Halo semuanya!Saya ingin berbicara tentang proyek yang sangat membosankan di mana robot, Machine Learning (dan bersama-sama ini adalah Robot Learning), realitas virtual dan sedikit teknologi cloud berpotongan. Dan semua ini sebenarnya masuk akal. Lagipula, sangat nyaman untuk pindah ke robot, menunjukkan apa yang harus dilakukan, dan kemudian melatih beban di server ML menggunakan data yang disimpan.Di bawah potongan, kami akan memberi tahu cara kerjanya sekarang, dan beberapa perincian tentang masing-masing aspek yang harus dikembangkan.
Untuk apa
Sebagai permulaan, ada baiknya mengungkapkan sedikit.Tampaknya robot yang dipersenjatai dengan Deep Learning akan mengusir orang dari pekerjaan mereka di mana-mana. Padahal, semuanya tidak begitu mulus. Di mana tindakan diulangi secara ketat, proses sudah benar-benar otomatis. Jika kita berbicara tentang "robot pintar", yaitu aplikasi di mana visi dan algoritma komputer sudah cukup. Tetapi ada juga banyak cerita yang sangat rumit. Robot hampir tidak dapat mengatasi berbagai objek yang harus dihadapi, dan keanekaragaman lingkungan.Poin-poin penting
Ada 3 hal utama dalam hal implementasi yang belum ditemukan di mana-mana:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
Yang kedua juga penting karena saat ini kita akan mengamati perubahan dalam pendekatan pembelajaran, algoritma, di belakangnya, dan alat komputasi. Algoritma persepsi dan kontrol akan menjadi lebih fleksibel. Upgrade robot membutuhkan biaya. Dan kalkulator dapat digunakan lebih efisien jika akan melayani beberapa robot sekaligus. Konsep ini disebut "cloud robotics".Dengan yang terakhir, semuanya sederhana - AI tidak cukup berkembang saat ini untuk memberikan keandalan dan akurasi 100% dalam semua situasi yang diperlukan oleh bisnis. Oleh karena itu, operator pengawas, yang terkadang dapat membantu robot bangsal, tidak akan terluka.Skema
Untuk mulai dengan, tentang platform perangkat lunak / jaringan yang menyediakan semua fungsi yang dijelaskan: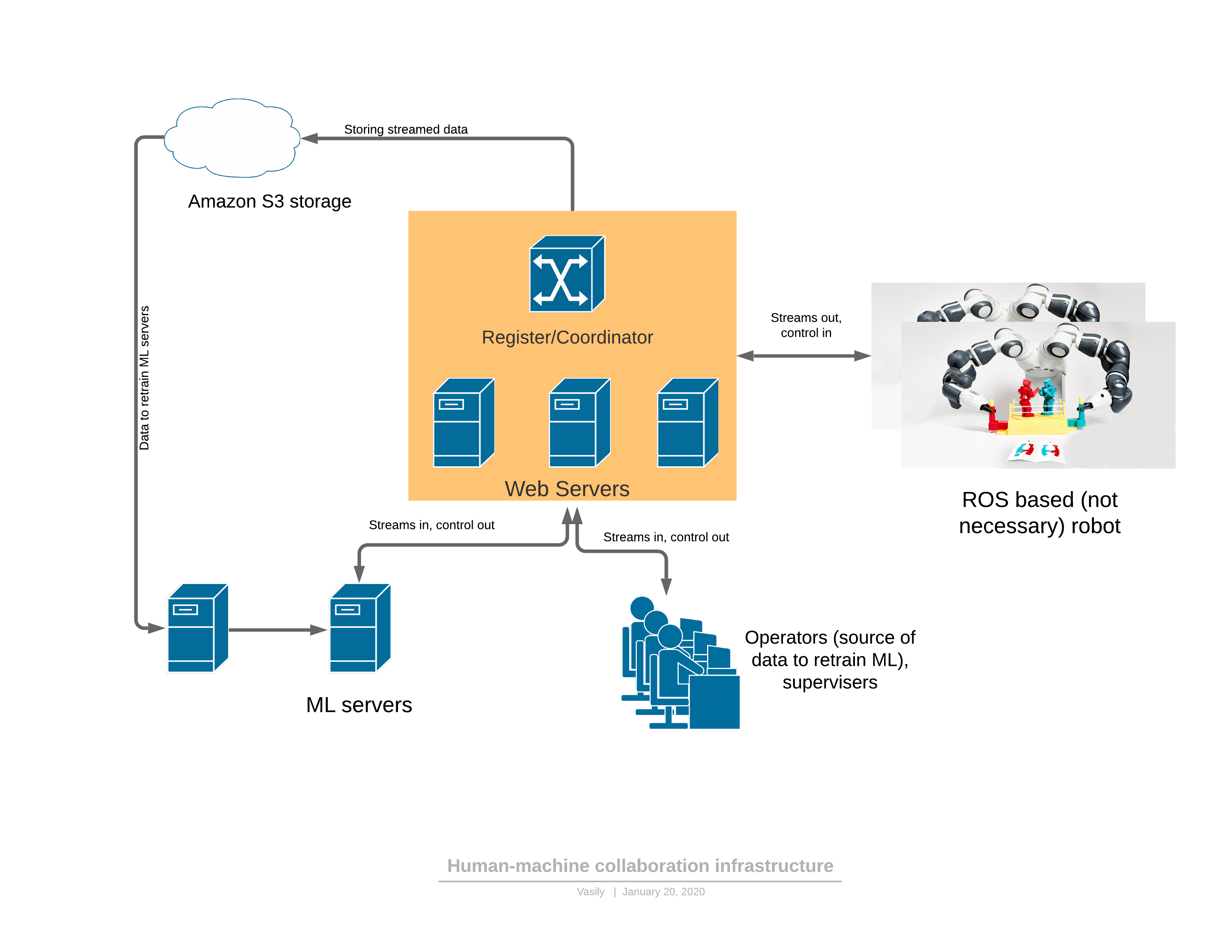 Komponen:
Komponen:- Robot mengirimkan aliran video 3D ke server dan menerima kontrol sebagai respons.
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
Ada 2 mode fungsi robot: otomatis dan manual.Dalam mode manual, robot berfungsi jika layanan ML belum dilatih. Kemudian robot beralih dari otomatis ke manual baik atas permintaan operator (saya melihat perilaku aneh saat menonton robot), atau ketika layanan ML sendiri mendeteksi anomali. Tentang deteksi anomali akan terjadi kemudian - ini adalah bagian yang sangat penting, yang tanpanya mustahil untuk menerapkan pendekatan yang diusulkan.Evolusi kontrol adalah sebagai berikut:- Tugas robot dibentuk dalam istilah yang dapat dibaca manusia dan indikator kinerja dijelaskan.
- Operator terhubung ke robot di VR dan melakukan tugas dalam alur kerja yang ada selama beberapa waktu
- Bagian ML dilatih tentang data yang diterima
- , ML
3D
Sangat sering, robot menggunakan lingkungan ROS (sistem operasi robot), yang sebenarnya merupakan kerangka kerja untuk mengelola "node" (node), yang masing-masing menyediakan bagian dari fungsi robot. Secara umum, ini adalah cara yang relatif mudah untuk pemrograman robot, yang dalam beberapa hal menyerupai arsitektur microservice dari aplikasi web pada intinya. Keuntungan utama ROS adalah standar industri dan sudah ada sejumlah besar modul yang diperlukan untuk membuat robot. Bahkan lengan robot industri dapat memiliki modul antarmuka ROS.Yang paling sederhana adalah membuat model jembatan antara bagian server kami dan ROS. Misalnya, begini. Sekarang dalam proyek kami, kami menggunakan versi yang lebih maju dari "simpul" ROS, yang login dan polling layanan microser dari register dimana server relay robot tertentu dapat terhubung. Kode sumber hanya diberikan sebagai contoh instruksi untuk menginstal modul ROS. Pada awalnya, ketika Anda menguasai kerangka kerja ini (ROS), semuanya terlihat sangat tidak ramah, tetapi dokumentasinya cukup bagus, dan setelah beberapa minggu, pengembang mulai menggunakan fungsinya dengan cukup percaya diri.Dari menarik - masalah kompresi aliran data 3D, yang harus diproduksi langsung pada robot.Tidaklah mudah untuk mengompres peta kedalaman. Bahkan dengan sedikit kompresi aliran RGB, distorsi kecerahan lokal yang sangat serius dari true dalam piksel di perbatasan atau ketika objek bergerak diizinkan. Mata hampir tidak memperhatikan hal ini, tetapi segera setelah distorsi yang sama diizinkan di peta kedalaman, ketika membuat 3D semuanya menjadi sangat buruk: (dari artikel )Cacat di tepi sangat merusak pemandangan 3D, karena hanya ada banyak sampah di udara.Kami mulai menggunakan kompresi frame-by-frame - JPEG untuk RGB dan PNG untuk peta kedalaman dengan retasan kecil. Metode ini memampatkan aliran 30FPS untuk resolusi pemindai 3D 640x480 pada 25 Mbps. Kompresi yang lebih baik juga dapat diberikan jika lalu lintas sangat penting untuk aplikasi. Ada codec aliran 3D komersial yang juga dapat digunakan untuk mengompresi aliran ini.
(dari artikel )Cacat di tepi sangat merusak pemandangan 3D, karena hanya ada banyak sampah di udara.Kami mulai menggunakan kompresi frame-by-frame - JPEG untuk RGB dan PNG untuk peta kedalaman dengan retasan kecil. Metode ini memampatkan aliran 30FPS untuk resolusi pemindai 3D 640x480 pada 25 Mbps. Kompresi yang lebih baik juga dapat diberikan jika lalu lintas sangat penting untuk aplikasi. Ada codec aliran 3D komersial yang juga dapat digunakan untuk mengompresi aliran ini.Kontrol realitas virtual
Setelah kami kalibrasi kerangka referensi kamera dan robot (dan kami sudah menulis artikel tentang kalibrasi ), lengan robot dapat dikontrol dalam realitas virtual. Pengontrol mengatur posisi dalam 3D XYZ dan orientasi. Untuk beberapa roboruk, hanya 3 koordinat yang akan cukup, tetapi dengan sejumlah besar derajat kebebasan, orientasi alat yang ditentukan oleh pengontrol juga harus ditransmisikan. Selain itu, ada cukup kontrol pada pengontrol untuk menjalankan perintah robot seperti menghidupkan / mematikan pompa, mengendalikan gripper, dan lainnya.Awalnya, diputuskan untuk menggunakan kerangka kerja JavaScript untuk A-frame realitas virtual, berdasarkan pada mesin WebVR. Dan hasil pertama (demonstrasi video di akhir artikel untuk lengan 4-koordinat) diperoleh pada bingkai-A.Faktanya, ternyata WebVR (atau A-frame) adalah solusi yang gagal karena beberapa alasan:- kompatibilitas terutama dengan FireFox , dan di FireFox kerangka A-frame tidak melepaskan sumber daya tekstur (sisa browser diatasi) hingga konsumsi memori mencapai 16GB
- interaksi terbatas dengan pengontrol dan helm VR. Jadi, misalnya, tidak mungkin untuk menambahkan tanda tambahan yang dapat Anda gunakan untuk mengatur posisi, misalnya, dari siku operator.
- Aplikasi ini membutuhkan multithreading atau beberapa proses. Dalam satu utas / proses, perlu untuk membongkar bingkai video, di yang lain - undian. Akibatnya, semuanya diatur melalui pekerja, tetapi waktu pembongkaran mencapai 30 ms, dan rendering dalam VR harus dilakukan pada frekuensi 90FPS.
Semua kekurangan ini menghasilkan fakta bahwa rendering frame tidak punya waktu dalam 10ms yang diberikan dan ada kedutan yang sangat tidak menyenangkan di VR. Mungkin, semuanya bisa diatasi, tetapi identitas masing-masing browser sedikit mengganggu.Sekarang kami memutuskan untuk berangkat ke port C #, OpenTK dan C # dari pustaka OpenVR. Masih ada alternatif - Persatuan. Mereka menulis bahwa Persatuan adalah untuk pemula ... tetapi sulit.Hal terpenting yang perlu ditemukan dan dikenal untuk mendapatkan kebebasan:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(ini adalah kode untuk mengirim dua tekstur ke mata kiri dan kanan helm)yaitu menggambar OpenGL dalam tekstur yang dilihat mata berbeda, dan mengirimkannya ke kacamata. Joy tidak mengenal batas ketika ternyata mengisi mata kiri dengan merah, dan kanan dengan biru. Hanya beberapa hari dan sekarang kedalaman dan peta RGB yang datang melalui webSocket dipindahkan ke model poligonal dalam 10ms, bukan 30 di JS. Dan kemudian cukup menginterogasi koordinat dan tombol pengendali, masukkan sistem acara untuk tombol, proses klik pengguna, masukkan Mesin Negara untuk UI dan sekarang Anda dapat mengambil gelas dari espresso:Sekarang kualitas Realsense D435 agak menyedihkan, tetapi akan segera berlalu begitu kami memberikan setidaknya pemindai 3D yang menarik dari Microsoft , titik cloud yang jauh lebih akurat.Sisi server
Relay serverElemen fungsional utama adalah relay server (server di tengah), yang menerima aliran video dari robot dengan gambar 3D dan pembacaan sensor dan keadaan robot dan mendistribusikannya di antara konsumen. Input data - frame yang dikemas dan pembacaan sensor yang datang melalui TCP / IP. Distribusi ke konsumen dilakukan oleh soket web (mekanisme yang sangat nyaman untuk streaming ke beberapa konsumen, termasuk browser).Selain itu, server staging menyimpan aliran data di penyimpanan cloud S3 sehingga nantinya dapat digunakan untuk pelatihan.Setiap server relai mendukung API http, yang memungkinkan Anda mengetahui keadaan saat ini, yang nyaman untuk memantau koneksi saat ini.Tugas relai cukup sulit, baik dari sudut pandang komputasi maupun dari sudut pandang lalu lintas. Oleh karena itu, di sini kami mengikuti logika bahwa server relai digunakan pada berbagai server cloud. Dan itu berarti bahwa Anda perlu melacak siapa yang menghubungkan di mana (terutama jika robot dan operator berada di daerah yang berbeda).Daftar yangpaling dapat diandalkan sekarang akan sulit untuk ditetapkan untuk setiap robot yang dapat terhubung ke server (redundansi tidak akan merugikan). Layanan manajemen ML dikaitkan dengan robot, itu polling server relay untuk menentukan yang mana robot terhubung dan terhubung ke yang sesuai, jika, tentu saja, ia memiliki hak yang cukup untuk ini. Aplikasi operator bekerja dengan cara yang sama.Yang paling menyenangkan! Karena kenyataan bahwa pelatihan robot adalah layanan, layanan hanya dapat dilihat oleh kami di dalam. Jadi, front-end-nya bisa senyaman mungkin bagi kita! Itu itu adalah konsol di peramban (ada perpustakaan terminalJS dengan kesederhanaan yang luar biasa , yang sangat mudah untuk dimodifikasi jika Anda menginginkan fungsi tambahan, seperti TAB pelengkapan otomatis atau riwayat panggilan putar) dan sepertinya ini: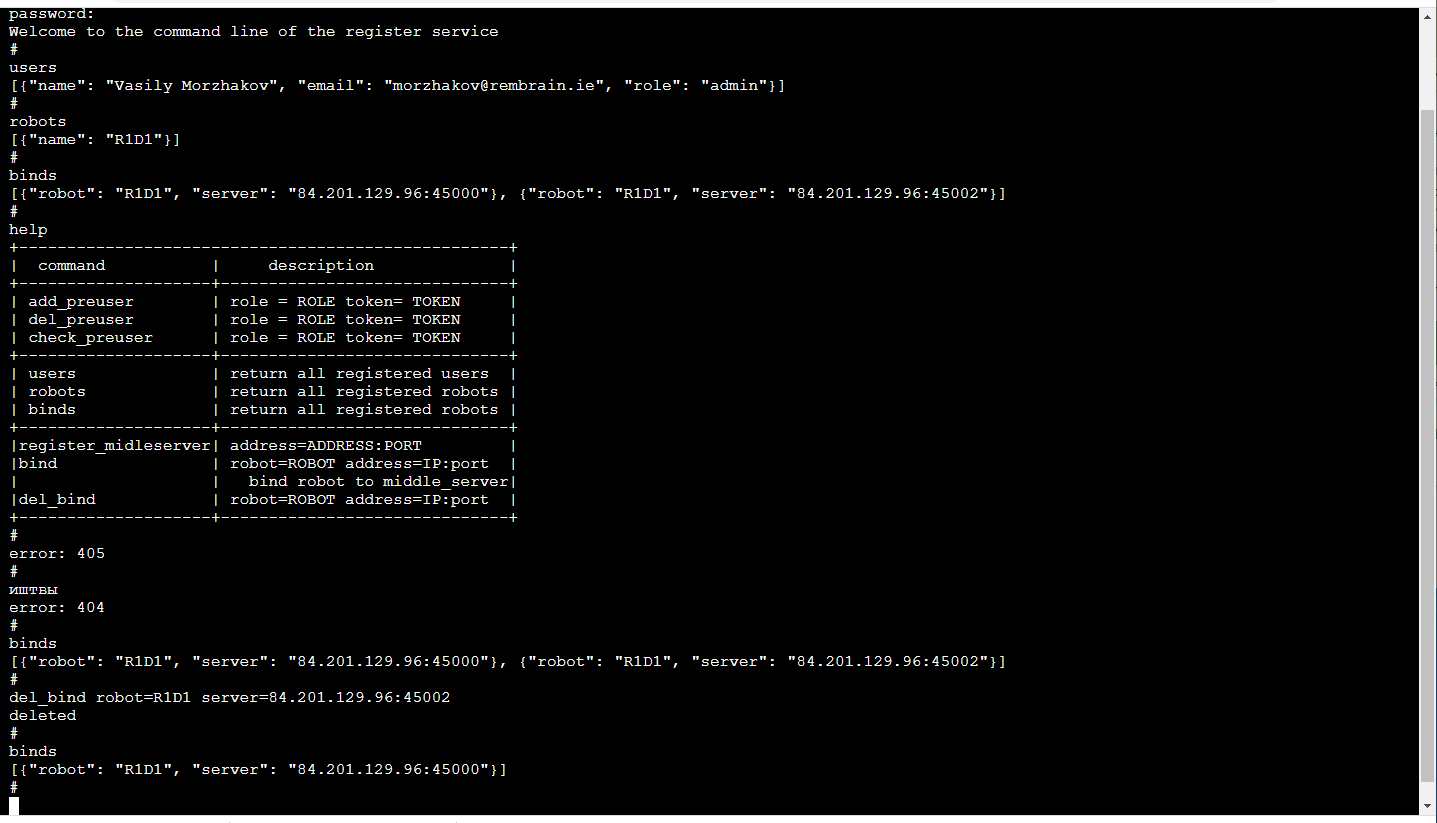 Ini, tentu saja, merupakan topik terpisah untuk diskusi, mengapa baris perintah untuk diskusi, mengapa baris perintah untuk diskusi sangat nyaman. Ngomong-ngomong, sangat nyaman untuk melakukan pengujian unit pada frontend tersebut.Selain http API, layanan ini menerapkan mekanisme untuk mendaftarkan pengguna dengan token sementara, operator login / logout, administrator dan robot, dukungan sesi, kunci enkripsi sesi untuk lalu lintas antara server relay dan robot.Semua ini dilakukan dalam Python dengan Flask - tumpukan yang sangat dekat untuk pengembang ML (mis. Kami). Ya, di samping itu, infrastruktur CI / CD yang ada untuk layanan-layanan microser sesuai dengan Flask.
Ini, tentu saja, merupakan topik terpisah untuk diskusi, mengapa baris perintah untuk diskusi, mengapa baris perintah untuk diskusi sangat nyaman. Ngomong-ngomong, sangat nyaman untuk melakukan pengujian unit pada frontend tersebut.Selain http API, layanan ini menerapkan mekanisme untuk mendaftarkan pengguna dengan token sementara, operator login / logout, administrator dan robot, dukungan sesi, kunci enkripsi sesi untuk lalu lintas antara server relay dan robot.Semua ini dilakukan dalam Python dengan Flask - tumpukan yang sangat dekat untuk pengembang ML (mis. Kami). Ya, di samping itu, infrastruktur CI / CD yang ada untuk layanan-layanan microser sesuai dengan Flask.Masalah keterlambatan
Jika kita ingin mengontrol manipulator secara real time, maka keterlambatan minimum sangat berguna. Jika penundaan menjadi terlalu besar (lebih dari 300 ms), maka sangat sulit untuk mengontrol manipulator berdasarkan gambar di helm virtual. Dalam solusi kami, karena kompresi frame-by-frame (yaitu, tidak ada buffering) dan tidak menggunakan alat standar seperti GStreamer, penundaan bahkan memperhitungkan server perantara adalah sekitar 150-200 ms. Waktu transmisi melalui jaringan mereka adalah sekitar 80 ms. Sisa penundaan disebabkan oleh kamera Realsense D435 dan frekuensi penangkapan terbatas.Tentu saja, ini adalah masalah ketinggian penuh yang muncul dalam mode "pelacakan", ketika manipulator dalam kenyataannya terus-menerus mengikuti pengontrol operator dalam realitas virtual. Dalam mode pindah ke titik XYZ tertentu, penundaan tidak menyebabkan masalah bagi operator.Bagian ML
Ada 2 jenis layanan: manajemen dan pelatihan.Layanan pelatihan mengumpulkan data yang disimpan dalam penyimpanan S3 dan memulai pelatihan ulang bobot model. Pada akhir pelatihan, bobot dikirim ke layanan manajemen.Layanan manajemen tidak berbeda dalam hal input dan output data dari aplikasi operator. Demikian juga, aliran input RGBD (RGB + Depth), pembacaan sensor dan status robot, perintah kontrol output. Karena identitas ini, tampaknya mungkin untuk melatih dalam kerangka konsep "pelatihan berbasis data".Keadaan robot (dan pembacaan sensor) adalah kisah kunci bagi ML. Ini mendefinisikan konteksnya. Misalnya, robot akan memiliki mesin negara yang merupakan karakteristik operasinya, yang sangat menentukan jenis kontrol apa yang diperlukan. 2 nilai ini ditransmisikan bersama dengan setiap frame: mode operasi dan vektor keadaan robot.Dan sedikit tentang pelatihan:Dalam demonstrasi di akhir artikel adalah tugas menemukan objek (kubus anak-anak) di adegan 3D. Ini adalah tugas dasar untuk memilih & menempatkan aplikasi.Pelatihan ini didasarkan pada sepasang frame "sebelum dan sesudah" dan penunjukan target yang diperoleh dengan kontrol manual: Karena adanya dua peta kedalaman, mudah untuk menghitung topeng objek yang dipindahkan dalam bingkai:
Karena adanya dua peta kedalaman, mudah untuk menghitung topeng objek yang dipindahkan dalam bingkai: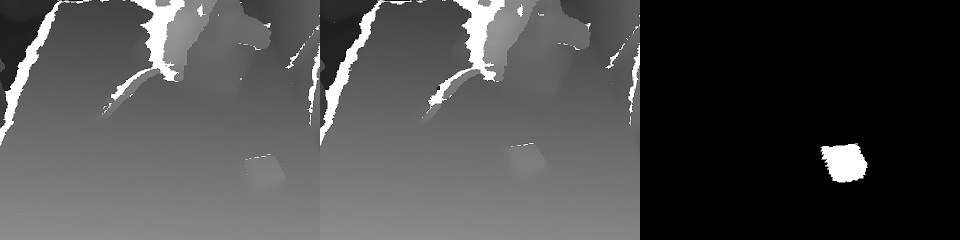 Selain itu, xyz diproyeksikan ke bidang kamera dan Anda dapat memilih lingkungan objek yang diambil:
Selain itu, xyz diproyeksikan ke bidang kamera dan Anda dapat memilih lingkungan objek yang diambil: Sebenarnya dengan lingkungan ini dan akan bekerja.Pertama kita mendapatkan XY dengan melatih Unet jaringan convolutional untuk segmentasi kubus.Kemudian, kita perlu menentukan kedalaman dan memahami jika gambar tidak normal di depan kita. Ini dilakukan dengan menggunakan auto encoder di RGB dan auto encoder bersyarat secara mendalam.Arsitektur model untuk pelatihan pembuat
Sebenarnya dengan lingkungan ini dan akan bekerja.Pertama kita mendapatkan XY dengan melatih Unet jaringan convolutional untuk segmentasi kubus.Kemudian, kita perlu menentukan kedalaman dan memahami jika gambar tidak normal di depan kita. Ini dilakukan dengan menggunakan auto encoder di RGB dan auto encoder bersyarat secara mendalam.Arsitektur model untuk pelatihan pembuat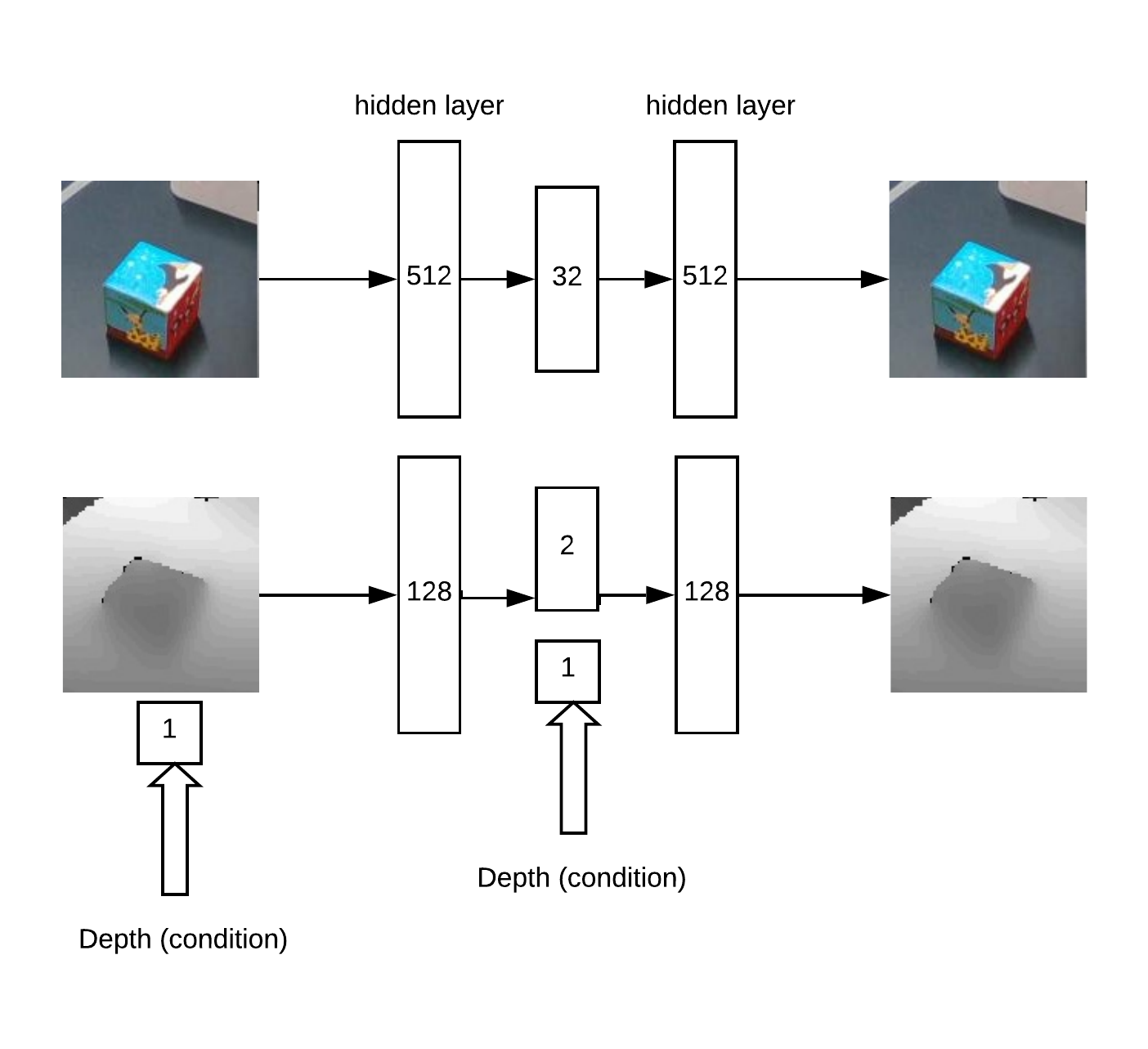 kode otomatis: Akibatnya, logika kerja:
kode otomatis: Akibatnya, logika kerja:- mencari maksimum pada "peta panas" (tentukan koordinat sudut u = x / zv = y / z objek) yang melebihi ambang
- kemudian auto encoder merekonstruksi lingkungan dari titik yang ditemukan untuk semua hipotesis secara mendalam (dengan langkah yang diberikan dari min_depth ke max_depth) dan memilih kedalaman di mana perbedaan antara rekonstruksi dan input minimal
- Memiliki koordinat sudut u, v dan kedalaman, Anda bisa mendapatkan koordinat x, y, z
Contoh rekonstruksi auto-encoder dari peta kedalaman kubus dengan kedalaman yang didefinisikan dengan benar: Sebagian, gagasan metode pencarian kedalaman didasarkan pada artikel tentang set auto-encoders .Pendekatan ini bekerja dengan baik untuk objek dari berbagai bentuk.Namun, secara umum, ada banyak pendekatan berbeda untuk menemukan objek XYZ dari gambar RGBD. Tentu saja, perlu dalam praktiknya dan pada sejumlah besar data untuk memilih metode yang paling akurat.Ada juga tugas mendeteksi anomali, untuk ini kita perlu jaringan konvolusional segmentasi untuk belajar dari topeng yang tersedia. Kemudian, menurut topeng ini, Anda dapat mengevaluasi keakuratan rekonstruksi auto-encoder di peta kedalaman dan RGB. Karena perbedaan ini, seseorang dapat memutuskan keberadaan anomali.Karena metode ini, dimungkinkan untuk mendeteksi tampilan objek yang sebelumnya tidak terlihat dalam bingkai, yang tetap terdeteksi oleh algoritma pencarian utama.
Sebagian, gagasan metode pencarian kedalaman didasarkan pada artikel tentang set auto-encoders .Pendekatan ini bekerja dengan baik untuk objek dari berbagai bentuk.Namun, secara umum, ada banyak pendekatan berbeda untuk menemukan objek XYZ dari gambar RGBD. Tentu saja, perlu dalam praktiknya dan pada sejumlah besar data untuk memilih metode yang paling akurat.Ada juga tugas mendeteksi anomali, untuk ini kita perlu jaringan konvolusional segmentasi untuk belajar dari topeng yang tersedia. Kemudian, menurut topeng ini, Anda dapat mengevaluasi keakuratan rekonstruksi auto-encoder di peta kedalaman dan RGB. Karena perbedaan ini, seseorang dapat memutuskan keberadaan anomali.Karena metode ini, dimungkinkan untuk mendeteksi tampilan objek yang sebelumnya tidak terlihat dalam bingkai, yang tetap terdeteksi oleh algoritma pencarian utama.Demonstrasi
Memeriksa dan men-debug seluruh platform perangkat lunak yang dibuat dilakukan di stand:- Kamera 3D Realsense D435
- 4 mengoordinasikan Dobot Magician
- Helm VR HTC Vive
- Server di Yandex Cloud (mengurangi latensi dibandingkan dengan AWS cloud)
Dalam video, kami mengajarkan cara menemukan kubus di adegan 3D dengan melakukan tugas di VR pick & place. Sekitar 50 contoh sudah cukup untuk pelatihan kubus. Kemudian objek berubah dan sekitar 30 contoh lainnya ditampilkan. Setelah pelatihan ulang, robot dapat menemukan objek baru.Seluruh proses memakan waktu sekitar 15 menit, di mana sekitar setengah model pelatihan bobot.Dan dalam video ini, YuMi mengontrol dalam VR. Untuk mempelajari cara memanipulasi objek, Anda perlu mengevaluasi orientasi dan lokasi alat. Matematika dibangun berdasarkan prinsip yang sama, tetapi sekarang berada pada tahap pengujian dan pengembangan.Kesimpulan
Data besar dan Pembelajaran mendalam tidak semuanya.Kami mengubah pendekatan untuk belajar, bergerak menuju cara orang belajar hal-hal baru - melalui mengulangi apa yang mereka lihat.Aparat matematika "di bawah tenda", yang akan kami kembangkan pada aplikasi nyata, ditujukan untuk masalah interpretasi dan kontrol konteks-sensitif. Konteksnya di sini adalah informasi alami yang tersedia dari sensor robot atau informasi eksternal tentang proses saat ini.Dan, semakin banyak proses teknologi yang kita kuasai, semakin banyak struktur "otak di awan" akan dikembangkan, dan bagian-bagiannya akan dilatih.Kekuatan dari pendekatan ini:- kemungkinan mempelajari cara memanipulasi objek variabel
- belajar di lingkungan yang berubah (mis. robot seluler)
- tugas yang tidak terstruktur dengan baik
- waktu singkat ke pasar; Anda dapat melakukan target bahkan dalam mode manual menggunakan operator
Batasan:- butuhkan untuk internet yang andal dan bagus
- metode tambahan diperlukan untuk mencapai akurasi tinggi, misalnya, kamera dalam manipulator itu sendiri
Kami saat ini sedang berupaya menerapkan pendekatan kami pada tugas memilih & menempatkan berbagai objek secara standar. Tetapi nampaknya bagi kita (secara alami!) Bahwa ia mampu berbuat lebih banyak. Ada ide di mana lagi untuk mencoba tangan Anda?Terima kasih atas perhatian Anda!