 Ketika masalah analitik melampaui alat yang dibuat sebelumnya, mungkin sudah waktunya bagi Anda untuk memilih database untuk analitik. Anda tidak boleh menulis skrip pertanyaan ke database yang berfungsi, karena Anda dapat mengubah urutan data dan, kemungkinan besar, memperlambat aplikasi.Anda juga dapat secara tidak sengaja menghapus informasi penting jika analis atau insinyur bekerja di sana.Untuk analisis, Anda memerlukan jenis database yang terpisah. Tapi yang mana yang benar?Dalam posting ini kami akan mempertimbangkan penawaran dan praktik terbaik untuk perusahaan biasa yang baru mulai bekerja. Pengaturan mana pun yang Anda pilih, Anda dapat menemukan kompromi di masa depan untuk meningkatkan kinerja atas apa yang kita diskusikan di sini.Bekerja dengan sejumlah besar klien, kami menemukan bahwa kriteria paling penting yang harus dipertimbangkan adalah:
Ketika masalah analitik melampaui alat yang dibuat sebelumnya, mungkin sudah waktunya bagi Anda untuk memilih database untuk analitik. Anda tidak boleh menulis skrip pertanyaan ke database yang berfungsi, karena Anda dapat mengubah urutan data dan, kemungkinan besar, memperlambat aplikasi.Anda juga dapat secara tidak sengaja menghapus informasi penting jika analis atau insinyur bekerja di sana.Untuk analisis, Anda memerlukan jenis database yang terpisah. Tapi yang mana yang benar?Dalam posting ini kami akan mempertimbangkan penawaran dan praktik terbaik untuk perusahaan biasa yang baru mulai bekerja. Pengaturan mana pun yang Anda pilih, Anda dapat menemukan kompromi di masa depan untuk meningkatkan kinerja atas apa yang kita diskusikan di sini.Bekerja dengan sejumlah besar klien, kami menemukan bahwa kriteria paling penting yang harus dipertimbangkan adalah:- Jenis data yang dianalisis
- Berapa banyak data yang Anda miliki?
- Fokus tim teknik Anda
- Seberapa cepat Anda memerlukan informasi?
Jenis data apa yang Anda analisis?
Pikirkan tentang data yang ingin Anda analisis. Apakah mereka cocok dalam baris dan kolom seperti lembar kerja Excel yang besar? Atau akan lebih masuk akal jika Anda memasukkannya ke dalam dokumen Word?Jika Anda menjawab Excel, database relasional seperti Postgres, MySQL, Amazon Redshift atau BigQuery akan sesuai dengan kebutuhan Anda. Basis data relasional terstruktur ini sangat bagus ketika Anda tahu persis data apa yang akan Anda terima dan bagaimana mereka saling berhubungan - pada dasarnya, bagaimana baris dan kolom saling berhubungan. Untuk sebagian besar jenis analisis pengguna, basis data relasional bekerja dengan baik. Atribut pengguna seperti nama, email, dan paket tagihan sangat cocok dengan tabel, seperti acara pengguna dan propertinya .Di sisi lain, jika data Anda lebih cocok di selembar kertas, Anda harus merujuk ke database non-relasional (NoSQL) seperti Hadoop atau Mongo.Database non-relasional dicirikan oleh sejumlah besar nilai privat (jutaan) data semi-terstruktur. Contoh klasik data semi-terstruktur adalah teks seperti email, buku dan jejaring sosial, data audiovisual, dan data geografis. Jika Anda melakukan banyak penambangan teks, pemrosesan bahasa, atau pemrosesan gambar, kemungkinan besar Anda perlu menggunakan penyimpanan data non-relasional.
Berapa banyak data yang Anda hadapi?
Pertanyaan selanjutnya untuk bertanya pada diri sendiri adalah berapa banyak data yang Anda hadapi. Semakin banyak data yang Anda miliki, semakin berguna basis data non-relasional, karena tidak akan memberlakukan batasan pada data yang masuk, yang akan memungkinkan Anda untuk menulis ke basis data lebih cepat. Ini bukan pembatasan ketat, dan masing-masing dapat memproses lebih banyak atau lebih sedikit data tergantung pada berbagai faktor, tetapi kami menemukan bahwa masing-masing database berfungsi dengan baik dalam batas-batas ini.Jika Anda memiliki kurang dari 1 TB data, maka dengan Postgres Anda akan mendapatkan kinerja yang baik. Tetapi melambat sekitar 6 TB. Jika Anda menyukai MySQL tetapi membutuhkan skala yang sedikit lebih besar, Aurora (versi Amazon sendiri) dapat mencapai 64 TB. Untuk ukuran petabyte, Amazon Redshift biasanya merupakan pilihan yang baik karena dioptimalkan untuk analisis hingga 2PB. Untuk pemrosesan paralel atau bahkan data MOAR, mungkin sudah saatnya untuk melihat Hadoop.Namun, AWS memberi tahu kami bahwa mereka menjalankan Amazon.com di Redshift, jadi jika Anda memiliki tim DBA kelas satu, Anda mungkin dapat meningkatkan skala melampaui "batas" 2PB.
Ini bukan pembatasan ketat, dan masing-masing dapat memproses lebih banyak atau lebih sedikit data tergantung pada berbagai faktor, tetapi kami menemukan bahwa masing-masing database berfungsi dengan baik dalam batas-batas ini.Jika Anda memiliki kurang dari 1 TB data, maka dengan Postgres Anda akan mendapatkan kinerja yang baik. Tetapi melambat sekitar 6 TB. Jika Anda menyukai MySQL tetapi membutuhkan skala yang sedikit lebih besar, Aurora (versi Amazon sendiri) dapat mencapai 64 TB. Untuk ukuran petabyte, Amazon Redshift biasanya merupakan pilihan yang baik karena dioptimalkan untuk analisis hingga 2PB. Untuk pemrosesan paralel atau bahkan data MOAR, mungkin sudah saatnya untuk melihat Hadoop.Namun, AWS memberi tahu kami bahwa mereka menjalankan Amazon.com di Redshift, jadi jika Anda memiliki tim DBA kelas satu, Anda mungkin dapat meningkatkan skala melampaui "batas" 2PB.Apa yang menjadi fokus tim teknik Anda?
Ini adalah pertanyaan penting lain untuk Anda tanyakan pada diri sendiri ketika membahas basis data. Semakin kecil tim Anda secara keseluruhan, semakin besar kemungkinan insinyur Anda akan fokus terutama pada penciptaan produk, bukan pada pemrosesan data dan manajemen. Jumlah orang yang dapat Anda curahkan untuk proyek-proyek ini akan sangat memengaruhi opsi Anda.Dengan beberapa sumber daya teknik, Anda memiliki lebih banyak pilihan - Anda dapat pergi ke basis data relasional atau non-relasional. Database relasional membutuhkan waktu lebih sedikit daripada NoSQL.Jika Anda memiliki beberapa insinyur yang sedang mengerjakan instalasi, tetapi tidak dapat membawa siapa pun ke layanan, pilih sesuatu seperti Postgres , Google SQL (hosting MySQL opsional) atau Segment Warehouse(Redshift hosting) mungkin merupakan opsi yang lebih baik daripada Redshift, Aurora atau BigQuery, karena mereka memerlukan koreksi berkala terhadap pemrosesan data. Jika Anda memiliki lebih banyak waktu untuk diservis, memilih Redshift atau BigQuery akan memberikan pertanyaan yang lebih cepat dan berskala lebih besar.Database relasional memiliki keunggulan lain: Anda bisa menggunakan SQL untuk menanyakannya. SQL dikenal baik oleh analis dan insinyur, dan lebih mudah dipelajari daripada kebanyakan bahasa pemrograman.Di sisi lain, analitik data semi-terstruktur biasanya membutuhkan, setidaknya, pengalaman dalam pemrograman berorientasi objek, atau, lebih baik, pengalaman dalam menulis kode untuk bekerja dengan data besar. Bahkan dengan munculnya alat analisis seperti Hunkuntuk Hadoop atau Slamdata untuk MongoDB, Anda akan memerlukan analis atau spesialis data yang berpengalaman untuk menganalisis jenis-jenis database ini.Seberapa cepat Anda membutuhkan data ini?
Sementara "analisis waktu nyata" sangat populer untuk kasus seperti deteksi penipuan dan pemantauan sistem, sebagian besar analisis tidak memerlukan data waktu nyata atau atau analisis langsung.Ketika Anda menjawab pertanyaan, misalnya, apa yang menyebabkan arus keluar pengguna atau bagaimana orang beralih dari aplikasi Anda ke situs web Anda, akses ke data Anda dengan sedikit keterlambatan (interval per jam atau harian) cukup dapat diterima. Data Anda tidak berubah setiap menit.Oleh karena itu, jika Anda terutama mengerjakan analisis yang sebenarnya, Anda harus merujuk ke database yang dioptimalkan untuk analitik, seperti Redshift atau BigQuery. Database semacam itu dirancang untuk mengakomodasi sejumlah besar data dan dengan cepat membaca dan menggabungkan data, membuat kueri menjadi cepat. Mereka juga dapat mengunduh data dengan cukup cepat (setiap jam) saat seseorang melakukan proses pembersihan, mengubah ukuran dan memonitor cluster.Jika Anda benar-benar membutuhkan data real-time, Anda harus beralih ke database yang tidak terstruktur seperti Hadoop. Anda dapat mendesain basis data Hadoop Anda sehingga data dimuat ke dalamnya dengan sangat cepat, meskipun permintaan itu mungkin membutuhkan waktu lebih lama tergantung pada penggunaan RAM, ruang disk yang tersedia, dan struktur data.Postgres vs. Amazon Redshift vs Google bigquery
Anda mungkin sudah menyadari bahwa basis data relasional akan menjadi pilihan terbaik untuk menganalisis sebagian besar tipe perilaku pengguna. Informasi tentang bagaimana pengguna Anda berinteraksi dengan situs dan aplikasi Anda dapat dengan mudah masuk ke dalam format terstruktur.analytics.track('Completed Order') — select * from ios.completed_order
 Jadi pertanyaannya adalah database SQL mana yang akan digunakan? Empat kriteria harus dipertimbangkan.
Jadi pertanyaannya adalah database SQL mana yang akan digunakan? Empat kriteria harus dipertimbangkan.Ukuran vs kecepatan
Ketika Anda membutuhkan kecepatan, ada baiknya mempertimbangkan Postgres: untuk database kurang dari 1TB, Postgres cukup cepat untuk memuat data dan permintaan. Plus, tersedia. Saat Anda mendekati 6TB (diwarisi dari Amazon RDS), kueri Anda akan berjalan lebih lambat.Karena itu, ketika Anda membutuhkan ukuran yang lebih besar, kami biasanya merekomendasikan Redshift. Pengalaman kami menunjukkan bahwa Redshift memiliki nilai terbaik untuk uang.Sorotan SQL
Redshift dibangun di atas variasi Postgres, dan keduanya mendukung SQL lama yang baik. Redshift tidak mendukung semua tipe data dan fungsi yang didukung postgres, tetapi jauh lebih dekat dengan standar industri daripada BigQuery, yang memiliki SQL sendiri.Tidak seperti banyak sistem berbasis SQL lainnya, BigQuery menggunakan sintaks yang dipisahkan koma untuk mengindikasikan gabungan tabel, dan tidak sesuai dengan dokumentasi SQL . Ini berarti bahwa tanpa hati-hati, kueri SQL dapat menyebabkan kesalahan atau hasil yang tidak terduga. Karenanya, banyak tim yang kami temui tidak dapat meyakinkan analis mereka untuk mempelajari BigQuery SQL.Ekosistem pihak ketiga
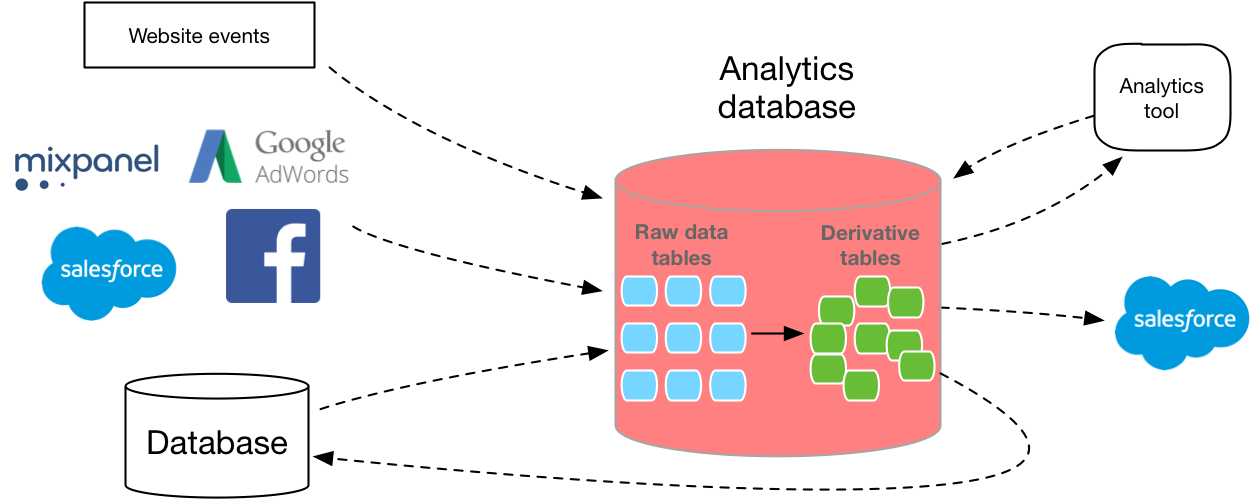
Jarang data warehouse Anda hidup sendiri. Anda perlu memasukkan data ke dalam basis data, dan di samping itu, Anda perlu menggunakan beberapa jenis perangkat lunak untuk menganalisisnya. (Kecuali jika Anda menjalankan query SQL dari baris perintah).Oleh karena itu, orang sering menyukai Redshift yang memiliki ekosistem alat pihak ketiga yang sangat besar. AWS memiliki kemampuan seperti Segment Data Warehouse untuk memuat data ke Redshift dari analytics API, dan mereka juga bekerja dengan hampir semua alat visualisasi data di pasar. Lebih sedikit layanan pihak ketiga yang terhubung ke Google, jadi memindahkan data yang sama ke BigQuery mungkin membutuhkan waktu lebih lama untuk dikembangkan, dan Anda tidak akan memiliki begitu banyak pilihan untuk perangkat lunak BI.Anda dapat melihat mitra Amazondi sini dan google di sini .Namun, jika Anda sudah menggunakan Google Cloud Storage dan bukan Amazon S3, mungkin bermanfaat bagi Anda untuk tetap berada di ekosistem Google. Kedua layanan menyederhanakan pemuatan data jika mereka sudah ada di repositori penyimpanan cloud yang sesuai, sehingga, meskipun mereka tidak akan melanggar ketentuan penggunaan, akan jauh lebih mudah jika Anda berhenti menggunakan salah satu penyedia ini.Latihan
Sekarang setelah Anda memiliki gagasan yang lebih jelas tentang basis data mana yang akan digunakan, langkah selanjutnya adalah mencari tahu bagaimana Anda akan mengumpulkan data ke dalam basis data.Banyak pengembang basis data baru meremehkan betapa sulitnya membangun jalur pipa data yang skalabel. Anda harus menulis layer ekstraksi Anda sendiri, API pengumpulan data, kueri dan lapisan konversi. Dan setiap orang harus mengukur. Selain itu, Anda perlu menentukan tata letak yang benar berdasarkan ukuran dan jenis setiap kolom. MVP mereplikasi database produksi Anda ke instance baru, tetapi ini biasanya berarti menggunakan database yang tidak dioptimalkan untuk analitik.Untungnya, ada beberapa opsi di pasar yang dapat membantu Anda mengatasi beberapa kendala ini dan secara otomatis melakukan ETL untuk Anda.Tetapi apakah itu pengembangan atau pembelian Anda sendiri, mendapatkan data dalam SQL tidak sia-sia.Berdasarkan data pengguna awal, hanya menggunakan format SQL yang fleksibel Anda dapat menjawab pertanyaan detail tentang apa yang pelanggan Anda lakukan, menilai distribusi dengan akurat, memahami perilaku lintas platform, membuat dashboard untuk perusahaan tertentu, dan banyak lagi.