Halo Habr.Nama saya Misha Butrimov, saya ingin berbicara sedikit tentang Cassandra. Kisah saya akan bermanfaat bagi mereka yang belum pernah menemukan basis data NoSQL - ia memiliki banyak fitur implementasi dan jebakan yang perlu Anda ketahui. Dan jika, terlepas dari Oracle atau basis relasional lainnya, Anda belum melihat apa pun, hal-hal ini akan menyelamatkan hidup Anda.Apa yang baik tentang Cassandra? Ini adalah database NoSQL yang dirancang tanpa satu titik kegagalan, yang berskala baik. Jika Anda perlu menambahkan beberapa terabyte untuk basis apa pun, Anda cukup menambahkan node ke ring. Perluas ke pusat data lain? Tambahkan node ke cluster. Tingkatkan RPS yang diproses? Tambahkan node ke cluster. Cara lain juga berhasil. Apa lagi yang dia kuasai? Ini untuk menangani banyak permintaan. Tetapi berapa banyak? 10, 20, 30, 40 ribu permintaan per detik - ini tidak banyak. 100 ribu permintaan per detik untuk direkam juga. Ada perusahaan yang mengatakan mereka menahan 2 juta permintaan per detik. Di sini mereka mungkin harus percaya.Dan pada prinsipnya, Cassandra memiliki satu perbedaan besar dari data relasional - tidak terlihat sama sekali. Dan ini sangat penting untuk diingat.
Apa lagi yang dia kuasai? Ini untuk menangani banyak permintaan. Tetapi berapa banyak? 10, 20, 30, 40 ribu permintaan per detik - ini tidak banyak. 100 ribu permintaan per detik untuk direkam juga. Ada perusahaan yang mengatakan mereka menahan 2 juta permintaan per detik. Di sini mereka mungkin harus percaya.Dan pada prinsipnya, Cassandra memiliki satu perbedaan besar dari data relasional - tidak terlihat sama sekali. Dan ini sangat penting untuk diingat.Tidak semua yang terlihat sama berfungsi sama
Suatu kali seorang kolega mendatangi saya dan bertanya: “Ini adalah bahasa query CQL Cassandra, dan ia memiliki pernyataan pilih, ia memiliki di mana, ia memiliki dan. Saya menulis surat dan itu tidak berhasil. Mengapa?". Jika Anda memperlakukan Cassandra sebagai basis data relasional, maka ini adalah cara yang ideal untuk mengakhiri hidup Anda dengan bunuh diri brutal. Dan saya tidak menganjurkan, itu dilarang di Rusia. Anda hanya merancang sesuatu yang salah.Sebagai contoh, seorang pelanggan mendatangi kami dan berkata: “Mari kita membangun database untuk acara TV, atau database untuk direktori resep. Kami akan memiliki hidangan makanan di sana atau daftar seri dan aktor di dalamnya. " Kami berkata dengan gembira: "Ayo!". Ini adalah dua byte untuk dikirim, beberapa piring dan semuanya sudah siap, semuanya akan bekerja dengan sangat cepat, andal. Dan semuanya baik-baik saja sampai pelanggan datang dan mengatakan bahwa ibu rumah tangga juga menyelesaikan masalah terbalik: mereka memiliki daftar produk dan mereka ingin tahu hidangan apa yang ingin mereka masak. Matilah Kau.Itu karena Cassandra adalah database hybrid: itu adalah nilai kunci dan menyimpan data dalam kolom yang luas. Berbicara di Jawa atau Kotlin, bisa digambarkan seperti ini:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>Yaitu, peta, di dalamnya ada juga peta yang diurutkan. Kunci pertama untuk peta ini adalah tombol Row atau kunci Partition - kunci partisi. Kunci kedua, yang merupakan kunci untuk peta yang sudah diurutkan, adalah kunci Clustering.Untuk mengilustrasikan distribusi database, kami menggambar tiga node. Sekarang Anda perlu memahami cara menguraikan data menjadi node. Karena jika kita mendorong semuanya menjadi satu (omong-omong, mungkin ada seribu, dua ribu, lima - sebanyak yang Anda suka), ini bukan tentang distribusi. Oleh karena itu, kita memerlukan fungsi matematika yang akan mengembalikan angka. Hanya angka, int panjang yang akan jatuh ke dalam kisaran tertentu. Dan kami memiliki satu simpul yang akan bertanggung jawab untuk satu rentang, yang kedua - untuk yang kedua, n-th - untuk n-th. Nomor ini diambil menggunakan fungsi hash yang berlaku hanya untuk apa yang kita sebut kunci Partition. Ini adalah kolom yang ditentukan dalam arahan kunci Primer, dan ini adalah kolom yang akan menjadi kunci peta pertama dan paling dasar. Ini menentukan simpul mana yang mendapatkan data mana. Tabel dibuat di Cassandra dengan sintaksis yang hampir sama seperti di SQL:
Nomor ini diambil menggunakan fungsi hash yang berlaku hanya untuk apa yang kita sebut kunci Partition. Ini adalah kolom yang ditentukan dalam arahan kunci Primer, dan ini adalah kolom yang akan menjadi kunci peta pertama dan paling dasar. Ini menentukan simpul mana yang mendapatkan data mana. Tabel dibuat di Cassandra dengan sintaksis yang hampir sama seperti di SQL:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
Kunci utama dalam hal ini terdiri dari satu kolom, dan juga merupakan kunci partisi.Bagaimana pengguna akan jatuh cinta dengan kami? Sebagian akan jatuh pada satu catatan, sebagian pada yang lain, dan sebagian pada yang ketiga. Ternyata tabel hash biasa, ini juga peta, juga kamus dengan Python, juga struktur nilai Key yang sederhana, dari mana kita bisa membaca semua nilai, membaca dan menulis dengan kunci.
Pilih: saat memungkinkan pemfilteran berubah menjadi pemindaian penuh, atau bagaimana tidak melakukannya
Mari kita menulis beberapa Pernyataan itu pilih: select * from users where, userid = . Tampaknya, seperti di Oracle: kita menulis pilih, kita tentukan kondisi dan semuanya berfungsi, pengguna mendapatkannya. Tetapi jika Anda memilih, misalnya, pengguna dengan tahun kelahiran tertentu, Cassandra bersumpah bahwa dia tidak dapat memenuhi permintaan tersebut. Karena dia tidak tahu apa-apa tentang bagaimana kita mendistribusikan data pada tahun kelahiran - dia hanya memiliki satu kolom yang ditentukan sebagai kunci. Lalu dia berkata, “Oke, saya masih bisa memenuhi permintaan ini. Tambahkan izinkan pemfilteran. " Kami menambahkan arahan, semuanya berfungsi. Dan pada saat itu terjadi hal yang mengerikan.Saat kami mengendarai data uji, semuanya baik-baik saja. Dan ketika Anda memenuhi permintaan dalam produksi, di mana, misalnya, kami memiliki 4 juta rekaman, maka semuanya tidak begitu baik bagi kami. Karena memungkinkan pemfilteran adalah arahan yang memungkinkan Cassandra untuk mengumpulkan semua data dari tabel ini dari semua node, semua pusat data (jika ada banyak di cluster ini), dan hanya kemudian memfilternya. Ini adalah analog dari Pemindaian Lengkap, dan hampir tidak ada orang yang menyukainya.Jika kami hanya membutuhkan pengguna dengan pengidentifikasi, ini cocok untuk kami. Tetapi kadang-kadang kita perlu menulis pertanyaan lain dan menerapkan batasan lain pada seleksi. Karena itu, kita ingat: kita semua memiliki peta, yang memiliki kunci partisi, tetapi di dalamnya ada peta yang diurutkan.Dan dia juga memiliki kunci, yang kami sebut Kunci Clustering. Kunci ini, yang, pada gilirannya, terdiri dari kolom yang kami pilih, yang dengannya Cassandra memahami bagaimana datanya diurutkan secara fisik dan akan terletak pada setiap node. Yaitu, untuk beberapa kunci Partisi, kunci Clustering akan memberi tahu Anda bagaimana mendorong data ke pohon ini, tempat apa yang akan mereka ambil di sana.Ini adalah pohon asli, pembanding disebut di sana, di mana kita melewati kumpulan kolom tertentu dalam bentuk objek, dan juga diatur dalam bentuk enumerasi kolom.CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Perhatikan arahan kunci Primer, ia memiliki argumen pertama (dalam kasus kami tahun ini) selalu merupakan kunci Partition. Itu bisa terdiri dari satu atau beberapa kolom, tidak masalah. Jika ada beberapa kolom, Anda harus menghapusnya lagi di dalam tanda kurung agar preprocessor bahasa memahami bahwa ini adalah kunci Utama, dan di belakangnya semua kolom lainnya - kunci Clustering. Dalam hal ini, mereka akan ditransmisikan dalam komparator sesuai urutan kemana mereka pergi. Artinya, kolom pertama lebih signifikan, yang kedua kurang signifikan dan seterusnya. Saat kita menulis untuk kelas data, misalnya, sama dengan bidang: kita mencantumkan bidang, dan untuk mereka kita menulis yang lebih besar dan yang lebih kecil. Dalam Cassandra, ini, secara relatif, bidang kelas data yang sama dengan yang ditulis untuk itu akan diterapkan.Kami mengatur semacam itu, memberlakukan batasan
Harus diingat bahwa urutan pengurutan (menurun, meningkat, itu tidak masalah) diatur pada saat yang sama ketika kunci dibuat, dan kemudian Anda tidak dapat mengubahnya nanti. Secara fisik menentukan bagaimana data akan diurutkan dan bagaimana itu akan berbohong. Jika Anda perlu mengubah kunci Clustering atau urutan, Anda harus membuat tabel baru dan menuangkan data ke dalamnya. Dengan yang sudah ada ini tidak akan berfungsi.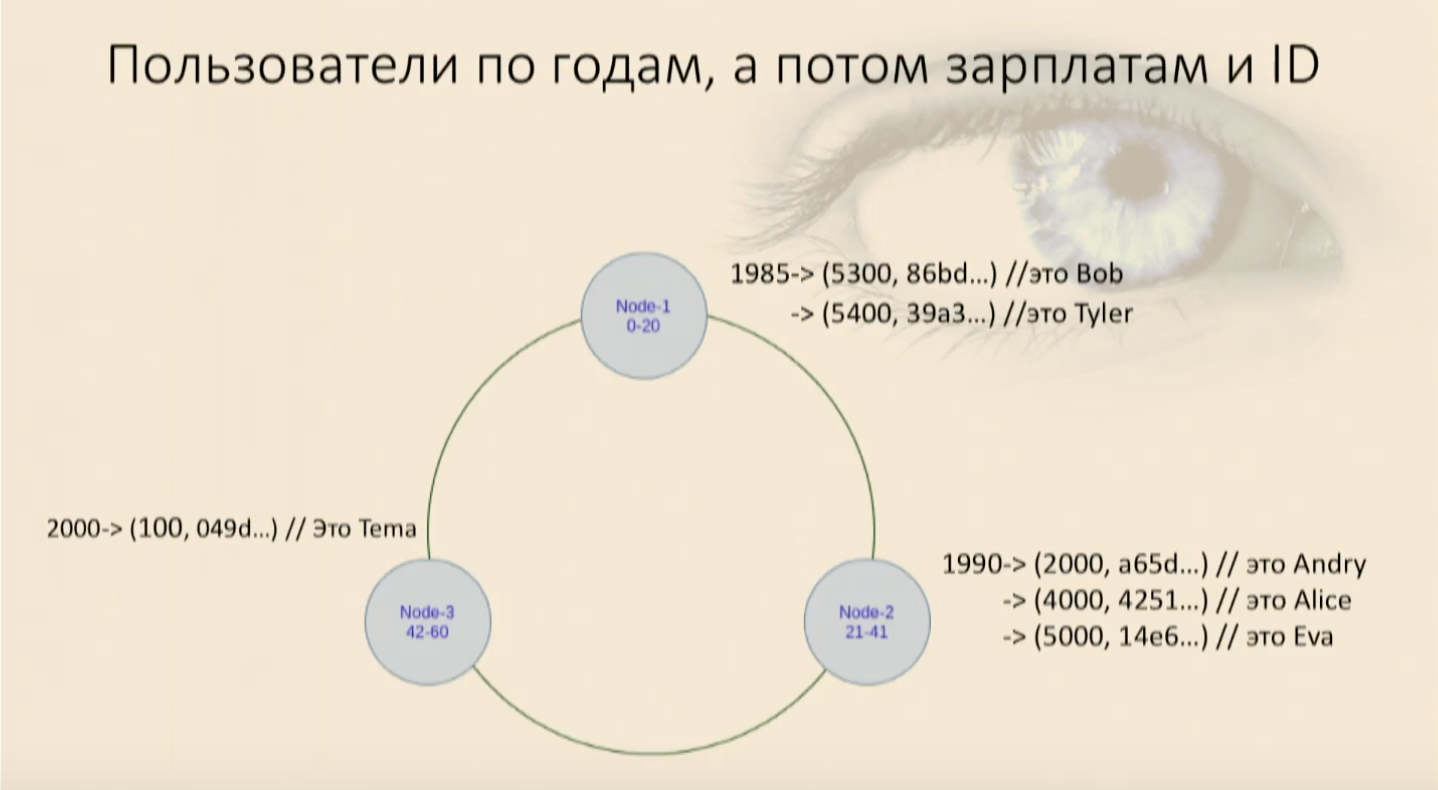 Kami mengisi meja kami dengan pengguna dan melihat bahwa mereka masuk ke cincin, pertama berdasarkan tahun kelahiran, dan kemudian di dalam pada setiap node dengan gaji dan dengan ID pengguna. Sekarang kita bisa memilih, memaksakan pembatasan.Pekerjaan kami muncul lagi
Kami mengisi meja kami dengan pengguna dan melihat bahwa mereka masuk ke cincin, pertama berdasarkan tahun kelahiran, dan kemudian di dalam pada setiap node dengan gaji dan dengan ID pengguna. Sekarang kita bisa memilih, memaksakan pembatasan.Pekerjaan kami muncul lagiwhere, and, dan pengguna mendatangi kami, dan semuanya baik-baik saja. Tetapi jika kita mencoba menggunakan hanya bagian kunci Clustering, bagian yang kurang penting, maka Cassandra akan segera bersumpah bahwa kita tidak dapat menemukan di peta kita di mana objek ini memiliki bidang-bidang ini untuk pembanding nol, tetapi yang ini yang baru saja Anda atur - di mana letaknya. Saya harus mengambil semua data dari node ini lagi dan memfilternya. Dan ini adalah analog Pemindaian Penuh dalam node, ini buruk.Dalam situasi yang tidak dapat dipahami, buat tabel baru
Jika kita ingin mendapatkan pengguna berdasarkan ID atau berdasarkan usia atau gaji, apa yang harus kita lakukan? Tidak ada. Cukup gunakan dua tabel. Jika Anda perlu mendapatkan pengguna dengan tiga cara berbeda - akan ada tiga tabel. Lewat sudah hari-hari ketika kita menghemat ruang pada sekrup. Ini sumber daya termurah. Harganya jauh lebih sedikit daripada waktu respons, yang bisa berakibat fatal bagi pengguna. Pengguna jauh lebih baik untuk mendapatkan sesuatu dalam hitungan detik daripada dalam 10 menit.Kami bertukar ruang yang berlebihan, mendenormalkan data untuk kemampuan untuk mengukur dengan baik, bekerja dengan andal. Memang, pada kenyataannya, sebuah cluster yang terdiri dari tiga pusat data, yang masing-masing memiliki lima node, dengan tingkat penyimpanan data yang dapat diterima (ketika tidak ada yang pasti hilang), mampu bertahan dari kematian satu pusat data sepenuhnya. Dan dua node lagi di masing-masing dua yang tersisa. Dan hanya setelah itu masalahnya dimulai. Ini adalah redundansi yang cukup bagus, harganya beberapa ssd-drive dan prosesor yang tidak perlu. Oleh karena itu, untuk menggunakan Cassandra, yang tidak pernah SQL, di mana tidak ada hubungan, tidak ada kunci asing, Anda perlu mengetahui aturan sederhana.Kami merancang semuanya dari permintaan. Yang utama bukanlah data, tetapi bagaimana aplikasi akan bekerja dengannya. Jika dia perlu menerima data yang berbeda dengan cara yang berbeda atau data yang sama dengan cara yang berbeda, kita harus meletakkannya dengan cara yang nyaman untuk aplikasi. Kalau tidak, kita akan gagal dalam Pemindaian Penuh dan Cassandra tidak akan memberi kita keuntungan apa pun.Mendenormalkan data adalah norma. Lupakan formulir normal, kami tidak lagi memiliki basis data relasional. Kami meletakkan sesuatu 100 kali, itu akan berbohong 100 kali. Itu lebih murah daripada menghentikannya.Kami memilih tombol untuk mempartisi sehingga terdistribusi secara normal. Kita tidak perlu hash dari kunci kita untuk jatuh ke dalam satu rentang sempit. Artinya, tahun kelahiran dalam contoh di atas adalah contoh yang buruk. Sebaliknya, itu baik jika pengguna kami biasanya didistribusikan berdasarkan tahun kelahiran, dan buruk jika kita berbicara tentang siswa kelas 5 - itu tidak akan sangat baik untuk dipartisi di sana.Penyortiran dipilih satu kali selama pembuatan Kunci Clustering. Jika Anda perlu mengubahnya, Anda harus memenuhi sampai melimpahi meja kami dengan kunci yang berbeda.Dan yang paling penting: jika kita perlu mengumpulkan data yang sama dalam 100 cara berbeda, maka kita akan memiliki 100 tabel berbeda.