Dalam artikel sebelumnya, kami meneliti mekanisme perhatian, metode yang sangat umum dalam model pembelajaran mendalam modern yang dapat meningkatkan indikator kinerja aplikasi terjemahan mesin saraf. Pada artikel ini, kita akan melihat Transformer, model yang menggunakan mekanisme perhatian untuk meningkatkan kecepatan belajar. Selain itu, untuk sejumlah tugas, Transformers mengungguli model terjemahan mesin saraf Google. Namun, keuntungan terbesar Transformers adalah efisiensi tinggi dalam kondisi paralelisasi. Bahkan Google Cloud merekomendasikan menggunakan Transformer sebagai model ketika bekerja di Cloud TPU . Mari kita coba mencari tahu apa model terdiri dan apa fungsinya.
Model Transformer pertama kali diusulkan dalam artikel Attention is All You Need . Implementasi pada TensorFlow tersedia sebagai bagian dari paket Tensor2Tensor , di samping itu, sekelompok peneliti NLP dari Harvard membuat anotasi panduan artikel dengan implementasi pada PyTorch . Dalam panduan yang sama ini, kami akan mencoba menguraikan ide dan konsep utama secara paling sederhana dan konsisten, yang kami harap akan membantu orang-orang yang tidak memiliki pengetahuan mendalam tentang bidang subjek untuk memahami model ini.
Tinjauan Tingkat Tinggi
Mari kita lihat modelnya sebagai semacam kotak hitam. Dalam aplikasi terjemahan mesin, ia menerima kalimat dalam satu bahasa sebagai input dan menampilkan kalimat dalam bahasa lain.

, , , .
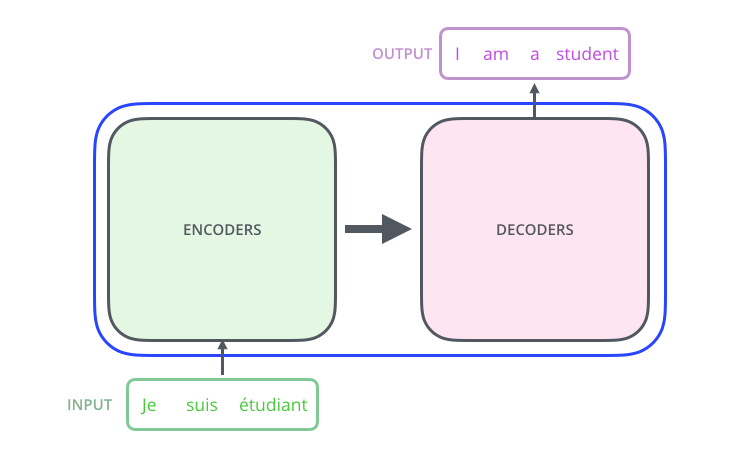
– ; 6 , ( 6 , ). – , .
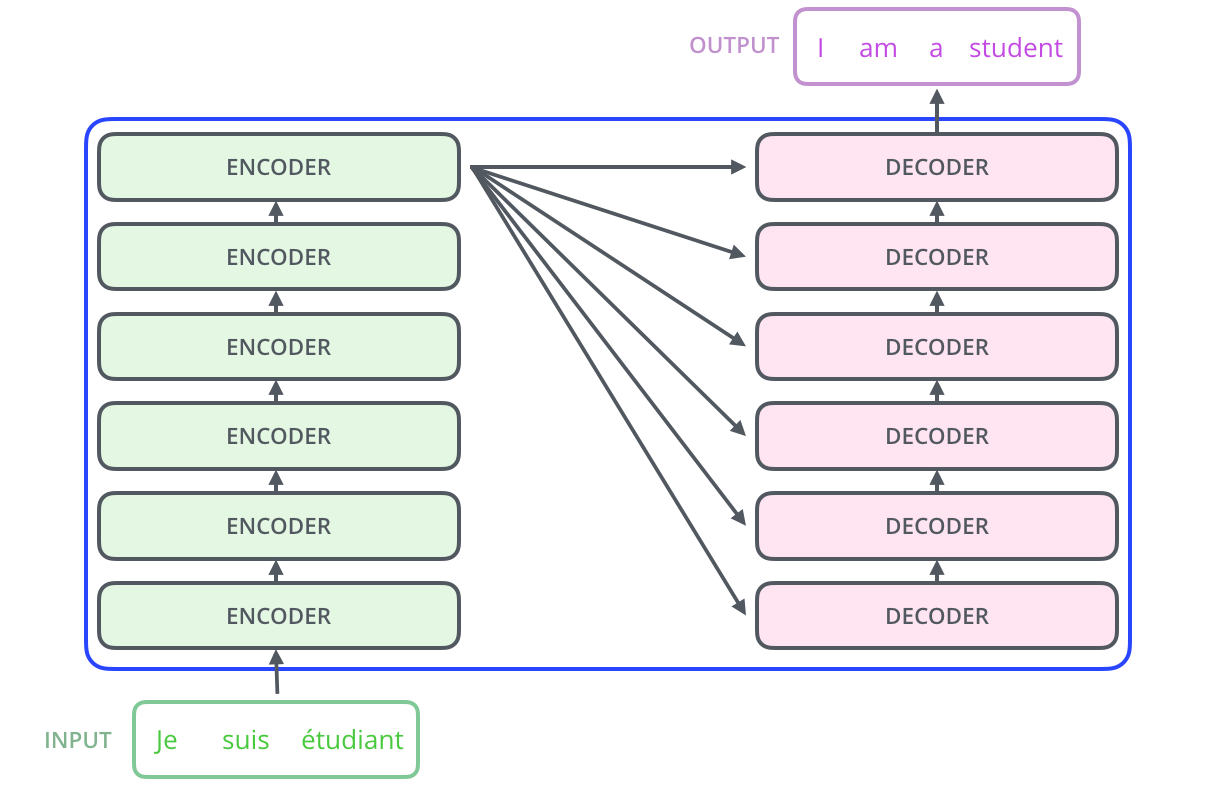
, . :
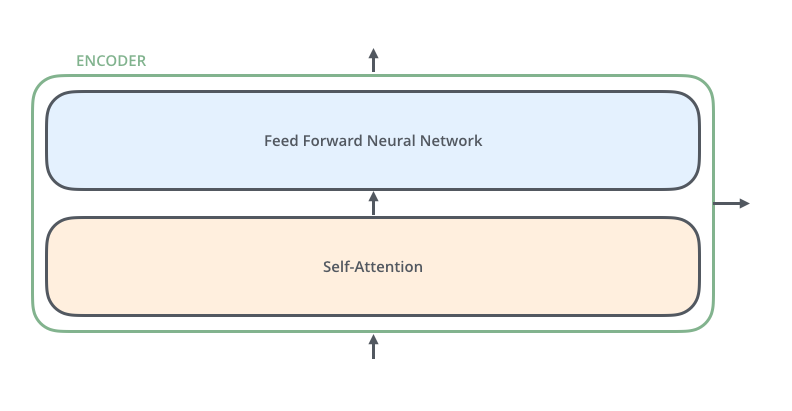
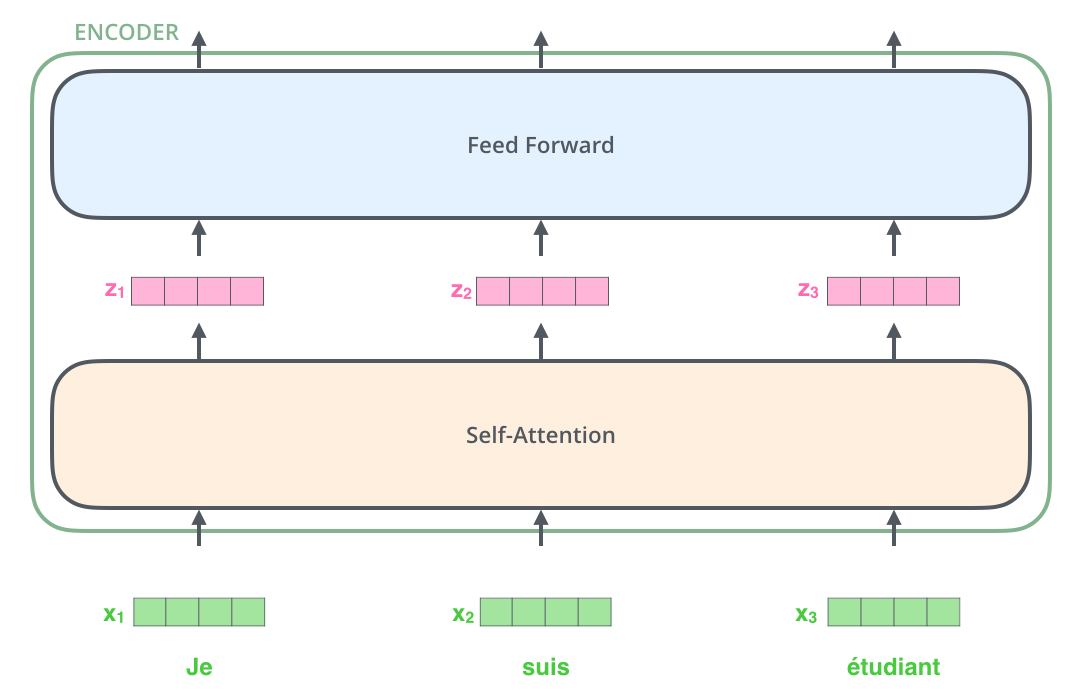
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
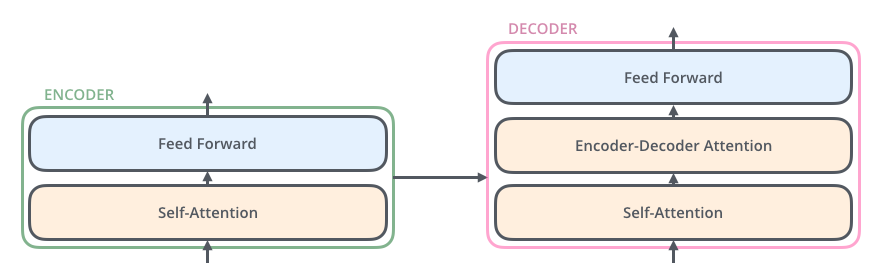
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
: . , , , .
, .
!
, , – , , , .
. , .
, « » -, . , «Attention is All You Need». , .
– , :
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
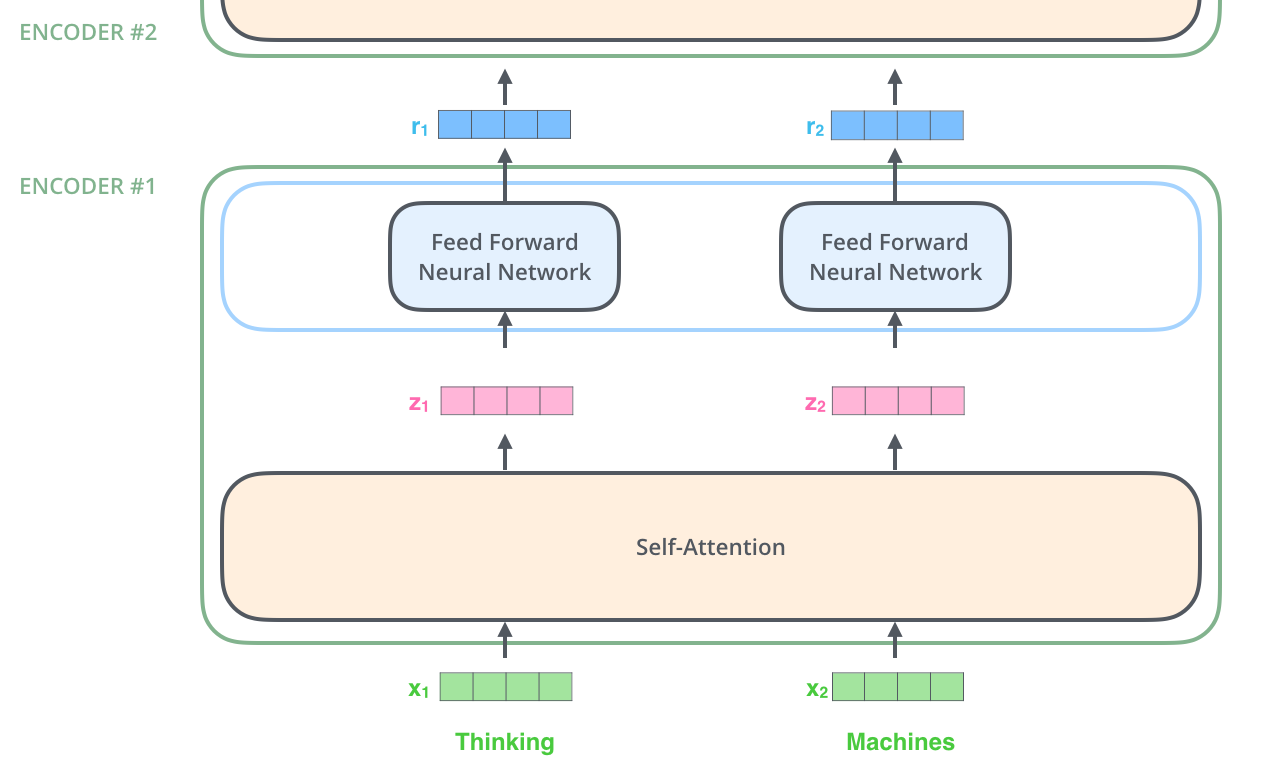
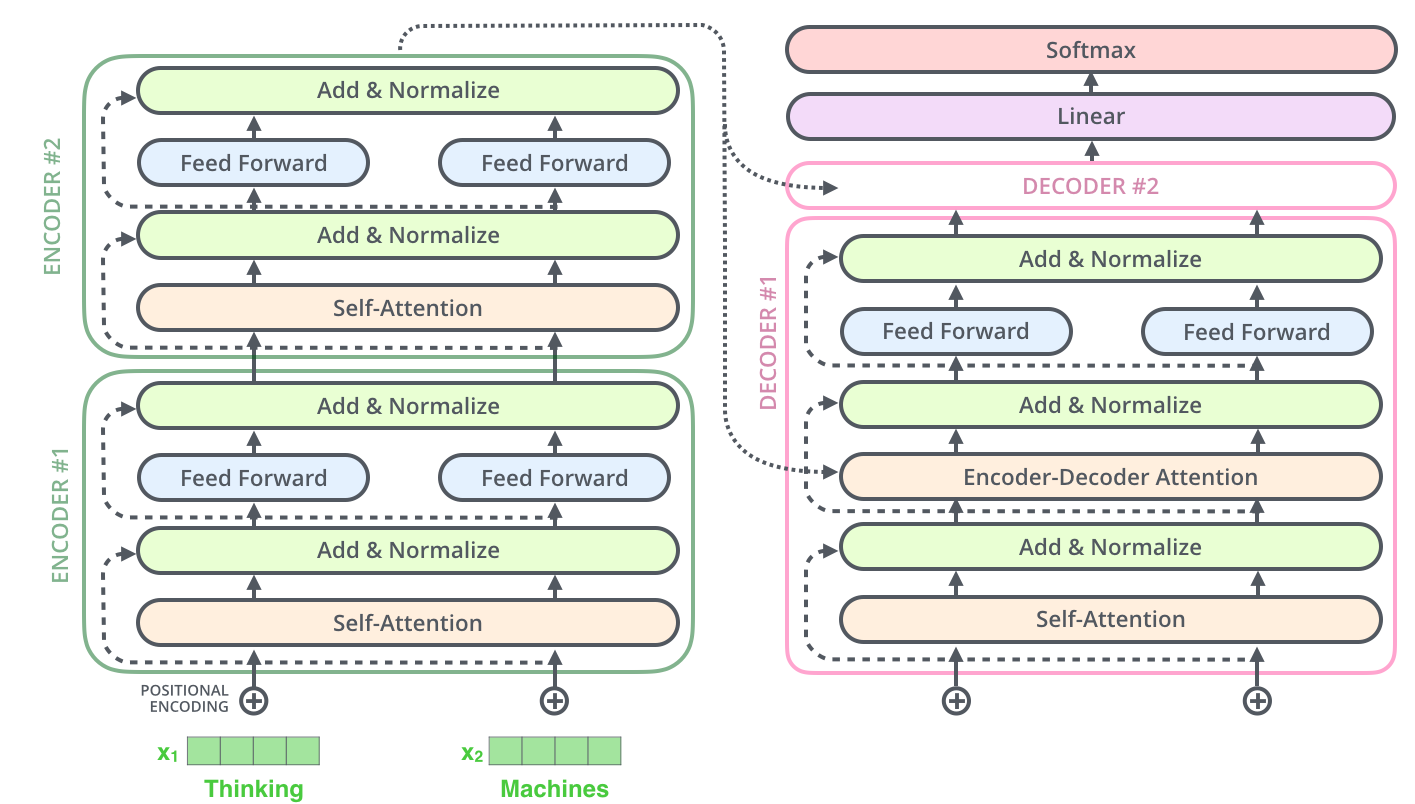
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
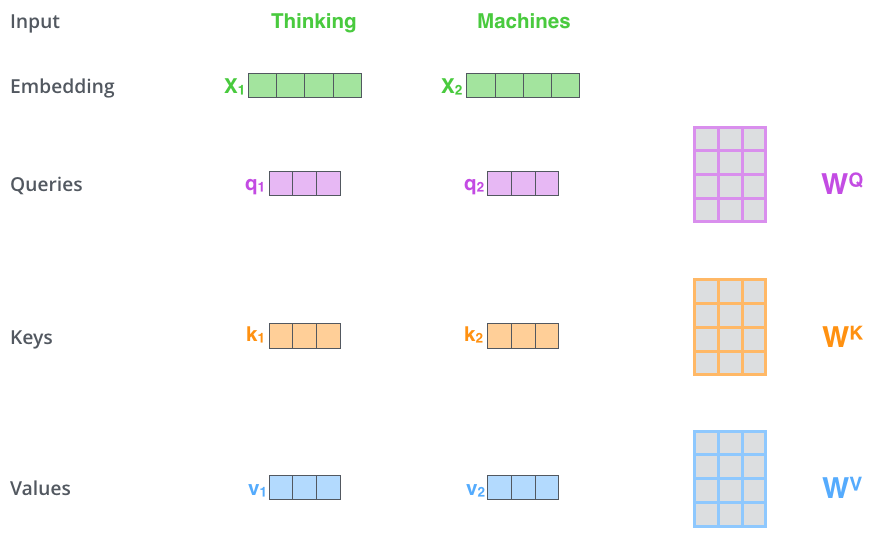
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
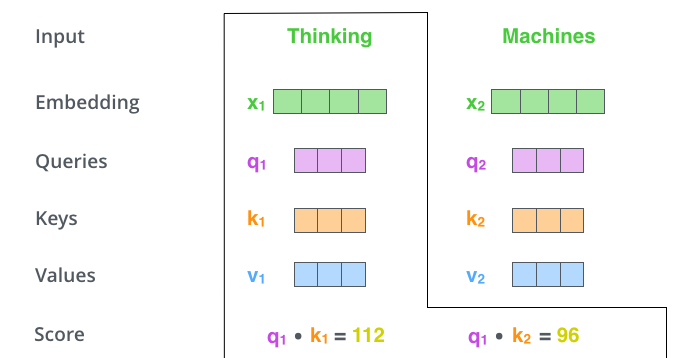
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
– 8 ( , – 64; , ), (softmax). , 1.
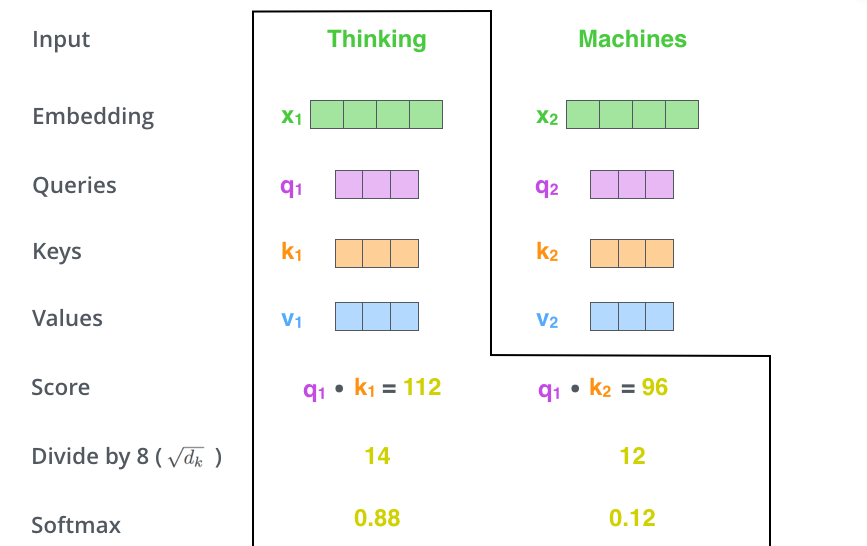
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
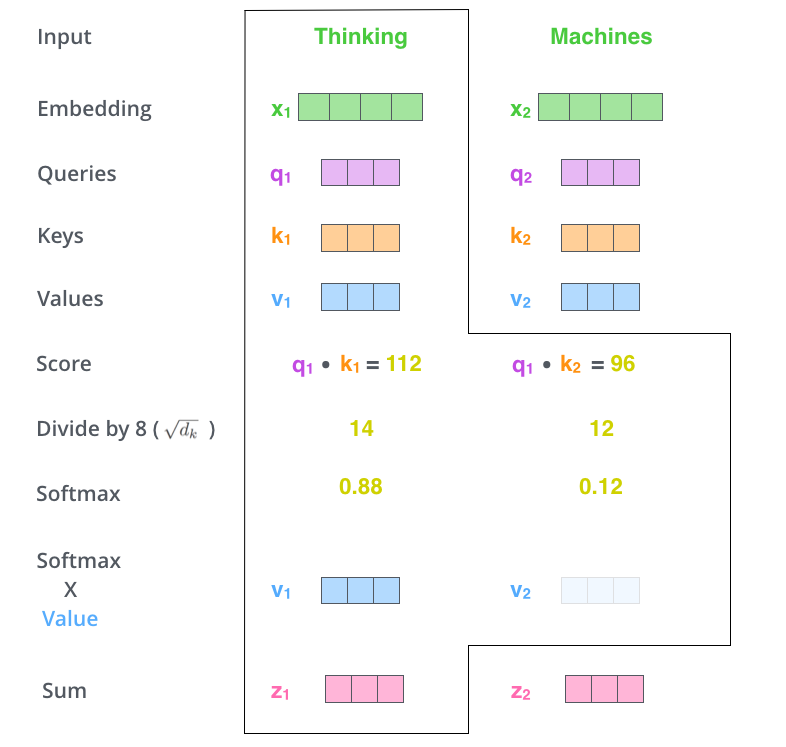
. , . , , . , , .
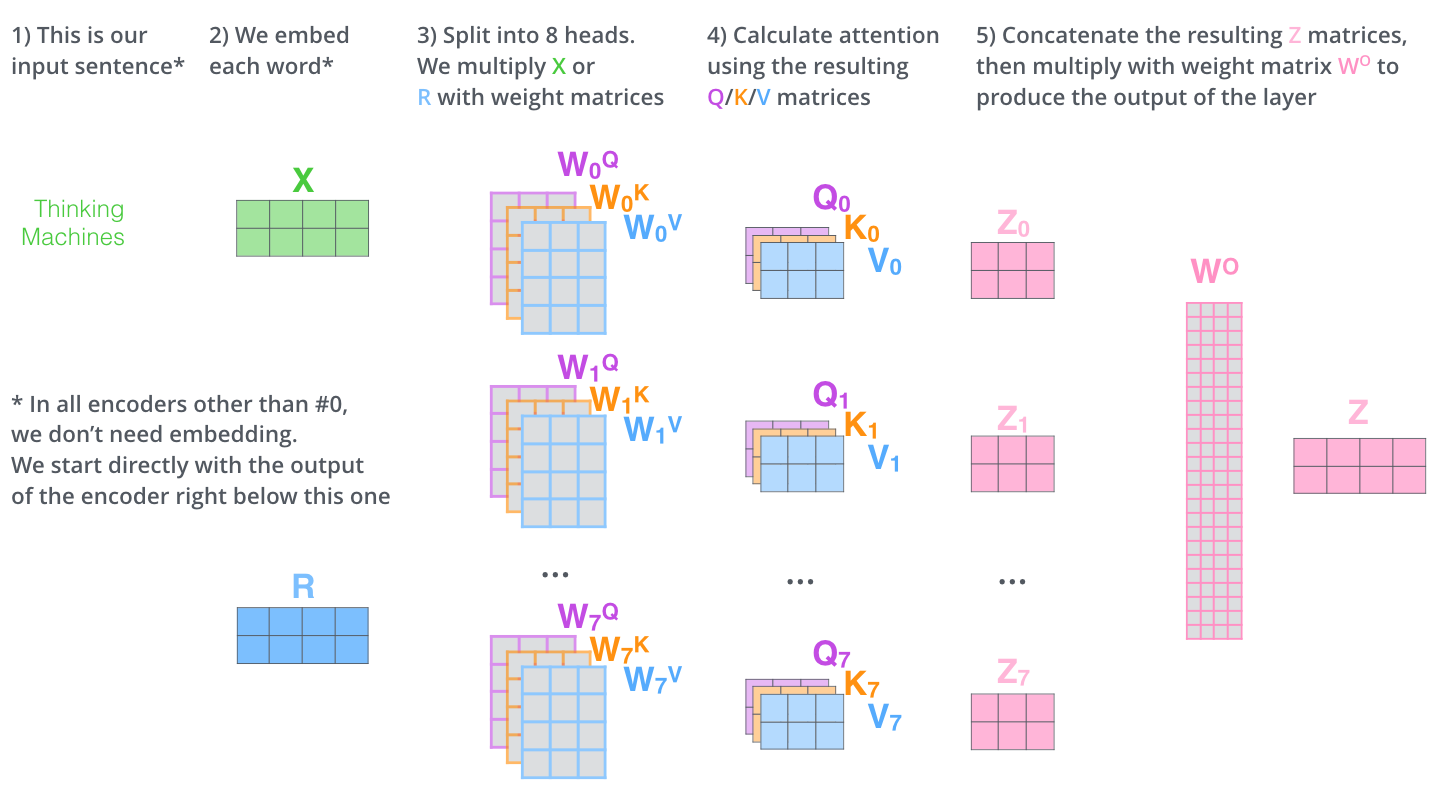
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
, , 2-6 .
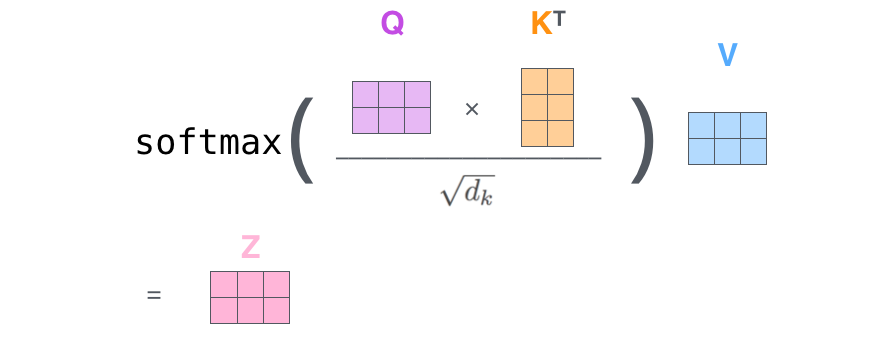
.
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
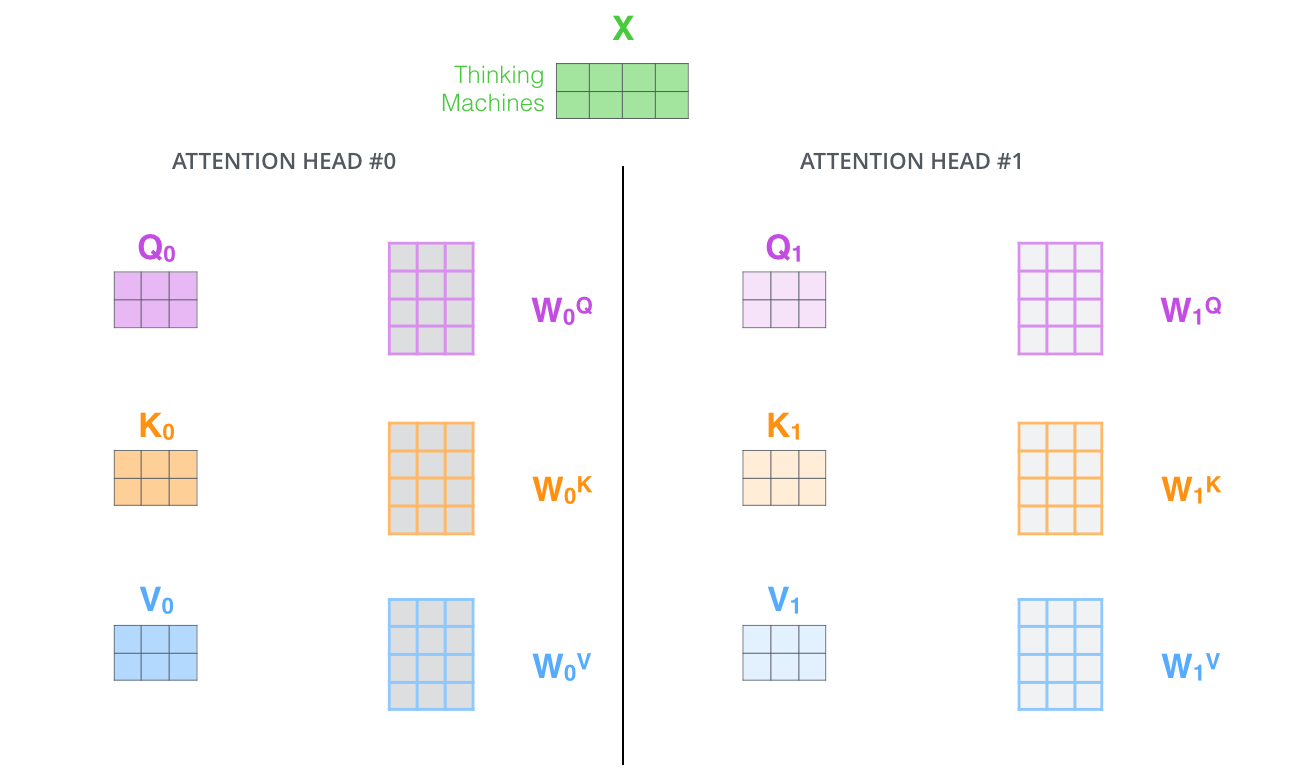
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
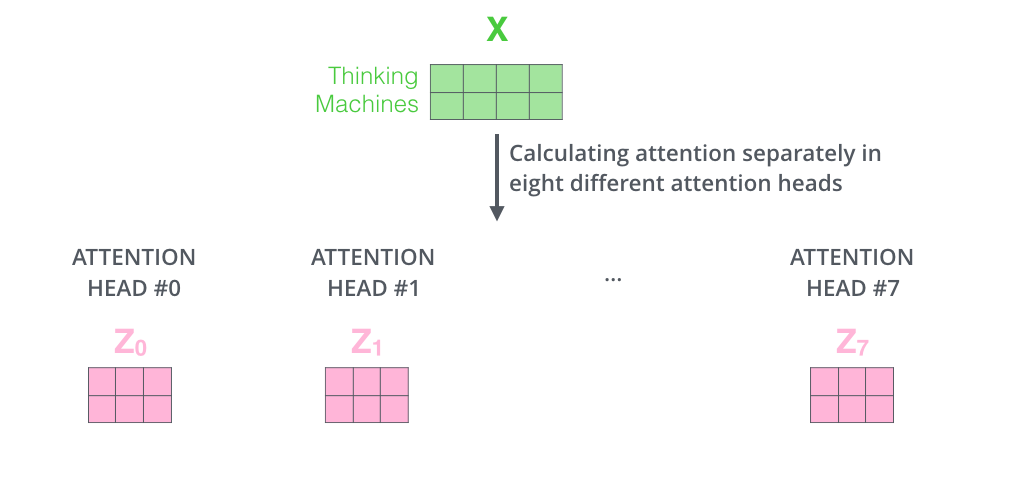
. , 8 – ( ), Z .
? WO.
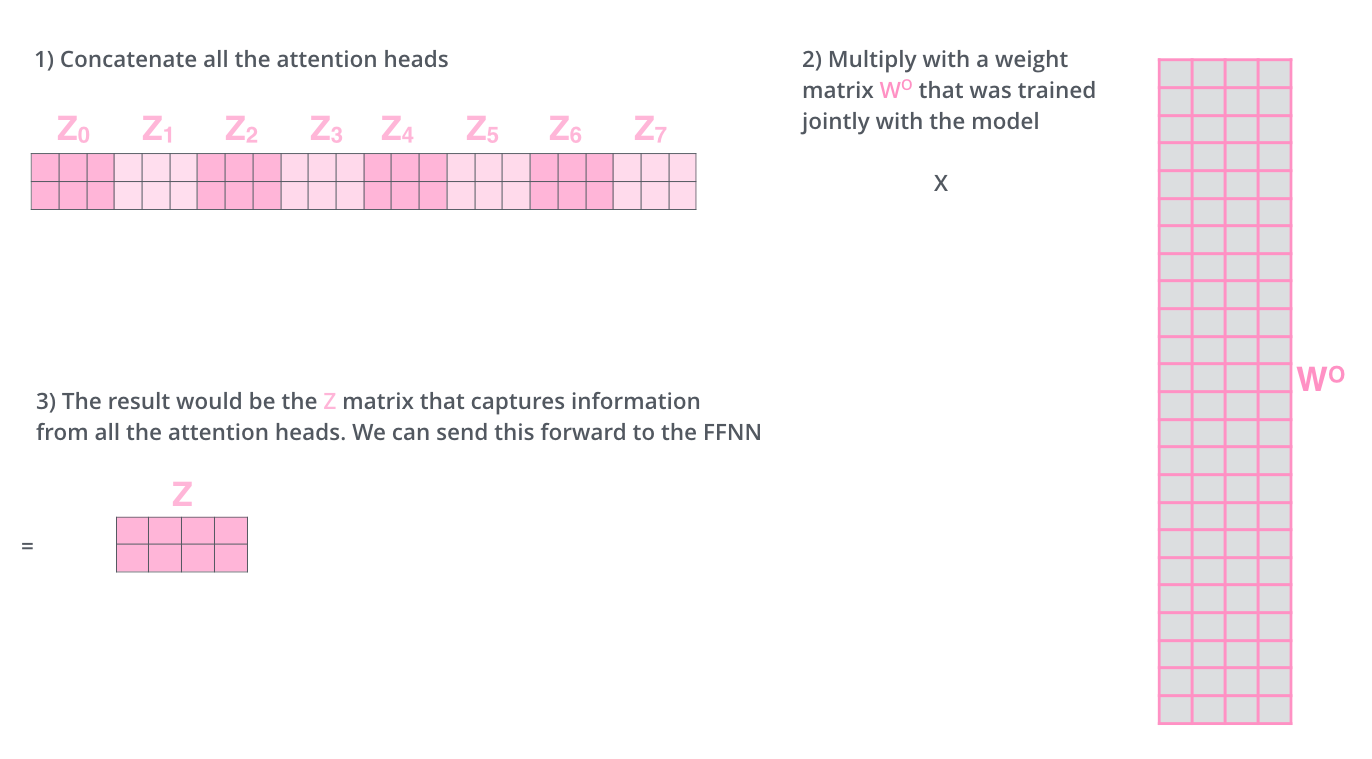
, , . , . , .
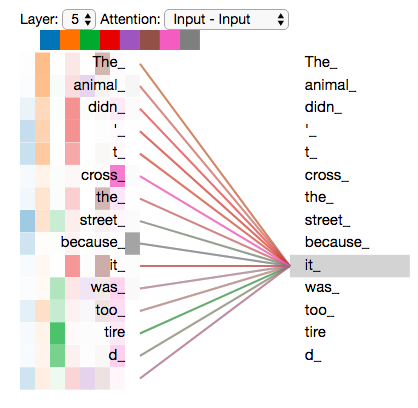
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
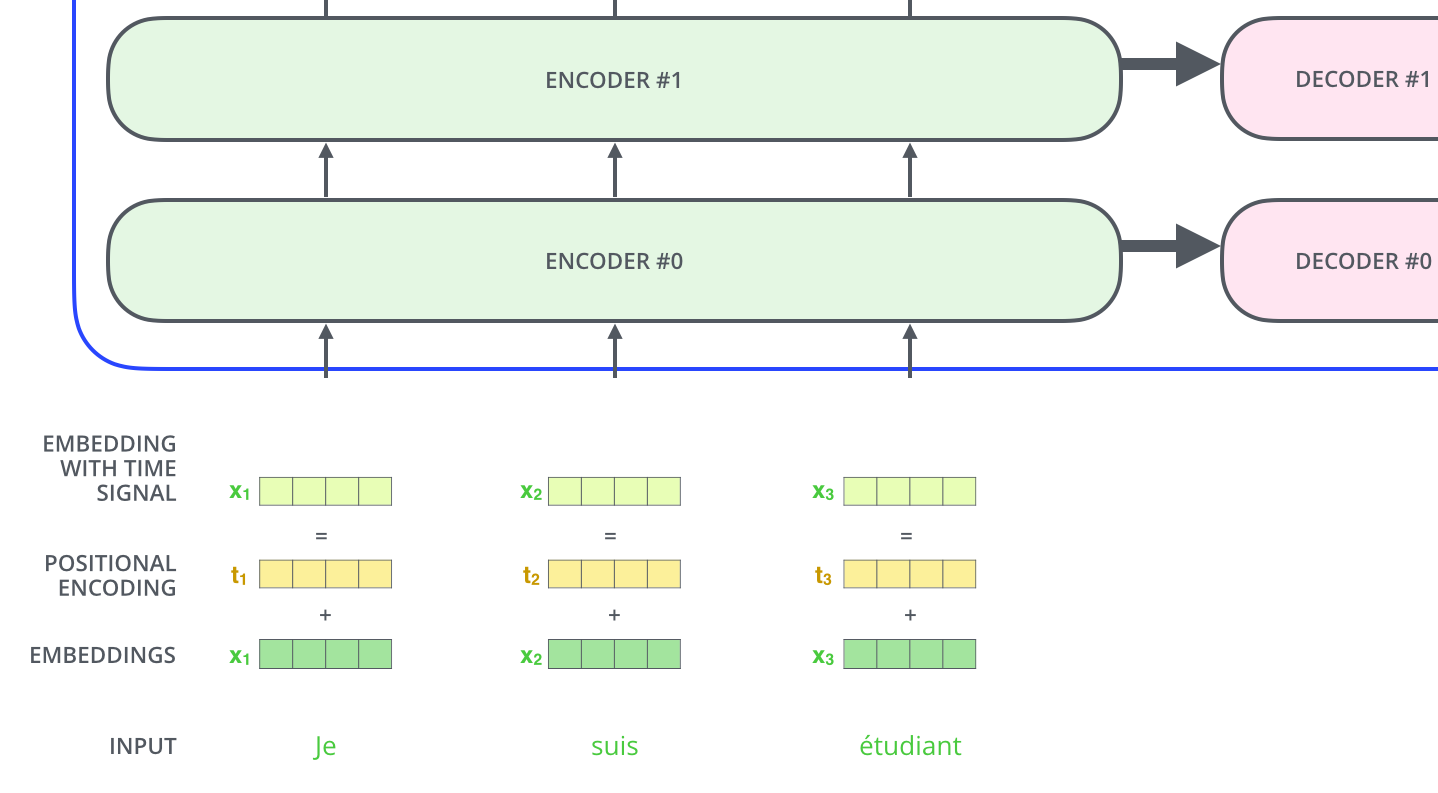
, , , .
, 4, :
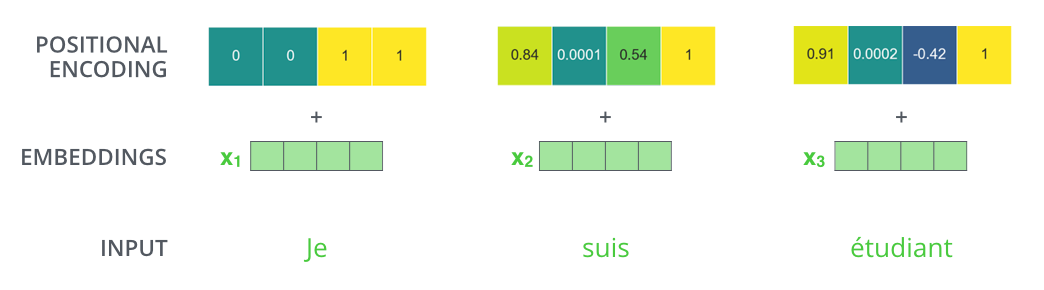
?
: , , , — .. 512 -1 1. , .
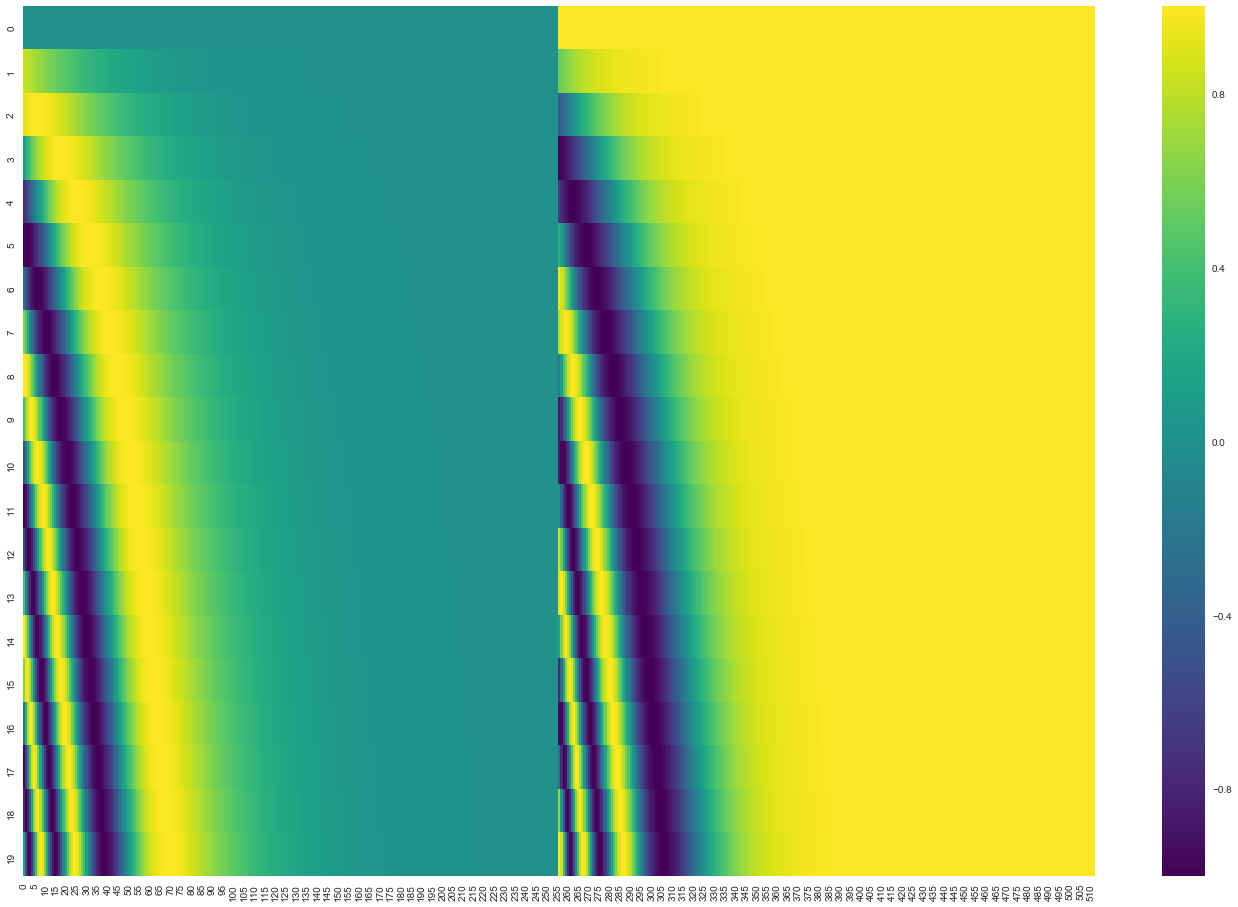
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
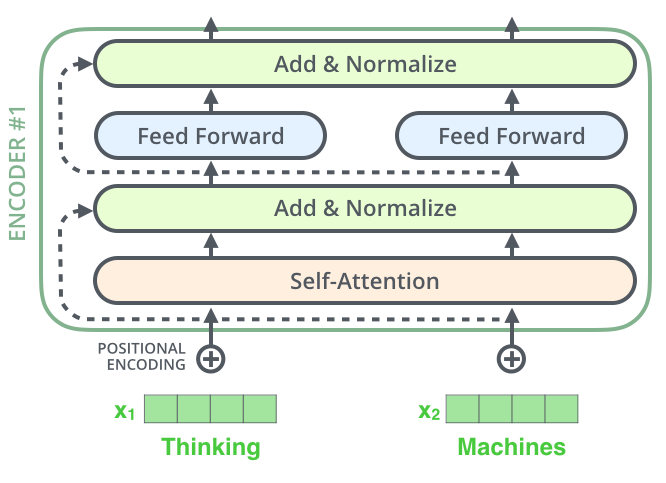
, , :
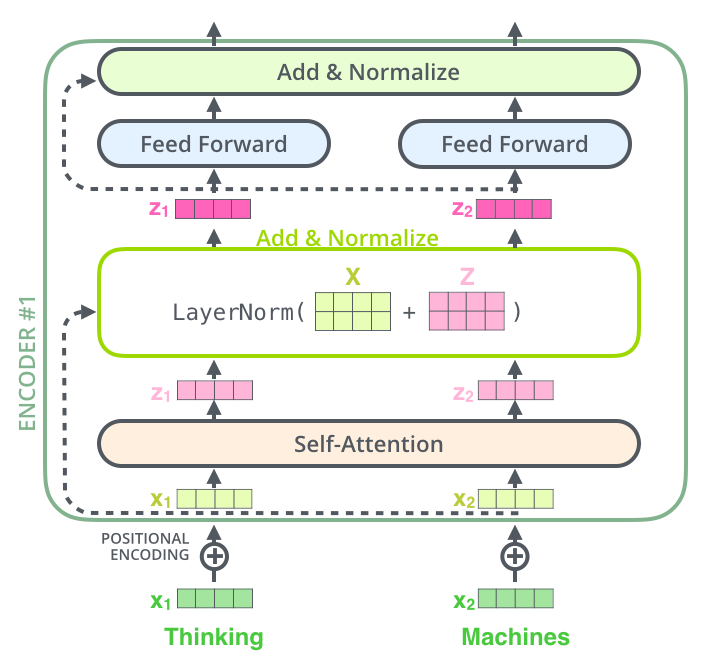
. , :
, , , . , .
. K V. «-» , :
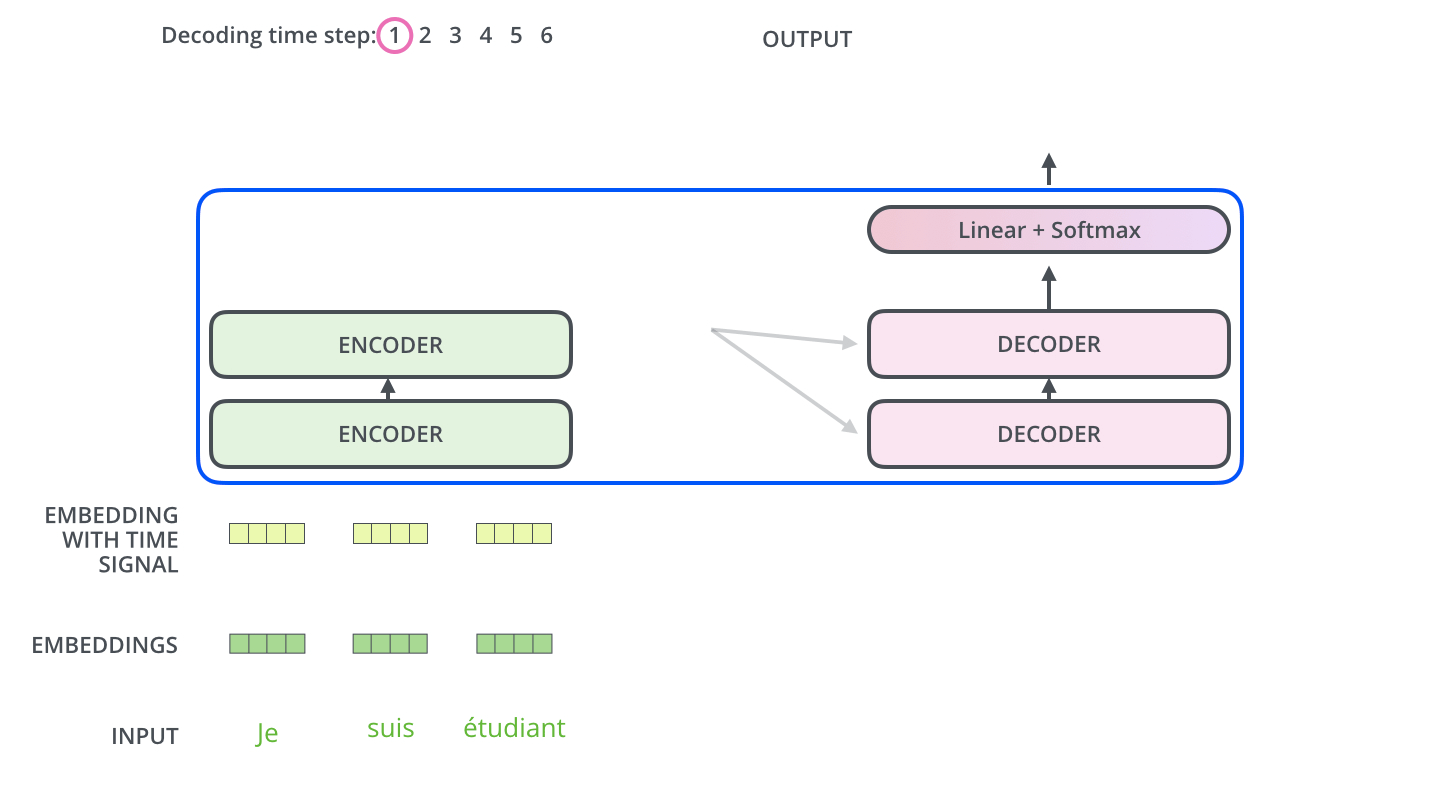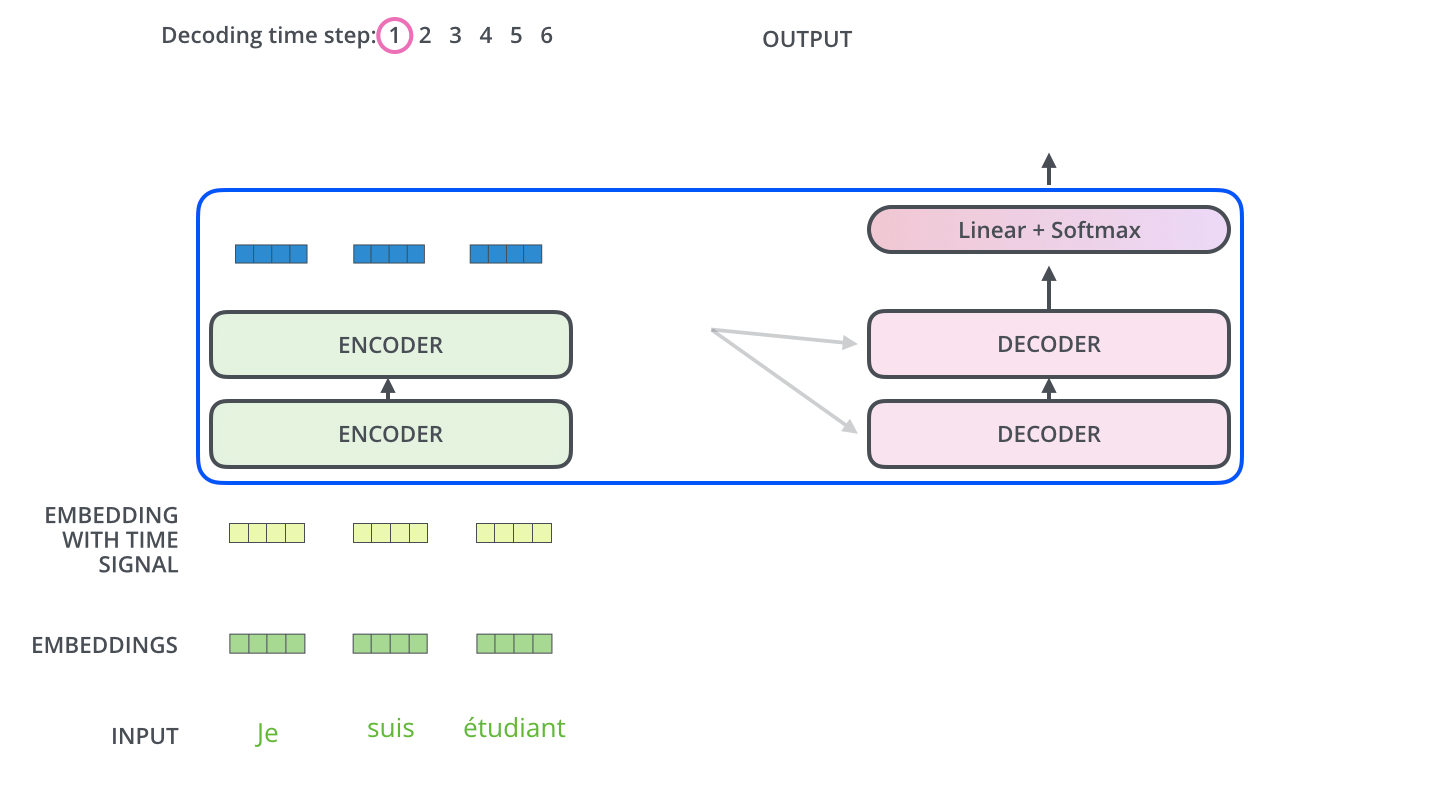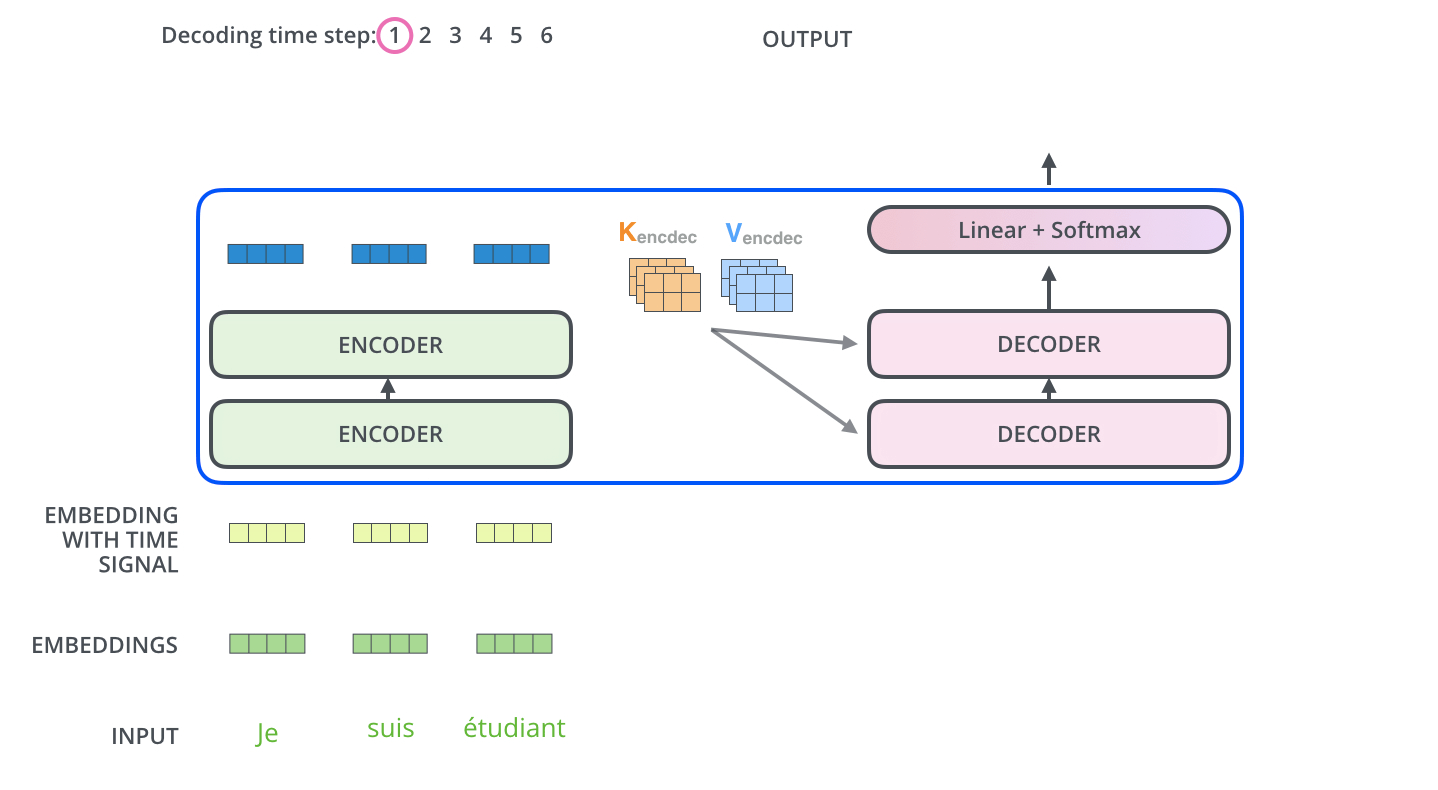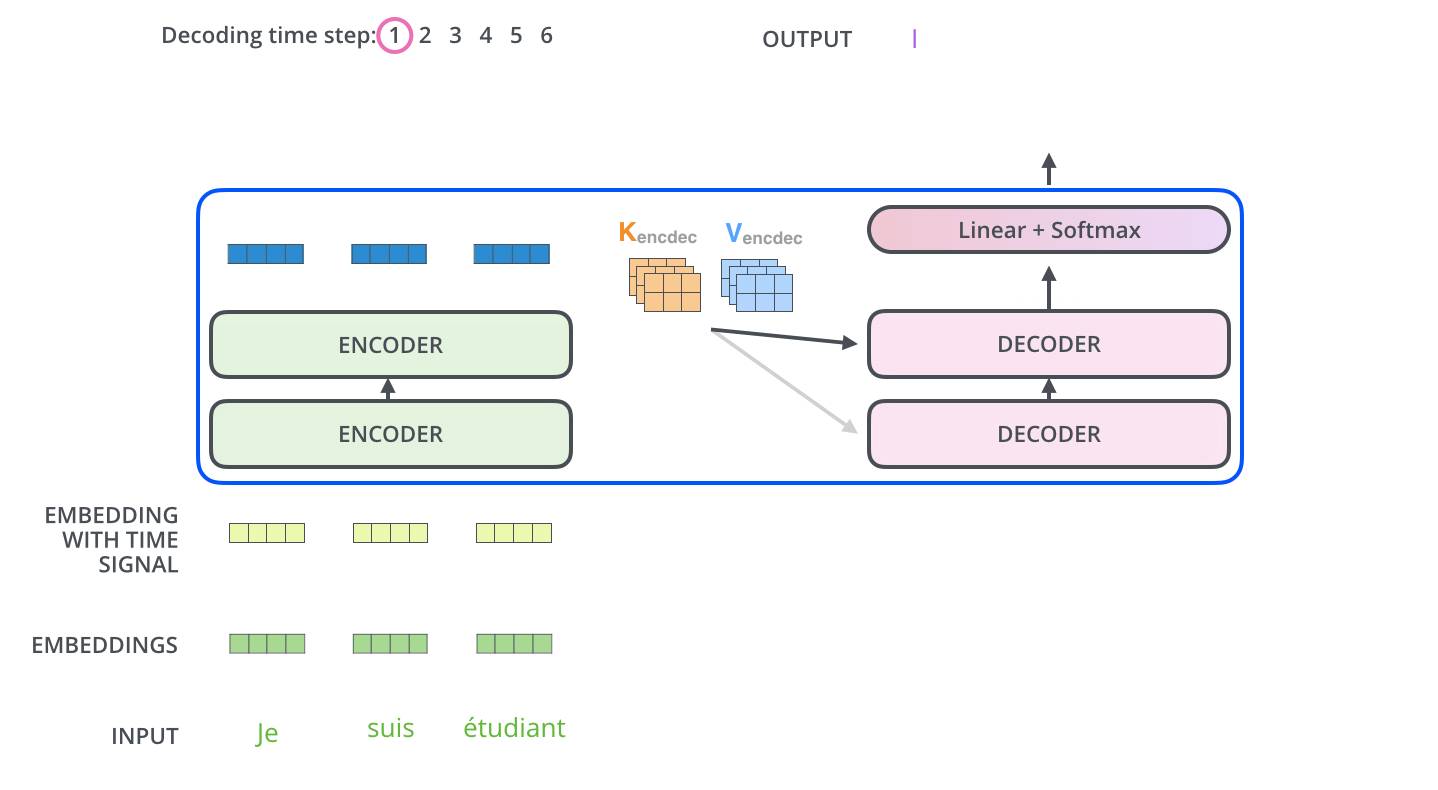
. ( – ).
, , . , , . , , , .
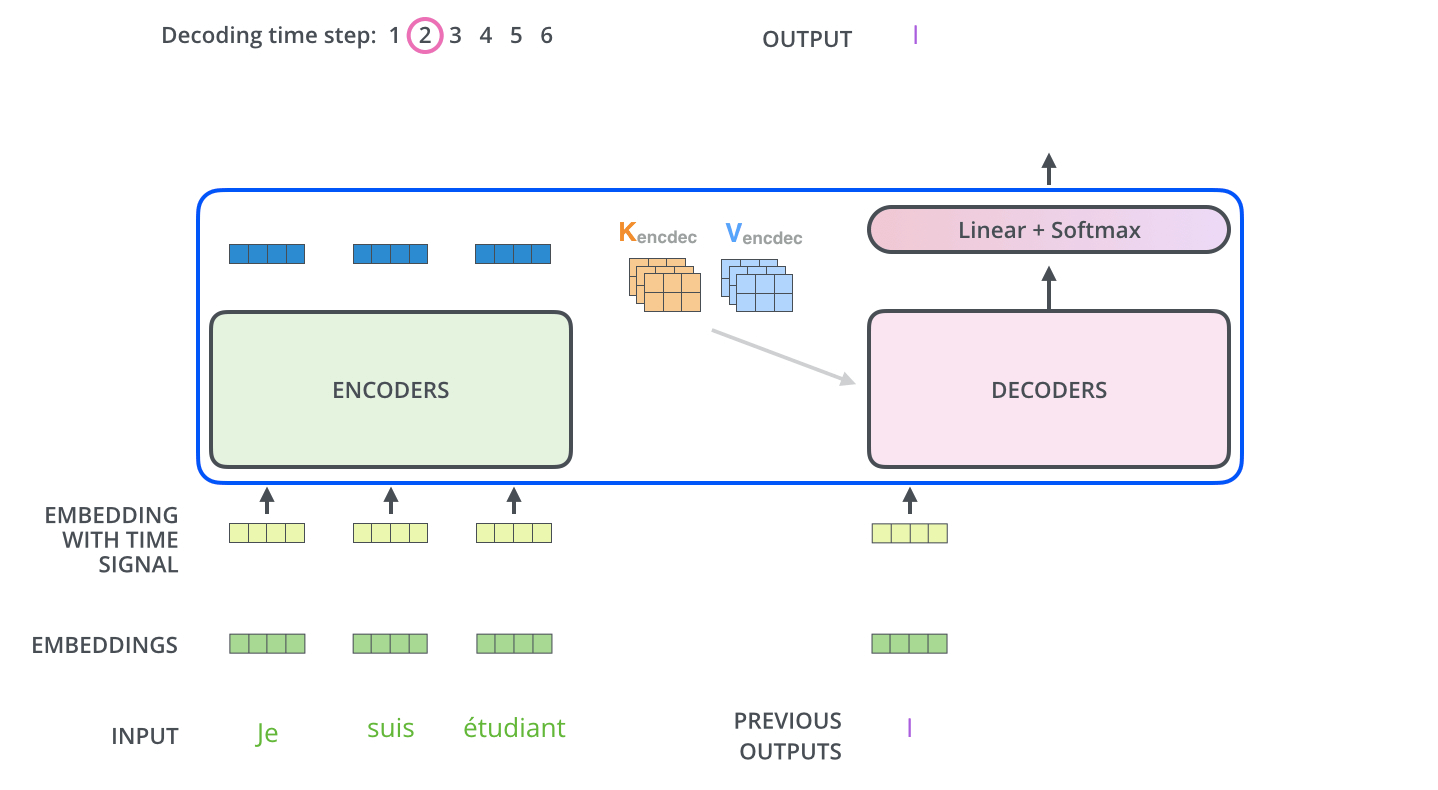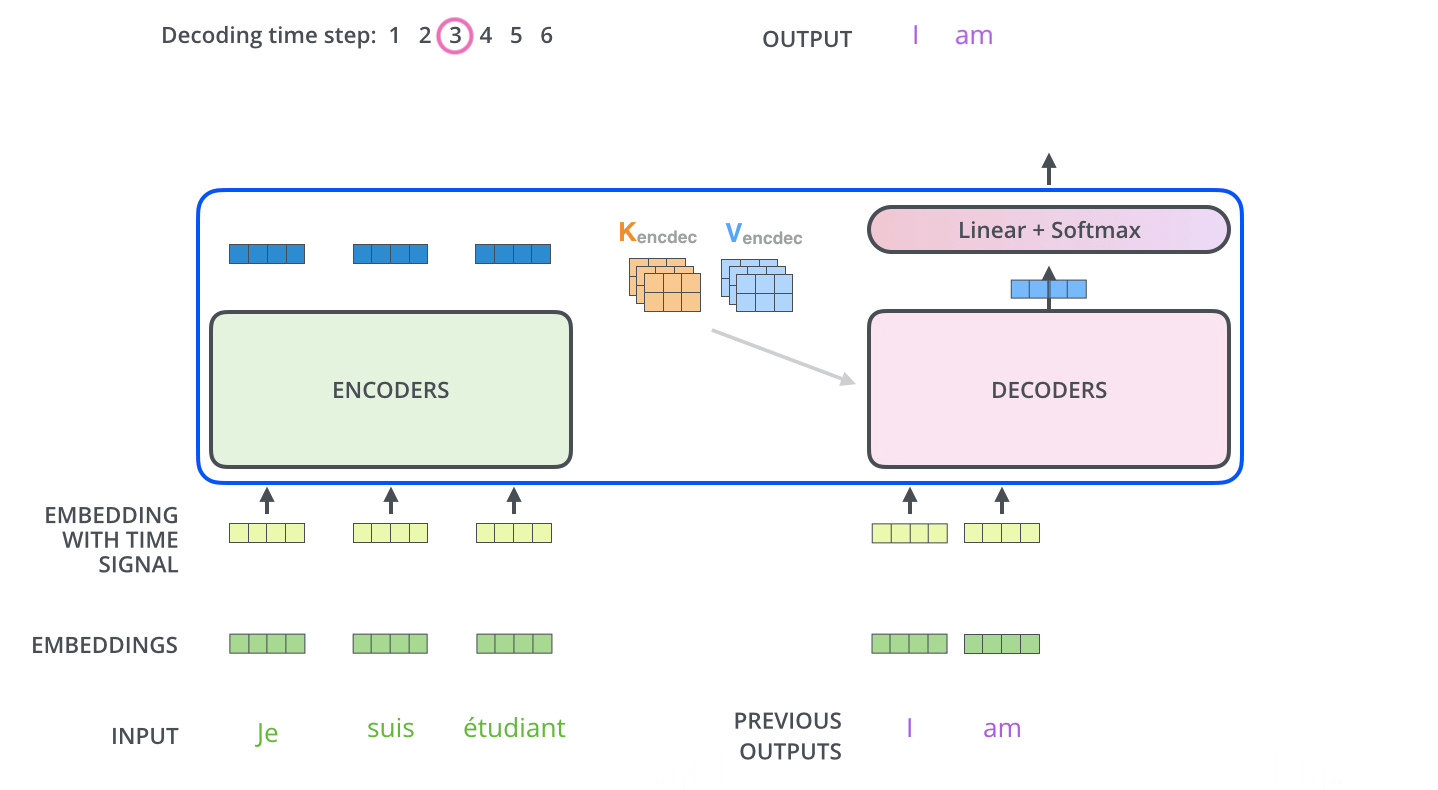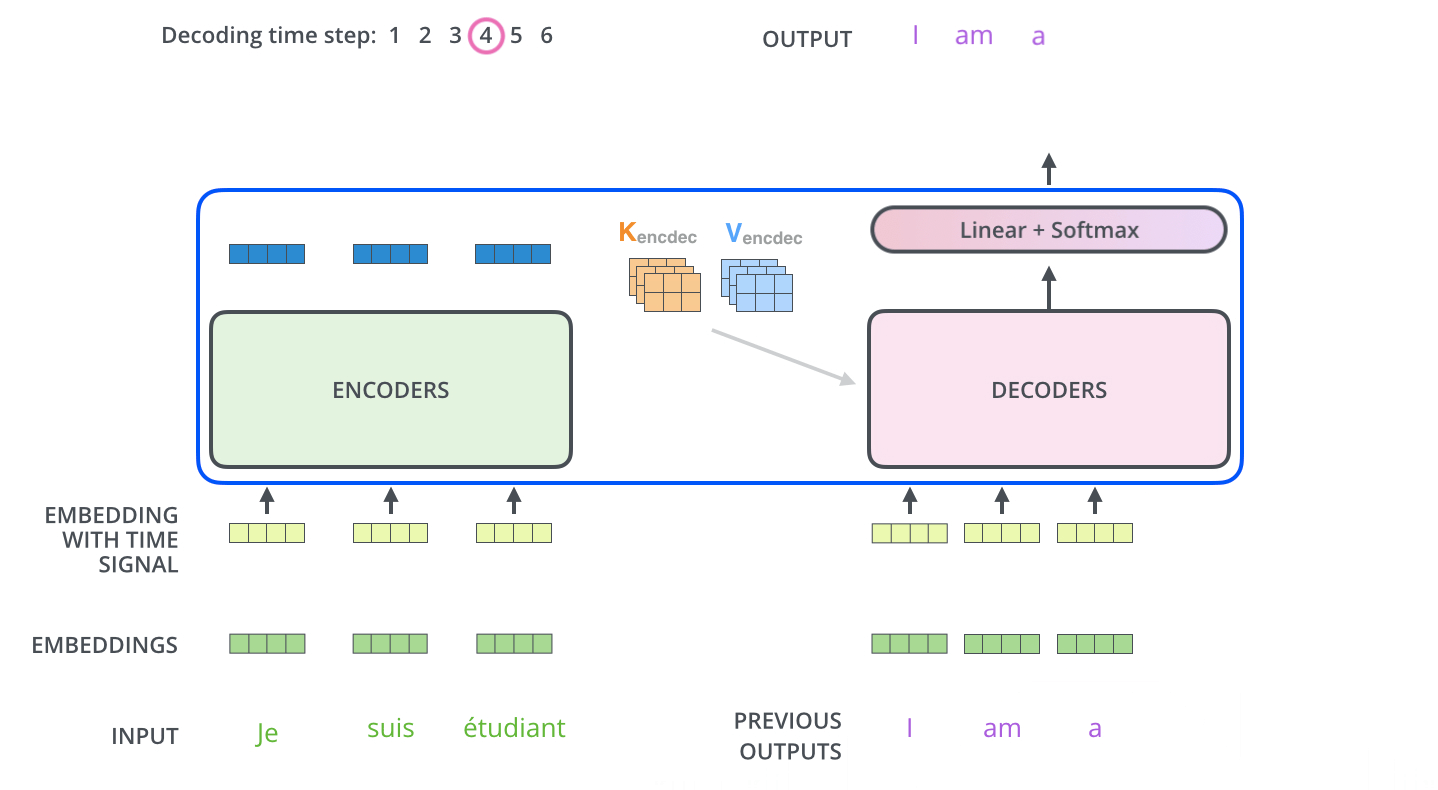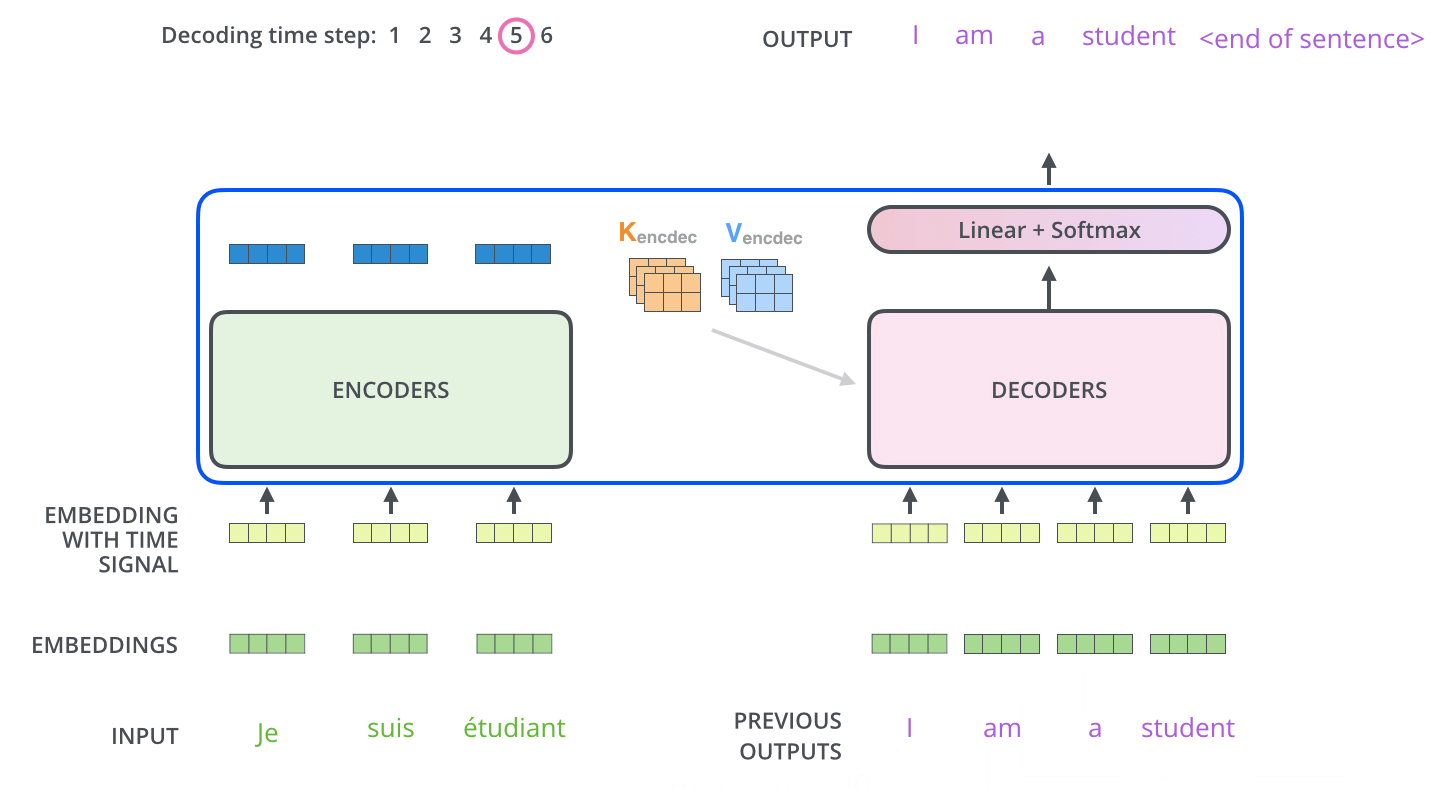
.
. ( –inf) .
«-» , , , , .
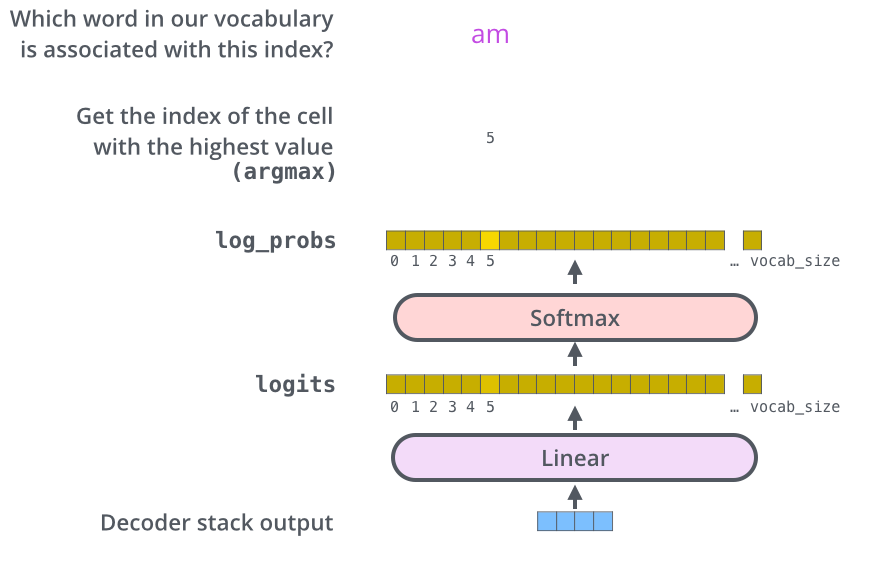
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
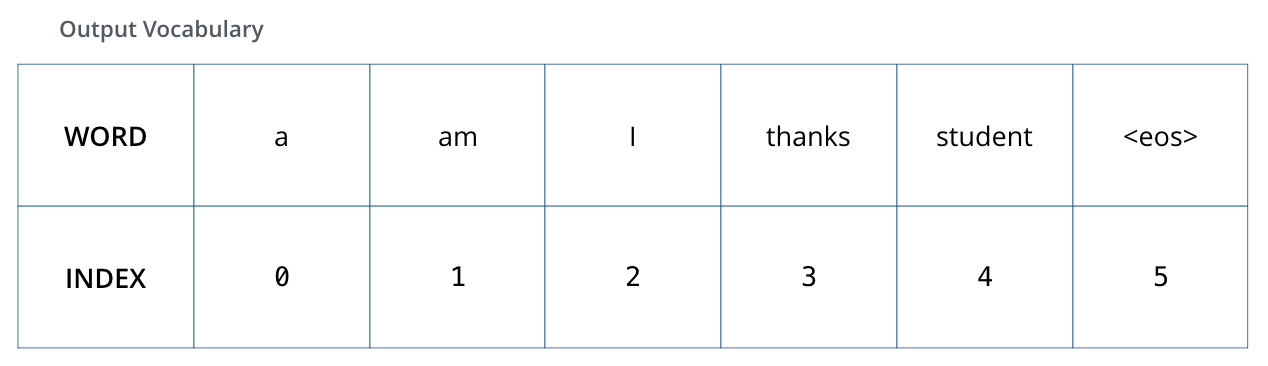
.
, (, one-hot-). , «am», :
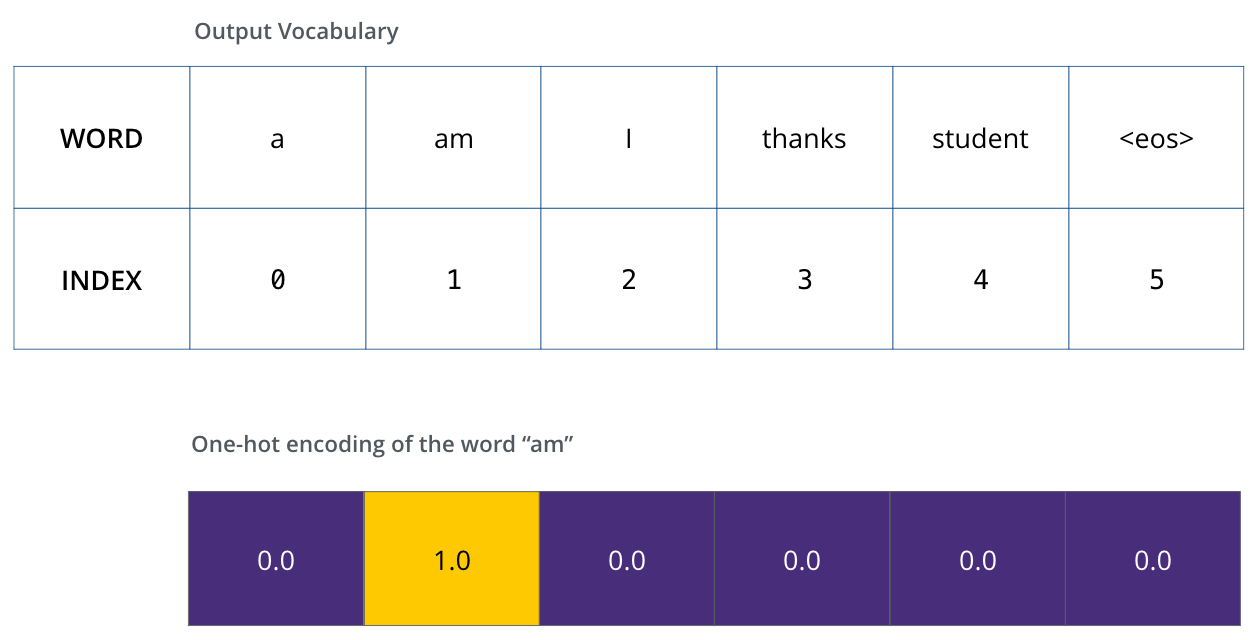
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
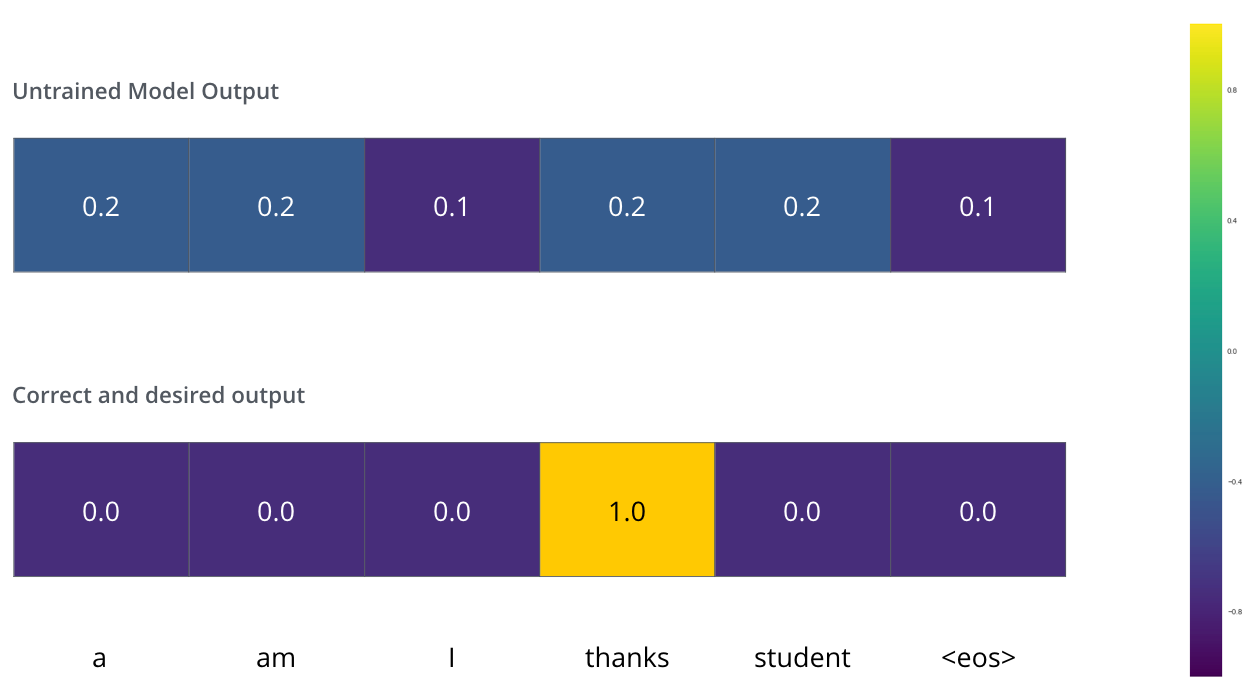
() , /. , , , .
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
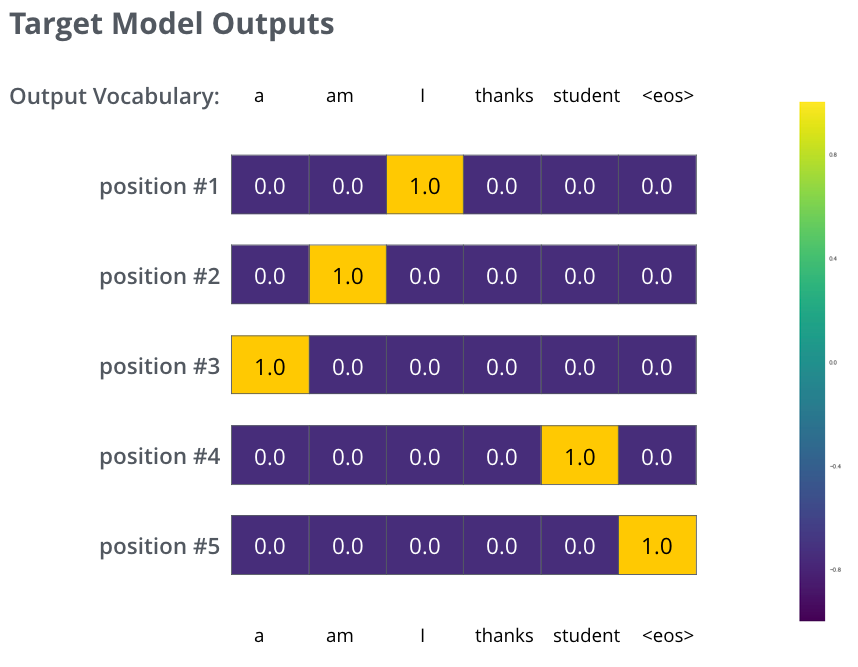
, :
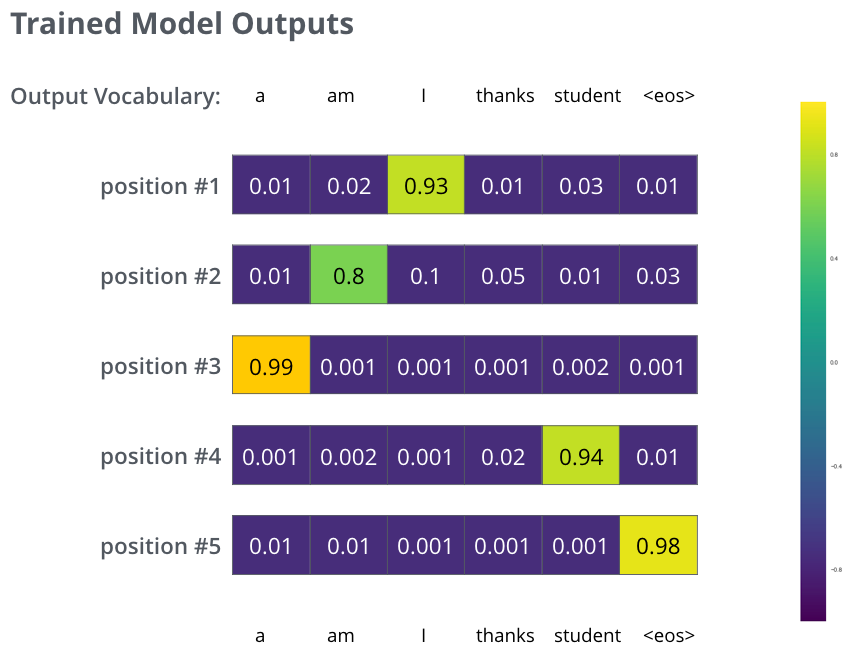
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
Penulis