जब एक और फलदायक वर्ष समाप्त होता है, तो मैं पीछे मुड़कर देखना चाहता हूं, स्टॉक लेता हूं और दिखाता हूं कि इस दौरान हम क्या कर पाए। #DeepPavlov पुस्तकालय, एक मिनट के लिए, पहले से ही दो साल पुराना है, और हमें खुशी है कि हमारा समुदाय हर दिन बढ़ रहा है।पुस्तकालय पर काम के वर्ष में, हमने हासिल किया है:- पिछले साल की तुलना में लाइब्रेरी डाउनलोड में एक तिहाई की वृद्धि हुई है। अब दीपपावलोव के पास 100 हजार से अधिक प्रतिष्ठान और 10 हजार से अधिक कंटेनर प्रतिष्ठान हैं।
- विभिन्न उद्योगों में खुदरा से लेकर उद्योग तक, दीपपावलोव में कार्यान्वित अत्याधुनिक तकनीकों के कारण वाणिज्यिक समाधानों की संख्या में वृद्धि हुई है।
- डीपपावलोव एजेंट की पहली रिलीज जारी की गई है ।
- सक्रिय समुदाय के सदस्यों की संख्या में 5 गुना वृद्धि हुई है।
- हमारी स्नातक और स्नातक छात्रों की टीम को एलेक्सा प्राइज सोशलबोट ग्रैंड चैलेंज 3 में भाग लेने के लिए चुना गया था ।
- लायब्रेरी Google द्वारा संचालित की गई प्रतियोगिता का विजेता बन गया है «Powered by TensorFlow Challenge»।
इस तरह के परिणामों को प्राप्त करने में क्या मदद मिली और क्यों डीपपावलोव संवादी एआई के निर्माण के लिए सबसे अच्छा खुला स्रोत है? हम अपने लेख में बताएंगे।
#DeepPavlov परिणाम के उद्देश्य से
हाल ही में, डायलॉग सिस्टम मानव-मशीन इंटरैक्शन के लिए मानक बन गए हैं। Chatbots का उपयोग लगभग सभी उद्योगों में किया जाता है, लोगों और कंप्यूटरों के बीच बातचीत को सरल बनाता है। वे वेबसाइटों, संदेश प्लेटफार्मों और उपकरणों में मूल रूप से एकीकृत होते हैं। कई कंपनियां आज इंटरएक्टिव सिस्टम को नियमित कार्यों को सौंपना पसंद करती हैं जो एक ही समय में कई उपयोगकर्ता अनुरोधों को संभाल सकती हैं, श्रम लागतों की बचत करती हैं।हालांकि, अक्सर कंपनियां यह नहीं जानती हैं कि अपने व्यवसाय की जरूरतों को पूरा करने के लिए बॉट विकसित करते समय कहां से शुरू करें। ऐतिहासिक रूप से, चैटबॉट को दो बड़े समूहों में विभाजित किया जा सकता है: नियमों पर आधारित और डेटा पर आधारित। पहला प्रकार पूर्वनिर्धारित कमांड और टेम्प्लेट पर निर्भर करता है। इनमें से प्रत्येक कमांड को नियमित अभिव्यक्ति और पाठ डेटा विश्लेषण का उपयोग करके चैटबोट डेवलपर द्वारा लिखा जाना चाहिए। इसके विपरीत, डेटा-चालित चैट बॉट मशीन लर्निंग मॉडल पर भरोसा करते हैं जिन्हें संवाद डेटा पर पूर्व-प्रशिक्षित किया गया है।ओपन सोर्स लाइब्रेरी - दीपपावलोवइंटरैक्टिव सिस्टम के निर्माण के लिए एक मुफ्त और आसान उपयोग समाधान प्रदान करता है। दीपपावलोव प्राकृतिक भाषा प्रसंस्करण (एनएलपी) से जुड़ी समस्याओं को हल करने के लिए कई पूर्व प्रशिक्षित घटकों के साथ आता है। दीपपावलोव समस्याओं का हल करता है जैसे: पाठ का वर्गीकरण, टाइपोस में सुधार, नामित संस्थाओं की मान्यता, ज्ञान के आधार पर प्रश्नों के उत्तर और कई अन्य। और आप रन करके DeepPavlov को एक लाइन में स्थापित कर सकते हैं:pip install -q deeppavlov
* ढांचा आपको मॉडल को प्रशिक्षित करने और परीक्षण करने की अनुमति देता है, साथ ही साथ अपने हाइपरपैरामीटर को भी अनुकूलित करता है। पुस्तकालय लिनक्स और विंडोज प्लेटफॉर्म का समर्थन करता है। आप लाइब्रेरी के डेमो संस्करण में इस और अन्य मॉडलों की कोशिश कर सकते हैं ।वर्तमान में, BERT पर आधारित मॉडलों के उपयोग के माध्यम से कई कार्यों में आधुनिक परिणाम प्राप्त किए गए हैं। दीपपावलोव टीम ने बीईआरटी को निम्नलिखित तीन कार्यों में एकीकृत किया: पाठ वर्गीकरण, नामित संस्थाओं की मान्यता और सवालों के जवाब। परिणामस्वरूप, हमने इन सभी कार्यों में महत्वपूर्ण सुधार किए हैं।1. BERT दीपपावलोव मॉडल
पाठ वर्गीकरण के लिए
BERT BERT DeepPavlov पर आधारित एक पाठ वर्गीकरण मॉडल, उदाहरण के लिए, अपमान का पता लगाने की समस्या को हल करने के लिए कार्य करता है। मॉडल में यह भविष्यवाणी करना शामिल है कि क्या सार्वजनिक चर्चा में प्रकाशित एक टिप्पणी को प्रतिभागियों में से एक के लिए अपमानजनक माना जाता है। इस मामले के लिए, वर्गीकरण केवल दो वर्गों में किया जाता है: अपमान और अपमान नहीं।किसी भी पूर्व-प्रशिक्षित मॉडल को आउटपुट के लिए कमांड लाइन इंटरफ़ेस (सीएलआई) और पायथन के माध्यम से दोनों के लिए उपयोग किया जा सकता है। मॉडल का उपयोग करने से पहले, सुनिश्चित करें कि सभी आवश्यक पैकेज कमांड का उपयोग करके स्थापित किए गए हैं:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
नामांकित इकाई मान्यता के लिए BERT,
पाठ वर्गीकरण मॉडल के अलावा, DeepPavlov में इकाई मान्यता (NER) नाम के लिए BERT- आधारित मॉडल शामिल है। यह एनएलपी में सबसे आम कार्यों में से एक है और हमारे पुस्तकालय का सबसे अधिक इस्तेमाल किया जाने वाला मॉडल है। इसी समय, एनईआर के पास कई व्यावसायिक अनुप्रयोग हैं। उदाहरण के लिए, एक मॉडल मानव संसाधन विशेषज्ञों के काम को सुविधाजनक बनाने के लिए एक फिर से शुरू से महत्वपूर्ण जानकारी निकाल सकता है। इसके अलावा, एनईआर का उपयोग ग्राहकों के अनुरोधों में प्रासंगिक संस्थाओं की पहचान करने के लिए किया जा सकता है, जैसे उत्पाद विनिर्देश, कंपनी के नाम या कंपनी की शाखा की जानकारी।दीपपावलोव टीम ने एनटीओ मॉडल को ओनटोनेट्स अंग्रेजी-भाषा के भवन में प्रशिक्षित किया, जिसमें 19 प्रकार के मार्कअप हैं, जिनमें पेर (व्यक्ति), एलओसी (स्थान), ओआरजी (संगठन) और कई अन्य शामिल हैं। बातचीत करने के लिए, आपको इसे कमांड के साथ इंस्टॉल करना होगा:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
प्रश्नों के उत्तर के लिए BERT एक प्रश्न का एक
प्रासंगिक उत्तर एक दिए गए संदर्भ में एक प्रश्न का उत्तर खोजने का कार्य है (उदाहरण के लिए, विकिपीडिया से एक पैराग्राफ), जहां प्रत्येक प्रश्न का उत्तर एक संदर्भ खंड है। उदाहरण के लिए, संदर्भ, प्रश्न और उत्तर की त्रिभुज प्रश्न का उत्तर देने के कार्य के लिए सही त्रिभुज बनाती है।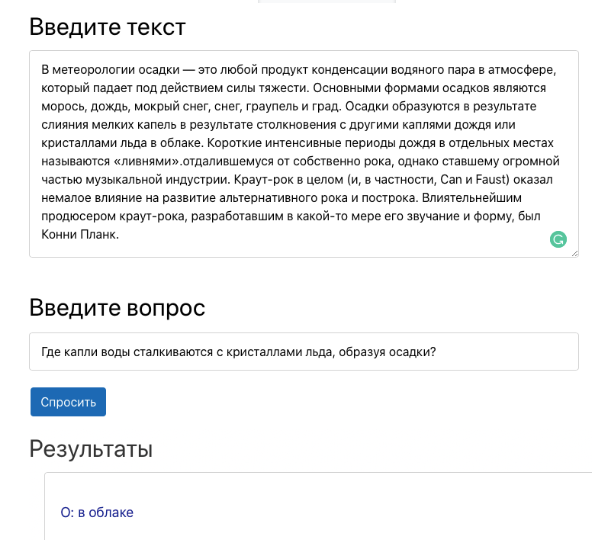 एक डेमो में सवाल-जवाब प्रणाली के काम की प्रस्तुति।सवालों के जवाब की एक प्रणाली एक व्यवसाय में कई प्रक्रियाओं को स्वचालित कर सकती है। उदाहरण के लिए, यह नियोक्ताओं को आंतरिक कंपनी प्रलेखन के आधार पर उत्तर प्राप्त करने में मदद कर सकता है। इसके अलावा, मॉडल छात्रों को सीखने की प्रक्रिया में पाठ को समझने की क्षमता का परीक्षण करने में मदद करेगा। हाल ही में, हालांकि, संदर्भ के आधार पर सवालों के जवाब देने के कार्य ने वैज्ञानिकों का बहुत ध्यान आकर्षित किया है। इस क्षेत्र में महत्वपूर्ण मोड़ में से एक स्टैनफोर्ड प्रश्न उत्तर सेट (SQuAD) का विमोचन था। SQuAD डेटासेट ने सवाल-जवाब प्रणाली की समस्या को हल करने के लिए अनगिनत तरीकों का नेतृत्व किया है। सबसे सफल में से एक डीपपावलोव बीईआरटी मॉडल है। यह अन्य सभी को पीछे छोड़ता है और वर्तमान में मानवीय विशेषताओं पर आधारित परिणाम प्रस्तुत कर रहा है।दीपपावलोव के साथ BERT- आधारित QA मॉडल का उपयोग करने के लिए, आपको यह करना होगा:
एक डेमो में सवाल-जवाब प्रणाली के काम की प्रस्तुति।सवालों के जवाब की एक प्रणाली एक व्यवसाय में कई प्रक्रियाओं को स्वचालित कर सकती है। उदाहरण के लिए, यह नियोक्ताओं को आंतरिक कंपनी प्रलेखन के आधार पर उत्तर प्राप्त करने में मदद कर सकता है। इसके अलावा, मॉडल छात्रों को सीखने की प्रक्रिया में पाठ को समझने की क्षमता का परीक्षण करने में मदद करेगा। हाल ही में, हालांकि, संदर्भ के आधार पर सवालों के जवाब देने के कार्य ने वैज्ञानिकों का बहुत ध्यान आकर्षित किया है। इस क्षेत्र में महत्वपूर्ण मोड़ में से एक स्टैनफोर्ड प्रश्न उत्तर सेट (SQuAD) का विमोचन था। SQuAD डेटासेट ने सवाल-जवाब प्रणाली की समस्या को हल करने के लिए अनगिनत तरीकों का नेतृत्व किया है। सबसे सफल में से एक डीपपावलोव बीईआरटी मॉडल है। यह अन्य सभी को पीछे छोड़ता है और वर्तमान में मानवीय विशेषताओं पर आधारित परिणाम प्रस्तुत कर रहा है।दीपपावलोव के साथ BERT- आधारित QA मॉडल का उपयोग करने के लिए, आपको यह करना होगा:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
प्रलेखन
में अधिक मॉडल पाए जा सकते हैं । और अगर आपको लाइब्रेरी घटकों का उपयोग करने के लिए ट्यूटोरियल की आवश्यकता है, तो हमारे आधिकारिक ब्लॉग में उन्हें देखें ।2. दीपपावलोव एजेंट - मल्टी टास्किंग चैट बॉट बनाने का एक मंच
आज, इंटरैक्टिव एजेंटों के विकास के लिए कई दृष्टिकोण हैं। वार्तालाप एजेंटों को विकसित करते समय, मॉड्यूलर वास्तुकला मुख्य रूप से एक केंद्रित संवाद के लिए उपयोग किया जाता है जिसमें स्क्रिप्ट सामने आती है। हालांकि, अक्सर उपयोगकर्ता को एक केंद्रित संवाद को संयोजित करने की आवश्यकता होती है, उदाहरण के लिए, एक अन्य कार्यक्षमता के साथ - प्रश्नों का उत्तर देना या जानकारी की खोज करना, साथ ही साथ एक वार्तालाप को बनाए रखना। इस प्रकार, आदर्श संवाद एजेंट एक व्यक्तिगत सहायक है जो विभिन्न प्रकार के एजेंटों को जोड़ता है, इसकी कार्यक्षमता और वर्णों के बीच स्विच करता है, जिसके आधार पर यह किस कार्य में उपयोग किया जाता है। उसी समय, एजेंट को अपने सार के बारे में जानकारी जमा करनी होगी, एक विशिष्ट उपयोगकर्ता के लिए अपने एल्गोरिदम को समायोजित करना होगा। दूसरी ओर, यह बाहरी सेवाओं के साथ एकीकृत करने में सक्षम होना चाहिए। उदाहरण के लिए,बाहरी डेटाबेस से पूछताछ करें, वहां से जानकारी प्राप्त करें, इसे संसाधित करें, महत्वपूर्ण को हाइलाइट करें और उपयोगकर्ता को प्रेषित करें। इस समस्या को हल करने के लिए, अक्टूबर 2019 में, मल्टी टास्किंग चैट बॉट्स बनाने के लिए एक मंच, दीपपावलोव एजेंट 1.0 की पहली रिलीज़ जारी की गई। एजेंट प्रोडक्शन चैटबॉट के डेवलपर्स को एक पाइपलाइन में कई एनएलपी मॉडल व्यवस्थित करने में मदद करता है।प्रलेखन
में मंच और सुविधाओं के बारे में और पढ़ें ।3. दीपपावलोव एनएलपी सास का कार्यान्वयन
दीपपावलोव से पूर्व प्रशिक्षित एनएलपी मॉडल के साथ काम को सरल बनाने के लिए, सितंबर 2019 में, सास सेवा शुरू की गई थी। दीपपावलोव क्लाउड आपको टेक्स्ट का विश्लेषण करने की अनुमति देता है, साथ ही क्लाउड में दस्तावेजों को संग्रहीत करता है। मॉडल का उपयोग करने के लिए, आपको हमारी सेवा में पंजीकरण करना होगा और अपने व्यक्तिगत खाते के टोकन अनुभाग में एक टोकन प्राप्त करना होगा। फिलहाल, सेवा रूसी में कई पूर्व प्रशिक्षित एनएलपी मॉडल का समर्थन करती है और सिस्टम के परीक्षण की प्रक्रिया में है।4. DSCT8 या लक्षित संवाद प्रणाली में भागीदारी
अमेज़ॅन एलेक्सा और गूगल असिस्टेंट जैसे आभासी सहायकों के उपयोग ने उन अनुप्रयोगों को विकसित करने के अवसरों को खोल दिया है जो हमें रोज़मर्रा के कई कार्यों के कार्यान्वयन को आसान बनाने की अनुमति देते हैं, जैसे टैक्सी ऑर्डर करना, रेस्तरां में टेबल बुक करना और कई अन्य। ऐसी समस्याओं को हल करने के लिए, केंद्रित सिस्टम का उपयोग किया जाता है।डायलॉग स्टेट ट्रेकिंग (डीएसटी) ऐसी संवाद प्रणालियों में एक प्रमुख घटक है। डीएसटी भाषा के शब्दार्थ प्रतिनिधित्व में मानव भाषा में उच्चारणों के अनुवाद के लिए जिम्मेदार है, विशेष रूप से, उपयोगकर्ता के लक्ष्य के अनुरूप इंटेंट और स्लॉट-वैल्यू जोड़े निकालने के लिए। DSTC8में टीम की भागीदारी के दौरानGOLOMB मॉडल (GOaL- ओरिएंटेड मल्टी-टास्क BERT- आधारित डायलॉग स्टेट ट्रैकर) विकसित किया गया था - संवाद की स्थिति को ट्रैक करने के लिए BERT पर आधारित एक लक्ष्य-उन्मुख मल्टी-टास्क मॉडल। संवाद की स्थिति का अनुमान लगाने के लिए, मॉडल कई वर्गीकरण समस्याओं और एक विकल्प खोजने के कार्य को हल करता है। जल्द ही यह मॉडल दीपपावलोव पुस्तकालय में दिखाई देगा। इस बीच, आप यहां पूरा लेख पढ़ सकते हैं । न्यूयॉर्क (यूएसए) में AAAI-20 सम्मेलन में पोस्टर की प्रस्तुति।
न्यूयॉर्क (यूएसए) में AAAI-20 सम्मेलन में पोस्टर की प्रस्तुति।
5. एलेक्सा प्राइज सोशलबोट ग्रैंड चैलेंज में भाग लेना
दीपपावलोव की टीम, मास्को इंस्टीट्यूट ऑफ फिजिक्स एंड टेक्नोलॉजी के छात्रों और स्नातक छात्रों से मिलकर, एलेक्सा पुरस्कार सोशलबोट ग्रैंड चैलेंज 3 में भाग लेने के लिए चुना गया - एक अंतरराष्ट्रीय प्रतियोगिता जो कि संवादी एआई प्रौद्योगिकी के विकास के लिए समर्पित है। प्रतियोगिता का उद्देश्य एक बॉट बनाना है जो प्रासंगिक विषयों पर लोगों के साथ स्वतंत्र रूप से संवाद कर सकता है। 375 आवेदनों में से, एलेक्सा प्राइज कमेटी ने 10 फाइनलिस्ट का चयन किया, जिसमें हमारी टीम भी शामिल है - DREAM। फिलहाल, टीम प्रतियोगिता के क्वार्टर फाइनल में पहुंच गई है और सेमीफाइनल में पहुंचने के लिए लड़ रही है। आप आधिकारिक पेज पर हमारे लिए न्यूज़ और चीयर को फॉलो कर सकते हैं , और ट्विटर को सब्सक्राइब करना ना भूलें । टीम रचना ड्रीम टीम।
टीम रचना ड्रीम टीम।
6. टीएफ चैलेंज द्वारा संचालित में भागीदारी
जैसा कि पहले कहा गया था, दीपपावलोव कई पूर्व प्रशिक्षित घटकों के साथ आता है जो टेंसोरफ्लो और केरस द्वारा संचालित हैं। और इस वर्ष, दीपपावलोव टीम ने सर्वश्रेष्ठ मशीन लर्निंग प्रोजेक्ट के लिए टीएफ चैलेंज प्रतियोगिता द्वारा संचालित गूगल को जीत लिया, जो कि टेन्सरफोर लाइब्रेरी का उपयोग करता है। 600 से अधिक प्रतियोगिता प्रतिभागियों में से, Google ने पांच सर्वश्रेष्ठ परियोजनाओं को चुना, जिनमें से एक दीपपावलोव पुस्तकालय था। परियोजना को आधिकारिक TensorFlow ब्लॉग पर प्रस्तुत किया गया था । यह ध्यान देने योग्य है कि TensorFlow का लचीलापन हमें किसी भी तंत्रिका नेटवर्क वास्तुकला को बनाने की अनुमति देता है जिसके बारे में हम सोच सकते हैं। और विशेष रूप से, हम BERT- आधारित मॉडल के साथ सहज एकीकरण के लिए TensorFlow का उपयोग करते हैं।
7. सामुदायिक विकास
हमारी परियोजना का वैश्विक लक्ष्य अगली पीढ़ी के इंटरैक्टिव सिस्टम बनाने के लिए सबसे उन्नत उपकरणों का उपयोग करने के लिए संवादी कृत्रिम बुद्धि के क्षेत्र में डेवलपर्स और शोधकर्ताओं को सक्षम करना है, साथ ही साथ अत्याधुनिक प्रौद्योगिकियों के अनुभव और शिक्षण के लिए एआई के क्षेत्र में एक अंतरराष्ट्रीय स्तर पर महत्वपूर्ण मंच बनना है।इसे प्राप्त करने के लिए, दीपपावलोव कर्मचारीकंप्यूटर विज्ञान में शामिल छात्रों और कर्मचारियों के लिए निःशुल्क सेमेस्टर प्रशिक्षण पाठ्यक्रम संचालित करना। उनमें से एक कोर्स है: "प्राकृतिक भाषा प्रसंस्करण में गहरी शिक्षा", जिसमें सेमिनार और कार्यशालाएं शामिल हैं। कक्षाओं में इस तरह के विषय शामिल हैं: संवाद प्रणाली का निर्माण, एक प्रतिक्रिया उत्पन्न करने की क्षमता के साथ एक संवाद प्रणाली का मूल्यांकन करने के तरीके, संवाद प्रणालियों के लिए विभिन्न रूपरेखा, संवाद नीतियों के अनुकूलन के कारण इनाम की मात्रा का आकलन करने के तरीके, उपयोगकर्ता अनुरोधों के प्रकार, मॉडलिंग कॉल-सेंटर कॉल पर विचार। 2020 में, हमने एक नई भर्ती शुरू की और पहले से ही 900 छात्रों और कर्मचारियों को नि: शुल्क प्रशिक्षण दिया। आप हमारी वेबसाइट पर इस और अन्य पाठ्यक्रमों के लिए समाचार और सेट का अनुसरण कर सकते हैं । और यदि आप पाठ्यक्रम से चूक गए हैं, लेकिन अधिक सीखना चाहते हैं - तो हमारे परयूट्यूब चैनल आप हमेशा उन्हें रिकॉर्ड में पा सकते हैं।आज, दीपपावलोव पुस्तकालय पाठ के साथ काम करने के लिए एआई-तैयार घटक प्रदान करता है, जो दुनिया के 92 देशों में उपयोग किया जाता है। फरवरी 2020 तक, पुस्तकालय के डाउनलोड की संख्या 100,000 हजार तक पहुंच गई, और प्रतिष्ठानों की गतिशीलता गति प्राप्त कर रही है। इसके अलावा, रूस में 30 से अधिक कंपनियां पहले ही लागू कर चुकी हैं और दीपपावलोव पर आधारित समाधानों का सफलतापूर्वक उपयोग कर रही हैं। इससे पता चलता है कि इस तरह के समाधान पूरी दुनिया में बहुत लोकप्रिय हैं।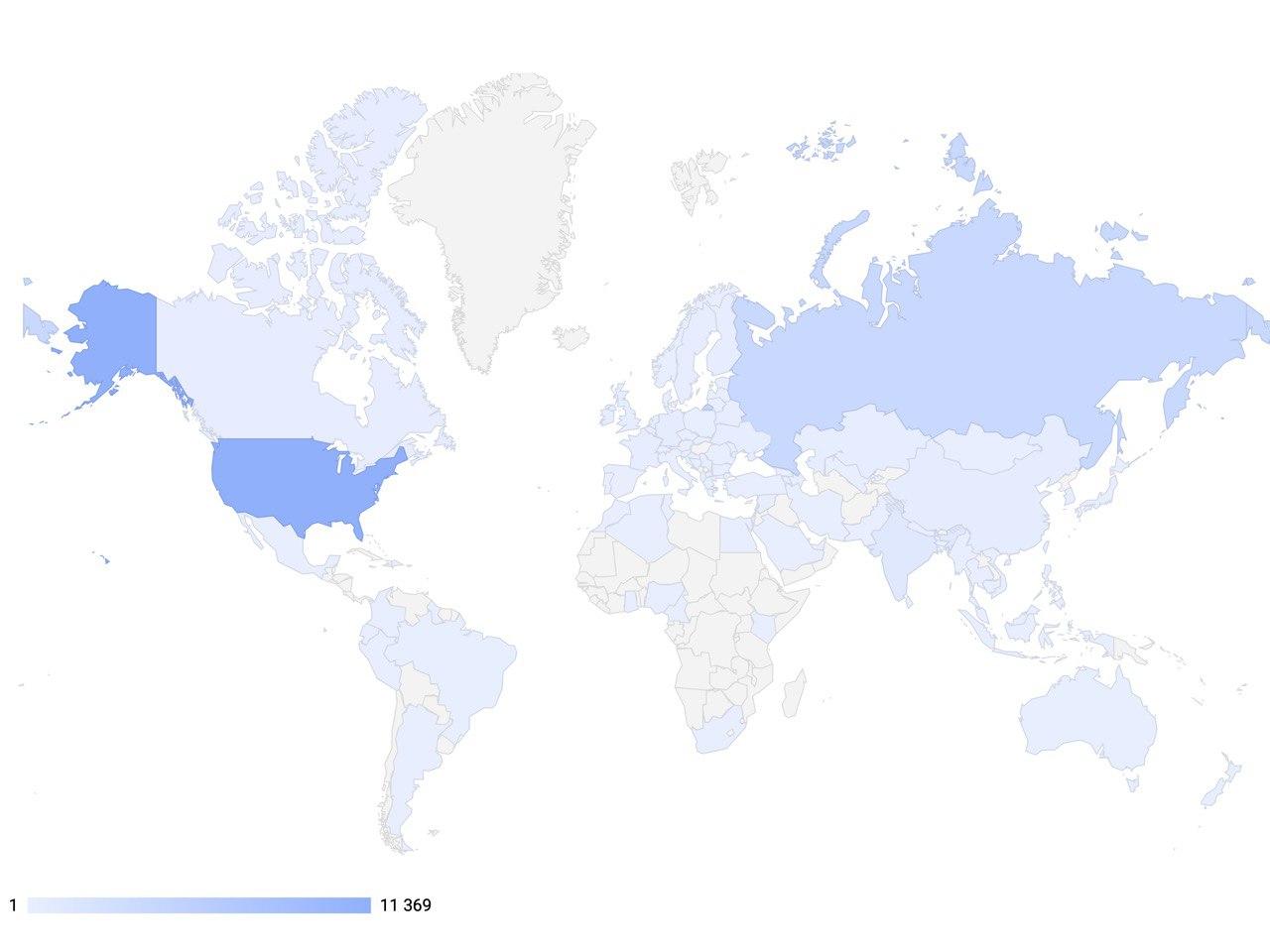
आगे क्या होगा?
हम आपकी सफलताओं को आपके साथ साझा करके प्रसन्न हैं, इसलिए हमने अपने समुदाय के लिए एक कार्यक्रम तैयार किया है। हम वास्तविक उत्पादन परियोजनाओं से अनुभव और ज्ञान को साझा करना चाहते हैं कि कैसे सर्वश्रेष्ठ एआई सहायक बनाए जाएं। कृत्रिम बुद्धि और इसके अनुप्रयोग के बारे में बात करने के लिए, साथ ही समुदाय के अन्य सदस्यों से मिलने के लिए 28 फरवरी को दीपपावलोव ओपन लाइब्रेरी के उपयोगकर्ताओं और डेवलपर्स की बैठक में शामिल हों। यह आयोजन 25 से 28 फरवरी तक एआई सप्ताह के भाग के रूप में आयोजित किया जाएगा । हम सभी का इंतजार कर रहे हैं जो डीपपावलोव का उपयोग करता है या हमारी तकनीक को जानना चाहता है।वक्ताओं और कार्यक्रम की सभी जानकारी साइट पर पाई जा सकती है, कार्यक्रम में भाग लेने के लिए पंजीकरण आवश्यक है।शामिल हों: दीपपावलोव 2 साल
एआई उद्योग का विकास जारी रहेगा, और हमें विश्वास है कि दीपपावलोव एक उन्नत तकनीक बन जाएगी जिसका उपयोग प्रत्येक डेवलपर प्राकृतिक भाषा को समझने के लिए करेगा। अगले साल, हम अपने समुदाय को दोगुना करने, ओपन सोर्स टूल्स बढ़ाने और मशीन लर्निंग रिसर्च में सुधार करने के लिए काम करेंगे। और यह मत भूलो कि दीपपावलोव के पास एक मंच है - पुस्तकालय और मॉडल के बारे में अपने प्रश्न पूछें। ध्यान देने के लिए आपको धन्यवाद!