एक बार यह दिलचस्प हो गया कि एलडीए "ड्यूरिचलेट के अव्यक्त प्लेसमेंट" के कौन से विषय "लाइव जर्नल" की सामग्री पर प्रकाश डालेगा। जैसा कि वे कहते हैं, ब्याज है - कोई समस्या नहीं।शुरुआत के लिए, उंगलियों पर एलडीए के बारे में थोड़ा, हम गणितीय विवरणों में नहीं जाते हैं (कोई भी रुचि - पढ़ता है)। तो, एलडीए - मॉडलिंग विषयों के लिए सबसे आम एल्गोरिदम में से एक है। प्रत्येक दस्तावेज़ (यह एक लेख, एक पुस्तक, या पाठ डेटा का कोई अन्य स्रोत हो) विषयों का एक मिश्रण है, और प्रत्येक विषय शब्दों का मिश्रण है।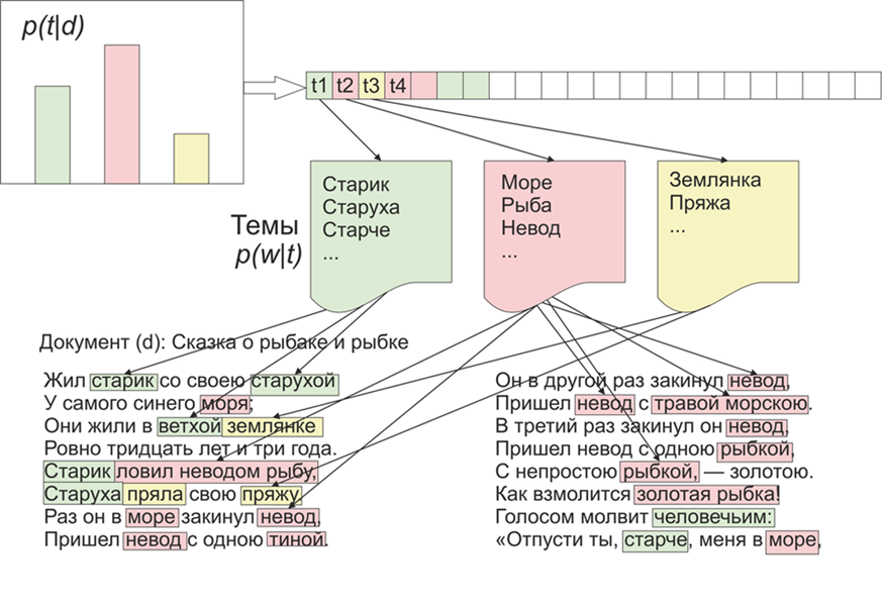 चित्र विकिपीडिया से लिया गया हैइस प्रकार, एलडीए का कार्य उन शब्दों के समूहों को खोजना है जो दस्तावेजों के संग्रह से विषय बनाते हैं। फिर, विषयों के आधार पर, आप टेक्स्ट को क्लस्टर कर सकते हैं या केवल कीवर्ड हाइलाइट कर सकते हैं।LifeJournal वेबसाइट से लगभग 1800 लेख प्राप्त हुए, उन सभी को jsonl फॉर्मेट में बदल दिया गया। मैं यैंडेक्स डिस्क पर अशुद्ध लेख छोड़ दूंगा । हम डेटा की कुछ सफाई और सामान्यीकरण करेंगे: टिप्पणियों को बाहर फेंकें, स्टॉप शब्द हटाएं (स्रोत कोड के साथ सूची गितुब पर उपलब्ध है), हम वर्तनी को कम करने के लिए सभी शब्द लाएंगे, हम 3 अक्षर या उससे कम वाले विराम चिह्न और शब्द हटा देंगे। लेकिन मुख्य पूर्व-प्रसंस्करण कार्यों में से एक: अक्सर होने वाले शब्दों को हटाना, सिद्धांत रूप में, केवल स्टॉप शब्दों को हटाने तक सीमित हो सकता है, लेकिन फिर अक्सर उपयोग किए जाने वाले शब्दों को उच्च संभावना वाले लगभग सभी विषयों में शामिल किया जाएगा। इस मामले में, ऐसे शब्दों को पोस्ट-प्रोसेस करना और हटाना संभव होगा। चुनना आपको है।
चित्र विकिपीडिया से लिया गया हैइस प्रकार, एलडीए का कार्य उन शब्दों के समूहों को खोजना है जो दस्तावेजों के संग्रह से विषय बनाते हैं। फिर, विषयों के आधार पर, आप टेक्स्ट को क्लस्टर कर सकते हैं या केवल कीवर्ड हाइलाइट कर सकते हैं।LifeJournal वेबसाइट से लगभग 1800 लेख प्राप्त हुए, उन सभी को jsonl फॉर्मेट में बदल दिया गया। मैं यैंडेक्स डिस्क पर अशुद्ध लेख छोड़ दूंगा । हम डेटा की कुछ सफाई और सामान्यीकरण करेंगे: टिप्पणियों को बाहर फेंकें, स्टॉप शब्द हटाएं (स्रोत कोड के साथ सूची गितुब पर उपलब्ध है), हम वर्तनी को कम करने के लिए सभी शब्द लाएंगे, हम 3 अक्षर या उससे कम वाले विराम चिह्न और शब्द हटा देंगे। लेकिन मुख्य पूर्व-प्रसंस्करण कार्यों में से एक: अक्सर होने वाले शब्दों को हटाना, सिद्धांत रूप में, केवल स्टॉप शब्दों को हटाने तक सीमित हो सकता है, लेकिन फिर अक्सर उपयोग किए जाने वाले शब्दों को उच्च संभावना वाले लगभग सभी विषयों में शामिल किया जाएगा। इस मामले में, ऐसे शब्दों को पोस्ट-प्रोसेस करना और हटाना संभव होगा। चुनना आपको है।stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
अगला, हम सभी शब्दों को सामान्य रूप में लाते हैं: इसके लिए हम pymorphy2 लाइब्रेरी का उपयोग करते हैं, जिसे पाइप के माध्यम से स्थापित किया जा सकता है।morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
हां, हम शब्दों के रूप के बारे में जानकारी खो देंगे, लेकिन इस संदर्भ में, हम एक-दूसरे के साथ शब्दों की संगतता में अधिक रुचि रखते हैं। यह वह जगह है जहां हमारा प्रीप्रोसेसिंग पूरा हो गया है, यह पूरा नहीं है, लेकिन यह देखना पर्याप्त है कि एलडीए एल्गोरिदम कैसे काम करता है।इसके अलावा, सिद्धांत में उपर्युक्त बिंदु को छोड़ा जा सकता है, लेकिन मेरी राय में, परिणाम अधिक पर्याप्त हैं, फिर से, क्या सीमा होगी, आप तय करते हैं, उदाहरण के लिए, आप एक फ़ंक्शन का निर्माण कर सकते हैं जो दस्तावेजों की औसत लंबाई और उनकी संख्या पर निर्भर करता है :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
आइए सीधे मॉडल के प्रशिक्षण के लिए आगे बढ़ें, इसके लिए हमें gensim लाइब्रेरी स्थापित करने की आवश्यकता है, जिसमें शांत बन्स का एक गुच्छा होता है। पहले आपको सभी शब्दों को एनकोड करने की जरूरत है, शब्दकोश फ़ंक्शन हमारे लिए यह करेगा, फिर हम शब्दों को उनके संख्यात्मक समकक्षों के साथ बदल देंगे। एलडीए कॉल का टिप्पणी-आउट संस्करण लंबा है, क्योंकि प्रत्येक दस्तावेज़ के बाद इसे अपडेट किया जाता है, आप सेटिंग्स के साथ खेल सकते हैं और उपयुक्त विकल्प का चयन कर सकते हैं।texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
कार्यक्रम के काम के बाद, कमांड का उपयोग करके विषयों को देखा जा सकता हैlda.show_topic(i,topn=30)
, जहां मैं विषय संख्या है, और टॉपन प्रदर्शित किए जाने वाले विषय में शब्दों की संख्या है।अब विज़ुअलाइज़िंग थीम के लिए एक छोटा सा बोनस, इसके लिए आपको वर्डक्लाउड लाइब्रेरी को स्थापित करने की आवश्यकता है (जैसे, समान उपयोगिताओं भी matplotlib में)। यह कोड थीम की कल्पना करता है और उन्हें वर्तमान फ़ोल्डर में बचाता है।from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
और अंत में, मेरे द्वारा प्राप्त किए गए विषयों के कुछ उदाहरण:
 प्रयोग और आप और भी अधिक सार्थक परिणाम प्राप्त कर सकते हैं।
प्रयोग और आप और भी अधिक सार्थक परिणाम प्राप्त कर सकते हैं।