Selama bertahun-tahun, para ahli di C ++ telah mendiskusikan semantik nilai-nilai, ketetapan, dan berbagi sumber daya melalui komunikasi. Tentang dunia baru tanpa mutex dan ras, tanpa pola Command dan Observer. Padahal, semuanya tidak sesederhana itu. Masalah utama masih dalam struktur data kami. Struktur data yang tidak dapat berubah tidak mengubah nilainya. Untuk melakukan sesuatu dengannya, Anda perlu membuat nilai baru. Nilai-nilai lama tetap di tempat yang sama, sehingga mereka dapat dibaca dari aliran yang berbeda tanpa masalah dan kunci. Akibatnya, sumber daya dapat dibagikan secara lebih rasional dan teratur, karena nilai lama dan baru dapat menggunakan data umum. Berkat ini, mereka jauh lebih cepat untuk membandingkan satu sama lain dan dengan kompak menyimpan sejarah operasi dengan kemungkinan pembatalan. Semua ini sangat cocok pada sistem multi-threaded dan interaktif: struktur data seperti itu menyederhanakan arsitektur aplikasi desktop dan memungkinkan layanan untuk skala yang lebih baik. Struktur yang tidak dapat diubah adalah rahasia kesuksesan Clojure dan Scala, dan bahkan komunitas JavaScript sekarang mengambil keuntungan darinya, karena mereka memiliki perpustakaan Immutable.js,ditulis di perut perusahaan Facebook.Di bawah potongan video dan terjemahan laporan Juan Puente dari konferensi C ++ Russia 2019 Moscow. Juan berbicara tentang Immer , perpustakaan struktur yang tidak dapat diubah untuk C ++. Di pos:
Struktur data yang tidak dapat berubah tidak mengubah nilainya. Untuk melakukan sesuatu dengannya, Anda perlu membuat nilai baru. Nilai-nilai lama tetap di tempat yang sama, sehingga mereka dapat dibaca dari aliran yang berbeda tanpa masalah dan kunci. Akibatnya, sumber daya dapat dibagikan secara lebih rasional dan teratur, karena nilai lama dan baru dapat menggunakan data umum. Berkat ini, mereka jauh lebih cepat untuk membandingkan satu sama lain dan dengan kompak menyimpan sejarah operasi dengan kemungkinan pembatalan. Semua ini sangat cocok pada sistem multi-threaded dan interaktif: struktur data seperti itu menyederhanakan arsitektur aplikasi desktop dan memungkinkan layanan untuk skala yang lebih baik. Struktur yang tidak dapat diubah adalah rahasia kesuksesan Clojure dan Scala, dan bahkan komunitas JavaScript sekarang mengambil keuntungan darinya, karena mereka memiliki perpustakaan Immutable.js,ditulis di perut perusahaan Facebook.Di bawah potongan video dan terjemahan laporan Juan Puente dari konferensi C ++ Russia 2019 Moscow. Juan berbicara tentang Immer , perpustakaan struktur yang tidak dapat diubah untuk C ++. Di pos:- keunggulan arsitektur kekebalan;
- pembuatan tipe vektor persisten yang efektif berdasarkan pohon RRB;
- analisis arsitektur pada contoh editor teks sederhana.
Tragedi arsitektur berbasis nilai
Untuk memahami pentingnya struktur data yang tidak dapat diubah, kami membahas semantik nilai. Ini adalah fitur yang sangat penting dari C ++, saya menganggapnya sebagai salah satu keunggulan utama bahasa ini. Untuk semua ini, sangat sulit untuk menggunakan semantik nilai seperti yang kita inginkan. Saya percaya bahwa ini adalah tragedi arsitektur berbasis nilai, dan jalan menuju tragedi ini ditaburi dengan niat baik. Misalkan kita perlu menulis perangkat lunak interaktif berdasarkan model data dengan representasi dokumen yang dapat diedit pengguna. Ketika arsitektur yang berbasis pada nilai-nilai di jantung model ini menggunakan jenis sederhana dan nyaman dari nilai-nilai yang sudah ada di bahasa: vector, map, tuple,struct. Logika aplikasi dibuat dari fungsi yang mengambil dokumen berdasarkan nilai dan mengembalikan versi baru dokumen berdasarkan nilai. Dokumen ini dapat berubah di dalam fungsi (seperti yang terjadi di bawah), tetapi semantik nilai dalam C ++, diterapkan pada argumen dengan nilai dan tipe pengembalian dengan nilai, memastikan bahwa tidak ada efek samping.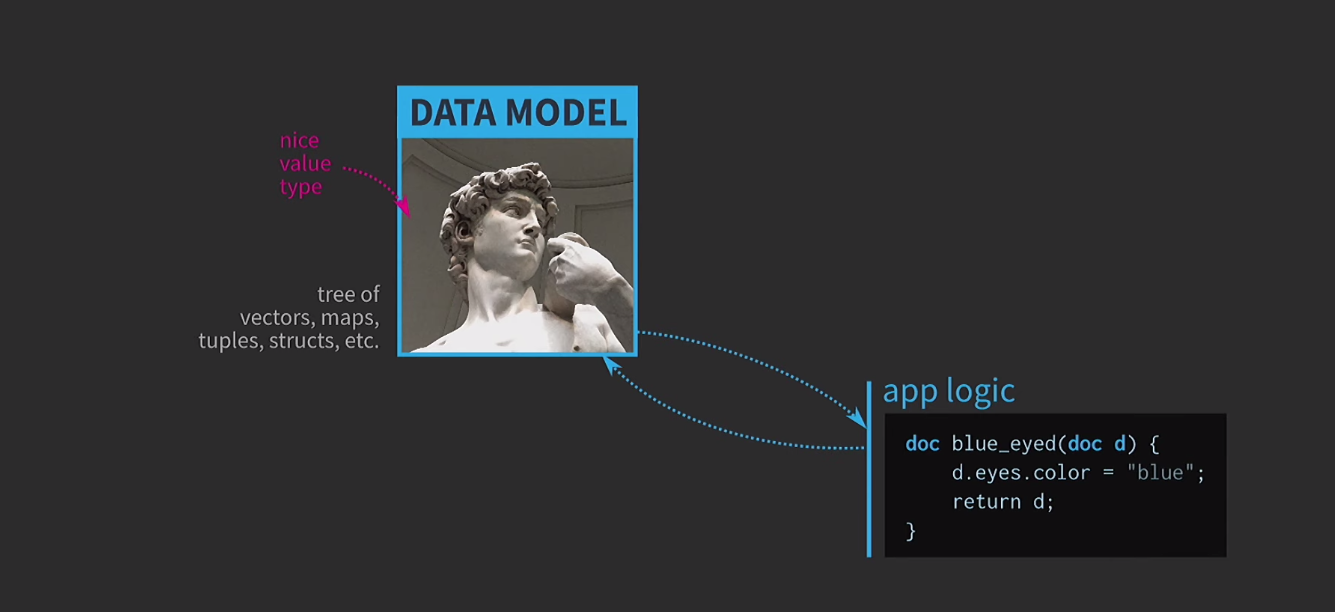 Fitur ini sangat mudah untuk dianalisis dan diuji.
Fitur ini sangat mudah untuk dianalisis dan diuji. Karena kami bekerja dengan nilai-nilai, kami akan mencoba menerapkan pembatalan tindakan. Ini bisa sulit, tetapi dengan pendekatan kami itu adalah tugas yang sepele: kami memiliki
Karena kami bekerja dengan nilai-nilai, kami akan mencoba menerapkan pembatalan tindakan. Ini bisa sulit, tetapi dengan pendekatan kami itu adalah tugas yang sepele: kami memiliki std::vectorberbagai negara dengan berbagai salinan dokumen.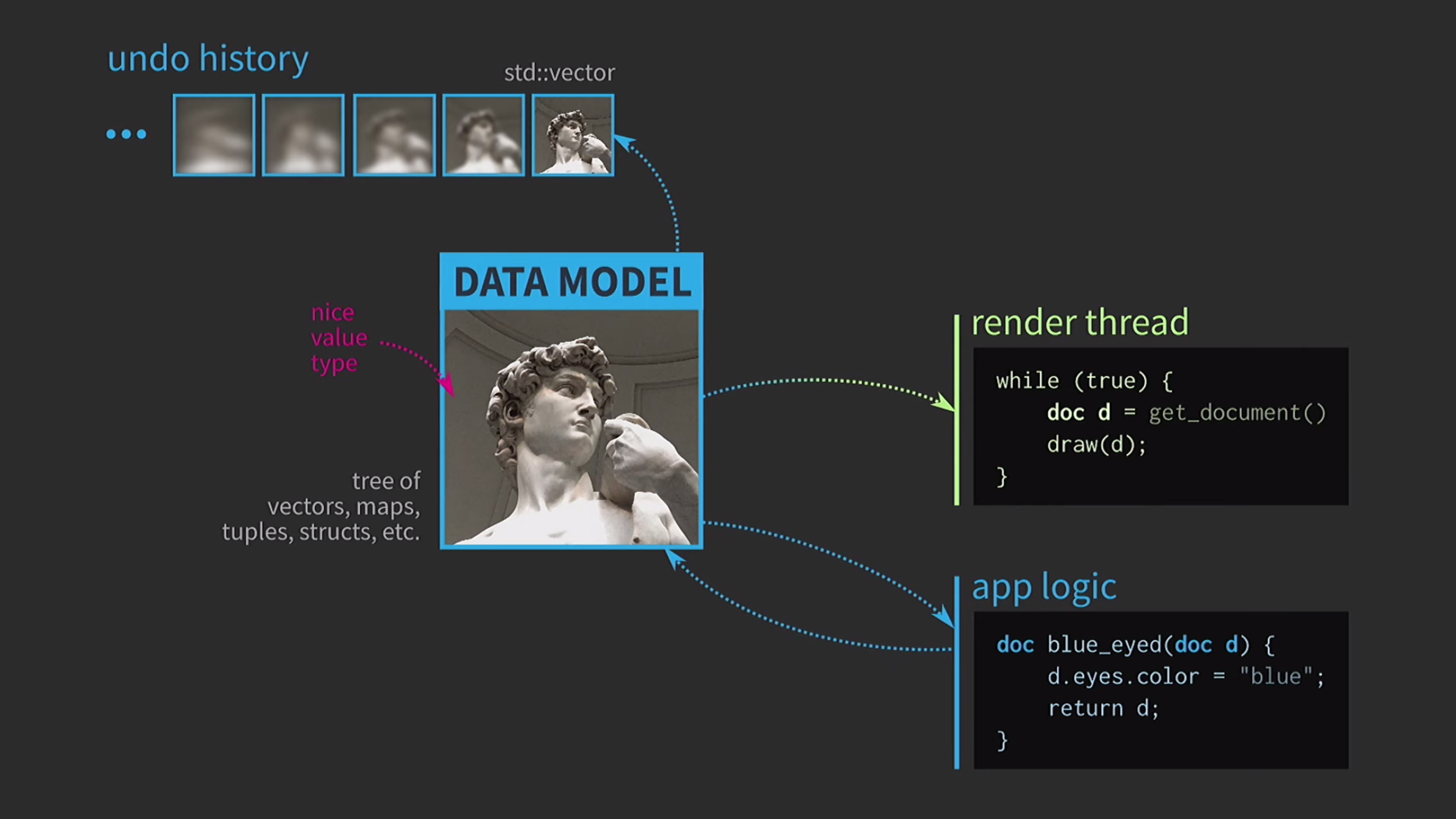 Misalkan kita juga memiliki UI, dan untuk memastikan responsifnya, pemetaan UI perlu dilakukan di utas terpisah. Dokumen dikirim ke aliran lain melalui pesan, dan interaksi juga terjadi berdasarkan pesan, dan bukan melalui pembagian penggunaan negara
Misalkan kita juga memiliki UI, dan untuk memastikan responsifnya, pemetaan UI perlu dilakukan di utas terpisah. Dokumen dikirim ke aliran lain melalui pesan, dan interaksi juga terjadi berdasarkan pesan, dan bukan melalui pembagian penggunaan negara mutexes. Ketika salinan diterima oleh aliran kedua, di sana Anda dapat melakukan semua operasi yang diperlukan. Menyimpan dokumen ke disk seringkali sangat lambat, terutama jika dokumen itu besar. Oleh karena itu, menggunakan
Menyimpan dokumen ke disk seringkali sangat lambat, terutama jika dokumen itu besar. Oleh karena itu, menggunakan std::asyncoperasi ini dilakukan secara tidak sinkron. Kami menggunakan lambda, menaruh tanda sama di dalamnya untuk memiliki salinan, dan sekarang Anda dapat menyimpan tanpa jenis sinkronisasi primitif lainnya.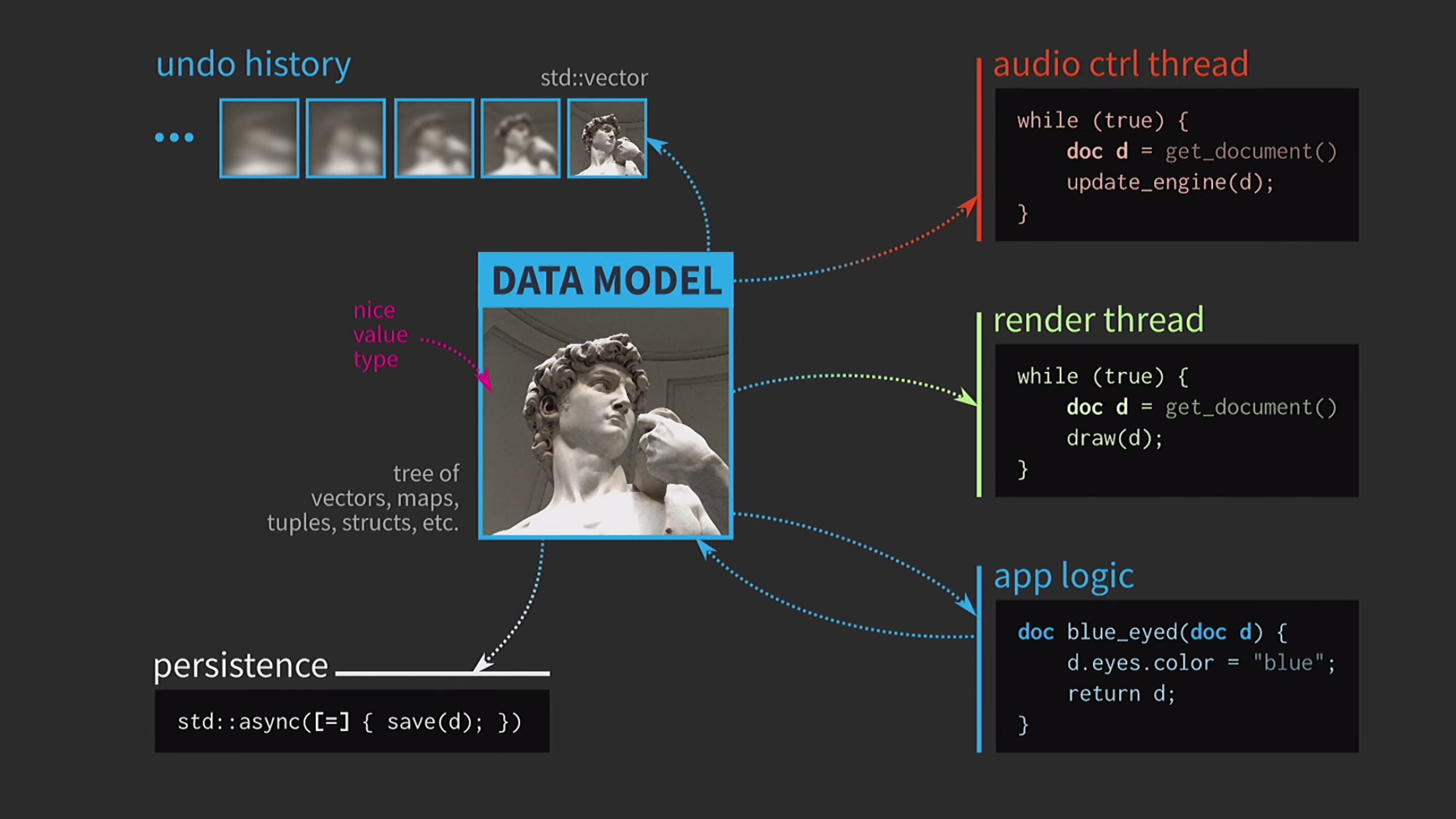 Selanjutnya, anggaplah kita juga memiliki aliran kontrol suara. Seperti yang saya katakan, saya banyak bekerja dengan perangkat lunak musik, dan suara adalah representasi lain dari dokumen kami, harus dalam aliran yang terpisah. Oleh karena itu, salinan dokumen juga diperlukan untuk aliran ini.Hasilnya, kami mendapat skema yang sangat indah, tetapi tidak terlalu realistis.
Selanjutnya, anggaplah kita juga memiliki aliran kontrol suara. Seperti yang saya katakan, saya banyak bekerja dengan perangkat lunak musik, dan suara adalah representasi lain dari dokumen kami, harus dalam aliran yang terpisah. Oleh karena itu, salinan dokumen juga diperlukan untuk aliran ini.Hasilnya, kami mendapat skema yang sangat indah, tetapi tidak terlalu realistis.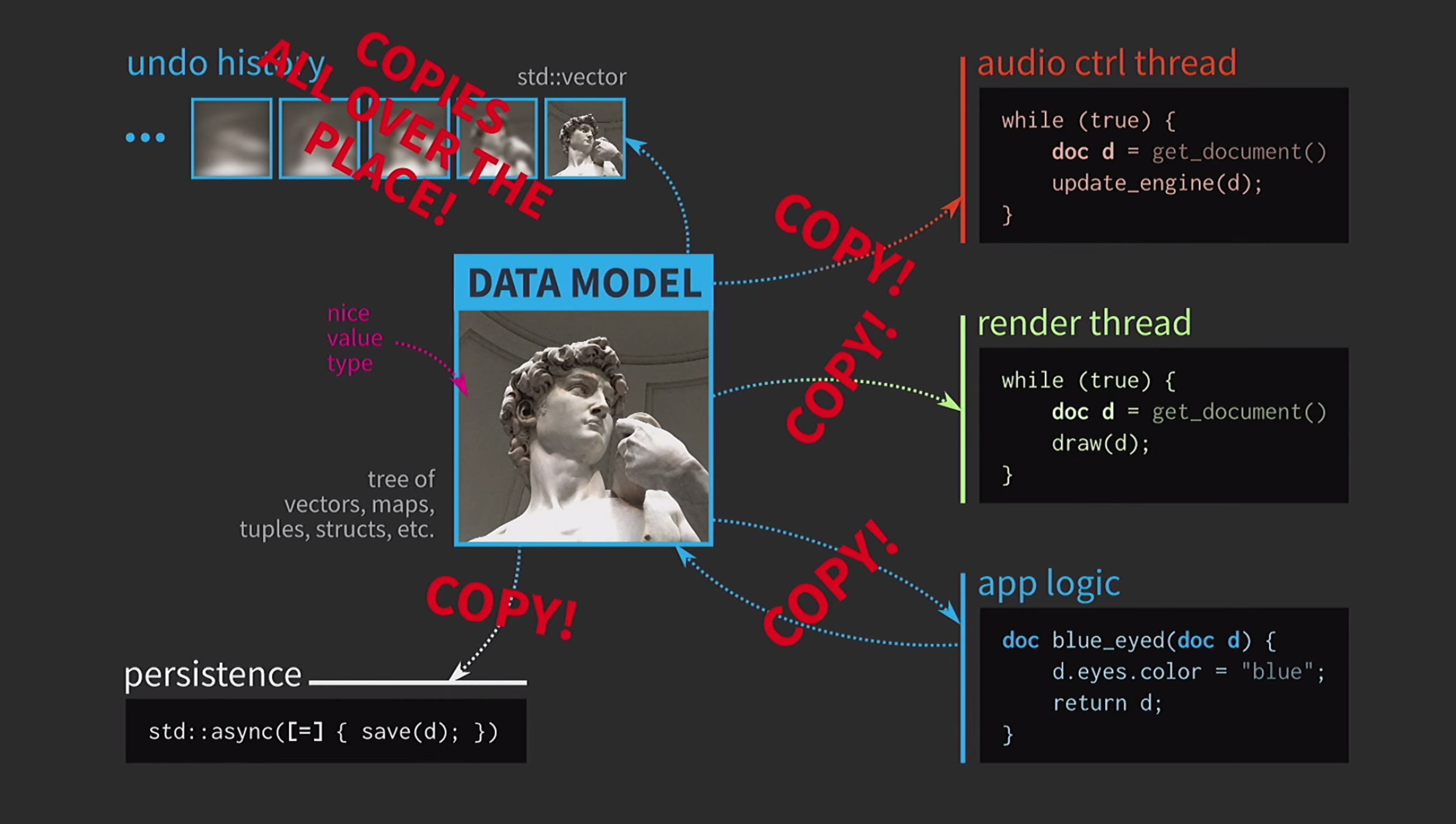 Selalu harus menyalin dokumen, riwayat tindakan untuk pembatalan membutuhkan gigabytes, dan untuk setiap rendering UI Anda perlu membuat salinan dokumen yang dalam. Secara umum, semua interaksi terlalu mahal.
Selalu harus menyalin dokumen, riwayat tindakan untuk pembatalan membutuhkan gigabytes, dan untuk setiap rendering UI Anda perlu membuat salinan dokumen yang dalam. Secara umum, semua interaksi terlalu mahal.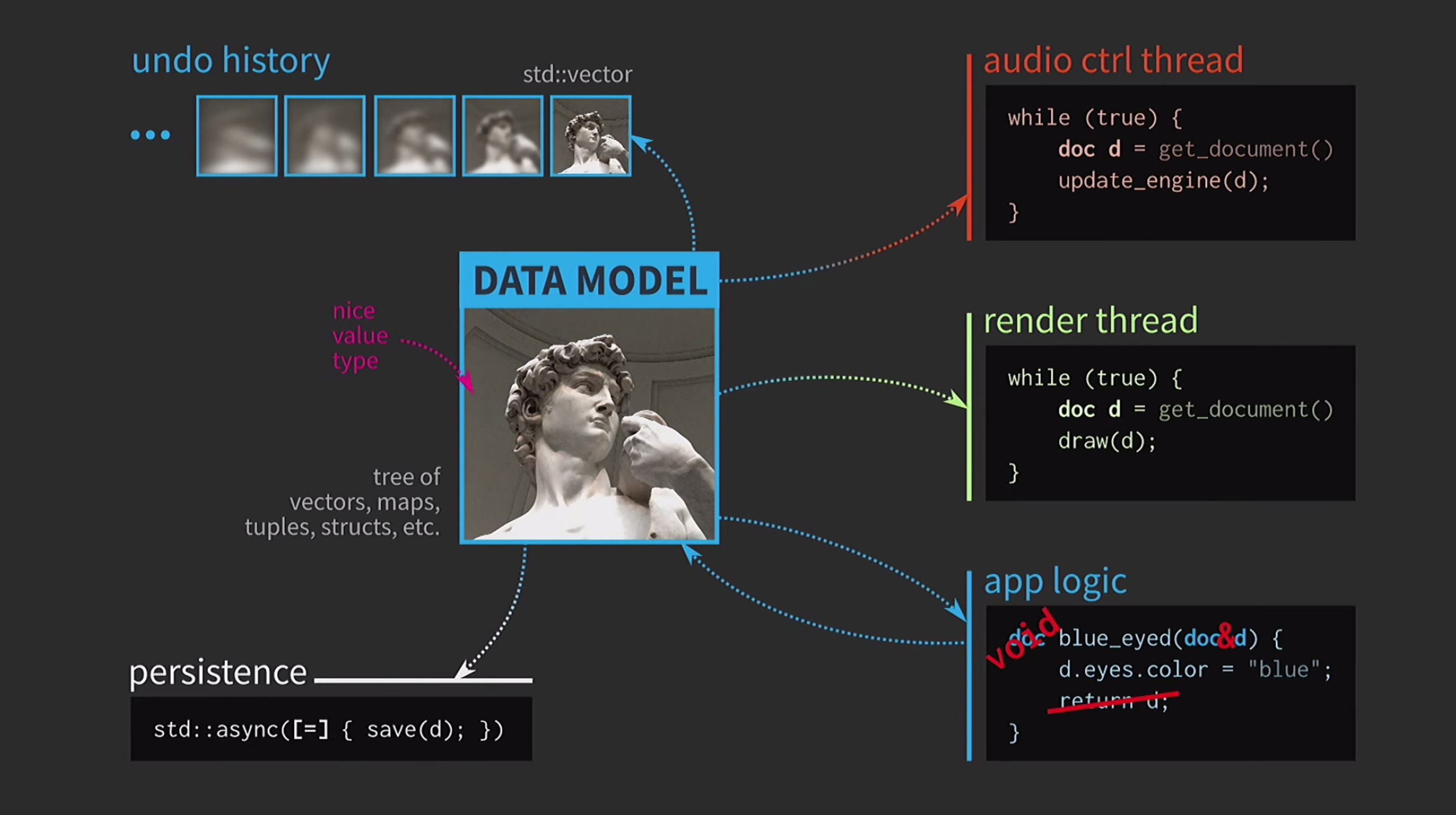 Apa yang dilakukan pengembang C ++ dalam situasi ini? Alih-alih menerima dokumen berdasarkan nilai, logika aplikasi sekarang menerima tautan ke dokumen dan memutakhirkannya jika perlu. Dalam hal ini, Anda tidak perlu mengembalikan apa pun. Tetapi sekarang kita tidak berurusan dengan nilai, tetapi dengan objek dan lokasi. Ini menciptakan masalah baru: jika ada tautan ke negara bagian dengan akses bersama, Anda memerlukannya
Apa yang dilakukan pengembang C ++ dalam situasi ini? Alih-alih menerima dokumen berdasarkan nilai, logika aplikasi sekarang menerima tautan ke dokumen dan memutakhirkannya jika perlu. Dalam hal ini, Anda tidak perlu mengembalikan apa pun. Tetapi sekarang kita tidak berurusan dengan nilai, tetapi dengan objek dan lokasi. Ini menciptakan masalah baru: jika ada tautan ke negara bagian dengan akses bersama, Anda memerlukannya mutex. Ini sangat mahal, sehingga akan ada beberapa representasi UI kami dalam bentuk pohon yang sangat kompleks dari berbagai Widget.Semua elemen ini harus menerima pembaruan ketika dokumen berubah, sehingga beberapa mekanisme antrian diperlukan untuk mengubah sinyal. Lebih jauh, sejarah dokumen tidak lagi merupakan set negara, melainkan akan menjadi implementasi dari pola Tim. Operasi harus dilaksanakan dua kali, dalam satu arah dan dalam yang lain, dan memastikan bahwa semuanya simetris. Menyimpan di utas terpisah sudah terlalu sulit, jadi ini harus ditinggalkan.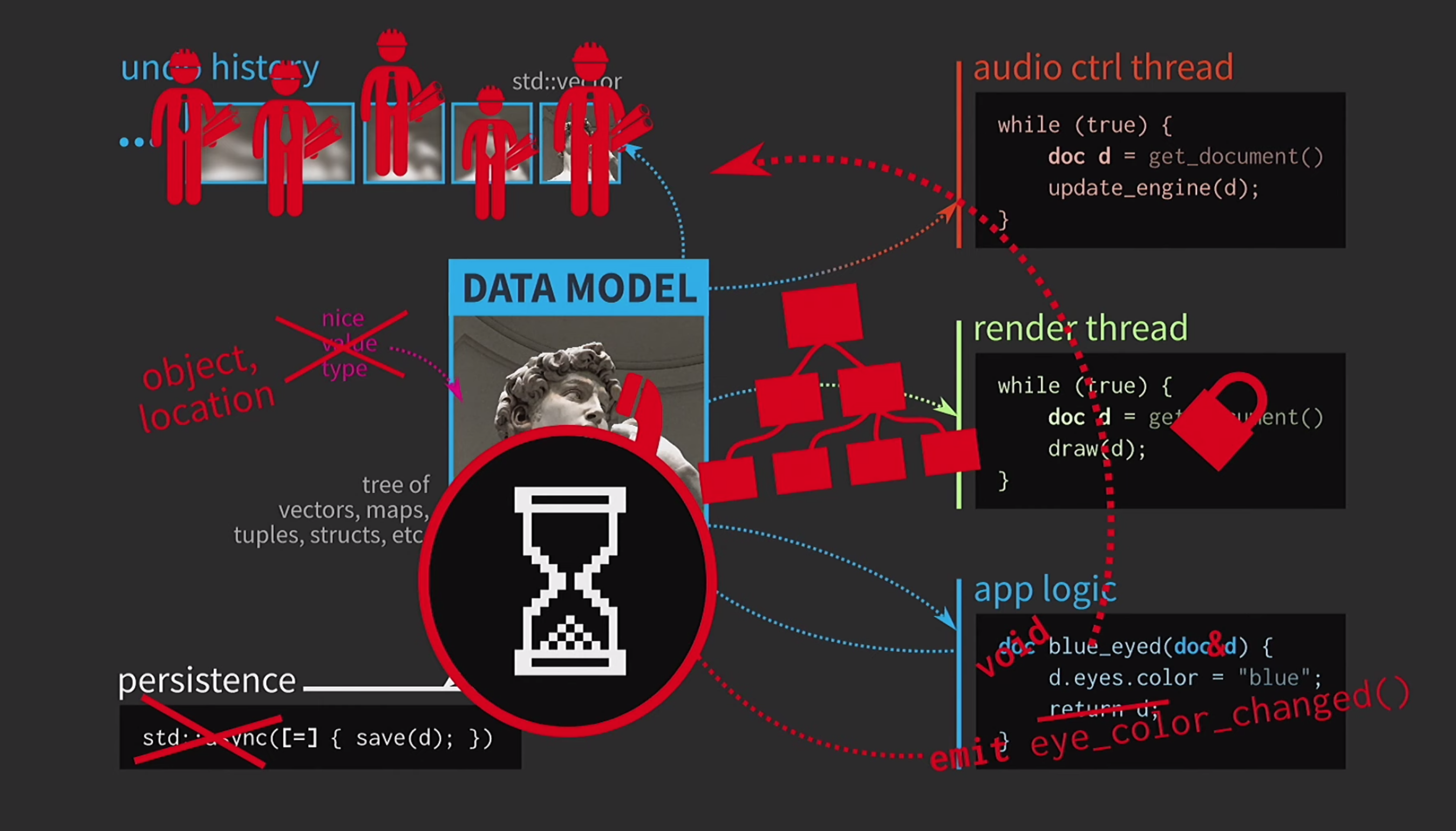 Pengguna sudah terbiasa dengan gambar jam pasir, jadi tidak apa-apa jika mereka menunggu sebentar. Hal lain yang menakutkan - monster pasta sekarang mengatur kode kita.Pada titik apa semuanya menjadi menurun? Kami merancang kode kami dengan sangat baik, dan kemudian kami harus berkompromi karena menyalin. Namun dalam C ++, penyalinan diperlukan untuk memberikan nilai hanya untuk data yang dapat diubah. Jika objek tidak berubah, maka operator penugasan dapat diimplementasikan sehingga hanya menyalin pointer ke representasi internal dan tidak lebih.
Pengguna sudah terbiasa dengan gambar jam pasir, jadi tidak apa-apa jika mereka menunggu sebentar. Hal lain yang menakutkan - monster pasta sekarang mengatur kode kita.Pada titik apa semuanya menjadi menurun? Kami merancang kode kami dengan sangat baik, dan kemudian kami harus berkompromi karena menyalin. Namun dalam C ++, penyalinan diperlukan untuk memberikan nilai hanya untuk data yang dapat diubah. Jika objek tidak berubah, maka operator penugasan dapat diimplementasikan sehingga hanya menyalin pointer ke representasi internal dan tidak lebih.const auto v0 = vector<int>{};
Pertimbangkan struktur data yang dapat membantu kami. Dalam vektor di bawah ini, semua metode ditandai sebagai const, sehingga tidak dapat diubah. Pada eksekusi .push_back, vektor tidak memperbarui, sebaliknya, vektor baru dikembalikan, ke mana data yang ditransfer ditambahkan. Sayangnya, kami tidak dapat menggunakan tanda kurung siku dengan pendekatan ini karena cara mereka didefinisikan. Sebagai gantinya, Anda dapat menggunakan fungsi ini.setyang mengembalikan versi baru dengan item yang diperbarui. Struktur data kami sekarang memiliki properti yang disebut kegigihan dalam pemrograman fungsional. Itu berarti bukan bahwa kita menyimpan struktur data ini ke hard drive, tetapi fakta bahwa ketika diperbarui, konten lama tidak dihapus - sebagai gantinya, garpu baru dunia kita dibuat, yaitu struktur. Berkat ini, kita dapat membandingkan nilai masa lalu dengan sekarang - ini dilakukan dengan bantuan dua assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
Perubahan sekarang dapat langsung diperiksa, mereka tidak lagi sifat tersembunyi dari struktur data. Fitur ini sangat berharga dalam sistem interaktif di mana kami harus selalu mengubah data.Properti penting lainnya adalah pembagian struktural. Sekarang kami tidak menyalin semua data untuk setiap versi baru dari struktur data. Bahkan dengan .push_backdan.settidak semua data disalin, tetapi hanya sebagian kecil saja. Semua garpu kami memiliki akses umum ke tampilan ringkas, yang proporsional dengan jumlah perubahan, bukan jumlah salinan. Ini juga mengikuti perbandingan yang sangat cepat: jika semuanya disimpan dalam satu blok memori, dalam satu pointer, maka Anda dapat dengan mudah membandingkan pointer dan tidak memeriksa elemen yang ada di dalamnya, jika mereka sama.Sejak vektor seperti itu, menurut saya, sangat berguna, Aku diimplementasikan di perpustakaan terpisah: ini adalah immer - perpustakaan struktur berubah, sebuah proyek open source.Saat menulisnya, saya ingin penggunaannya agar tidak asing bagi pengembang C ++. Ada banyak perpustakaan yang menerapkan konsep pemrograman fungsional dalam C ++, tetapi memberi kesan bahwa pengembang menulis untuk Haskell, bukan untuk C ++. Ini menciptakan ketidaknyamanan. Selain itu, saya mencapai kinerja yang baik. Orang-orang menggunakan C ++ ketika sumber daya yang tersedia terbatas. Akhirnya, saya ingin perpustakaan disesuaikan. Persyaratan ini terkait dengan persyaratan kinerja.Mencari vektor sihir
Pada bagian kedua dari laporan ini, kami akan mempertimbangkan bagaimana vektor tidak berubah ini terstruktur. Cara termudah untuk memahami prinsip-prinsip struktur data seperti itu adalah dengan memulai dengan daftar reguler. Jika Anda sedikit terbiasa dengan pemrograman fungsional (menggunakan Lisp atau Haskell sebagai contoh), Anda tahu bahwa daftar adalah struktur data abadi yang paling umum.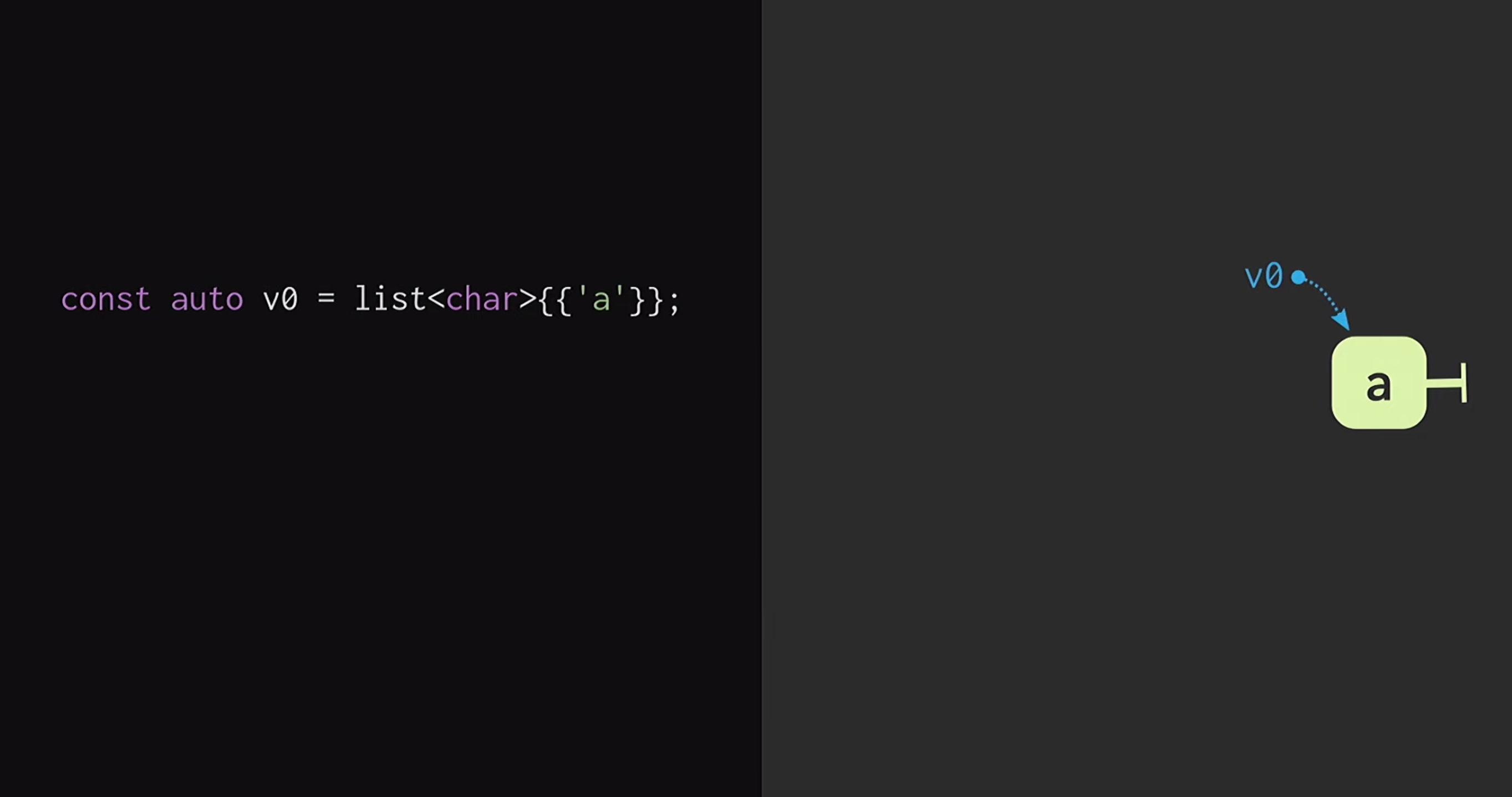 Untuk memulai, mari kita asumsikan bahwa kita memiliki daftar dengan satu simpul
Untuk memulai, mari kita asumsikan bahwa kita memiliki daftar dengan satu simpul v1mereka v0menunjukkan elemen yang berbeda.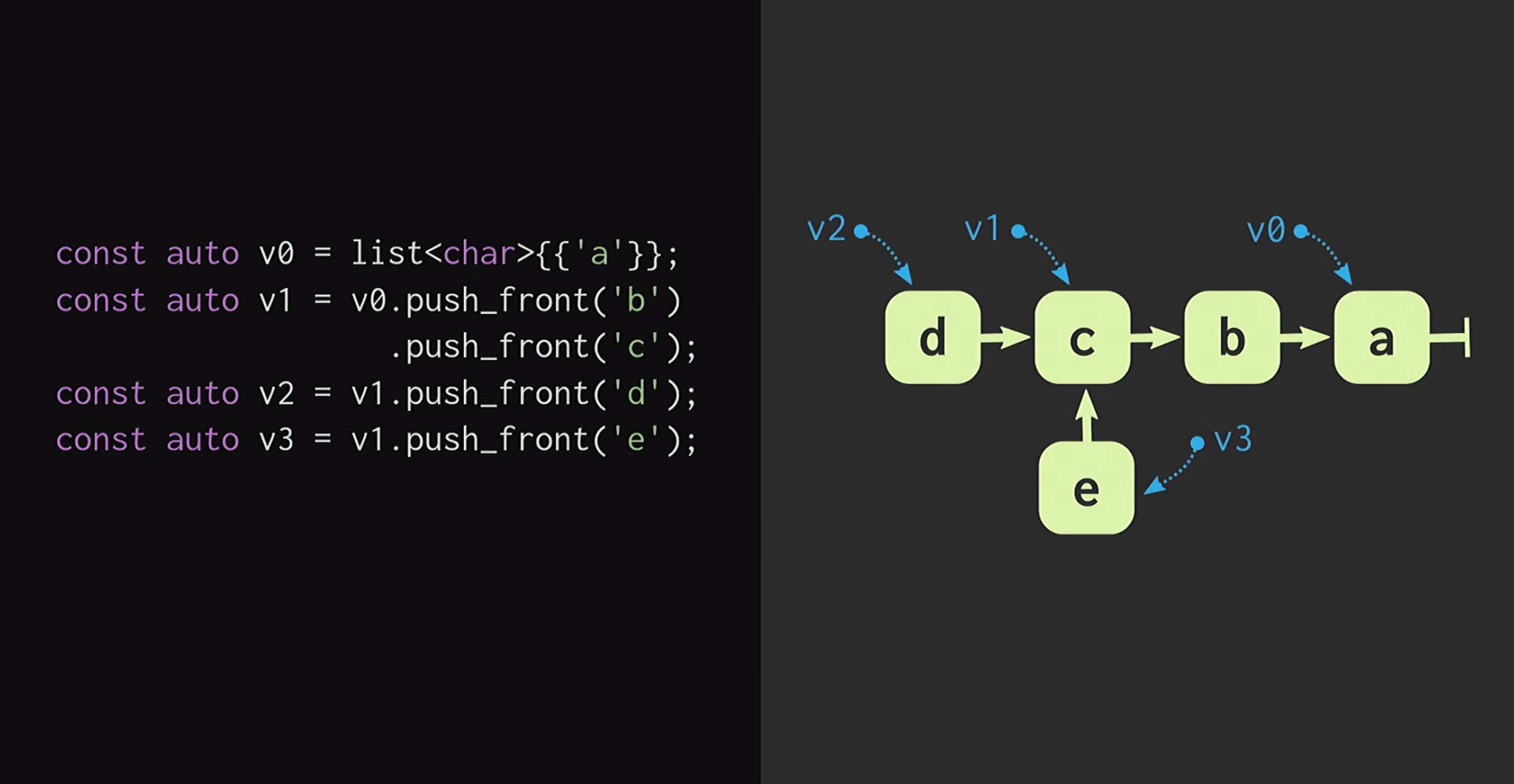 Kita juga dapat membuat garpu realitas, yaitu, membuat daftar baru yang memiliki akhir yang sama, tetapi awal yang berbeda.Struktur data seperti itu telah dipelajari untuk waktu yang lama: Chris Okasaki menulis karya mendasar Struktur Data Murni Fungsional . Selain itu, struktur data Finger Tree yang diajukan oleh Ralf Hinze dan Ross Paterson sangat menarik . Tetapi untuk C ++, struktur data seperti itu tidak berfungsi dengan baik. Mereka menggunakan node kecil, dan kita tahu bahwa di C ++ node kecil berarti kurangnya efisiensi caching.Selain itu, mereka sering mengandalkan properti yang tidak dimiliki C ++, seperti kemalasan. Oleh karena itu, karya Phil Bagwell tentang struktur data yang tidak berubah jauh lebih bermanfaat bagi kita - tautan yang ditulis pada awal 2000-an, serta karya Rich Hickey - tautan, penulis Clojure. Rich Hickey membuat daftar, yang sebenarnya bukan daftar, tetapi berdasarkan pada struktur data modern: vektor dan peta hash. Struktur data ini memiliki efisiensi caching dan berinteraksi dengan baik dengan prosesor modern, yang tidak diinginkan untuk bekerja dengan node kecil. Struktur seperti itu dapat digunakan dalam C ++.Bagaimana cara membangun vektor kekebalan? Di jantung struktur apa pun, bahkan yang menyerupai vektor, harus ada array. Tetapi array tidak memiliki pembagian struktural. Untuk mengubah elemen array apa pun, tanpa kehilangan properti persistensi, Anda harus menyalin seluruh array. Agar tidak melakukan ini, array dapat dibagi menjadi beberapa bagian terpisah.Sekarang, ketika memperbarui elemen vektor, kita hanya perlu menyalin satu bagian, dan bukan seluruh vektor. Tetapi potongan-potongan itu sendiri bukanlah struktur data, mereka harus digabungkan dengan satu atau lain cara. Tempatkan mereka di array lain. Sekali lagi, muncul masalah bahwa array bisa sangat besar, dan kemudian menyalinnya lagi akan memakan waktu terlalu banyak.Kami membagi array ini menjadi beberapa bagian, menempatkannya kembali dalam array yang terpisah, dan ulangi prosedur ini hingga hanya ada satu array root. Struktur yang dihasilkan disebut pohon sisa. Pohon ini dijelaskan oleh konstanta M = 2B, yaitu faktor percabangan. Indikator cabang ini harusnya kekuatan dua, dan kami akan segera mencari tahu mengapa. Dalam contoh pada slide, blok empat karakter digunakan, tetapi dalam praktiknya, blok 32 karakter digunakan. Ada eksperimen yang dengannya Anda dapat menemukan ukuran blok optimal untuk arsitektur tertentu. Ini memungkinkan Anda untuk mencapai rasio terbaik dari akses struktural bersama terhadap waktu akses: semakin rendah pohon, semakin sedikit waktu akses.Membaca ini, pengembang menulis dalam C ++ mungkin berpikir: tetapi struktur berbasis pohon sangat lambat! Pohon tumbuh dengan peningkatan jumlah elemen di dalamnya, dan karena ini, waktu akses terdegradasi. Itu sebabnya programmer lebih suka
Kita juga dapat membuat garpu realitas, yaitu, membuat daftar baru yang memiliki akhir yang sama, tetapi awal yang berbeda.Struktur data seperti itu telah dipelajari untuk waktu yang lama: Chris Okasaki menulis karya mendasar Struktur Data Murni Fungsional . Selain itu, struktur data Finger Tree yang diajukan oleh Ralf Hinze dan Ross Paterson sangat menarik . Tetapi untuk C ++, struktur data seperti itu tidak berfungsi dengan baik. Mereka menggunakan node kecil, dan kita tahu bahwa di C ++ node kecil berarti kurangnya efisiensi caching.Selain itu, mereka sering mengandalkan properti yang tidak dimiliki C ++, seperti kemalasan. Oleh karena itu, karya Phil Bagwell tentang struktur data yang tidak berubah jauh lebih bermanfaat bagi kita - tautan yang ditulis pada awal 2000-an, serta karya Rich Hickey - tautan, penulis Clojure. Rich Hickey membuat daftar, yang sebenarnya bukan daftar, tetapi berdasarkan pada struktur data modern: vektor dan peta hash. Struktur data ini memiliki efisiensi caching dan berinteraksi dengan baik dengan prosesor modern, yang tidak diinginkan untuk bekerja dengan node kecil. Struktur seperti itu dapat digunakan dalam C ++.Bagaimana cara membangun vektor kekebalan? Di jantung struktur apa pun, bahkan yang menyerupai vektor, harus ada array. Tetapi array tidak memiliki pembagian struktural. Untuk mengubah elemen array apa pun, tanpa kehilangan properti persistensi, Anda harus menyalin seluruh array. Agar tidak melakukan ini, array dapat dibagi menjadi beberapa bagian terpisah.Sekarang, ketika memperbarui elemen vektor, kita hanya perlu menyalin satu bagian, dan bukan seluruh vektor. Tetapi potongan-potongan itu sendiri bukanlah struktur data, mereka harus digabungkan dengan satu atau lain cara. Tempatkan mereka di array lain. Sekali lagi, muncul masalah bahwa array bisa sangat besar, dan kemudian menyalinnya lagi akan memakan waktu terlalu banyak.Kami membagi array ini menjadi beberapa bagian, menempatkannya kembali dalam array yang terpisah, dan ulangi prosedur ini hingga hanya ada satu array root. Struktur yang dihasilkan disebut pohon sisa. Pohon ini dijelaskan oleh konstanta M = 2B, yaitu faktor percabangan. Indikator cabang ini harusnya kekuatan dua, dan kami akan segera mencari tahu mengapa. Dalam contoh pada slide, blok empat karakter digunakan, tetapi dalam praktiknya, blok 32 karakter digunakan. Ada eksperimen yang dengannya Anda dapat menemukan ukuran blok optimal untuk arsitektur tertentu. Ini memungkinkan Anda untuk mencapai rasio terbaik dari akses struktural bersama terhadap waktu akses: semakin rendah pohon, semakin sedikit waktu akses.Membaca ini, pengembang menulis dalam C ++ mungkin berpikir: tetapi struktur berbasis pohon sangat lambat! Pohon tumbuh dengan peningkatan jumlah elemen di dalamnya, dan karena ini, waktu akses terdegradasi. Itu sebabnya programmer lebih suka std::unordered_map, daripada std::map. Saya segera meyakinkan Anda: pohon kami tumbuh sangat lambat. Vektor yang berisi semua nilai yang mungkin dari int 32-bit hanya memiliki 7 level. Dapat ditunjukkan secara eksperimental bahwa dengan ukuran data ini, rasio cache ke volume beban secara signifikan mempengaruhi kinerja daripada kedalaman pohon.Mari kita lihat bagaimana akses ke elemen pohon dilakukan. Misalkan Anda perlu beralih ke elemen 17. Kami mengambil representasi biner dari indeks dan membaginya menjadi kelompok-kelompok ukuran faktor percabangan. Di setiap grup, kami menggunakan nilai biner yang sesuai dan dengan demikian turun pohon.Selanjutnya, misalkan kita perlu membuat perubahan dalam struktur data ini, yaitu, jalankan metode
Di setiap grup, kami menggunakan nilai biner yang sesuai dan dengan demikian turun pohon.Selanjutnya, misalkan kita perlu membuat perubahan dalam struktur data ini, yaitu, jalankan metode .set.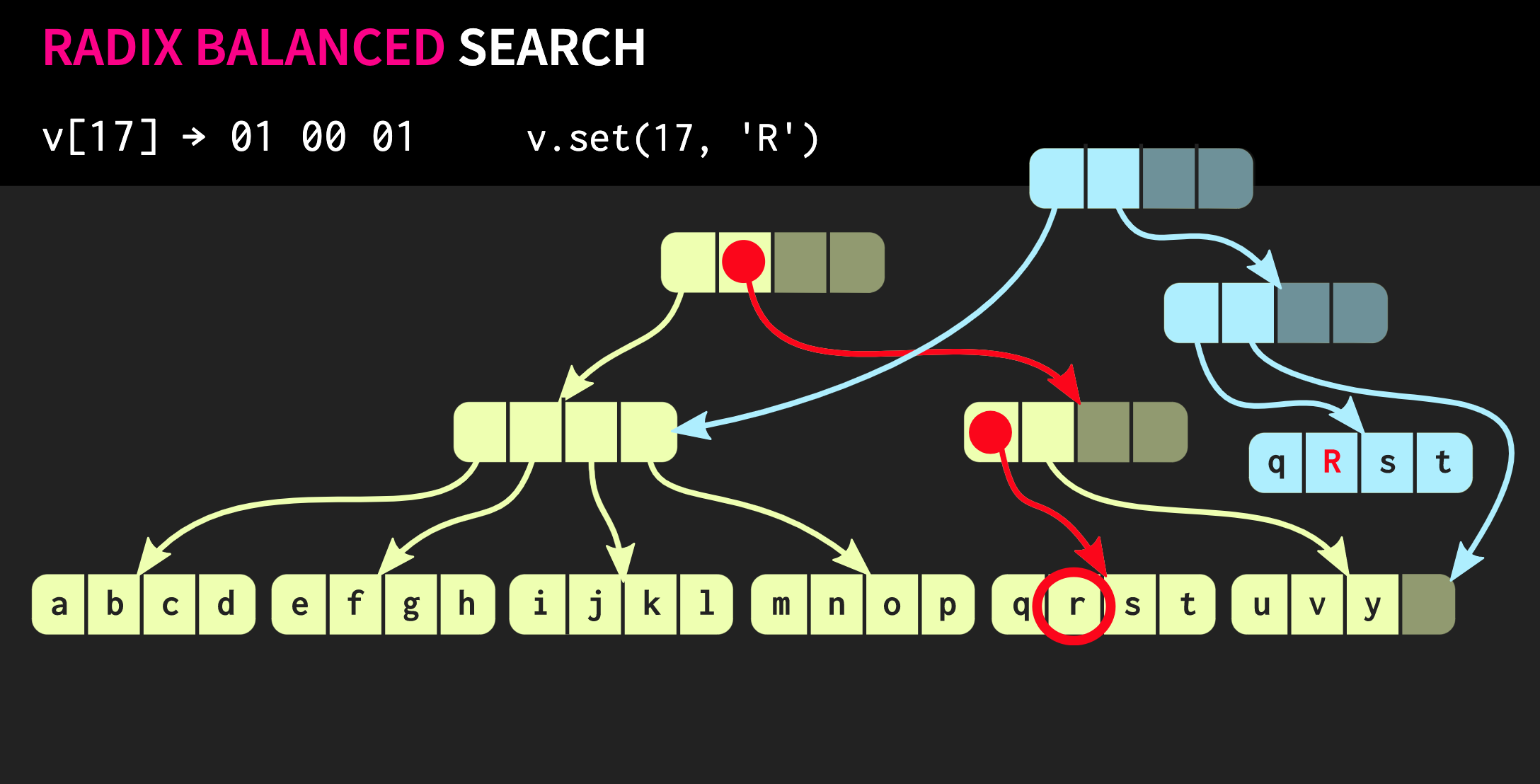 Untuk melakukan ini, pertama-tama Anda perlu menyalin blok di mana elemen itu berada, dan kemudian salin setiap node internal dalam perjalanan ke elemen. Di satu sisi, cukup banyak data yang harus disalin, tetapi pada saat yang sama sebagian besar dari data ini adalah umum, ini mengkompensasi volume mereka.Omong-omong, ada struktur data yang jauh lebih tua yang sangat mirip dengan yang saya jelaskan. Ini adalah halaman memori dengan bagan tabel halaman. Manajemennya juga dilakukan menggunakan panggilan
Untuk melakukan ini, pertama-tama Anda perlu menyalin blok di mana elemen itu berada, dan kemudian salin setiap node internal dalam perjalanan ke elemen. Di satu sisi, cukup banyak data yang harus disalin, tetapi pada saat yang sama sebagian besar dari data ini adalah umum, ini mengkompensasi volume mereka.Omong-omong, ada struktur data yang jauh lebih tua yang sangat mirip dengan yang saya jelaskan. Ini adalah halaman memori dengan bagan tabel halaman. Manajemennya juga dilakukan menggunakan panggilan fork.Mari kita coba memperbaiki struktur data kita. Misalkan kita perlu menghubungkan dua vektor. Struktur data yang dijelaskan sejauh ini memiliki keterbatasan yang sama std::vector:karena memiliki sel kosong di bagian paling kanannya. Karena strukturnya seimbang sempurna, sel-sel kosong ini tidak mungkin berada di tengah pohon. Oleh karena itu, jika ada vektor kedua yang ingin kita gabungkan dengan yang pertama, kita perlu menyalin elemen ke dalam sel kosong, yang akan membuat sel kosong di vektor kedua, dan pada akhirnya kita harus menyalin seluruh vektor kedua. Operasi semacam itu memiliki kompleksitas komputasi O (n), di mana n adalah ukuran vektor kedua.Kami akan berusaha mencapai hasil yang lebih baik. Ada versi modifikasi dari struktur data kami yang disebut pohon santai radix seimbang. Dalam struktur ini, node yang tidak di jalur paling kiri mungkin memiliki sel kosong. Oleh karena itu, dalam simpul yang tidak lengkap (atau santai), perlu untuk menghitung ukuran subtree. Sekarang Anda dapat melakukan operasi gabungan yang kompleks tetapi logaritmik. Operasi dengan kompleksitas waktu konstan ini adalah O (log (32)). Karena pohonnya dangkal, waktu aksesnya konstan, walaupun relatif lama. Karena kami memiliki operasi penyatuan, versi yang santai dari struktur data ini disebut confluent: selain persisten, dan Anda dapat menggunakannya, dua struktur tersebut dapat digabungkan menjadi satu.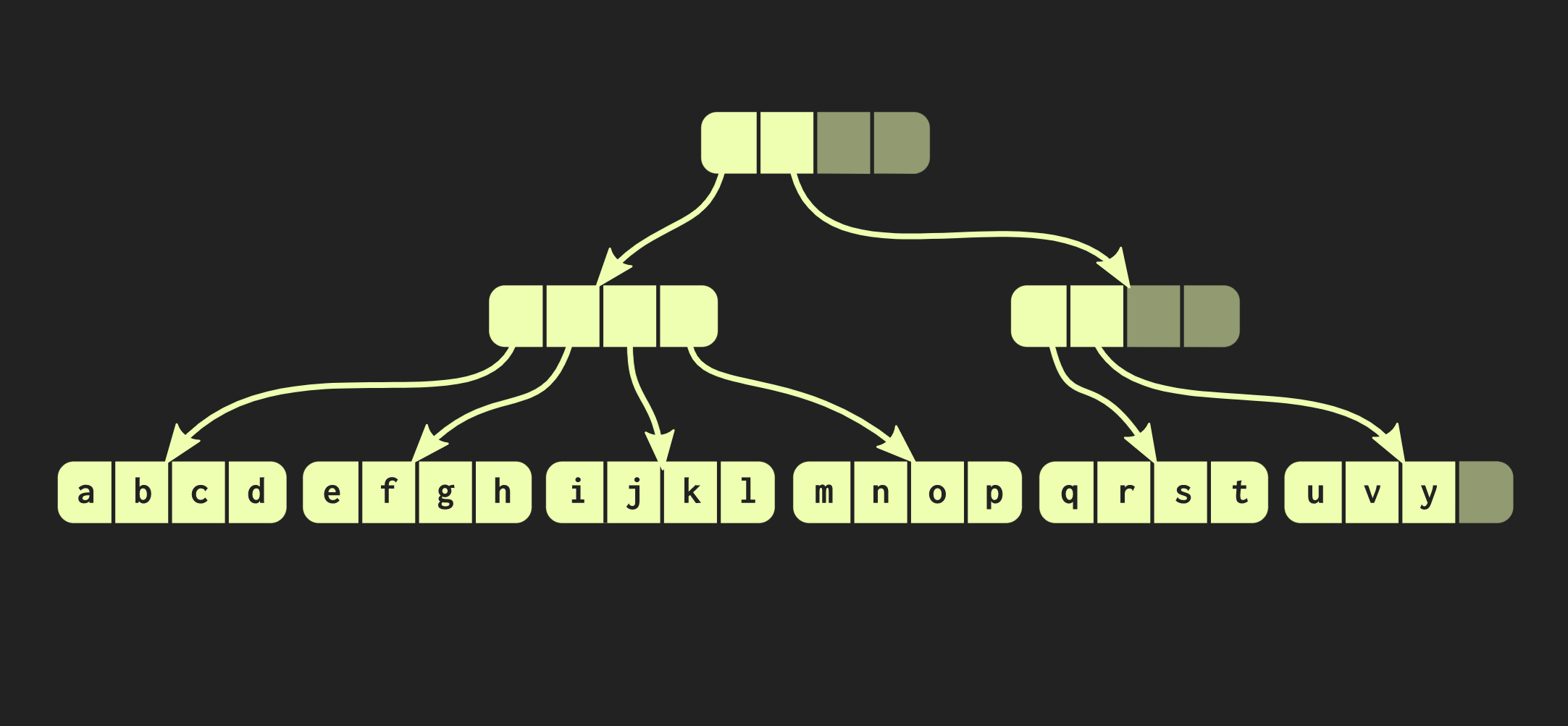 Dalam contoh yang telah kami kerjakan sejauh ini, struktur data sangat rapi, tetapi dalam praktiknya, implementasi di Clojure dan bahasa fungsional lainnya terlihat berbeda. Mereka membuat wadah untuk setiap nilai, yaitu, setiap elemen dalam vektor berada di sel yang terpisah, dan simpul daun berisi pointer ke elemen-elemen ini. Tetapi pendekatan ini sangat tidak efisien, dalam C ++ biasanya tidak memasukkan setiap nilai dalam sebuah wadah. Oleh karena itu, akan lebih baik jika elemen-elemen ini berada di node secara langsung. Kemudian masalah lain muncul: elemen yang berbeda memiliki ukuran yang berbeda. Jika elemen berukuran sama dengan pointer, struktur kami akan terlihat seperti yang ditunjukkan di bawah ini:
Dalam contoh yang telah kami kerjakan sejauh ini, struktur data sangat rapi, tetapi dalam praktiknya, implementasi di Clojure dan bahasa fungsional lainnya terlihat berbeda. Mereka membuat wadah untuk setiap nilai, yaitu, setiap elemen dalam vektor berada di sel yang terpisah, dan simpul daun berisi pointer ke elemen-elemen ini. Tetapi pendekatan ini sangat tidak efisien, dalam C ++ biasanya tidak memasukkan setiap nilai dalam sebuah wadah. Oleh karena itu, akan lebih baik jika elemen-elemen ini berada di node secara langsung. Kemudian masalah lain muncul: elemen yang berbeda memiliki ukuran yang berbeda. Jika elemen berukuran sama dengan pointer, struktur kami akan terlihat seperti yang ditunjukkan di bawah ini: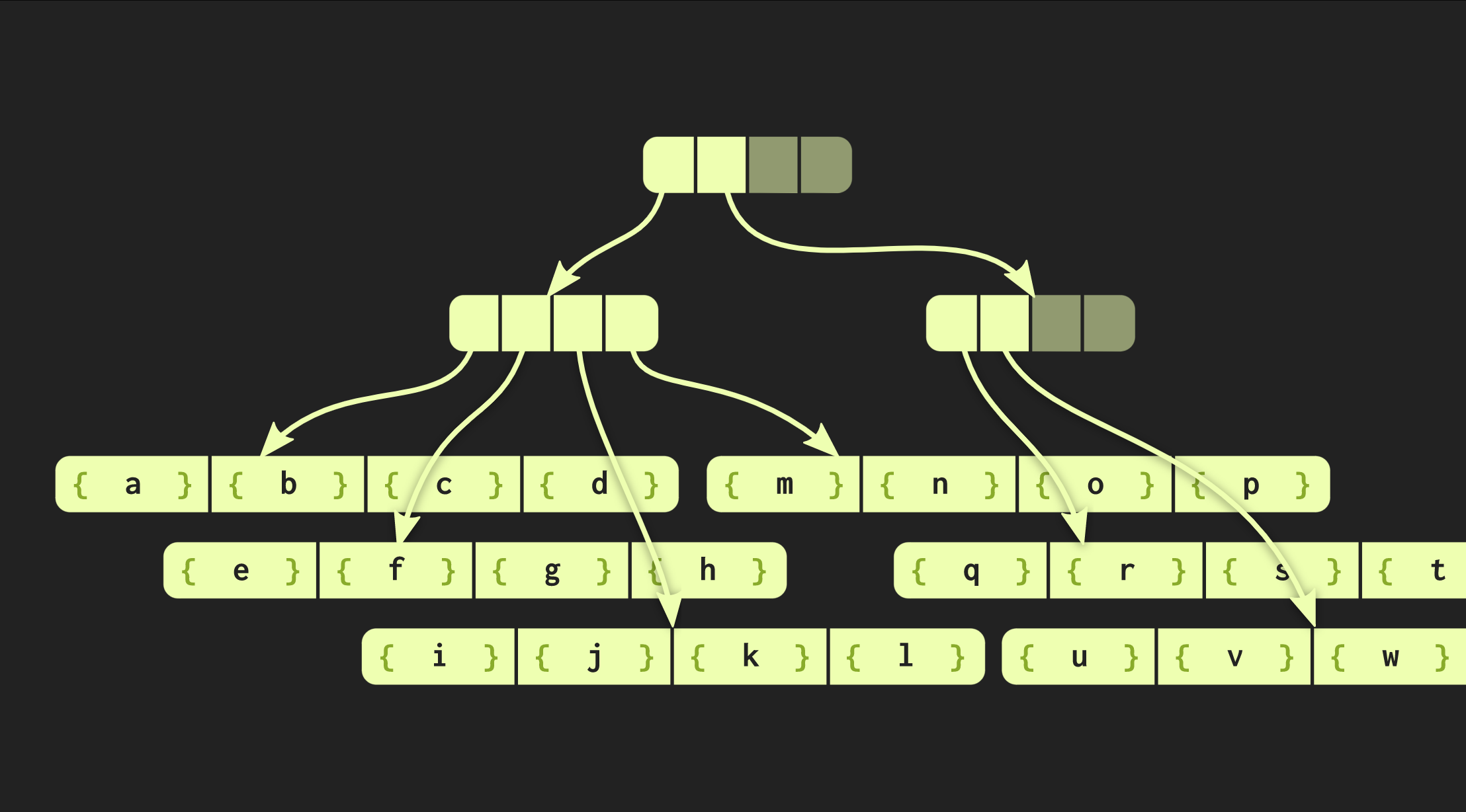 Tetapi jika elemen-elemennya besar, maka struktur data kehilangan properti yang kami ukur (waktu akses O (log (32) ()), karena menyalin satu lembar sekarang membutuhkan waktu lebih lama. Oleh karena itu, saya mengubah struktur data ini sehingga dengan bertambahnya ukuran jumlah elemen yang terkandung di dalamnya mengurangi jumlah elemen-elemen ini dalam simpul daun. Sebaliknya, jika elemen-elemen kecil, mereka sekarang dapat lebih cocok. Versi baru dari pohon ini disebut menanamkan pohon radix seimbang. Ini digambarkan bukan oleh satu konstanta, tetapi oleh dua: salah satunya menggambarkan node internal, dan daun kedua .. Implementasi pohon di C ++ dapat menghitung ukuran optimal elemen daun tergantung pada ukuran pointer dan elemen itu sendiri.Pohon kami sudah bekerja dengan cukup baik, tetapi masih bisa diperbaiki. Lihatlah fungsi yang mirip dengan fungsi
Tetapi jika elemen-elemennya besar, maka struktur data kehilangan properti yang kami ukur (waktu akses O (log (32) ()), karena menyalin satu lembar sekarang membutuhkan waktu lebih lama. Oleh karena itu, saya mengubah struktur data ini sehingga dengan bertambahnya ukuran jumlah elemen yang terkandung di dalamnya mengurangi jumlah elemen-elemen ini dalam simpul daun. Sebaliknya, jika elemen-elemen kecil, mereka sekarang dapat lebih cocok. Versi baru dari pohon ini disebut menanamkan pohon radix seimbang. Ini digambarkan bukan oleh satu konstanta, tetapi oleh dua: salah satunya menggambarkan node internal, dan daun kedua .. Implementasi pohon di C ++ dapat menghitung ukuran optimal elemen daun tergantung pada ukuran pointer dan elemen itu sendiri.Pohon kami sudah bekerja dengan cukup baik, tetapi masih bisa diperbaiki. Lihatlah fungsi yang mirip dengan fungsi iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
Dibutuhkan input vector, dijalankan push_backpada akhir vektor untuk setiap integer antara firstdan last, dan mengembalikan apa yang terjadi. Semuanya sesuai dengan kebenaran fungsi ini, tetapi berfungsi secara tidak efisien. Setiap panggilan push_backmenyalin blok paling kiri yang tidak perlu: panggilan berikutnya mendorong elemen lain dan salinan diulang lagi, dan data yang disalin oleh metode sebelumnya dihapus.Anda dapat mencoba implementasi lain dari fungsi ini, di mana kami meninggalkan kegigihan dalam fungsi tersebut. Dapat digunakan transient vectordengan API yang bisa berubah yang kompatibel dengan API reguler vector. Dalam fungsi seperti itu, setiap panggilan push_backmengubah struktur data.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
Implementasi ini lebih efisien, dan memungkinkan Anda untuk menggunakan kembali elemen baru di jalur yang benar. Di akhir fungsi, panggilan .persistent()dibuat yang mengembalikan kekal vector. Kemungkinan efek samping tetap tidak terlihat dari luar fungsi. Yang asli vectoradalah dan tetap tidak berubah, hanya data yang dibuat di dalam fungsi yang diubah. Seperti yang saya katakan, keuntungan penting dari pendekatan ini adalah Anda dapat menggunakan std::back_inserteralgoritma standar yang membutuhkan API yang bisa diubah.Pertimbangkan contoh lain.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
Fungsi tidak menerima dan kembali vector, tetapi rantai panggilan dijalankan di dalam push_back. Di sini, seperti dalam contoh sebelumnya, penyalinan yang tidak perlu di dalam panggilan dapat terjadi push_back. Perhatikan bahwa nilai pertama yang dieksekusi push_backadalah nilai yang dinamai, dan sisanya adalah nilai-r, yaitu tautan anonim. Jika Anda menggunakan penghitungan referensi, metode ini push_backdapat merujuk ke penghitung referensi untuk node yang memori dialokasikan di pohon. Dan dalam hal nilai-r, jika jumlah tautannya satu, menjadi jelas bahwa tidak ada bagian lain dari program yang mengakses node-node ini. Di sini kinerjanya persis sama seperti pada kasus dengan transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
Selanjutnya, untuk membantu kompiler, kita dapat mengeksekusinya move(v), karena vtidak digunakan di tempat lain dalam fungsi. Kami memiliki keuntungan penting, yang tidak ada dalam transientvarian: jika kami meneruskan nilai yang dikembalikan dari say_hi lain ke fungsi say_hi, maka tidak akan ada salinan tambahan. Dalam kasus c, transientada batas di mana penyalinan berlebih dapat terjadi. Dengan kata lain, kami memiliki struktur data yang persisten dan tidak dapat diubah, yang kinerjanya tergantung pada jumlah aktual dari akses bersama dalam runtime. Jika tidak ada pembagian, maka kinerjanya akan sama dengan struktur data yang bisa berubah. Ini adalah properti yang sangat penting. Contoh yang sudah saya tunjukkan di atas dapat ditulis ulang dengan metode move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
Sejauh ini kita telah berbicara tentang vektor, dan selain itu ada juga peta hash. Mereka didedikasikan untuk laporan yang sangat berguna oleh Phil Nash: Cawan Suci. Sebuah array hash dipetakan untuk C ++ . Ini menggambarkan tabel hash diimplementasikan berdasarkan prinsip yang sama yang baru saja saya bicarakan.Saya yakin banyak dari Anda memiliki keraguan tentang kinerja struktur seperti itu. Apakah mereka bekerja cepat dalam latihan? Saya telah melakukan banyak tes, dan singkatnya jawaban saya adalah ya. Jika Anda ingin mempelajari lebih lanjut tentang hasil tes, mereka diterbitkan dalam artikel saya untuk Konferensi Internasional Pemrograman Fungsional 2017. Sekarang, saya pikir, lebih baik untuk membahas bukan nilai absolut, tetapi efek struktur data ini terhadap sistem secara keseluruhan. Tentu saja, memperbarui vektor kami lebih lambat karena Anda perlu menyalin beberapa blok data dan mengalokasikan memori untuk data lain. Tetapi melewati vektor kita dilakukan pada kecepatan yang hampir sama dengan yang normal. Sangat penting bagi saya untuk mencapai ini, karena membaca data dilakukan jauh lebih sering daripada mengubahnya.Selain itu, karena pembaruan yang lebih lambat, tidak perlu menyalin apa pun, hanya struktur data yang disalin. Oleh karena itu, waktu yang dihabiskan untuk memperbarui vektor, seolah-olah, diamortisasi untuk semua salinan yang dilakukan dalam sistem. Oleh karena itu, jika Anda menerapkan struktur data ini dalam arsitektur yang mirip dengan yang saya jelaskan di awal laporan, kinerja akan meningkat secara signifikan.Ewig
Saya tidak akan berdasar dan menunjukkan struktur data saya menggunakan contoh. Saya menulis editor teks kecil. Ini adalah alat interaktif yang disebut ewig , di mana dokumen diwakili oleh vektor yang tidak berubah. Saya memiliki salinan seluruh Esperanto Wikipedia pada disk saya, beratnya 1 gigabyte (awalnya saya ingin mengunduh versi bahasa Inggris, tetapi terlalu besar). Apapun editor teks yang Anda gunakan, saya yakin dia tidak akan menyukai file ini. Dan ketika Anda mengunduh file ini di ewig , Anda dapat segera mengeditnya, karena unduhannya tidak sinkron. Navigasi file berfungsi, tidak ada yang hang, tidak mutex, tidak ada sinkronisasi. Seperti yang Anda lihat, file yang diunduh membutuhkan 20 juta baris kode.Sebelum mempertimbangkan properti paling penting dari alat ini, mari kita perhatikan detail lucu. Di awal baris, disorot dalam warna putih di bagian bawah gambar, Anda melihat dua tanda hubung. UI ini kemungkinan besar akrab bagi pengguna emacs; tanda hubung di sana berarti bahwa dokumen tersebut belum dimodifikasi dengan cara apa pun. Jika Anda melakukan perubahan, maka tanda bintang ditampilkan sebagai ganti tanda hubung. Tapi, tidak seperti editor lain, jika Anda menghapus perubahan ini di ewig (jangan urungkan, hapus saja), maka tanda hubung akan ditampilkan sebagai ganti tanda bintang karena semua versi teks sebelumnya disimpan dalam ewig . Berkat ini, bendera khusus tidak diperlukan untuk menunjukkan apakah dokumen telah diubah: keberadaan perubahan ditentukan oleh perbandingan dengan dokumen asli.Pertimbangkan properti lain yang menarik dari alat ini: salin seluruh teks dan tempelkan beberapa kali di tengah teks yang ada. Seperti yang Anda lihat, ini terjadi secara instan. Bergabung dengan vektor di sini adalah operasi logaritmik, dan logaritma jutaan orang bukanlah operasi yang panjang. Jika Anda mencoba menyimpan dokumen besar ini ke hard drive Anda, itu akan memakan waktu lebih lama, karena teks tidak lagi disajikan sebagai vektor yang diperoleh dari versi sebelumnya dari vektor ini. Saat menyimpan ke disk, serialisasi terjadi, sehingga kegigihan hilang.
Di awal baris, disorot dalam warna putih di bagian bawah gambar, Anda melihat dua tanda hubung. UI ini kemungkinan besar akrab bagi pengguna emacs; tanda hubung di sana berarti bahwa dokumen tersebut belum dimodifikasi dengan cara apa pun. Jika Anda melakukan perubahan, maka tanda bintang ditampilkan sebagai ganti tanda hubung. Tapi, tidak seperti editor lain, jika Anda menghapus perubahan ini di ewig (jangan urungkan, hapus saja), maka tanda hubung akan ditampilkan sebagai ganti tanda bintang karena semua versi teks sebelumnya disimpan dalam ewig . Berkat ini, bendera khusus tidak diperlukan untuk menunjukkan apakah dokumen telah diubah: keberadaan perubahan ditentukan oleh perbandingan dengan dokumen asli.Pertimbangkan properti lain yang menarik dari alat ini: salin seluruh teks dan tempelkan beberapa kali di tengah teks yang ada. Seperti yang Anda lihat, ini terjadi secara instan. Bergabung dengan vektor di sini adalah operasi logaritmik, dan logaritma jutaan orang bukanlah operasi yang panjang. Jika Anda mencoba menyimpan dokumen besar ini ke hard drive Anda, itu akan memakan waktu lebih lama, karena teks tidak lagi disajikan sebagai vektor yang diperoleh dari versi sebelumnya dari vektor ini. Saat menyimpan ke disk, serialisasi terjadi, sehingga kegigihan hilang.Kembali ke arsitektur berbasis nilai
 Mari kita mulai dengan bagaimana Anda tidak dapat kembali ke arsitektur ini: menggunakan Pengontrol, Model, dan Tampilan gaya Java yang biasa, yang paling sering digunakan untuk aplikasi interaktif di C ++. Tidak ada yang salah dengan mereka, tetapi mereka tidak cocok untuk masalah kita. Di satu sisi, pola Model-View-Controller memungkinkan untuk pemisahan tugas, tetapi di sisi lain, masing-masing elemen ini adalah objek, baik dari sudut pandang berorientasi objek dan dari sudut pandang C ++, yaitu, ini adalah area memori dengan bisa berubah kondisi. Lihat yang tahu tentang Model; yang jauh lebih buruk - Model secara tidak langsung tahu tentang View, karena hampir pasti ada panggilan balik yang melaluinya View diberitahu ketika Model berubah. Bahkan dengan penerapan prinsip-prinsip berorientasi objek terbaik, kami mendapatkan banyak ketergantungan timbal balik.
Mari kita mulai dengan bagaimana Anda tidak dapat kembali ke arsitektur ini: menggunakan Pengontrol, Model, dan Tampilan gaya Java yang biasa, yang paling sering digunakan untuk aplikasi interaktif di C ++. Tidak ada yang salah dengan mereka, tetapi mereka tidak cocok untuk masalah kita. Di satu sisi, pola Model-View-Controller memungkinkan untuk pemisahan tugas, tetapi di sisi lain, masing-masing elemen ini adalah objek, baik dari sudut pandang berorientasi objek dan dari sudut pandang C ++, yaitu, ini adalah area memori dengan bisa berubah kondisi. Lihat yang tahu tentang Model; yang jauh lebih buruk - Model secara tidak langsung tahu tentang View, karena hampir pasti ada panggilan balik yang melaluinya View diberitahu ketika Model berubah. Bahkan dengan penerapan prinsip-prinsip berorientasi objek terbaik, kami mendapatkan banyak ketergantungan timbal balik.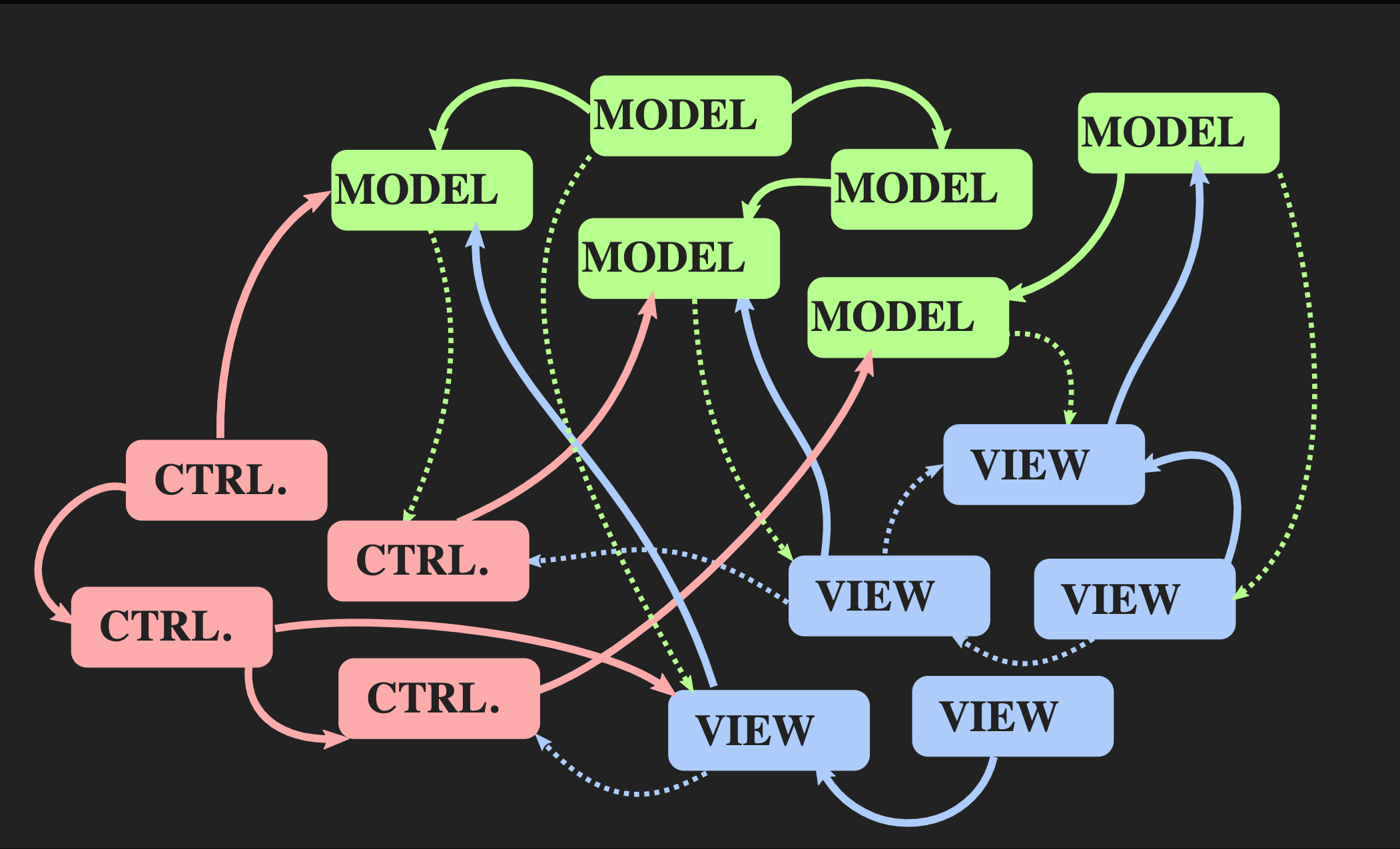 Seiring bertambahnya aplikasi dan Model, Pengendali, dan Tampilan baru ditambahkan, muncul situasi ketika, untuk mengubah segmen program, Anda perlu mengetahui tentang semua bagian yang terkait dengannya, tentang semua Tampilan yang menerima peringatan melalui
Seiring bertambahnya aplikasi dan Model, Pengendali, dan Tampilan baru ditambahkan, muncul situasi ketika, untuk mengubah segmen program, Anda perlu mengetahui tentang semua bagian yang terkait dengannya, tentang semua Tampilan yang menerima peringatan melalui callback, dll. Akibatnya, semua orang monster pasta yang akrab mulai mengintip melalui dependensi ini.Apakah arsitektur lain mungkin? Ada pendekatan alternatif untuk pola Model-View-Controller yang disebut "Arsitektur Aliran Data Unidirectional". Konsep ini tidak ditemukan oleh saya, cukup sering digunakan dalam pengembangan web. Di Facebook, ini disebut arsitektur Flux, tetapi di C ++, ini belum diterapkan.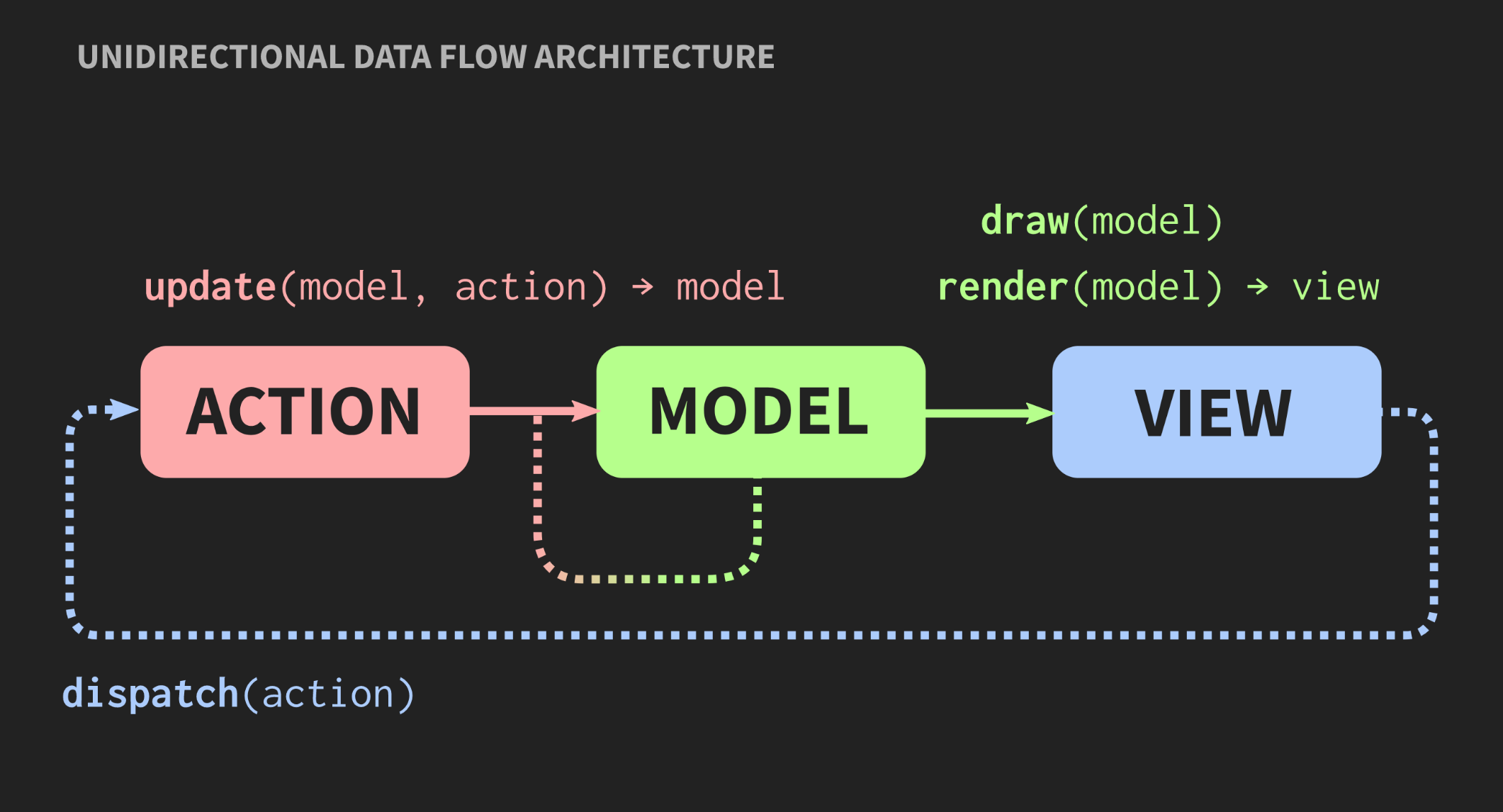 Elemen arsitektur seperti itu sudah akrab bagi kita: Aksi, Model dan Tampilan, tetapi arti dari blok dan panah berbeda. Blok adalah nilai, bukan objek dan bukan wilayah dengan status yang bisa berubah. Ini berlaku bahkan untuk Tampilan. Lebih jauh, panah bukanlah tautan, karena tanpa objek tidak ada tautan. Di sini panah adalah fungsi. Antara Aksi dan Model, ada fungsi pembaruan yang menerima Model saat ini, yaitu, kondisi dunia saat ini, dan Aksi, yang merupakan representasi dari suatu peristiwa, misalnya, klik mouse, atau peristiwa tingkat abstraksi lain, misalnya, penyisipan elemen atau simbol ke dalam dokumen. Fungsi pembaruan memperbarui dokumen dan mengembalikan negara baru di dunia. Model terhubung ke render fungsi tampilan, yang mengambil Model dan mengembalikan tampilan. Ini membutuhkan kerangka kerja di mana Tampilan dapat direpresentasikan sebagai nilai.Dalam pengembangan web, React melakukan ini, tetapi dalam C ++ belum ada yang seperti itu, walaupun siapa tahu, jika ada orang yang ingin membayar saya untuk menulis sesuatu seperti ini, mungkin akan segera muncul. Sementara itu, Anda dapat menggunakan API mode Langsung, di mana fungsi draw memungkinkan Anda untuk membuat nilai sebagai efek samping.Akhirnya, Tampilan harus memiliki mekanisme yang memungkinkan pengguna atau sumber acara lainnya untuk mengirim Tindakan. Ada cara mudah untuk menerapkan ini, disajikan di bawah ini:
Elemen arsitektur seperti itu sudah akrab bagi kita: Aksi, Model dan Tampilan, tetapi arti dari blok dan panah berbeda. Blok adalah nilai, bukan objek dan bukan wilayah dengan status yang bisa berubah. Ini berlaku bahkan untuk Tampilan. Lebih jauh, panah bukanlah tautan, karena tanpa objek tidak ada tautan. Di sini panah adalah fungsi. Antara Aksi dan Model, ada fungsi pembaruan yang menerima Model saat ini, yaitu, kondisi dunia saat ini, dan Aksi, yang merupakan representasi dari suatu peristiwa, misalnya, klik mouse, atau peristiwa tingkat abstraksi lain, misalnya, penyisipan elemen atau simbol ke dalam dokumen. Fungsi pembaruan memperbarui dokumen dan mengembalikan negara baru di dunia. Model terhubung ke render fungsi tampilan, yang mengambil Model dan mengembalikan tampilan. Ini membutuhkan kerangka kerja di mana Tampilan dapat direpresentasikan sebagai nilai.Dalam pengembangan web, React melakukan ini, tetapi dalam C ++ belum ada yang seperti itu, walaupun siapa tahu, jika ada orang yang ingin membayar saya untuk menulis sesuatu seperti ini, mungkin akan segera muncul. Sementara itu, Anda dapat menggunakan API mode Langsung, di mana fungsi draw memungkinkan Anda untuk membuat nilai sebagai efek samping.Akhirnya, Tampilan harus memiliki mekanisme yang memungkinkan pengguna atau sumber acara lainnya untuk mengirim Tindakan. Ada cara mudah untuk menerapkan ini, disajikan di bawah ini:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
Dengan pengecualian menyimpan dan memuat secara tidak sinkron, ini adalah kode yang digunakan dalam editor yang baru saja disajikan. Ada objek di sini terminalyang memungkinkan Anda membaca dan menulis dari baris perintah. Selanjutnya, applicationini adalah nilai Model, ini menyimpan seluruh keadaan aplikasi. Seperti yang dapat Anda lihat di bagian atas layar, ada fungsi yang mengembalikan versi baru application. Siklus di dalam fungsi dijalankan hingga aplikasi harus ditutup, yaitu sampai !state.done. Dalam loop, negara baru ditarik, maka acara berikutnya diminta. Akhirnya, status disimpan dalam variabel lokal state, dan loop dimulai lagi. Kode ini memiliki keunggulan yang sangat penting: hanya ada satu variabel yang dapat berubah yang ada di seluruh eksekusi program, ini adalah objek state.Pengembang Clojure menyebut arsitektur atom-tunggal ini: ada satu titik tunggal di seluruh aplikasi yang melaluinya semua perubahan dilakukan. Logika aplikasi tidak berpartisipasi dalam memperbarui titik ini dengan cara apa pun, ini membuat siklus yang dirancang khusus untuk ini. Berkat ini, logika aplikasi seluruhnya terdiri dari fungsi murni, seperti fungsi update.Dengan pendekatan ini untuk menulis aplikasi, cara berpikir tentang perangkat lunak berubah. Pekerjaan sekarang dimulai bukan dengan diagram antarmuka dan operasi UML, tetapi dengan data itu sendiri. Ada beberapa kesamaan dengan desain berorientasi data. Benar, desain berorientasi data biasanya digunakan untuk mendapatkan kinerja maksimal, di sini, selain kecepatan, kami berusaha untuk kesederhanaan dan kebenaran. Penekanannya sedikit berbeda, tetapi ada kesamaan penting dalam metodologi.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
Di atas adalah tipe data utama dari aplikasi kita. Tubuh utama dari aplikasi terdiri dari line, yaitu flex_vector, dan flex_vector adalah vectorsalah satu yang Anda dapat melakukan operasi gabungan. Berikutnya textadalah vektor di mana ia disimpan line. Seperti yang Anda lihat, ini adalah representasi teks yang sangat sederhana. Textdisimpan dengan bantuan fileyang memiliki nama, yaitu alamat dalam sistem file, dan sebenarnya text. Seperti fileyang digunakan jenis lain, sederhana tapi sangat berguna: box. Ini adalah wadah elemen tunggal. Ini memungkinkan Anda untuk memasukkan tumpukan dan memindahkan objek, menyalin yang mungkin terlalu banyak sumber daya.Jenis penting lain: snapshot. Berdasarkan jenis ini, fungsi batal aktif. Ini berisi dokumen (dalam bentuktext) dan posisi kursor (coord). Ini memungkinkan Anda untuk mengembalikan kursor ke posisi di mana ia selama mengedit.Jenis selanjutnya adalah buffer. Ini adalah istilah dari vim dan emacs, karena dokumen terbuka disebut di sana. Di buffersana ada file dari mana teks diunduh, serta konten teks - ini memungkinkan Anda untuk memeriksa perubahan dalam dokumen. Untuk menyorot bagian dari teks, ada variabel opsional yang selection_startmenunjukkan awal pemilihan. Vektor dari snapshotadalah kisah teks. Perhatikan bahwa kami tidak menggunakan pola Tim, sejarah hanya terdiri dari negara. Akhirnya, jika pembatalan baru saja selesai, kita perlu indeks posisi dalam sejarah negara history_pos.Jenis berikutnya: application. Ini berisi dokumen terbuka (buffer), key_mapdankey_sequntuk pintasan keyboard, serta vektor dari textuntuk clipboard dan vektor lain untuk pesan yang ditampilkan di bagian bawah layar. Sejauh ini, dalam versi debut aplikasi hanya akan ada satu utas dan satu jenis tindakan yang membutuhkan input key_codedan coord.Kemungkinan besar, banyak dari Anda sudah memikirkan cara mengimplementasikan operasi ini. Jika diambil berdasarkan nilai dan dikembalikan dengan nilai, maka dalam kebanyakan kasus operasi cukup sederhana. Kode editor teks saya diposting di github , sehingga Anda dapat melihat tampilannya sebenarnya. Sekarang saya akan membahas secara terperinci hanya pada kode yang mengimplementasikan fungsi pembatalan.Membatalkan
Menulis pembatalan dengan benar tanpa infrastruktur yang sesuai tidaklah mudah. Dalam editor saya, saya menerapkannya di sepanjang garis emacs, jadi pertama-tama beberapa kata tentang prinsip-prinsip dasarnya. Perintah pengembalian tidak ada di sini, dan berkat ini, Anda tidak dapat kehilangan pekerjaan Anda. Jika diperlukan pengembalian, perubahan apa pun dilakukan pada teks, dan kemudian semua tindakan pembatalan menjadi bagian lagi dari riwayat pembatalan. Prinsip ini digambarkan di atas. Belah ketupat merah di sini menunjukkan posisi dalam sejarah: jika pembatalan belum selesai, belah ketupat merah selalu di akhir. Jika Anda membatalkan, berlian akan memindahkan satu negara kembali, tetapi pada saat yang sama, negara lain akan ditambahkan ke akhir antrian - sama seperti yang dilihat pengguna saat ini (S3). Jika Anda membatalkan lagi dan kembali ke S2, negara S2 ditambahkan ke akhir antrian. Jika sekarang pengguna membuat semacam perubahan, itu akan ditambahkan ke akhir antrian sebagai negara baru S5, dan belah ketupat akan dipindahkan ke sana. Sekarang, ketika membatalkan tindakan sebelumnya, tindakan membatalkan sebelumnya akan digulirkan terlebih dahulu. Untuk menerapkan sistem pembatalan seperti itu, kode berikut cukup:
Prinsip ini digambarkan di atas. Belah ketupat merah di sini menunjukkan posisi dalam sejarah: jika pembatalan belum selesai, belah ketupat merah selalu di akhir. Jika Anda membatalkan, berlian akan memindahkan satu negara kembali, tetapi pada saat yang sama, negara lain akan ditambahkan ke akhir antrian - sama seperti yang dilihat pengguna saat ini (S3). Jika Anda membatalkan lagi dan kembali ke S2, negara S2 ditambahkan ke akhir antrian. Jika sekarang pengguna membuat semacam perubahan, itu akan ditambahkan ke akhir antrian sebagai negara baru S5, dan belah ketupat akan dipindahkan ke sana. Sekarang, ketika membatalkan tindakan sebelumnya, tindakan membatalkan sebelumnya akan digulirkan terlebih dahulu. Untuk menerapkan sistem pembatalan seperti itu, kode berikut cukup:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
Ada dua tindakan, recorddan undo. Recorddilakukan selama operasi apa pun. Ini sangat nyaman karena kita tidak perlu tahu apakah ada pengeditan dokumen yang terjadi. Fungsi transparan untuk logika aplikasi. Setelah tindakan apa pun, fungsi memeriksa apakah dokumen telah berubah. Jika terjadi perubahan, push_backkonten dan posisi kursor untuk dieksekusi history. Jika tindakan tidak mengarah ke perubahan history_pos(yaitu, input yang diterima bufferbukan disebabkan oleh tindakan pembatalan), maka history_posnilai diberikan null. Jika perlu undo, kami periksa history_pos. Jika tidak ada artinya, kami menganggapnya history_posdi akhir cerita. Jika riwayat pembatalan tidak kosong (mis.history_postidak di awal cerita), pembatalan dilakukan. Konten dan kursor saat ini diganti dan diubah history_pos. Irrevocability dari operasi undo dicapai oleh fungsi record, yang juga disebut selama operasi undo.Jadi, kami memiliki operasi undoyang memakan 10 baris kode, dan yang tanpa perubahan (atau dengan perubahan minimal) dapat digunakan di hampir semua aplikasi lain.Perjalanan waktu
Tentang perjalanan waktu. Seperti yang akan kita lihat sekarang, ini adalah topik yang terkait dengan pembatalan. Saya akan menunjukkan karya kerangka kerja yang akan menambah fungsionalitas yang berguna untuk aplikasi apa pun dengan arsitektur yang sama. Kerangka kerja di sini disebut ewig-debug . Versi ewig ini mencakup beberapa fitur debugging. Sekarang dari browser Anda dapat membuka debugger, di mana Anda dapat memeriksa status aplikasi. Kami melihat bahwa tindakan terakhir diubah ukurannya, karena saya membuka jendela baru, dan manajer jendela saya secara otomatis mengubah ukuran jendela yang sudah terbuka. Tentu saja, untuk serialisasi otomatis di JSON, saya harus menambahkan anotasi untuk struct dari perpustakaan refleksi khusus. Tetapi sisa dari sistem ini cukup universal, dapat dihubungkan ke aplikasi serupa. Sekarang di browser Anda dapat melihat semua tindakan selesai. Tentu saja, ada kondisi awal yang tidak memiliki tindakan. Ini adalah keadaan sebelum pengunduhan. Selain itu, dengan mengklik dua kali saya dapat mengembalikan aplikasi ke keadaan sebelumnya. Ini adalah alat debugging yang sangat berguna yang memungkinkan Anda untuk melacak terjadinya kegagalan fungsi dalam aplikasi.Jika Anda tertarik, Anda dapat mendengarkan laporan saya tentang CPPCON 19, Nilai-nilai paling berharga, di sana saya akan memeriksa debugger ini secara detail.Selain itu, arsitektur berbasis nilai dibahas lebih rinci di sana. Di dalamnya, saya juga memberi tahu Anda cara menerapkan tindakan dan mengaturnya secara hierarkis. Ini memastikan modularitas sistem dan memungkinkan Anda untuk tidak menyimpan semuanya dalam satu fungsi pembaruan besar. Selain itu, laporan itu berbicara tentang unduhan file asinkron dan multi-utas. Ada versi lain dari laporan ini di mana setengah jam dari materi tambahan adalah struktur data yang tidak dapat diubah Postmodern.
Kami melihat bahwa tindakan terakhir diubah ukurannya, karena saya membuka jendela baru, dan manajer jendela saya secara otomatis mengubah ukuran jendela yang sudah terbuka. Tentu saja, untuk serialisasi otomatis di JSON, saya harus menambahkan anotasi untuk struct dari perpustakaan refleksi khusus. Tetapi sisa dari sistem ini cukup universal, dapat dihubungkan ke aplikasi serupa. Sekarang di browser Anda dapat melihat semua tindakan selesai. Tentu saja, ada kondisi awal yang tidak memiliki tindakan. Ini adalah keadaan sebelum pengunduhan. Selain itu, dengan mengklik dua kali saya dapat mengembalikan aplikasi ke keadaan sebelumnya. Ini adalah alat debugging yang sangat berguna yang memungkinkan Anda untuk melacak terjadinya kegagalan fungsi dalam aplikasi.Jika Anda tertarik, Anda dapat mendengarkan laporan saya tentang CPPCON 19, Nilai-nilai paling berharga, di sana saya akan memeriksa debugger ini secara detail.Selain itu, arsitektur berbasis nilai dibahas lebih rinci di sana. Di dalamnya, saya juga memberi tahu Anda cara menerapkan tindakan dan mengaturnya secara hierarkis. Ini memastikan modularitas sistem dan memungkinkan Anda untuk tidak menyimpan semuanya dalam satu fungsi pembaruan besar. Selain itu, laporan itu berbicara tentang unduhan file asinkron dan multi-utas. Ada versi lain dari laporan ini di mana setengah jam dari materi tambahan adalah struktur data yang tidak dapat diubah Postmodern.Untuk meringkas
Saya pikir sudah waktunya untuk mengambil stok. Saya akan mengutip Andy Wingo - dia adalah pengembang yang sangat baik, dia mencurahkan banyak waktu untuk V8 dan kompiler pada umumnya, akhirnya, dia terlibat dalam mendukung Guile, mengimplementasikan Skema untuk GNU. Baru-baru ini, ia menulis di Twitter-nya: “Untuk mencapai sedikit percepatan program, kami mengukur setiap perubahan kecil dan hanya menyisakan yang memberikan hasil positif. Tetapi kami benar-benar mencapai percepatan yang signifikan, secara membabi buta, menginvestasikan banyak usaha, tidak memiliki kepercayaan diri 100% dan hanya dibimbing oleh intuisi. Sungguh dikotomi yang aneh. ”Sepertinya saya bahwa pengembang C ++ berhasil dalam genre pertama. Beri kami sistem tertutup, dan kami, dengan dipersenjatai dengan alat kami, akan memeras segala yang mungkin darinya. Namun dalam genre kedua kita tidak terbiasa bekerja. Tentu saja, pendekatan kedua lebih berisiko, dan seringkali itu mengarah pada usaha yang sia-sia. Di sisi lain, dengan sepenuhnya menulis ulang suatu program, seringkali dapat dibuat lebih mudah dan lebih cepat. Saya harap saya berhasil meyakinkan Anda untuk setidaknya mencoba pendekatan kedua ini.Juan Puente berbicara di konferensi C ++ Russia 2019 Moscow dan berbicara tentang struktur data yang memungkinkan Anda melakukan hal-hal menarik. Bagian dari keajaiban struktur ini terletak pada salinan salinan - inilah yang akan dibicarakan oleh Anton Polukhin dan Roman Rusyaev pada konferensi mendatang . Ikuti pembaruan program di situs.