Optimasi kueri PostgreSQL besar-besaran. Kirill Borovikov (Tensor)
Laporan ini menyajikan beberapa pendekatan yang memungkinkan Anda untuk memantau kinerja query SQL ketika ada jutaan dari mereka per hari , dan ratusan server PostgreSQL yang dikendalikan.Solusi teknis apa yang memungkinkan kami memproses secara efisien volume informasi semacam itu, dan bagaimana hal itu memfasilitasi kehidupan pengembang biasa.Siapa yang tertarik dalam menganalisis masalah khusus dan berbagai teknik untuk mengoptimalkan pertanyaan SQL dan menyelesaikan masalah DBA pada PostgreSQL ? Anda juga dapat membaca serangkaian artikel tentang topik ini.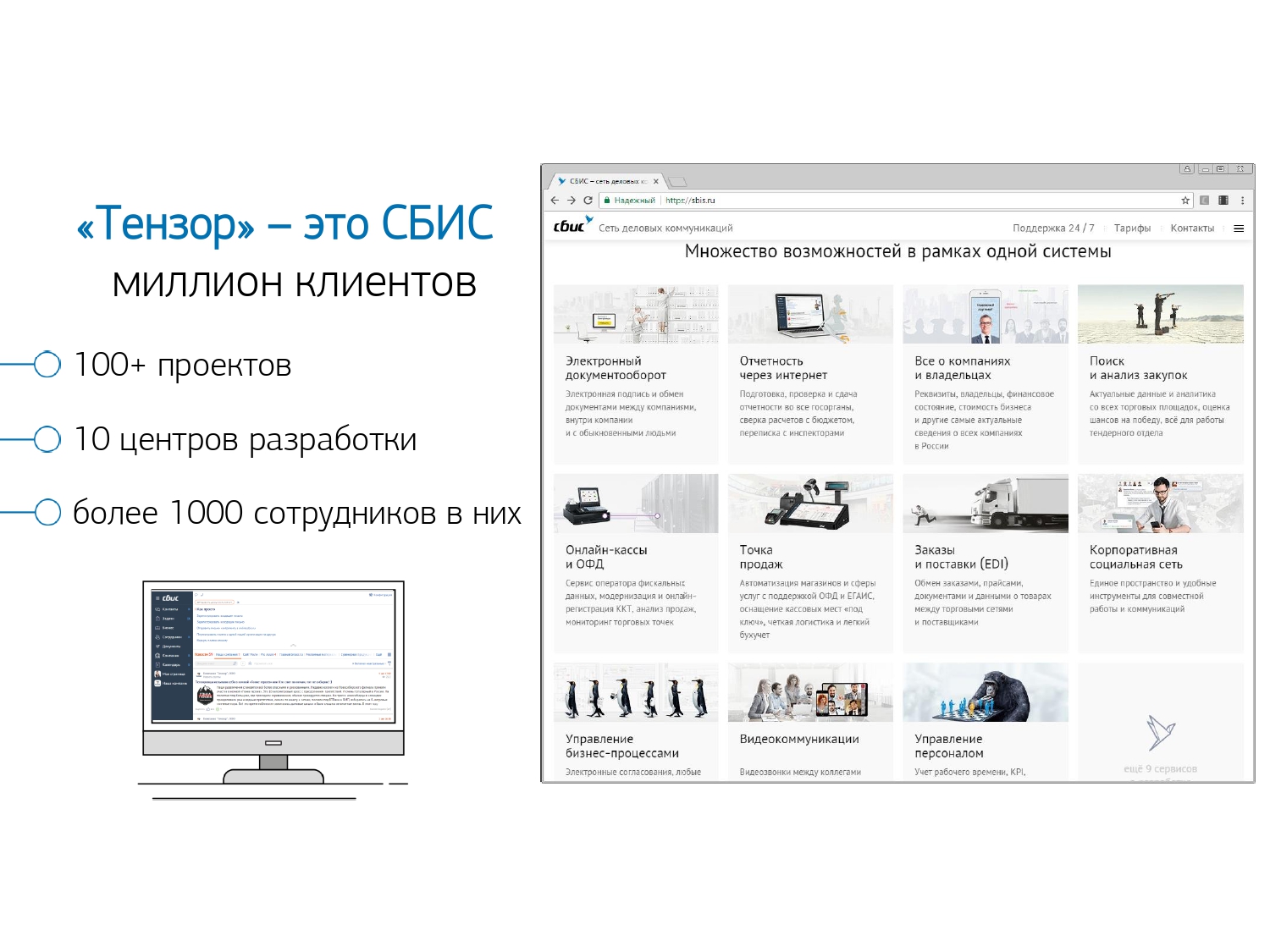 Nama saya Kirill Borovikov, saya mewakili perusahaan "Tensor" . Secara khusus, saya berspesialisasi dalam bekerja dengan database di perusahaan kami.Hari ini saya akan memberi tahu Anda bagaimana kami melakukan optimasi kueri, ketika Anda tidak perlu "mengambil" kinerja satu permintaan, tetapi untuk menyelesaikan masalah secara massal. Ketika ada jutaan permintaan, dan Anda perlu menemukan beberapa pendekatan untuk menyelesaikan masalah besar ini.Secara umum, "Tensor" untuk jutaan pelanggan kami adalah VLSI - aplikasi kami : jejaring sosial perusahaan, solusi komunikasi video, untuk manajemen dokumen internal dan eksternal, sistem akuntansi untuk pembukuan dan penyimpanan ... Yaitu, "gabungan besar" untuk manajemen bisnis terintegrasi, yang lebih dari 100 proyek internal yang berbeda.Untuk memastikan bahwa mereka semua bekerja dan berkembang secara normal, kami memiliki 10 pusat pengembangan di seluruh negeri, mereka memiliki lebih dari 1000 pengembang .Kami telah bekerja dengan PostgreSQL sejak 2008 dan telah mengumpulkan sejumlah besar dari apa yang kami proses - ini adalah data klien, statistik, analitik, data dari sistem informasi eksternal - lebih dari 400TB . Hanya "dalam produksi" ada sekitar 250 server, dan total server database yang kami monitor sekitar 1000.
Nama saya Kirill Borovikov, saya mewakili perusahaan "Tensor" . Secara khusus, saya berspesialisasi dalam bekerja dengan database di perusahaan kami.Hari ini saya akan memberi tahu Anda bagaimana kami melakukan optimasi kueri, ketika Anda tidak perlu "mengambil" kinerja satu permintaan, tetapi untuk menyelesaikan masalah secara massal. Ketika ada jutaan permintaan, dan Anda perlu menemukan beberapa pendekatan untuk menyelesaikan masalah besar ini.Secara umum, "Tensor" untuk jutaan pelanggan kami adalah VLSI - aplikasi kami : jejaring sosial perusahaan, solusi komunikasi video, untuk manajemen dokumen internal dan eksternal, sistem akuntansi untuk pembukuan dan penyimpanan ... Yaitu, "gabungan besar" untuk manajemen bisnis terintegrasi, yang lebih dari 100 proyek internal yang berbeda.Untuk memastikan bahwa mereka semua bekerja dan berkembang secara normal, kami memiliki 10 pusat pengembangan di seluruh negeri, mereka memiliki lebih dari 1000 pengembang .Kami telah bekerja dengan PostgreSQL sejak 2008 dan telah mengumpulkan sejumlah besar dari apa yang kami proses - ini adalah data klien, statistik, analitik, data dari sistem informasi eksternal - lebih dari 400TB . Hanya "dalam produksi" ada sekitar 250 server, dan total server database yang kami monitor sekitar 1000. SQL adalah bahasa deklaratif. Anda menjelaskan bukan "bagaimana" sesuatu harus bekerja, tetapi "apa" yang ingin Anda terima. DBMS lebih tahu cara membuat GABUNG - bagaimana menghubungkan tablet Anda, kondisi apa yang akan dikenakan, apa yang akan terjadi dengan indeks, apa yang tidak ...Beberapa DBMS menerima petunjuk: "Tidak, hubungkan kedua tablet ini dalam antrian ini dan itu", tetapi PostgreSQL tidak. Ini adalah posisi sadar dari pengembang terkemuka: "Lebih baik kita menyelesaikan optimizer kueri daripada membiarkan pengembang menggunakan semacam petunjuk."Tetapi, terlepas dari kenyataan bahwa PostgreSQL tidak mengizinkan "luar" mengontrol dirinya sendiri, PostgreSQL memungkinkan Anda untuk melihat apa yang terjadi "di dalam" ketika Anda mengeksekusi kueri Anda dan di mana ia memiliki masalah.
SQL adalah bahasa deklaratif. Anda menjelaskan bukan "bagaimana" sesuatu harus bekerja, tetapi "apa" yang ingin Anda terima. DBMS lebih tahu cara membuat GABUNG - bagaimana menghubungkan tablet Anda, kondisi apa yang akan dikenakan, apa yang akan terjadi dengan indeks, apa yang tidak ...Beberapa DBMS menerima petunjuk: "Tidak, hubungkan kedua tablet ini dalam antrian ini dan itu", tetapi PostgreSQL tidak. Ini adalah posisi sadar dari pengembang terkemuka: "Lebih baik kita menyelesaikan optimizer kueri daripada membiarkan pengembang menggunakan semacam petunjuk."Tetapi, terlepas dari kenyataan bahwa PostgreSQL tidak mengizinkan "luar" mengontrol dirinya sendiri, PostgreSQL memungkinkan Anda untuk melihat apa yang terjadi "di dalam" ketika Anda mengeksekusi kueri Anda dan di mana ia memiliki masalah. Secara umum, dengan masalah klasik apa yang biasanya pengembang [datang ke DBA]? "Di sini kita telah memenuhi permintaan, dan semuanya lambat , semuanya hang, sesuatu terjadi ... Semacam masalah!"Alasannya hampir selalu sama:
Secara umum, dengan masalah klasik apa yang biasanya pengembang [datang ke DBA]? "Di sini kita telah memenuhi permintaan, dan semuanya lambat , semuanya hang, sesuatu terjadi ... Semacam masalah!"Alasannya hampir selalu sama:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... Dan untuk yang lainnya, kita perlu rencana ! Kita perlu melihat apa yang terjadi di dalam server. Rencana eksekusi permintaan untuk PostgreSQL adalah pohon algoritma eksekusi permintaan dalam representasi tekstual. Algoritme inilah yang, sebagai hasil analisis oleh perencana, diakui sebagai yang paling efektif.Setiap simpul pohon adalah operasi: mengekstraksi data dari tabel atau indeks, membangun bitmap, menggabungkan dua tabel, menggabungkan, memotong, atau menghilangkan sampel. Pemenuhan permintaan adalah bagian melalui simpul pohon ini.Untuk mendapatkan rencana permintaan, cara termudah adalah dengan menjalankan pernyataan
Rencana eksekusi permintaan untuk PostgreSQL adalah pohon algoritma eksekusi permintaan dalam representasi tekstual. Algoritme inilah yang, sebagai hasil analisis oleh perencana, diakui sebagai yang paling efektif.Setiap simpul pohon adalah operasi: mengekstraksi data dari tabel atau indeks, membangun bitmap, menggabungkan dua tabel, menggabungkan, memotong, atau menghilangkan sampel. Pemenuhan permintaan adalah bagian melalui simpul pohon ini.Untuk mendapatkan rencana permintaan, cara termudah adalah dengan menjalankan pernyataan EXPLAIN. Untuk mendapatkan semua atribut nyata, yaitu, sebenarnya jalankan query berdasarkan - EXPLAIN (ANALYZE, BUFFERS) SELECT ....Poin buruknya: ketika Anda menjalankannya, itu terjadi "di sini dan sekarang", oleh karena itu hanya cocok untuk debugging lokal. Jika Anda mengambil beberapa server bermuatan tinggi, yang berada di bawah aliran perubahan data yang kuat, dan Anda melihat: "Ay! Di sini kita lebih lambat meminta Xia . " Setengah jam, satu jam yang lalu - saat Anda menjalankan dan mendapatkan permintaan ini dari log, membawanya lagi ke server, seluruh dataset dan statistik Anda telah berubah. Anda menjalankannya untuk debug - dan itu berjalan cepat! Dan Anda tidak dapat memahami mengapa, mengapa itu lambat. Untuk memahami apa sebenarnya saat permintaan dijalankan di server, orang pintar menulis modul auto_explain. Ia hadir di hampir semua distribusi PostgreSQL yang paling umum, dan Anda cukup mengaktifkannya di file konfigurasi.Jika dia mengerti bahwa permintaan sedang dieksekusi lebih lama dari perbatasan yang Anda katakan kepadanya, ia mengambil "snapshot" dari rencana untuk permintaan ini dan menulisnya bersama dalam log .
Untuk memahami apa sebenarnya saat permintaan dijalankan di server, orang pintar menulis modul auto_explain. Ia hadir di hampir semua distribusi PostgreSQL yang paling umum, dan Anda cukup mengaktifkannya di file konfigurasi.Jika dia mengerti bahwa permintaan sedang dieksekusi lebih lama dari perbatasan yang Anda katakan kepadanya, ia mengambil "snapshot" dari rencana untuk permintaan ini dan menulisnya bersama dalam log . Segalanya tampak baik-baik saja sekarang, kita pergi ke log dan melihat di sana ... [teks jejak]. Tapi kami tidak bisa mengatakan apa-apa tentang dia, kecuali kenyataan bahwa ini adalah rencana yang sangat baik, karena butuh 11ms untuk menyelesaikannya.Segalanya tampak baik-baik saja - tetapi tidak ada yang jelas tentang apa yang sebenarnya terjadi. Selain total waktu, kami tidak melihat banyak. Karena melihat seperti "latuha" teks biasa umumnya dicintai.Tetapi bahkan jika itu dicintai, meskipun tidak nyaman, tetapi ada masalah yang lebih besar:
Segalanya tampak baik-baik saja sekarang, kita pergi ke log dan melihat di sana ... [teks jejak]. Tapi kami tidak bisa mengatakan apa-apa tentang dia, kecuali kenyataan bahwa ini adalah rencana yang sangat baik, karena butuh 11ms untuk menyelesaikannya.Segalanya tampak baik-baik saja - tetapi tidak ada yang jelas tentang apa yang sebenarnya terjadi. Selain total waktu, kami tidak melihat banyak. Karena melihat seperti "latuha" teks biasa umumnya dicintai.Tetapi bahkan jika itu dicintai, meskipun tidak nyaman, tetapi ada masalah yang lebih besar:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
Dalam keadaan ini, pahami "Siapa tautan terlemah?" hampir tidak realistis. Oleh karena itu, bahkan para pengembang sendiri dalam "manual" menulis bahwa "Memahami rencana adalah seni yang perlu dipelajari, pengalaman ..." .Tetapi kami memiliki 1000 pengembang, dan masing-masing dari mereka tidak akan meneruskan pengalaman ini ke kepala mereka. Saya, Anda, dia - mereka tahu, dan seseorang di sana - tidak lagi di sana. Mungkin dia akan belajar, atau mungkin tidak, tetapi dia harus bekerja sekarang - dan dari mana dia mendapatkan pengalaman ini.Rencanakan visualisasi
Oleh karena itu, kami menyadari bahwa untuk mengatasi masalah ini, kami memerlukan visualisasi rencana yang baik . [artikel]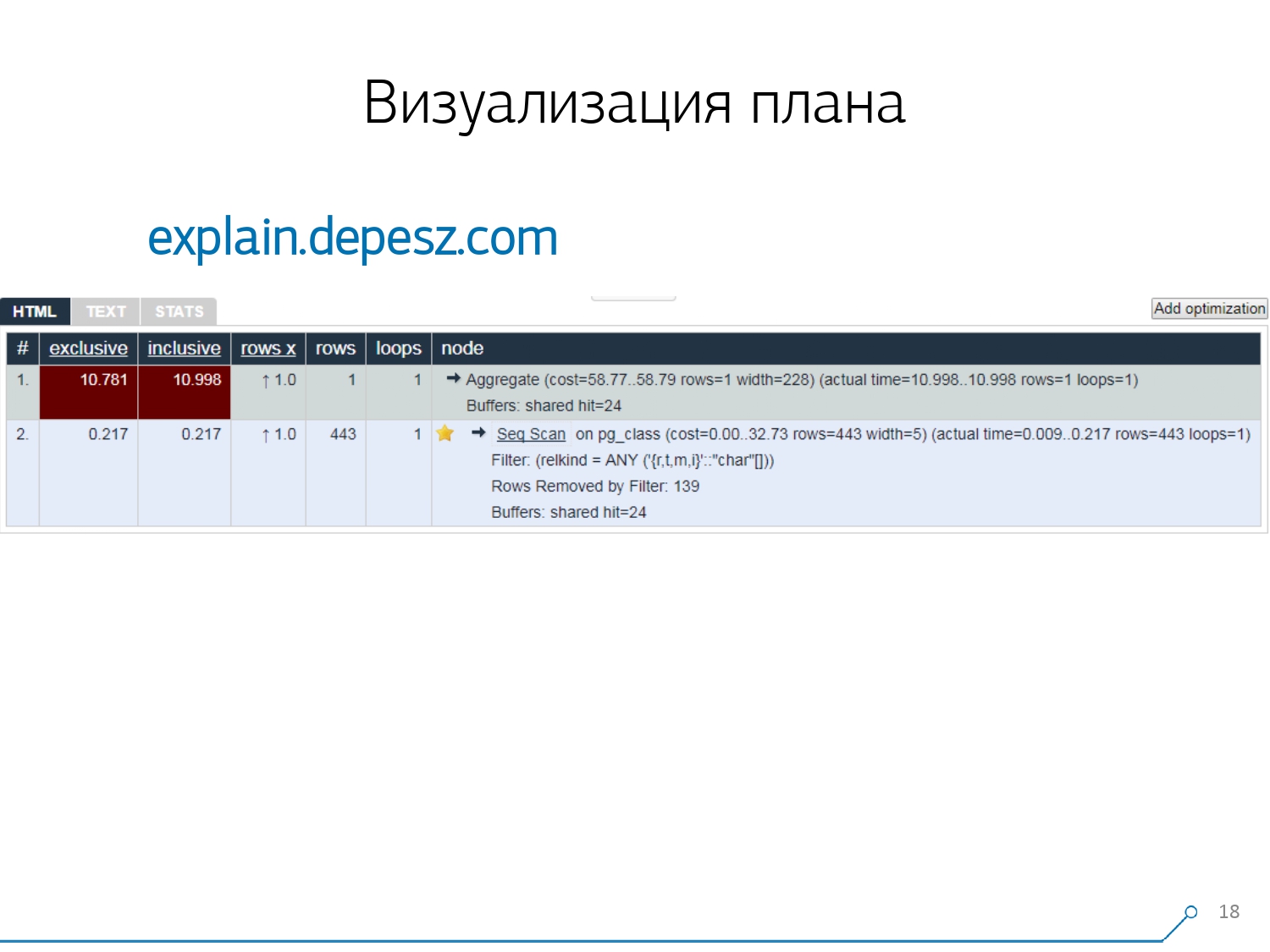 Kami duluan “berkeliling pasar” - mari kita lihat di internet untuk apa yang ada secara umum.Tapi, ternyata solusi yang relatif "hidup" yang lebih atau kurang dikembangkan, ada sangat sedikit - secara harfiah, satu hal: jelaskan.depesz.com dari Hubert Lubaczewski. Di pintu masuk ke bidang "umpan" representasi tekstual dari paket, itu menunjukkan Anda sebuah piring dengan data yang diuraikan:
Kami duluan “berkeliling pasar” - mari kita lihat di internet untuk apa yang ada secara umum.Tapi, ternyata solusi yang relatif "hidup" yang lebih atau kurang dikembangkan, ada sangat sedikit - secara harfiah, satu hal: jelaskan.depesz.com dari Hubert Lubaczewski. Di pintu masuk ke bidang "umpan" representasi tekstual dari paket, itu menunjukkan Anda sebuah piring dengan data yang diuraikan:- simpul waktu kerja yang tepat
- total waktu di seluruh subtree
- jumlah catatan yang diambil dan yang secara statistik diharapkan
- tubuh simpul itu sendiri
Layanan ini juga memiliki kemampuan untuk berbagi arsip tautan. Anda melemparkan rencana Anda ke sana dan berkata: "Hei, Vasya, ini ada tautan untuk Anda, ada sesuatu yang salah di sana." Tetapi ada beberapa masalah kecil.Pertama, sejumlah besar copy-paste. Anda mengambil sepotong log, meletakkannya di sana, dan lagi dan lagi.Kedua, tidak ada analisis jumlah data yang dibaca - buffer yang ditampilkan
Tetapi ada beberapa masalah kecil.Pertama, sejumlah besar copy-paste. Anda mengambil sepotong log, meletakkannya di sana, dan lagi dan lagi.Kedua, tidak ada analisis jumlah data yang dibaca - buffer yang ditampilkan EXPLAIN (ANALYZE, BUFFERS), di sini kita tidak melihat. Dia sama sekali tidak tahu bagaimana membongkar, memahami dan bekerja dengan mereka. Ketika Anda membaca banyak data dan memahami bahwa Anda dapat "menguraikan" secara tidak benar pada disk dan cache di memori, informasi ini sangat penting.Poin negatif ketiga adalah perkembangan proyek ini yang sangat lemah. Komitnya sangat kecil, ada baiknya jika setiap enam bulan, dan kode di Perl.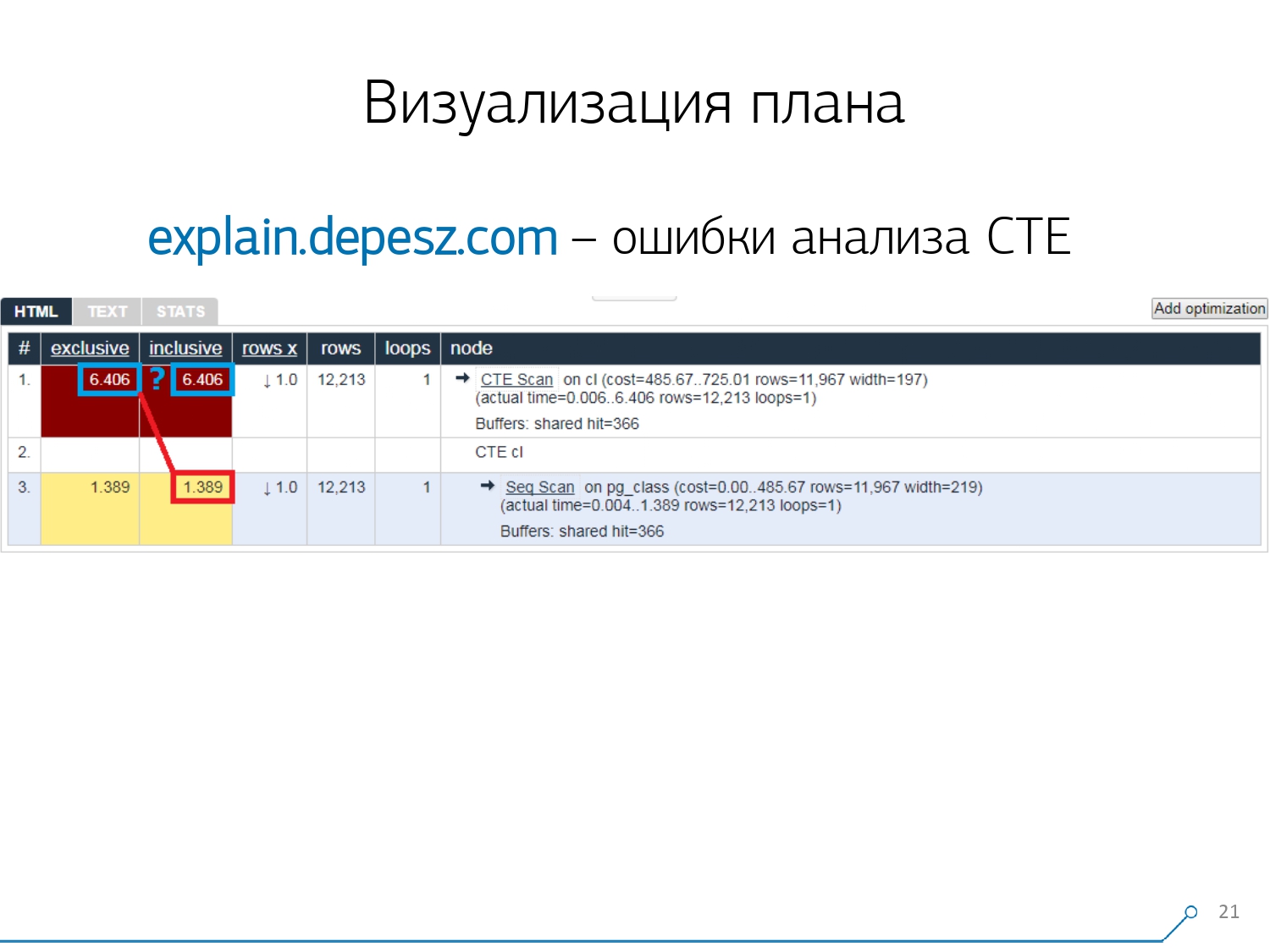 Tapi ini semua "lirik", entah bagaimana orang bisa hidup dengannya, tetapi ada satu hal yang membuat kami menjauh dari layanan ini. Ini adalah kesalahan analisis Common Table Expression (CTE) dan berbagai node dinamis seperti InitPlan / SubPlan.Jika Anda meyakini gambar ini, maka kami memiliki total waktu eksekusi setiap node individual lebih besar dari total waktu eksekusi seluruh permintaan. Sederhana - waktu pembuatan CTE ini tidak dikurangi dari simpul CTE Scan . Oleh karena itu, kami tidak lagi tahu jawaban yang benar, berapa banyak yang diambil oleh CTE itu sendiri.
Tapi ini semua "lirik", entah bagaimana orang bisa hidup dengannya, tetapi ada satu hal yang membuat kami menjauh dari layanan ini. Ini adalah kesalahan analisis Common Table Expression (CTE) dan berbagai node dinamis seperti InitPlan / SubPlan.Jika Anda meyakini gambar ini, maka kami memiliki total waktu eksekusi setiap node individual lebih besar dari total waktu eksekusi seluruh permintaan. Sederhana - waktu pembuatan CTE ini tidak dikurangi dari simpul CTE Scan . Oleh karena itu, kami tidak lagi tahu jawaban yang benar, berapa banyak yang diambil oleh CTE itu sendiri. Kemudian kami menyadari bahwa sudah waktunya untuk menulis sendiri - hore! Setiap pengembang mengatakan: "Sekarang kita akan menulis milik kita sendiri, itu akan menjadi super!"Mereka mengambil tumpukan layanan web yang khas: inti pada Node.js + Express, menarik Bootstrap dan untuk diagram yang indah - D3.js. Dan harapan kami dibenarkan - kami menerima prototipe pertama dalam 2 minggu:
Kemudian kami menyadari bahwa sudah waktunya untuk menulis sendiri - hore! Setiap pengembang mengatakan: "Sekarang kita akan menulis milik kita sendiri, itu akan menjadi super!"Mereka mengambil tumpukan layanan web yang khas: inti pada Node.js + Express, menarik Bootstrap dan untuk diagram yang indah - D3.js. Dan harapan kami dibenarkan - kami menerima prototipe pertama dalam 2 minggu:- own plan parser
Yaitu, sekarang kita secara umum dapat menguraikan rencana apa pun dari yang dihasilkan oleh PostgreSQL. - analisis yang benar dari node dinamis - CTE Scan, InitPlan, SubPlan
- analisis distribusi buffer - di mana halaman data dari memori dibaca, di mana dari cache lokal, di mana dari disk
- visibilitas yang diterima
Sehingga bukan "di log" yang "digali", tetapi Anda melihat "tautan terlemah" segera di gambar.
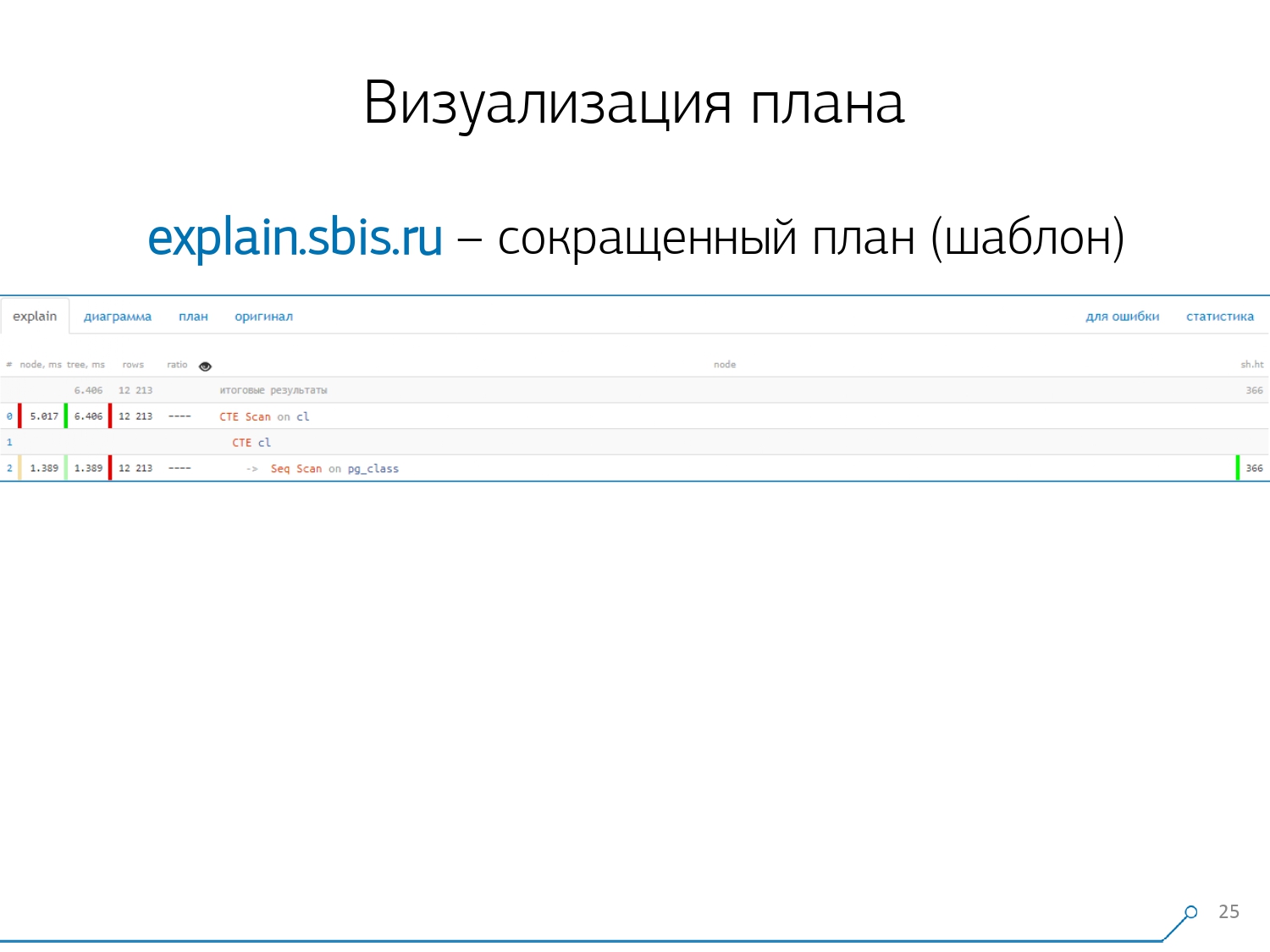 Kami mendapat sesuatu seperti ini - segera dengan penyorotan sintaksis. Tetapi biasanya pengembang kami tidak lagi bekerja dengan presentasi lengkap dari rencana, tetapi dengan yang lebih pendek. Bagaimanapun, kami telah menguraikan semua digit dan melemparkannya ke kiri dan kanan, dan di tengah kami hanya meninggalkan baris pertama: seperti apa simpulnya: CTE Scan, CTE atau Seq Scan generation dengan beberapa jenis label.Tampilan singkat ini adalah apa yang kita sebut templat paket .
Kami mendapat sesuatu seperti ini - segera dengan penyorotan sintaksis. Tetapi biasanya pengembang kami tidak lagi bekerja dengan presentasi lengkap dari rencana, tetapi dengan yang lebih pendek. Bagaimanapun, kami telah menguraikan semua digit dan melemparkannya ke kiri dan kanan, dan di tengah kami hanya meninggalkan baris pertama: seperti apa simpulnya: CTE Scan, CTE atau Seq Scan generation dengan beberapa jenis label.Tampilan singkat ini adalah apa yang kita sebut templat paket .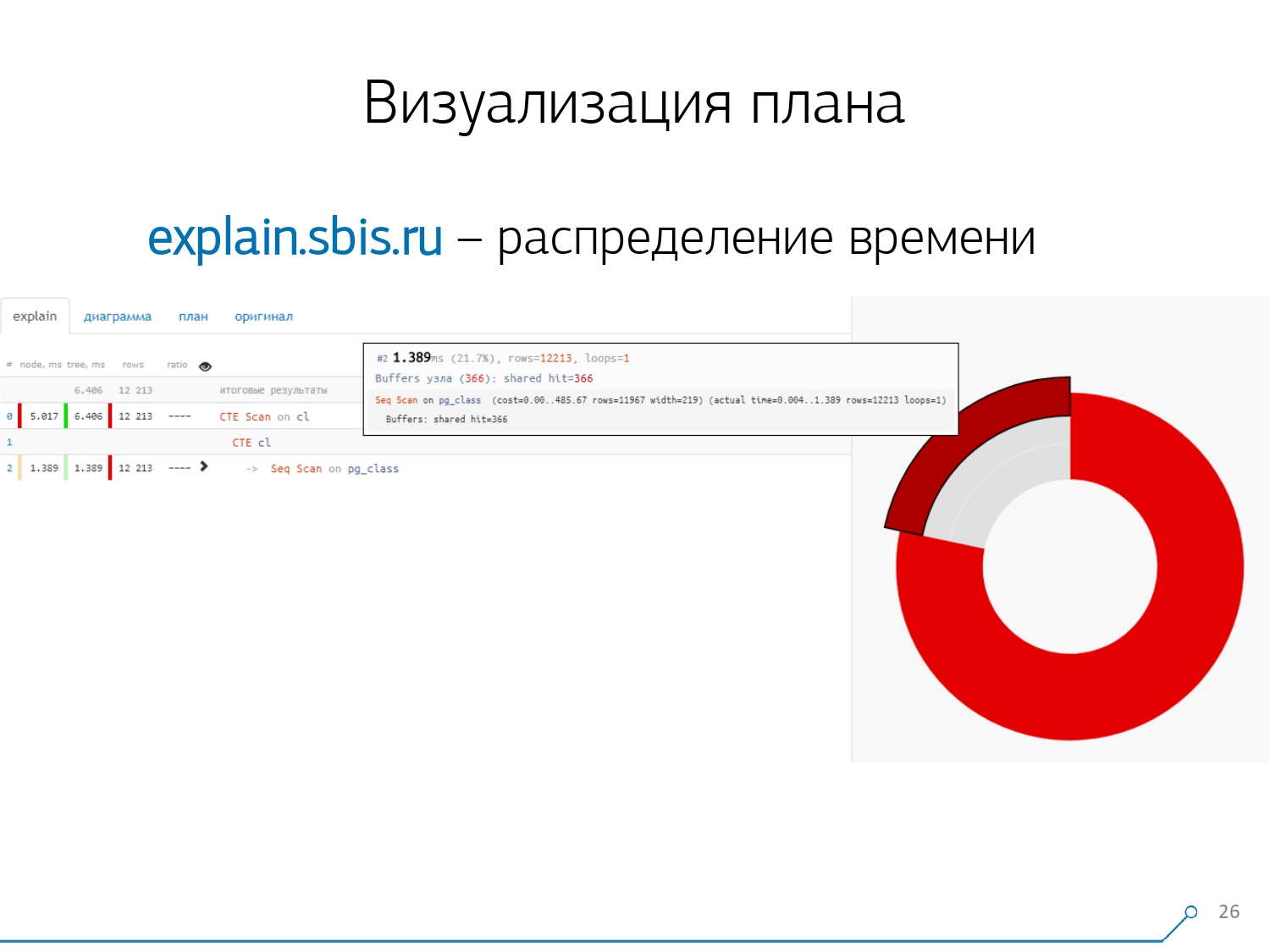 Apa lagi yang nyaman? Akan lebih mudah untuk melihat berapa proporsi dari simpul mana dari total waktu yang dialokasikan untuk kita - dan hanya "terjebak" diagram lingkaran di samping .Kami menunjuk ke simpul dan melihat - bersama kami, ternyata Seq Scan membutuhkan waktu kurang dari seperempat dari seluruh waktu, dan 3/4 sisanya mengambil CTE Scan. Kengerian! Ini adalah komentar kecil tentang "laju kebakaran" CTE Scan, jika Anda menggunakannya secara aktif dalam pertanyaan Anda. Mereka tidak terlalu cepat - mereka kehilangan bahkan ke pemindaian tabel biasa. [artikel] [artikel]Tapi biasanya diagram seperti itu lebih menarik, lebih rumit ketika kita langsung menunjuk ke sebuah segmen, dan kita melihat, misalnya, bahwa lebih dari separuh waktu yang dimiliki oleh beberapa Seq Scan “makan”. Selain itu, ada semacam Filter di dalamnya, banyak catatan dijatuhkan di atasnya ... Anda dapat langsung melempar gambar ini ke pengembang dan berkata: "Vasya, semuanya buruk dengan Anda di sini! Pahami, lihat - ada sesuatu yang salah! "
Apa lagi yang nyaman? Akan lebih mudah untuk melihat berapa proporsi dari simpul mana dari total waktu yang dialokasikan untuk kita - dan hanya "terjebak" diagram lingkaran di samping .Kami menunjuk ke simpul dan melihat - bersama kami, ternyata Seq Scan membutuhkan waktu kurang dari seperempat dari seluruh waktu, dan 3/4 sisanya mengambil CTE Scan. Kengerian! Ini adalah komentar kecil tentang "laju kebakaran" CTE Scan, jika Anda menggunakannya secara aktif dalam pertanyaan Anda. Mereka tidak terlalu cepat - mereka kehilangan bahkan ke pemindaian tabel biasa. [artikel] [artikel]Tapi biasanya diagram seperti itu lebih menarik, lebih rumit ketika kita langsung menunjuk ke sebuah segmen, dan kita melihat, misalnya, bahwa lebih dari separuh waktu yang dimiliki oleh beberapa Seq Scan “makan”. Selain itu, ada semacam Filter di dalamnya, banyak catatan dijatuhkan di atasnya ... Anda dapat langsung melempar gambar ini ke pengembang dan berkata: "Vasya, semuanya buruk dengan Anda di sini! Pahami, lihat - ada sesuatu yang salah! " Secara alami, ada "rake".Hal pertama yang mereka “injak” adalah masalah pembulatan. Waktu simpul masing-masing individu dalam rencana ditunjukkan dengan akurasi 1 μs. Dan ketika jumlah siklus simpul melebihi, misalnya, 1000 - setelah eksekusi PostgreSQL membaginya “hingga”, maka dalam perhitungan terbalik kita mendapatkan total waktu “di suatu tempat antara 0,95 ms dan 1,05 ms”. Ketika akun dihabiskan dalam mikrodetik - belum ada, tetapi ketika sudah selama [mili] detik - perlu untuk mengambil informasi ini ke akun ketika "membuka ikatan" sumber daya pada node dari rencana "siapa yang sudah berapa banyak dikonsumsi siapa".
Secara alami, ada "rake".Hal pertama yang mereka “injak” adalah masalah pembulatan. Waktu simpul masing-masing individu dalam rencana ditunjukkan dengan akurasi 1 μs. Dan ketika jumlah siklus simpul melebihi, misalnya, 1000 - setelah eksekusi PostgreSQL membaginya “hingga”, maka dalam perhitungan terbalik kita mendapatkan total waktu “di suatu tempat antara 0,95 ms dan 1,05 ms”. Ketika akun dihabiskan dalam mikrodetik - belum ada, tetapi ketika sudah selama [mili] detik - perlu untuk mengambil informasi ini ke akun ketika "membuka ikatan" sumber daya pada node dari rencana "siapa yang sudah berapa banyak dikonsumsi siapa". Poin kedua, yang lebih kompleks, adalah distribusi sumber daya (buffer yang sama) di antara node dinamis. Ini menghabiskan biaya 2 minggu pertama pada prototipe plus plus minggu 4.Untuk mendapatkan masalah ini cukup sederhana - kami membuat CTE dan kami seharusnya membaca sesuatu di dalamnya. Faktanya, PostgreSQL cerdas dan tidak akan membaca apa pun di sana. Lalu kami mengambil catatan pertama darinya, dan seratus pertama dari CTE yang sama untuk itu.
Poin kedua, yang lebih kompleks, adalah distribusi sumber daya (buffer yang sama) di antara node dinamis. Ini menghabiskan biaya 2 minggu pertama pada prototipe plus plus minggu 4.Untuk mendapatkan masalah ini cukup sederhana - kami membuat CTE dan kami seharusnya membaca sesuatu di dalamnya. Faktanya, PostgreSQL cerdas dan tidak akan membaca apa pun di sana. Lalu kami mengambil catatan pertama darinya, dan seratus pertama dari CTE yang sama untuk itu.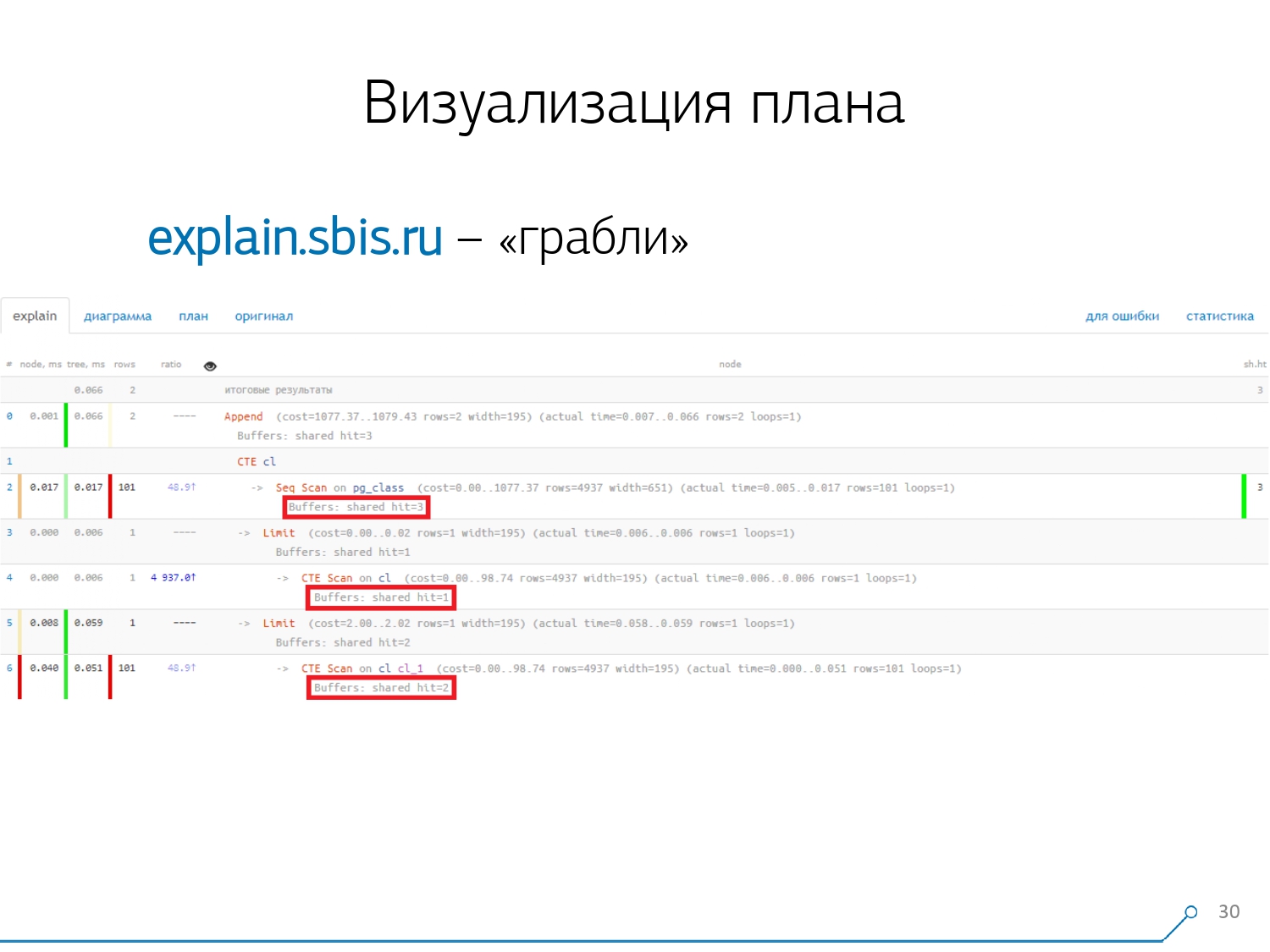 Kami melihat rencana dan mengerti - aneh, kami memiliki 3 buffer (halaman data) "dikonsumsi" di Seq Scan, 1 lainnya di CTE Scan, dan 2 lagi di CTE Scan kedua. Artinya, jika semuanya diringkas secara sederhana, kita mendapatkan 6, tetapi dari piring kita hanya membaca 3! CTE Scan tidak membaca apa pun dari mana saja, tetapi bekerja langsung dengan memori proses. Artinya, jelas ada sesuatu yang salah di sini!Faktanya, ternyata di sini semua 3 halaman data yang diminta dari Seq Scan, pertama 1 meminta CTE Scan 1, dan kemudian 2, dan mereka membaca 2 lagi. Artinya, 3 halaman dibaca secara total data, bukan 6.
Kami melihat rencana dan mengerti - aneh, kami memiliki 3 buffer (halaman data) "dikonsumsi" di Seq Scan, 1 lainnya di CTE Scan, dan 2 lagi di CTE Scan kedua. Artinya, jika semuanya diringkas secara sederhana, kita mendapatkan 6, tetapi dari piring kita hanya membaca 3! CTE Scan tidak membaca apa pun dari mana saja, tetapi bekerja langsung dengan memori proses. Artinya, jelas ada sesuatu yang salah di sini!Faktanya, ternyata di sini semua 3 halaman data yang diminta dari Seq Scan, pertama 1 meminta CTE Scan 1, dan kemudian 2, dan mereka membaca 2 lagi. Artinya, 3 halaman dibaca secara total data, bukan 6.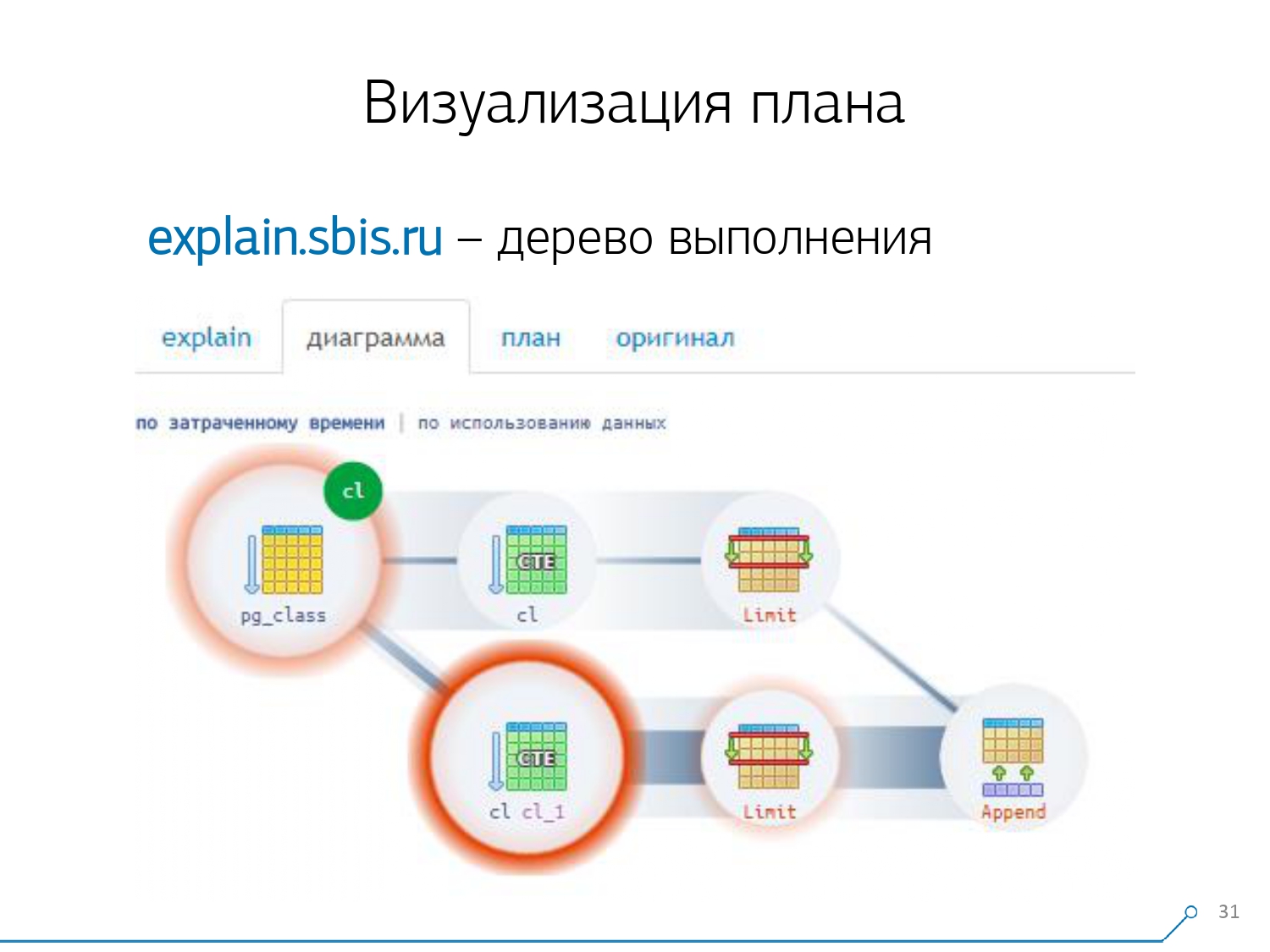 Dan gambaran ini membuat kami memahami bahwa implementasi rencana tersebut bukan lagi pohon, tetapi hanya semacam grafik asiklik. Dan kami mendapat bagan seperti ini sehingga kami mengerti "dari mana asalnya sama sekali." Yaitu, di sini kami membuat CTE dari pg_class, dan memintanya dua kali, dan hampir sepanjang waktu kami naik cabang ketika kami memintanya untuk kedua kalinya. Jelas bahwa membaca catatan ke-101 jauh lebih mahal daripada hanya tanggal 1 tablet.
Dan gambaran ini membuat kami memahami bahwa implementasi rencana tersebut bukan lagi pohon, tetapi hanya semacam grafik asiklik. Dan kami mendapat bagan seperti ini sehingga kami mengerti "dari mana asalnya sama sekali." Yaitu, di sini kami membuat CTE dari pg_class, dan memintanya dua kali, dan hampir sepanjang waktu kami naik cabang ketika kami memintanya untuk kedua kalinya. Jelas bahwa membaca catatan ke-101 jauh lebih mahal daripada hanya tanggal 1 tablet. Kami menghela napas sebentar. Mereka berkata: “Sekarang, Neo, kamu tahu kung fu! Sekarang pengalaman kami ada di layar Anda. Sekarang kamu bisa menggunakannya. ” [artikel]
Kami menghela napas sebentar. Mereka berkata: “Sekarang, Neo, kamu tahu kung fu! Sekarang pengalaman kami ada di layar Anda. Sekarang kamu bisa menggunakannya. ” [artikel]Konsolidasi Log
1000 pengembang kami menarik napas lega. Tetapi kami mengerti bahwa kami hanya memiliki ratusan server "pertempuran", dan semua "salin-tempel" oleh pengembang ini sama sekali tidak nyaman. Kami menyadari bahwa kami perlu mengambilnya sendiri. Secara umum, ada modul reguler yang dapat mengumpulkan statistik, namun, itu juga perlu diaktifkan dalam konfigurasi - ini adalah modul pg_stat_statements . Tapi dia tidak cocok dengan kita.Pertama, ia memberikan QueryId yang berbeda ke permintaan yang sama pada skema yang berbeda dalam database yang sama . Artinya, jika Anda pertama kali membuat
Secara umum, ada modul reguler yang dapat mengumpulkan statistik, namun, itu juga perlu diaktifkan dalam konfigurasi - ini adalah modul pg_stat_statements . Tapi dia tidak cocok dengan kita.Pertama, ia memberikan QueryId yang berbeda ke permintaan yang sama pada skema yang berbeda dalam database yang sama . Artinya, jika Anda pertama kali membuat SET search_path = '01'; SELECT * FROM user LIMIT 1;, dan kemudian SET search_path = '02';permintaan yang sama, maka statistik modul ini akan memiliki entri yang berbeda, dan saya tidak akan dapat mengumpulkan statistik umum secara tepat dalam konteks profil permintaan ini, tanpa memperhitungkan skema.Poin kedua yang menghalangi kami untuk menggunakannya adalah kurangnya rencana . Artinya, tidak ada rencana, hanya ada permintaan sendiri. Kami melihat apa yang melambat, tetapi kami tidak mengerti mengapa. Dan di sini kita kembali ke masalah dataset yang berubah dengan cepat.Dan poin terakhir adalah kurangnya "fakta . " Artinya, tidak mungkin untuk mengatasi contoh spesifik dari eksekusi permintaan - tidak ada, hanya ada statistik gabungan. Meskipun mungkin untuk bekerja dengannya, itu hanya sangat sulit.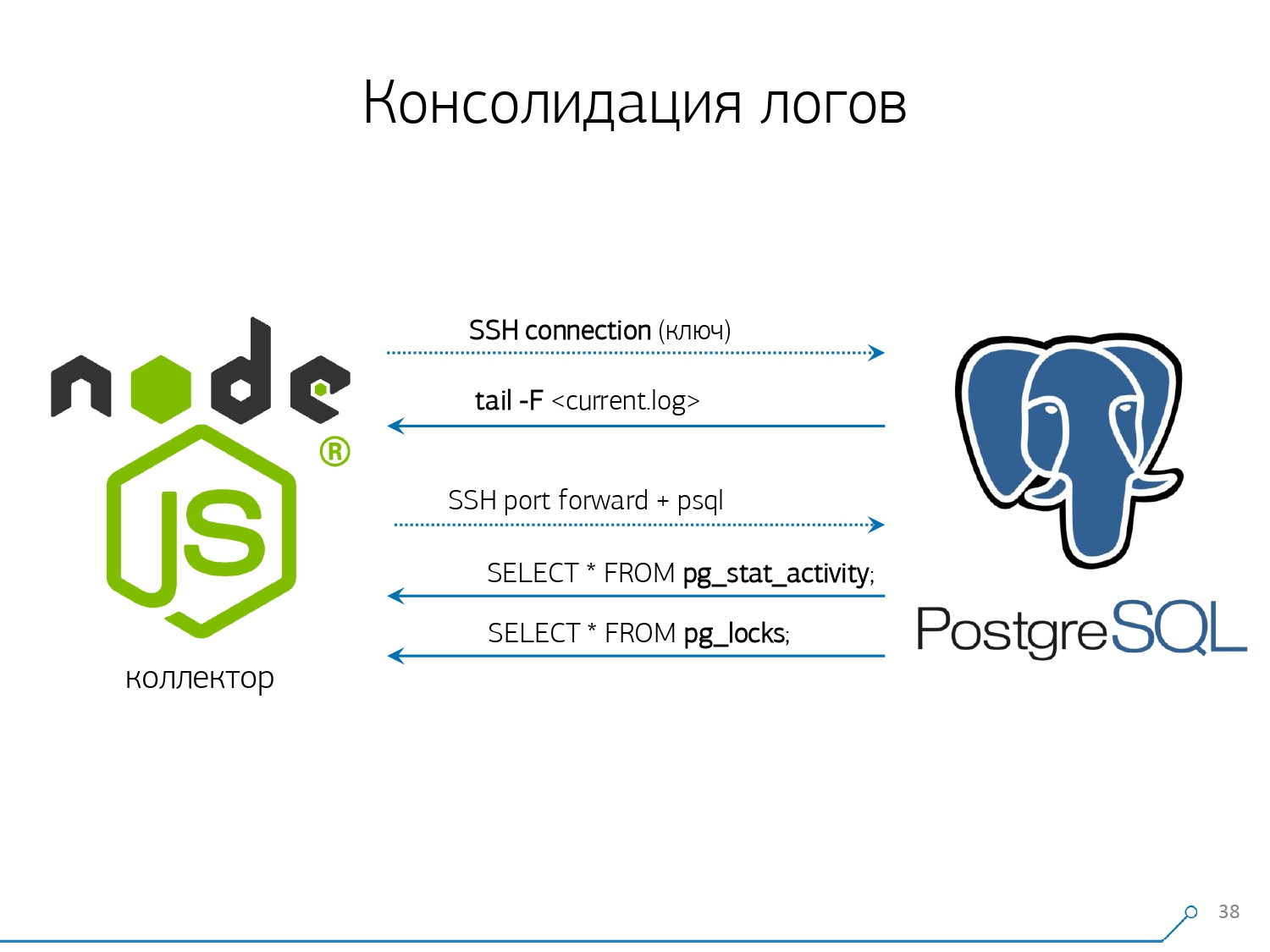 Karena itu, kami memutuskan untuk melawan "copy-paste" dan mulai menulis kolektor .Kolektor terhubung melalui SSH, “menarik” koneksi aman ke server dengan database menggunakan sertifikat dan
Karena itu, kami memutuskan untuk melawan "copy-paste" dan mulai menulis kolektor .Kolektor terhubung melalui SSH, “menarik” koneksi aman ke server dengan database menggunakan sertifikat dan tail -F“melekat” padanya ke file log. Jadi di sesi inikami mendapatkan "mirror" lengkap dari seluruh file log yang dihasilkan server. Beban di server itu sendiri minimal, karena kami tidak menguraikan apa pun di sana, kami hanya mencerminkan lalu lintas.Karena kami sudah mulai menulis antarmuka di Node.js, kami terus menulis kolektor di atasnya. Dan teknologi ini terbayar, karena sangat nyaman menggunakan JavaScript untuk bekerja dengan data teks yang diformat dengan buruk, yang merupakan log. Dan infrastruktur Node.js sendiri sebagai platform backend memungkinkan Anda untuk dengan mudah dan nyaman bekerja dengan koneksi jaringan, dan memang dengan semacam aliran data.Oleh karena itu, kami "menarik" dua koneksi: yang pertama adalah "mendengarkan" log itu sendiri dan membawanya ke diri kami sendiri, dan yang kedua adalah secara berkala menanyakan database. "Tapi dalam log itu tiba bahwa plat dengan oid 123 diblokir," tapi itu tidak mengatakan apa-apa kepada pengembang, dan akan menyenangkan untuk bertanya pada database "Apa OID = 123 setelah semua?" Jadi kami secara berkala meminta pangkalan untuk sesuatu yang belum kami ketahui di rumah. "Kamu tidak memperhitungkan, ada sejenis lebah seperti gajah! ..." Kami mulai mengembangkan sistem ini ketika kami ingin memantau 10 server. Yang paling kritis dalam pemahaman kami, di mana ada beberapa masalah yang sulit untuk diatasi. Tetapi selama kuartal pertama kami mendapat seratus untuk pemantauan - karena sistem "masuk", semua orang menginginkannya, semua orang merasa nyaman.Semua ini harus ditambahkan, aliran data besar, aktif. Sebenarnya, kami memantau apa yang bisa kami tangani - lalu kami menggunakannya. Kami juga menggunakan PostgreSQL sebagai gudang data. Tapi tidak ada yang lebih cepat untuk "menuangkan" data ke dalamnya daripada
"Kamu tidak memperhitungkan, ada sejenis lebah seperti gajah! ..." Kami mulai mengembangkan sistem ini ketika kami ingin memantau 10 server. Yang paling kritis dalam pemahaman kami, di mana ada beberapa masalah yang sulit untuk diatasi. Tetapi selama kuartal pertama kami mendapat seratus untuk pemantauan - karena sistem "masuk", semua orang menginginkannya, semua orang merasa nyaman.Semua ini harus ditambahkan, aliran data besar, aktif. Sebenarnya, kami memantau apa yang bisa kami tangani - lalu kami menggunakannya. Kami juga menggunakan PostgreSQL sebagai gudang data. Tapi tidak ada yang lebih cepat untuk "menuangkan" data ke dalamnya daripada COPYbelum ada operator .Tapi hanya "menuangkan" data bukan teknologi kita sebenarnya. Karena jika Anda memiliki sekitar 50 ribu permintaan per detik pada seratus server, maka ini akan menghasilkan 100-150GB log per hari untuk Anda. Karena itu, kami harus hati-hati “melihat” pangkalan.Pertama, kami melakukan partisi setiap hari , karena, pada umumnya, tidak ada yang tertarik pada korelasi antara hari-hari. Apa perbedaan yang Anda miliki kemarin, jika malam ini Anda meluncurkan versi baru aplikasi - dan sudah beberapa statistik baru.Kedua, kami belajar (dipaksa) menulis dengan sangat cepatCOPY . Artinya, bukan hanya COPYkarena lebih cepat daripada INSERT, tetapi bahkan lebih cepat. Poin ketiga - saya harus mengabaikan pemicu, masing-masing, dan dari Kunci Asing . Artinya, kita tidak memiliki integritas referensial mutlak. Karena jika Anda memiliki tabel di mana terdapat sepasang FK, dan Anda mengatakan dalam struktur database bahwa "di sini adalah entri log merujuk ke FK, misalnya, sekelompok catatan", maka ketika Anda memasukkannya, PostgreSQL tidak ada hubungannya selain bagaimana mengambil dan menjalankan
Poin ketiga - saya harus mengabaikan pemicu, masing-masing, dan dari Kunci Asing . Artinya, kita tidak memiliki integritas referensial mutlak. Karena jika Anda memiliki tabel di mana terdapat sepasang FK, dan Anda mengatakan dalam struktur database bahwa "di sini adalah entri log merujuk ke FK, misalnya, sekelompok catatan", maka ketika Anda memasukkannya, PostgreSQL tidak ada hubungannya selain bagaimana mengambil dan menjalankan SELECT 1 FROM master_fk1_table WHERE ...dengan jujur dengan pengidentifikasi yang Anda coba masukkan - hanya untuk memeriksa apakah entri ini ada, bahwa Anda tidak "memutuskan" Kunci Asing ini dengan memasukkan Anda.Kami mendapatkan alih-alih satu catatan di tabel target dan indeksnya, ditambah lagi bacaan dari semua tabel yang dirujuk. Dan kami sama sekali tidak membutuhkannya - tugas kami adalah menulis sebanyak mungkin dan secepat mungkin dengan beban terendah. Jadi FK - turun!Poin selanjutnya adalah agregasi dan hashing. Awalnya, mereka diimplementasikan dalam database kami - setelah semua, mudah untuk segera, ketika rekaman tiba, buat "plus satu" di semacam pelat tepat di pelatuk . Ini bagus, nyaman, tetapi hal yang sama buruk - masukkan satu catatan, tetapi Anda dipaksa untuk membaca dan menulis sesuatu yang lain dari tabel lain. Selain itu, tidak hanya itu, baca dan tulis - dan juga lakukan setiap saat.Sekarang bayangkan Anda memiliki piringan di mana Anda cukup menghitung jumlah permintaan yang dikirimkan pada host tertentu:+1, +1, +1, ..., +1. Dan Anda, pada prinsipnya, tidak membutuhkannya - semua ini dapat diringkas dalam memori pada kolektor dan dikirim ke database sekaligus +10.Ya, integritas logis Anda dapat "berantakan" jika terjadi beberapa masalah, tetapi ini hampir merupakan kasus yang tidak realistis - karena Anda memiliki server normal, ia memiliki baterai di controller, Anda memiliki log transaksi, log pada sistem file ... Secara umum, tidak setimpal. Tidak sebanding dengan hilangnya produktivitas yang Anda dapatkan karena pekerjaan pemicu / FK, biaya yang Anda keluarkan pada saat yang sama.Hal yang sama dengan hashing. Permintaan tertentu terbang kepada Anda, Anda menghitung pengidentifikasi tertentu dari database dari itu, menulis ke database dan kemudian kirim ke semua orang. Semuanya baik-baik saja, sampai pada saat merekam orang kedua datang kepada Anda yang ingin merekamnya - dan Anda memiliki kunci, dan ini sudah buruk. Oleh karena itu, jika Anda dapat menghapus pembuatan beberapa ID pada klien (relatif terhadap database), lebih baik melakukannya.Kami hanya cocok untuk menggunakan MD5 dari teks - permintaan, rencana, templat, ... Kami menghitungnya di sisi kolektor, dan "menuangkan" ID yang sudah disiapkan ke dalam basis data. Panjang MD5 dan partisi harian memungkinkan kita untuk tidak khawatir tentang kemungkinan tabrakan.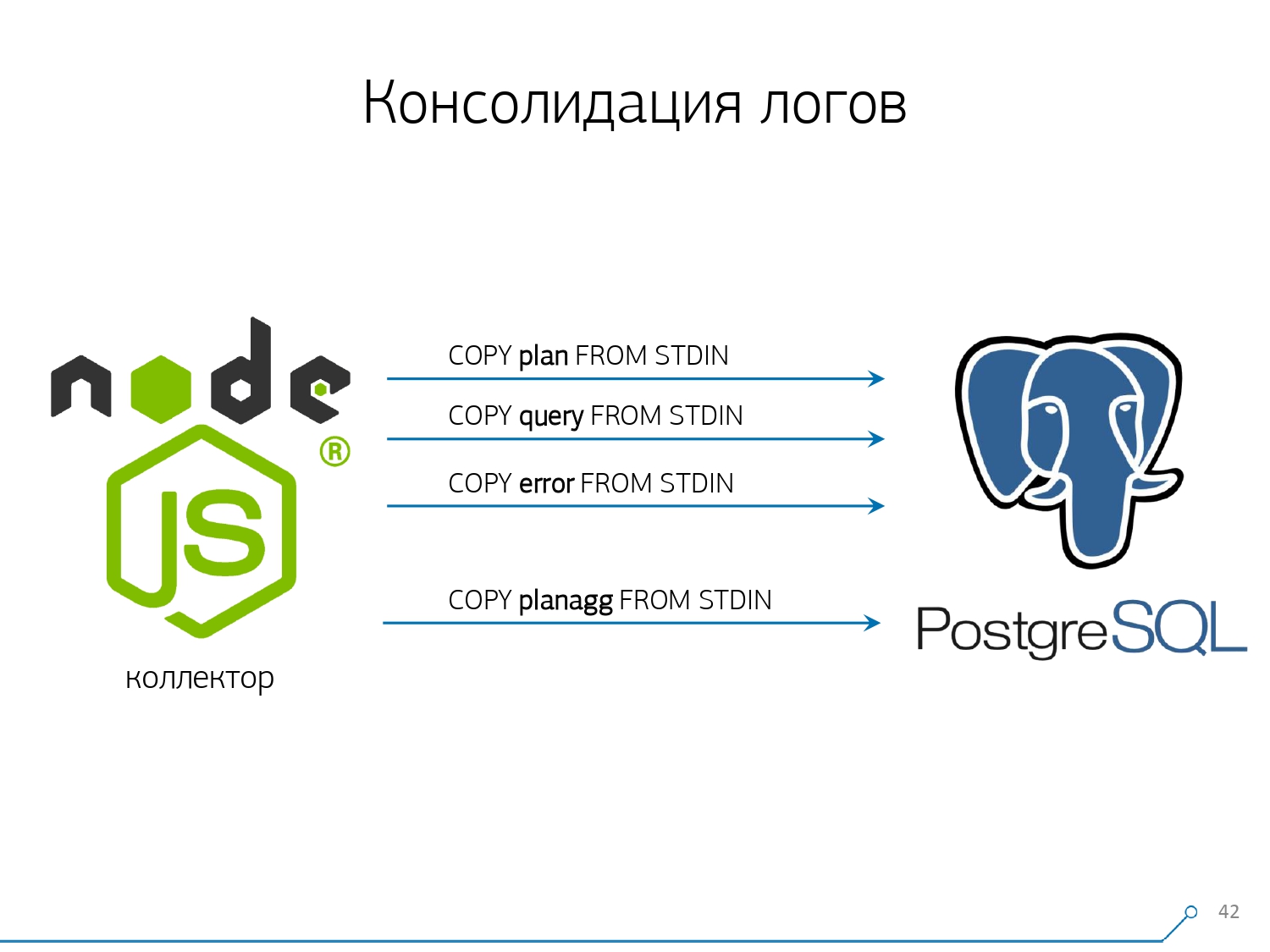 Tetapi untuk merekam semua ini dengan cepat, kami perlu memodifikasi prosedur perekaman itu sendiri.Bagaimana biasanya Anda menulis data? Kami memiliki beberapa jenis dataset, kami menguraikannya menjadi beberapa tabel, dan kemudian COPY - pertama di pertama, di kedua, di ketiga ... Itu tidak nyaman, karena kami semacam menulis satu aliran data dalam tiga langkah secara berurutan. Tidak menyenangkan. Apakah mungkin melakukan lebih cepat? Bisa!Untuk melakukan ini, cukup hanya dengan menguraikan aliran ini secara paralel satu sama lain. Ternyata kami memiliki kesalahan, permintaan, templat, kunci, terbang dalam aliran terpisah ... - dan kami menulis semuanya secara paralel. Untuk melakukan ini, biarkan saja saluran COPY terbuka secara permanen pada setiap tabel target individu .
Tetapi untuk merekam semua ini dengan cepat, kami perlu memodifikasi prosedur perekaman itu sendiri.Bagaimana biasanya Anda menulis data? Kami memiliki beberapa jenis dataset, kami menguraikannya menjadi beberapa tabel, dan kemudian COPY - pertama di pertama, di kedua, di ketiga ... Itu tidak nyaman, karena kami semacam menulis satu aliran data dalam tiga langkah secara berurutan. Tidak menyenangkan. Apakah mungkin melakukan lebih cepat? Bisa!Untuk melakukan ini, cukup hanya dengan menguraikan aliran ini secara paralel satu sama lain. Ternyata kami memiliki kesalahan, permintaan, templat, kunci, terbang dalam aliran terpisah ... - dan kami menulis semuanya secara paralel. Untuk melakukan ini, biarkan saja saluran COPY terbuka secara permanen pada setiap tabel target individu . Artinya, kolektor selalu memiliki alirandi mana saya dapat menulis data yang saya butuhkan. Tetapi agar database melihat data ini, dan seseorang tidak menggantung di kunci, menunggu data ini ditulis, COPY harus diinterupsi pada frekuensi tertentu . Bagi kami, periode urutan 100 ms ternyata yang paling efektif - tutup dan segera buka lagi di meja yang sama. Dan jika kita tidak memiliki satu aliran di beberapa puncak, maka kita mengumpulkan hingga batas tertentu.Selain itu, kami menemukan bahwa untuk profil memuat seperti itu, agregasi apa pun ketika catatan dikumpulkan dalam paket adalah jahat. Kejahatan klasik
Artinya, kolektor selalu memiliki alirandi mana saya dapat menulis data yang saya butuhkan. Tetapi agar database melihat data ini, dan seseorang tidak menggantung di kunci, menunggu data ini ditulis, COPY harus diinterupsi pada frekuensi tertentu . Bagi kami, periode urutan 100 ms ternyata yang paling efektif - tutup dan segera buka lagi di meja yang sama. Dan jika kita tidak memiliki satu aliran di beberapa puncak, maka kita mengumpulkan hingga batas tertentu.Selain itu, kami menemukan bahwa untuk profil memuat seperti itu, agregasi apa pun ketika catatan dikumpulkan dalam paket adalah jahat. Kejahatan klasik INSERT ... VALUESmelebihi 1000 catatan. Karena pada saat ini Anda memiliki rekaman puncak di media, dan semua orang yang mencoba menulis sesuatu ke disk akan menunggu.Untuk menghilangkan anomali semacam itu, cukup jangan agregat apa pun, jangan buffer sama sekali . Dan jika buffering ke disk benar-benar terjadi (untungnya, API Stream di Node.js memungkinkan Anda untuk mengetahuinya) - tunda koneksi ini. Saat itulah acara datang kepada Anda bahwa itu gratis lagi - menulis untuk itu dari antrian akumulasi. Sementara itu, sibuk - ambil yang berikutnya gratis dari kolam dan tulis untuk itu.Sebelum menerapkan pendekatan ini pada perekaman data, kami memiliki sekitar 4K operasi tulis, dan dengan cara ini kami mengurangi beban sebanyak 4 kali. Sekarang mereka telah tumbuh 6 kali karena basis baru yang dapat diamati - hingga 100MB / s. Dan sekarang kami menyimpan log selama 3 bulan terakhir dalam jumlah sekitar 10-15TB, berharap bahwa hanya dalam tiga bulan setiap pengembang dapat menyelesaikan masalah.Kami mengerti masalahnya
Tapi mengumpulkan semua data ini bagus, bermanfaat, sesuai, tetapi tidak cukup - Anda harus memahaminya. Karena jutaan rencana berbeda per hari. Tetapi jutaan orang tidak dapat dikendalikan, Anda harus terlebih dahulu melakukan "kurang." Dan, pertama-tama, perlu untuk memutuskan bagaimana Anda akan mengatur ini "lebih kecil".Kami telah mengidentifikasi sendiri tiga poin utama:
Tetapi jutaan orang tidak dapat dikendalikan, Anda harus terlebih dahulu melakukan "kurang." Dan, pertama-tama, perlu untuk memutuskan bagaimana Anda akan mengatur ini "lebih kecil".Kami telah mengidentifikasi sendiri tiga poin utama:- yang mengirim permintaan ini.
Yaitu, dari aplikasi mana ia “terbang”: antarmuka web, backend, sistem pembayaran atau yang lainnya. - di mana ini terjadi
Di server tertentu. Karena jika Anda memiliki beberapa server di bawah satu aplikasi, dan tiba-tiba satu "tumpul" (karena "disk telah membusuk", "kehabisan memori", beberapa masalah lainnya), maka Anda perlu secara khusus menangani server. - bagaimana masalah memanifestasikan dirinya dalam satu atau lain cara
Untuk memahami "siapa" yang mengirimi kami permintaan, kami menggunakan alat biasa - mengatur variabel sesi: SET application_name = '{bl-host}:{bl-method}';- mengirim nama host dari logika bisnis dari mana permintaan dibuat, dan nama metode atau aplikasi yang memprakarsainya.Setelah kami melewati "pemilik" permintaan, itu harus ditampilkan dalam log - untuk ini kami mengkonfigurasi variabel log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Siapa pun yang tertarik dapat melihat di manual apa artinya semua ini. Ternyata yang kita lihat di log:- waktu
- pengidentifikasi proses dan transaksi
- nama dasar
- IP orang yang mengirim permintaan ini
- dan nama metode
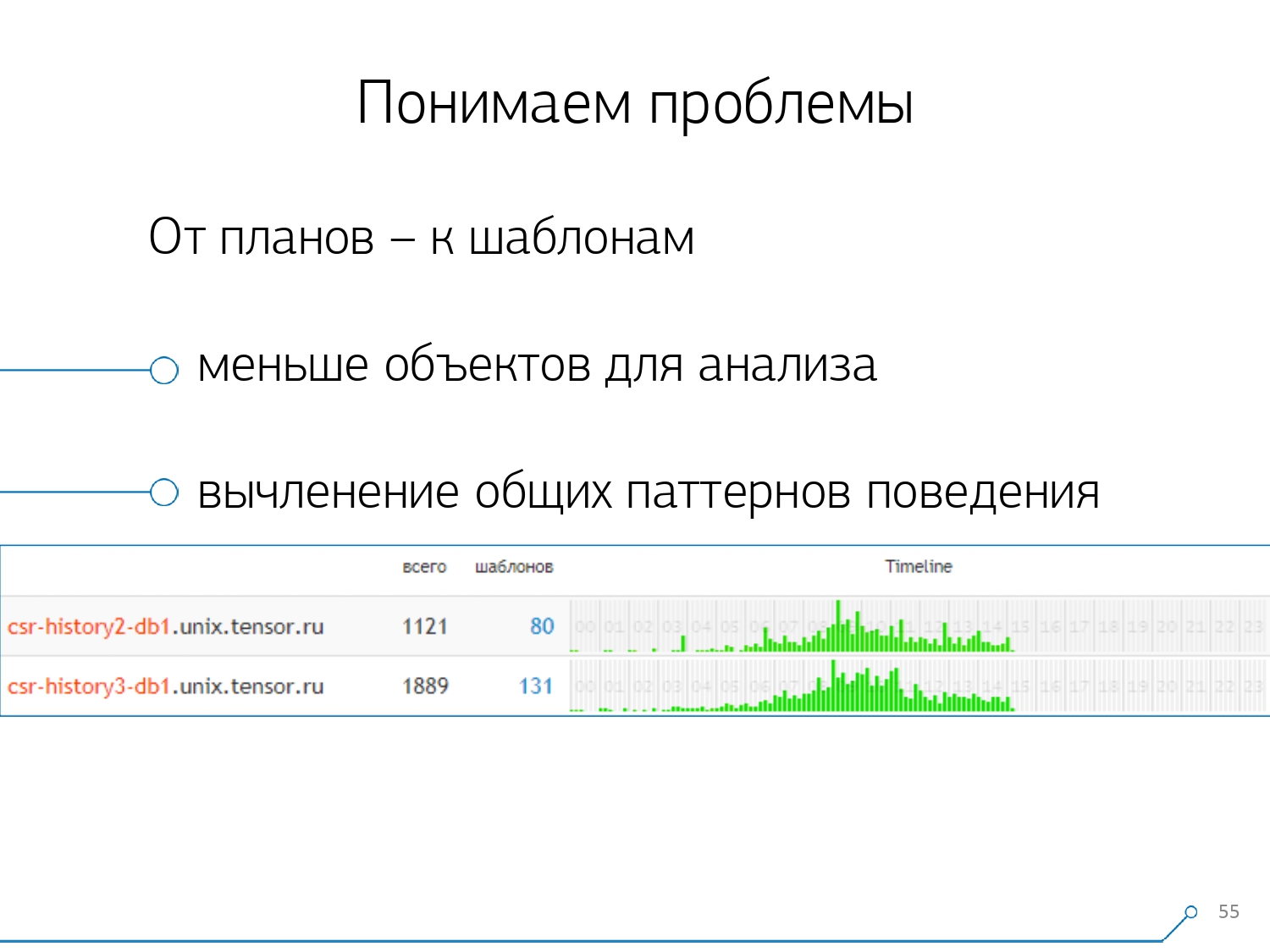 Kemudian kami menyadari bahwa tidak terlalu menarik untuk melihat korelasi satu permintaan antara server yang berbeda. Ini jarang terjadi ketika Anda memiliki satu aplikasi yang sama-sama craps di sana-sini. Tetapi bahkan jika itu sama, lihatlah salah satu dari server ini.Jadi, bagian "satu server - satu hari" ternyata cukup untuk analisis apa pun.Bagian analitis pertama adalah "templat" yang sangat - bentuk presentasi singkat dari rencana, dibersihkan dari semua indikator numerik. Bagian kedua adalah aplikasi atau metode, dan yang ketiga adalah simpul khusus dari rencana yang menyebabkan masalah pada kita.Ketika kami pindah dari contoh khusus ke templat, kami segera menerima dua keuntungan:
Kemudian kami menyadari bahwa tidak terlalu menarik untuk melihat korelasi satu permintaan antara server yang berbeda. Ini jarang terjadi ketika Anda memiliki satu aplikasi yang sama-sama craps di sana-sini. Tetapi bahkan jika itu sama, lihatlah salah satu dari server ini.Jadi, bagian "satu server - satu hari" ternyata cukup untuk analisis apa pun.Bagian analitis pertama adalah "templat" yang sangat - bentuk presentasi singkat dari rencana, dibersihkan dari semua indikator numerik. Bagian kedua adalah aplikasi atau metode, dan yang ketiga adalah simpul khusus dari rencana yang menyebabkan masalah pada kita.Ketika kami pindah dari contoh khusus ke templat, kami segera menerima dua keuntungan:
, .
, «» - , . , - , , , — , , — , , . , , .
 Metode yang tersisa didasarkan pada indikator yang kami ekstrak dari rencana: berapa kali template seperti itu terjadi, total dan waktu rata-rata, berapa banyak data yang dibaca dari disk, dan berapa banyak dari memori ...Karena Anda, misalnya, datang ke halaman analisis oleh tuan rumah, lihat - sesuatu yang terlalu banyak pada disk untuk membaca awal. Disk di server tidak mengatasi - dan siapa yang membacanya?Dan Anda dapat mengurutkan berdasarkan kolom apa pun dan memutuskan apa yang akan Anda tangani saat ini - dengan beban pada prosesor atau disk, atau dengan jumlah total permintaan ... Diurutkan, tampak "atas", diperbaiki - meluncurkan versi baru aplikasi.[ceramah video]Dan segera Anda dapat melihat berbagai aplikasi yang datang dengan templat yang sama dari permintaan seperti
Metode yang tersisa didasarkan pada indikator yang kami ekstrak dari rencana: berapa kali template seperti itu terjadi, total dan waktu rata-rata, berapa banyak data yang dibaca dari disk, dan berapa banyak dari memori ...Karena Anda, misalnya, datang ke halaman analisis oleh tuan rumah, lihat - sesuatu yang terlalu banyak pada disk untuk membaca awal. Disk di server tidak mengatasi - dan siapa yang membacanya?Dan Anda dapat mengurutkan berdasarkan kolom apa pun dan memutuskan apa yang akan Anda tangani saat ini - dengan beban pada prosesor atau disk, atau dengan jumlah total permintaan ... Diurutkan, tampak "atas", diperbaiki - meluncurkan versi baru aplikasi.[ceramah video]Dan segera Anda dapat melihat berbagai aplikasi yang datang dengan templat yang sama dari permintaan sepertiSELECT * FROM users WHERE login = 'Vasya'. Frontend, backend, pemrosesan ... Dan Anda bertanya-tanya mengapa pengguna harus membaca pemrosesan jika dia tidak berinteraksi dengannya.Cara sebaliknya adalah dengan segera melihat dari aplikasi apa yang dilakukannya. Misalnya, frontend adalah ini, ini, ini, dan ini satu jam sekali (hanya garis waktu membantu). Dan segera muncul pertanyaan - sepertinya bukan urusan front-end untuk melakukan sesuatu sekali dalam satu jam ... Setelah beberapa waktu, kami menyadari bahwa kami tidak memiliki statistik agregat dalam hal node rencana . Kami mengisolasi dari rencana hanya simpul-simpul yang melakukan sesuatu dengan data tabel itu sendiri (baca / tulis dengan indeks atau tidak). Faktanya, relatif terhadap gambar sebelumnya, hanya satu aspek yang ditambahkan - berapa banyak rekaman yang dibawa node ini kepada kami , dan berapa banyak yang jatuh (Rows Removed by Filter).Anda tidak memiliki indeks yang sesuai di piring, Anda membuat permintaan untuk itu, itu terbang melewati indeks, jatuh ke Pemindaian Seq ... Anda telah memfilter semua catatan kecuali satu. Dan mengapa Anda membutuhkan 100 juta catatan yang difilter per hari, apakah lebih baik untuk menggulung indeks?
Setelah beberapa waktu, kami menyadari bahwa kami tidak memiliki statistik agregat dalam hal node rencana . Kami mengisolasi dari rencana hanya simpul-simpul yang melakukan sesuatu dengan data tabel itu sendiri (baca / tulis dengan indeks atau tidak). Faktanya, relatif terhadap gambar sebelumnya, hanya satu aspek yang ditambahkan - berapa banyak rekaman yang dibawa node ini kepada kami , dan berapa banyak yang jatuh (Rows Removed by Filter).Anda tidak memiliki indeks yang sesuai di piring, Anda membuat permintaan untuk itu, itu terbang melewati indeks, jatuh ke Pemindaian Seq ... Anda telah memfilter semua catatan kecuali satu. Dan mengapa Anda membutuhkan 100 juta catatan yang difilter per hari, apakah lebih baik untuk menggulung indeks? Setelah memeriksa semua paket berdasarkan node, kami menyadari bahwa ada beberapa struktur tipikal dalam paket yang sangat mungkin terlihat mencurigakan. Dan akan menyenangkan untuk memberi tahu pengembang: "Teman, di sini Anda pertama kali membaca berdasarkan indeks, lalu mengurutkannya, dan kemudian memotongnya" - sebagai aturan, ada satu catatan.Setiap orang yang menulis pertanyaan dengan pola ini mungkin menemukan: "Beri aku urutan terakhir untuk Vasya, teman kencannya" Dan jika Anda tidak memiliki indeks berdasarkan tanggal, atau indeks yang digunakan tidak memiliki tanggal, maka lakukan "rake" dan melangkahlah tepat seperti itu .Tetapi kita tahu bahwa ini adalah "rake" - jadi mengapa tidak segera memberi tahu pengembang apa yang harus dia lakukan. Oleh karena itu, membuka rencana sekarang, pengembang kami segera melihat gambar yang indah dengan petunjuk, di mana ia segera diberitahu: "Anda memiliki masalah di sini dan di sini, tetapi mereka dipecahkan dengan cara ini dan itu."Akibatnya, jumlah pengalaman yang dibutuhkan untuk menyelesaikan masalah di awal dan sekarang telah turun secara signifikan. Di sini kita punya alat semacam itu.
Setelah memeriksa semua paket berdasarkan node, kami menyadari bahwa ada beberapa struktur tipikal dalam paket yang sangat mungkin terlihat mencurigakan. Dan akan menyenangkan untuk memberi tahu pengembang: "Teman, di sini Anda pertama kali membaca berdasarkan indeks, lalu mengurutkannya, dan kemudian memotongnya" - sebagai aturan, ada satu catatan.Setiap orang yang menulis pertanyaan dengan pola ini mungkin menemukan: "Beri aku urutan terakhir untuk Vasya, teman kencannya" Dan jika Anda tidak memiliki indeks berdasarkan tanggal, atau indeks yang digunakan tidak memiliki tanggal, maka lakukan "rake" dan melangkahlah tepat seperti itu .Tetapi kita tahu bahwa ini adalah "rake" - jadi mengapa tidak segera memberi tahu pengembang apa yang harus dia lakukan. Oleh karena itu, membuka rencana sekarang, pengembang kami segera melihat gambar yang indah dengan petunjuk, di mana ia segera diberitahu: "Anda memiliki masalah di sini dan di sini, tetapi mereka dipecahkan dengan cara ini dan itu."Akibatnya, jumlah pengalaman yang dibutuhkan untuk menyelesaikan masalah di awal dan sekarang telah turun secara signifikan. Di sini kita punya alat semacam itu.
Source: https://habr.com/ru/post/undefined/
All Articles