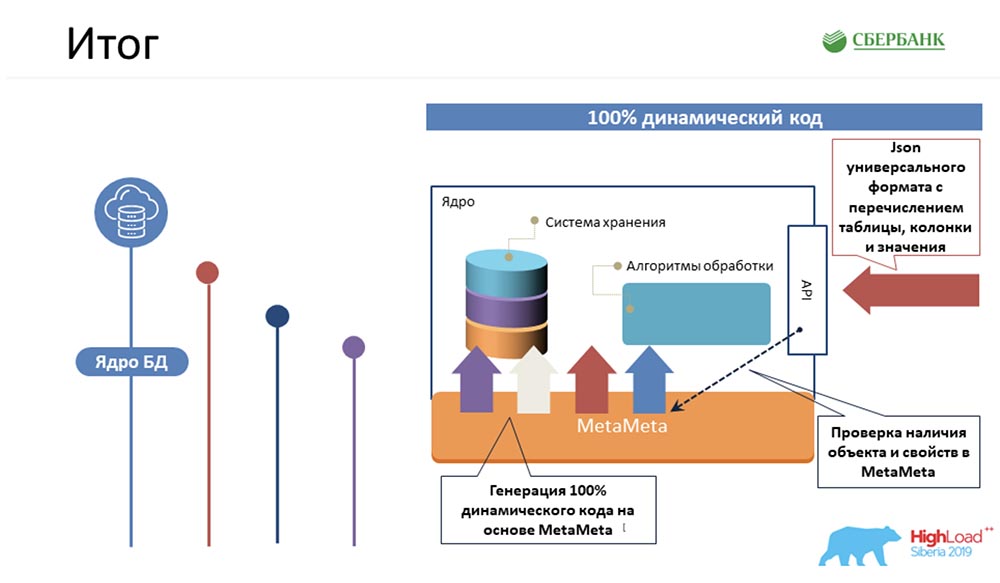 Kedua, kami berhasil di level server aplikasi (jika tidak memungkinkan) untuk juga menghindari pemrograman karena pembuatan kode - tombol yang sama dengan yang Anda contohkan:
Kedua, kami berhasil di level server aplikasi (jika tidak memungkinkan) untuk juga menghindari pemrograman karena pembuatan kode - tombol yang sama dengan yang Anda contohkan: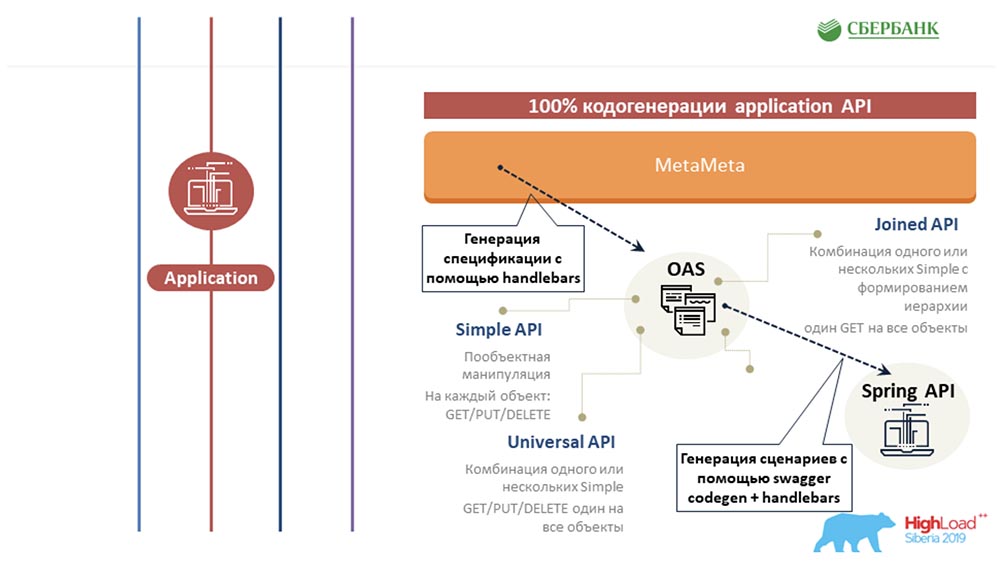 AC: - Kami mencoba memperluas pendekatan yang sama berdasarkan metadata ke area lain, ke area pengujian. Kami juga menulis template sekali untuk beberapa objek, menyisipkan tag di sana. Dan ketika templat ini dijalankan di sepanjang metadata, ia menghasilkan lembar jadi dengan semua skenario pengujian, yaitu, pada kenyataannya, kami menutup semua objek dengan pengujian.
AC: - Kami mencoba memperluas pendekatan yang sama berdasarkan metadata ke area lain, ke area pengujian. Kami juga menulis template sekali untuk beberapa objek, menyisipkan tag di sana. Dan ketika templat ini dijalankan di sepanjang metadata, ia menghasilkan lembar jadi dengan semua skenario pengujian, yaitu, pada kenyataannya, kami menutup semua objek dengan pengujian.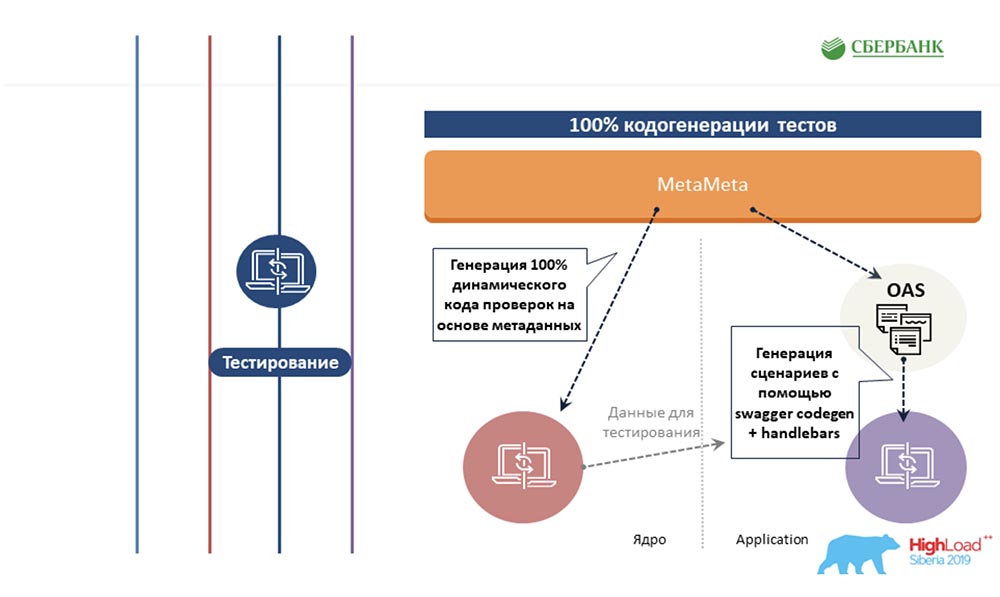 Selanjutnya adalah ceri di atas kue. Saya tahu sedikit orang yang suka mendokumentasikan apa yang mereka lakukan. Kami memecahkan rasa sakit ini berdasarkan metadata juga. Setelah kami menyiapkan templat dengan markup html, beri tag. Dan ketika kita melihat metadata, semua tag ini diganti dengan propertinya sesuai dengan objek.
Selanjutnya adalah ceri di atas kue. Saya tahu sedikit orang yang suka mendokumentasikan apa yang mereka lakukan. Kami memecahkan rasa sakit ini berdasarkan metadata juga. Setelah kami menyiapkan templat dengan markup html, beri tag. Dan ketika kita melihat metadata, semua tag ini diganti dengan propertinya sesuai dengan objek. Outputnya adalah halaman html selesai yang indah. Kemudian kami menerbitkan di Confluence, dan kami dapat memberikan pengguna kami dalam format yang dapat dibaca manusia sehingga mereka dapat melihat apa yang kami miliki dalam sistem, cara bekerja dengannya, beberapa deskripsi minimal, nilai yang dapat diterima, properti yang diperlukan, kunci ... Mereka semua dapat melakukan ini lihat dan cukup mudah mengetahuinya.Sebagai hasilnya, kami memiliki empat poin utama, dan pendekatan ini disebut MDA (Model Driven Architecture). Untuk beberapa alasan, ini diterjemahkan sebagai "arsitektur model-driven," meskipun saya akan menyebutnya "metode pengembangan perangkat lunak."
Outputnya adalah halaman html selesai yang indah. Kemudian kami menerbitkan di Confluence, dan kami dapat memberikan pengguna kami dalam format yang dapat dibaca manusia sehingga mereka dapat melihat apa yang kami miliki dalam sistem, cara bekerja dengannya, beberapa deskripsi minimal, nilai yang dapat diterima, properti yang diperlukan, kunci ... Mereka semua dapat melakukan ini lihat dan cukup mudah mengetahuinya.Sebagai hasilnya, kami memiliki empat poin utama, dan pendekatan ini disebut MDA (Model Driven Architecture). Untuk beberapa alasan, ini diterjemahkan sebagai "arsitektur model-driven," meskipun saya akan menyebutnya "metode pengembangan perangkat lunak." Apa intinya? Anda membuat model, menyetujui aturan tertentu. Kemudian Anda membuat pola transformasi sekali model ini dalam beberapa bahasa pemrograman yang tersedia untuk Anda. Semua ini berfungsi untuk mengubah objek lama, untuk menambahkan yang baru. Anda menulis kode sekali dan tidak lagi repot.SC: - Saya dengan jujur menunggu seluruh laporan ketika Anda menjawab pertanyaan ini. Mari beralih ke slide favorit saya.
Apa intinya? Anda membuat model, menyetujui aturan tertentu. Kemudian Anda membuat pola transformasi sekali model ini dalam beberapa bahasa pemrograman yang tersedia untuk Anda. Semua ini berfungsi untuk mengubah objek lama, untuk menambahkan yang baru. Anda menulis kode sekali dan tidak lagi repot.SC: - Saya dengan jujur menunggu seluruh laporan ketika Anda menjawab pertanyaan ini. Mari beralih ke slide favorit saya.Keputusan. Proses. Sebelum
AC: - “Prosesnya. Sebelum ”- ini adalah kebanggaan kami, karena kami sering memprogram, hampir tidak makan apa pun - kami sangat jahat. Saya harus melakukan semua 5 langkah ini untuk setiap objek: Itu sangat sedih dan kami membutuhkan banyak waktu. Sekarang kami telah mengurangi rantai makanan ini menjadi tiga tautan, yang paling penting adalah membuat objek dengan benar, dan tidak lebih:
Itu sangat sedih dan kami membutuhkan banyak waktu. Sekarang kami telah mengurangi rantai makanan ini menjadi tiga tautan, yang paling penting adalah membuat objek dengan benar, dan tidak lebih: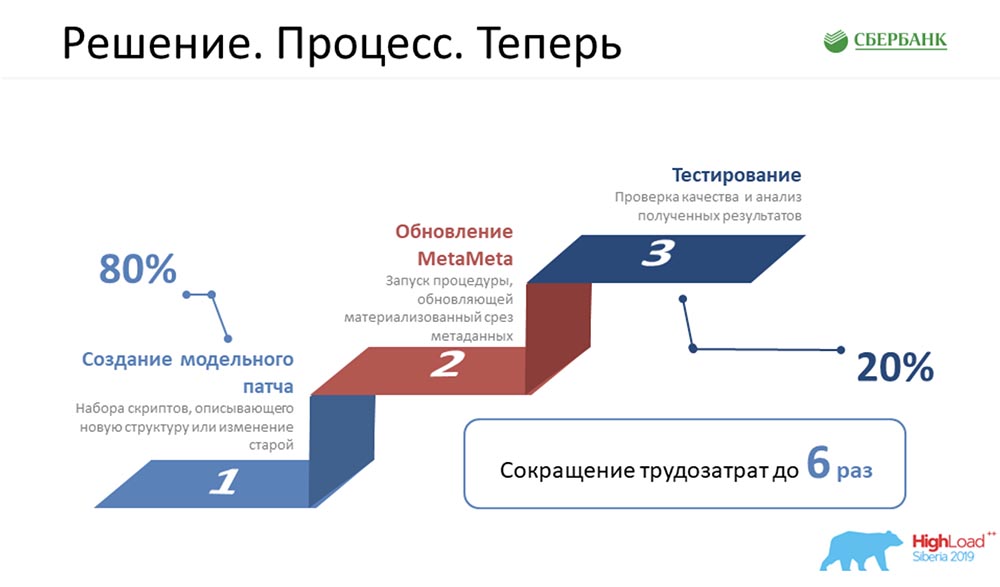 MetaMeta diluncurkan oleh sebuah tombol (pembaruan), lalu pengujian. Kami sedang mencari untuk memastikan bahwa tidak ada yang jatuh dari kami, karena kami baru-baru ini mulai menerapkan pendekatan ini. Kami mencoba mengendalikan seluruh proses ini.Menurut perkiraan, semua biaya tenaga kerja kami untuk pengembangan semua perangkat lunak kami telah berkurang sebanyak 6 kali.SC:- Saya ingin dengan tulus mengatakan dari diri sendiri bahwa angka 6 tidak meledak, bahkan konservatif. Bahkan, efisiensinya bahkan lebih tinggi.
MetaMeta diluncurkan oleh sebuah tombol (pembaruan), lalu pengujian. Kami sedang mencari untuk memastikan bahwa tidak ada yang jatuh dari kami, karena kami baru-baru ini mulai menerapkan pendekatan ini. Kami mencoba mengendalikan seluruh proses ini.Menurut perkiraan, semua biaya tenaga kerja kami untuk pengembangan semua perangkat lunak kami telah berkurang sebanyak 6 kali.SC:- Saya ingin dengan tulus mengatakan dari diri sendiri bahwa angka 6 tidak meledak, bahkan konservatif. Bahkan, efisiensinya bahkan lebih tinggi.Rencana masa depan
Anda bertanya di akhir laporan untuk memikirkan rencana kami. Pertama-tama, tampaknya kita harus mencapai tidak hanya solusi yang lengkap, tetapi teralienasi dan kotak. Teknologi ini dapat diterapkan di suatu tempat di dekatnya, jika perlu. Saya ingin mencapai produk jadi yang akan dikembangkan, dan yang dapat kami tawarkan atas nama Sberbank.Tentu saja, jika kita berbicara tentang tugas-tugas mendesak, mereka semua ditampilkan pada slide dengan peluru. Terlepas dari optimasi yang kami terima, beban di tim masih cukup serius. Saya tidak bisa mengatakan dengan pasti dari kuartal mana kita bisa beralih ke implementasi langkah-langkah ini.Nomor 6 dan kasus yang dibawa Nastya - mereka jujur. Itu benar-benar pada hari Jumat, ketika kami perlu mendapatkan dokumen (pesawat, perjalanan, dll.). Tim yang berdekatan dijadwalkan untuk pengujian pada hari Senin, dan kami harus melepaskan tambalan ini, bukan untuk mengatur orang-orang. Berhasil! Ini adalah kasus nyata.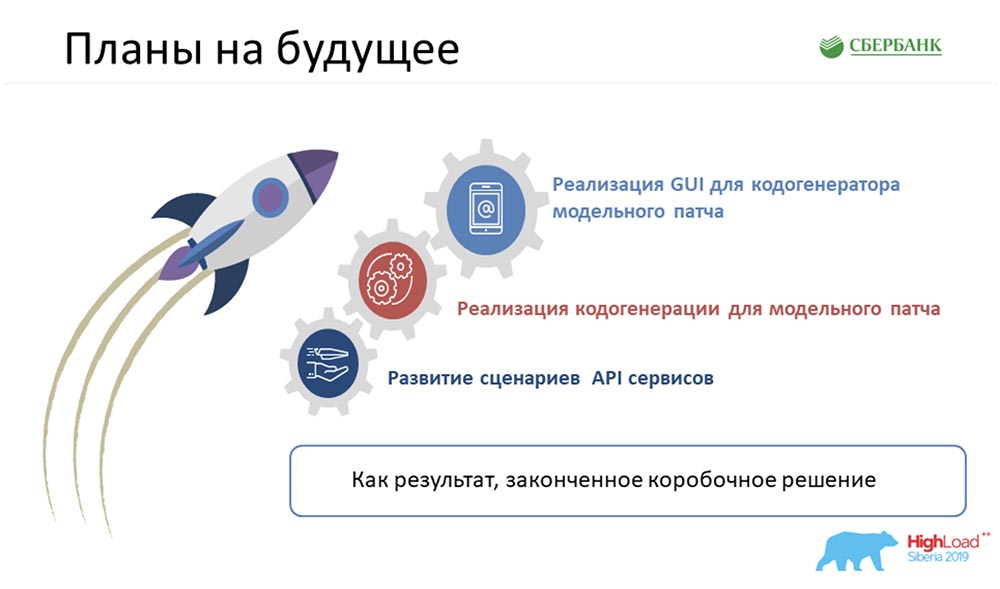 Saya akan senang jika ini bisa berguna bagi Anda. Jika Anda memiliki pertanyaan, kami tersedia. Dan setelah laporan, ada juga waktu di sini. Meminta. Kami akan dengan senang hati membantu Anda!AC:- Memang, pendekatan ini, saya pikir, dapat mulai digunakan oleh semua orang. Tidak harus dalam bentuk kami (kami terlibat dalam manajemen metadata). Ini bisa menjadi sistem kontrol apa pun. Yang perlu Anda miliki hanyalah pandangan relasional, ambil metadata dari sana, pahami beberapa mesin templat, dan pahami beberapa bahasa pemrograman (cara kerjanya).Semua alat ini berada dalam domain publik - Anda sudah dapat mulai googling dan memahami cara menggunakannya. Saya yakin bahwa menggunakannya akan membuat hidup Anda lebih mudah, lebih baik, dan umumnya meluangkan waktu untuk tugas-tugas baru, ambisius, dan keren. Terima kasih!
Saya akan senang jika ini bisa berguna bagi Anda. Jika Anda memiliki pertanyaan, kami tersedia. Dan setelah laporan, ada juga waktu di sini. Meminta. Kami akan dengan senang hati membantu Anda!AC:- Memang, pendekatan ini, saya pikir, dapat mulai digunakan oleh semua orang. Tidak harus dalam bentuk kami (kami terlibat dalam manajemen metadata). Ini bisa menjadi sistem kontrol apa pun. Yang perlu Anda miliki hanyalah pandangan relasional, ambil metadata dari sana, pahami beberapa mesin templat, dan pahami beberapa bahasa pemrograman (cara kerjanya).Semua alat ini berada dalam domain publik - Anda sudah dapat mulai googling dan memahami cara menggunakannya. Saya yakin bahwa menggunakannya akan membuat hidup Anda lebih mudah, lebih baik, dan umumnya meluangkan waktu untuk tugas-tugas baru, ambisius, dan keren. Terima kasih!Pertanyaan
Pertanyaan dari audiens (selanjutnya - A): - Apakah saya mengerti benar bahwa semuanya ditumpuk karena Anda menggunakan database relasional? Tampak bagi saya bahwa jika Anda melihat ke arah database berorientasi dokumen, semua solusi ini akan jauh lebih mudah bagi Anda daripada yang saya lihat sekarang.SC: - Tidak juga. Apa yang kita mulai dengan ketika kita berbicara tentang orang-orang yang bekerja di tingkat glosarium dan laba-laba yang pergi ke pesta, membaca cerita-cerita ini dan memeriksa - memang, meja dengan bidang yang bertanggung jawab untuk istilah glosarium ini terjadi di pesta . Mereka mengatakan dari layanan kami: "Kawan, Anda harus memiliki REST API. Bagaimana Anda melakukannya adalah masalah Anda. Berikut adalah daftar teknologi yang diizinkan - gunakan sesuatu dari daftar ini (inilah yang dapat kita gunakan di Sberbank). "Ini adalah tingkat solusi kami, arsitektur terapan. Bagi kami, sebaliknya, lebih mudah melakukan ini bukan pada hubungan. Mengapa? Saya akan memberikan contoh, satu dari banyak ... Misalnya, saya perlu memastikan, ketika saya menulis bidang, bahwa itu tidak merujuk di mana saja ke tabel yang tidak ada. Saya hanya melakukan kunci asing di database dan saya tidak khawatir. Saya tidak menulis garis - dia tidak akan membiarkan saya membuat catatan ini. Dan ada banyak contoh seperti itu!Di sini kita lebih baik berbicara tentang sesuatu yang lain. Cerita yang lebih rumit: kami akan merilis model patch dengan set data penyesuaian / sertifikasi, dan ada 6 objek di sana. Dan tak terhindarkan, bagi Anda untuk menyediakan set API yang lembut ini, Anda perlu tiga bulan untuk bekerja (begitu saja). Kami akan membutuhkan waktu satu setengah minggu. Tanpa menerapkan teknologi ini, mustahil untuk bertahan dalam kondisi ini. Kami hanya tidak akan memberikan tingkat layanan seperti itu!Ini dimungkinkan jika Anda membangun produksi sedemikian rupa sehingga Anda memiliki tambalan model (objek baru), tombol "Lakukan semuanya dengan baik" dan beberapa perangkat lunak yang akan menguji dalam mode emulasi klien. Menghasilkan yang baru, yang lama tidak jatuh - ini harus dicapai, tetapi bagaimana - itu adalah pilihan tim. A: - Saya punya pertanyaan kedua. Dan apa contoh penggunaan dari kehidupan? Saya mengerti bahwa secara teori sepertinya Anda setidaknya dapat menggambarkan seluruh dunia dengan objek META_META Anda ... Tetapi dalam kehidupan, bagaimana Anda menggunakannya? Menilai dari bagaimana itu diterapkan (semuanya harus dimasukkan satu sama lain), itu harus melambat!SC:- Ngomong-ngomong, tidak (mengejutkan)! Aplikasi lain dari kisah ini adalah pembuat kode. Di sinilah beberapa etalase, penyimpanan dibangun, dan Anda ETL, Anda mencoba memarkir semua opsi yang memungkinkan ke sembilan templat, sembilan mesin templat yang dijelaskan sebelumnya. Menggunakan metadata, Anda menggambarkan transformasi ini, menggunakan templat ini sebagai bertopik. Selanjutnya, mesin ini tanpa pemrograman memberikan kode ETL, menghasilkan kode berdasarkan metadata. Saya percaya bahwa ada juga teknologi seperti itu, pendekatan akan sesuai dan benar.A: - Saya mengandalkan contoh yang lebih spesifik.A: - Katakan, tolong, ada tertulis dalam persyaratan Anda bahwa Anda perlu melakukan pertanyaan struktural yang kompleks (Bergabunglah dan sejenisnya). Bahasa apa itu diterapkan, atau apakah Anda menggambarkannya entah bagaimana secara logis?SC:- Akses melalui REST API, paling sering itu Java, meskipun bisa bahasa apa saja. Layanan kami telah dipublikasikan (dhttps, tanyakan https - Anda akan mendapatkan JSON kembali). Potongan kode yang kami tunjukkan adalah SQL. Untuk memahami urutan apa yang harus diproses, kami melakukan penyetelan SQL atas kamus DBMS dan memarkirnya dalam skema terpisah dalam bentuk representasi terwujud. Dengan demikian, ketika tambalan model dilepaskan, tombol “Refresh materialized view” diklik (+ bidang muncul). Tapi sebenarnya kode kami adalah Java dan Oracle.AC:- Perlu dicatat di sini bahwa kami memutuskan untuk membagi bidang tanggung jawab. Kami dengan sengaja mentransfer semua keajaiban ke kernel, dan Aplikasi hanya menginterpretasikan jawaban ini dengan benar. Yaitu, mekanisme Bergabung itu sendiri terjadi di kernel, dan Java hanya kompeten mencerai-beraikan semuanya di pohon dan memberikan pengguna hasil akhir.A: - Dan apa yang dilakukan Code Gens - apakah Anda sudah menuliskan logika kueri kompleks di sana? Atau apakah itu dilakukan di sisi klien? Kita perlu memahami sisi mana yang sedang dideskripsikan ... Mereka mempresentasikan, ternyata, Kode Gen, di mana perlu untuk secara akurat menggambarkan dalam beberapa struktur: misalnya, saya ingin API saya untuk belajar ini dan itu Bergabung, melalui daftar; lalu katakan apakah ada di dalam atau tidak ... - pertanyaan kompleks sudah cukup. Pada tahap apa ini ditulis?SC:- Jika saya memahami pertanyaan Anda dengan benar, ini persis seperti cerita ketika pelanggan kami, pelanggan kami (ini adalah tim di dalam kernel, platform) mengatakan: "Dengar, kami tidak ingin memprogram - berikan kami ini." "Ini dia" semuanya dilakukan pada intinya. Inti - intinya apa? 80 persen, mungkin 90 - ini adalah generasi kode dinamis, teks yang akan dipanggil dari bawah PL / SQL, tetapi beralih ke database. Di sana, bahkan pada waktunya, baris ini dihasilkan lebih lama, kemudian database diakses (misalnya, permintaan Gabung), mengembalikan, membungkusnya dalam JSON, dan menampilkannya secara terbalik. Selanjutnya, Jawa mengubah semua ini menjadi kontrak, yang tergantung pada strukturnya.DAN:- Mengungkapkan solusi pembaruan batch. Dan bagaimana jaminan pengiriman dibuat - apakah seluruh paket tiba, atau bagian dari paket? Apakah mereka memiliki cachend tertentu? Dan bagaimana memastikan bahwa tidak ada layanan yang jatuh, atau struktur data memiliki jenis koherensi, sehingga tidak ada kesalahan?SC: - Kami memiliki protokol - ada dua mode pembaruan. Di salah satunya, Anda dapat mengatur bendera "Terapkan semua yang Anda bisa." Ada beberapa perangkat lunak yang dikonversi Excel ke JSON - mungkin ada 10 ribu baris. Dan Anda, sebenarnya, dua baris bisa tidak valid (kesalahan). Dan Anda mengatakan: "Terapkan semua yang Anda bisa"; atau "Hanya berlaku jika keseluruhan cerita tidak akan memiliki satu kesalahan." Di sana, status integral akan dikembalikan, misalnya. Faktanya, sebuah insert dibuat ke basis data, tetapi commit tidak dipanggil.Dalam hal terjadi kesalahan - itu disebut rollback, itu ada dalam protokol; Anda tetap mendapatkan protokolnya. Anda mendapatkan status di setiap baris, dan Anda memiliki pengidentifikasi di bidang terpisah - baik angka (id objek), atau beberapa kunci alternatif, atau keduanya. Protokol memungkinkan untuk memahami apa yang terjadi pada permintaan saya.AC: - Pengguna sendiri menunjukkan di mana opsi yang harus ia pindahkan. Kami meneruskan parameter ini ke sisi inti, dan inti sudah menghasilkan semua keajaiban, memberi kami jawabannya, dan kami menafsirkannya.DAN:"Kenapa kamu tidak menggunakan kompiler ekspresi bawaan yang akan membantu mendefinisikan aturan?" Misalkan kita memiliki templat, saya ngeblog dalam beberapa bahasa (diketik / tidak diketik bahasa skrip); menulis: "Saya ingin daftar." Melewati fragmen ini sehingga beberapa pemroses kode akan mengunyah semuanya, memasukkannya ke dalam basis data NoSQL, seperti yang disarankan dalam pertanyaan pertama ... Namun, tidak jelas mengapa basis data relasional dan mengapa dan bagaimana menangani redundansi data? Seorang pria mengirimi Anda templat dengan satu miliar sampah ... Bagaimana perjanjian ini tercapai ketika seseorang membutuhkannya?
A: - Saya punya pertanyaan kedua. Dan apa contoh penggunaan dari kehidupan? Saya mengerti bahwa secara teori sepertinya Anda setidaknya dapat menggambarkan seluruh dunia dengan objek META_META Anda ... Tetapi dalam kehidupan, bagaimana Anda menggunakannya? Menilai dari bagaimana itu diterapkan (semuanya harus dimasukkan satu sama lain), itu harus melambat!SC:- Ngomong-ngomong, tidak (mengejutkan)! Aplikasi lain dari kisah ini adalah pembuat kode. Di sinilah beberapa etalase, penyimpanan dibangun, dan Anda ETL, Anda mencoba memarkir semua opsi yang memungkinkan ke sembilan templat, sembilan mesin templat yang dijelaskan sebelumnya. Menggunakan metadata, Anda menggambarkan transformasi ini, menggunakan templat ini sebagai bertopik. Selanjutnya, mesin ini tanpa pemrograman memberikan kode ETL, menghasilkan kode berdasarkan metadata. Saya percaya bahwa ada juga teknologi seperti itu, pendekatan akan sesuai dan benar.A: - Saya mengandalkan contoh yang lebih spesifik.A: - Katakan, tolong, ada tertulis dalam persyaratan Anda bahwa Anda perlu melakukan pertanyaan struktural yang kompleks (Bergabunglah dan sejenisnya). Bahasa apa itu diterapkan, atau apakah Anda menggambarkannya entah bagaimana secara logis?SC:- Akses melalui REST API, paling sering itu Java, meskipun bisa bahasa apa saja. Layanan kami telah dipublikasikan (dhttps, tanyakan https - Anda akan mendapatkan JSON kembali). Potongan kode yang kami tunjukkan adalah SQL. Untuk memahami urutan apa yang harus diproses, kami melakukan penyetelan SQL atas kamus DBMS dan memarkirnya dalam skema terpisah dalam bentuk representasi terwujud. Dengan demikian, ketika tambalan model dilepaskan, tombol “Refresh materialized view” diklik (+ bidang muncul). Tapi sebenarnya kode kami adalah Java dan Oracle.AC:- Perlu dicatat di sini bahwa kami memutuskan untuk membagi bidang tanggung jawab. Kami dengan sengaja mentransfer semua keajaiban ke kernel, dan Aplikasi hanya menginterpretasikan jawaban ini dengan benar. Yaitu, mekanisme Bergabung itu sendiri terjadi di kernel, dan Java hanya kompeten mencerai-beraikan semuanya di pohon dan memberikan pengguna hasil akhir.A: - Dan apa yang dilakukan Code Gens - apakah Anda sudah menuliskan logika kueri kompleks di sana? Atau apakah itu dilakukan di sisi klien? Kita perlu memahami sisi mana yang sedang dideskripsikan ... Mereka mempresentasikan, ternyata, Kode Gen, di mana perlu untuk secara akurat menggambarkan dalam beberapa struktur: misalnya, saya ingin API saya untuk belajar ini dan itu Bergabung, melalui daftar; lalu katakan apakah ada di dalam atau tidak ... - pertanyaan kompleks sudah cukup. Pada tahap apa ini ditulis?SC:- Jika saya memahami pertanyaan Anda dengan benar, ini persis seperti cerita ketika pelanggan kami, pelanggan kami (ini adalah tim di dalam kernel, platform) mengatakan: "Dengar, kami tidak ingin memprogram - berikan kami ini." "Ini dia" semuanya dilakukan pada intinya. Inti - intinya apa? 80 persen, mungkin 90 - ini adalah generasi kode dinamis, teks yang akan dipanggil dari bawah PL / SQL, tetapi beralih ke database. Di sana, bahkan pada waktunya, baris ini dihasilkan lebih lama, kemudian database diakses (misalnya, permintaan Gabung), mengembalikan, membungkusnya dalam JSON, dan menampilkannya secara terbalik. Selanjutnya, Jawa mengubah semua ini menjadi kontrak, yang tergantung pada strukturnya.DAN:- Mengungkapkan solusi pembaruan batch. Dan bagaimana jaminan pengiriman dibuat - apakah seluruh paket tiba, atau bagian dari paket? Apakah mereka memiliki cachend tertentu? Dan bagaimana memastikan bahwa tidak ada layanan yang jatuh, atau struktur data memiliki jenis koherensi, sehingga tidak ada kesalahan?SC: - Kami memiliki protokol - ada dua mode pembaruan. Di salah satunya, Anda dapat mengatur bendera "Terapkan semua yang Anda bisa." Ada beberapa perangkat lunak yang dikonversi Excel ke JSON - mungkin ada 10 ribu baris. Dan Anda, sebenarnya, dua baris bisa tidak valid (kesalahan). Dan Anda mengatakan: "Terapkan semua yang Anda bisa"; atau "Hanya berlaku jika keseluruhan cerita tidak akan memiliki satu kesalahan." Di sana, status integral akan dikembalikan, misalnya. Faktanya, sebuah insert dibuat ke basis data, tetapi commit tidak dipanggil.Dalam hal terjadi kesalahan - itu disebut rollback, itu ada dalam protokol; Anda tetap mendapatkan protokolnya. Anda mendapatkan status di setiap baris, dan Anda memiliki pengidentifikasi di bidang terpisah - baik angka (id objek), atau beberapa kunci alternatif, atau keduanya. Protokol memungkinkan untuk memahami apa yang terjadi pada permintaan saya.AC: - Pengguna sendiri menunjukkan di mana opsi yang harus ia pindahkan. Kami meneruskan parameter ini ke sisi inti, dan inti sudah menghasilkan semua keajaiban, memberi kami jawabannya, dan kami menafsirkannya.DAN:"Kenapa kamu tidak menggunakan kompiler ekspresi bawaan yang akan membantu mendefinisikan aturan?" Misalkan kita memiliki templat, saya ngeblog dalam beberapa bahasa (diketik / tidak diketik bahasa skrip); menulis: "Saya ingin daftar." Melewati fragmen ini sehingga beberapa pemroses kode akan mengunyah semuanya, memasukkannya ke dalam basis data NoSQL, seperti yang disarankan dalam pertanyaan pertama ... Namun, tidak jelas mengapa basis data relasional dan mengapa dan bagaimana menangani redundansi data? Seorang pria mengirimi Anda templat dengan satu miliar sampah ... Bagaimana perjanjian ini tercapai ketika seseorang membutuhkannya? SC:"Aku akan mencoba menjawab ketika aku mengerti pertanyaannya." Sebagian besar program berkomunikasi dengan kami sekarang. Ketika mekanisme interaksi integrasi diatur, tidak banyak orang berkomunikasi dengan kami sebagai program. Tentu saja ada kasus ketika orang mengirim la exelnik untuk tumpahan utama: kami membuat JSON dari mereka, mengunggah, tetapi ini lebih merupakan pengaturan utama.Dan kami memiliki mode ketika Anda mengirim 5.000 baris, di mana 4.900 dikembalikan dengan status "Saya memproses, saya tidak menemukan perubahan, saya tidak melakukan apa pun." Tetapi ini tercermin dalam protokol dan tidak ada kesalahan. Ini adalah redundansi di satu sisi.Kami memiliki seluruh cerita ini disimpan dalam perkiraan ke bentuk normal ketiga, yang tidak menyiratkan redundansi, berbeda dengan beberapa struktur denormalized yang digunakan, misalnya, untuk jendela toko.Mengapa relasional? Generator kode bekerja untuk kita, dan sensitivitas terhadap kualitas metadata dalam sistem sangat tinggi. Dan ketika kita memiliki kesempatan untuk mengkonfigurasi kunci asing menggunakan relasional dan memastikan ... Catatan tidak akan berbaring - akan ada kesalahan jika ada sesuatu yang salah dalam sistem, jika terjadi kegagalan. Dan kami ingin, tetapi kami tidak mencari pekerjaan tambahan ...Kami tidak diukur karena berapa banyak baris kode yang kami tulis: "Sudahkah Anda memecahkan masalah layanan dan stabilitasnya atau tidak?" Anda mungkin tidak menulis sama sekali - hal utama adalah itu berfungsi. Dalam hal ini, itu hanya lebih cepat dan lebih nyaman bagi kita untuk melakukannya.Saya tidak mengambil vendor tertentu, tetapi basis data relasional telah berkembang selama 20 tahun! Bukan hanya seperti itu. Ambil, misalnya, Word atau Excel di Windows - Anda tidak memprogram kode di sana, yang dengan bantuan "Assembler" mengakses dan menggerakkan kepala hard drive untuk menulis file ... Hal yang sama ada di sini! Kami hanya menggunakan perkembangan yang ada di RDBMS, dan itu nyaman.AC:- Untuk memastikan semua persyaratan kami, integritas metadata penting bagi kami. Dan di sini kami mungkin juga ingin menyampaikan bahwa kami tidak harus bergantung sama sekali - kami menggunakan relasional, bukan relasional ... Inti dari laporan ini adalah Anda juga dapat mulai menggunakannya. Tidak harus berdasarkan relasional, karena yang pasti orang lain juga memiliki semacam metadata yang dapat dikumpulkan: setidaknya, tabel, bidang apa, dan ini semua diprogram.A: - Sistem ini melibatkan beberapa penggunaan. Bagaimana Anda merencanakan (atau telah melakukan) pengiriman data ke sistem Anda? Jelas bahwa semacam memperbarui struktur data terjadi di toko. Bagaimana ini semua terjadi padamu? Secara otomatis, atau agen Anda berdiri, atau apakah Anda membengkokkan semua tim pengembangan sehingga Anda menerima pembaruan?AC:- Kami memiliki dua mode operasi. Salah satunya adalah ketika pengembang sendiri atau tim sendiri dipaksa untuk memasukkan metadata ke dalam sistem melalui layanan REST. Mode operasi kedua adalah "penyedot debu" yang sama: kita sendiri masuk ke lingkungan dan mengambil semua kemungkinan metadata dari sana. Kami melakukan ini sekali sehari, dan hanya memeriksa apa yang dikirim pengembang kepada kami.
SC:"Aku akan mencoba menjawab ketika aku mengerti pertanyaannya." Sebagian besar program berkomunikasi dengan kami sekarang. Ketika mekanisme interaksi integrasi diatur, tidak banyak orang berkomunikasi dengan kami sebagai program. Tentu saja ada kasus ketika orang mengirim la exelnik untuk tumpahan utama: kami membuat JSON dari mereka, mengunggah, tetapi ini lebih merupakan pengaturan utama.Dan kami memiliki mode ketika Anda mengirim 5.000 baris, di mana 4.900 dikembalikan dengan status "Saya memproses, saya tidak menemukan perubahan, saya tidak melakukan apa pun." Tetapi ini tercermin dalam protokol dan tidak ada kesalahan. Ini adalah redundansi di satu sisi.Kami memiliki seluruh cerita ini disimpan dalam perkiraan ke bentuk normal ketiga, yang tidak menyiratkan redundansi, berbeda dengan beberapa struktur denormalized yang digunakan, misalnya, untuk jendela toko.Mengapa relasional? Generator kode bekerja untuk kita, dan sensitivitas terhadap kualitas metadata dalam sistem sangat tinggi. Dan ketika kita memiliki kesempatan untuk mengkonfigurasi kunci asing menggunakan relasional dan memastikan ... Catatan tidak akan berbaring - akan ada kesalahan jika ada sesuatu yang salah dalam sistem, jika terjadi kegagalan. Dan kami ingin, tetapi kami tidak mencari pekerjaan tambahan ...Kami tidak diukur karena berapa banyak baris kode yang kami tulis: "Sudahkah Anda memecahkan masalah layanan dan stabilitasnya atau tidak?" Anda mungkin tidak menulis sama sekali - hal utama adalah itu berfungsi. Dalam hal ini, itu hanya lebih cepat dan lebih nyaman bagi kita untuk melakukannya.Saya tidak mengambil vendor tertentu, tetapi basis data relasional telah berkembang selama 20 tahun! Bukan hanya seperti itu. Ambil, misalnya, Word atau Excel di Windows - Anda tidak memprogram kode di sana, yang dengan bantuan "Assembler" mengakses dan menggerakkan kepala hard drive untuk menulis file ... Hal yang sama ada di sini! Kami hanya menggunakan perkembangan yang ada di RDBMS, dan itu nyaman.AC:- Untuk memastikan semua persyaratan kami, integritas metadata penting bagi kami. Dan di sini kami mungkin juga ingin menyampaikan bahwa kami tidak harus bergantung sama sekali - kami menggunakan relasional, bukan relasional ... Inti dari laporan ini adalah Anda juga dapat mulai menggunakannya. Tidak harus berdasarkan relasional, karena yang pasti orang lain juga memiliki semacam metadata yang dapat dikumpulkan: setidaknya, tabel, bidang apa, dan ini semua diprogram.A: - Sistem ini melibatkan beberapa penggunaan. Bagaimana Anda merencanakan (atau telah melakukan) pengiriman data ke sistem Anda? Jelas bahwa semacam memperbarui struktur data terjadi di toko. Bagaimana ini semua terjadi padamu? Secara otomatis, atau agen Anda berdiri, atau apakah Anda membengkokkan semua tim pengembangan sehingga Anda menerima pembaruan?AC:- Kami memiliki dua mode operasi. Salah satunya adalah ketika pengembang sendiri atau tim sendiri dipaksa untuk memasukkan metadata ke dalam sistem melalui layanan REST. Mode operasi kedua adalah "penyedot debu" yang sama: kita sendiri masuk ke lingkungan dan mengambil semua kemungkinan metadata dari sana. Kami melakukan ini sekali sehari, dan hanya memeriksa apa yang dikirim pengembang kepada kami. SC: - Dari empat level yang kami teliti, tiga level teratas (glosarium, model logis, model fisik) adalah kisah yang datang kepada kami secara default dalam mode Broker Metadata, dan kami adalah peserta pasif. Mereka memanggil kita, memberikan kita sesuatu, bertanya; tugas kita adalah memarkir secara konsisten. Meskipun ada kasus ketika kami membuat beberapa cerita dengan sumber daya tim, jika kami sangat tertarik memiliki metadata ini.Seperti yang dikatakan Nastya, mengenai cerita dengan kebalikannya (dalam jargon teknis kami menyebutnya "penyedot debu"), kami pergi ke lingkungan industri dan membaca beberapa data. Ada beberapa kasus berbeda - kami siap untuk membahas nanti, kami siap untuk menceritakan banyak kisah menarik.A: - Saya dari pusat teknologi keuangan. Saya melihat kata yang akrab di sana - DACUM utama. Platform kami memiliki metadata sendiri. Bagaimana kabarmu teman - langsung dengan tabel Oracle atau dengan metadata kami dalam kasus ini? Karena dalam kasus kami, berteman dengan tabel Oracle tidak sepenuhnya bersifat indikatif.SC:- Ada DACUM utama seperti tabel, yang berisi kabel. Ini bukan rahasia: ada dan ada produk yang bekerja pada cerita ini. Ini adalah salah satu sumber informasi dalam repositori. Ada beberapa jenis sistem yang merupakan penyedia data. Secara alami, ini adalah fokus perhatian kami dalam hal metadata, karena salah satu kisah yang harus kami tunjukkan dan belum menyentuh sama sekali di sini (karena topik laporan) adalah garis keturunan Data. Anda harus menunjukkan dari mana riwayat data bidang ini berasal. Dalam pengertian ini, jika ada tabel DACUM utama, kita tahu tentang itu.
SC: - Dari empat level yang kami teliti, tiga level teratas (glosarium, model logis, model fisik) adalah kisah yang datang kepada kami secara default dalam mode Broker Metadata, dan kami adalah peserta pasif. Mereka memanggil kita, memberikan kita sesuatu, bertanya; tugas kita adalah memarkir secara konsisten. Meskipun ada kasus ketika kami membuat beberapa cerita dengan sumber daya tim, jika kami sangat tertarik memiliki metadata ini.Seperti yang dikatakan Nastya, mengenai cerita dengan kebalikannya (dalam jargon teknis kami menyebutnya "penyedot debu"), kami pergi ke lingkungan industri dan membaca beberapa data. Ada beberapa kasus berbeda - kami siap untuk membahas nanti, kami siap untuk menceritakan banyak kisah menarik.A: - Saya dari pusat teknologi keuangan. Saya melihat kata yang akrab di sana - DACUM utama. Platform kami memiliki metadata sendiri. Bagaimana kabarmu teman - langsung dengan tabel Oracle atau dengan metadata kami dalam kasus ini? Karena dalam kasus kami, berteman dengan tabel Oracle tidak sepenuhnya bersifat indikatif.SC:- Ada DACUM utama seperti tabel, yang berisi kabel. Ini bukan rahasia: ada dan ada produk yang bekerja pada cerita ini. Ini adalah salah satu sumber informasi dalam repositori. Ada beberapa jenis sistem yang merupakan penyedia data. Secara alami, ini adalah fokus perhatian kami dalam hal metadata, karena salah satu kisah yang harus kami tunjukkan dan belum menyentuh sama sekali di sini (karena topik laporan) adalah garis keturunan Data. Anda harus menunjukkan dari mana riwayat data bidang ini berasal. Dalam pengertian ini, jika ada tabel DACUM utama, kita tahu tentang itu.Sedikit iklan :)
Terima kasih untuk tetap bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda, cloud VPS untuk pengembang mulai $ 4,99 , analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang Cara Membangun Infrastruktur Bldg. kelas c menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen? Source: https://habr.com/ru/post/undefined/
All Articles