मुझे लंबे समय से हैव आई बी पीनड (HIBP) साइट के बारे में पता है । यह सच है कि हाल तक, वह कभी नहीं था। मेरे पास हमेशा दो पासवर्ड थे। उनमें से एक को बार-बार कचरा मेल और अजीब साइटों पर कुछ खातों के लिए इस्तेमाल किया गया था। लेकिन मुझे इसे मना करना पड़ा, क्योंकि मेल हैक हो गया था। और ईमानदार होने के लिए, मैं हैकर का आभारी हूं क्योंकि इस घटना ने मेरे पासवर्ड की समीक्षा की - जिस तरह से मैं उनका उपयोग करता हूं और उन्हें संग्रहीत करता हूं।बेशक, मैंने उन सभी खातों पर पासवर्ड बदल दिए, जहां समझौता पासवर्ड था। तब मुझे आश्चर्य हुआ कि क्या लीक पासवर्ड HIBP डेटाबेस में था। मैं साइट पर पासवर्ड दर्ज नहीं करना चाहता था, इसलिए मैंने डेटाबेस डाउनलोड किया (pwned-passwords-sha1-ordered-by-count-v5) आधार बहुत प्रभावशाली है। यह SHA-1 हैश के सेट के साथ 22.8 जीबी की टेक्स्ट फ़ाइल है, प्रत्येक पंक्ति में एक काउंटर के साथ है, लीक में इस हैश के साथ पासवर्ड कितनी बार हुआ। मैंने अपने फटे हुए पासवर्ड के SHA-1 का पता लगाया और उसे खोजने की कोशिश की।अंतर्वस्तु
[जी] प्रतिनिधि
हमारे पास प्रत्येक पंक्ति में एक हैश के साथ एक पाठ फ़ाइल है। शायद जाने के लिए सबसे अच्छी जगह है grep।grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtमेरा पासवर्ड 1,500 से अधिक बार की आवृत्ति के साथ सूची में सबसे ऊपर था, इसलिए यह वास्तव में बेकार है। तदनुसार, खोज परिणाम लगभग तुरंत लौट आए।लेकिन सभी के पास कमजोर पासवर्ड नहीं हैं। मैं यह जांचना चाहता था कि सबसे खराब स्थिति को खोजने में कितना समय लगेगा - फाइल में अंतिम हैश:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtपरिणाम: 33,35s user 23,39s system 41% cpu 2:15,35 totalयह दुखद है। आखिरकार, चूंकि मेरा मेल हैक हो गया था, मैं डेटाबेस में अपने सभी पुराने और नए पासवर्डों की उपस्थिति की जांच करना चाहता था। लेकिन दो मिनट का ग्रीप बस आपको आराम से ऐसा करने की अनुमति नहीं देता है। बेशक, मैं एक स्क्रिप्ट लिख सकता था, इसे चला सकता था और टहलने जा सकता था, लेकिन यह कोई विकल्प नहीं है। मैं एक बेहतर समाधान खोजना चाहता था और कुछ सीखना चाहता था।त्रि संरचना
पहला विचार एक त्रि डेटा संरचना का उपयोग करना था। संरचना SHA-1 हैश के भंडारण के लिए आदर्श लगती है। वर्णमाला छोटी है, इसलिए परिणामी फ़ाइल के रूप में नोड्स भी छोटे होंगे। शायद यह रैम में भी फिट बैठता है? कुंजी खोज बहुत तेज होनी चाहिए।इसलिए मैंने इस ढांचे को लागू किया। तब उन्होंने परिणामी फ़ाइल बनाने और जाँचने के लिए कि क्या बनाई गई फ़ाइल में सब कुछ है, स्रोत डेटाबेस का पहला 1,000,000 हैश लिया।हां, मुझे फ़ाइल में सब कुछ मिल सकता है, इसलिए संरचना ने अच्छी तरह से काम किया। समस्या अलग थी।परिणामी फ़ाइल 2283686592B (2.2 जीबी) आकार में जारी की गई थी। यह अच्छा नहीं है। आइए गिनें और देखें कि क्या होता है। एक नोड सोलह 32-बिट मानों की एक सरल संरचना है। मान निर्दिष्ट SHA-1 हैश प्रतीक के साथ निम्न नोड्स के "पॉइंटर्स" हैं। तो, एक नोड 16 * 4 बाइट्स = 64 बाइट्स लेता है। यह एक छोटा सा लगता है? लेकिन अगर आप इसके बारे में सोचते हैं, तो एक नोड एक हैश में एक चरित्र का प्रतिनिधित्व करता है। इस प्रकार, सबसे खराब स्थिति में, SHA-1 हैश 40 * 64 बाइट्स = 2560 बाइट्स लेगा। यह तुलना में बहुत खराब है, उदाहरण के लिए, एक हैश का एक पाठीय प्रतिनिधित्व जो केवल 40 बाइट्स लेता है।तीनों संरचना में नोड्स के पुन: उपयोग का लाभ है। यदि आपके पास दो शब्द हैं aaaऔर abb, तो पहले वर्णों के लिए नोड पुन: उपयोग किया जाता है, क्योंकि वर्ण समान हैं - a।आइए हम अपनी समस्या पर वापस आते हैं। आइए गणना करें कि परिणामी फ़ाइल में कितने नोड संग्रहीत हैं: file_size / node_size = 2283686592 / 64 = 35682603अब देखते हैं कि एक लाख हैश से सबसे खराब स्थिति में कितने नोड बनाए जाएंगे: 1000000 * 40 = 40000000इस प्रकार, त्रि संरचना केवल 40000000 - 35682603 = 4317397नोड्स का पुन: उपयोग करती है, जो कि सबसे खराब स्थिति का 10.8% है।ऐसे संकेतकों के साथ, पूरे एचआईबीपी डेटाबेस के लिए परिणामी फाइल 1421513361920 बाइट्स (1.02 टीबी) लेगी। कुंजी खोज की गति की जांच करने के लिए मेरे पास पर्याप्त हार्ड ड्राइव नहीं है।उस दिन, मुझे पता चला कि त्रिक संरचना अपेक्षाकृत यादृच्छिक डेटा के लिए उपयुक्त नहीं है।आइए दूसरे उपाय की तलाश करें।द्विआधारी खोज
SHA-1 हैश में दो अच्छी विशेषताएं हैं: वे एक दूसरे के लिए तुलनीय हैं और वे सभी एक ही आकार के हैं।इसके लिए धन्यवाद, हम मूल HIBP डेटाबेस को संसाधित कर सकते हैं और सॉर्ट किए गए SHA-1 मानों से एक फ़ाइल बना सकते हैं।लेकिन 22 जीबी फाइल कैसे छांटें?सवाल। स्रोत फ़ाइल क्यों सॉर्ट करें? HIBP हैश द्वारा पहले से छंटे तार के साथ एक फाइल लौटाता है।
उत्तर। मैंने अभी इसके बारे में नहीं सोचा था। उस पल में मुझे हल की गई फाइल के बारे में नहीं पता था।छंटाई
RAM में सभी हैश को छांटना एक विकल्प नहीं है, मेरे पास ज्यादा RAM नहीं है। समाधान यह था:- रैम में फिट होने वाली बड़ी फ़ाइल को छोटे में विभाजित करें।
- छोटी फ़ाइलों से डेटा डाउनलोड करें, रैम में सॉर्ट करें और फ़ाइलों पर वापस लिखें।
- एक बड़े में सभी छोटे, क्रमबद्ध फ़ाइलों को मिलाएं।
एक बड़ी छँटाई फ़ाइल के साथ, आप एक बाइनरी खोज का उपयोग करके हमारे हैश की खोज कर सकते हैं। हार्ड ड्राइव पहुंच मायने रखती है। आइए गणना करें कि बाइनरी खोज में कितने हिट आवश्यक हैं: log2(555278657) = 29.0486367039अर्थात, 30 हिट। इतना बुरा नहीं।पहले चरण में, अनुकूलन प्रदर्शन किया जा सकता है। टेक्स्ट हैश को बाइनरी डेटा में बदलें। इससे परिणामी डेटा का आकार आधे से कम हो जाएगा: 22 से 11 जीबी तक। ठीक।वापस क्यों मिला?
उस पल, मुझे एहसास हुआ कि आप और अधिक स्मार्ट हो सकते हैं। क्या होगा यदि आप छोटी फ़ाइलों को एक बड़े में संयोजित नहीं करते हैं, लेकिन रैम में छँटाई गई छोटी फ़ाइलों में एक द्विआधारी खोज का संचालन करते हैं? समस्या यह है कि कुंजी फ़ाइल को कैसे खोजना है जिसमें कुंजी की तलाश है। समाधान बहुत सरल है। नया दृष्टिकोण:- "00" ... "एफएफ" नामों के साथ 256 फाइलें बनाएं।
- बड़ी फ़ाइल से हैश पढ़ते समय, "00 .." से शुरू होने वाली फ़ाइल को "00", हैश कि "01 .." के साथ शुरू होने वाली हैश - एक फ़ाइल "01" और इसी तरह से शुरू करें।
- छोटी फ़ाइलों से डेटा डाउनलोड करें, रैम में सॉर्ट करें और फ़ाइलों पर वापस लिखें।
सब कुछ बहुत सरल है। इसके अलावा, एक और अनुकूलन विकल्प दिखाई देता है। यदि हैश फ़ाइल "00" में संग्रहीत है, तो हम जानते हैं कि यह "00" से शुरू होता है। यदि हैश फ़ाइल "F2" में संग्रहीत किया जाता है, तो यह "F2" से शुरू होता है। इस प्रकार, जब छोटी फाइलों में हैश लिखते हैं, तो हम प्रत्येक हैश के पहले बाइट को छोड़ सकते हैं! यह सभी डेटा का 5% है। कुल 555 MB बच गया है।समानता
छोटी फ़ाइलों में पृथक्करण अनुकूलन के लिए एक और अवसर प्रदान करता है। फाइलें एक दूसरे से स्वतंत्र हैं, इसलिए हम उन्हें समानांतर में सॉर्ट कर सकते हैं। हमें याद है कि आपके सभी प्रोसेसर एक ही समय में पसीना करना पसंद करते हैं;)एक स्वार्थी कमीने मत बनो
जब मैंने उपरोक्त समाधान को लागू किया, तो मुझे महसूस हुआ कि अन्य लोगों को भी शायद इसी तरह की समस्या थी। संभवतः कई अन्य लोग भी HIBP डेटाबेस को डाउनलोड और खोज करते हैं। इसलिए मैंने अपना काम साझा करने का फैसला किया।इससे पहले, मैंने एक बार फिर से अपने दृष्टिकोण को संशोधित किया और कुछ समस्याएं पाईं जिन्हें मैं गिथब पर कोड और टूल पोस्ट करने से पहले ठीक करना चाहूंगा।सबसे पहले, एक अंतिम उपयोगकर्ता के रूप में, मैं एक उपकरण का उपयोग नहीं करना चाहूंगा जो अजीब नामों के साथ कई अजीब फाइलें बनाता है, जिसमें यह स्पष्ट नहीं है कि क्या संग्रहीत है, आदि।ठीक है, इसे "00" .. "FF" फाइलों के संयोजन से हल किया जा सकता है। एक बड़ी फ़ाइल।दुर्भाग्य से, छँटाई के लिए एक बड़ी फ़ाइल होने से एक नई समस्या खड़ी हो जाती है। यदि मैं इस फ़ाइल में हैश सम्मिलित करना चाहता हूँ तो क्या होगा? बस एक हैश। यह केवल 20 बाइट्स है। ओह, हैश "000000000 .." से शुरू होता है। ठीक है। आइए 11 जीबी की अन्य हैश को स्थानांतरित करके इसके लिए स्थान खाली करें ...आप समझते हैं कि समस्या क्या है। किसी फ़ाइल के बीच में डेटा डालना सबसे तेज़ ऑपरेशन नहीं है।इस दृष्टिकोण का एक और दोष यह है कि आपको पहले बाइट्स को फिर से स्टोर करने की आवश्यकता है - यह 555 एमबी डेटा है।और अंतिम लेकिन कम से कम नहीं, हार्ड ड्राइव पर संग्रहीत डेटा पर एक द्विआधारी खोज रैम तक पहुँचने की तुलना में बहुत धीमी है। मेरा मतलब है, यह 30 डिस्क रीड्स बनाम 0 डिस्क रीड्स है।बी 3
फिर। हमारे पास क्या है और हम क्या हासिल करना चाहते हैं।हमारे पास 11 जीबी के बाइनरी मान हैं। सभी मूल्य तुलनीय हैं और समान आकार के हैं। हम यह पता लगाना चाहते हैं कि क्या संग्रहित डेटा में कोई विशेष कुंजी मौजूद है, और डेटाबेस को भी बदलना चाहते हैं। और ताकि सब कुछ जल्दी से काम करे।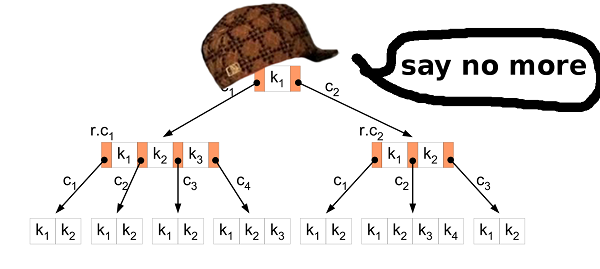 बी पेड़? सहीबी-ट्री आपको खोज, संशोधन आदि के दौरान डिस्क तक पहुंच को कम करने की अनुमति देता है। इसमें बहुत अधिक विशेषताएं हैं, लेकिन हमें इन दोनों की आवश्यकता है।
बी पेड़? सहीबी-ट्री आपको खोज, संशोधन आदि के दौरान डिस्क तक पहुंच को कम करने की अनुमति देता है। इसमें बहुत अधिक विशेषताएं हैं, लेकिन हमें इन दोनों की आवश्यकता है।सम्मिलन सॉर्ट
पहला कदम डेटा को HIBP स्रोत फ़ाइल से बी-ट्री में परिवर्तित करना है। इसका मतलब है कि आपको बारी-बारी से सभी हैश को निकालने और उन्हें संरचना में सम्मिलित करने की आवश्यकता है। सामान्य सम्मिलन एल्गोरिथ्म इसके लिए उपयुक्त है। लेकिन हमारे मामले में, आप बेहतर कर सकते हैं।बी-ट्री में बहुत सारे कच्चे डेटा डालना एक प्रसिद्ध परिदृश्य है। समझदार लोगों ने सामान्य आवेषण की तुलना में इसके लिए एक बेहतर दृष्टिकोण का आविष्कार किया है। सबसे पहले, आपको डेटा को सॉर्ट करने की आवश्यकता है। यह ऊपर वर्णित के रूप में किया जा सकता है (फ़ाइल को छोटे लोगों में विभाजित करें और उन्हें रैम में सॉर्ट करें)। फिर पेड़ में डेटा डालें।सामान्य एल्गोरिथ्म में, यदि आपको वह पत्ता नोड मिलता है, जहाँ आप मान सम्मिलित करना चाहते हैं और वह भरा हुआ है, तो आप एक नया नोड बनाते हैं (दाएं पर) और समान रूप से दो नोड्स के बीच के मानों को वितरित करते हैं, बाएँ और दाएँ (साथ ही एक मान मूल नोड में जाता है) लेकिन यह यहाँ महत्वपूर्ण नहीं है) संक्षेप में, बाएं नोड में मान हमेशा दाईं ओर के मानों से कम होते हैं। तथ्य यह है कि जब आप सॉर्ट किए गए डेटा को सम्मिलित करते हैं, तो आप जानते हैं कि छोटे मूल्यों को अब पेड़ में नहीं डाला जाएगा, इसलिए कोई भी अधिक मूल्य बाएं नोड पर नहीं जाएगा। बायाँ नोड हर समय आधा खाली रहता है। इसके अलावा, यदि आप पर्याप्त मान डालते हैं, तो आप पा सकते हैं कि दायां नोड भरा हुआ है, इसलिए आपको आधे मानों को नई दाईं ओर ले जाने की आवश्यकता है। पिछले मामले की तरह, विभाजित नोड आधा खाली रहता है। आदि…नतीजतन, सभी आवेषण के बाद, आपको एक पेड़ मिलता है जिसमें लगभग सभी नोड्स आधे खाली होते हैं। यह अंतरिक्ष का बहुत कुशल उपयोग नहीं है। हम बेहतर कर सकते हैं।अलग हुआ या नहीं?
सॉर्ट किए गए डेटा डालने के मामले में, आप सम्मिलन एल्गोरिथ्म में एक छोटा संशोधन कर सकते हैं। यदि आप जिस नोड में मान चिपकाना चाहते हैं, वह भरा हुआ है, तो उसे तोड़ें नहीं। बस एक नया, खाली नोड बनाएं और मूल्य को मूल नोड में चिपकाएं। फिर, जब आप निम्न मान सम्मिलित करते हैं (जो पिछले वाले से बड़े होते हैं), तो आप उन्हें एक ताज़ा, खाली नोड में सम्मिलित करते हैं।बी-पेड़ के गुणों को संरक्षित करने के लिए, सभी सम्मिलन के बाद, पेड़ की प्रत्येक परत (जड़ को छोड़कर) में सबसे दाहिने नोड्स को छांटना आवश्यक है और समान रूप से इस चरम नोड और इसके बाएं पड़ोसी के मूल्यों को विभाजित करते हैं। तो आपको सबसे छोटा संभव पेड़ मिलता है।HIBP ट्री गुण
बी-पेड़ को डिजाइन करते समय, आपको इसका क्रम चुनने की आवश्यकता होती है। यह दिखाता है कि एक नोड में कितने मान संग्रहीत किए जा सकते हैं, साथ ही साथ कितने बच्चों के नोड हो सकते हैं। इस पैरामीटर में हेरफेर करके, हम पेड़ की ऊंचाई, नोड के द्विआधारी आकार आदिमें हेरफेर कर सकते हैं 555278657। HIBP में, हमारे पास राख है । मान लें कि हम ऊंचाई में एक पेड़ तीन चाहते हैं (इसलिए हमें हैश की उपस्थिति के लिए जांच करने के लिए तीन से अधिक पढ़ने के संचालन की आवश्यकता नहीं है)। हमें M का ऐसा मान खोजना होगा जो ऐसा हो logM(555278657) < 3। मैंने 1024 को चुना। यह सबसे छोटा संभव मूल्य नहीं है, लेकिन यह अधिक हैश डालना और पेड़ की ऊंचाई को संरक्षित करना संभव बनाता है।आउटपुट फाइल
HIBP स्रोत फ़ाइल का आकार 22.8 GB है। बी-ट्री के साथ आउटपुट फ़ाइल 12.4 जीबी है। मेरी मशीन (Intel Core i7-6700, 3.4 GHz, 16 GB RAM), हार्ड डिस्क (SSD नहीं) पर इसे बनाने में लगभग 11 मिनट लगते हैं।मानक
बी-ट्री विकल्प एक बहुत अच्छा परिणाम दिखाता है:| | समय [μs] | % |
| -----------------: - ------------: | ------------: |
| ओकेन | 49 | 100 |
| grep '^ हैश' | 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++ लाइन द्वारा लाइन | 135'720’201 | 276'980'002 |
okon - पुस्तकालय और सीएलआई
जैसा कि मैंने कहा, मैं अपने काम को दुनिया के साथ साझा करना चाहता था। मैंने HIBP डेटाबेस के प्रसंस्करण के लिए एक पुस्तकालय और कमांड लाइन इंटरफ़ेस लागू किया और जल्दी से हैश की खोज की। खोज इतनी तेज है कि यह, उदाहरण के लिए, एक पासवर्ड मैनेजर में एकीकृत किया जा सकता है और जब भी किसी कुंजी को दबाया जाता है, तो उपयोगकर्ता को प्रतिक्रिया दें। कई संभावित उपयोग हैं।लाइब्रेरी में C इंटरफ़ेस है, इसलिए इसका उपयोग लगभग हर जगह किया जा सकता है। सीएलआई एक सीएलआई है। आप बस बना सकते हैं और चला सकते हैं: (कोड मेरे भंडार में है ।डिस्क्लेमर: ओकेन अभी तक बनाए गए बी-ट्री में मान डालने के लिए एक इंटरफेस प्रदान नहीं करता है। यह केवल HIBP फ़ाइल को संसाधित कर सकता है, एक बी-ट्री बना सकता है और इसमें खोज कर सकता है। ये फ़ंक्शन काफी अच्छी तरह से काम करते हैं, इसलिए मैंने कोड साझा करने का फैसला किया और सम्मिलित और अन्य संभावित कार्यों पर काम करना जारी रखा।लिंक और चर्चा
पढ़ने के लिए धन्यवाद
(: