
नमस्कार, हेब्र! हम चैनल #article_essense से ओपन डेटा साइंस समुदाय के सदस्यों के वैज्ञानिक लेखों की समीक्षाओं को प्रकाशित करना जारी रखते हैं। यदि आप उन्हें हर किसी से पहले प्राप्त करना चाहते हैं - समुदाय में शामिल हों !
11 Computer Vision, Natural Language Processing, Reinforcement learning .
:
- Side-Tuning: Network Adaptation via Additive Side Networks (University of California, Stanford University, 2019)
- Stacked DeBERT: All Attention in Incomplete Data for Text Classification (Kyungpook National University, South Korea, 2020)
- Zero-Shot Video Object Segmentation via Attentive Graph Neural Networks (UAE, USA, 2020)
- SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation (Toronto and Waterloo, Canada, 2020)
- FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping (Peking University, Microsoft Research, 2019)
- Towards a Human-like Open-Domain Chatbot (Google Brain, 2020)
- Positive Algorithmic Bias Cannot Stop Fragmentation in Homophilic Social Networks (Oxford, London, UK, 2020)
- BERT-of-Theseus: Compressing BERT by Progressive Module Replacing (Wuhan and Beihang Universities, Microsoft Research Asia, 2020)
- A Simple Framework for Contrastive Learning of Visual Representations (Google Research, 2020)
- BADGR: An Autonomous Self-Supervised Learning-Based Navigation System (Berkeley AI Research, USA, 2020)
- Training Large Neural Networks with Constant Memory using a New Execution Algorithm (Microsoft, 2020)
1. Side-Tuning: Network Adaptation via Additive Side Networks
: Jeffrey O Zhang, Alexander Sax, Amir Zamir, Leonidas Guibas, Jitendra Malik (University of California, Stanford University, 2019)
:: GitHub project
: ( artgor)
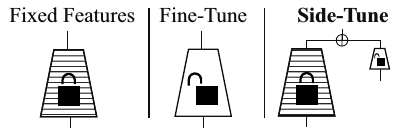
, pretrained , (, ), , . . A pretrained , , , . , , RL . , , .
, , :
- . , . feature extractor.
- side-tuning . , . .
- output . — , .
: . "" , . "", . , , residuals . boosting.
- : L(x,y) = || D(alpha B(x) + (1 — alpha) S(x)) — y||. , — . , alpha=1 feature extraction, aplha=W0 — fine-tuning. aplha , 0, - stage-wise RL. — hyperbolical decay. . .
:
- side-tuning - .
- … side network. .
- N .
, , .
side-tuning . Taskonomy iCIFAR ( CIFAR 10 10 ). Sidetune (A) — , — multilayer perceptron. side-tuning Progressive NN.
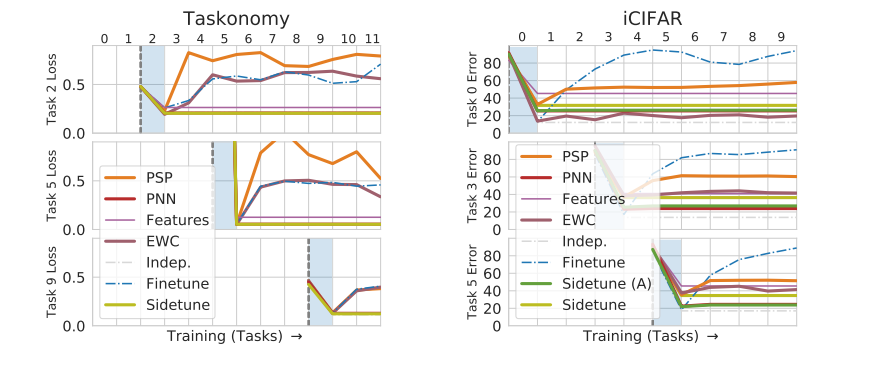
, :
- Transfer Learning Taxonomy — object classification, surface normal estimation, and curvature estimation
- Question-Answering in SQuAD v2 — BERT.
- Imitation Learning for Navigation in Habitat.
- Reinforcement Learning for Navigation in Habitat
:
- alpha , ;
- ;
- , ;
- — side-tuning . ;
- fine-tuning RL;
- , .
2. Stacked DeBERT: All Attention in Incomplete Data for Text Classification
: Gwenaelle Cunha Sergio, Minho Lee (Kyungpook National University, South Korea, 2020)
:: GitHub project
: ( artgor)
, , , — - .
: input, embedding , , denoising transformers, . multilayer perceptron , .
the Chatbot Natural Language Understanding Evaluation Corpus Kaggle's Twitter Sentiment Corpus. F1 Speech2Text .
2 :
- "incomplete intent and sentiment classification from incorrect sentences"
:
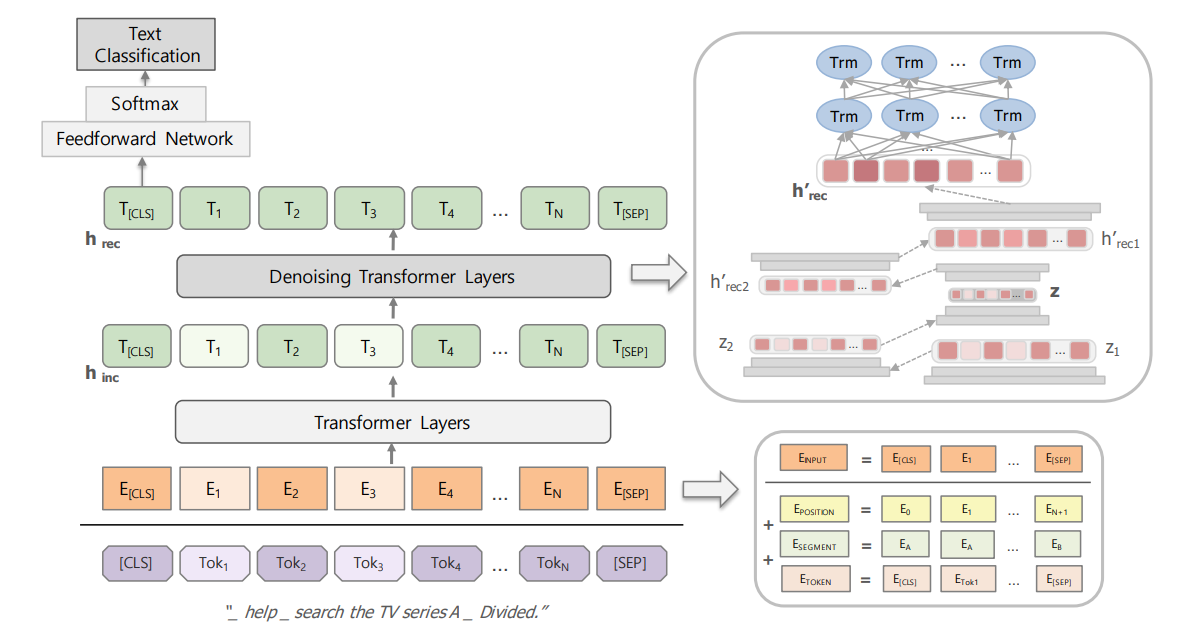
BERT — , . - "incomplete text classification corpus". Denoising transformer — stacks of multilayer perceptron bidirectional transformers. — , — . ( ). . (N, 768, 128) — , .
Stacks of multilayer perceptron:
- 3 .
- : 768 -> 128 -> 32 -> 12.
- .
— MSE.
( ), bidirectional transformers input. fine-tuning incomplete text classification corpus.
, 2 .
Twitter Sentiment Classification
(1.6 ). 200 ( ) . Amazon Turk, . - :

- 200 . 50 , .
Intent Classification from Text with STT Error
, . Text-to-Speech Speech-to-Text — . 2 (- 100 )
TTS, STT. :

:
- : Google Dialogflow, SAP Conversational AI, Rasa
- Semantic hashing with classifier. , ,
- BERT
- Stacked DeBERT
3 : "" gtts-witai macsay-witai. .
3. Zero-Shot Video Object Segmentation via Attentive Graph Neural Networks
: Wenguan Wang, Xiankai Lu, Jianbing Shen, David Crandall, Ling Shao (UAE, USA, 2020)
:: GitHub project
: ( artgor)
attentive graph neural network (AGNN) zero-shot video object segmentation (ZVOS). , — , attention. ZVOS, image object co-segmentation (IOCS).
AGNN:
:

— . — ; (interconnected self-connections ). GNN — message propagation . .
:
- , DeepLabV3 .
- , self-connection — . .
- inter-attention .
- FCN
:
- DAVIS16 — 50 (30 , 20 ). .
- Youtube-Objects — 126 , 10 . .
- DAVIS17 — 60 30 , 30 . , . .
- IOSC —
Ablation study:
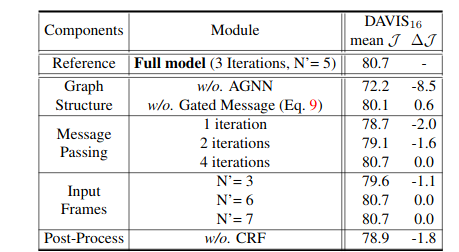
4. SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
: Jesse Sun, Fatemeh Darbeha, Mark Zaidi, Bo Wang (Toronto and Waterloo, Canada, 2020)
:: GitHub project
: ( artgor)
TL;DR: UNet + + dense + dual attention decoder = SOTA + interpretability
: CNN , . . — CNN , . — gradient-based saliency . .
UNet , . dual-attention decoder, . : SAUNet — SOTA SUN09 AC17.
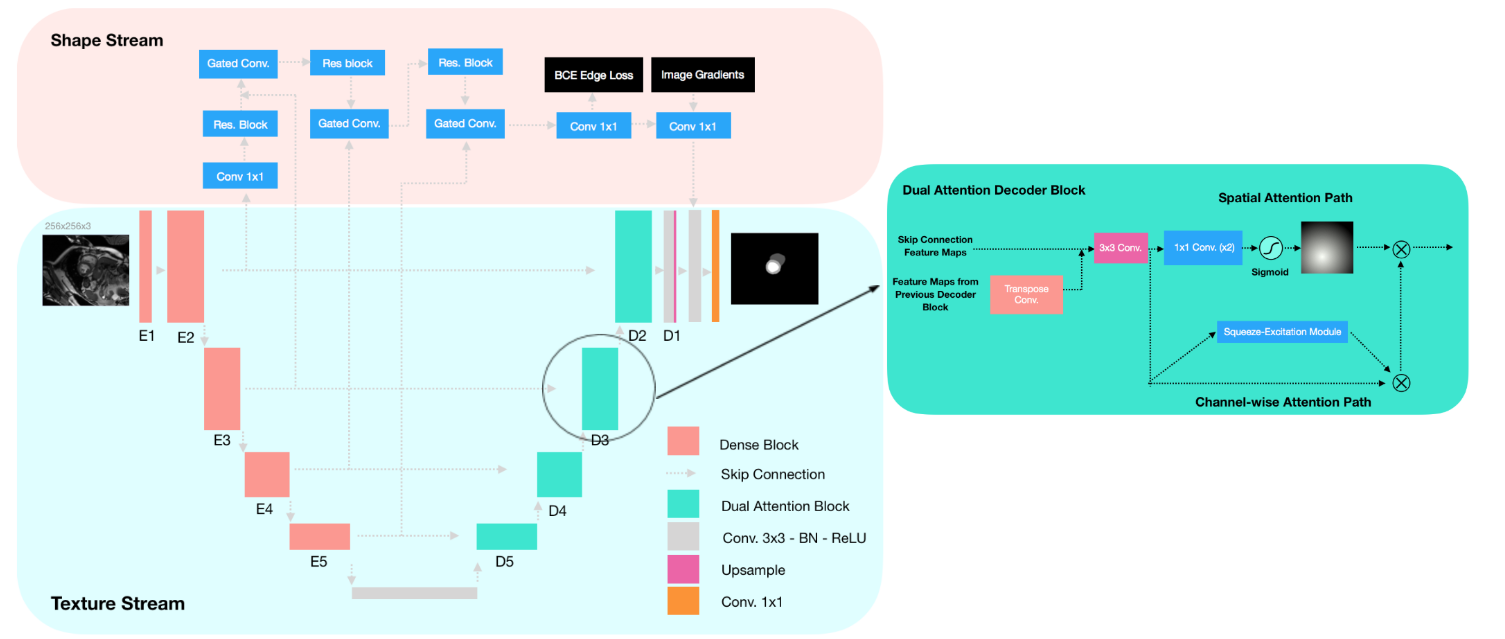
SAUNet
, 2 .
Texture stream
UNet, dense Tiramisu. — dual attention decoder block.
Gated shape stream
Gated-SCNN. , unet downsample . gated convolutional layer: alpha_L = sigma(C_1x1(S_L||C_1x1(T_t))), S — feature map shape stream, T — feature map texture stream, C1x1 — 11 convolution.
, convolution . residual blocks — 2 3x3 convolution skip-connection. S alpha. residual block.
steam shape deeply supervision Ledge. binary cross entropy loss . : "The output of the gated shape stream is the predicted shapefeature maps of the classes of interest concatenated channel-wise with the Canny edges from the original image. Theoutput is then concatenated with the texture stream featuremaps before the last normalized 3x3 convolution layer ofthe texture stream."
Dual Attention Decoder Block.
(2 3x3 convolution feature maps) : Spatial attention path Channel-wise attention
Spatial attention path
. convolution 1x1 ( C/2 , ), sigmoid. ( , ).
Channel-wise attention path
. SE .
Dual-Task Loss function
: L_total = lambda1 L_CE + lambda2 L_Dice + lambda3 * L_Edge
1 lambda.
- SUN09 — 2 : he endocardium and the epicardium. 260+135 128128.
- AC17 — 200 , 8-20 . 256256.
. Ablation study , shape stream . , , saliency maps.
5. FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
: Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen (Peking University, Microsoft Research, 2019)
:: Non official GitHub project
: ( shiron8bit)
person agnostic gan- face swap, , . , , / - , unet-style , adain-style , , - .
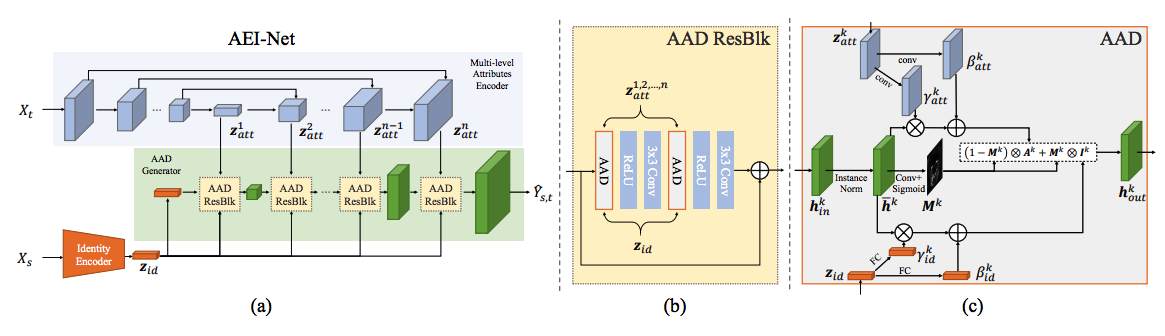
( ) , X_s X_t, (a) AADGenerator, AADResBlck z_id ( ArcFace-), AADResBlck feature map . feature map, z_id transposed 2d convolution.
AADResBlck, (b), Residual block, relu (2 3 , / ) AAD-.
AAD-, AdaIN/SPADE- ( : 1, 2), :
- feature map ( instance normalization)
- fully connected- ( ) , , A_k
- , , I_k
- ( 0 1)
- A_k I_k .
, — : , (4x4, 8x8), (16x16, 32x32) ( , , ), .
Ablation study , , / A_k I_k. , ( 8 256x256).

adversarial loss 3 : L_id ( , L2 , Arcface ), L_rec — L2- ( , X_s X_t , 0.1), L_att — Y_s,t.
AEI-Net , , X_t - . , , . Unet- Hear-Net, Y_s,t, X_t Y_t,t ( X_t X_t). : AEI-Net , , - , , .
semi-supervised , ground truth, , Y_s,t X_t (L_chg L_rec ). - , , EgoHands, GTEA Hand2K, ShapeNet ( CelebaHQ, FFHQ VGGFace).
6. Towards a Human-like Open-Domain Chatbot
: Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, Quoc V. Le (Google Brain, 2020)
:: Blog
: ( fuckai)
TL;DR
Google Brain SOTA Meena. Evolved Transformer 2.6B 340GB 2048 TPU v3 30 . . , AGI .
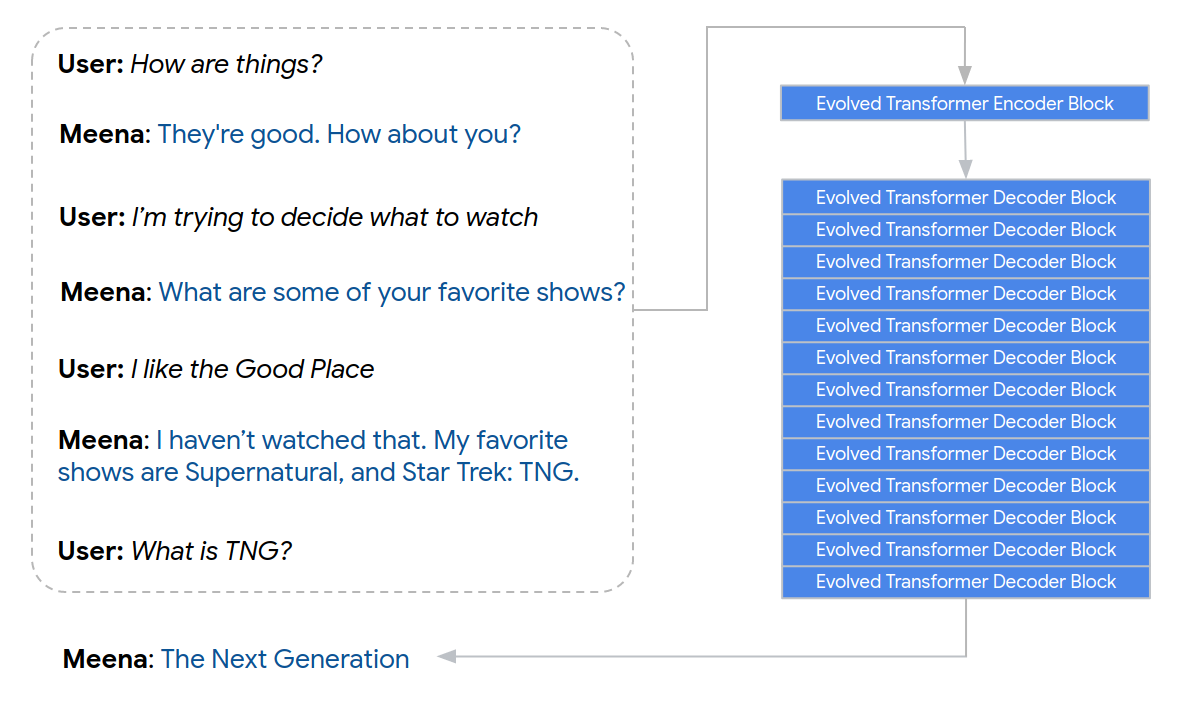
seq2seq , — 1 Evolved Transformer’a, — 13 . . — perplexity( ppl). , ppl , 10.2 vs 10.7 ppl.
— BPE, — 8K byte-pairs. , TPU 16GB. 7 , 128 .
“public domain social media”. , ++- . , , / , . 360GB 876M (, ).
30 TPU 2048 TPU v3. 164 , 10 . .
.
- Sampling-and-rank — N - , . . — - , . N = 20.
- top-k — , k .
- . , . ngram’ .
- .
SSA — Sensibleness and Specificity Average. . Sensibleness — . , , , — 0, 1. Specificity — . SSA = (Sensibleness + Specificity) / 2. SSA , .
:
- XiaoIce — Microsoft, ~100M , .
- DialoGPT, SOTA MS, GPT2 745M .
- Mitsuku — , 5 Loebner Prize — , — .
- Cleverbot — 1986 , .
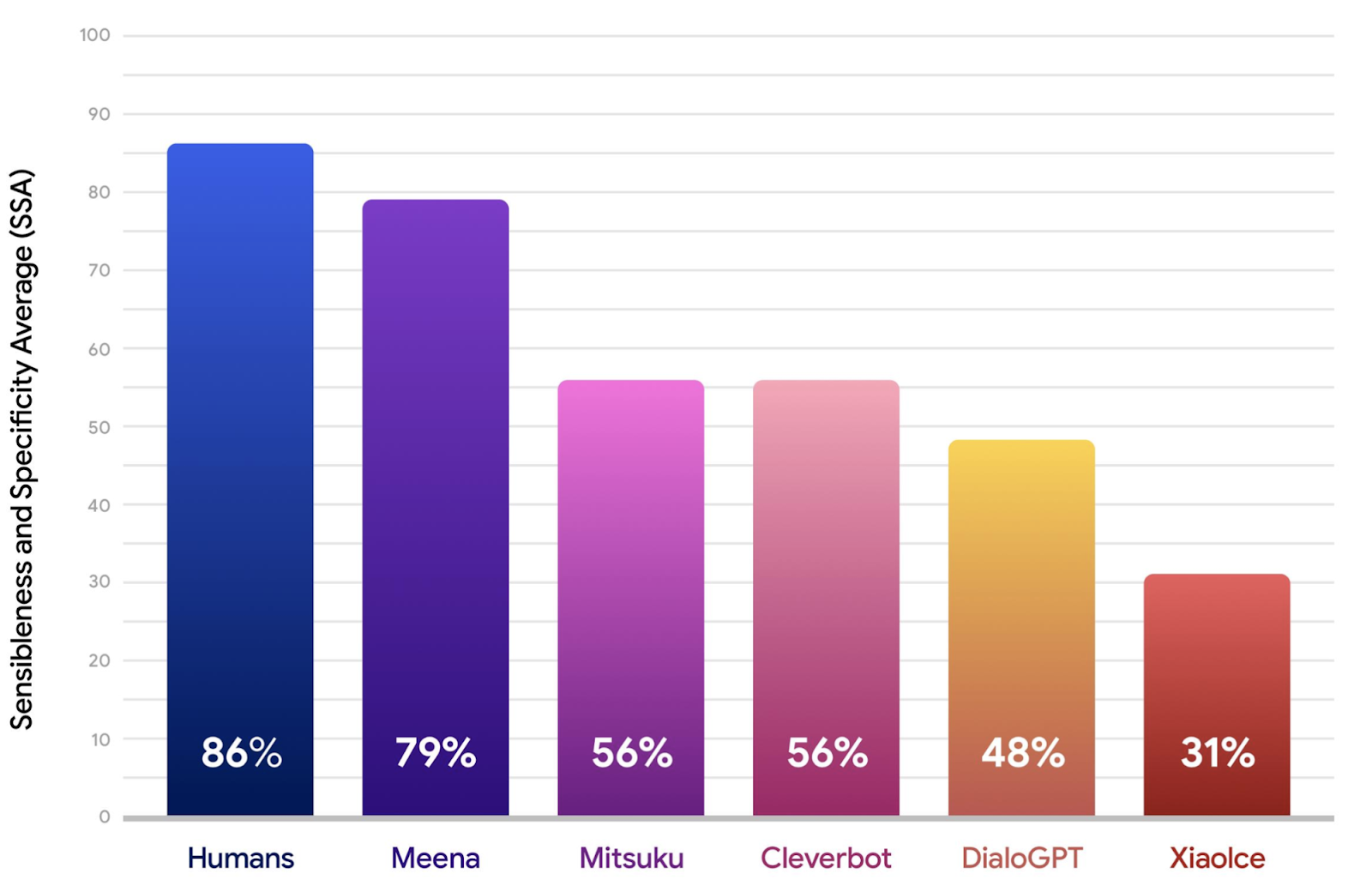
Meena Sensibleness, Specificity, SSA. , , Meena .
ppl SSA, , .
7. Positive Algorithmic Bias Cannot Stop Fragmentation in Homophilic Social Networks
: Christian Blex, Taha Yasseri (Oxford, London, UK, 2020)
: ( sem)
TL;DR
. , preferential attchment , . . , . , .
: , . . ( , ) "" . , . "" , "" . , , (aka ). , ( ), , 0.5.
:
:
( ) , , , , , : . , , ? ? , .
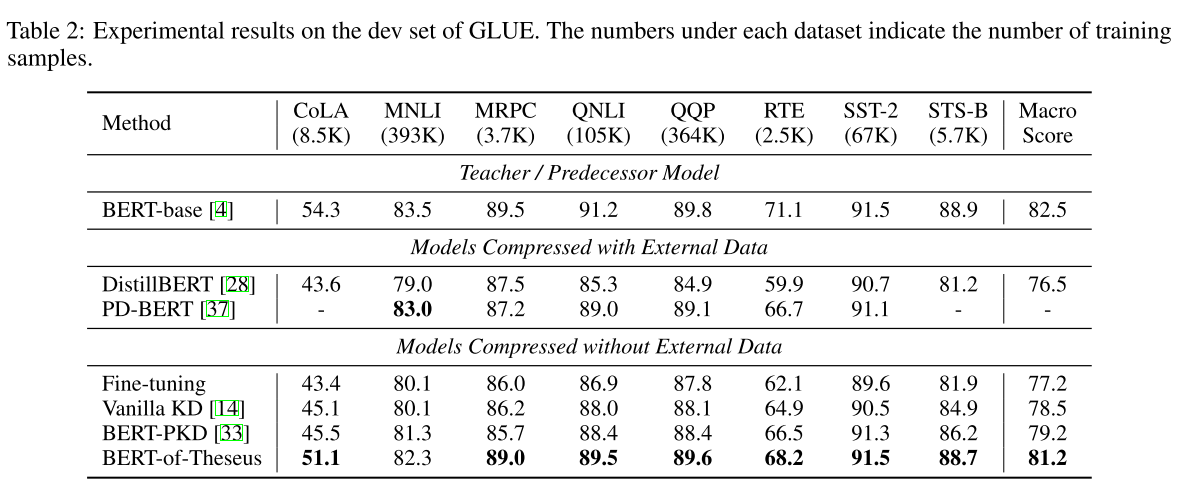
8. BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
: Canwen Xu, Wangchunshu Zhou, Tao Ge, Furu Wei, Ming Zhou (Wuhan and Beihang Universities, Microsoft Research Asia, 2020)
:: GitHub project
: ( belskikh)
Knowledge Distillation BERT, x1.98 98% ( ). , model-agnostic - distillation , end-to-end. ( , ?) Theseus Compression.
, , , "" -. , , . predecessor, - — successor ( teacher-student)
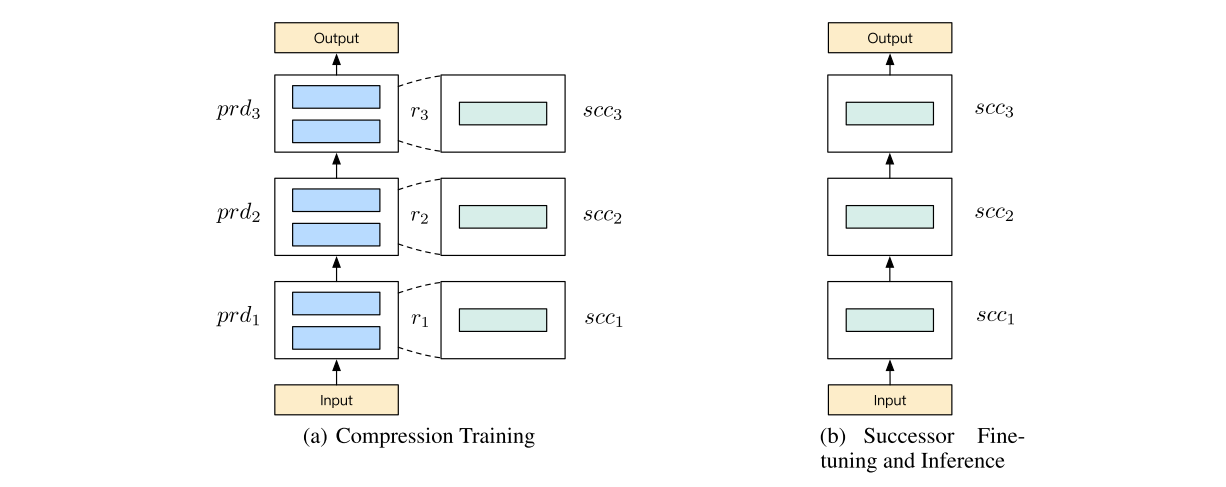
forward p, . , predecessor, successor.
, successor, predessor (.. ). task-specific , CE, BCE, whatever, .
— . .
knowledge distillation ( ). , .
9. A Simple Framework for Contrastive Learning of Visual Representations
: Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton (Google Research, 2020)
:: GitHub project
: ( belskikh)
TL;DR
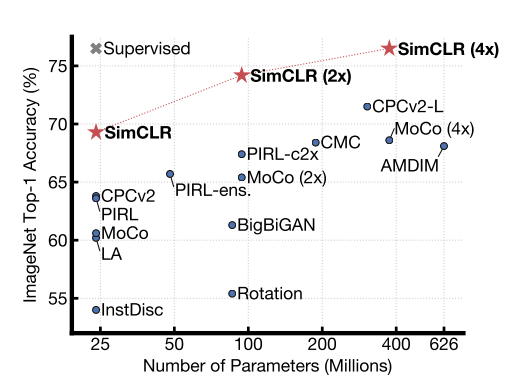
representation learning ( semi-supervised self-supervised) Google Brain, , representation learning
( — ) SimCLR (simple framework for contrastive learning of visual representation), , 76.5% -1 . 1% , 85.8% -5 .
, :
- MLP , ,
- contrastive learning , .
:
- N
- ( (+, , )
- - ( ResNet)
- projection head ( MLP) ,
- ( )
. 2N 2(N-1) . :
sim — cosine similarity , 1 — , , similarity ( 1=1 if k!=i), t — . NT-Xent (the normalized temperature-scaled cross entropy loss).
, 256 8192. SGD , LARS. Cloud TPU, 32 128 ( ). 128 TPUv3 1.5 ResNet-50 4096, 100 .
, , :
projection head:
:
12 ( Imagenet) supervised . - , 10 12.
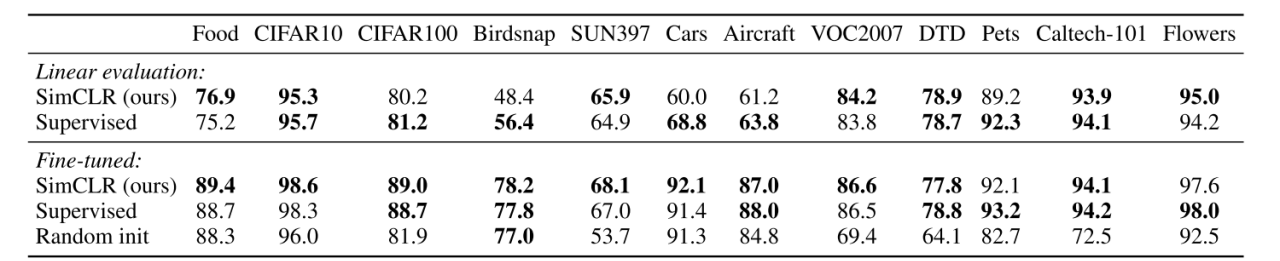
, , , self-supervised
10. BADGR: An Autonomous Self-Supervised Learning-Based Navigation System
: Gregory Kahn, Pieter Abbeel, Sergey Levine (Berkeley AI Research, USA, 2020)
:: GitHub project :: Video
: ( belskikh)
, , . , , — , . , BADGR—Berkeley Autonomous Driving Ground Robot.
, , , , , .. . , ( — ). CNN-LSTM , , .
Cearpath Jackak, 6-DOF IMU sensors + GPS + wheel velocity sensors. 170 deg FOV 640x480, . NVIDIA jetson TX2 4G , .
42 (34 8 ) , 720 000 . , , .
, (, ).

— GPS , (, ). SLAM-P "" (naive — GPS ). .

11. Training Large Neural Networks with Constant Memory using a New Execution Algorithm
: Bharadwaj Pudipeddi, Maral Mesmakhosroshahi, Jinwen Xi, Sujeeth Bharadwaj (Microsoft, 2020)
: ( belskikh)
TL;DR;
Microsoft 40% /.
. , , , . CPU DRAM ( CPU)
L2L (layer to layer). distributed L2L-p. , distributed , BERT-Large 32, 8GB V100 ( =2)

DeepSpeed , . PyTorch, - , .. forward backward ( ). BERT-Large Huggingface.
:
- Baseline = 2.05sec
- L2L = 2.92sec
- L2L-p = 2.45sec
, BERT 96 , V100 .
(F1 score) (AG — accumulated gradient):

L2L:

, BERT-Large GPU c 35% 32 ( 2 ). , L2L .
( DRAM ) — , , Neaural Architecture Search (NAS)