देश भर में बिक्री कार्यालयों के हजारों प्रबंधक हर दिन हमारे सीआरएम सिस्टम में हजारों संपर्कों को रिकॉर्ड करते हैं - संभावित या पहले से ही हमारे साथ काम करने वाले ग्राहकों के साथ संचार के तथ्य। और इस ग्राहक के लिए आपको पहले ढूंढना होगा, और अधिमानतः बहुत जल्दी। और यह नाम से अक्सर होता है।इसलिए, यह आश्चर्य की बात नहीं है कि, एक बार फिर से लोड किए गए डेटाबेस में से एक "भारी" अनुरोधों का विश्लेषण - हमारे अपने कॉर्पोरेट वीएलएसआई खाते , मैंने "शीर्ष" में पाया " कंपनी कार्ड के लिए नाम से" त्वरित "खोज के लिए एक अनुरोध ।इसके अलावा, एक और जांच में अनुकूलन का एक दिलचस्प उदाहरण और फिर प्रदर्शन में गिरावट का पता चला कई टीमों द्वारा इसके बाद के शोधन में अनुरोध, जिनमें से प्रत्येक ने पूरी तरह से अच्छी तरह से काम किया।0: उपयोगकर्ता क्या चाहता था
[केडीपीवी यहाँ से ]आमतौर पर उपयोगकर्ता का क्या मतलब है जब वह नाम से "त्वरित" खोज करता है? लगभग कभी भी यह एक प्रकार के विकल्प पर "ईमानदार" खोज ... LIKE '%%'नहीं करता है - क्योंकि तब न केवल और , बल्कि यहां तक कि परिणाम भी मिलता है । उपयोगकर्ता का तात्पर्य घरेलू स्तर पर है कि आप उसे शीर्षक में एक शब्द की शुरुआत में एक खोज प्रदान करते हैं और दर्ज किए गए के साथ अधिक प्रासंगिक दिखाते हैं । और इसे लगभग तुरंत करें - इंटरलिअर इनपुट के साथ।''' '''' '1: कार्य को सीमित करें
और इससे भी अधिक, एक व्यक्ति विशेष रूप से प्रवेश नहीं करेगा ' 'ताकि आपको हर शब्द उपसर्ग की खोज करनी पड़े। नहीं, उपयोगकर्ता के लिए पिछले शब्द के लिए त्वरित संकेत का जवाब देना बहुत आसान है, पिछले वाले जानबूझकर "मिस" करने के बजाय - देखें कि कोई भी खोज इंजन कैसे काम करता है।सामान्य तौर पर, किसी कार्य के लिए सही ढंग से तैयार करने की आवश्यकताएं आधे से अधिक समाधान हैं। कभी-कभी उपयोग के मामले का सावधानीपूर्वक विश्लेषण परिणाम को महत्वपूर्ण रूप से प्रभावित कर सकता है ।सार डेवलपर क्या करता है?1.0: बाहरी खोज इंजन
ओह, खोज करना मुश्किल है, मैं कुछ भी नहीं करना चाहता हूं - चलो इसे देवो को दें! उन्हें डेटाबेस के सापेक्ष एक बाहरी खोज इंजन में तैनात करें: स्फिंक्स, इलास्टिकसर्च, ... एककाम, यद्यपि समय लेने वाली, तुल्यकालन और परिवर्तन की गति के विकल्प में। लेकिन हमारे मामले में नहीं, क्योंकि खोज प्रत्येक ग्राहक के लिए उसके खाते के डेटा के ढांचे के भीतर की जाती है। और डेटा में एक उच्च परिवर्तनशीलता है - और अगर प्रबंधक ने अब कार्ड डाला है ' ', तो 5-10 सेकंड के बाद वह पहले से ही याद रख सकता है कि वह ईमेल को इंगित करना भूल गया है और इसे ढूंढना और ठीक करना चाहता है।इसलिए - चलो "डेटाबेस में सीधे खोजें" । सौभाग्य से, PostgreSQL हमें यह करने की अनुमति देता है, और केवल एक विकल्प नहीं है - हम उन पर विचार करेंगे।1.1: "ईमानदार" विकल्प
हम "सब्स्ट्रिंग" शब्द से चिपके हुए हैं। लेकिन वास्तव में (और यहां तक कि नियमित अभिव्यक्तियों द्वारा भी) अनुक्रमणिका खोज के लिए एक उत्कृष्ट मॉड्यूल है pg_trgm ! इसके बाद ही सही ढंग से छांटना जरूरी होगा।आइए मॉडल की सादगी के लिए एक प्लेट लेने की कोशिश करें:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
हम वास्तविक संगठनों और सूचकांक के 7.8 मिलियन रिकॉर्ड भरते हैं:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
इंटरलाइन खोज के लिए पहले 10 प्रविष्टियों के लिए आइए देखें:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
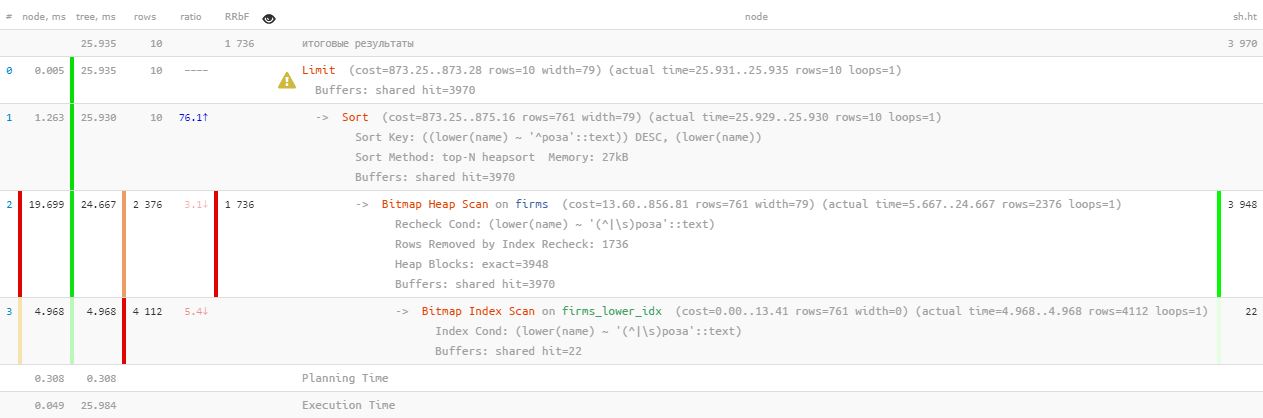 [ स्पष्टीकरण पर एक नज़र डालें। Tensor.ru ] ठीक है, कि ... 26ms, रीड डेटा के 31MB और 1.7K से अधिक फ़िल्टर किए गए रिकॉर्ड - 10 लोगों के लिए। ओवरहेड बहुत अधिक है, क्या किसी तरह अधिक कुशल होना संभव है?
[ स्पष्टीकरण पर एक नज़र डालें। Tensor.ru ] ठीक है, कि ... 26ms, रीड डेटा के 31MB और 1.7K से अधिक फ़िल्टर किए गए रिकॉर्ड - 10 लोगों के लिए। ओवरहेड बहुत अधिक है, क्या किसी तरह अधिक कुशल होना संभव है?1.2: पाठ खोज? यह FTS है!
दरअसल, PostgreSQL उपसर्ग खोज की संभावना सहित पूर्ण पाठ खोज (पूर्ण पाठ खोज) के लिए एक बहुत शक्तिशाली तंत्र प्रदान करता है । एक बढ़िया विकल्प, यहां तक कि एक्सटेंशन को भी स्थापित करने की आवश्यकता नहीं है! कोशिश करते हैं:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [ स्पष्टीकरणपर देखें ।ensor.ru ] यहाँ क्वेरी निष्पादन के समानांतरकरण ने हमें थोड़ा मदद की, समय को आधा से 11ms कम कर दिया । हां, और हमें 1.5 गुना कम पढ़ना था - केवल 20MB । और यहाँ, छोटा बेहतर है, क्योंकि हम जितना बड़ा घटाते हैं, कैश मिस होने की संभावना उतनी ही अधिक होती है, और डिस्क से पढ़ा गया हर अतिरिक्त डेटा पेज अनुरोध के लिए एक संभावित "ब्रेक" है।
[ स्पष्टीकरणपर देखें ।ensor.ru ] यहाँ क्वेरी निष्पादन के समानांतरकरण ने हमें थोड़ा मदद की, समय को आधा से 11ms कम कर दिया । हां, और हमें 1.5 गुना कम पढ़ना था - केवल 20MB । और यहाँ, छोटा बेहतर है, क्योंकि हम जितना बड़ा घटाते हैं, कैश मिस होने की संभावना उतनी ही अधिक होती है, और डिस्क से पढ़ा गया हर अतिरिक्त डेटा पेज अनुरोध के लिए एक संभावित "ब्रेक" है।1.3: अभी भी पसंद है?
पिछला अनुरोध सभी के लिए अच्छा है, लेकिन केवल यदि आप इसे दिन में एक लाख बार खींचते हैं, तो रीड डेटा के 2TB तक चलेगा । सबसे अच्छे रूप में - मेमोरी से, लेकिन अगर आप भाग्यशाली नहीं हैं, तो डिस्क से। तो चलिए इसे छोटा बनाने की कोशिश करते हैं।याद रखें कि उपयोगकर्ता पहले "जो शुरू होता है ..." देखना चाहता है । तो यह अपने शुद्ध रूप में एक उपसर्ग खोज के साथ है text_pattern_ops! और केवल अगर हम 10 आवश्यक रिकॉर्ड तक "पर्याप्त नहीं" हैं, तो हमें एफटीएस खोज का उपयोग करके उन्हें पढ़ना होगा:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
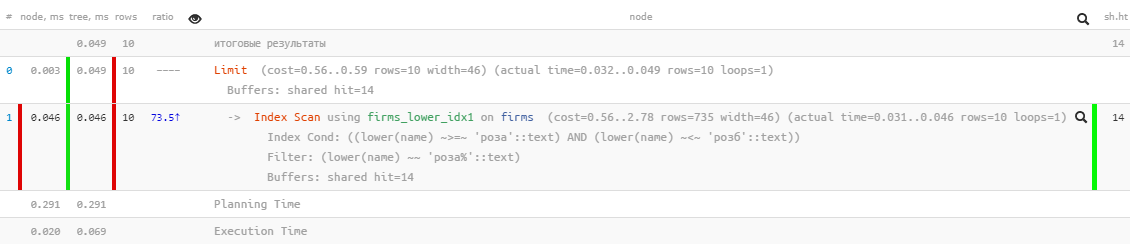 [ स्पष्टीकरण पर देखें ।ensor.ru ]उत्कृष्ट प्रदर्शन - सिर्फ 0.05ms और थोड़ा अधिक 100KB पढ़ें! केवल हम नाम से सॉर्ट करना भूल गए ताकि उपयोगकर्ता परिणामों में खो न जाए:
[ स्पष्टीकरण पर देखें ।ensor.ru ]उत्कृष्ट प्रदर्शन - सिर्फ 0.05ms और थोड़ा अधिक 100KB पढ़ें! केवल हम नाम से सॉर्ट करना भूल गए ताकि उपयोगकर्ता परिणामों में खो न जाए:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
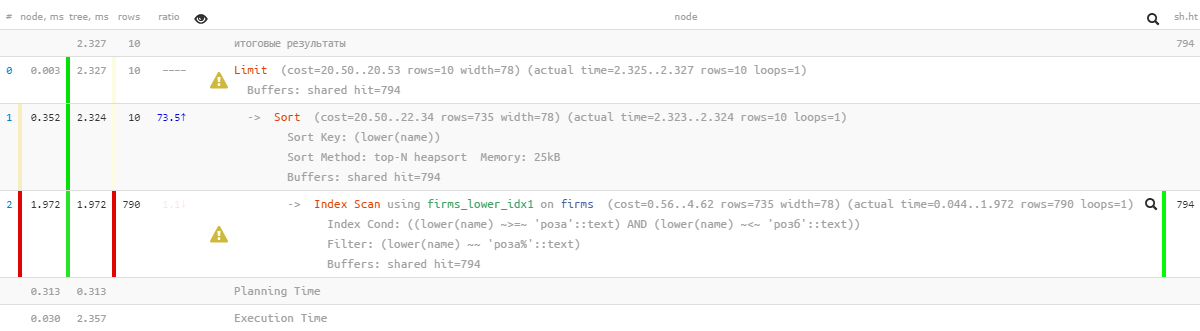 [Expl.t.toror.ru पर देखें]ओह, अब कुछ बहुत सुंदर नहीं है - ऐसा लगता है कि एक सूचकांक है, लेकिन यह पिछले मक्खियों को छांट रहा है ... यह, निश्चित रूप से, पिछले संस्करण की तुलना में पहले से कई गुना अधिक प्रभावी है, लेकिन ...
[Expl.t.toror.ru पर देखें]ओह, अब कुछ बहुत सुंदर नहीं है - ऐसा लगता है कि एक सूचकांक है, लेकिन यह पिछले मक्खियों को छांट रहा है ... यह, निश्चित रूप से, पिछले संस्करण की तुलना में पहले से कई गुना अधिक प्रभावी है, लेकिन ...1.4: "एक फ़ाइल के साथ संशोधित करें"
लेकिन एक सूचकांक है जो आपको रेंज द्वारा खोज करने की अनुमति देता है, और छँटाई का उपयोग करना सामान्य है - सामान्य बीट्री !CREATE INDEX ON firms(lower(name));
इसके लिए केवल एक अनुरोध "मैन्युअल रूप से इकट्ठे" होना होगा:SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [स्पष्टीकरण पर देखें ।ensor.ru]महान - दोनों छँटाई काम करता है और संसाधन खपत "सूक्ष्म" रहता है, "शुद्ध" एफटीएस की तुलना में हजारों गुना अधिक कुशल है ! यह एक ही अनुरोध में एकत्र करने के लिए बनी हुई है:
[स्पष्टीकरण पर देखें ।ensor.ru]महान - दोनों छँटाई काम करता है और संसाधन खपत "सूक्ष्म" रहता है, "शुद्ध" एफटीएस की तुलना में हजारों गुना अधिक कुशल है ! यह एक ही अनुरोध में एकत्र करने के लिए बनी हुई है:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
मैं ध्यान दें कि दूसरे सबक्वेरी है केवल निष्पादित करता है, तो पहले की तुलना में कम लौटेLIMIT पंक्तियों की संख्या से उम्मीद पिछले । मैंने पहले ही क्वेरी ऑप्टिमाइज़ेशन के इस तरीके के बारे में लिखा था ।तो हां, हमारे पास अब एक ही समय पर टेबल पर बीटीआरआई और जिन है, लेकिन सांख्यिकीय रूप से यह पता चला है कि 10% से कम अनुरोध दूसरे ब्लॉक तक पहुंचते हैं । यही है, कार्य के लिए इस तरह की प्रसिद्ध विशिष्ट सीमाओं के साथ, हम कुल सर्वर संसाधन खपत को लगभग एक हजार गुना कम करने में सक्षम थे!1.5 *: फाइल के साथ डिस्पेंस
ऊपर LIKEहमें गलत प्रकार का उपयोग करने से रोका गया था। लेकिन यह USING स्टेटमेंट को निर्दिष्ट करके "सही रास्ते पर सेट" किया जा सकता है:डिफ़ॉल्ट निहित है ASC। इसके अलावा, आप एक वाक्य में एक विशिष्ट प्रकार के ऑपरेटर का नाम निर्दिष्ट कर सकते हैं USING। सॉर्ट ऑपरेटर बी-ट्री ऑपरेटरों के एक निश्चित परिवार से कम या अधिक का सदस्य होना चाहिए। ASCआमतौर पर समतुल्य USING <और DESCआमतौर पर समतुल्य USING >।
हमारे मामले में, "कम" है ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [स्पष्टीकरण देखें ।ensor.ru]
[स्पष्टीकरण देखें ।ensor.ru]2: कैसे "खट्टा" अनुरोध करने के लिए
अब हम आधे साल या एक साल के लिए "आग्रह" करने के लिए अपना अनुरोध छोड़ देते हैं, और आश्चर्य के साथ हम इसे फिर से "शीर्ष" में पाते हैं , जो कि 5.5TB में मेमोरी ( बफ़र्स साझा हिट ) के कुल दैनिक "पम्पिंग" के संकेतक के साथ है - अर्थात, यह मूल रूप से भी अधिक था। नहीं, निश्चित रूप से, हमारा व्यवसाय बढ़ा है, और भार में वृद्धि हुई है, लेकिन इतना नहीं! तो यहाँ कुछ गंदा है - आइए इसे समझें।२.१: पेजिंग का जन्म
कुछ बिंदु पर, एक अन्य विकास टीम उसी के साथ एक त्वरित सबस्क्रिप्ट खोज से रजिस्ट्री में "कूद" करना संभव बनाना चाहती थी, लेकिन परिणामों का विस्तार किया। और पेज नेविगेशन के बिना क्या रजिस्ट्री? चलो इसे पेंच!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
अब डेवलपर के लिए "टाइप-पेज" लोडिंग के साथ खोज परिणामों की रजिस्ट्री दिखाने के लिए दबाव डाले बिना संभव था।बेशक, वास्तव में, डेटा के प्रत्येक अगले पृष्ठ के लिए, अधिक से अधिक पढ़ा जा रहा है (पिछली बार के सभी, जिसे हम त्याग देते हैं, साथ ही वांछित "पूंछ") - अर्थात, यह एक अस्पष्ट एंटीपैटर्न है। और इंटरफ़ेस में संग्रहीत कुंजी से अगले पुनरावृत्ति पर खोज शुरू करना अधिक सही होगा, लेकिन इसके बारे में - एक और समय।२.२: विदेशी चाहिए
कुछ बिंदु पर, डेवलपर दूसरे तालिका से डेटा के साथ परिणामी चयन में विविधता लाना चाहता था , जिस उद्देश्य के लिए पूरे पिछले अनुरोध को CTE को भेजा गया था:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
और यहां तक कि - बुरा नहीं है, क्योंकि एक उपश्रेणी की गणना केवल 10 रिटर्न रिकॉर्ड के लिए की जाती है, यदि नहीं ...2.3: DISTINCT अर्थहीन और निर्दयी है
इस तरह के एक विकास की प्रक्रिया में कहीं, एक स्थिति 2 वें उप-क्षेत्र से खोNOT LIKE गई थी । यह स्पष्ट है कि उसके बाद मैंने दो बार कुछ रिकॉर्डUNION ALL वापस करना शुरू किया - पहली बार लाइन की शुरुआत में पाया, और फिर फिर से - इस लाइन के पहले शब्द की शुरुआत में। सीमा में, द्वितीय उपवर्ग के सभी रिकॉर्ड पहले के रिकॉर्ड के साथ मेल खा सकते थे।एक डेवलपर एक कारण की तलाश करने के बजाय क्या करता है? .. कोई सवाल नहीं!- मूल नमूनों का आकार दोगुना
- DISTINCT लगाएं ताकि हमें प्रत्येक पंक्ति के केवल एक ही उदाहरण मिलें
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
यही है, यह स्पष्ट है कि परिणाम, अंत में, बिल्कुल वैसा ही है, लेकिन 2 सीटीई उप-वर्ग के लिए "उड़ान" करने का मौका बहुत अधिक हो गया है, और इसके बिना, यह स्पष्ट रूप से अधिक पढ़ा जाता है ।लेकिन यह सबसे दुखद बात नहीं है। चूंकि डेवलपर ने मुझे चुनने के लिए कहा, DISTINCTन कि विशिष्ट द्वारा, बल्कि तुरंत रिकॉर्ड के सभी क्षेत्रों द्वारा , उप_क्षेत्र क्षेत्र, उपश्रेणी का परिणाम, स्वचालित रूप से वहां भी मिला। अब, निष्पादन के लिए DISTINCT, डेटाबेस को 10 उपश्रेणियों को निष्पादित नहीं करना था , लेकिन सभी <2 * N> + 10 !2.4: सब से ऊपर सहयोग!
इसलिए, डेवलपर्स रहते थे - वे परेशान नहीं थे, क्योंकि रजिस्ट्री में उन्हें प्रत्येक अगले "पृष्ठ" को प्राप्त करने में पुरानी मंदी के साथ महत्वपूर्ण एन मूल्यों के लिए "पैच अप" किया गया था।जब तक किसी अन्य विभाग के डेवलपर्स उनके पास नहीं आए, और पुनरावृत्ति खोज के लिए इस तरह की एक सुविधाजनक विधि का उपयोग नहीं करना चाहते थे - अर्थात् , हम कुछ नमूने से एक टुकड़ा लेते हैं, अतिरिक्त परिस्थितियों से फ़िल्टर करते हैं, परिणाम आकर्षित करते हैं, फिर अगला टुकड़ा (जो हमारे मामले में प्राप्त होता है) एन) को बढ़ाएं, और इसी तरह जब तक हम स्क्रीन को भरते हैं।सामान्य तौर पर, पकड़े गए नमूने में एन लगभग 17K के मूल्यों तक पहुंच गया , और केवल 24 घंटों में कम से कम 4K ऐसे अनुरोधों को "श्रृंखला में" निष्पादित किया गया। उनमें से आखिरी ने साहसपूर्वक पहले ही स्कैन कर लियाप्रत्येक पुनरावृत्ति में 1GB मेमोरी ...