Memahami model pembelajaran mesin yang merusak CAPTCHA
Halo semuanya! Bulan ini, OTUS merekrut kelompok baru pada kursus Pembelajaran Mesin . Menurut tradisi yang sudah mapan, pada awal kursus, kami membagikan kepada Anda terjemahan materi yang menarik tentang topik tersebut. Visi komputer adalah salah satu topik AI yang paling relevan dan diteliti [1], namun metode saat ini untuk menyelesaikan masalah menggunakan jaringan saraf convolutional dikritik serius karena fakta bahwa jaringan seperti itu mudah dibodohi. Agar tidak berdasar, saya akan memberi tahu Anda tentang beberapa alasan: jaringan jenis ini memberikan hasil yang salah dengan kepercayaan tinggi untuk gambar yang muncul secara alami yang tidak mengandung sinyal statistik [2], yang diandalkan oleh jaringan saraf convolutional, untuk gambar yang sebelumnya diklasifikasikan dengan benar, tetapi di mana satu piksel [3] atau gambar dengan objek fisik yang ditambahkan ke adegan tetapi tidak harus mengubah hasil klasifikasi [4] berubah. Faktanya adalah, jika kita ingin membuat mesin yang benar-benar cerdas,tampaknya masuk akal bagi kita untuk berinvestasi dalam studi ide-ide baru.Salah satu ide baru ini adalah aplikasi Vicarious dari Recursive Cortical Network (RCN), yang menarik inspirasi dari ilmu saraf. Model ini diklaim sangat efektif dalam memecah teks captcha, sehingga menyebabkan banyak pembicaraan di sekitarnya . Oleh karena itu, saya memutuskan untuk menulis beberapa artikel, yang masing-masing menjelaskan aspek tertentu dari model ini. Pada artikel ini, kita akan berbicara tentang strukturnya dan bagaimana generasi gambar yang disajikan dalam bahan-bahan artikel utama tentang RCN [5] dihasilkan.Artikel ini mengasumsikan bahwa Anda sudah terbiasa dengan jaringan saraf convolutional, jadi saya akan menggambar banyak analogi dengan mereka.Untuk mempersiapkan kesadaran RCN, Anda perlu memahami bahwa RCN didasarkan pada gagasan memisahkan bentuk (sketsa objek) dari penampilan (teksturnya) dan bahwa itu adalah model generatif, bukan model diskriminatif, sehingga kami dapat menghasilkan gambar yang menggunakannya, seperti pada generatif jaringan permusuhan. Selain itu, struktur hierarkis paralel digunakan, mirip dengan arsitektur jaringan saraf convolutional, yang dimulai dengan tahap menentukan bentuk objek target di lapisan bawah, dan kemudian penampilannya ditambahkan pada lapisan atas. Tidak seperti jaringan saraf convolutional, model yang kami pertimbangkan bergantung pada basis teoritis yang kaya dari model grafis, bukan jumlah tertimbang dan keturunan gradien. Sekarang mari kita mempelajari fitur struktur RCN.
Visi komputer adalah salah satu topik AI yang paling relevan dan diteliti [1], namun metode saat ini untuk menyelesaikan masalah menggunakan jaringan saraf convolutional dikritik serius karena fakta bahwa jaringan seperti itu mudah dibodohi. Agar tidak berdasar, saya akan memberi tahu Anda tentang beberapa alasan: jaringan jenis ini memberikan hasil yang salah dengan kepercayaan tinggi untuk gambar yang muncul secara alami yang tidak mengandung sinyal statistik [2], yang diandalkan oleh jaringan saraf convolutional, untuk gambar yang sebelumnya diklasifikasikan dengan benar, tetapi di mana satu piksel [3] atau gambar dengan objek fisik yang ditambahkan ke adegan tetapi tidak harus mengubah hasil klasifikasi [4] berubah. Faktanya adalah, jika kita ingin membuat mesin yang benar-benar cerdas,tampaknya masuk akal bagi kita untuk berinvestasi dalam studi ide-ide baru.Salah satu ide baru ini adalah aplikasi Vicarious dari Recursive Cortical Network (RCN), yang menarik inspirasi dari ilmu saraf. Model ini diklaim sangat efektif dalam memecah teks captcha, sehingga menyebabkan banyak pembicaraan di sekitarnya . Oleh karena itu, saya memutuskan untuk menulis beberapa artikel, yang masing-masing menjelaskan aspek tertentu dari model ini. Pada artikel ini, kita akan berbicara tentang strukturnya dan bagaimana generasi gambar yang disajikan dalam bahan-bahan artikel utama tentang RCN [5] dihasilkan.Artikel ini mengasumsikan bahwa Anda sudah terbiasa dengan jaringan saraf convolutional, jadi saya akan menggambar banyak analogi dengan mereka.Untuk mempersiapkan kesadaran RCN, Anda perlu memahami bahwa RCN didasarkan pada gagasan memisahkan bentuk (sketsa objek) dari penampilan (teksturnya) dan bahwa itu adalah model generatif, bukan model diskriminatif, sehingga kami dapat menghasilkan gambar yang menggunakannya, seperti pada generatif jaringan permusuhan. Selain itu, struktur hierarkis paralel digunakan, mirip dengan arsitektur jaringan saraf convolutional, yang dimulai dengan tahap menentukan bentuk objek target di lapisan bawah, dan kemudian penampilannya ditambahkan pada lapisan atas. Tidak seperti jaringan saraf convolutional, model yang kami pertimbangkan bergantung pada basis teoritis yang kaya dari model grafis, bukan jumlah tertimbang dan keturunan gradien. Sekarang mari kita mempelajari fitur struktur RCN.Lapisan fitur
Jenis lapisan pertama di RCN disebut lapisan fitur. Kami akan mempertimbangkan model secara bertahap, jadi mari kita asumsikan sekarang bahwa seluruh hierarki model hanya terdiri dari lapisan-lapisan jenis ini yang saling bertumpuk. Kami akan beralih dari konsep abstrak tingkat tinggi ke fitur yang lebih spesifik dari lapisan bawah, seperti yang ditunjukkan pada Gambar 1 . Lapisan jenis ini terdiri dari beberapa node yang terletak di ruang dua dimensi, mirip dengan fitur peta dalam jaringan saraf convolutional. Gambar 1 : Beberapa layer fitur terletak satu di atas yang lain dengan node dalam ruang dua dimensi. Transisi dari lapisan keempat ke lapisan pertama berarti transisi dari yang umum ke yang khusus.Setiap node terdiri dari beberapa saluran, yang masing-masing mewakili fitur terpisah. Saluran adalah variabel biner yang mengambil nilai Benar atau Salah, yang menunjukkan apakah objek yang sesuai dengan saluran ini ada di gambar yang dihasilkan akhir dalam koordinat (x, y) dari node. Pada level apa pun, node memiliki tipe saluran yang sama.Sebagai contoh, mari kita ambil layer perantara dan bicarakan salurannya dan layer di atas untuk menyederhanakan penjelasan. Daftar saluran pada lapisan ini adalah hiperbola, lingkaran, dan parabola. Pada menjalankan tertentu ketika menghasilkan gambar, perhitungan lapisan atasnya membutuhkan lingkaran di koordinat (1,1). Dengan demikian, simpul (1, 1) akan memiliki saluran yang sesuai dengan objek "lingkaran" dalam nilai True. Ini akan secara langsung mempengaruhi beberapa node di lapisan di bawah ini, yaitu, fitur tingkat lebih rendah yang terkait dengan lingkaran di lingkungan (1,1) akan diatur ke True. Objek tingkat rendah ini dapat, misalnya, empat busur dengan orientasi yang berbeda. Ketika fitur-fitur lapisan bawah diaktifkan, mereka mengaktifkan saluran pada lapisan lebih rendah sampai lapisan terakhir tercapai,menghasilkan gambar. Visualisasi aktivasi ditampilkan diGambar 2 .Anda mungkin bertanya, bagaimana menjadi jelas bahwa representasi lingkaran adalah 4 busur? Dan bagaimana RCN tahu bahwa itu membutuhkan saluran untuk mewakili lingkaran? Saluran dan ikatan mereka ke lapisan lain akan dibentuk pada tahap pelatihan RCN.
Gambar 1 : Beberapa layer fitur terletak satu di atas yang lain dengan node dalam ruang dua dimensi. Transisi dari lapisan keempat ke lapisan pertama berarti transisi dari yang umum ke yang khusus.Setiap node terdiri dari beberapa saluran, yang masing-masing mewakili fitur terpisah. Saluran adalah variabel biner yang mengambil nilai Benar atau Salah, yang menunjukkan apakah objek yang sesuai dengan saluran ini ada di gambar yang dihasilkan akhir dalam koordinat (x, y) dari node. Pada level apa pun, node memiliki tipe saluran yang sama.Sebagai contoh, mari kita ambil layer perantara dan bicarakan salurannya dan layer di atas untuk menyederhanakan penjelasan. Daftar saluran pada lapisan ini adalah hiperbola, lingkaran, dan parabola. Pada menjalankan tertentu ketika menghasilkan gambar, perhitungan lapisan atasnya membutuhkan lingkaran di koordinat (1,1). Dengan demikian, simpul (1, 1) akan memiliki saluran yang sesuai dengan objek "lingkaran" dalam nilai True. Ini akan secara langsung mempengaruhi beberapa node di lapisan di bawah ini, yaitu, fitur tingkat lebih rendah yang terkait dengan lingkaran di lingkungan (1,1) akan diatur ke True. Objek tingkat rendah ini dapat, misalnya, empat busur dengan orientasi yang berbeda. Ketika fitur-fitur lapisan bawah diaktifkan, mereka mengaktifkan saluran pada lapisan lebih rendah sampai lapisan terakhir tercapai,menghasilkan gambar. Visualisasi aktivasi ditampilkan diGambar 2 .Anda mungkin bertanya, bagaimana menjadi jelas bahwa representasi lingkaran adalah 4 busur? Dan bagaimana RCN tahu bahwa itu membutuhkan saluran untuk mewakili lingkaran? Saluran dan ikatan mereka ke lapisan lain akan dibentuk pada tahap pelatihan RCN.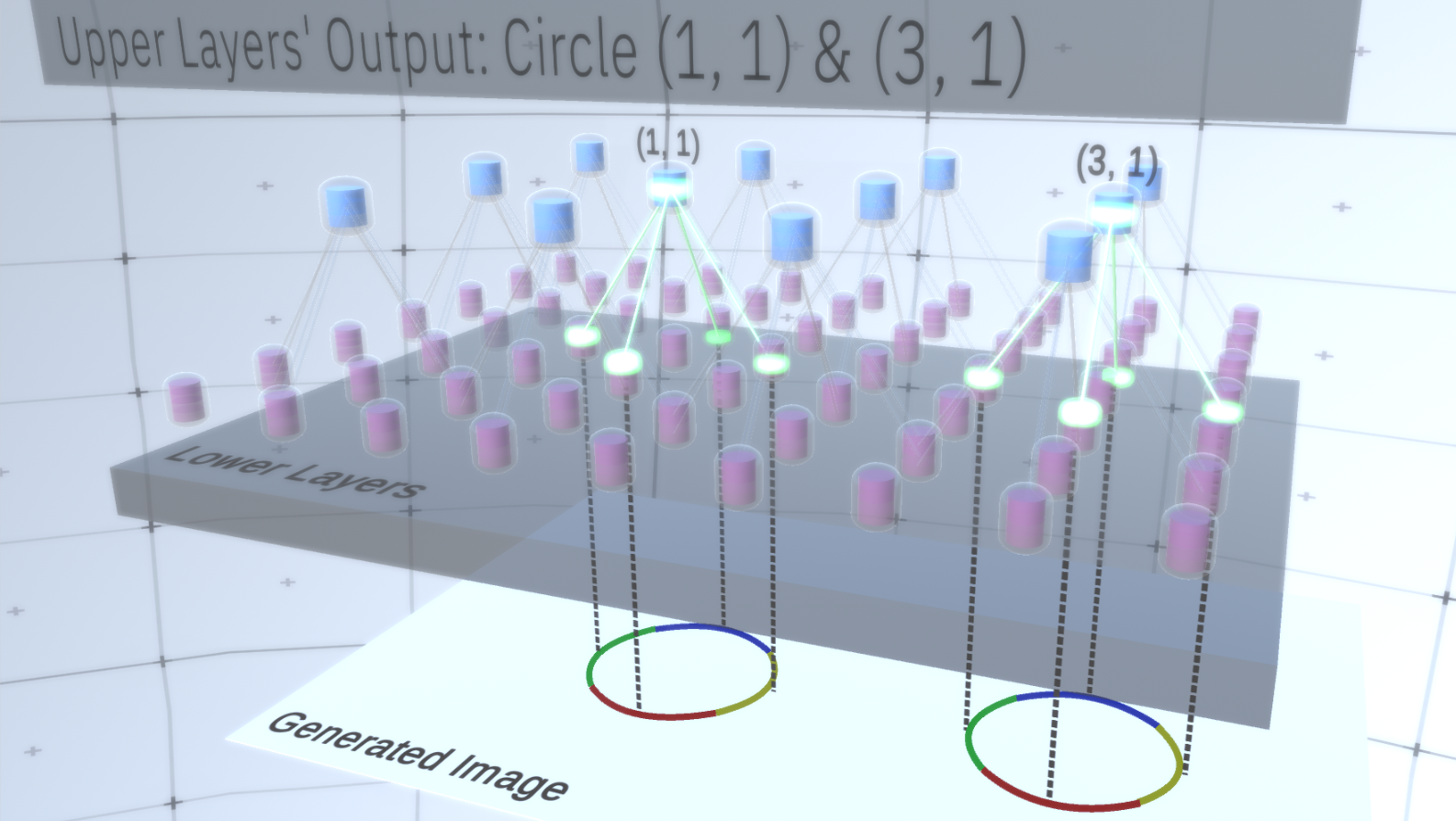 Gambar 2: Aliran informasi di lapisan fitur. Node tanda adalah kapsul yang berisi disk yang mewakili saluran. Beberapa lapisan atas dan bawah disajikan dalam bentuk parallelepiped untuk penyederhanaan, namun pada kenyataannya mereka juga terdiri dari fitur fitur sebagai lapisan menengah. Harap dicatat bahwa lapisan menengah atas terdiri dari 3 saluran, dan lapisan kedua terdiri dari 4 saluran.Anda dapat menunjukkan metode yang sangat kaku dan deterministik untuk menghasilkan model yang diadopsi, tetapi bagi orang-orang, gangguan kecil dari kelengkungan lingkaran masih dianggap sebagai lingkaran, seperti yang dapat Anda lihat pada Gambar 3 .
Gambar 2: Aliran informasi di lapisan fitur. Node tanda adalah kapsul yang berisi disk yang mewakili saluran. Beberapa lapisan atas dan bawah disajikan dalam bentuk parallelepiped untuk penyederhanaan, namun pada kenyataannya mereka juga terdiri dari fitur fitur sebagai lapisan menengah. Harap dicatat bahwa lapisan menengah atas terdiri dari 3 saluran, dan lapisan kedua terdiri dari 4 saluran.Anda dapat menunjukkan metode yang sangat kaku dan deterministik untuk menghasilkan model yang diadopsi, tetapi bagi orang-orang, gangguan kecil dari kelengkungan lingkaran masih dianggap sebagai lingkaran, seperti yang dapat Anda lihat pada Gambar 3 .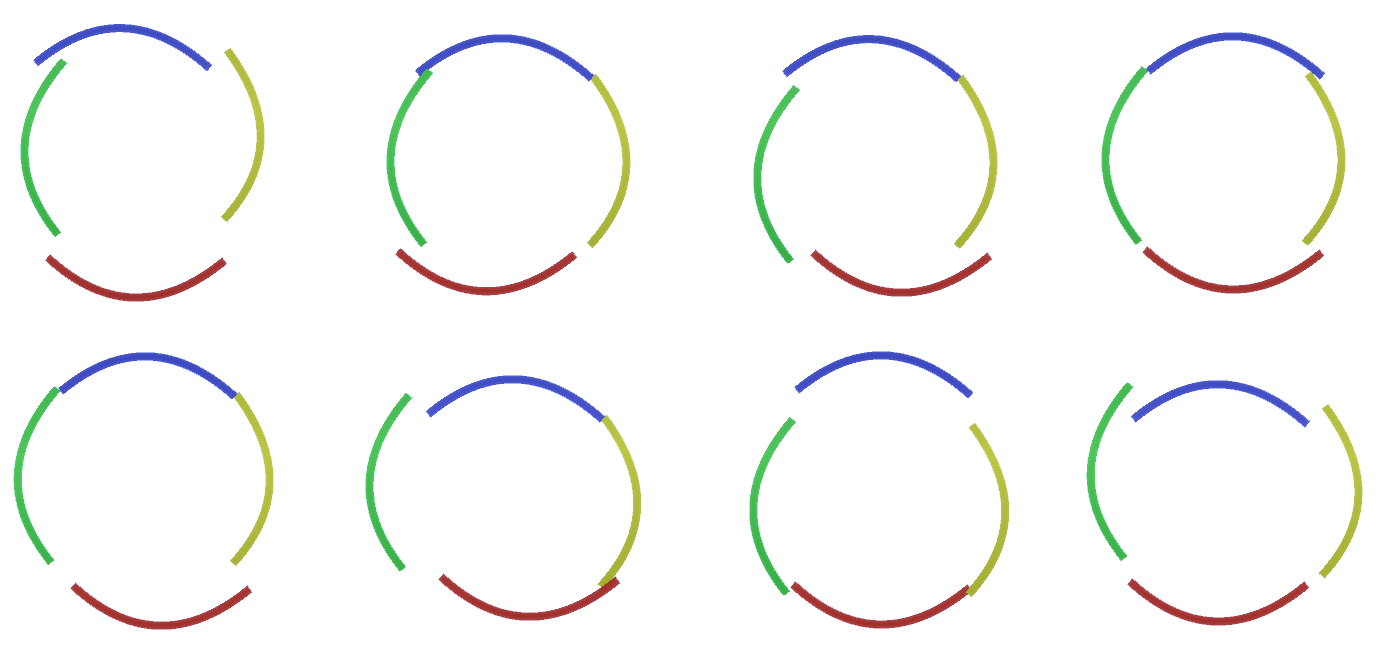 Gambar 3: Banyak variasi konstruksi lingkaran empat lengkung lengkung dari Gambar 2.Akan sulit untuk mempertimbangkan masing-masing variasi ini sebagai saluran baru yang terpisah di lapisan. Demikian pula, pengelompokan variasi ke dalam entitas yang sama akan sangat memudahkan generalisasi ke dalam variasi baru ketika kita mengadaptasi RCN ke klasifikasi alih-alih menghasilkan beberapa saat kemudian. Tetapi bagaimana kita mengubah RCN untuk mendapatkan kesempatan ini?
Gambar 3: Banyak variasi konstruksi lingkaran empat lengkung lengkung dari Gambar 2.Akan sulit untuk mempertimbangkan masing-masing variasi ini sebagai saluran baru yang terpisah di lapisan. Demikian pula, pengelompokan variasi ke dalam entitas yang sama akan sangat memudahkan generalisasi ke dalam variasi baru ketika kita mengadaptasi RCN ke klasifikasi alih-alih menghasilkan beberapa saat kemudian. Tetapi bagaimana kita mengubah RCN untuk mendapatkan kesempatan ini?Berlapis-lapis lapisan
Untuk melakukan ini, Anda memerlukan tipe layer baru - layer pooling. Itu terletak di antara dua lapisan tanda dan bertindak sebagai perantara di antara mereka. Ini juga terdiri dari saluran, tetapi mereka memiliki nilai integer, bukan yang biner.Untuk mengilustrasikan cara kerja lapisan ini, mari kembali ke contoh lingkaran. Alih-alih membutuhkan 4 busur dengan koordinat tetap dari lapisan fitur di atasnya sebagai fitur lingkaran, pencarian akan dilakukan pada lapisan subsampel. Kemudian, setiap saluran yang diaktifkan dalam lapisan subsampel akan memilih sebuah simpul pada lapisan yang mendasarinya di sekitarnya untuk memungkinkan sedikit distorsi fitur. Dengan demikian, jika kita menjalin komunikasi dengan 9 node langsung di bawah node subsampel, maka saluran subsampel, kapan pun diaktifkan, akan secara merata memilih salah satu dari 9 node ini dan mengaktifkannya, dan indeks dari node yang dipilih akan menjadi keadaan saluran subsampel - bilangan bulat. Dalam Gambar 4Anda dapat melihat beberapa proses, di mana masing-masing proses menggunakan set node tingkat rendah yang berbeda, masing-masing, memungkinkan Anda untuk membuat lingkaran dengan berbagai cara. Gambar 4: Pengoperasian lapisan subsampling. Setiap frame dalam gambar GIF ini adalah peluncuran terpisah. Node subsampling dipotong dadu. Dalam gambar ini, node subsampel memiliki 4 saluran yang setara dengan 4 saluran dari lapisan fitur di bawahnya. Lapisan atas dan bawah sepenuhnya dihapus dari gambar.Terlepas dari kenyataan bahwa kami membutuhkan variabilitas model kami, akan lebih baik jika tetap lebih terkendali dan fokus. Dalam dua gambar sebelumnya, beberapa lingkaran terlihat terlalu aneh untuk benar-benar menafsirkannya sebagai lingkaran karena fakta bahwa busur tidak saling berhubungan, seperti yang dapat dilihat dari Gambar 5. Kami ingin menghindari membuatnya. Dengan demikian, jika kita dapat menambahkan mekanisme untuk subsampling saluran untuk mengoordinasikan pemilihan node fitur dan fokus pada formulir kontinu, model kita akan lebih akurat.
Gambar 4: Pengoperasian lapisan subsampling. Setiap frame dalam gambar GIF ini adalah peluncuran terpisah. Node subsampling dipotong dadu. Dalam gambar ini, node subsampel memiliki 4 saluran yang setara dengan 4 saluran dari lapisan fitur di bawahnya. Lapisan atas dan bawah sepenuhnya dihapus dari gambar.Terlepas dari kenyataan bahwa kami membutuhkan variabilitas model kami, akan lebih baik jika tetap lebih terkendali dan fokus. Dalam dua gambar sebelumnya, beberapa lingkaran terlihat terlalu aneh untuk benar-benar menafsirkannya sebagai lingkaran karena fakta bahwa busur tidak saling berhubungan, seperti yang dapat dilihat dari Gambar 5. Kami ingin menghindari membuatnya. Dengan demikian, jika kita dapat menambahkan mekanisme untuk subsampling saluran untuk mengoordinasikan pemilihan node fitur dan fokus pada formulir kontinu, model kita akan lebih akurat. Gambar 5: Banyak opsi untuk membangun lingkaran. Opsi yang ingin kita jatuhkan ditandai dengan tanda silang merah.Penulis RCN menggunakan koneksi lateral dalam subsampling layer untuk tujuan ini. Pada dasarnya, saluran subsampling akan memiliki tautan dengan saluran subsampling lain dari lingkungan terdekat, dan tautan ini tidak akan memungkinkan beberapa pasangan negara untuk hidup berdampingan dalam dua saluran secara bersamaan. Bahkan, area sampel dari dua saluran ini hanya akan terbatas. Dalam berbagai versi lingkaran, koneksi ini, misalnya, tidak akan memungkinkan dua busur yang berdekatan untuk saling menjauh. Mekanisme ini ditunjukkan pada Gambar 6.. Sekali lagi, hubungan ini terjalin pada tahap pelatihan. Perlu dicatat bahwa jaringan saraf tiruan vanilla modern tidak memiliki koneksi lateral di lapisannya, meskipun mereka ada dalam jaringan saraf biologis dan diasumsikan bahwa mereka memainkan peran dalam integrasi kontur dalam korteks visual (tetapi, terus terang, korteks visual memiliki perangkat yang lebih kompleks daripada yang terlihat dari pernyataan sebelumnya).
Gambar 5: Banyak opsi untuk membangun lingkaran. Opsi yang ingin kita jatuhkan ditandai dengan tanda silang merah.Penulis RCN menggunakan koneksi lateral dalam subsampling layer untuk tujuan ini. Pada dasarnya, saluran subsampling akan memiliki tautan dengan saluran subsampling lain dari lingkungan terdekat, dan tautan ini tidak akan memungkinkan beberapa pasangan negara untuk hidup berdampingan dalam dua saluran secara bersamaan. Bahkan, area sampel dari dua saluran ini hanya akan terbatas. Dalam berbagai versi lingkaran, koneksi ini, misalnya, tidak akan memungkinkan dua busur yang berdekatan untuk saling menjauh. Mekanisme ini ditunjukkan pada Gambar 6.. Sekali lagi, hubungan ini terjalin pada tahap pelatihan. Perlu dicatat bahwa jaringan saraf tiruan vanilla modern tidak memiliki koneksi lateral di lapisannya, meskipun mereka ada dalam jaringan saraf biologis dan diasumsikan bahwa mereka memainkan peran dalam integrasi kontur dalam korteks visual (tetapi, terus terang, korteks visual memiliki perangkat yang lebih kompleks daripada yang terlihat dari pernyataan sebelumnya).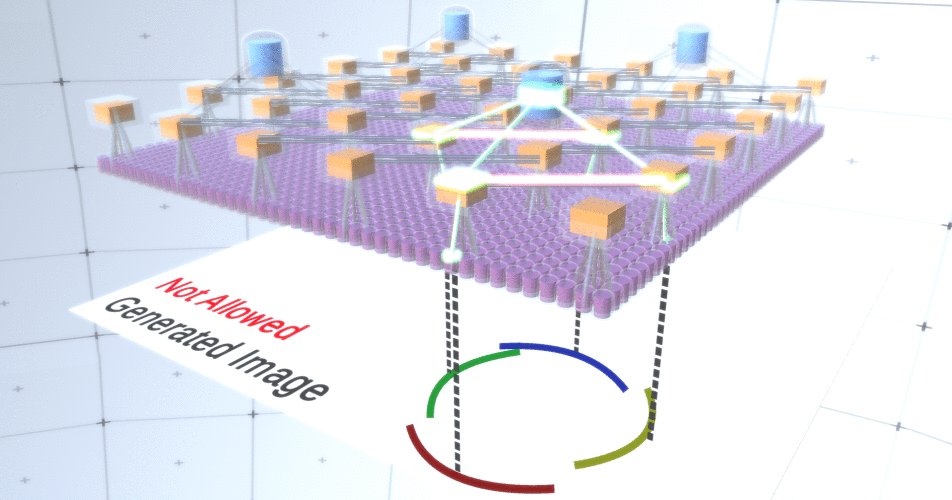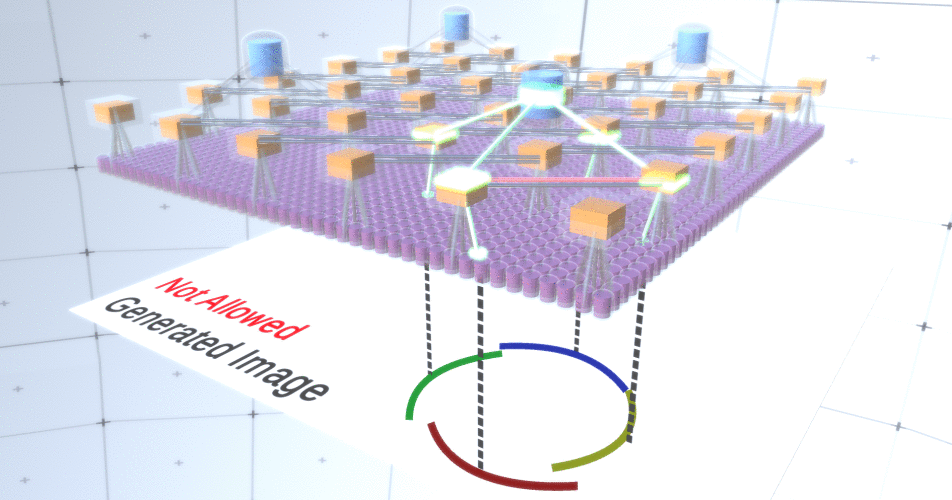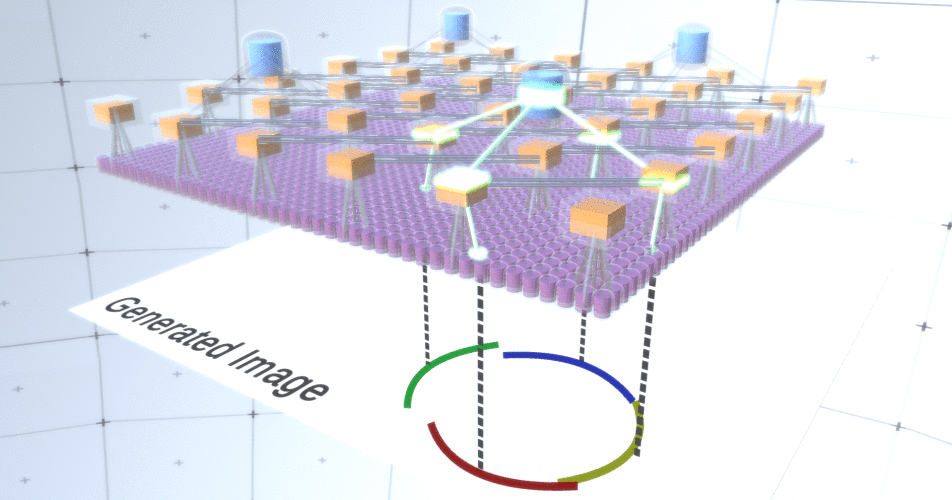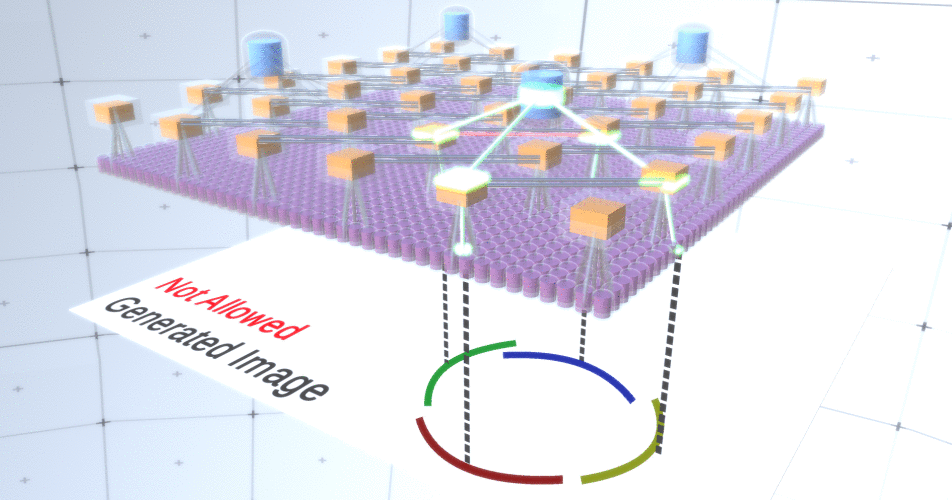 Gambar 6: GIF- RCN . , . , RCN , , . .Sejauh ini, kita berbicara tentang lapisan menengah RCN, kita hanya memiliki lapisan paling atas dan lapisan terendah yang berinteraksi dengan piksel dari gambar yang dihasilkan. Lapisan paling atas adalah lapisan fitur biasa, di mana saluran setiap node akan menjadi kelas dari dataset berlabel kami. Saat menghasilkan, kita cukup memilih lokasi dan kelas yang ingin kita buat, pergi ke simpul dengan lokasi yang ditentukan dan katakan bahwa itu mengaktifkan saluran kelas yang kita pilih. Ini mengaktifkan beberapa saluran di lapisan subsampel di bawahnya, lalu lapisan fitur di bawah, dan seterusnya, hingga kita mencapai lapisan fitur terakhir. Berdasarkan pengetahuan Anda tentang jaringan saraf convolutional, Anda harus berpikir bahwa lapisan paling atas akan memiliki satu node, tetapi ini tidak begitu, dan ini adalah salah satu keunggulan RCN,tetapi diskusi tentang topik ini berada di luar cakupan artikel ini.Lapisan fitur terakhir akan menjadi unik. Ingat, saya berbicara tentang bagaimana RCN memisahkan bentuk dari penampilan? Lapisan inilah yang akan bertanggung jawab untuk mendapatkan bentuk objek yang dihasilkan. Dengan demikian, lapisan ini harus bekerja dengan fitur tingkat sangat rendah, blok bangunan paling dasar dari segala bentuk, yang akan membantu kita menghasilkan bentuk yang diinginkan. Perbatasan kecil yang berputar pada sudut yang berbeda cukup cocok, dan justru itulah yang digunakan oleh para pembuat teknologi.Penulis memilih atribut level terakhir untuk mewakili jendela 3x3 yang memiliki batas dengan sudut rotasi tertentu, yang mereka sebut descriptor tambalan. Jumlah sudut rotasi yang mereka pilih adalah 16. Selain itu, agar dapat menambahkan tampilan nanti, Anda memerlukan dua orientasi untuk setiap rotasi agar dapat mengetahui apakah latar belakang di sebelah kiri atau di perbatasan kanan, jika ini adalah batas eksternal , dan orientasi tambahan dalam kasus batas internal (mis., di dalam objek). Dalam Gambar 7 menunjukkan karakteristik perakitan lapisan terakhir, dan Gambar 8 menunjukkan bagaimana deskriptor tambalan dapat menghasilkan bentuk tertentu.
Gambar 6: GIF- RCN . , . , RCN , , . .Sejauh ini, kita berbicara tentang lapisan menengah RCN, kita hanya memiliki lapisan paling atas dan lapisan terendah yang berinteraksi dengan piksel dari gambar yang dihasilkan. Lapisan paling atas adalah lapisan fitur biasa, di mana saluran setiap node akan menjadi kelas dari dataset berlabel kami. Saat menghasilkan, kita cukup memilih lokasi dan kelas yang ingin kita buat, pergi ke simpul dengan lokasi yang ditentukan dan katakan bahwa itu mengaktifkan saluran kelas yang kita pilih. Ini mengaktifkan beberapa saluran di lapisan subsampel di bawahnya, lalu lapisan fitur di bawah, dan seterusnya, hingga kita mencapai lapisan fitur terakhir. Berdasarkan pengetahuan Anda tentang jaringan saraf convolutional, Anda harus berpikir bahwa lapisan paling atas akan memiliki satu node, tetapi ini tidak begitu, dan ini adalah salah satu keunggulan RCN,tetapi diskusi tentang topik ini berada di luar cakupan artikel ini.Lapisan fitur terakhir akan menjadi unik. Ingat, saya berbicara tentang bagaimana RCN memisahkan bentuk dari penampilan? Lapisan inilah yang akan bertanggung jawab untuk mendapatkan bentuk objek yang dihasilkan. Dengan demikian, lapisan ini harus bekerja dengan fitur tingkat sangat rendah, blok bangunan paling dasar dari segala bentuk, yang akan membantu kita menghasilkan bentuk yang diinginkan. Perbatasan kecil yang berputar pada sudut yang berbeda cukup cocok, dan justru itulah yang digunakan oleh para pembuat teknologi.Penulis memilih atribut level terakhir untuk mewakili jendela 3x3 yang memiliki batas dengan sudut rotasi tertentu, yang mereka sebut descriptor tambalan. Jumlah sudut rotasi yang mereka pilih adalah 16. Selain itu, agar dapat menambahkan tampilan nanti, Anda memerlukan dua orientasi untuk setiap rotasi agar dapat mengetahui apakah latar belakang di sebelah kiri atau di perbatasan kanan, jika ini adalah batas eksternal , dan orientasi tambahan dalam kasus batas internal (mis., di dalam objek). Dalam Gambar 7 menunjukkan karakteristik perakitan lapisan terakhir, dan Gambar 8 menunjukkan bagaimana deskriptor tambalan dapat menghasilkan bentuk tertentu.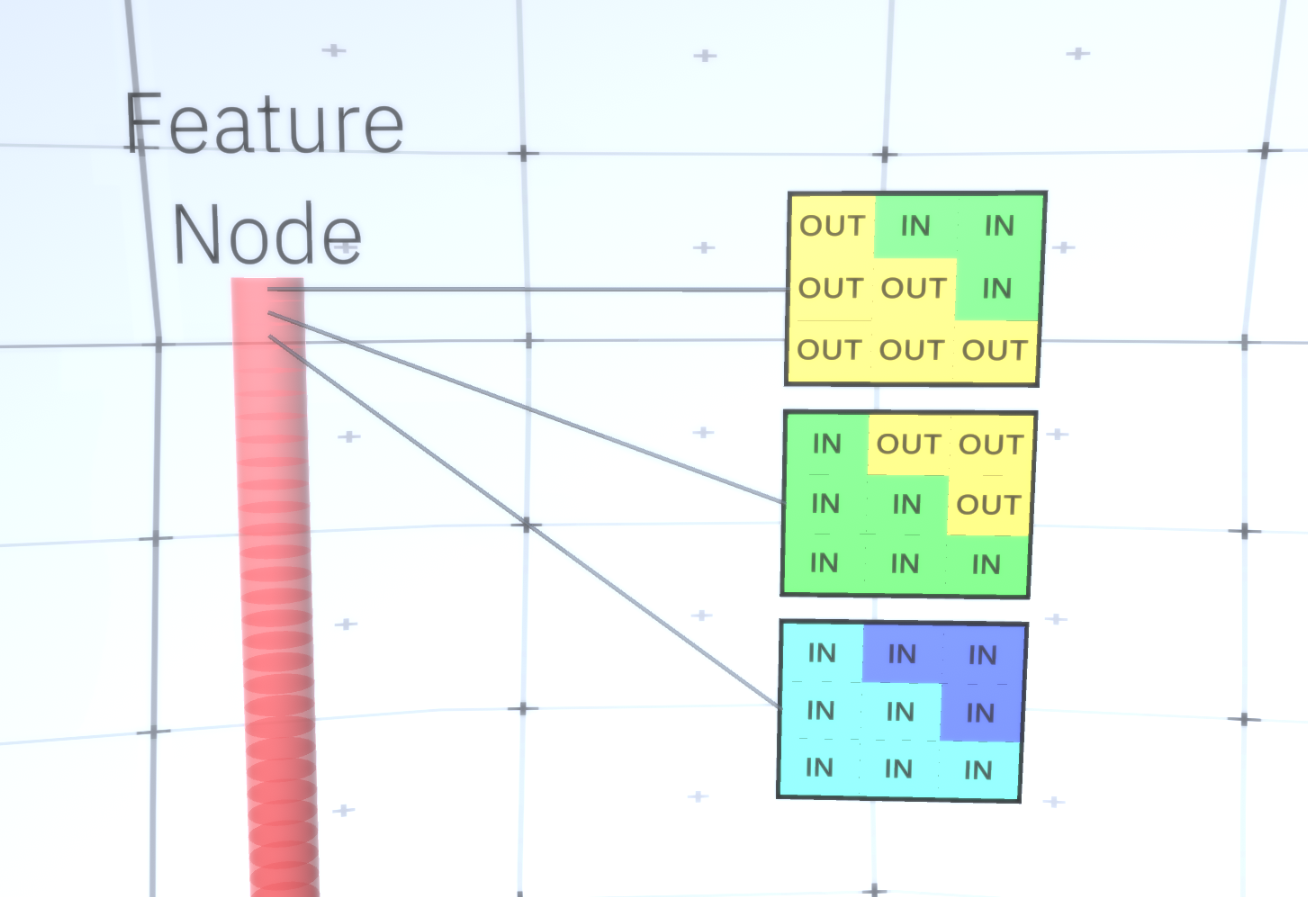 Gambar 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — .
Gambar 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — . 8: «i» .Sekarang kita telah mencapai lapisan tanda terakhir, kita memiliki diagram di mana batas-batas objek ditentukan dan pemahaman apakah area di luar perbatasan adalah internal atau eksternal. Tetap menambahkan tampilan, menunjuk setiap area yang tersisa dalam gambar sebagai IN atau OUT dan mengecat area tersebut. Bidang acak bersyarat dapat membantu di sini. Tanpa masuk ke perincian matematis, kami cukup menetapkan setiap piksel pada gambar akhir distribusi probabilitas berdasarkan warna dan status (IN atau OUT). Distribusi ini akan mencerminkan informasi yang diperoleh dari perbatasan peta. Misalnya, jika ada dua piksel yang berdekatan, salah satunya adalah IN, dan yang lainnya adalah OUT, kemungkinan bahwa mereka akan memiliki warna yang berbeda meningkat sangat. Jika dua piksel yang berdekatan berada di sisi berlawanan dari batas dalam, probabilitasnyayang akan memiliki warna berbeda juga akan bertambah. Jika piksel terletak di dalam perbatasan dan tidak dipisahkan oleh apa pun, maka kemungkinan mereka memiliki warna yang sama meningkat, tetapi piksel eksternal mungkin memiliki sedikit penyimpangan satu sama lain dan seterusnya. Untuk mendapatkan gambar akhir, Anda hanya perlu memilih dari distribusi probabilitas gabungan yang baru saja kami instal. Untuk membuat gambar yang dihasilkan lebih menarik, kita dapat mengganti warna dengan tekstur. Kami tidak akan membahas lapisan ini karena RCN dapat melakukan klasifikasi tanpa didasarkan pada tampilan.Untuk mendapatkan gambar akhir, Anda hanya perlu memilih dari distribusi probabilitas gabungan yang baru saja kami instal. Untuk membuat gambar yang dihasilkan lebih menarik, kita dapat mengganti warna dengan tekstur. Kami tidak akan membahas lapisan ini karena RCN dapat melakukan klasifikasi tanpa didasarkan pada tampilan.Untuk mendapatkan gambar akhir, Anda hanya perlu memilih dari distribusi probabilitas gabungan yang baru saja kami instal. Untuk membuat gambar yang dihasilkan lebih menarik, kita dapat mengganti warna dengan tekstur. Kami tidak akan membahas lapisan ini karena RCN dapat melakukan klasifikasi tanpa didasarkan pada tampilan.Baiklah, kita akan berakhir di sini hari ini. Jika Anda ingin tahu lebih banyak tentang RCN, baca artikel ini [5] dan lampiran dengan bahan tambahan, atau Anda dapat membaca artikel saya yang lain tentang kesimpulan logis , pelatihan dan hasil penggunaan RCN pada berbagai dataset .
8: «i» .Sekarang kita telah mencapai lapisan tanda terakhir, kita memiliki diagram di mana batas-batas objek ditentukan dan pemahaman apakah area di luar perbatasan adalah internal atau eksternal. Tetap menambahkan tampilan, menunjuk setiap area yang tersisa dalam gambar sebagai IN atau OUT dan mengecat area tersebut. Bidang acak bersyarat dapat membantu di sini. Tanpa masuk ke perincian matematis, kami cukup menetapkan setiap piksel pada gambar akhir distribusi probabilitas berdasarkan warna dan status (IN atau OUT). Distribusi ini akan mencerminkan informasi yang diperoleh dari perbatasan peta. Misalnya, jika ada dua piksel yang berdekatan, salah satunya adalah IN, dan yang lainnya adalah OUT, kemungkinan bahwa mereka akan memiliki warna yang berbeda meningkat sangat. Jika dua piksel yang berdekatan berada di sisi berlawanan dari batas dalam, probabilitasnyayang akan memiliki warna berbeda juga akan bertambah. Jika piksel terletak di dalam perbatasan dan tidak dipisahkan oleh apa pun, maka kemungkinan mereka memiliki warna yang sama meningkat, tetapi piksel eksternal mungkin memiliki sedikit penyimpangan satu sama lain dan seterusnya. Untuk mendapatkan gambar akhir, Anda hanya perlu memilih dari distribusi probabilitas gabungan yang baru saja kami instal. Untuk membuat gambar yang dihasilkan lebih menarik, kita dapat mengganti warna dengan tekstur. Kami tidak akan membahas lapisan ini karena RCN dapat melakukan klasifikasi tanpa didasarkan pada tampilan.Untuk mendapatkan gambar akhir, Anda hanya perlu memilih dari distribusi probabilitas gabungan yang baru saja kami instal. Untuk membuat gambar yang dihasilkan lebih menarik, kita dapat mengganti warna dengan tekstur. Kami tidak akan membahas lapisan ini karena RCN dapat melakukan klasifikasi tanpa didasarkan pada tampilan.Untuk mendapatkan gambar akhir, Anda hanya perlu memilih dari distribusi probabilitas gabungan yang baru saja kami instal. Untuk membuat gambar yang dihasilkan lebih menarik, kita dapat mengganti warna dengan tekstur. Kami tidak akan membahas lapisan ini karena RCN dapat melakukan klasifikasi tanpa didasarkan pada tampilan.Baiklah, kita akan berakhir di sini hari ini. Jika Anda ingin tahu lebih banyak tentang RCN, baca artikel ini [5] dan lampiran dengan bahan tambahan, atau Anda dapat membaca artikel saya yang lain tentang kesimpulan logis , pelatihan dan hasil penggunaan RCN pada berbagai dataset .Sumber:
- [1] R. Perrault, Y. Shoham, E. Brynjolfsson, dkk., Laporan Tahunan 2019 Indeks AI (2019), Human-Centered AI Institute - Stanford University.
- [2] D. Hendrycks, K. Zhao, S. Basart, et al., Contoh-contoh permusuhan Alam (2019), arXiv: 1907.07174.
- [3] J. Su, D. Vasconcellos Vargas, dan S. Kouichi, One Pixel Attack untuk Fooling Deep Neural Networks (2017), arXiv: 1710.08864.
- [4] M. Sharif, S. Bhagavatula, L. Bauer, Kerangka Umum untuk Contoh Permusuhan dengan Tujuan (2017), arXiv: 1801.00349.
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
: « : ». Source: https://habr.com/ru/post/undefined/
All Articles