Ivi के अस्तित्व के 10 वर्षों में, हमने विभिन्न लंबाई, आकार और गुणवत्ता के 90,000 वीडियो का एक डेटाबेस बनाया है। हर हफ्ते सैकड़ों नए दिखाई देते हैं। हमारे पास मेटाडेटा की गीगाबाइट्स हैं, जो सिफारिशों के लिए उपयोगी हैं, सेवा के नेविगेशन को सरल करती हैं और विज्ञापन स्थापित करती हैं। लेकिन हमने केवल दो साल पहले वीडियो से सीधे जानकारी निकालना शुरू किया।इस लेख में मैं आपको बताऊंगा कि कैसे हम संरचनात्मक तत्वों में फिल्मों को पार्स करते हैं और हमें इसकी आवश्यकता क्यों है। अंत में, एल्गोरिथ्म कोड और उदाहरणों के साथ जीथब रिपॉजिटरी का एक लिंक है।
वीडियो में क्या होता है?
वीडियो क्लिप में एक पदानुक्रमित संरचना है। यह डिजिटल वीडियो के बारे में है, इसलिए सबसे निचले स्तर पर पिक्सेल , रंगीन डॉट्स हैं जो एक स्थिर चित्र बनाते हैं।फिर भी चित्रों को फ्रेम कहा जाता है - वे एक-दूसरे को बदलते हैं और आंदोलन का प्रभाव पैदा करते हैं। स्थापना के समय, फ़्रेम को समूहों में काट दिया जाता है, जो कि निर्देशक द्वारा निर्देशित किया जाता है, आपस में जुड़े और पीछे की ओर चिपके होते हैं। अंग्रेजी में एक असेंबली ग्लूइंग से दूसरे तक फ्रेम के अनुक्रम को शॉट शॉट कहा जाता है। दुर्भाग्य से, रूसी शब्दावली असफल है, क्योंकि इसमें ऐसे समूहों को फ्रेम भी कहा जाता है। भ्रमित न होने के लिए, आइए अंग्रेजी शब्द का उपयोग करें। बस रूसी-भाषा संस्करण दर्ज करें: "शॉट" ।शॉट्स को अर्थ से समूहीकृत किया जाता है, उन्हें दृश्य कहा जाता है।दृश्य में जगह, समय और पात्रों की एकता होती है।हम आसानी से अलग-अलग फ्रेम और यहां तक कि इन फ़्रेमों के पिक्सेल भी प्राप्त कर सकते हैं, क्योंकि डिजिटल वीडियो एन्कोडिंग एल्गोरिदम इतने व्यवस्थित हैं। प्रजनन के लिए यह जानकारी आवश्यक है।दृश्यों और दृश्यों की सीमाओं को प्राप्त करना अधिक कठिन है। स्थापना कार्यक्रमों के स्रोत मदद कर सकते हैं, लेकिन वे हमारे लिए उपलब्ध नहीं हैं।सौभाग्य से, एल्गोरिदम ऐसा कर सकते हैं, हालांकि पूरी तरह से सही नहीं है। मैं आपको दृश्यों में विभाजित करने के लिए एल्गोरिथ्म के बारे में बताऊंगा।
स्थापना के समय, फ़्रेम को समूहों में काट दिया जाता है, जो कि निर्देशक द्वारा निर्देशित किया जाता है, आपस में जुड़े और पीछे की ओर चिपके होते हैं। अंग्रेजी में एक असेंबली ग्लूइंग से दूसरे तक फ्रेम के अनुक्रम को शॉट शॉट कहा जाता है। दुर्भाग्य से, रूसी शब्दावली असफल है, क्योंकि इसमें ऐसे समूहों को फ्रेम भी कहा जाता है। भ्रमित न होने के लिए, आइए अंग्रेजी शब्द का उपयोग करें। बस रूसी-भाषा संस्करण दर्ज करें: "शॉट" ।शॉट्स को अर्थ से समूहीकृत किया जाता है, उन्हें दृश्य कहा जाता है।दृश्य में जगह, समय और पात्रों की एकता होती है।हम आसानी से अलग-अलग फ्रेम और यहां तक कि इन फ़्रेमों के पिक्सेल भी प्राप्त कर सकते हैं, क्योंकि डिजिटल वीडियो एन्कोडिंग एल्गोरिदम इतने व्यवस्थित हैं। प्रजनन के लिए यह जानकारी आवश्यक है।दृश्यों और दृश्यों की सीमाओं को प्राप्त करना अधिक कठिन है। स्थापना कार्यक्रमों के स्रोत मदद कर सकते हैं, लेकिन वे हमारे लिए उपलब्ध नहीं हैं।सौभाग्य से, एल्गोरिदम ऐसा कर सकते हैं, हालांकि पूरी तरह से सही नहीं है। मैं आपको दृश्यों में विभाजित करने के लिए एल्गोरिथ्म के बारे में बताऊंगा।हमें यह क्यों चाहिये?
हम वीडियो के अंदर खोज समस्या को हल करते हैं और आइवी पर प्रत्येक फिल्म के प्रत्येक दृश्य को स्वचालित रूप से जांचना चाहते हैं। दृश्यों में विभाजित करना इस पाइपलाइन का एक महत्वपूर्ण हिस्सा है।यह जानने के लिए कि दृश्य कहाँ से शुरू और समाप्त होते हैं, आपको सिंथेटिक ट्रेलरों को बनाने की आवश्यकता है। हमारे पास पहले से ही एक एल्गोरिथ्म है जो उन्हें उत्पन्न करता है, लेकिन अभी तक, दृश्य पहचान का उपयोग वहां नहीं किया गया है।दृश्यों में विभाजित करने के लिए सिफारिशकर्ता प्रणाली भी उपयोगी है। उनसे, संकेत प्राप्त किए जाते हैं जो यह वर्णन करते हैं कि कौन से उपयोगकर्ता संरचना में पसंद करते हैं।समस्या को हल करने के लिए दृष्टिकोण क्या हैं?
समस्या दो पक्षों से हल की गई है:- वे पूरे वीडियो को लेते हैं और दृश्यों की सीमाओं की तलाश करते हैं।
- पहले, वे वीडियो को शॉट्स में विभाजित करते हैं, और फिर उन्हें दृश्यों में संयोजित करते हैं।
हम दूसरे तरीके से गए, क्योंकि यह औपचारिक रूप से आसान है, और इस विषय पर वैज्ञानिक लेख हैं। हम पहले से ही वीडियो को शॉट्स में विभाजित करना जानते हैं। यह इन दृश्यों को दृश्यों में एकत्र करने के लिए बना हुआ है।पहली चीज जिसे आप आज़माना चाहते हैं, वह है क्लस्टरिंग। शॉट्स लें, उन्हें वैक्टर में बदल दें, और फिर शास्त्रीय गुच्छन एल्गोरिदम का उपयोग करके वैक्टर को शास्त्रीय समूहों में विभाजित करें। इस दृष्टिकोण का मुख्य दोष: यह ध्यान में नहीं रखता है कि शॉट्स और दृश्य एक दूसरे का अनुसरण करते हैं। दूसरे दृश्य का एक शॉट एक दृश्य के दो दृश्यों के बीच में नहीं खड़ा हो सकता है, और क्लस्टरिंग के साथ यह संभव है।2016 में, डैनियल रोथमान और उनके आईबीएम सहयोगियों ने एक एल्गोरिथ्म का प्रस्ताव दिया जो समय संरचना को ध्यान में रखता है और एक इष्टतम अनुक्रमिक समूह कार्य के रूप में दृश्यों के संयोजन को तैयार करता है:
इस दृष्टिकोण का मुख्य दोष: यह ध्यान में नहीं रखता है कि शॉट्स और दृश्य एक दूसरे का अनुसरण करते हैं। दूसरे दृश्य का एक शॉट एक दृश्य के दो दृश्यों के बीच में नहीं खड़ा हो सकता है, और क्लस्टरिंग के साथ यह संभव है।2016 में, डैनियल रोथमान और उनके आईबीएम सहयोगियों ने एक एल्गोरिथ्म का प्रस्ताव दिया जो समय संरचना को ध्यान में रखता है और एक इष्टतम अनुक्रमिक समूह कार्य के रूप में दृश्यों के संयोजन को तैयार करता है:- का एक क्रम दिया शॉट्स
- इसे विभाजित करने की आवश्यकता है सेगमेंट ताकि यह पृथक्करण इष्टतम हो।
इष्टतम पृथक्करण क्या है?
अभी के लिए, हम मान लेते हैं दी गई, अर्थात दृश्यों की संख्या ज्ञात है। केवल उनकी सीमाएं अज्ञात हैं।जाहिर है, किसी तरह की मेट्रिक की जरूरत है। तीन मैट्रिक्स का आविष्कार किया गया था, वे शॉट्स के बीच जोड़ीदार दूरी के विचार पर आधारित हैं।प्रारंभिक चरण निम्नानुसार हैं:- हम शॉट्स को वैक्टर में बदलते हैं (एक तंत्रिका नेटवर्क की एक हिस्टोग्राम या आउटपुट परत)
- वैक्टर (यूक्लिडियन, कोसाइन, या कुछ अन्य) के बीच जोड़ीदार दूरी खोजें
- हमें एक चौकोर मैट्रिक्स मिलता है जहां प्रत्येक तत्व शॉट्स के बीच की दूरी है तथा ।
 यह मैट्रिक्स सममित है, और मुख्य विकर्ण पर यह हमेशा शून्य होगा, क्योंकि स्वयं वेक्टर की दूरी शून्य है।अंधेरे वर्गों को विकर्ण के साथ पता लगाया जाता है - वे क्षेत्र जहां पड़ोसी शॉट एक दूसरे के समान होते हैं, इसी तरह कम दूरी।यदि हम अच्छी एम्बेडिंग चुनते हैं जो शॉट्स के शब्दार्थ को दर्शाते हैं और एक अच्छी दूरी का कार्य चुनते हैं, तो ये वर्ग दृश्य हैं। वर्गों की सीमाओं का पता लगाएं - हम दृश्यों की सीमाएं पाएंगे।मैट्रिक्स को देखते हुए, इजरायल के सहयोगियों ने इष्टतम विभाजन के लिए तीन मापदंड तैयार किए:
यह मैट्रिक्स सममित है, और मुख्य विकर्ण पर यह हमेशा शून्य होगा, क्योंकि स्वयं वेक्टर की दूरी शून्य है।अंधेरे वर्गों को विकर्ण के साथ पता लगाया जाता है - वे क्षेत्र जहां पड़ोसी शॉट एक दूसरे के समान होते हैं, इसी तरह कम दूरी।यदि हम अच्छी एम्बेडिंग चुनते हैं जो शॉट्स के शब्दार्थ को दर्शाते हैं और एक अच्छी दूरी का कार्य चुनते हैं, तो ये वर्ग दृश्य हैं। वर्गों की सीमाओं का पता लगाएं - हम दृश्यों की सीमाएं पाएंगे।मैट्रिक्स को देखते हुए, इजरायल के सहयोगियों ने इष्टतम विभाजन के लिए तीन मापदंड तैयार किए:
दृश्य सीमा वेक्टर है।इष्टतम विभाजन में से कौन सा मापदंड चुनना है?
एक इष्टतम अनुक्रमिक समूहीकरण कार्य के लिए एक अच्छा नुकसान समारोह में दो गुण हैं:- यदि फिल्म में एक दृश्य होता है, तो जहां भी हम इसे दो भागों में विभाजित करने का प्रयास करते हैं, फ़ंक्शन का मान हमेशा समान रहेगा।
- यदि ठीक से दृश्यों में विभाजित किया गया है, तो मान सही नहीं होने से कम होगा।
यह पता चला है तथा इन आवश्यकताओं का सामना न करें, लेकिन मुकाबला। इसे समझने के लिए, हम दो प्रयोग करेंगे।पहले प्रयोग में, हम जोड़ीदार दूरियों का एक सिंथेटिक मैट्रिक्स बनायेंगे, इसे समान शोर से भरेंगे। यदि हम दो दृश्यों में विभाजित करने का प्रयास करते हैं, तो हमें निम्नलिखित चित्र मिलते हैं: का कहना है कि वीडियो के बीच में दृश्यों का एक परिवर्तन है, जो वास्तव में सच नहीं है। परअसामान्य कूदता है यदि विभाजन को शुरुआत में या वीडियो के अंत में रखा गया है। केवलआवश्यकतानुसार व्यवहार करता है।दूसरे प्रयोग में, हम समान मैट्रिक्स को समान शोर के साथ बनाएंगे, लेकिन इसमें से दो वर्गों को घटाएँगे, जैसे कि हमारे पास दो दृश्य हैं जो एक दूसरे से थोड़े अलग हैं।
का कहना है कि वीडियो के बीच में दृश्यों का एक परिवर्तन है, जो वास्तव में सच नहीं है। परअसामान्य कूदता है यदि विभाजन को शुरुआत में या वीडियो के अंत में रखा गया है। केवलआवश्यकतानुसार व्यवहार करता है।दूसरे प्रयोग में, हम समान मैट्रिक्स को समान शोर के साथ बनाएंगे, लेकिन इसमें से दो वर्गों को घटाएँगे, जैसे कि हमारे पास दो दृश्य हैं जो एक दूसरे से थोड़े अलग हैं।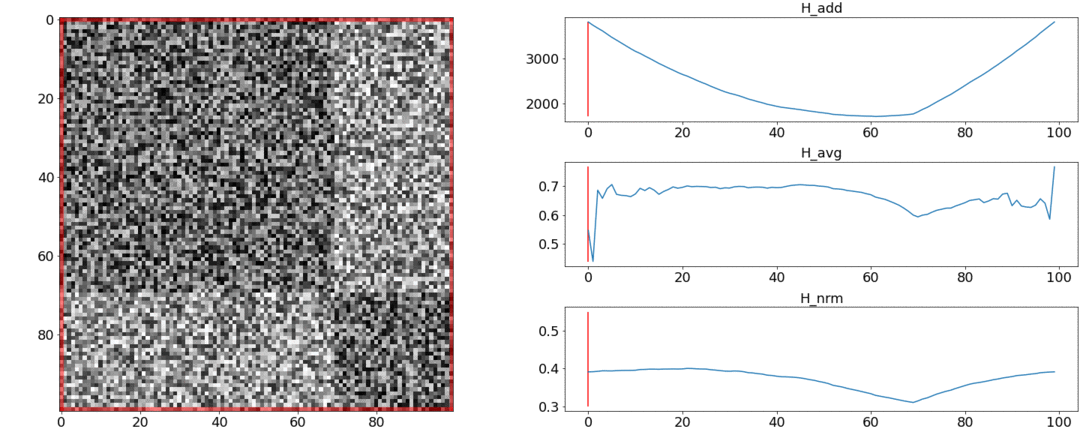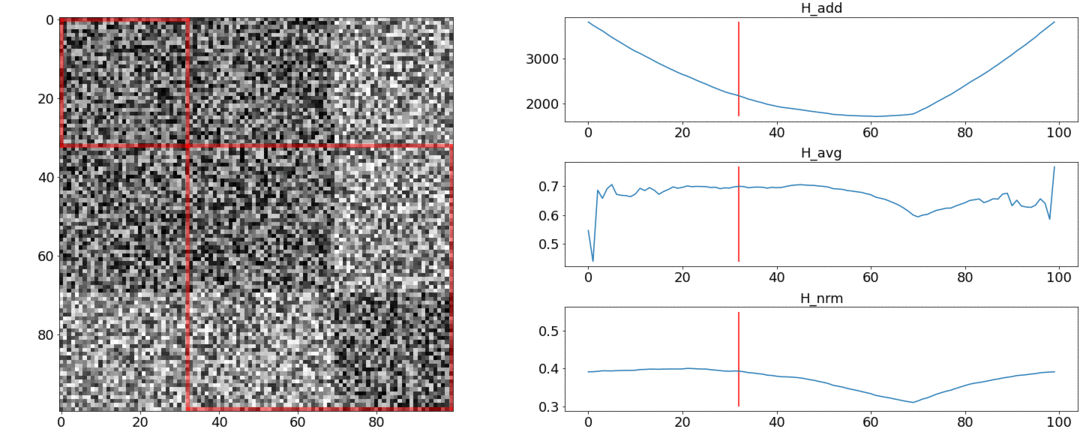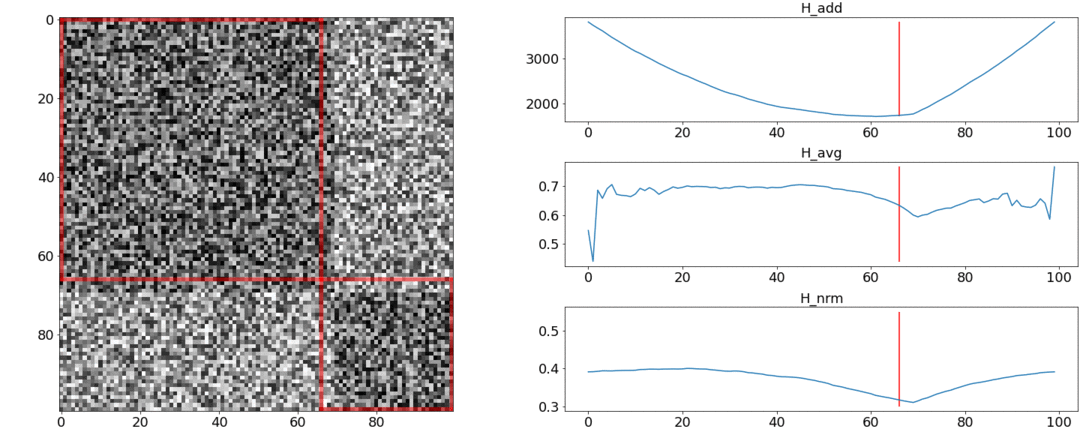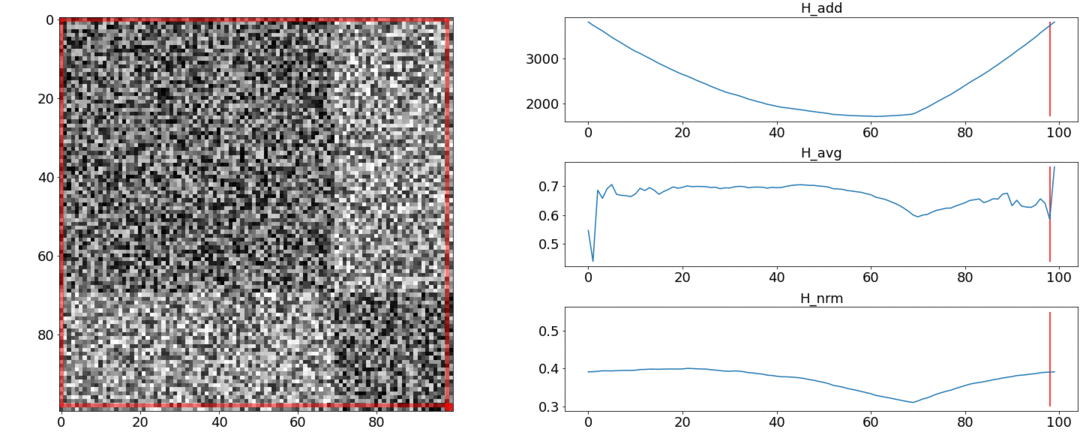 इस ग्लूइंग का पता लगाने के लिए, फ़ंक्शन को न्यूनतम मान लेना चाहिए। लेकिन एक न्यूनतम अभी भी खंड के मध्य के करीब है, जबकि - शुरुआत तक। पर एक स्पष्ट न्यूनतम पर दिखाई देता है ।परीक्षण यह भी बताते हैं कि सबसे सटीक विभाजन का उपयोग करके प्राप्त किया जाता है। ऐसा लगता है कि आपको इसे लेने की आवश्यकता है, और सब कुछ ठीक हो जाएगा। लेकिन चलो पहले अनुकूलन एल्गोरिथ्म की जटिलता को देखें।डैनियल रोथमैन और उनके समूह ने गतिशील प्रोग्रामिंग का उपयोग करके इष्टतम विभाजन की तलाश करने का सुझाव दिया । कार्य को पुनरावर्ती तरीके से उप-प्रकारों में विभाजित किया जाता है और बदले में हल किया जाता है। यह विधि एक वैश्विक इष्टतम देती है, लेकिन इसे खोजने के लिए, आपको प्रत्येक पर पुनरावृति करने की आवश्यकता है0th से Nth शॉट्स के विभाजन के सभी संयोजन और सर्वश्रेष्ठ चुनें। यहाँ - दृश्यों की संख्या, और - शॉट्स की संख्या।कोई ट्वीक और एक्सीलेरेशन ऑप्टिमाइज़ेशन नहीं समय में काम करेंगे । एटीगणना के लिए एक और पैरामीटर है - विभाजन का क्षेत्र, और प्रत्येक चरण में इसके सभी मूल्यों की जांच करना आवश्यक है। तदनुसार, समय बढ़ जाता है।हम कुछ सुधार करने में कामयाब रहे और मेमोराइजेशन तकनीक का उपयोग करके अनुकूलन को गति दी - स्मृति में पुनरावृत्ति के परिणामों को कैशिंग करना ताकि एक ही चीज़ को कई बार न पढ़ें। लेकिन, जैसा कि नीचे दिए गए परीक्षण बताते हैं, गति में एक मजबूत वृद्धि हासिल नहीं की गई थी।
इस ग्लूइंग का पता लगाने के लिए, फ़ंक्शन को न्यूनतम मान लेना चाहिए। लेकिन एक न्यूनतम अभी भी खंड के मध्य के करीब है, जबकि - शुरुआत तक। पर एक स्पष्ट न्यूनतम पर दिखाई देता है ।परीक्षण यह भी बताते हैं कि सबसे सटीक विभाजन का उपयोग करके प्राप्त किया जाता है। ऐसा लगता है कि आपको इसे लेने की आवश्यकता है, और सब कुछ ठीक हो जाएगा। लेकिन चलो पहले अनुकूलन एल्गोरिथ्म की जटिलता को देखें।डैनियल रोथमैन और उनके समूह ने गतिशील प्रोग्रामिंग का उपयोग करके इष्टतम विभाजन की तलाश करने का सुझाव दिया । कार्य को पुनरावर्ती तरीके से उप-प्रकारों में विभाजित किया जाता है और बदले में हल किया जाता है। यह विधि एक वैश्विक इष्टतम देती है, लेकिन इसे खोजने के लिए, आपको प्रत्येक पर पुनरावृति करने की आवश्यकता है0th से Nth शॉट्स के विभाजन के सभी संयोजन और सर्वश्रेष्ठ चुनें। यहाँ - दृश्यों की संख्या, और - शॉट्स की संख्या।कोई ट्वीक और एक्सीलेरेशन ऑप्टिमाइज़ेशन नहीं समय में काम करेंगे । एटीगणना के लिए एक और पैरामीटर है - विभाजन का क्षेत्र, और प्रत्येक चरण में इसके सभी मूल्यों की जांच करना आवश्यक है। तदनुसार, समय बढ़ जाता है।हम कुछ सुधार करने में कामयाब रहे और मेमोराइजेशन तकनीक का उपयोग करके अनुकूलन को गति दी - स्मृति में पुनरावृत्ति के परिणामों को कैशिंग करना ताकि एक ही चीज़ को कई बार न पढ़ें। लेकिन, जैसा कि नीचे दिए गए परीक्षण बताते हैं, गति में एक मजबूत वृद्धि हासिल नहीं की गई थी।दृश्यों की संख्या का अनुमान कैसे लगाया जाए?
IBM के एक समूह ने सुझाव दिया कि चूंकि मैट्रिक्स की कई पंक्तियाँ रैखिक रूप से निर्भर हैं, इसलिए विकर्ण के साथ वर्ग समूहों की संख्या मैट्रिक्स की रैंक के लगभग बराबर होगी।इसे प्राप्त करने के लिए और एक ही समय में शोर को फ़िल्टर करने के लिए, आपको मैट्रिक्स के एक विलक्षण अपघटन की आवश्यकता होती है।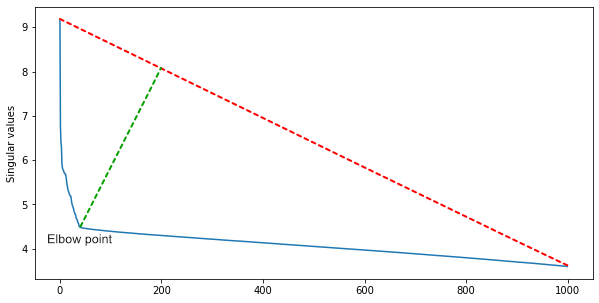 एकवचन मूल्यों के बीच, अवरोही क्रम में क्रमबद्ध, हम कोहनी बिंदु पाते हैं - वह जिसमें से मूल्यों में कमी तेजी से घटती है। कोहनी बिंदु सूचकांक एक फिल्म में दृश्यों की अनुमानित संख्या है।पहले सन्निकटन के लिए, यह पर्याप्त है, लेकिन आप सिनेमा के विभिन्न शैलियों के लिए एल्गोरिदम के साथ एल्गोरिदम को पूरक कर सकते हैं। एक्शन फिल्मों में, अधिक दृश्य होते हैं, और एक मेहराब में - कम।
एकवचन मूल्यों के बीच, अवरोही क्रम में क्रमबद्ध, हम कोहनी बिंदु पाते हैं - वह जिसमें से मूल्यों में कमी तेजी से घटती है। कोहनी बिंदु सूचकांक एक फिल्म में दृश्यों की अनुमानित संख्या है।पहले सन्निकटन के लिए, यह पर्याप्त है, लेकिन आप सिनेमा के विभिन्न शैलियों के लिए एल्गोरिदम के साथ एल्गोरिदम को पूरक कर सकते हैं। एक्शन फिल्मों में, अधिक दृश्य होते हैं, और एक मेहराब में - कम।टेस्ट
हम दो बातें समझना चाहते थे:- क्या गति का अंतर इतना नाटकीय है?
- तेज एल्गोरिथ्म का उपयोग करते समय यह कितनी सटीकता से ग्रस्त है?
टेस्ट को दो समूहों में विभाजित किया गया था: सिंथेटिक और वास्तविक डेटा। सिंथेटिक परीक्षणों पर, दोनों एल्गोरिदम की गुणवत्ता और गति की तुलना की गई, और वास्तविक लोगों पर, उन्होंने सबसे तेज एल्गोरिथ्म की गुणवत्ता को मापा। मैकबुक प्रो 2017, 2.3 गीगाहर्ट्ज इंटेल कोर i5, 16 जीबी 2133 मेगाहर्ट्ज एलपीडीडीआर 3 पर स्पीड टेस्ट किए गए थे।सिंथेटिक गुणवत्ता परीक्षण
हमने 12 से 122 शॉट्स के बीच जोड़ीदार दूरी के 999 मैट्रिसेस उत्पन्न किए, बेतरतीब ढंग से उन्हें 2-10 दृश्यों में विभाजित किया और ऊपर से सामान्य शोर जोड़ा।प्रत्येक मैट्रिक्स के लिए, इष्टतम विभाजन के संदर्भ में पाया गया था तथा , और फिर प्रेसिजन, रिकॉल, एफ 1 और आईओयू मेट्रिक्स की गिनती की।हम निम्नलिखित सूत्रों का उपयोग करके अंतराल के लिए परिशुद्धता और स्मरण पर विचार करते हैं:
हम एफ 1 को हमेशा की तरह मानते हैं, अंतराल परिशुद्धता और रिकॉल को प्रतिस्थापित करते हैं:
फिल्म के भीतर अनुमानित और सच्चे खंडों की तुलना करने के लिए, प्रत्येक भविष्यवाणी के लिए, हम सबसे बड़े चौराहे के साथ सही खंड पाते हैं और इस जोड़ी के लिए मीट्रिक पर विचार करते हैं।यहाँ परिणाम हैं: फ़ंक्शन अनुकूलन एल्गोरिथ्म के लेखकों के परीक्षणों में, सभी मैट्रिक्स में जीता गया।
फ़ंक्शन अनुकूलन एल्गोरिथ्म के लेखकों के परीक्षणों में, सभी मैट्रिक्स में जीता गया।सिंथेटिक गति परीक्षण
गति का परीक्षण करने के लिए, हमने अन्य सिंथेटिक परीक्षण किए। पहला तरीका यह है कि एल्गोरिथ्म का रनिंग टाइम शॉट्स की संख्या पर निर्भर करता है।दृश्यों की एक निश्चित संख्या के साथ: परीक्षण ने एक सैद्धांतिक मूल्यांकन की पुष्टि की: अनुकूलन समय विकास के साथ बहुपत्नी बढ़ता है रैखिक समय की तुलना में पर ।यदि आप शॉट्स की संख्या को ठीक करते हैं और धीरे-धीरे दृश्यों की संख्या में वृद्धि करें , हमें एक और दिलचस्प तस्वीर मिलती है। सबसे पहले, समय बढ़ने की उम्मीद है, लेकिन फिर यह बेर होना शुरू हो जाता है। तथ्य यह है कि संभावित भाजक मानों की संख्या (सूत्र)) कि हमें उन तरीकों की संख्या के अनुपात में जांच करने की आवश्यकता है जिन्हें हम तोड़ सकते हैं खंडों पर । इसकी गणना के संयोजन का उपयोग करके की जाती है द्वारा :
परीक्षण ने एक सैद्धांतिक मूल्यांकन की पुष्टि की: अनुकूलन समय विकास के साथ बहुपत्नी बढ़ता है रैखिक समय की तुलना में पर ।यदि आप शॉट्स की संख्या को ठीक करते हैं और धीरे-धीरे दृश्यों की संख्या में वृद्धि करें , हमें एक और दिलचस्प तस्वीर मिलती है। सबसे पहले, समय बढ़ने की उम्मीद है, लेकिन फिर यह बेर होना शुरू हो जाता है। तथ्य यह है कि संभावित भाजक मानों की संख्या (सूत्र)) कि हमें उन तरीकों की संख्या के अनुपात में जांच करने की आवश्यकता है जिन्हें हम तोड़ सकते हैं खंडों पर । इसकी गणना के संयोजन का उपयोग करके की जाती है द्वारा :
विकास के साथ संयोजनों की संख्या पहले बढ़ती है, और फिर आपके पास आते ही गिर जाती है । यह शांत प्रतीत होता है, लेकिन दृश्यों की संख्या शायद ही कभी शॉट्स की संख्या के बराबर होगी, और हमेशा इस तरह के मूल्य पर ले जाएगा कि कई संयोजन हैं। पहले से ही उल्लेखित "एवेंजर्स" में 2700 शॉट्स और 105 दृश्य। संयोजनों की संख्या:
यह शांत प्रतीत होता है, लेकिन दृश्यों की संख्या शायद ही कभी शॉट्स की संख्या के बराबर होगी, और हमेशा इस तरह के मूल्य पर ले जाएगा कि कई संयोजन हैं। पहले से ही उल्लेखित "एवेंजर्स" में 2700 शॉट्स और 105 दृश्य। संयोजनों की संख्या:
यह सुनिश्चित करने के लिए कि सबकुछ सही ढंग से समझा गया था और मूल लेखों के अंकन में उलझा नहीं था, हमने डैनियल रोथमान को एक पत्र लिखा। उन्होंने इसकी पुष्टि की वास्तव में धीमी गति से अनुकूलन और 10 मिनट से अधिक समय तक वीडियो के लिए उपयुक्त नहीं है, और व्यवहार में स्वीकार्य परिणाम देता है।वास्तविक डेटा परीक्षण
इसलिए, हमने एक मीट्रिक चुना है , जो, हालांकि थोड़ा कम सटीक है, बहुत तेजी से काम करता है। अब हमें मैट्रिक्स की आवश्यकता है, जिसमें से हम एक बेहतर एल्गोरिथ्म की खोज पर निर्माण करेंगे।परीक्षण के लिए हमने विभिन्न शैलियों और वर्षों की 20 फिल्मों को चिह्नित किया। मार्कअप पांच चरणों में किया गया था:- :
- , .
- . « ?»
- CV. — , .
- , « ».
इस तरह से स्क्रिबलर और इंस्पेक्टर की स्क्रीन दिखती है: और यह है कि फिल्म के पहले 300 शॉट्स "एवेंजर्स: इन्फिनिटी वॉर" को दृश्यों में विभाजित किया गया है। बाईं ओर सच्चे दृश्य हैं, और दाईं ओर एल्गोरिदम द्वारा भविष्यवाणी की गई है:
और यह है कि फिल्म के पहले 300 शॉट्स "एवेंजर्स: इन्फिनिटी वॉर" को दृश्यों में विभाजित किया गया है। बाईं ओर सच्चे दृश्य हैं, और दाईं ओर एल्गोरिदम द्वारा भविष्यवाणी की गई है: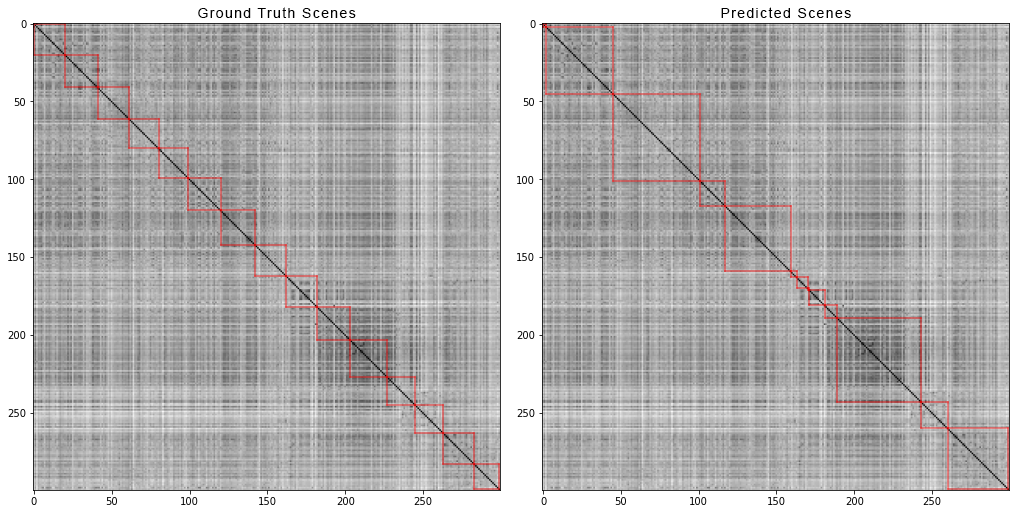 जोड़ीदार दूरी के एक मैट्रिक्स को प्राप्त करने के लिए, हमने निम्नलिखित कार्य किए:डेटासेट से प्रत्येक वीडियो के लिए, हमने जोड़ीदार दूरियों के मैट्रिक्स उत्पन्न किए और सिंथेटिक डेटा के लिए, हमने चार मीट्रिक की गणना की। ये संख्याएं सामने आई हैं:
जोड़ीदार दूरी के एक मैट्रिक्स को प्राप्त करने के लिए, हमने निम्नलिखित कार्य किए:डेटासेट से प्रत्येक वीडियो के लिए, हमने जोड़ीदार दूरियों के मैट्रिक्स उत्पन्न किए और सिंथेटिक डेटा के लिए, हमने चार मीट्रिक की गणना की। ये संख्याएं सामने आई हैं:- परिशुद्धता : 0.4861919030708739
- स्मरण करें : 0.8225937459424839
- एफ 1 : 0.513676858711775
- IoU : 0.37560909807842874
तो क्या?
हमें एक आधार रेखा मिली जो पूरी तरह से काम नहीं करती है, लेकिन अब आप इस पर निर्माण कर सकते हैं जबकि हम अधिक सटीक तरीकों की तलाश कर रहे हैं।आगे की कुछ योजनाएँ:- सुविधा निष्कर्षण के लिए अन्य CNN आर्किटेक्चर आज़माएं।
- शॉट्स के बीच अन्य दूरी मैट्रिक्स की कोशिश करें।
- अन्य अनुकूलन विधियों का प्रयास करें , उदाहरण के लिए, आनुवंशिक एल्गोरिदम।
- पूरी फिल्म के टूटने को अलग-अलग हिस्सों में कम करने की कोशिश करें एक उचित समय में पूरा करती है, और तुलना करती है कि गुणवत्ता में क्या नुकसान होगा।
सिंथेटिक डेटा पर दोनों तरीकों और प्रयोगों का कोड जीथब पर प्रकाशित किया गया था । आप स्वयं को गति देने के लिए स्पर्श कर सकते हैं और प्रयास कर सकते हैं। पसंद और पुल अनुरोधों का स्वागत है।अलविदा, आप अगले लेखों में देखें!