NiFi अधिक से अधिक लोकप्रियता प्राप्त कर रहा है और हर नई रिलीज़ के साथ इसे डेटा के साथ काम करने के लिए अधिक से अधिक उपकरण मिलते हैं। फिर भी, किसी विशेष समस्या को हल करने के लिए आपका अपना उपकरण होना आवश्यक हो सकता है। Apache Nifi के बेस पैकेज में 300 से अधिक प्रोसेसर हैं। Nifi प्रोसेसर यह NiFi इकोसिस्टम में डेटाफ्लो बनाने के लिए मुख्य बिल्डिंग ब्लॉक है। प्रोसेसर एक इंटरफ़ेस प्रदान करते हैं, जिसके माध्यम से NiFi फ्लोफाइल, इसकी विशेषताओं और सामग्री तक पहुंच प्रदान करता है। स्वयं के कस्टम प्रोसेसर बिजली, समय और उपयोगकर्ता का ध्यान बचाएंगे, क्योंकि कई सरल प्रोसेसर तत्वों के बजाय, इंटरफ़ेस में केवल एक प्रदर्शित किया जाएगा और केवल एक को निष्पादित किया जाएगा (अच्छी तरह से, या आप कितना लिखते हैं)। मानक प्रोसेसर की तरह, एक कस्टम प्रोसेसर आपको विभिन्न संचालन करने और एक प्रवाह की सामग्री को संसाधित करने की अनुमति देता है। आज हम कार्यक्षमता के विस्तार के लिए मानक उपकरणों के बारे में बात करेंगे।
यह NiFi इकोसिस्टम में डेटाफ्लो बनाने के लिए मुख्य बिल्डिंग ब्लॉक है। प्रोसेसर एक इंटरफ़ेस प्रदान करते हैं, जिसके माध्यम से NiFi फ्लोफाइल, इसकी विशेषताओं और सामग्री तक पहुंच प्रदान करता है। स्वयं के कस्टम प्रोसेसर बिजली, समय और उपयोगकर्ता का ध्यान बचाएंगे, क्योंकि कई सरल प्रोसेसर तत्वों के बजाय, इंटरफ़ेस में केवल एक प्रदर्शित किया जाएगा और केवल एक को निष्पादित किया जाएगा (अच्छी तरह से, या आप कितना लिखते हैं)। मानक प्रोसेसर की तरह, एक कस्टम प्रोसेसर आपको विभिन्न संचालन करने और एक प्रवाह की सामग्री को संसाधित करने की अनुमति देता है। आज हम कार्यक्षमता के विस्तार के लिए मानक उपकरणों के बारे में बात करेंगे।ExecuteScript
ExecuteScript एक सार्वभौमिक प्रोसेसर है जिसे एक प्रोग्रामिंग भाषा (Groovy, Jython, Javascript, JRuby) में व्यावसायिक तर्क को लागू करने के लिए डिज़ाइन किया गया है। यह दृष्टिकोण आपको वांछित कार्यक्षमता प्राप्त करने की अनुमति देता है। एक स्क्रिप्ट में NiFi घटकों तक पहुंच प्रदान करने के लिए, निम्न चर का उपयोग करना संभव है:सत्र : प्रकार का एक प्रकार। org.apache.nifi.processor.ProcessSession। चर आपको फ्लोफाइल के साथ संचालन करने की अनुमति देता है, जैसे कि क्रिएट (), putAttribute () और ट्रांसफर (), साथ ही पढ़ा () और लिखना ()।प्रसंग : org.apache.nifi.processor.ProcessContext इसका उपयोग प्रोसेसर के गुण, संबंध, नियंत्रक सेवाओं और StateManager को प्राप्त करने के लिए किया जा सकता है।REL_SUCCESS : संबंध "सफलता"।REL_FAILURE : विफलता संबंधडायनेमिक गुण : ExecuteScript में परिभाषित डायनेमिक गुण स्क्रिप्ट इंजन के लिए वैरिएबल के रूप में दिए जाते हैं, एक PropertyValue के रूप में सेट किए जाते हैं। यह आपको संपत्ति का मूल्य प्राप्त करने की अनुमति देता है, मूल्य को उपयुक्त डेटा प्रकार में परिवर्तित करता है, उदाहरण के लिए, तार्किक, आदि। उपयोग के लिए, बस हमारी स्क्रिप्ट या स्क्रिप्ट के साथ Script Engineफ़ाइल का स्थान चुनें और निर्दिष्ट करें । आइए कुछ उदाहरणों को देखें: कतार से एक स्ट्रीम फ़ाइल प्राप्त करेंScript File Script Body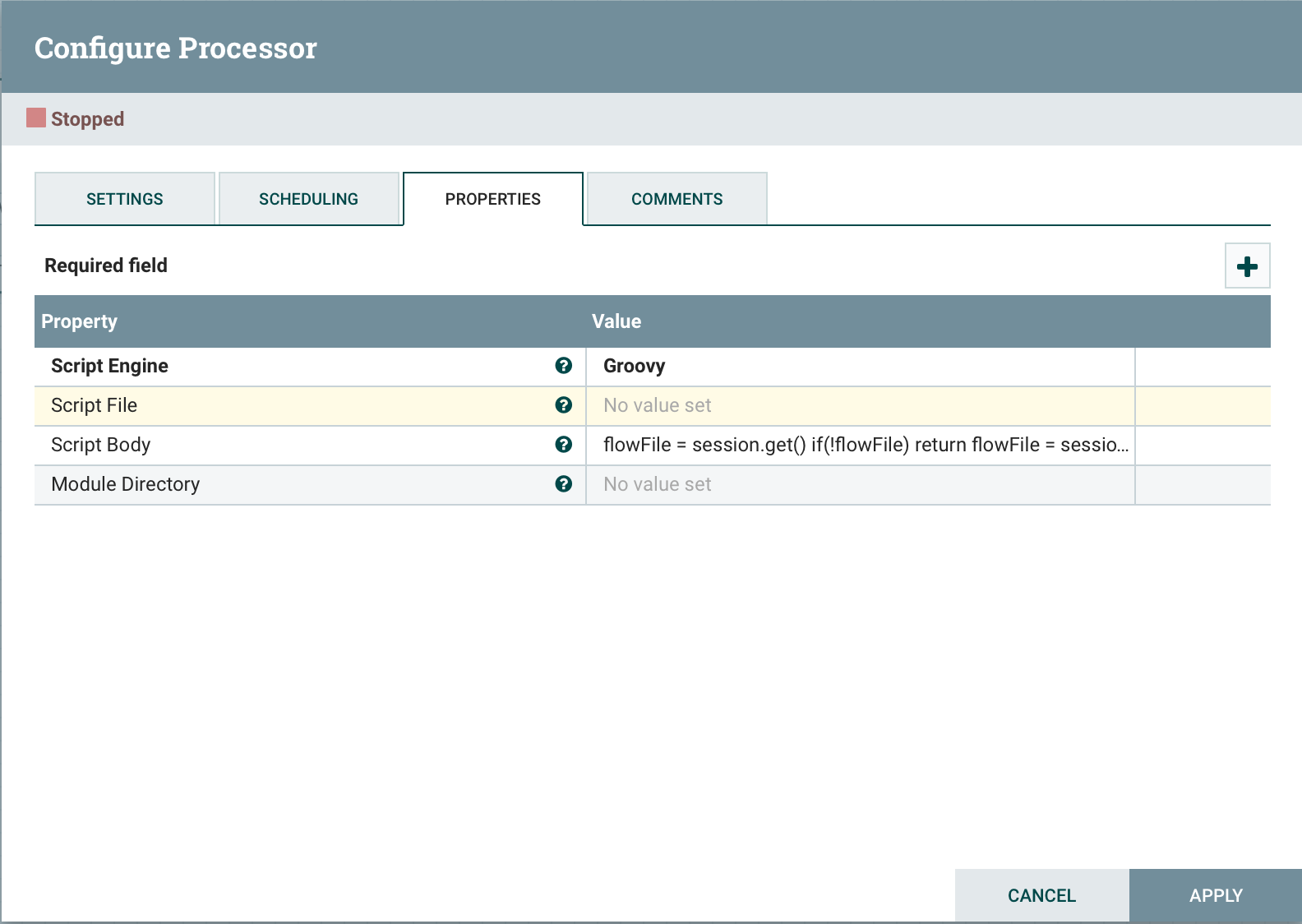
flowFile = session.get()
if(!flowFile) return
एक नया FlowFile जनरेट करेंflowFile = session.create()
// Additional processing here
फ़्लोफ़ाइल में विशेषता जोड़ेंflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
सभी विशेषताओं को निकालें और संसाधित करें।flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
लकड़हाराlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
आप ExecuteScript में उन्नत सुविधाओं का उपयोग कर सकते हैं, इसके बारे में अधिक लेख ExecuteScript Cookbook में पाया जा सकता है।ExecuteGroovyScript
ExecuteGroovyScript में ExecuteScript के समान कार्यक्षमता है, लेकिन मान्य भाषाओं के चिड़ियाघर के बजाय, आप केवल एक का उपयोग कर सकते हैं - groovy। इस प्रोसेसर का मुख्य लाभ सेवा सेवाओं का अधिक सुविधाजनक उपयोग है। चर सत्र, संदर्भ, आदि के मानक सेट के अलावा। आप CTL और SQL उपसर्ग के साथ गतिशील गुणों को परिभाषित कर सकते हैं। संस्करण 1.11 से शुरू होकर, RecordReader और Record Writer का समर्थन दिखाई दिया। सभी संपत्तियाँ हैशपॉप हैं, जो कुंजी के रूप में "सेवा नाम" का उपयोग करती हैं, और संपत्ति के आधार पर मूल्य एक विशिष्ट वस्तु है:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
यह जानकारी पहले से ही जीवन को आसान बनाती है। हम स्रोतों में देख सकते हैं या किसी विशेष वर्ग के लिए प्रलेखन पा सकते हैं।डेटाबेस के साथ कार्य करनायदि हम SQL.DB संपत्ति को परिभाषित करते हैं और DBCPService को बांधते हैं, तो हम कोड से संपत्ति तक पहुंचेंगे। SQL.DB.rows('select * from table') प्रोसेसर स्वचालित रूप से निष्पादन से पहले dbcp सेवा से एक कनेक्शन स्वीकार करता है और लेनदेन की प्रक्रिया करता है। डेटाबेस ट्रांजेक्शंस स्वचालित रूप से वापस आ जाते हैं जब कोई त्रुटि होती है और सफल होने पर प्रतिबद्ध होती है। ExecuteGroovyScript में, आप उचित स्थिर विधियों को लागू करके घटनाओं को शुरू और रोक सकते हैं।
प्रोसेसर स्वचालित रूप से निष्पादन से पहले dbcp सेवा से एक कनेक्शन स्वीकार करता है और लेनदेन की प्रक्रिया करता है। डेटाबेस ट्रांजेक्शंस स्वचालित रूप से वापस आ जाते हैं जब कोई त्रुटि होती है और सफल होने पर प्रतिबद्ध होती है। ExecuteGroovyScript में, आप उचित स्थिर विधियों को लागू करके घटनाओं को शुरू और रोक सकते हैं।import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
एक और दिलचस्प प्रोसेसर। इसका उपयोग करने के लिए, आपको एक वर्ग की घोषणा करने की आवश्यकता है जो लागू करता है इंटरफ़ेस लागू करता है और एक प्रोसेसर चर को परिभाषित करता है। आप किसी भी PropertyDescriptor या रिलेशनशिप को परिभाषित कर सकते हैं, पैरेंट कंपोनेंटलॉग को भी एक्सेस कर सकते हैं और void onScheduled (ProcessContext संदर्भ) और शून्य ऑनस्टॉप (ProcessContext संदर्भ) विधियों को परिभाषित कर सकते हैं। इन तरीकों को तब बुलाया जाएगा जब NiFi (onScheduled) में कोई शेड्यूल किया गया इवेंट शुरू होता है और जब यह बंद हो जाता है (onScheduled)।class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
तर्क को विधि में लागू किया जाना चाहिए void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
इंटरफ़ेस में घोषित सभी तरीकों का वर्णन करना अनावश्यक है, तो चलो एक सार वर्ग मिलता है जिसमें हम निम्नलिखित विधि की घोषणा करते हैं:abstract void executeScript(ProcessContext context, ProcessSession session)
जिस विधि में हम बुलाएंगेvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
अब हम एक उत्तराधिकारी वर्ग की घोषणा करते हैं BaseGroovyProcessorऔर हमारे निष्पादनों का वर्णन करते हैं, हम रिलेशनशिप रैलसक्युस और रिलेटिव को भी जोड़ते हैं।import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
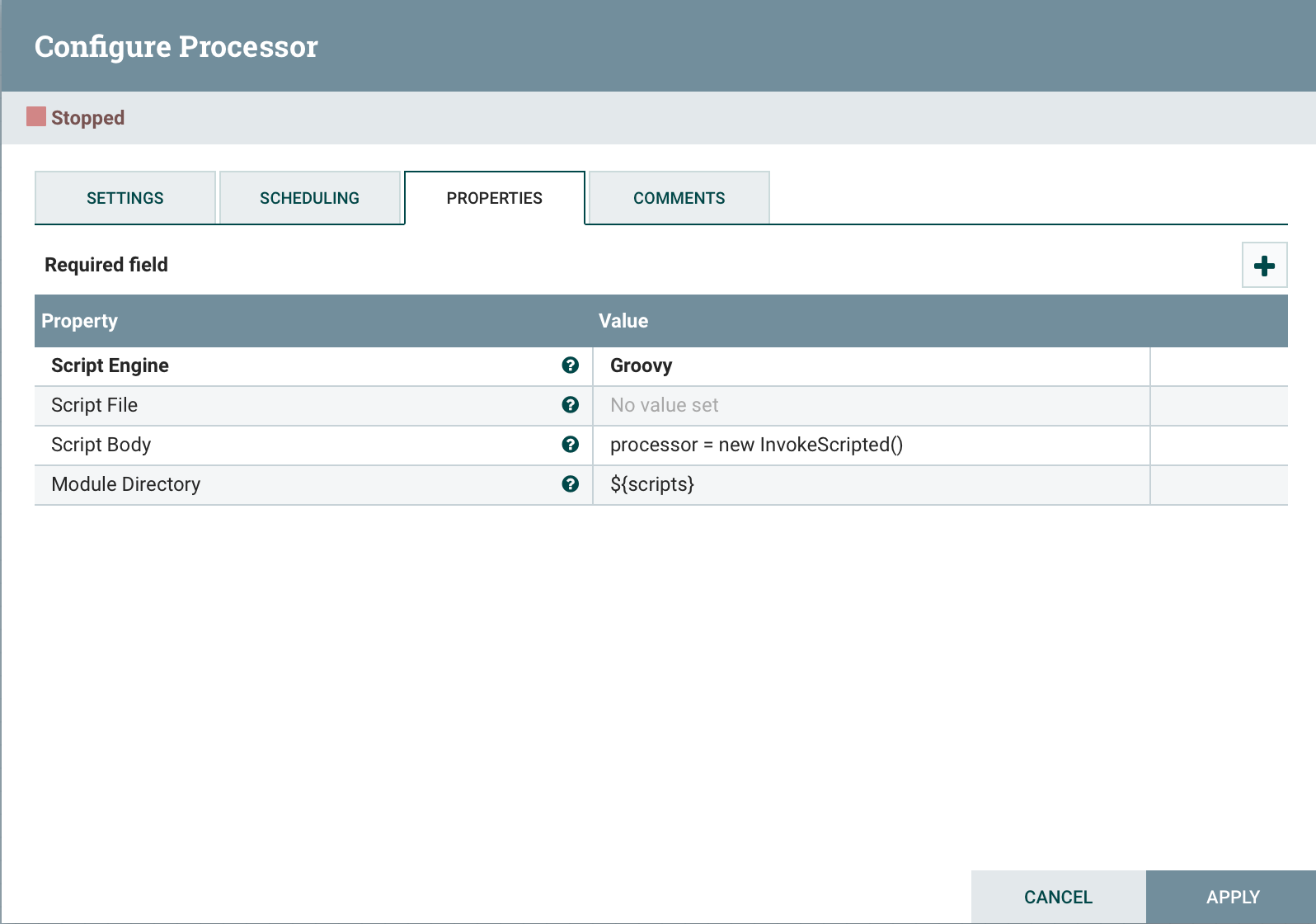 कोड के अंत में जोड़ें।
कोड के अंत में जोड़ें। processor = new InvokeScripted()यह दृष्टिकोण एक कस्टम प्रोसेसर बनाने के समान है।निष्कर्ष
एक कस्टम प्रोसेसर बनाना सबसे आसान काम नहीं है - पहली बार आपको यह पता लगाने के लिए कड़ी मेहनत करनी होगी, लेकिन इस कार्रवाई के लाभ निर्विवाद हैं।रोस्टेलकॉम डेटा मैनेजमेंट टीम द्वारा तैयार पोस्ट