HighLoad ++, Mikhail Makurov, Maxim Chernetsov (Intersvyaz): Zabbix, 100kNVPS pada satu server
Konferensi HighLoad ++ berikutnya akan diadakan pada 6 dan 7 April 2020 di St. Petersburg. Rincian dan tiket di sini . HighLoad ++ Moscow 2018. Moscow Hall. 9 November, 3 malam Abstrak dan presentasi . * Pemantauan - online dan analitik.* Keterbatasan utama platform ZABBIX.* Solusi untuk meningkatkan penyimpanan analitik.* Optimalisasi server ZABBIX.* Optimasi UI.* Pengalaman dalam mengoperasikan sistem dengan beban lebih dari 40k NVPS.* Kesimpulan singkat.Mikhail Makurov (selanjutnya - MM): - Halo semuanya!Maxim Chernetsov (selanjutnya - MCH): - Selamat siang!MM: - Izinkan saya memperkenalkan Maxim. Max adalah insinyur yang berbakat, networker terbaik yang saya tahu. Maxim berurusan dengan jaringan dan layanan, pengembangan dan pengoperasian mereka.
* Pemantauan - online dan analitik.* Keterbatasan utama platform ZABBIX.* Solusi untuk meningkatkan penyimpanan analitik.* Optimalisasi server ZABBIX.* Optimasi UI.* Pengalaman dalam mengoperasikan sistem dengan beban lebih dari 40k NVPS.* Kesimpulan singkat.Mikhail Makurov (selanjutnya - MM): - Halo semuanya!Maxim Chernetsov (selanjutnya - MCH): - Selamat siang!MM: - Izinkan saya memperkenalkan Maxim. Max adalah insinyur yang berbakat, networker terbaik yang saya tahu. Maxim berurusan dengan jaringan dan layanan, pengembangan dan pengoperasian mereka. KIA: - Dan saya ingin berbicara tentang Michael. Michael adalah pengembang C. Dia menulis beberapa solusi pemrosesan lalu lintas yang sangat dimuat untuk perusahaan kami. Kami tinggal dan bekerja di Ural, di kota petani Chelyabinsk yang parah, di perusahaan Intersvyaz. Perusahaan kami adalah penyedia layanan Internet dan televisi kabel untuk satu juta orang di 16 kota.MM:- Dan patut dikatakan bahwa Intersvyaz jauh lebih dari sekedar penyedia, itu adalah perusahaan IT. Sebagian besar keputusan kami dibuat oleh departemen TI kami.A: dari server yang memproses lalu lintas, ke pusat panggilan dan aplikasi seluler. Ada sekitar 80 orang di departemen TI dengan kompetensi yang sangat, sangat beragam.
KIA: - Dan saya ingin berbicara tentang Michael. Michael adalah pengembang C. Dia menulis beberapa solusi pemrosesan lalu lintas yang sangat dimuat untuk perusahaan kami. Kami tinggal dan bekerja di Ural, di kota petani Chelyabinsk yang parah, di perusahaan Intersvyaz. Perusahaan kami adalah penyedia layanan Internet dan televisi kabel untuk satu juta orang di 16 kota.MM:- Dan patut dikatakan bahwa Intersvyaz jauh lebih dari sekedar penyedia, itu adalah perusahaan IT. Sebagian besar keputusan kami dibuat oleh departemen TI kami.A: dari server yang memproses lalu lintas, ke pusat panggilan dan aplikasi seluler. Ada sekitar 80 orang di departemen TI dengan kompetensi yang sangat, sangat beragam.Tentang Zabbix dan arsitekturnya
MCH: - Dan sekarang saya akan mencoba untuk membuat catatan pribadi dan mengatakan dalam satu menit apa itu Zabbix (selanjutnya - "Zabbiks").Zabbix memposisikan dirinya sebagai sistem pemantauan "out of the box" di tingkat perusahaan. Ini memiliki banyak fitur penyederhanaan hidup: aturan eskalasi lanjutan, API untuk integrasi, pengelompokan, dan deteksi otomatis host dan metrik. Di Zabbix ada yang disebut alat penskalaan - proksi. Zabbix adalah sistem sumber terbuka.Secara singkat tentang arsitektur. Kita dapat mengatakan bahwa itu terdiri dari tiga komponen: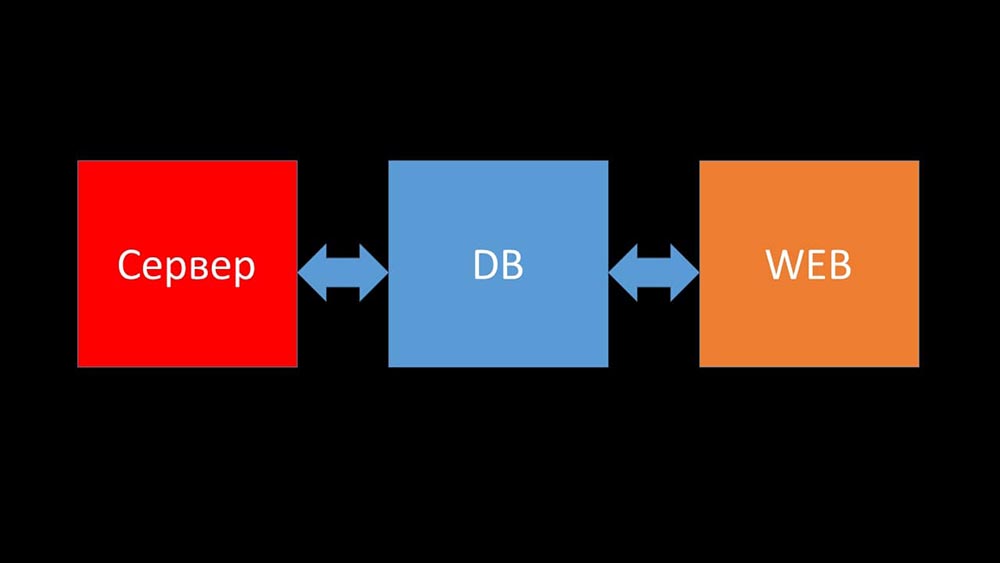
- Server. Itu ditulis dalam C. Dengan pemrosesan yang agak rumit dan pengiriman informasi antar aliran. Semua pemrosesan terjadi di dalamnya: dari menerima hingga menyimpan ke basis data.
- Semua data disimpan dalam database. Zabbix mendukung MySQL, PostreSQL, dan Oracle.
- Antarmuka web ditulis dalam PHP. Pada kebanyakan sistem, ia hadir dengan server Apache, tetapi bekerja lebih efisien dalam bundel nginx + php.
Hari ini kami ingin menceritakan dari perusahaan kami satu kisah yang berkaitan dengan Zabbix ...Kisah hidup perusahaan Intersvyaz. Apa yang kita miliki dan apa yang dibutuhkan?
 5 atau 6 bulan lalu. Sekali sepulang kerja ...KIA: - Misha, halo! Senang saya berhasil menangkap Anda - ada percakapan. Kami lagi memiliki masalah dengan pemantauan. Selama kecelakaan besar, semuanya melambat, dan tidak ada informasi tentang status jaringan. Sayangnya, ini bukan kali pertama diulang. Saya membutuhkan bantuan Anda. Mari kita buat pemantauan kita bekerja dalam keadaan apa pun!MM: - Tapi mari kita sinkronisasi dulu. Saya belum mencari di sana selama beberapa tahun. Sejauh yang saya ingat, kami menolak Nagios dan beralih ke Zabbix 8 tahun yang lalu. Dan sekarang kita tampaknya memiliki 6 server yang kuat dan sekitar selusin proksi. Apakah saya membingungkan sesuatu?KIA:- Hampir. 15 server, beberapa di antaranya adalah mesin virtual. Yang paling penting, ini tidak menyelamatkan kita pada saat kita sangat membutuhkannya. Seperti kecelakaan - server melambat dan tidak ada yang terlihat. Kami mencoba mengoptimalkan konfigurasi, tetapi ini tidak memberikan keuntungan kinerja yang optimal.MM: - Begitu. Apakah Anda melihat sesuatu, apakah Anda menggali sesuatu dari diagnosis?KIA:- Hal pertama yang harus Anda tangani hanyalah database. MySQL terus dimuat, mempertahankan metrik baru, dan ketika Zabbix mulai menghasilkan banyak acara, database masuk sendiri secara harfiah selama beberapa jam. Saya sudah memberi tahu Anda tentang mengoptimalkan konfigurasi, tetapi secara harfiah tahun ini kami memperbarui perangkat keras: ada lebih dari seratus gigabytes memori di server dan disk array pada SSD RAID-ahs - tidak ada gunanya menumbuhkannya secara linear. Apa yang kita lakukan?MM: - Begitu. Secara umum, MySQL adalah database LTP. Tampaknya, itu tidak lagi cocok untuk menyimpan arsip metrik ukuran kita. Mari kita cari tahu.KIA: - Ayo!
5 atau 6 bulan lalu. Sekali sepulang kerja ...KIA: - Misha, halo! Senang saya berhasil menangkap Anda - ada percakapan. Kami lagi memiliki masalah dengan pemantauan. Selama kecelakaan besar, semuanya melambat, dan tidak ada informasi tentang status jaringan. Sayangnya, ini bukan kali pertama diulang. Saya membutuhkan bantuan Anda. Mari kita buat pemantauan kita bekerja dalam keadaan apa pun!MM: - Tapi mari kita sinkronisasi dulu. Saya belum mencari di sana selama beberapa tahun. Sejauh yang saya ingat, kami menolak Nagios dan beralih ke Zabbix 8 tahun yang lalu. Dan sekarang kita tampaknya memiliki 6 server yang kuat dan sekitar selusin proksi. Apakah saya membingungkan sesuatu?KIA:- Hampir. 15 server, beberapa di antaranya adalah mesin virtual. Yang paling penting, ini tidak menyelamatkan kita pada saat kita sangat membutuhkannya. Seperti kecelakaan - server melambat dan tidak ada yang terlihat. Kami mencoba mengoptimalkan konfigurasi, tetapi ini tidak memberikan keuntungan kinerja yang optimal.MM: - Begitu. Apakah Anda melihat sesuatu, apakah Anda menggali sesuatu dari diagnosis?KIA:- Hal pertama yang harus Anda tangani hanyalah database. MySQL terus dimuat, mempertahankan metrik baru, dan ketika Zabbix mulai menghasilkan banyak acara, database masuk sendiri secara harfiah selama beberapa jam. Saya sudah memberi tahu Anda tentang mengoptimalkan konfigurasi, tetapi secara harfiah tahun ini kami memperbarui perangkat keras: ada lebih dari seratus gigabytes memori di server dan disk array pada SSD RAID-ahs - tidak ada gunanya menumbuhkannya secara linear. Apa yang kita lakukan?MM: - Begitu. Secara umum, MySQL adalah database LTP. Tampaknya, itu tidak lagi cocok untuk menyimpan arsip metrik ukuran kita. Mari kita cari tahu.KIA: - Ayo!Integrasi Zabbix dan Clickhouse sebagai hasil dari hackathon
Setelah beberapa waktu, kami menerima data menarik: Sebagian besar ruang dalam basis data kami ditempati oleh arsip metrik dan kurang dari 1% digunakan untuk konfigurasi, templat, dan pengaturan. Pada saat itu, selama lebih dari setahun sekarang kami telah mengoperasikan solusi Big data berdasarkan Clickhouse. Arah gerakan itu jelas bagi kami. Di Hackathon musim semi kami, ia menulis integrasi Zabbix dengan Clickhouse untuk server dan frontend. Pada saat itu, Zabbix sudah memiliki dukungan untuk ElasticSearch, dan kami memutuskan untuk membandingkannya.
Sebagian besar ruang dalam basis data kami ditempati oleh arsip metrik dan kurang dari 1% digunakan untuk konfigurasi, templat, dan pengaturan. Pada saat itu, selama lebih dari setahun sekarang kami telah mengoperasikan solusi Big data berdasarkan Clickhouse. Arah gerakan itu jelas bagi kami. Di Hackathon musim semi kami, ia menulis integrasi Zabbix dengan Clickhouse untuk server dan frontend. Pada saat itu, Zabbix sudah memiliki dukungan untuk ElasticSearch, dan kami memutuskan untuk membandingkannya.
Bandingkan Clickhouse dan Elasticsearch
MM: - Sebagai perbandingan, kami menghasilkan beban yang sama dengan yang disediakan server Zabbix dan melihat bagaimana sistem akan berperilaku. Kami menulis data dalam batch 1000 baris, menggunakan CURL. Kami sebelumnya menyarankan bahwa Clickhouse akan lebih efektif untuk memuat profil yang Zabbix lakukan. Hasilnya bahkan melebihi harapan kami: Di bawah kondisi pengujian yang sama, Clickhouse menulis data tiga kali lebih banyak. Pada saat yang sama, kedua sistem mengkonsumsi sangat efisien (sejumlah kecil sumber daya) saat membaca data. Tetapi "Elastix" membutuhkan sejumlah besar prosesor saat merekam:Secara total, Clickhouse secara signifikan melebihi Elastix dalam konsumsi dan kecepatan prosesor. Pada saat yang sama, karena kompresi data, "Clickhouse" menggunakan 11 kali lebih sedikit pada hard disk dan melakukan sekitar 30 kali lebih sedikit operasi disk:
Di bawah kondisi pengujian yang sama, Clickhouse menulis data tiga kali lebih banyak. Pada saat yang sama, kedua sistem mengkonsumsi sangat efisien (sejumlah kecil sumber daya) saat membaca data. Tetapi "Elastix" membutuhkan sejumlah besar prosesor saat merekam:Secara total, Clickhouse secara signifikan melebihi Elastix dalam konsumsi dan kecepatan prosesor. Pada saat yang sama, karena kompresi data, "Clickhouse" menggunakan 11 kali lebih sedikit pada hard disk dan melakukan sekitar 30 kali lebih sedikit operasi disk: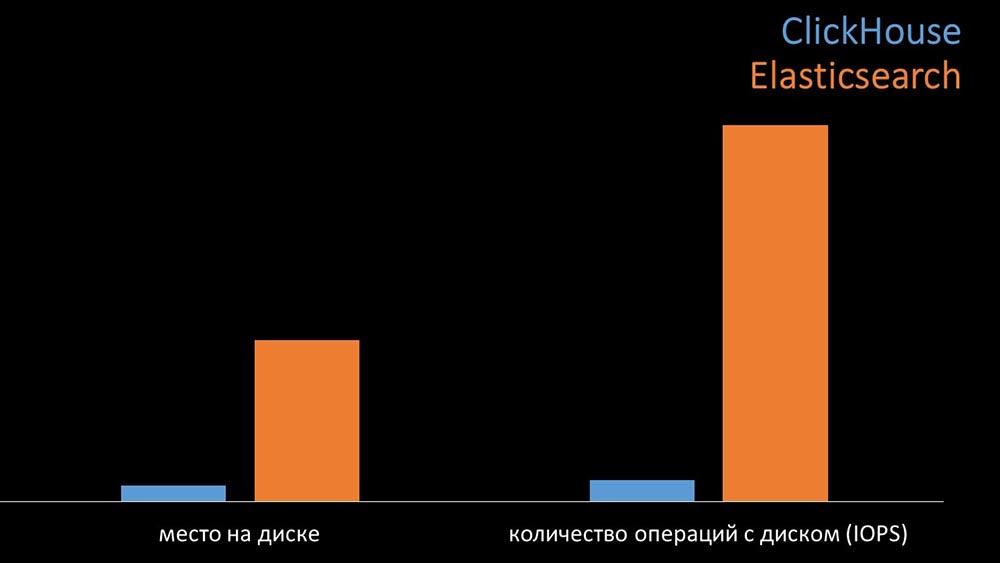 MCH: - Ya, bekerja dengan subsistem disk di "Clickhouse" sangat efektif. Di bawah basis, Anda dapat menggunakan disk SATA besar dan mendapatkan kecepatan tulis ratusan ribu baris per detik. Sistem "out of the box" mendukung sharding, replikasi, sangat mudah dikonfigurasi. Kami sangat senang dengan operasinya selama setahun.Untuk mengoptimalkan sumber daya, Anda dapat menginstal "Clickhouse" di sebelah basis utama yang ada dan dengan demikian menghemat banyak waktu prosesor dan operasi disk. Kami mengeluarkan arsip metrik ke kluster "Clickhouse" yang ada:
MCH: - Ya, bekerja dengan subsistem disk di "Clickhouse" sangat efektif. Di bawah basis, Anda dapat menggunakan disk SATA besar dan mendapatkan kecepatan tulis ratusan ribu baris per detik. Sistem "out of the box" mendukung sharding, replikasi, sangat mudah dikonfigurasi. Kami sangat senang dengan operasinya selama setahun.Untuk mengoptimalkan sumber daya, Anda dapat menginstal "Clickhouse" di sebelah basis utama yang ada dan dengan demikian menghemat banyak waktu prosesor dan operasi disk. Kami mengeluarkan arsip metrik ke kluster "Clickhouse" yang ada: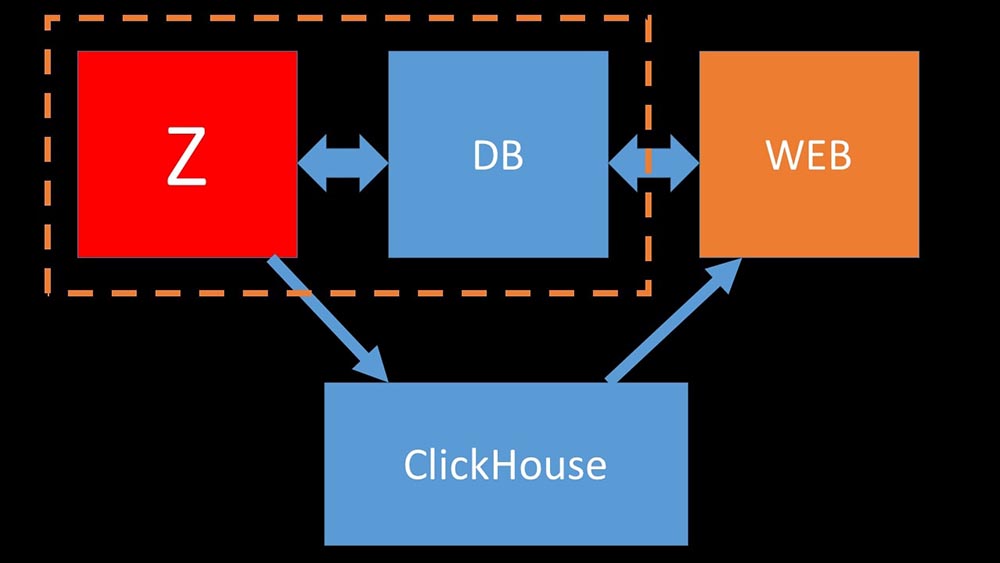 Kami membongkar basis data MySQL utama sehingga kami dapat menggabungkannya di mesin yang sama dengan server Zabbix dan meninggalkan server khusus untuk MySQL.
Kami membongkar basis data MySQL utama sehingga kami dapat menggabungkannya di mesin yang sama dengan server Zabbix dan meninggalkan server khusus untuk MySQL.Bagaimana cara kerja polling di Zabbix?
4 bulan laluMM: - Nah, Anda bisa melupakan masalah dengan pangkalan?KIA: - Pasti! Masalah lain yang perlu kita selesaikan adalah pengumpulan data yang lambat. Sekarang semua dari 15 proxy kami kelebihan beban dengan SNMP dan proses pemungutan suara. Dan tidak ada yang lain selain menyiapkan server baru dan baru.MM: - Hebat. Tapi pertama-tama katakan padaku bagaimana polling bekerja di Zabbix.MCH: - Singkatnya, ada 20 jenis metrik dan selusin cara untuk mendapatkannya. Zabbix dapat mengumpulkan data baik dalam mode "permintaan-respons", atau mengharapkan data baru melalui "Trapper Interface". Perlu dicatat bahwa dalam Zabbix asli metode ini (Trapper) adalah yang tercepat.Ada proksi untuk penyeimbangan beban:
Perlu dicatat bahwa dalam Zabbix asli metode ini (Trapper) adalah yang tercepat.Ada proksi untuk penyeimbangan beban: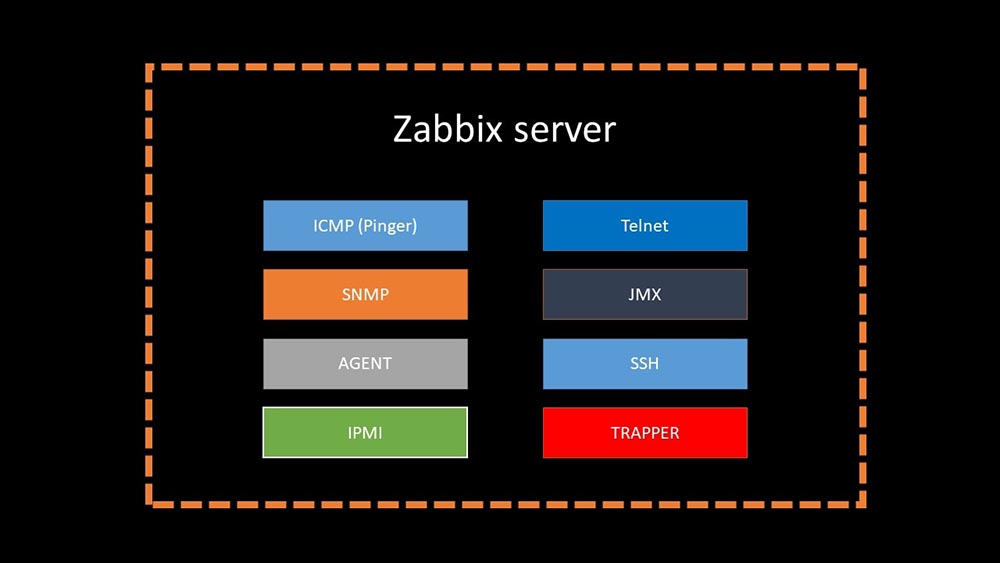 Proxy dapat melakukan fungsi pengumpulan yang sama dengan server Zabbix, menerima tugas darinya dan mengirim metrik yang dikumpulkan melalui antarmuka Trapper. Ini adalah metode penyeimbangan beban yang direkomendasikan secara resmi. Juga, proksi berguna untuk memantau infrastruktur jarak jauh yang bekerja melalui NAT atau saluran lambat:
Proxy dapat melakukan fungsi pengumpulan yang sama dengan server Zabbix, menerima tugas darinya dan mengirim metrik yang dikumpulkan melalui antarmuka Trapper. Ini adalah metode penyeimbangan beban yang direkomendasikan secara resmi. Juga, proksi berguna untuk memantau infrastruktur jarak jauh yang bekerja melalui NAT atau saluran lambat: MM: - Semuanya jelas dengan arsitekturnya. Kita harus melihat sumbernya ...Beberapa hari kemudian
MM: - Semuanya jelas dengan arsitekturnya. Kita harus melihat sumbernya ...Beberapa hari kemudianKisah tentang bagaimana nmap fping menang
MM: - Sepertinya saya menggali sesuatu.KIA: - Katakan padaku!MM: - Saya menemukan bahwa selama pemeriksaan ketersediaan, Zabbix melakukan pemeriksaan hingga 128 host sekaligus. Saya mencoba meningkatkan angka ini menjadi 500 dan menghapus interval antar paket dalam ping (ping) mereka - ini meningkatkan kinerja dengan faktor dua. Tapi saya ingin jumlah besar.KIA: - Dalam praktik saya, kadang-kadang saya harus memeriksa ketersediaan ribuan host, dan saya belum melihat sesuatu yang lebih cepat daripada nmap. Saya yakin ini adalah cara tercepat. Ayo kita coba! Anda perlu meningkatkan jumlah host secara signifikan dalam satu iterasi.MM: - Periksa lebih dari lima ratus? 600?KIA: - Setidaknya beberapa ribu.MM:- Baik. Hal terpenting yang ingin saya katakan: Saya menemukan bahwa sebagian besar pemungutan suara di Zabbix dilakukan secara serempak. Kita harus mengulanginya secara tidak sinkron. Kemudian, kami dapat secara dramatis meningkatkan jumlah metrik yang dikumpulkan oleh para pemberi suara, terutama jika kami menambah jumlah metrik dalam satu iterasi.KIA: - Hebat! Dan kapan?MM: - Seperti biasa, kemarin.KIA: - Kami membandingkan kedua versi fping dan nmap: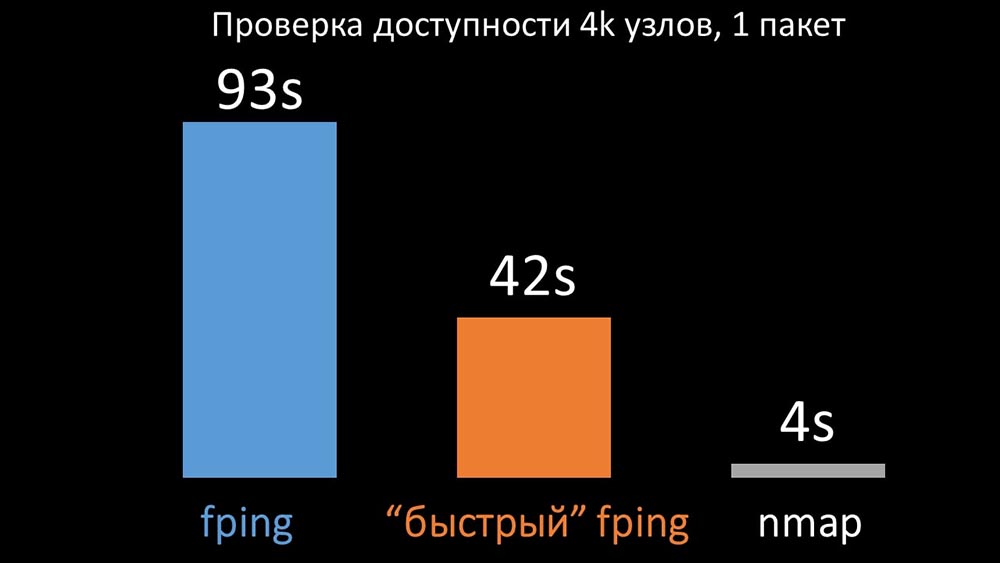 Pada sejumlah besar host, nmap diharapkan hingga lima kali lebih efisien. Karena nmap hanya memeriksa fakta ketersediaan dan waktu respons, kami mentransfer perhitungan kehilangan ke pemicu dan secara signifikan mengurangi interval pemeriksaan ketersediaan. Kami menemukan jumlah host yang optimal untuk nmap di wilayah 4 ribu per iterasi. Nmap memungkinkan kami mengurangi biaya CPU untuk pemeriksaan ketersediaan tiga kali dan mengurangi interval dari 120 detik menjadi 10.
Pada sejumlah besar host, nmap diharapkan hingga lima kali lebih efisien. Karena nmap hanya memeriksa fakta ketersediaan dan waktu respons, kami mentransfer perhitungan kehilangan ke pemicu dan secara signifikan mengurangi interval pemeriksaan ketersediaan. Kami menemukan jumlah host yang optimal untuk nmap di wilayah 4 ribu per iterasi. Nmap memungkinkan kami mengurangi biaya CPU untuk pemeriksaan ketersediaan tiga kali dan mengurangi interval dari 120 detik menjadi 10.Optimalisasi polling
MM: - Lalu kami masuk untuk pollers. Kami terutama tertarik pada penghapusan SNMP dan agen. Di Zabbix, pemungutan suara dilakukan secara serempak dan langkah-langkah khusus diambil untuk meningkatkan efisiensi sistem. Dalam mode sinkron, ketidaktersediaan host menyebabkan degradasi polling yang signifikan. Ada seluruh sistem negara, ada proses khusus - yang disebut tidak dapat dijangkau-pollers yang hanya bekerja dengan host yang tidak dapat diakses: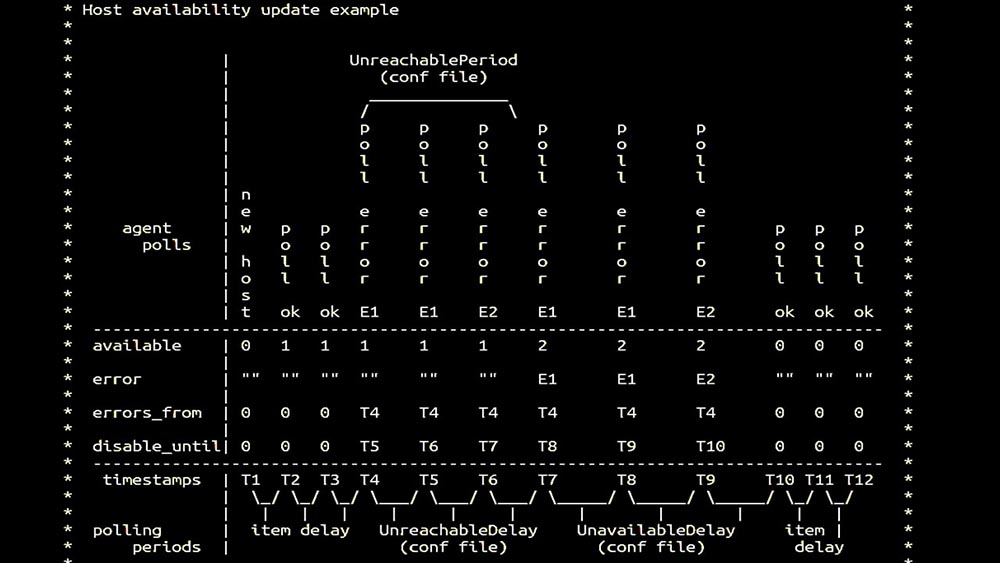 Ini adalah komentar yang menunjukkan matriks negara, semua kompleksitas sistem transisi yang diperlukan agar sistem tetap efektif. Selain itu, jajak pendapat sinkron itu sendiri agak lambat:
Ini adalah komentar yang menunjukkan matriks negara, semua kompleksitas sistem transisi yang diperlukan agar sistem tetap efektif. Selain itu, jajak pendapat sinkron itu sendiri agak lambat: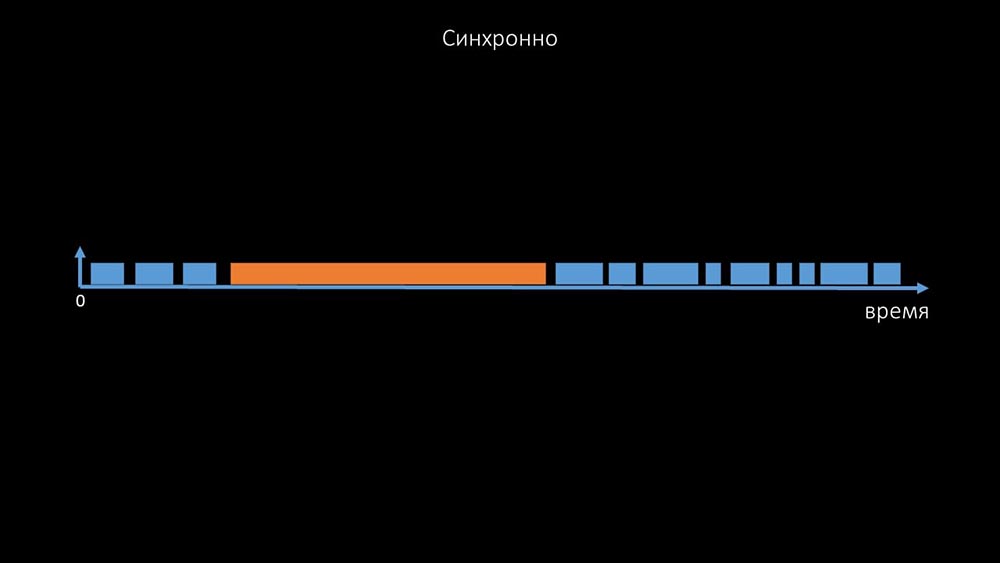 Itulah sebabnya ribuan utas poller pada selusin proxy tidak dapat mengumpulkan jumlah data yang diperlukan untuk kami. Implementasi asinkron memecahkan tidak hanya masalah dengan jumlah utas, tetapi juga secara signifikan menyederhanakan sistem keadaan host yang tidak dapat diakses, karena untuk setiap nomor yang diperiksa dalam satu iterasi polling, waktu tunggu maksimum adalah 1 timeout: Selain
Itulah sebabnya ribuan utas poller pada selusin proxy tidak dapat mengumpulkan jumlah data yang diperlukan untuk kami. Implementasi asinkron memecahkan tidak hanya masalah dengan jumlah utas, tetapi juga secara signifikan menyederhanakan sistem keadaan host yang tidak dapat diakses, karena untuk setiap nomor yang diperiksa dalam satu iterasi polling, waktu tunggu maksimum adalah 1 timeout: Selain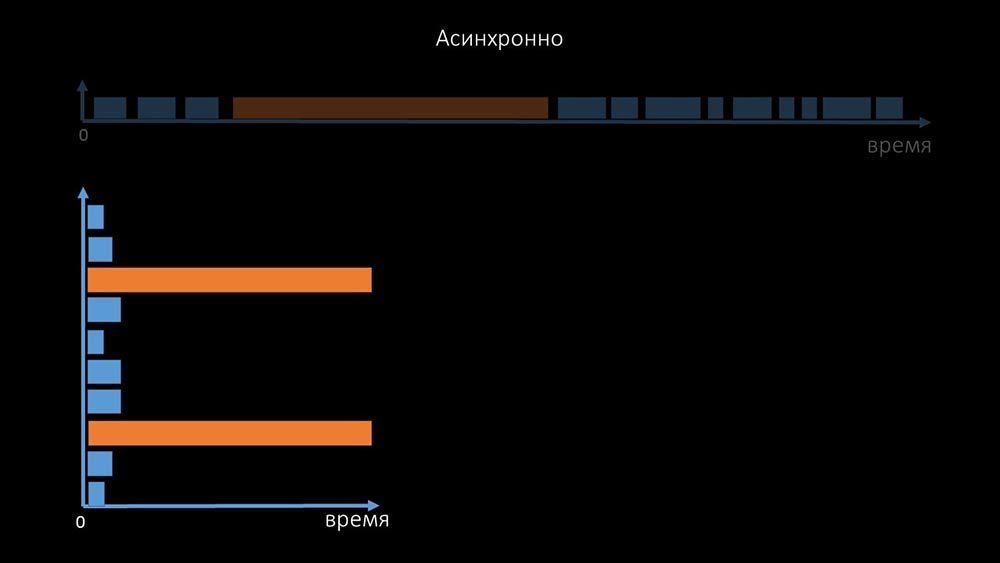 itu, kami memodifikasi dan meningkatkan sistem polling untuk SNMP- pertanyaan. Faktanya adalah bahwa sebagian besar tidak dapat menanggapi beberapa permintaan SNMP secara bersamaan. Oleh karena itu, kami membuat mode hibrid ketika polling SNMP dari host yang sama melakukan secara asinkron:
itu, kami memodifikasi dan meningkatkan sistem polling untuk SNMP- pertanyaan. Faktanya adalah bahwa sebagian besar tidak dapat menanggapi beberapa permintaan SNMP secara bersamaan. Oleh karena itu, kami membuat mode hibrid ketika polling SNMP dari host yang sama melakukan secara asinkron: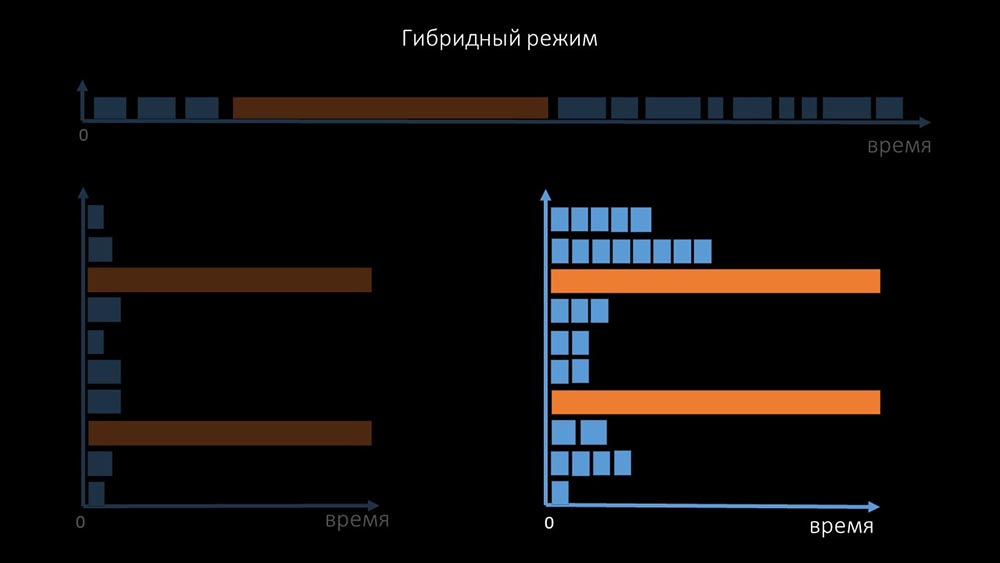 Ini dilakukan untuk seluruh bundel host. Mode ini pada akhirnya tidak lebih lambat dari sepenuhnya asinkron, karena polling satu setengah ratus nilai SNMP masih jauh lebih cepat dari 1 timeout.Eksperimen kami menunjukkan bahwa jumlah permintaan optimal dalam satu iterasi adalah sekitar 8 ribu dengan pemungutan suara SNMP. Secara total, transisi ke mode asinkron memungkinkan untuk mempercepat kinerja pemungutan suara sebanyak 200 kali, beberapa ratus kali.MCH: - Optimalisasi polling yang diperoleh menunjukkan bahwa kami tidak hanya dapat menghilangkan semua proxy, tetapi juga mengurangi interval untuk banyak pemeriksaan, dan proxy tidak akan diperlukan sebagai cara untuk berbagi beban.Sekitar tiga bulan lalu
Ini dilakukan untuk seluruh bundel host. Mode ini pada akhirnya tidak lebih lambat dari sepenuhnya asinkron, karena polling satu setengah ratus nilai SNMP masih jauh lebih cepat dari 1 timeout.Eksperimen kami menunjukkan bahwa jumlah permintaan optimal dalam satu iterasi adalah sekitar 8 ribu dengan pemungutan suara SNMP. Secara total, transisi ke mode asinkron memungkinkan untuk mempercepat kinerja pemungutan suara sebanyak 200 kali, beberapa ratus kali.MCH: - Optimalisasi polling yang diperoleh menunjukkan bahwa kami tidak hanya dapat menghilangkan semua proxy, tetapi juga mengurangi interval untuk banyak pemeriksaan, dan proxy tidak akan diperlukan sebagai cara untuk berbagi beban.Sekitar tiga bulan laluUbah arsitektur - tambah beban!
MM: - Baik, Max, sudah saatnya menjadi produktif? Saya membutuhkan server yang kuat dan insinyur yang baik.MCH: - Ya, kami berencana. Sudah waktunya untuk turun pada 5.000 metrik per detik.Pagi setelah peningkatanKIA: - Misha, kami memperbarui, tetapi memutar kembali di pagi hari ... Tebak kecepatan apa yang Anda raih?MM: - Ribuan 20 maksimum.KIA: - Ya, 25! Sayangnya, kita berada di tempat kita mulai.MM: - Jadi? Apakah Anda mendapatkan diagnostik?KIA: - Ya tentu saja! Di sini, misalnya, atasan yang menarik: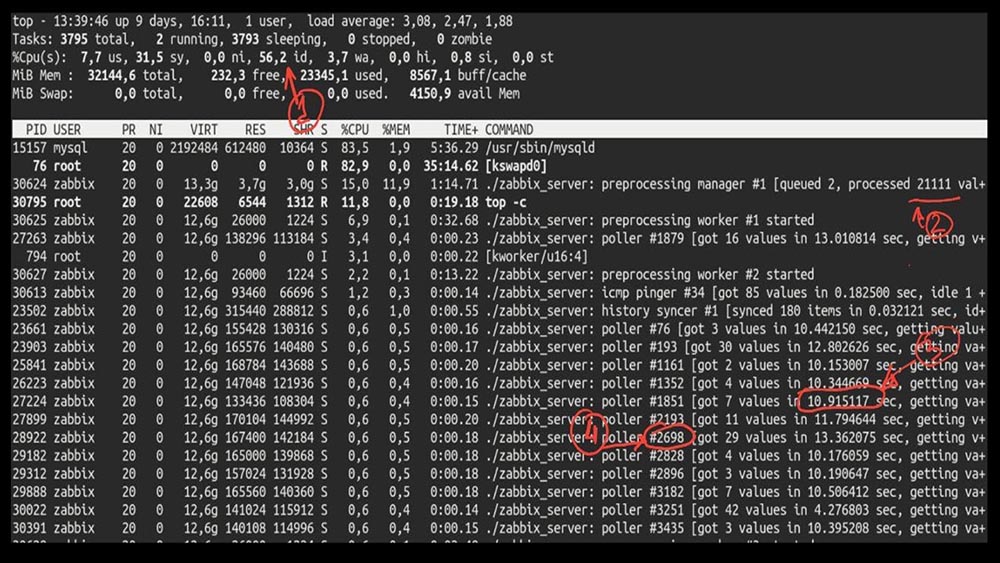 MM: - Mari kita lihat. Saya melihat bahwa kami mencoba sejumlah besar jajak pendapat:
MM: - Mari kita lihat. Saya melihat bahwa kami mencoba sejumlah besar jajak pendapat: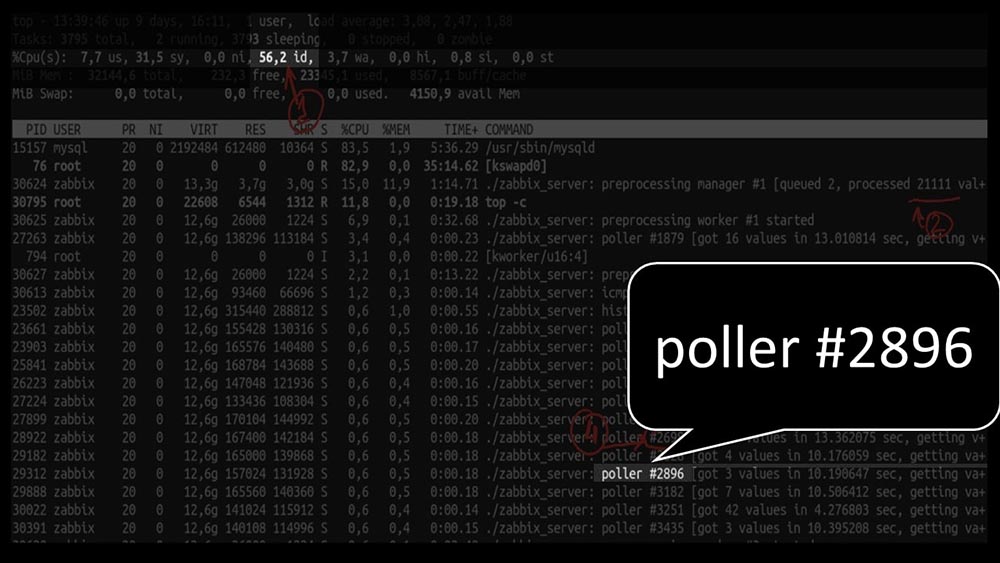 Tetapi pada saat yang sama kami tidak dapat memanfaatkan sistem bahkan di tengah jalan:
Tetapi pada saat yang sama kami tidak dapat memanfaatkan sistem bahkan di tengah jalan: Dan kinerja keseluruhan cukup kecil, sekitar 4 ribu metrik per detik:
Dan kinerja keseluruhan cukup kecil, sekitar 4 ribu metrik per detik: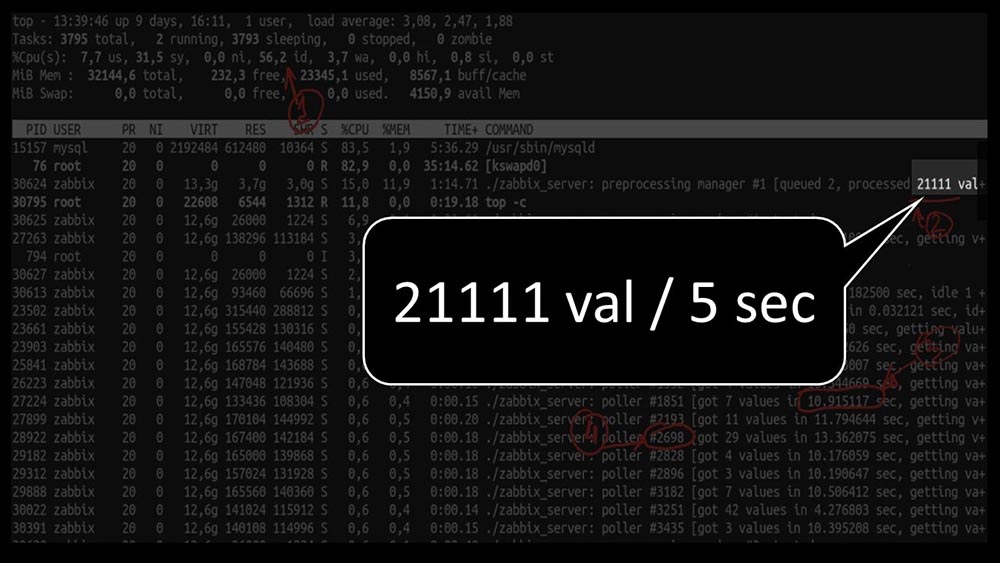 Apakah ada hal lain?MCH: - Ya, salah satu dari polling:
Apakah ada hal lain?MCH: - Ya, salah satu dari polling: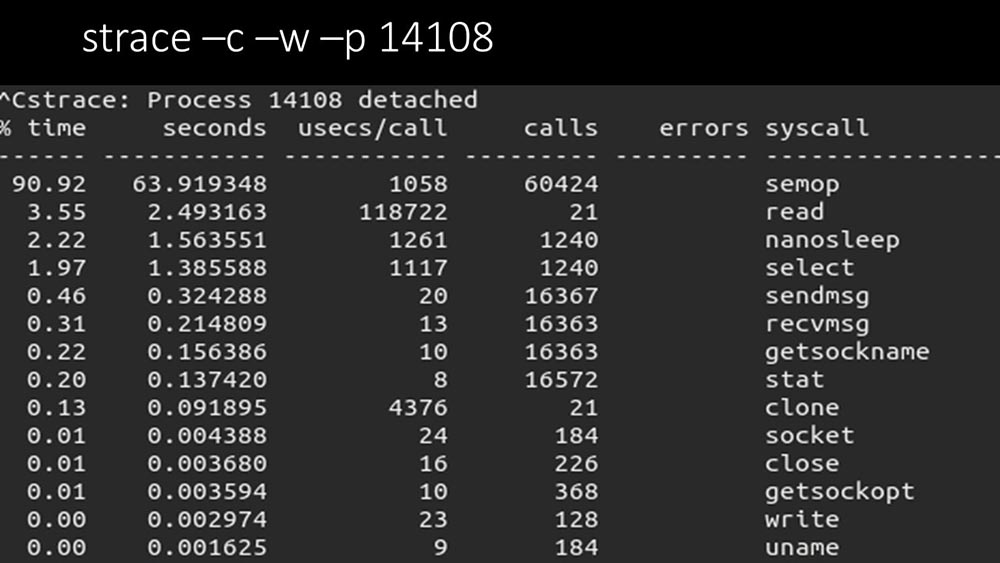 MM: - Jelas terlihat di sini bahwa proses pemungutan suara sedang menunggu "semaphore". Ini adalah kunci:
MM: - Jelas terlihat di sini bahwa proses pemungutan suara sedang menunggu "semaphore". Ini adalah kunci: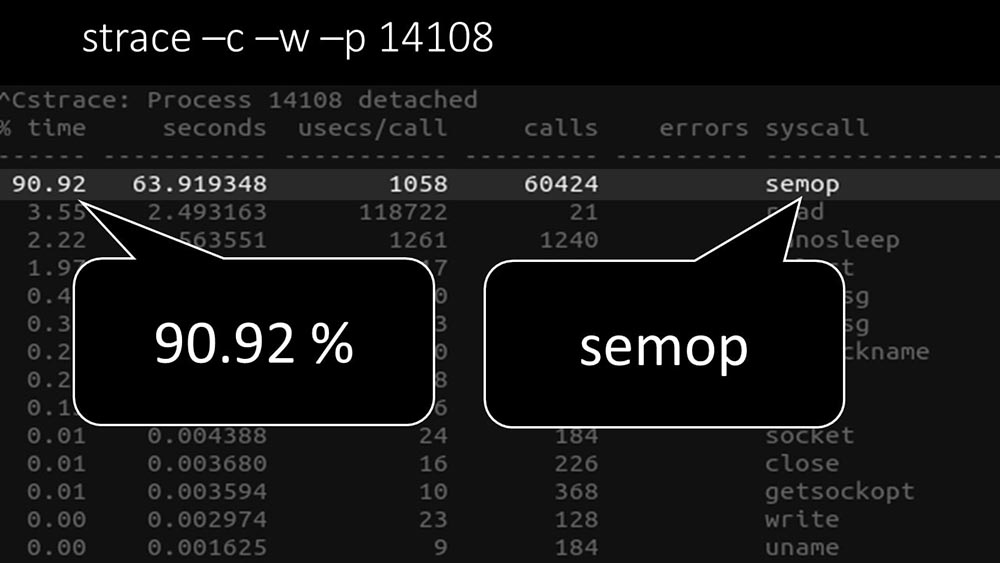 KIA: - Tidak jelas.MM: - Lihat, ini seperti situasi di mana sekelompok utas berusaha untuk bekerja dengan sumber daya yang hanya dapat bekerja satu per satu. Maka yang bisa mereka lakukan adalah membagikan sumber ini berdasarkan waktu:
KIA: - Tidak jelas.MM: - Lihat, ini seperti situasi di mana sekelompok utas berusaha untuk bekerja dengan sumber daya yang hanya dapat bekerja satu per satu. Maka yang bisa mereka lakukan adalah membagikan sumber ini berdasarkan waktu: Dan total produktivitas bekerja dengan sumber daya semacam itu dibatasi oleh kecepatan satu inti: Ada
Dan total produktivitas bekerja dengan sumber daya semacam itu dibatasi oleh kecepatan satu inti: Ada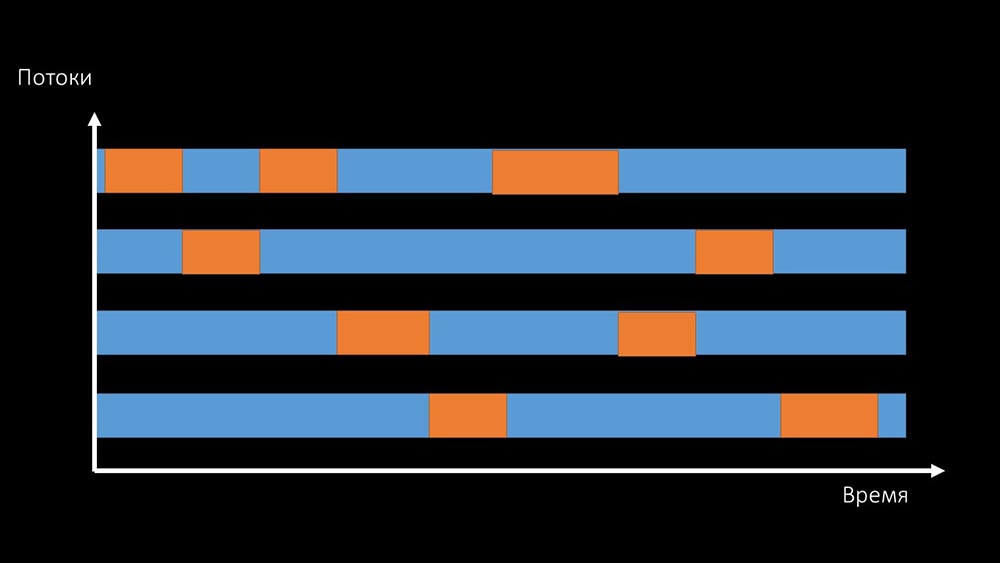 dua cara untuk menyelesaikan masalah ini.Mutakhirkan setrika mesin, alihkan ke kernel yang lebih cepat:
dua cara untuk menyelesaikan masalah ini.Mutakhirkan setrika mesin, alihkan ke kernel yang lebih cepat: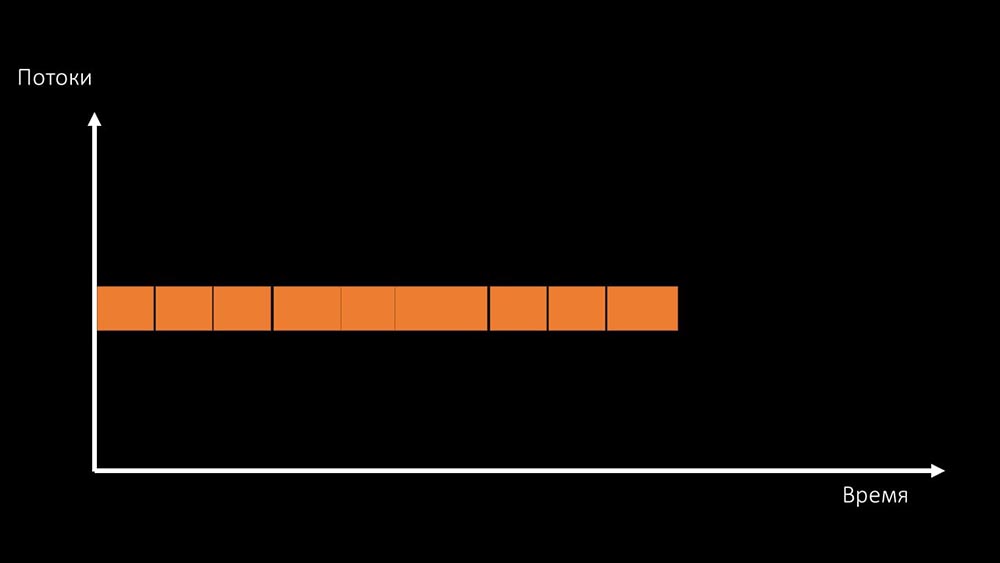 Atau ubah arsitektur dan , pada saat yang sama , beban:
Atau ubah arsitektur dan , pada saat yang sama , beban: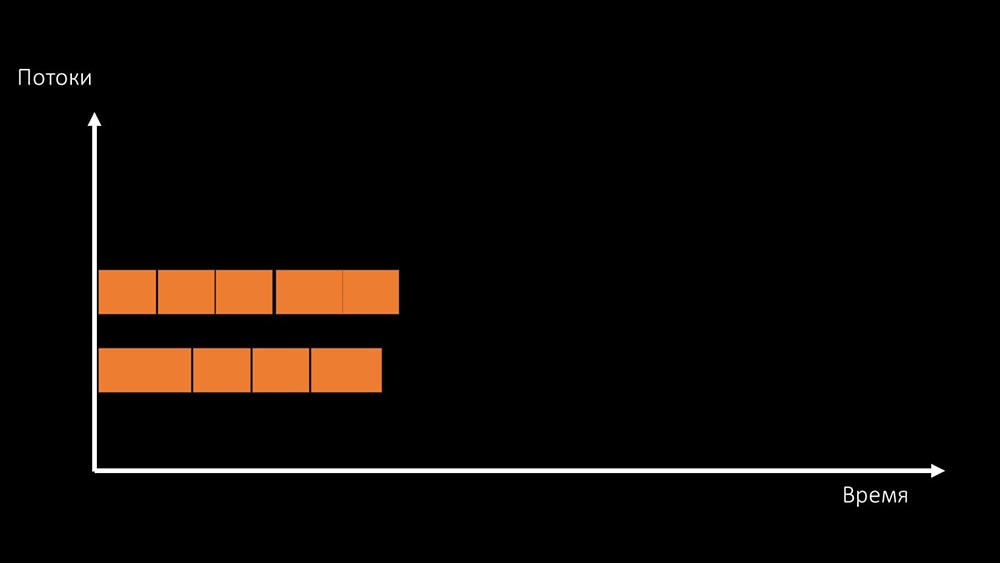 MCH: - Ngomong-ngomong, kami akan menggunakan lebih sedikit core pada mesin uji daripada pada mesin pertarungan, tetapi mereka akan 1,5 kali lebih cepat dalam frekuensi per core!MM: - Apakah itu jelas? Perlu untuk melihat kode server.
MCH: - Ngomong-ngomong, kami akan menggunakan lebih sedikit core pada mesin uji daripada pada mesin pertarungan, tetapi mereka akan 1,5 kali lebih cepat dalam frekuensi per core!MM: - Apakah itu jelas? Perlu untuk melihat kode server.Jalur Data di Zabbix Server
KIA: - Untuk memahami, kami mulai menganalisis bagaimana data dikirimkan di dalam server Zabbix: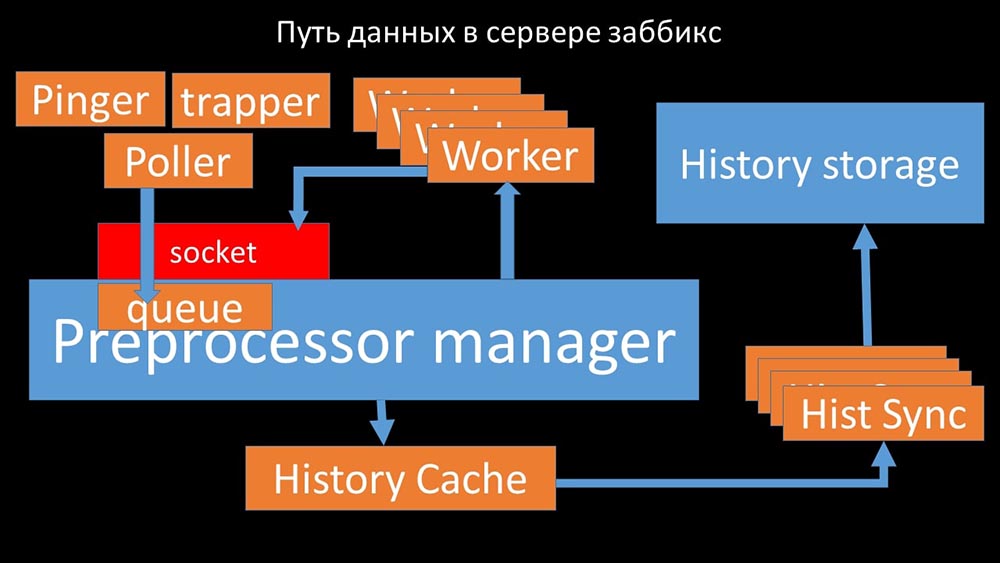 Gambar keren, bukan? Mari kita lalui langkah demi langkah untuk sedikit banyak memperjelas. Ada aliran dan layanan yang bertanggung jawab untuk mengumpulkan data:
Gambar keren, bukan? Mari kita lalui langkah demi langkah untuk sedikit banyak memperjelas. Ada aliran dan layanan yang bertanggung jawab untuk mengumpulkan data: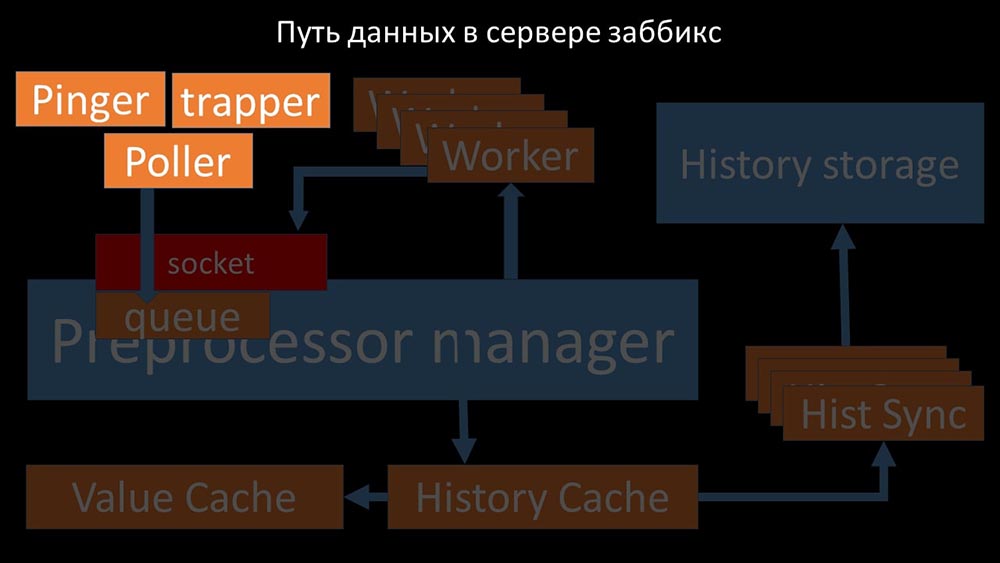 Mereka mentransfer metrik yang dikumpulkan melalui soket ke manajer Preprocessor, di mana mereka di-antri:
Mereka mentransfer metrik yang dikumpulkan melalui soket ke manajer Preprocessor, di mana mereka di-antri: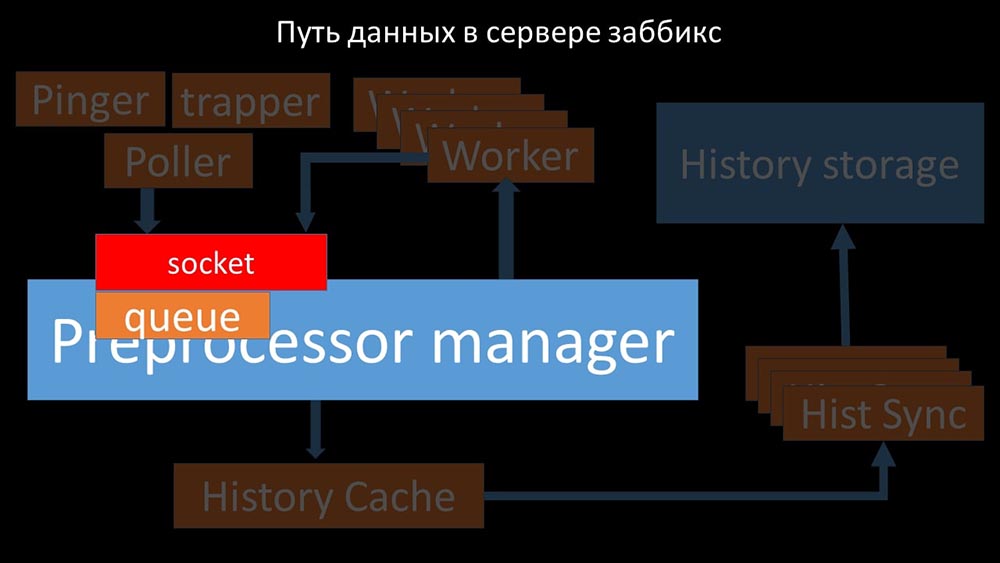 Preprocessor-manager ”mentransfer data ke pekerjanya yang menjalankan instruksi preprocessing dan mengembalikannya melalui soket yang sama:
Preprocessor-manager ”mentransfer data ke pekerjanya yang menjalankan instruksi preprocessing dan mengembalikannya melalui soket yang sama: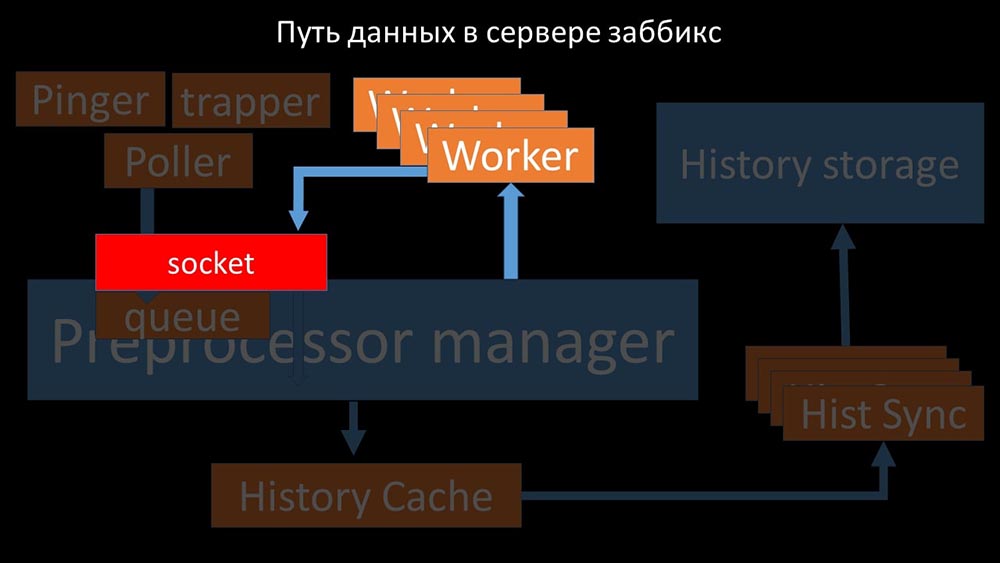 Setelah itu, preprocessor -Manager menyimpannya dalam cache riwayat:
Setelah itu, preprocessor -Manager menyimpannya dalam cache riwayat: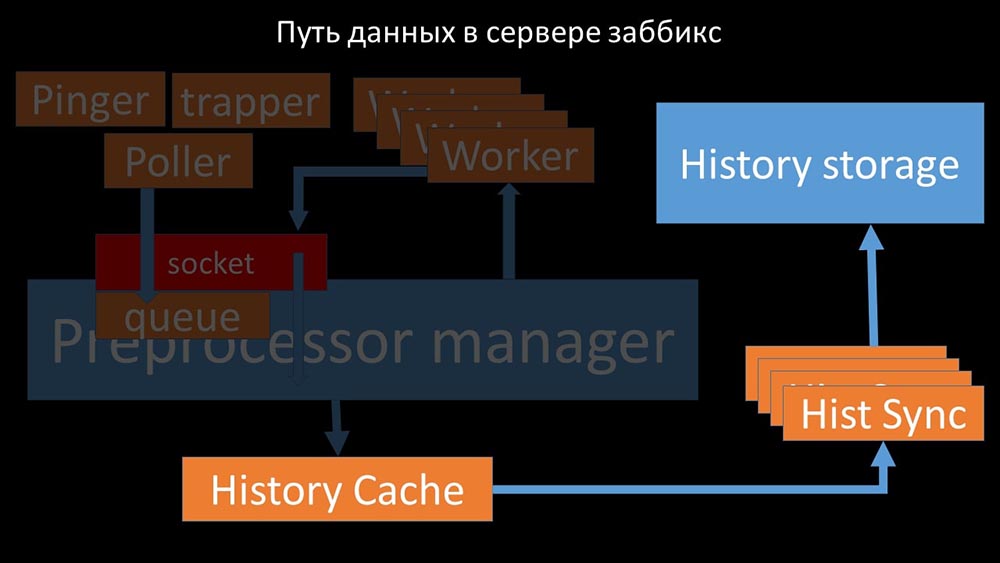 Dari sana, mereka diambil oleh sinkron riwayat yang menjalankan cukup banyak fungsi: misalnya, menghitung pemicu, mengisi cache nilai dan, yang paling penting, menyimpan metrik di toko riwayat. Secara umum, prosesnya rumit dan sangat membingungkan.
Dari sana, mereka diambil oleh sinkron riwayat yang menjalankan cukup banyak fungsi: misalnya, menghitung pemicu, mengisi cache nilai dan, yang paling penting, menyimpan metrik di toko riwayat. Secara umum, prosesnya rumit dan sangat membingungkan. MM: - Hal pertama yang kami lihat adalah sebagian besar utas bersaing untuk apa yang disebut "cache konfigurasi" (area memori tempat semua konfigurasi server disimpan). Terutama banyak kunci dibuat oleh aliran yang bertanggung jawab untuk pengumpulan data:
MM: - Hal pertama yang kami lihat adalah sebagian besar utas bersaing untuk apa yang disebut "cache konfigurasi" (area memori tempat semua konfigurasi server disimpan). Terutama banyak kunci dibuat oleh aliran yang bertanggung jawab untuk pengumpulan data: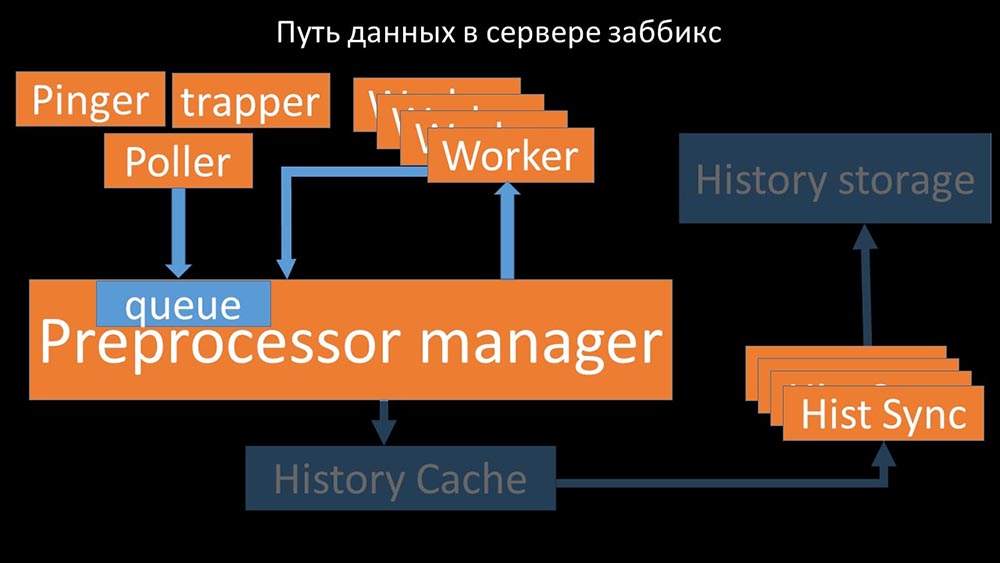 ... karena konfigurasi menyimpan tidak hanya metrik dengan parameternya, tetapi juga antrian, dari mana para pemberi informasi mengambil informasi tentang apa yang harus dilakukan selanjutnya. Ketika ada banyak poller, dan satu blok konfigurasi, sisanya menunggu permintaan:
... karena konfigurasi menyimpan tidak hanya metrik dengan parameternya, tetapi juga antrian, dari mana para pemberi informasi mengambil informasi tentang apa yang harus dilakukan selanjutnya. Ketika ada banyak poller, dan satu blok konfigurasi, sisanya menunggu permintaan:
Poller tidak boleh konflik
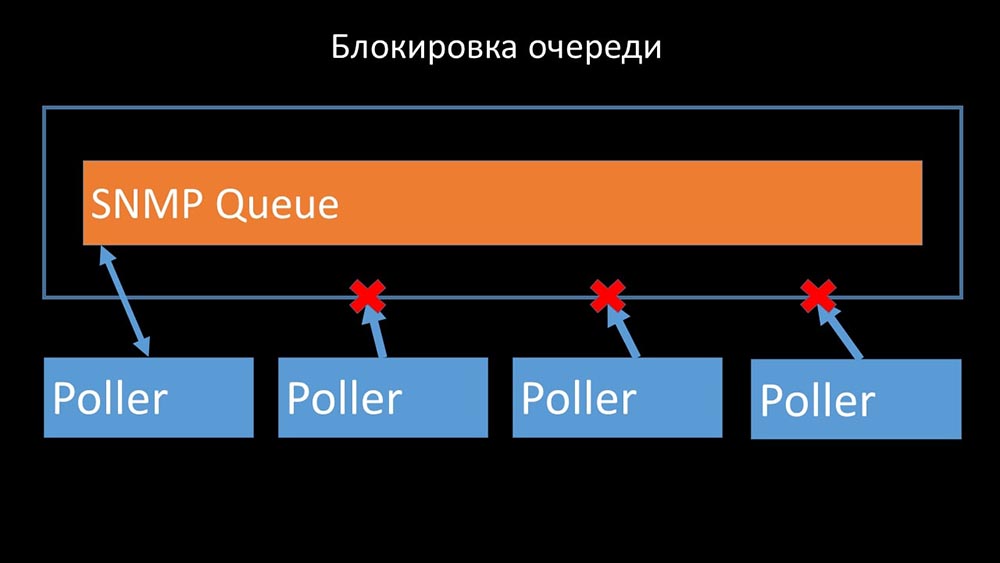 Oleh karena itu, hal pertama yang kami lakukan adalah membagi antrian menjadi 4 bagian dan memungkinkan para pemungut suara untuk memblokir antrian ini dengan aman, bagian-bagian ini pada saat yang sama:
Oleh karena itu, hal pertama yang kami lakukan adalah membagi antrian menjadi 4 bagian dan memungkinkan para pemungut suara untuk memblokir antrian ini dengan aman, bagian-bagian ini pada saat yang sama: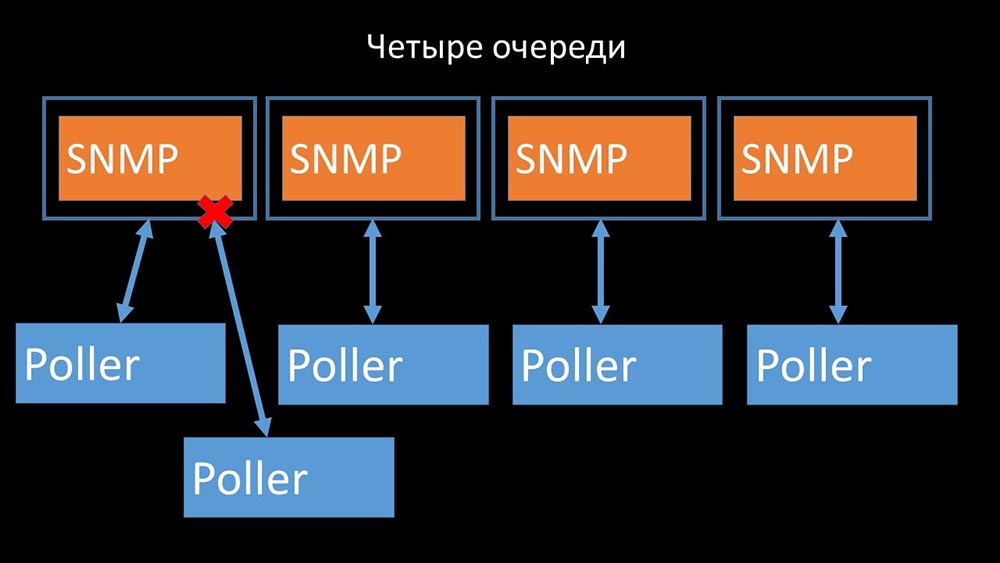 Ini menghapus kompetisi untuk cache konfigurasi, dan kecepatan pollers meningkat secara signifikan. Tapi kemudian kami dihadapkan dengan fakta bahwa manajer preprocessor mulai mengumpulkan antrian pekerjaan:
Ini menghapus kompetisi untuk cache konfigurasi, dan kecepatan pollers meningkat secara signifikan. Tapi kemudian kami dihadapkan dengan fakta bahwa manajer preprocessor mulai mengumpulkan antrian pekerjaan:
Manajer preprosesor harus dapat memprioritaskan
Ini terjadi ketika dia kurang produktivitas. Kemudian yang bisa dia lakukan adalah mengumpulkan permintaan dari proses pengumpulan data dan menambahkan buffer mereka sampai dia memakan semua memori dan crash: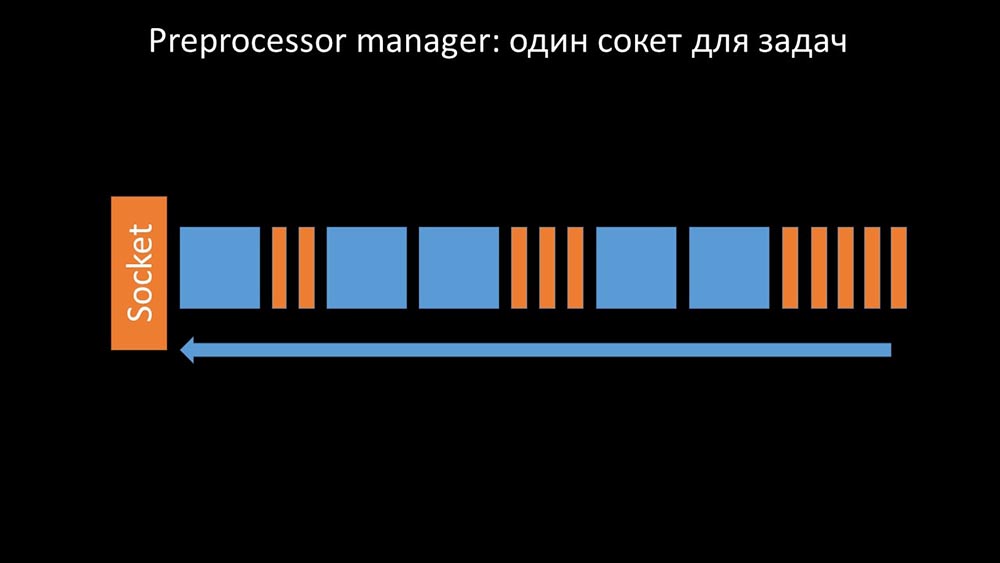 Untuk mengatasi masalah ini, kami menambahkan soket kedua, yang dialokasikan khusus untuk pekerja:
Untuk mengatasi masalah ini, kami menambahkan soket kedua, yang dialokasikan khusus untuk pekerja: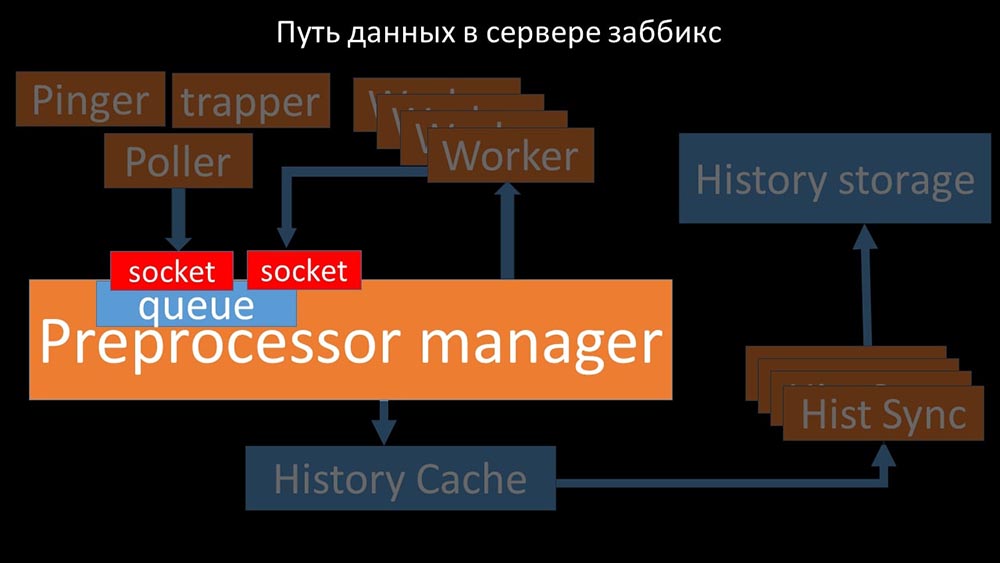 Dengan demikian , preprocessor-manager mendapat kesempatan untuk memprioritaskan pekerjaannya dan jika buffer bertambah, tugasnya adalah memperlambat makan, memberi pekerja kesempatan untuk mengambil buffer ini:
Dengan demikian , preprocessor-manager mendapat kesempatan untuk memprioritaskan pekerjaannya dan jika buffer bertambah, tugasnya adalah memperlambat makan, memberi pekerja kesempatan untuk mengambil buffer ini: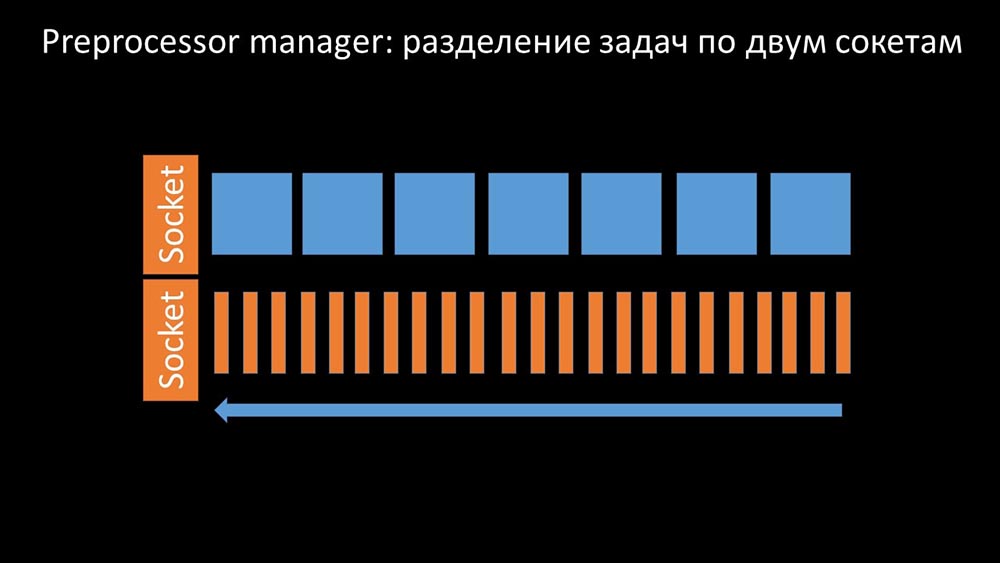 Kemudian kami menemukan bahwa salah satu alasan perlambatan adalah karena para pekerja sendiri bersaing untuk sumber daya vital untuk pekerjaan mereka. Kami mendaftarkan masalah ini dengan perbaikan bug, dan dalam versi baru Zabbix, masalah tersebut telah terpecahkan:
Kemudian kami menemukan bahwa salah satu alasan perlambatan adalah karena para pekerja sendiri bersaing untuk sumber daya vital untuk pekerjaan mereka. Kami mendaftarkan masalah ini dengan perbaikan bug, dan dalam versi baru Zabbix, masalah tersebut telah terpecahkan: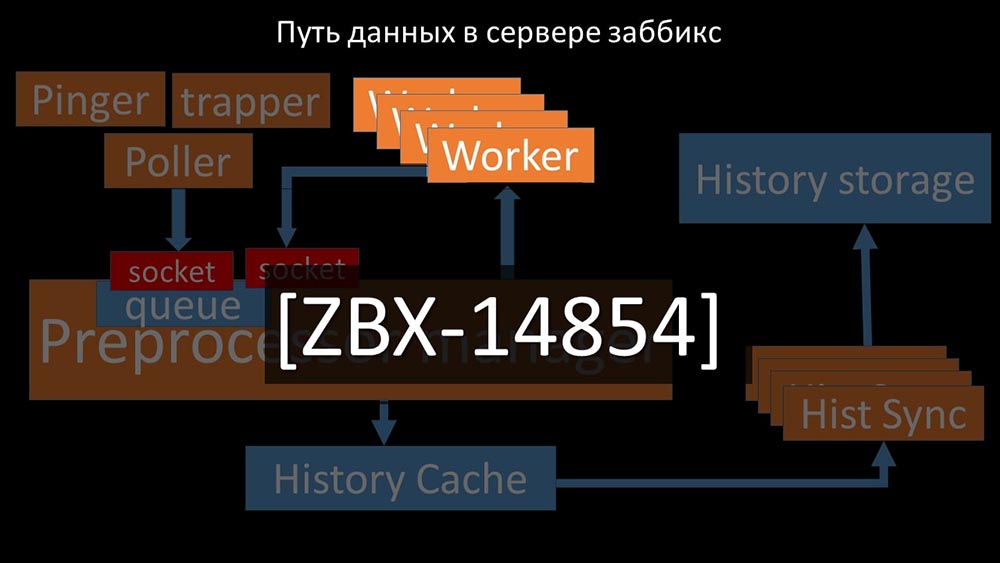
Kami menambah jumlah soket - kami mendapatkan hasilnya
Lebih lanjut, manajer preprocessor sendiri menjadi tautan sempit, karena merupakan utas tunggal. Itu bertumpu pada kecepatan inti, memberikan kecepatan maksimum sekitar 70 ribu metrik per detik: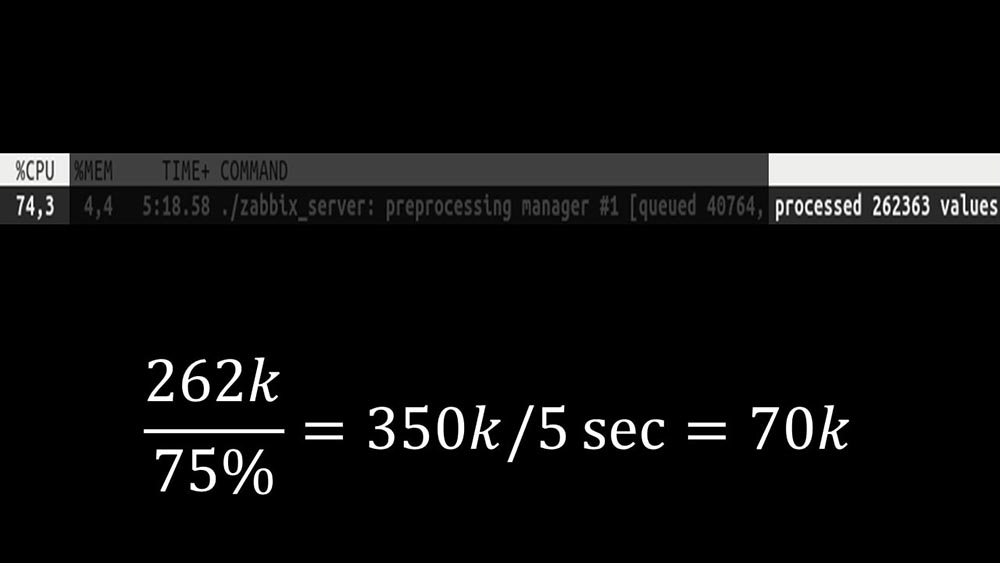 Oleh karena itu, kami membuat empat, dengan empat set soket, pekerja:
Oleh karena itu, kami membuat empat, dengan empat set soket, pekerja: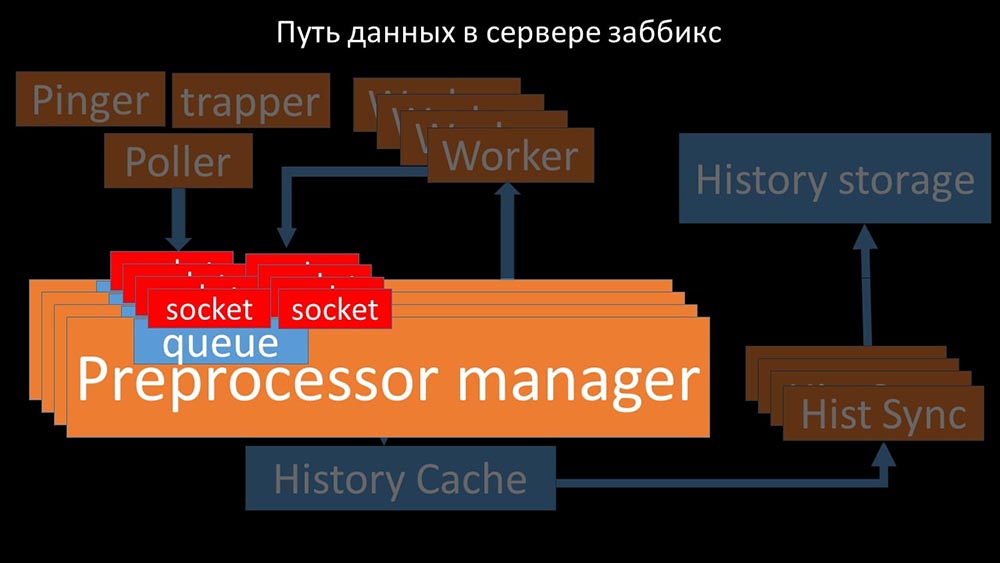 Dan ini memungkinkan kami untuk meningkatkan kecepatan hingga sekitar 130 ribu metrik:
Dan ini memungkinkan kami untuk meningkatkan kecepatan hingga sekitar 130 ribu metrik: Pertumbuhan non-linearitas dijelaskan oleh fakta bahwa ada persaingan untuk cache. cerita. Baginya, 4 manajer praprosesor dan penyelundup sejarah berkompetisi. Pada titik ini, kami menerima sekitar 130 ribu metrik per detik pada mesin uji, menggunakannya sekitar 95% pada prosesor:
Pertumbuhan non-linearitas dijelaskan oleh fakta bahwa ada persaingan untuk cache. cerita. Baginya, 4 manajer praprosesor dan penyelundup sejarah berkompetisi. Pada titik ini, kami menerima sekitar 130 ribu metrik per detik pada mesin uji, menggunakannya sekitar 95% pada prosesor: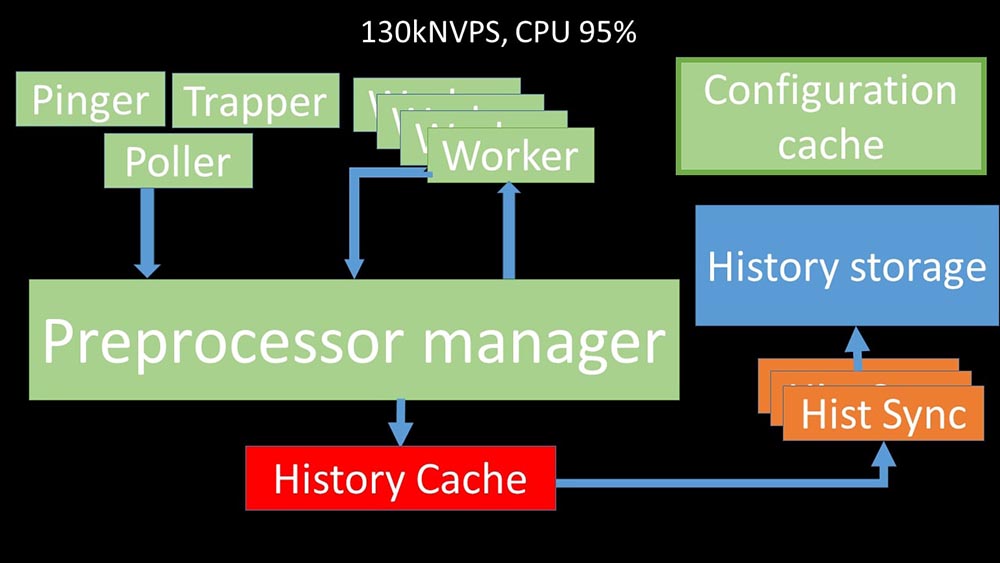 Sekitar 2,5 bulan lalu
Sekitar 2,5 bulan laluPenolakan komunitas snmp meningkatkan NVP satu setengah kali
MM: - Max, saya perlu mesin uji baru! Kami tidak lagi cocok dengan yang sekarang.KIA: - Dan sekarang apa?MM: - Sekarang - 130k NVP dan prosesor "rak".KIA: - Wow! Keren! Tunggu, saya punya dua pertanyaan. Menurut perhitungan saya, kebutuhan kita adalah di wilayah 15-20 ribu metrik per detik. Mengapa kita membutuhkan lebih banyak?MM: - Saya ingin menyelesaikan pekerjaan sampai akhir. Saya ingin melihat seberapa banyak kita dapat keluar dari sistem ini.MCH: - Tapi ...MM: - Tapi itu tidak berguna untuk bisnis.KIA: - Begitu. Dan pertanyaan kedua: apa yang kita miliki sekarang, dapatkah kita menghidupi diri sendiri, tanpa bantuan pengembang?MM:- Aku tidak berpikir. Mengubah cache konfigurasi adalah masalah. Ini berurusan dengan perubahan di sebagian besar utas dan sulit untuk dipertahankan. Kemungkinan besar, mendukungnya akan sangat sulit.MCH: - Maka Anda membutuhkan beberapa alternatif.MM: - Ada opsi seperti itu. Kita dapat beralih ke core cepat, sambil meninggalkan sistem penguncian yang baru. Kami masih mendapatkan kinerja 60-80 ribu metrik. Dalam hal ini, kita dapat meninggalkan sisa kode. Clickhouse, polling asinkron akan bekerja. Dan itu akan mudah dipertahankan.KIA: - Hebat! Saya mengusulkan untuk memikirkan ini.Setelah mengoptimalkan sisi server, kami akhirnya dapat menjalankan kode baru menjadi produktif. Kami mengabaikan sebagian perubahan demi beralih ke mesin dengan kernel cepat dan meminimalkan jumlah perubahan dalam kode. Kami juga menyederhanakan konfigurasi dan, jika mungkin, mengabaikan makro dalam elemen data, karena mereka adalah sumber kunci tambahan. Misalnya, penolakan makro komunitas snmp, yang sering ditemukan dalam dokumentasi dan contoh, dalam kasus kami memungkinkan kami untuk mempercepat NVP tambahan sekitar 1,5 kali.Setelah dua hari di produksi
Misalnya, penolakan makro komunitas snmp, yang sering ditemukan dalam dokumentasi dan contoh, dalam kasus kami memungkinkan kami untuk mempercepat NVP tambahan sekitar 1,5 kali.Setelah dua hari di produksiHapus sembulan riwayat kejadian
MCH: - Misha, kami menggunakan sistem selama dua hari, dan semuanya berfungsi. Tetapi hanya ketika semuanya bekerja! Kami telah merencanakan pekerjaan dengan transfer segmen jaringan yang cukup besar, dan sekali lagi dengan tangan kami memeriksa bahwa itu telah meningkat, bahwa itu tidak.MM: - Tidak mungkin! Kami memeriksa semuanya 10 kali. Server bahkan memproses aksesibilitas jaringan secara instan.KIA: - Ya, saya mengerti segalanya: server, pangkalan, atas, austat, log - semuanya cepat ... Tapi kami melihat antarmuka web, dan di sana kami memiliki prosesor "di rak" di server dan ini: MM: - Begitu. Ayo tonton webnya. Kami menemukan bahwa dalam situasi di mana terdapat sejumlah besar insiden aktif, sebagian besar widget operasional mulai bekerja sangat lambat:
MM: - Begitu. Ayo tonton webnya. Kami menemukan bahwa dalam situasi di mana terdapat sejumlah besar insiden aktif, sebagian besar widget operasional mulai bekerja sangat lambat: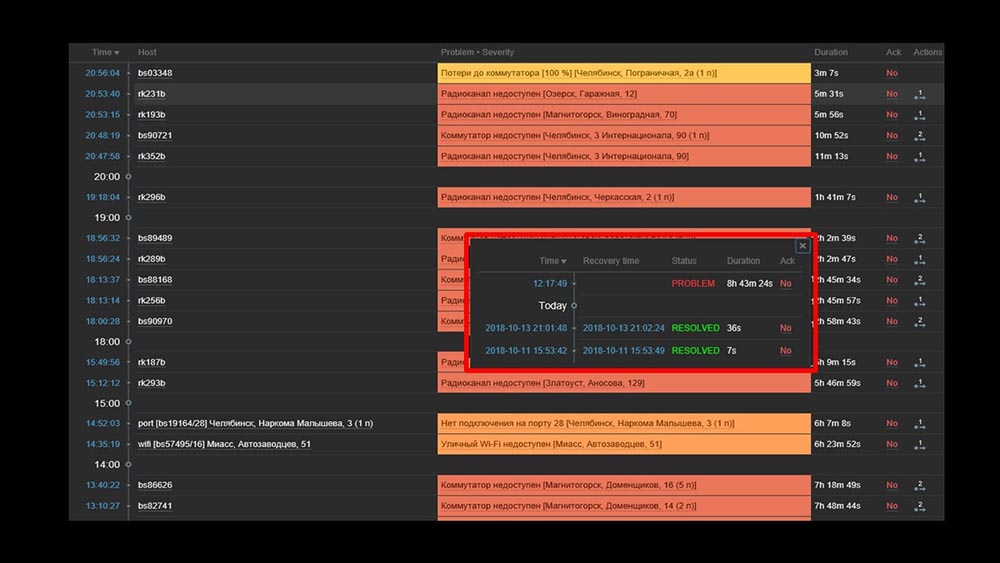 Alasannya adalah generasi sembulan dengan riwayat insiden yang dihasilkan untuk setiap item dalam daftar. Oleh karena itu, kami menolak untuk menghasilkan windows ini (berkomentar 5 baris dalam kode), dan ini memecahkan masalah kami.Waktu pemuatan widget, bahkan ketika sepenuhnya tidak dapat diakses, dikurangi dari beberapa menit menjadi dapat diterima selama 10-15 detik, dan riwayat masih dapat dilihat dengan mengklik waktu:
Alasannya adalah generasi sembulan dengan riwayat insiden yang dihasilkan untuk setiap item dalam daftar. Oleh karena itu, kami menolak untuk menghasilkan windows ini (berkomentar 5 baris dalam kode), dan ini memecahkan masalah kami.Waktu pemuatan widget, bahkan ketika sepenuhnya tidak dapat diakses, dikurangi dari beberapa menit menjadi dapat diterima selama 10-15 detik, dan riwayat masih dapat dilihat dengan mengklik waktu: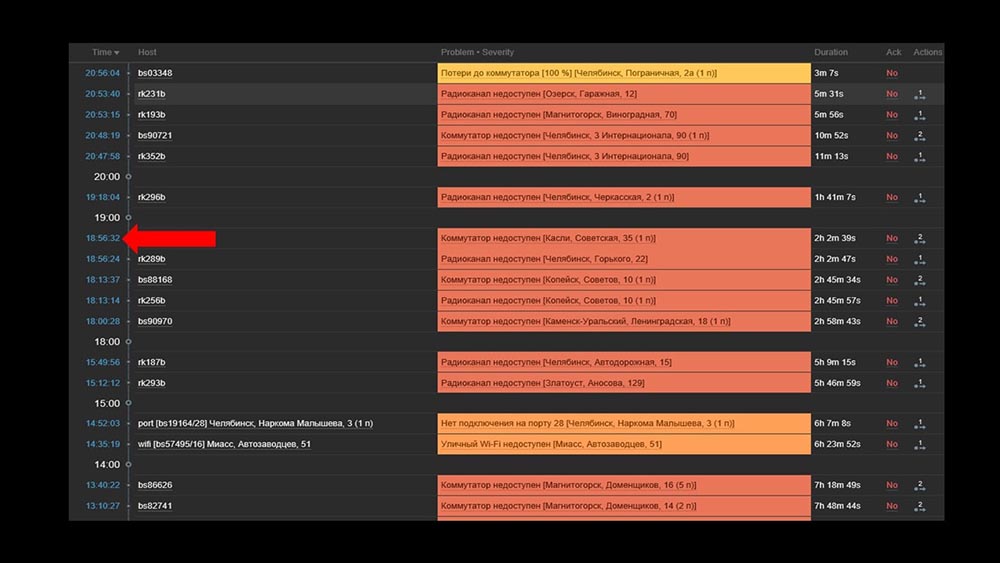 Setelah bekerja. 2 bulan laluKIA: - Misha, kamu mau pergi? Kita harus bicara.MM: - Tidak akan. Lagi sesuatu dengan Zabbix?KIA: - Oh tidak, santai! Saya hanya ingin mengatakan: semuanya bekerja, terima kasih! Bir denganku.
Setelah bekerja. 2 bulan laluKIA: - Misha, kamu mau pergi? Kita harus bicara.MM: - Tidak akan. Lagi sesuatu dengan Zabbix?KIA: - Oh tidak, santai! Saya hanya ingin mengatakan: semuanya bekerja, terima kasih! Bir denganku.Zabbix efektif
Zabbix adalah sistem dan fungsi yang cukup fleksibel dan kaya. Ini dapat digunakan untuk instalasi kecil di luar kotak, tetapi dengan pertumbuhan kebutuhan itu harus dioptimalkan. Untuk menyimpan arsip metrik yang besar, gunakan penyimpanan yang sesuai:- Anda dapat menggunakan alat bawaan dalam bentuk integrasi dengan Elastixerch atau mengunggah riwayat ke file teks (tersedia dari versi keempat);
- Anda dapat memanfaatkan pengalaman dan integrasi kami dengan Clickhouse.
Untuk secara drastis meningkatkan kecepatan pengumpulan metrik, kumpulkan secara tidak sinkron dan transfer melalui antarmuka trapper ke server Zabbix; atau Anda dapat menggunakan patch untuk polling asinkron dari Zabbix itu sendiri.Zabbix ditulis dalam bahasa C dan cukup efektif. Solusi dari beberapa tempat arsitektur yang sempit memungkinkan untuk lebih meningkatkan produktivitasnya dan, dalam pengalaman kami, untuk menerima lebih dari 100 ribu metrik pada mesin prosesor tunggal.
Patch Zabbix yang sama
MM: - Saya ingin menambahkan beberapa poin. Seluruh laporan saat ini, semua tes, angka diberikan untuk konfigurasi yang digunakan bersama kami. Kami sekarang mengambil sekitar 20 ribu metrik per detik darinya. Jika Anda mencoba memahami apakah ini akan berhasil untuk Anda - Anda dapat membandingkan. Apa yang mereka bicarakan hari ini diposting di GitHub sebagai tambalan: github.com/miklert/zabbix Tambalan itu meliputi:
meliputi:- integrasi penuh dengan Clickhouse (baik server Zabbix dan frontend);
- menyelesaikan masalah dengan manajer preprosesor;
- polling asinkron.
Patch ini kompatibel dengan semua versi 4, termasuk lts. Kemungkinan besar, dengan perubahan minimal, ini akan berfungsi pada versi 3.4.Terimakasih atas perhatiannya.Pertanyaan
Pertanyaan dari hadirin (selanjutnya - A): - Selamat siang! Tolong beritahu saya, apakah Anda memiliki rencana untuk interaksi intensif dengan tim Zabbix atau apakah mereka memiliki dengan Anda sehingga ini bukan patch, tetapi perilaku normal Zabbix?MM: - Ya, kami pasti akan melakukan bagian dari perubahan. Sesuatu akan terjadi, sesuatu akan tetap ada di tambalan.A: - Terima kasih banyak atas laporannya! Katakan, tolong, setelah menerapkan tambalan, dukungan dari sisi Zabbix akan tetap dan bagaimana melanjutkan untuk meningkatkan ke versi yang lebih tinggi? Apakah mungkin untuk memperbarui Zabbix setelah tambalan Anda ke 4.2, 5.0?MM:- Saya tidak bisa mengatakan tentang dukungan. Jika saya adalah dukungan teknis Zabbix, saya mungkin akan mengatakan tidak, karena ini adalah kode orang lain. Adapun basis kode 4.2, posisi kami adalah ini: "Kami akan pergi dengan waktu, dan kami akan diperbarui pada versi berikutnya." Karenanya, untuk beberapa waktu kami akan mengunggah tambalan ke versi yang diperbarui. Saya sudah mengatakan dalam laporan: jumlah perubahan dengan versi masih cukup kecil. Saya pikir transisi dari 3,4 ke 4 membawa kami, tampaknya, sekitar 15 menit. Sesuatu telah berubah di sana, tetapi tidak terlalu penting.A: - Jadi Anda berencana untuk mempertahankan tambalan Anda dan Anda dapat dengan aman memproduksinya, di kemudian hari mendapatkan pembaruan dengan cara tertentu?MM: - Kami sangat merekomendasikannya. Ini memecahkan banyak masalah bagi kami.KIA:- Sekali lagi, saya ingin menekankan bahwa perubahan yang tidak berhubungan dengan arsitektur dan tidak berhubungan dengan kunci, antrian - mereka adalah modular, mereka berada dalam modul yang terpisah. Bahkan dengan perubahan kecil mereka dapat dipelihara dengan mudah.MM: - Jika detailnya menarik, maka "Clickhouse" menggunakan perpustakaan sejarah yang disebut. Tidak terikat - ini adalah salinan dari dukungan Elastic, yang dapat dikonfigurasi. Polling hanya mengubah poller. Kami percaya ini akan bekerja untuk waktu yang lama.A: - Terima kasih banyak. Tapi katakan padaku, apakah ada dokumentasi perubahan yang dibuat? MM:- Dokumentasi adalah tambalan. Jelas, dengan diperkenalkannya "Clickhouse," dengan diperkenalkannya jenis-jenis poller baru, opsi-opsi konfigurasi baru muncul. Tautan dari slide terakhir memiliki deskripsi singkat tentang cara menggunakannya.
MM:- Dokumentasi adalah tambalan. Jelas, dengan diperkenalkannya "Clickhouse," dengan diperkenalkannya jenis-jenis poller baru, opsi-opsi konfigurasi baru muncul. Tautan dari slide terakhir memiliki deskripsi singkat tentang cara menggunakannya.Tentang mengganti fping dengan nmap
A: - Bagaimana Anda akhirnya mengimplementasikan ini? Bisakah Anda memberikan contoh spesifik: apakah itu strappers dan skrip eksternal Anda? Apa yang akhirnya memeriksa begitu banyak host dengan begitu cepat? Bagaimana Anda mendapatkan host ini? Apakah nmap perlu memberi mereka makan entah bagaimana, mendapatkannya dari suatu tempat, memasukkannya, memulai sesuatu? ..MM:- Keren. Pertanyaan yang sangat benar! Intinya adalah ini. Kami memodifikasi pustaka (ping ICMP, bagian dari Zabbix) untuk pemeriksaan ICMP, yang menunjukkan jumlah paket - unit (1), dan kode mencoba menggunakan nmap. Artinya, ini adalah pekerjaan internal Zabbix, itu telah menjadi pekerjaan internal sang pinger. Karenanya, tidak diperlukan sinkronisasi atau penggunaan trapper. Ini dilakukan dengan sengaja untuk meninggalkan sistem yang koheren dan tidak terlibat dalam sinkronisasi dua sistem dasar: apa yang harus diperiksa, diisi melalui poller, dan jika isiannya rusak pada kita? .. Ini jauh lebih sederhana.A: - Apakah itu berfungsi untuk proxy juga?MM: - Ya, tapi kami tidak memeriksanya. Kode polling sama di Zabbix dan server. Harus bekerja Saya tekankan lagi: kinerja sistem sedemikian rupa sehingga kita tidak perlu proxy.MCH: - Jawaban yang benar untuk pertanyaan ini adalah: "Mengapa Anda memerlukan proxy dengan sistem seperti itu?" Hanya karena NAT'a atau untuk memantau melalui saluran lambat beberapa ...A: - Dan Anda menggunakan Zabbix sebagai alergen, jika saya mengerti dengan benar. Atau grafik (di mana lapisan arsip) Anda pergi ke sistem lain, seperti Grafana? Atau apakah Anda tidak menggunakan fungsi ini?MM: - Saya akan tekankan sekali lagi: kami telah melakukan integrasi penuh. Kami menuangkan histori menjadi "Clickhouse", tetapi pada saat yang sama mengubah frontend php. Php-frontend pergi ke "Clickhouse" dan melakukan semua gambar dari sana. Pada saat yang sama, jujur, kami memiliki bagian yang dibangun dari "Clickhouse" yang sama, dari data Zabbix yang sama, data dalam sistem tampilan grafik lainnya.KIA: - Di "Grafan" juga.Bagaimana keputusan untuk mengalokasikan sumber daya dibuat?
A: - Bagikan sedikit dapur bagian dalam. Bagaimana keputusan dibuat bahwa sumber daya harus dialokasikan untuk pemrosesan produk yang serius? Ini, secara umum, risiko tertentu. Dan tolong beri tahu saya, dalam konteks fakta bahwa Anda akan mendukung versi baru: bagaimana keputusan ini dibenarkan dari sudut pandang manajemen?MM: - Rupanya, kami tidak menceritakan drama dengan baik. Kami menemukan diri kami dalam situasi di mana sesuatu harus dilakukan, dan pada dasarnya pergi dua perintah paralel:- Salah satunya terlibat dalam meluncurkan sistem pemantauan menggunakan metode baru: pemantauan sebagai layanan, serangkaian standar solusi sumber terbuka yang kami kombinasikan dan kemudian mencoba mengubah proses bisnis agar dapat bekerja dengan sistem pemantauan yang baru.
- Secara paralel, kami memiliki programmer yang antusias yang melakukan ini (tentang dirinya sendiri). Kebetulan dia menang.
A: - Dan berapa ukuran tim?KIA: - Dia ada di depanmu.A: - Itu, seperti biasa, dibutuhkan gairah?MM: - Saya tidak tahu apa itu passionarian.A: - Dalam hal ini, tampaknya, Anda. Terima kasih banyak, kamu keren.MM: - Terima kasih.Tentang tambalan untuk Zabbix
A: - Untuk sistem yang menggunakan proxy (misalnya, dalam beberapa sistem terdistribusi), apakah mungkin bagi keputusan Anda untuk beradaptasi dan menambal, katakanlah, poller, proxy, dan sebagian preprosesor Zabbix itu sendiri; dan interaksi mereka? Apakah mungkin untuk mengoptimalkan perkembangan yang ada untuk sistem dengan banyak proksi?MM: - Saya tahu bahwa server Zabbix dirakit menggunakan proxy (ini mengkompilasi dan kode diperoleh). Kami tidak menguji ini pada produk. Saya tidak yakin tentang ini, tetapi, menurut pendapat saya, manajer preprosesor tidak digunakan dalam proksi. Tugas proxy adalah mengambil satu set metrik dari Zabbix, mengisinya (itu juga menulis konfigurasi, basis data lokal) dan mengembalikannya ke server Zabbix. Kemudian server itu sendiri akan melakukan preprocessing ketika menerimanya.Ketertarikan pada proxy dapat dimengerti. Kami akan memverifikasi ini. Ini adalah topik yang menarik.A: - Idenya adalah ini: jika Anda dapat menambal poller, mereka dapat ditambal ke proksi dan menambal interaksi dengan server, dan preprocessor dapat diadaptasi untuk keperluan ini hanya di server.MM: - Saya pikir semuanya lebih sederhana. Anda mengambil kode, menerapkan tambalan, lalu mengonfigurasinya sesuai kebutuhan - mengumpulkan server proxy (misalnya, dengan ODBC) dan mendistribusikan kode yang ditambal ke sistem. Jika perlu - kumpulkan proxy, jika perlu - server.A: - Selain itu, Anda tidak perlu menambal transmisi proxy ke server, kemungkinan besar?KIA: - Tidak, itu standar.MM:- Sebenarnya, salah satu ide tidak terdengar. Kami selalu menjaga keseimbangan antara ledakan ide dan jumlah perubahan, kemudahan dukungan.Sedikit iklan :)
Terima kasih untuk tetap bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikan kepada teman Anda VPS berbasis cloud untuk pengembang mulai $ 4,99 , analog unik dari server entry-level yang diciptakan oleh kami untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps mulai dari $ 19 atau cara membagi server? (opsi tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).Dell R730xd 2 kali lebih murah di pusat data Equinix Tier IV di Amsterdam? Hanya kami yang memiliki 2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV dari $ 199 di Belanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - mulai dari $ 99! Baca tentang Cara Membangun Infrastruktur Bldg. kelas c menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen? Source: https://habr.com/ru/post/undefined/
All Articles