Catastrophic Cloud: Bagaimana Cara Kerjanya
Halo, Habr!Setelah liburan Tahun Baru, kami memulai kembali cloud yang tahan bencana berdasarkan dua situs. Hari ini kami akan memberi tahu Anda cara kerjanya dan menunjukkan apa yang terjadi pada mesin virtual klien ketika masing-masing elemen kluster gagal dan seluruh situs jatuh (spoiler - semuanya baik-baik saja dengan mereka). Penyimpanan cloud tahan bencana di situs OST.
Penyimpanan cloud tahan bencana di situs OST.Apa yang ada di dalam
Di bawah kap cluster adalah server Cisco UCS dengan hyperware VMware ESXi, dua sistem penyimpanan INFINIDAT InfiniBox F2240, peralatan jaringan Nexus Nexus, serta sakelar Brocade SAN. Cluster ditempatkan dalam dua situs - OST dan NORD, yaitu, di setiap pusat data satu set peralatan yang identik. Sebenarnya, ini membuatnya menjadi bencana.Dalam satu platform, elemen-elemen utama juga digandakan (host, switch SAN, kartu jaringan).Dua situs dihubungkan oleh jalur serat optik khusus, juga disediakan.Beberapa kata tentang penyimpanan. Cloud tahan bencana pertama yang kami bangun di NetApp. INFINIDAT dipilih di sini, dan inilah alasannya:- Opsi replikasi aktif-aktif. Ini memungkinkan mesin virtual untuk tetap beroperasi bahkan jika salah satu sistem penyimpanan benar-benar gagal. Saya akan memberi tahu Anda lebih banyak tentang replikasi nanti.
- Tiga pengontrol disk untuk meningkatkan ketahanan sistem. Biasanya ada dua.
- Solusi siap. Rak yang sudah dirakit mendatangi kami, yang hanya perlu dihubungkan ke jaringan dan dikonfigurasi.
- Dukungan teknis yang penuh perhatian. Insinyur INFINIDAT secara konstan menganalisis log dan peristiwa sistem penyimpanan, menginstal versi baru di firmware, dan membantu dengan konfigurasi.
Berikut beberapa foto dari pembongkaran:

bagaimana cara kerjanya
Awan sudah tangguh dalam dirinya sendiri. Ini melindungi klien dari kegagalan perangkat keras dan perangkat lunak tunggal. Catastrophic akan membantu melindungi terhadap kegagalan massal dalam situs yang sama: misalnya, kegagalan sistem penyimpanan (atau gugus SDS, yang sering terjadi :)), kesalahan massal di jaringan penyimpanan, dan lainnya. Nah dan yang paling penting: awan seperti itu menyelamatkan ketika seluruh situs menjadi tidak dapat diakses karena kebakaran, pemadaman, penangkapan perampok, pendaratan alien.Dalam semua kasus ini, mesin virtual klien terus berjalan, dan inilah sebabnya.Skema cluster dirancang sedemikian rupa sehingga setiap host ESXi dengan mesin virtual klien dapat mengakses salah satu dari dua sistem penyimpanan. Jika penyimpanan di situs OST gagal, maka mesin virtual akan terus bekerja: host tempat mereka bekerja akan mengakses penyimpanan di NORD untuk data. Ini adalah bagaimana diagram koneksi di cluster terlihat.Ini dimungkinkan karena fakta bahwa Inter-Switch Link dikonfigurasikan antara pabrik-pabrik SAN dari dua situs: switch Fabric A OST SAN terhubung ke switch Fabric A NORD SAN, mirip dengan switch SAN Fabric B.Nah, agar semua seluk-beluk pabrik SAN ini masuk akal, replikasi Aktif-Aktif dikonfigurasikan antara dua sistem penyimpanan: informasi ditulis hampir bersamaan ke sistem penyimpanan lokal dan jarak jauh, RPO = 0. Ternyata pada satu SHD data asli disimpan, di sisi lain - replika mereka. Data direplikasi pada tingkat volume penyimpanan, dan data VM (disk-nya, file konfigurasi, file swap, dll.) Sudah tersimpan di dalamnya.Host ESXi melihat volume primer dan replikanya sebagai perangkat penyimpanan tunggal. Ada 24 jalur dari host ESXi ke setiap perangkat disk:12 jalur menghubungkannya dengan penyimpanan lokal (jalur optimal), dan 12 jalur lainnya - dengan remote (jalur tidak optimal). Dalam situasi normal, ESXi mengakses data pada penyimpanan lokal menggunakan jalur "optimal". Jika sistem penyimpanan ini gagal, ESXi kehilangan jalur optimalnya dan beralih ke jalur “tidak optimal”. Begini tampilannya di diagram.
Ini adalah bagaimana diagram koneksi di cluster terlihat.Ini dimungkinkan karena fakta bahwa Inter-Switch Link dikonfigurasikan antara pabrik-pabrik SAN dari dua situs: switch Fabric A OST SAN terhubung ke switch Fabric A NORD SAN, mirip dengan switch SAN Fabric B.Nah, agar semua seluk-beluk pabrik SAN ini masuk akal, replikasi Aktif-Aktif dikonfigurasikan antara dua sistem penyimpanan: informasi ditulis hampir bersamaan ke sistem penyimpanan lokal dan jarak jauh, RPO = 0. Ternyata pada satu SHD data asli disimpan, di sisi lain - replika mereka. Data direplikasi pada tingkat volume penyimpanan, dan data VM (disk-nya, file konfigurasi, file swap, dll.) Sudah tersimpan di dalamnya.Host ESXi melihat volume primer dan replikanya sebagai perangkat penyimpanan tunggal. Ada 24 jalur dari host ESXi ke setiap perangkat disk:12 jalur menghubungkannya dengan penyimpanan lokal (jalur optimal), dan 12 jalur lainnya - dengan remote (jalur tidak optimal). Dalam situasi normal, ESXi mengakses data pada penyimpanan lokal menggunakan jalur "optimal". Jika sistem penyimpanan ini gagal, ESXi kehilangan jalur optimalnya dan beralih ke jalur “tidak optimal”. Begini tampilannya di diagram. Skema gugus tahan bencana.Semua jaringan klien dibuat di kedua situs melalui pabrik jaringan yang sama. Provider Edge (PE) berjalan di setiap situs, di mana jaringan klien diakhiri. PEs digabungkan menjadi satu cluster. Jika PE gagal di satu situs, semua lalu lintas dialihkan ke situs kedua. Berkat ini, mesin virtual dari situs tanpa PE tetap tersedia melalui jaringan untuk klien.Mari kita lihat apa yang akan terjadi pada mesin virtual klien jika terjadi berbagai kegagalan. Mari kita mulai dengan opsi paling ringan dan akhiri dengan yang paling serius - kegagalan seluruh situs. Dalam contoh, situs utama adalah OST, dan cadangan, dengan replika data, adalah NORD.
Skema gugus tahan bencana.Semua jaringan klien dibuat di kedua situs melalui pabrik jaringan yang sama. Provider Edge (PE) berjalan di setiap situs, di mana jaringan klien diakhiri. PEs digabungkan menjadi satu cluster. Jika PE gagal di satu situs, semua lalu lintas dialihkan ke situs kedua. Berkat ini, mesin virtual dari situs tanpa PE tetap tersedia melalui jaringan untuk klien.Mari kita lihat apa yang akan terjadi pada mesin virtual klien jika terjadi berbagai kegagalan. Mari kita mulai dengan opsi paling ringan dan akhiri dengan yang paling serius - kegagalan seluruh situs. Dalam contoh, situs utama adalah OST, dan cadangan, dengan replika data, adalah NORD.Apa yang terjadi pada mesin virtual klien jika ...
Gagal Tautan Replikasi. Replikasi antara sistem penyimpanan dua situs berhenti.ESXi hanya akan bekerja dengan perangkat disk lokal (di sepanjang jalur optimal).Mesin virtual terus bekerja. Ada celah ISL (Inter-Switch Link). Kasusnya tidak mungkin. Kecuali beberapa ekskavator gila menggali beberapa rute optik sekaligus, yang melewati rute independen dan dibawa ke lokasi melalui input yang berbeda. Tapi bagaimanapun juga. Dalam hal ini, host ESXi kehilangan setengah dari jalurnya dan hanya dapat mengakses penyimpanan lokal mereka. Replika dikumpulkan, tetapi tuan rumah tidak akan dapat mengaksesnya.Mesin virtual bekerja secara normal.
Ada celah ISL (Inter-Switch Link). Kasusnya tidak mungkin. Kecuali beberapa ekskavator gila menggali beberapa rute optik sekaligus, yang melewati rute independen dan dibawa ke lokasi melalui input yang berbeda. Tapi bagaimanapun juga. Dalam hal ini, host ESXi kehilangan setengah dari jalurnya dan hanya dapat mengakses penyimpanan lokal mereka. Replika dikumpulkan, tetapi tuan rumah tidak akan dapat mengaksesnya.Mesin virtual bekerja secara normal. Menolak sakelar SAN di salah satu situs.Host ESXi kehilangan beberapa jalur penyimpanannya. Dalam hal ini, host di situs tempat sakelar gagal hanya akan bekerja melalui HBA mereka sendiri.Pada saat yang sama, mesin virtual terus bekerja secara normal.
Menolak sakelar SAN di salah satu situs.Host ESXi kehilangan beberapa jalur penyimpanannya. Dalam hal ini, host di situs tempat sakelar gagal hanya akan bekerja melalui HBA mereka sendiri.Pada saat yang sama, mesin virtual terus bekerja secara normal. Semua SAN beralih pada salah satu situs gagal. Katakanlah bencana seperti itu terjadi di situs OST. Dalam hal ini, host ESXi di situs ini akan kehilangan semua jalur ke perangkat disk mereka. Mekanisme VMware vSphere HA standar mulai digunakan: mekanisme ini akan memulai kembali semua mesin virtual platform OST di NORD setelah maksimal 140 detik.Mesin virtual yang berjalan di host situs NORD bekerja secara normal.
Semua SAN beralih pada salah satu situs gagal. Katakanlah bencana seperti itu terjadi di situs OST. Dalam hal ini, host ESXi di situs ini akan kehilangan semua jalur ke perangkat disk mereka. Mekanisme VMware vSphere HA standar mulai digunakan: mekanisme ini akan memulai kembali semua mesin virtual platform OST di NORD setelah maksimal 140 detik.Mesin virtual yang berjalan di host situs NORD bekerja secara normal.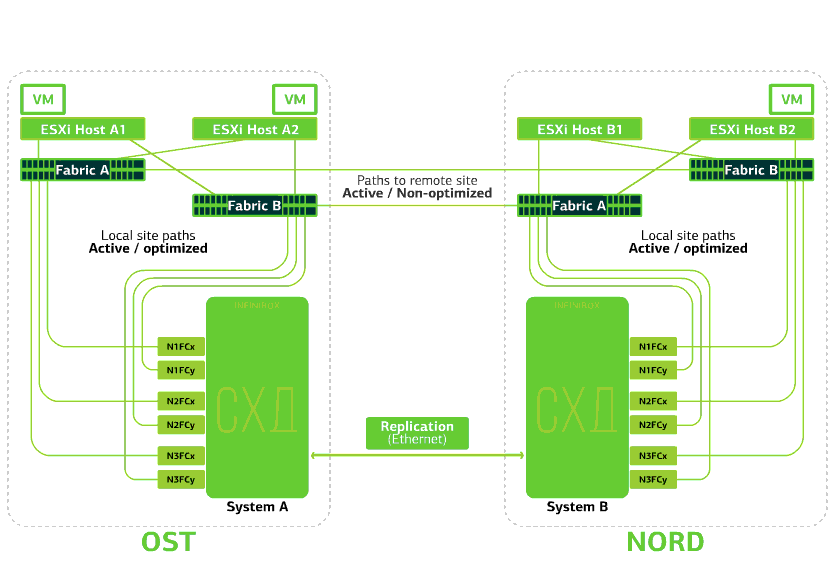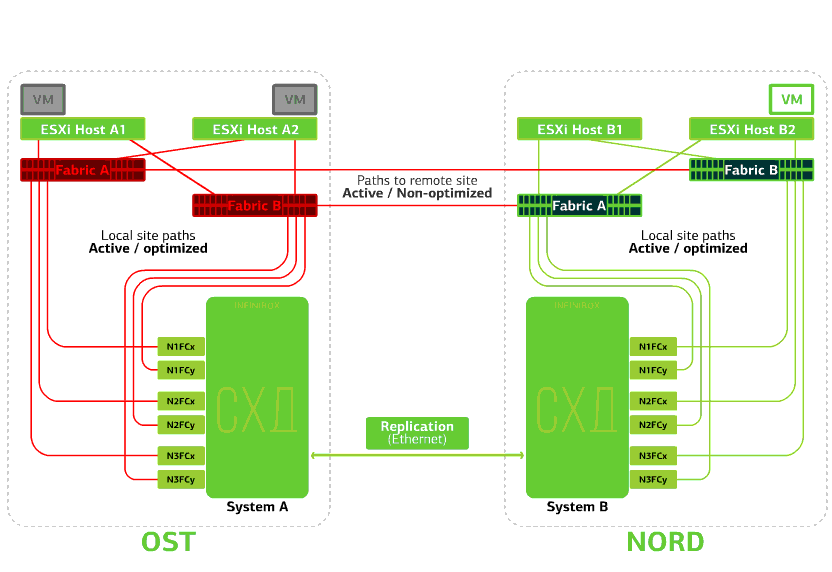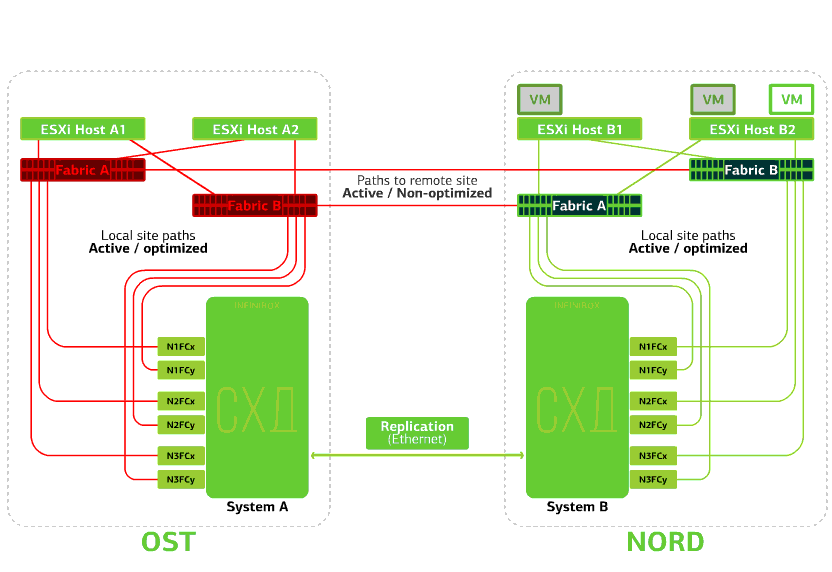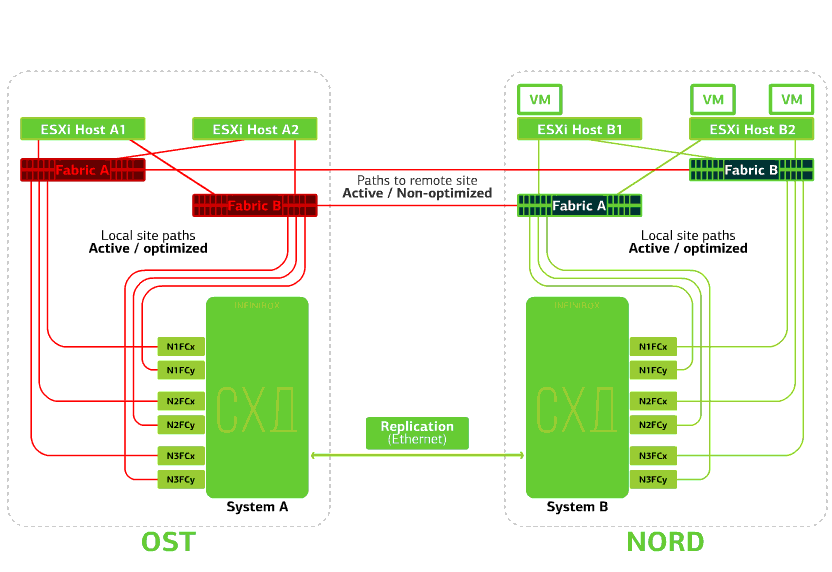 Menolak host ESXi di satu situs.Di sini mekanisme HA vSphere berfungsi lagi: mesin virtual dari host yang gagal dihidupkan ulang pada host lain - di situs yang sama atau jauh. Waktu restart mesin virtual hingga 1 menit.Jika semua host ESXi dari platform OST gagal, tidak ada opsi: VM restart pada yang lain. Waktu restart adalah sama.
Menolak host ESXi di satu situs.Di sini mekanisme HA vSphere berfungsi lagi: mesin virtual dari host yang gagal dihidupkan ulang pada host lain - di situs yang sama atau jauh. Waktu restart mesin virtual hingga 1 menit.Jika semua host ESXi dari platform OST gagal, tidak ada opsi: VM restart pada yang lain. Waktu restart adalah sama.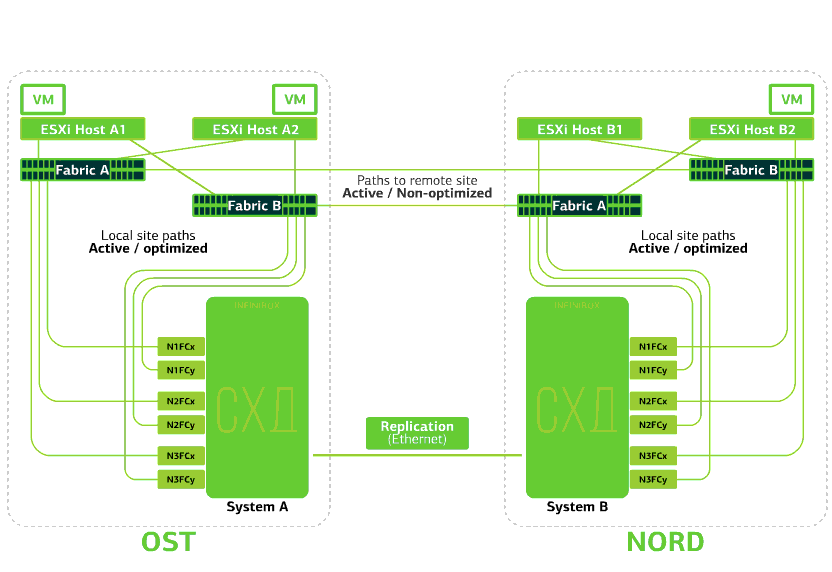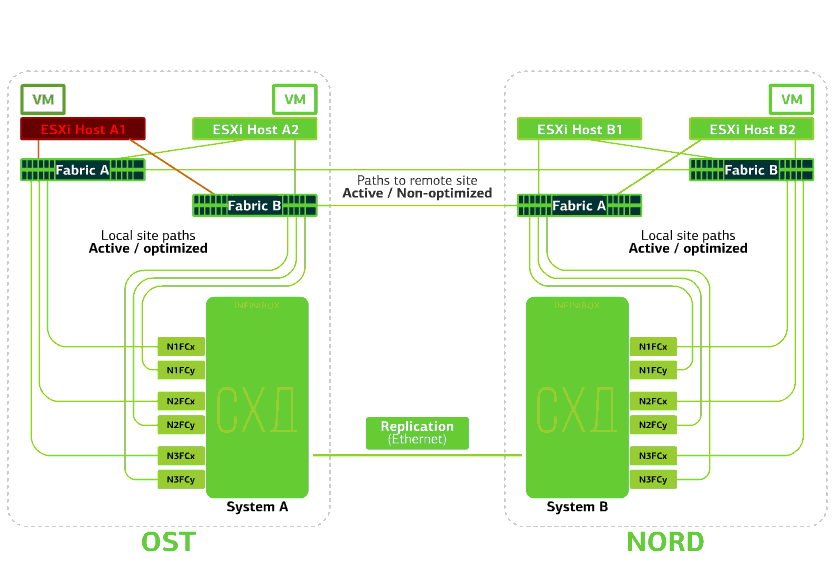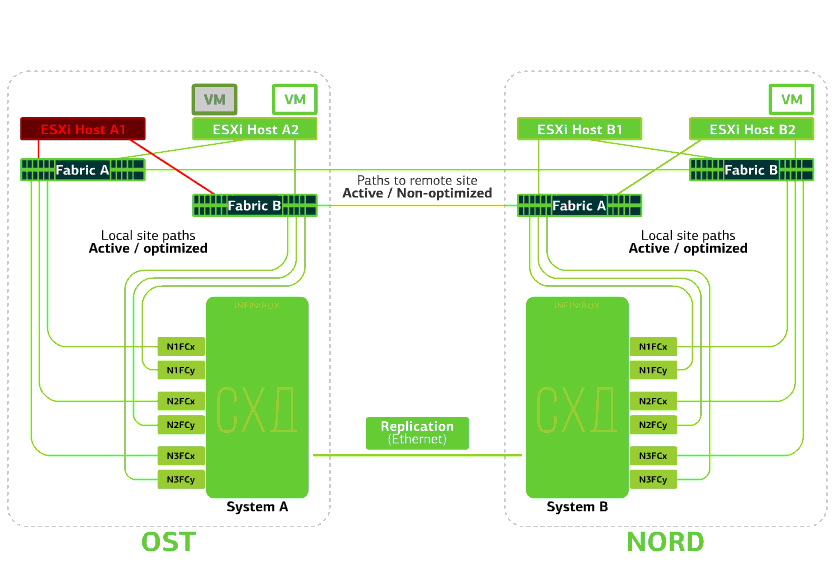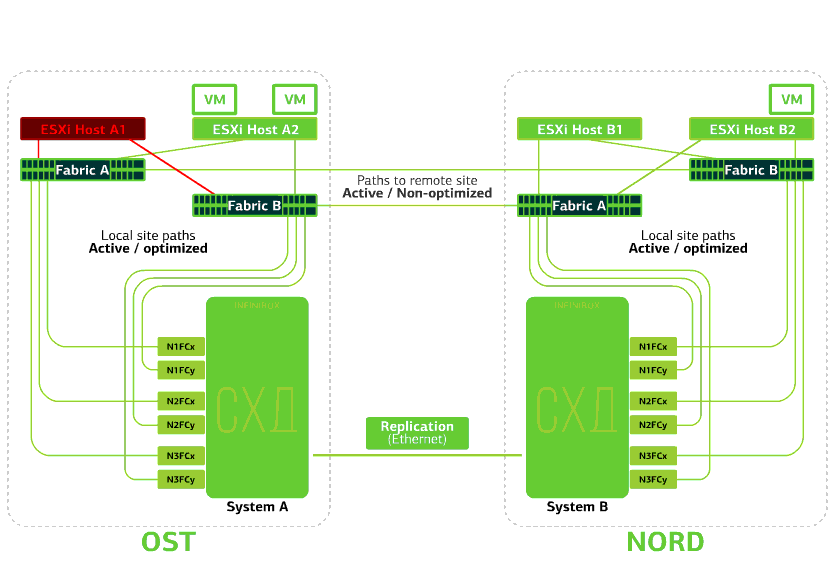 Menolak penyimpanan di situs yang sama. Katakanlah sistem penyimpanan ditolak di situs OST. Kemudian host OST ESXi beralih untuk bekerja dengan replika penyimpanan di NORD. Setelah sistem penyimpanan yang gagal kembali ke sistem, replikasi paksa terjadi, host OST ESXi akan kembali menghubungi sistem penyimpanan lokal.Mesin virtual telah bekerja selama ini.
Menolak penyimpanan di situs yang sama. Katakanlah sistem penyimpanan ditolak di situs OST. Kemudian host OST ESXi beralih untuk bekerja dengan replika penyimpanan di NORD. Setelah sistem penyimpanan yang gagal kembali ke sistem, replikasi paksa terjadi, host OST ESXi akan kembali menghubungi sistem penyimpanan lokal.Mesin virtual telah bekerja selama ini. Gagal salah satu situs.Dalam hal ini, semua mesin virtual akan memulai kembali di situs cadangan melalui mekanisme HA vSphere. Waktu mulai ulang VM - 140 detik. Dalam hal ini, semua pengaturan jaringan mesin virtual akan disimpan, dan itu tetap tersedia untuk klien melalui jaringan.Untuk me-restart mesin di situs cadangan tanpa masalah, setiap situs hanya setengah penuh. Bagian kedua adalah cadangan jika semua mesin virtual dipindahkan dari situs kedua yang terluka.
Gagal salah satu situs.Dalam hal ini, semua mesin virtual akan memulai kembali di situs cadangan melalui mekanisme HA vSphere. Waktu mulai ulang VM - 140 detik. Dalam hal ini, semua pengaturan jaringan mesin virtual akan disimpan, dan itu tetap tersedia untuk klien melalui jaringan.Untuk me-restart mesin di situs cadangan tanpa masalah, setiap situs hanya setengah penuh. Bagian kedua adalah cadangan jika semua mesin virtual dipindahkan dari situs kedua yang terluka.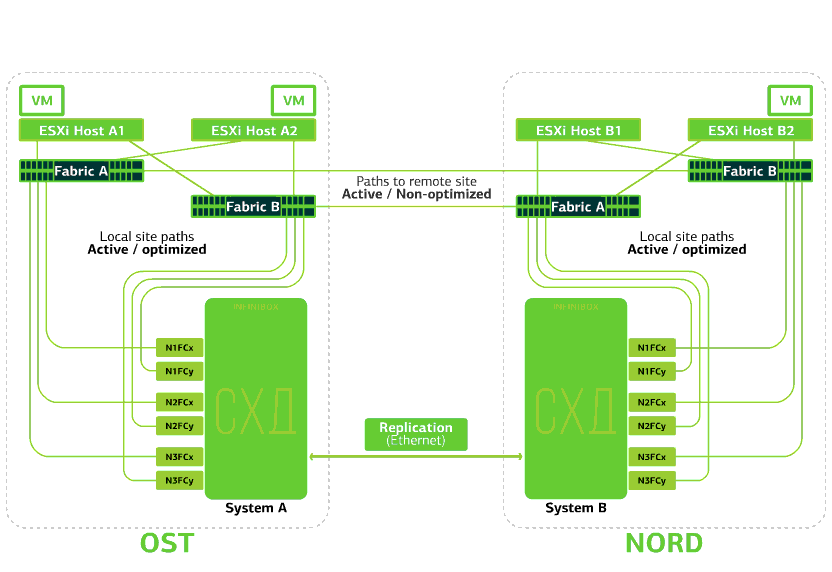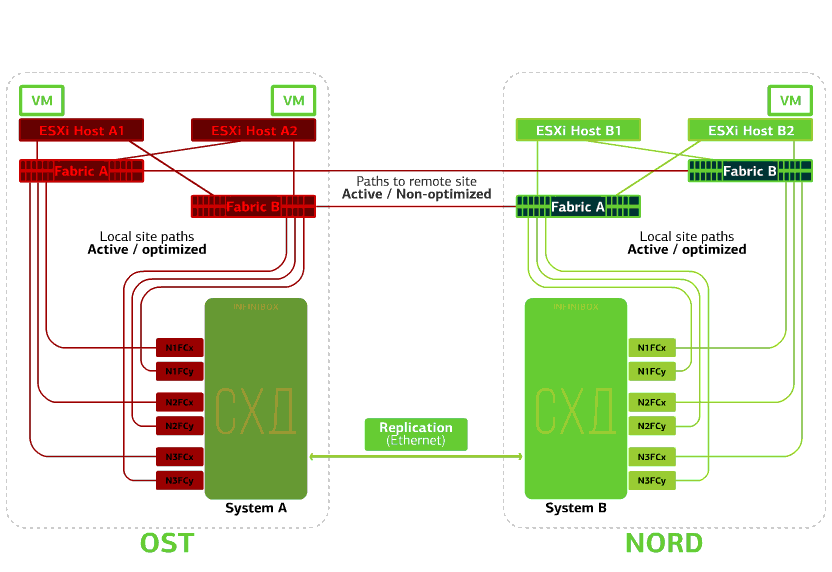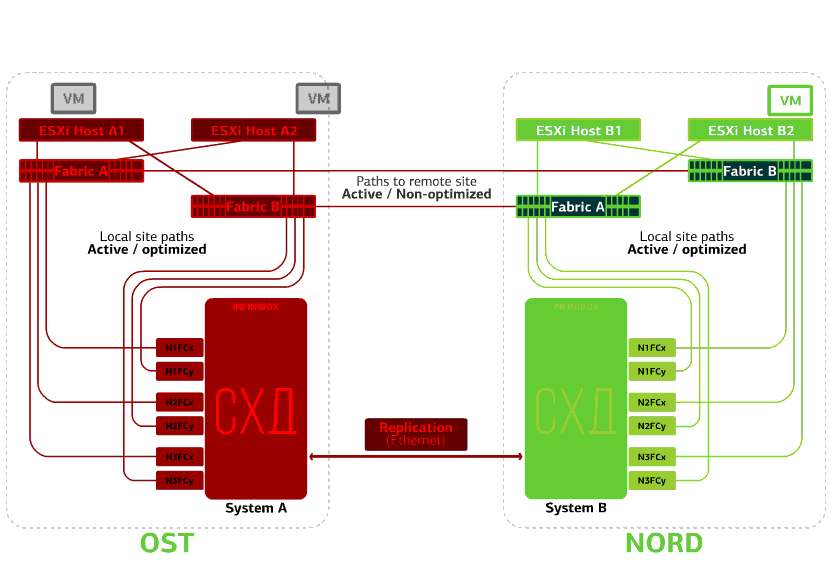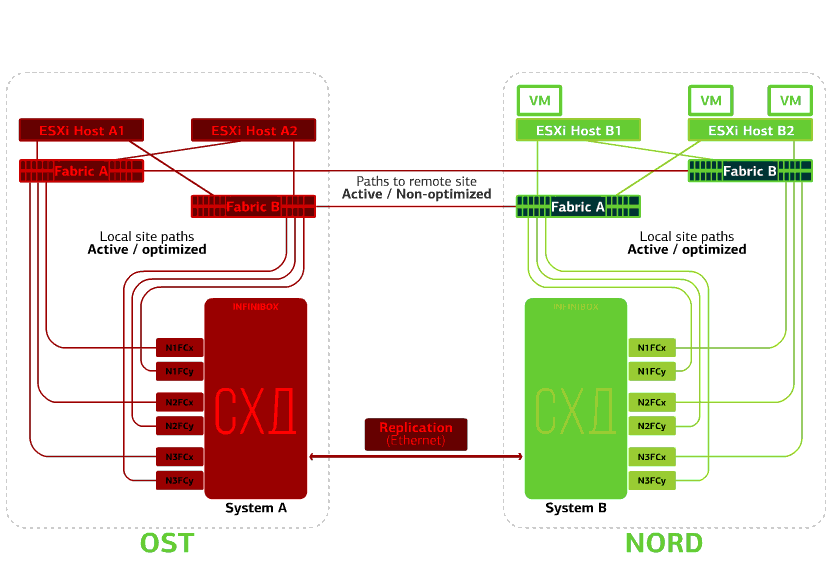 Awan tahan bencana berdasarkan dua pusat data melindungi dari kegagalan tersebut.Kesenangan ini tidak murah, karena, selain sumber daya utama, Anda memerlukan cadangan di situs kedua. Oleh karena itu, mereka menempatkan layanan yang penting bagi bisnis dalam awan seperti itu, downtime panjang yang menimbulkan kerugian finansial dan reputasi yang besar, atau jika persyaratan toleransi bencana dibebankan pada sistem informasi dari regulator atau peraturan internal perusahaan.Sumber:
Awan tahan bencana berdasarkan dua pusat data melindungi dari kegagalan tersebut.Kesenangan ini tidak murah, karena, selain sumber daya utama, Anda memerlukan cadangan di situs kedua. Oleh karena itu, mereka menempatkan layanan yang penting bagi bisnis dalam awan seperti itu, downtime panjang yang menimbulkan kerugian finansial dan reputasi yang besar, atau jika persyaratan toleransi bencana dibebankan pada sistem informasi dari regulator atau peraturan internal perusahaan.Sumber:- www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
- support.infinidat.com/hc/en-us/articles/207057109-InfiniBox-best-practices-guides
Source: https://habr.com/ru/post/undefined/
All Articles