डिनर पर बातचीत में कुछ हफ्ते पहले, एक सहकर्मी ने किसी तरह की धीमी प्रक्रिया के बारे में शिकायत की। उन्होंने उत्पन्न बाइट्स की संख्या, प्रसंस्करण चक्रों की संख्या और अंततः राम की मात्रा की गणना की। एक सहकर्मी ने कहा कि 500 जीबी / एस से अधिक की मेमोरी बैंडविड्थ वाला एक आधुनिक जीपीयू अपने कार्य को खाएगा और चोक नहीं होगा।मुझे ऐसा लग रहा था कि यह एक दिलचस्प दृष्टिकोण है। व्यक्तिगत रूप से, मैंने पहले इस दृष्टिकोण से प्रदर्शन के उद्देश्यों का मूल्यांकन नहीं किया है। हां, मुझे प्रोसेसर और मेमोरी प्रदर्शन में अंतर के बारे में पता है। मुझे पता है कि कैसे कोड लिखना है जो कैश का भारी उपयोग करता है। मैं अनुमानित देरी के आंकड़े जानता हूं। लेकिन यह मेमोरी बैंडविड्थ का तुरंत आकलन करने के लिए पर्याप्त नहीं है।यहाँ एक सोचा प्रयोग है। स्मृति में एक बिलियन 32-बिट पूर्णांक की एक निरंतर सरणी की कल्पना करें। यह 4 गीगाबाइट है। इस सरणी पर पुनरावृति करने और मानों को जोड़ने में कितना समय लगेगा? CPU प्रति सेकंड कितने बाइट्स RAM से पढ़ सकता है? निरंतर डेटा? रैंडम एक्सेस? इस प्रक्रिया को कितनी अच्छी तरह से समानांतर किया जा सकता है?आप कहेंगे कि ये बेकार के सवाल हैं। इस तरह के भोले लैंडमार्क बनाने के लिए वास्तविक कार्यक्रम बहुत जटिल हैं। और वहां है! असली जवाब "स्थिति पर निर्भर करता है।"हालांकि, मुझे लगता है कि यह मुद्दा तलाशने लायक है। मैं जवाब खोजने की कोशिश नहीं कर रहा हूं । लेकिन मुझे लगता है कि हम कुछ ऊपरी और निचली सीमाओं को परिभाषित कर सकते हैं, बीच में कुछ दिलचस्प बिंदु और प्रक्रिया में कुछ सीख सकते हैं।
मुझे पता है कि कैसे कोड लिखना है जो कैश का भारी उपयोग करता है। मैं अनुमानित देरी के आंकड़े जानता हूं। लेकिन यह मेमोरी बैंडविड्थ का तुरंत आकलन करने के लिए पर्याप्त नहीं है।यहाँ एक सोचा प्रयोग है। स्मृति में एक बिलियन 32-बिट पूर्णांक की एक निरंतर सरणी की कल्पना करें। यह 4 गीगाबाइट है। इस सरणी पर पुनरावृति करने और मानों को जोड़ने में कितना समय लगेगा? CPU प्रति सेकंड कितने बाइट्स RAM से पढ़ सकता है? निरंतर डेटा? रैंडम एक्सेस? इस प्रक्रिया को कितनी अच्छी तरह से समानांतर किया जा सकता है?आप कहेंगे कि ये बेकार के सवाल हैं। इस तरह के भोले लैंडमार्क बनाने के लिए वास्तविक कार्यक्रम बहुत जटिल हैं। और वहां है! असली जवाब "स्थिति पर निर्भर करता है।"हालांकि, मुझे लगता है कि यह मुद्दा तलाशने लायक है। मैं जवाब खोजने की कोशिश नहीं कर रहा हूं । लेकिन मुझे लगता है कि हम कुछ ऊपरी और निचली सीमाओं को परिभाषित कर सकते हैं, बीच में कुछ दिलचस्प बिंदु और प्रक्रिया में कुछ सीख सकते हैं।हर प्रोग्रामर को नंबर पता होना चाहिए
यदि आप प्रोग्रामिंग ब्लॉग पढ़ते हैं, तो आप शायद "संख्याएं जो हर प्रोग्रामर को पता होनी चाहिए।" वे कुछ इस तरह दिखते हैं:एल 1 कैश 0.5 एनएस से लिंक करें
गलत 5 ns भविष्यवाणी
L2 कैश से लिंक करें 7 ns 14x से L1 कैश
म्यूटेक्स कैप्चर / रिलीज़ 25 एन.एस.
मुख्य मेमोरी का लिंक 100 ns 20x से L2 कैश, 200x से L1 कैश
Zippy 3000 ns 3 μs के साथ 1000 बाइट्स संपीड़ित करें
1 Gbps नेटवर्क 10,000 ns 10 μs से अधिक 1000 बाइट भेजना
SSD 150,000 ns 150 μs ~ 1GB / s SSD के साथ रैंडम रीड 4000
250 एमबी एनएस 250 μs से क्रमिक रूप से 1 एमबी पढ़ें
डाटा सेंटर 500,000 एनएस 500 μs के अंदर गोल-यात्रा पैकेट
SSD 1,000,000 ns 1,000 μs 1 ms ~ 1 GB / s SSD, 4x मेमोरी में 1 MB अनुक्रमिक पढ़ा
डिस्क खोज 10,000,000 एनएस 10,000 μs 10 एमएस 20x डेटा सेंटर के लिए
डिस्क से 1 एमबी क्रमिक रूप से पढ़ें 20,000,000 ns 20,000 μs 20 ms 80x to memory, 20x to SSD
पैकेज भेजना सीए-> नीदरलैंड-> सीए 150,000,000 एनएस 150,000 μs 150 एमएस
स्रोत: जोनास बोनरमहान सूची वह साल में कम से कम एक बार HackerNews पर पॉप अप करता है। प्रत्येक प्रोग्रामर को इन नंबरों को जानना चाहिए।लेकिन ये संख्या कुछ और ही है। विलंबता और बैंडविड्थ एक ही बात नहीं है।2020 में देरी
वह सूची 2012 में संकलित की गई थी, और 2020 के इस लेख में समय बदल गया है। यहाँ StackOverflow के साथ Intel i7 के लिए नंबर दिए गए हैं ।L1 कैश में हिट करें, ~ 4 चक्र (2.1 - 1.2 ns)
L2 कैश में हिट करें, ~ 10 चक्र (5.3 - 3.0 ns)
L3 कैश में हिट करें, एक ही कोर के लिए ~ 40 चक्र (21.4 - 12.0 एनएस)
L3 कैश में हिट करें, एक और कर्नेल के लिए एक साथ ~ 65 चक्र (34.8 - 19.5 एनएस)
L3 कैश को हिट करें, एक और कर्नेल के लिए बदलाव के साथ ~ 75 चक्र (40.2 - 22.5 एनएस)
लोकल रैम ~ 60 ns
दिलचस्प! किया बदल गया?- L1 धीमा हो गया है;
0,5 → 1,5
- एल 2 तेजी से;
7 → 4,2
- एल 1 और एल 2 का अनुपात बहुत कम है;
2,5x 14(वाह!)
- L3 कैश अब मानक बन गया है;
12 40
- रैम तेज हो गई है;
100 → 60
हम दूरगामी निष्कर्ष नहीं निकालेंगे। यह स्पष्ट नहीं है कि मूल संख्याओं की गणना कैसे की गई। हम संतरे के साथ सेब की तुलना नहीं करेंगे। मेरे प्रोसेसर की बैंडविड्थ और कैश आकार पर विकिपिप केकुछ आंकड़े यहां दिए गए हैं ।मेमोरी बैंडविड्थ: 39.74 गीगाबाइट प्रति सेकंड
L1 कैश: 192 किलोबाइट (32 KB प्रति कोर)
L2 कैश: 1.5 मेगाबाइट (कोर प्रति 256 KB)
L3 कैश: 12 मेगाबाइट (साझा; 2 एमबी प्रति कोर)
मै क्या जानना चाहता हूँ:- RAM प्रदर्शन ऊपरी सीमा
- निचली सीमा
- L1 / L2 / L3 कैश सीमाएँ
Naive बेंचमार्किंग
चलो कुछ परीक्षण करते हैं। बैंडविड्थ को मापने के लिए, मैंने एक सरल सी ++ प्रोग्राम लिखा। बहुत लगभग वह इस तरह दिखती है।
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
कुछ विवरण छोड़े गए हैं। लेकिन आप विचार को समझ गए। तत्वों का एक बड़ा, निरंतर सरणी बनाएं। सरणी को अलग-अलग टुकड़ों में विभाजित करें। प्रत्येक टुकड़े को एक अलग धागे में संसाधित करें। संचित परिणाम।आपको यादृच्छिक पहुंच को मापने की भी आवश्यकता है। ये बहुत मुश्किल है। मैंने कई तरीकों की कोशिश की, आखिरकार पूर्व-संकलित अनुक्रमित मिश्रण करने का फैसला किया। प्रत्येक सूचकांक बिल्कुल एक बार मौजूद होता है। फिर आंतरिक लूप सूचकांकों और गणनाओं पर निर्भर करता है sum += nums[index]।std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
थ्रूपुट की गणना में, मैं इंडेक्स ऐरे की मेमोरी पर विचार नहीं करता। केवल बाइट्स जो कुल में योगदान करते हैं, गिने जाते हैं sum। मैं अपने हार्डवेयर को बेंचमार्क नहीं करता हूं, लेकिन विभिन्न आकारों के डेटा सेट और विभिन्न एक्सेस योजनाओं के साथ काम करने की क्षमता का आकलन करता हूं।हम तीन डेटा प्रकारों के साथ परीक्षण करेंगे:int- मुख्य 32-बिट पूर्णांकmatri4x4- इसमें शामिल हैं int[16]; एक 64-बाइट कैश लाइन में फिट बैठता हैmatrix4x4_simd- अंतर्निहित टूल का उपयोग करता है__m256iबड़ा ब्लॉक
मेरी पहली परीक्षा स्मृति के एक बड़े ब्लॉक के साथ काम करती है। Nवस्तुओं का 1 जीबी ब्लॉक हाइलाइट किया गया है और छोटे यादृच्छिक मूल्यों से भरा है। एक साधारण लूप एक सरणी N समय पर पुनरावृत्त होता है, इसलिए यह N राशि की गणना करने के लिए वॉल्यूम के साथ मेमोरी तक पहुंचता है int64_t। कई थ्रेड्स सरणी को विभाजित करते हैं, और प्रत्येक को समान संख्या में तत्वों तक पहुंच मिलती है।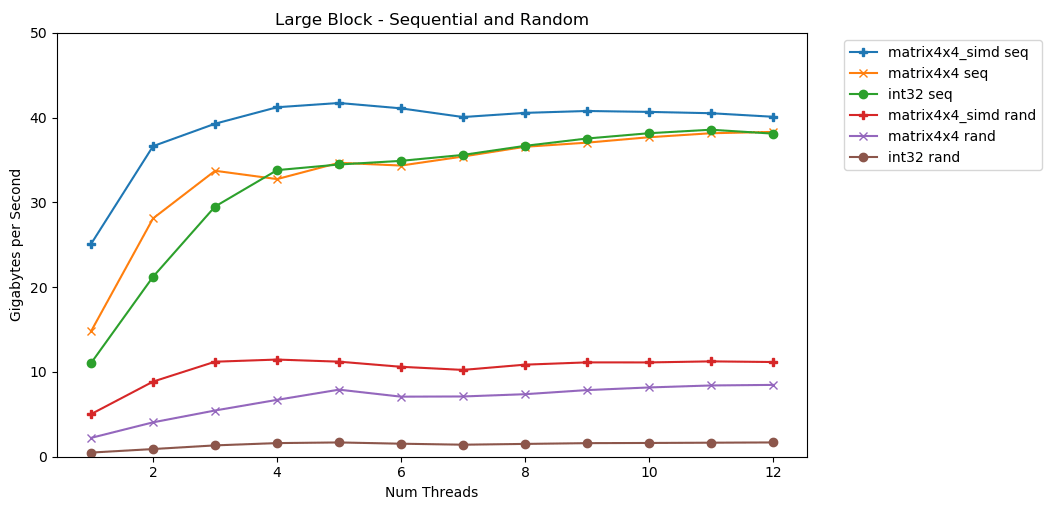 TA-दाह! इस ग्राफ में, हम योग आपरेशन की औसत निष्पादन समय लेने के लिए और से परिवर्तित
TA-दाह! इस ग्राफ में, हम योग आपरेशन की औसत निष्पादन समय लेने के लिए और से परिवर्तित runtime_in_nanosecondsकरने के लिए gigabytes_per_second।बहुत अच्छा परिणाम है। int32क्रमिक रूप से एक ही स्ट्रीम में 11 जीबी / एस पढ़ सकते हैं। यह 38 जीबी / एस तक पहुंचने तक रैखिक रूप से मापता है। टेस्ट matrix4x4और matrix4x4_simdतेज, लेकिन एक ही छत के खिलाफ आराम करें।प्रति सेकंड रैम से हम कितना डेटा पढ़ सकते हैं, इस पर एक स्पष्ट और स्पष्ट छत है। मेरे सिस्टम पर, यह लगभग 40 GB / s है। यह ऊपर सूचीबद्ध वर्तमान विनिर्देशों का अनुपालन करता है।नीचे के तीन ग्राफ़ को देखते हुए, रैंडम एक्सेस धीमा है। बहुत, बहुत धीमा। एकल-थ्रेडेड प्रदर्शन int32एक नगण्य 0.46 GB / s है। यह 11.03 GB / s पर अनुक्रमिक स्टैकिंग की तुलना में 24 गुना धीमा है! परीक्षण matrix4x4सबसे अच्छा परिणाम दिखाता है, क्योंकि यह पूर्ण कैश लाइनों पर चलता है। लेकिन यह अभी भी अनुक्रमिक पहुंच की तुलना में चार से सात गुना धीमा है, और केवल 8 जीबी / एस पर चोटियां हैं।छोटा ब्लॉक: अनुक्रमिक पढ़ा
मेरे सिस्टम पर, प्रत्येक स्ट्रीम के लिए L1 / L2 / L3 कैश आकार 32 KB, 256 KB और 2 MB है। यदि आप तत्वों का 32-किलोबाइट ब्लॉक लेते हैं और 125,000 बार इसे सुलझाते हैं तो क्या होता है? यह 4 जीबी मेमोरी है, लेकिन हम हमेशा कैश में जाएंगे।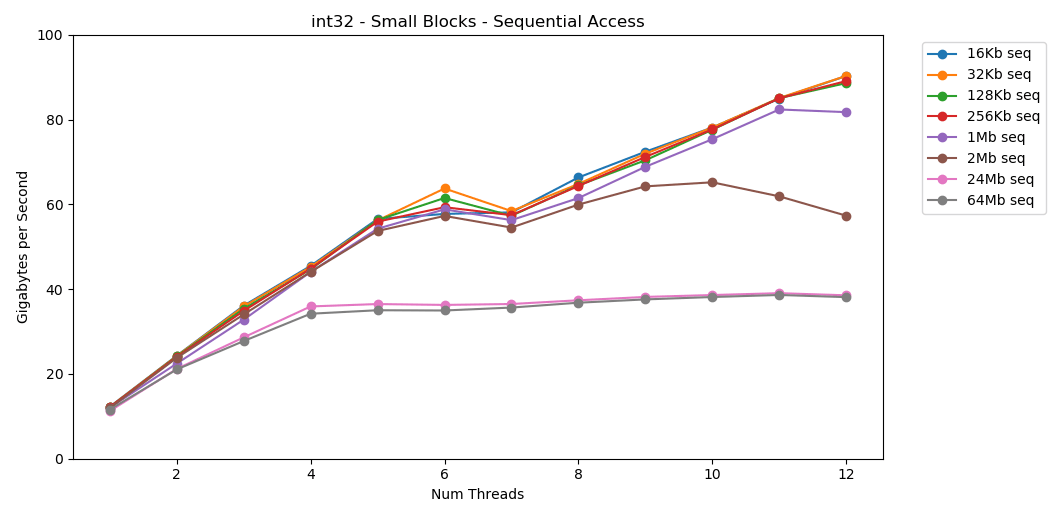 बहुत बढ़िया! एकल-थ्रेडेड प्रदर्शन एक बड़े ब्लॉक को पढ़ने के समान है, लगभग 12 जीबी / एस। इस समय को छोड़कर, मल्टीथ्रेडिंग 40 जीबी / एस की छत के माध्यम से टूट जाती है। यह समझ में आता है। डेटा कैश में रहता है, इसलिए RAM टोंटी दिखाई नहीं देती है। डेटा के लिए जो L3 कैश में फिट नहीं था, लगभग 38 जीबी / एस की एक ही छत लागू होती है।परीक्षण
बहुत बढ़िया! एकल-थ्रेडेड प्रदर्शन एक बड़े ब्लॉक को पढ़ने के समान है, लगभग 12 जीबी / एस। इस समय को छोड़कर, मल्टीथ्रेडिंग 40 जीबी / एस की छत के माध्यम से टूट जाती है। यह समझ में आता है। डेटा कैश में रहता है, इसलिए RAM टोंटी दिखाई नहीं देती है। डेटा के लिए जो L3 कैश में फिट नहीं था, लगभग 38 जीबी / एस की एक ही छत लागू होती है।परीक्षण matrix4x4सर्किट के समान परिणाम दिखाता है, लेकिन इससे भी तेज; एकल-थ्रेडेड मोड में 31 जीबी / एस, बहु-थ्रेडेड में 171 जीबी / एस।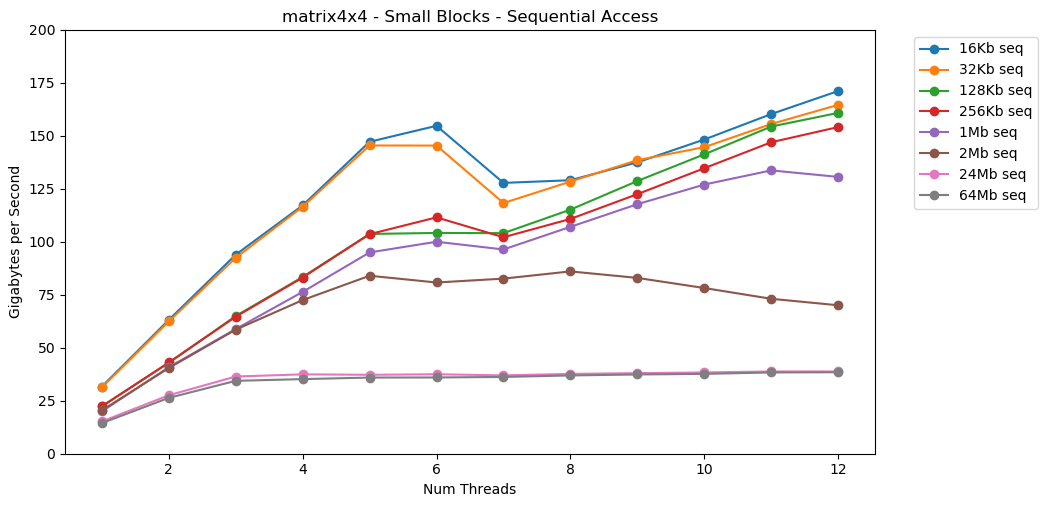 अब देखते हैं
अब देखते हैं matrix4x4_simd। Y अक्ष पर ध्यान दें।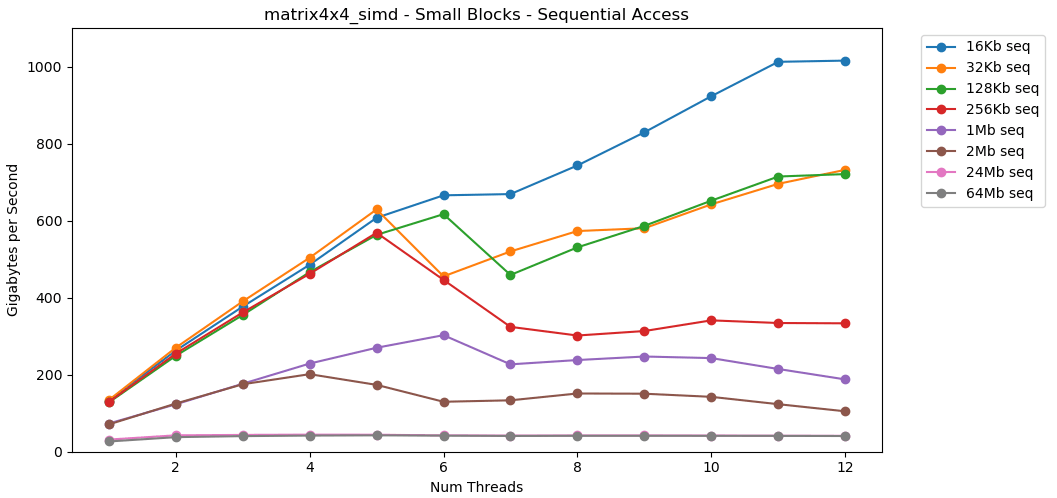
matrix4x4_simdअसाधारण तेजी से प्रदर्शन किया। की तुलना में यह 10 गुना तेज है int32। 16 केबी ब्लॉक पर, यह 1000 जीबी / एस से भी टूटता है!जाहिर है, यह एक सतह सिंथेटिक परीक्षण है। अधिकांश अनुप्रयोग समान डेटा के साथ एक पंक्ति में एक लाख बार एक ही ऑपरेशन नहीं करते हैं। परीक्षण वास्तविक दुनिया में प्रदर्शन नहीं दिखाता है।लेकिन सबक स्पष्ट है। कैश के अंदर, डेटा जल्दी से संसाधित होता है । SIMD का उपयोग करते समय बहुत अधिक छत के साथ: एकल-थ्रेडेड मोड में 100 GB / s से अधिक, बहु-थ्रेडेड में 1000 GB / s से अधिक। कैश में डेटा लिखना धीमा है और लगभग 40 जीबी / एस की कठिन सीमा के साथ है।छोटा ब्लॉक: यादृच्छिक पढ़ा
चलो ऐसा ही करते हैं, लेकिन अब यादृच्छिक पहुंच के साथ। यह लेख का मेरा पसंदीदा हिस्सा है।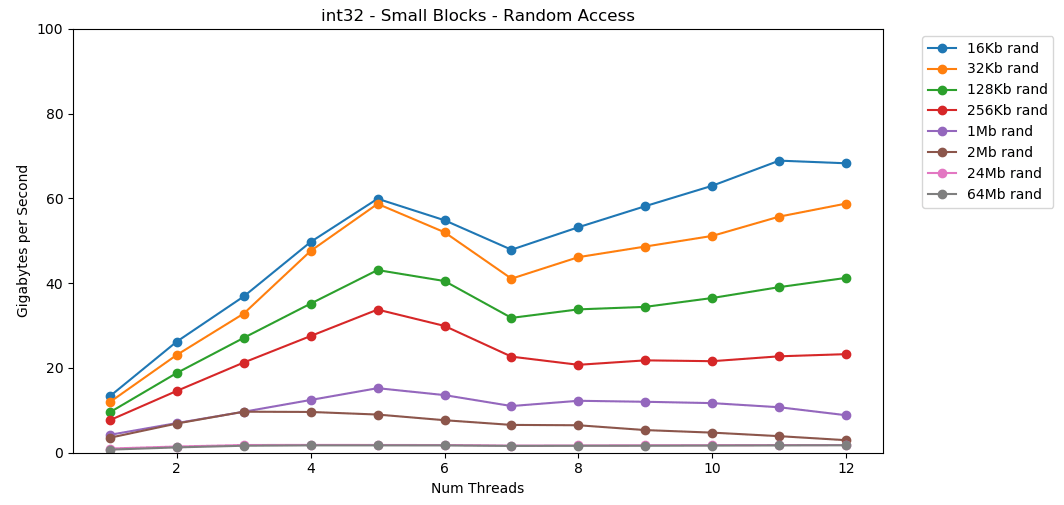 RAM से यादृच्छिक मान पढ़ना धीमा है, केवल 0.46 GB / s है। L1 कैश से यादृच्छिक मान पढ़ना बहुत तेज है: 13 जीबी / एस। यह
RAM से यादृच्छिक मान पढ़ना धीमा है, केवल 0.46 GB / s है। L1 कैश से यादृच्छिक मान पढ़ना बहुत तेज है: 13 जीबी / एस। यह int32रैम (11 जीबी / एस) से सीरियल डेटा पढ़ने से तेज है ।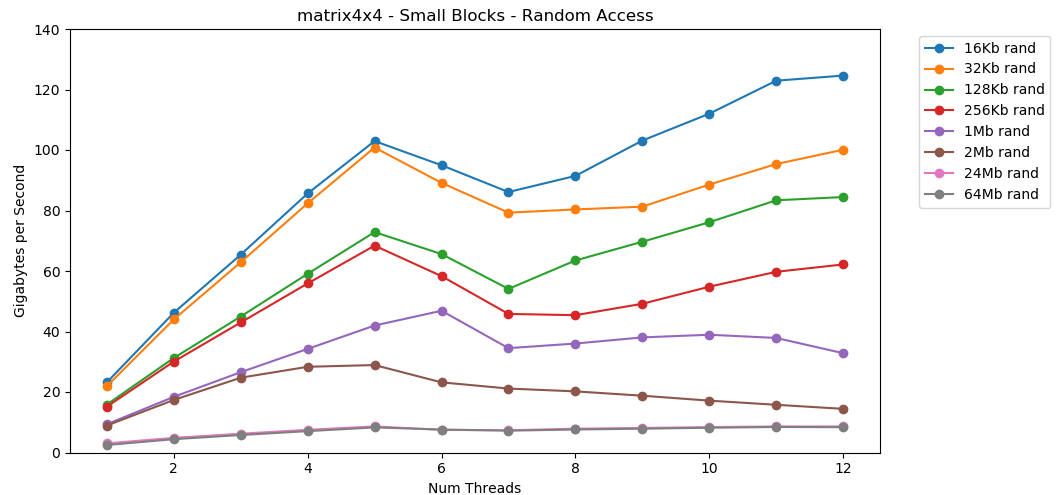 परीक्षण
परीक्षण matrix4x4समान टेम्पलेट के लिए एक समान परिणाम दिखाता है, लेकिन लगभग दोगुनी तेजी से int।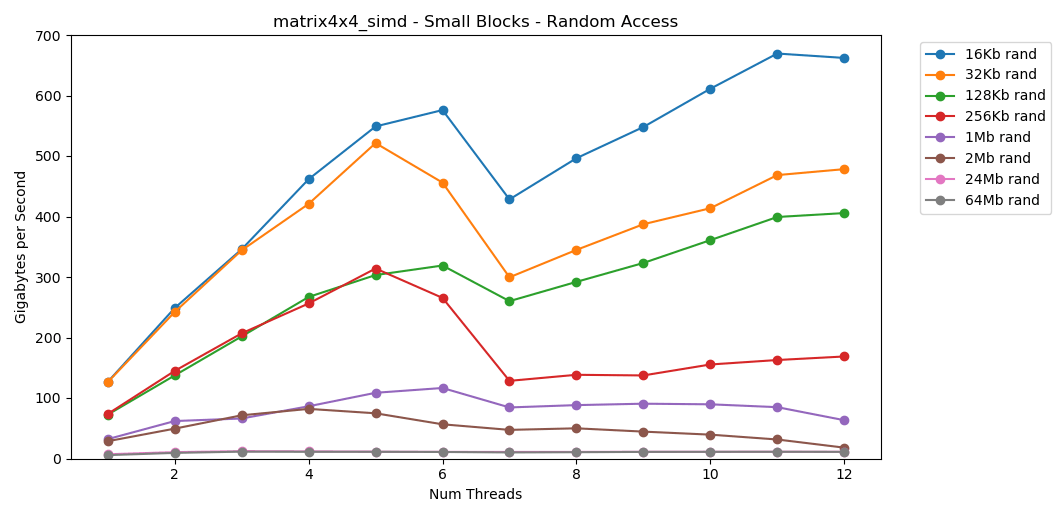 रैंडम एक्सेस
रैंडम एक्सेस matrix4x4_simdपागलपन से तेज है।रैंडम एक्सेस फाइंडिंग
स्मृति से मुक्त पढ़ना धीमा है। भयावह रूप से धीमा। दोनों परीक्षण मामलों के लिए 1 जीबी / एस से कम int32। उसी समय, कैश से रैंडम रीड आश्चर्यजनक रूप से तेज होते हैं। यह रैम से अनुक्रमिक पढ़ने के लिए तुलनीय है ।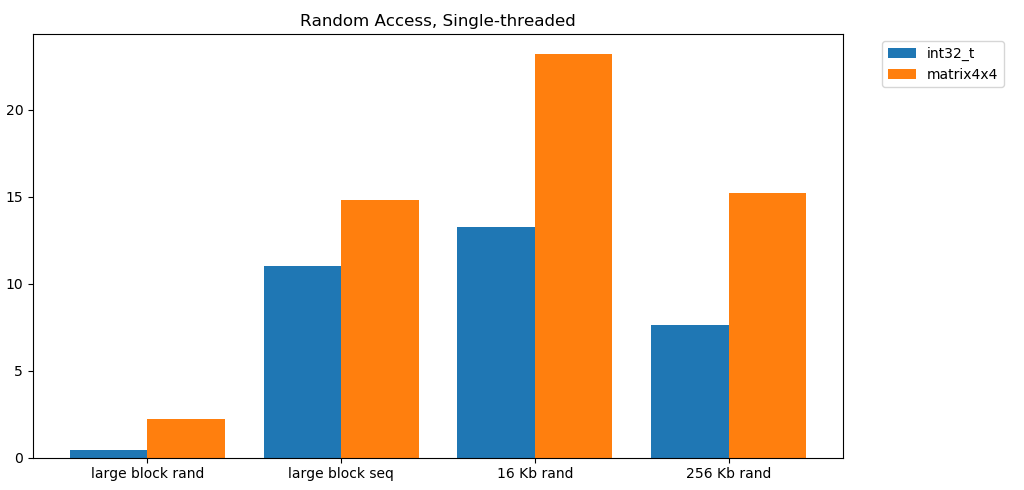 इसे पचाने की जरूरत है। कैश में रैंडम एक्सेस रैम की अनुक्रमिक पहुंच की गति में तुलनीय है। L1 16 KB से L2 256 KB तक की गिरावट केवल आधी या उससे कम है।मुझे लगता है कि इसका गहरा परिणाम होगा।
इसे पचाने की जरूरत है। कैश में रैंडम एक्सेस रैम की अनुक्रमिक पहुंच की गति में तुलनीय है। L1 16 KB से L2 256 KB तक की गिरावट केवल आधी या उससे कम है।मुझे लगता है कि इसका गहरा परिणाम होगा।लिंक्ड लिस्ट को हानिकारक माना जाता है
एक पॉइंटर (पॉइंटर्स पर कूदना) का पीछा करना बुरा है। बहुत बहुत बुरा। प्रदर्शन कितना घट रहा है? अपने आप को देखो। मैंने एक अतिरिक्त परीक्षण किया जो अंदर लपेटता matrix4x4है std::unique_ptr। प्रत्येक पहुंच एक सूचक के माध्यम से जाती है। यहाँ एक भयानक, सिर्फ भयावह परिणाम है। 1 धागा | मैट्रिक्स 4x4 | unique_ptr | अंतर |
-------------------- | --------------- | ------------ | -------- |
बड़ा ब्लॉक - Seq | 14.8 जीबी / एस | 0.8 जीबी / एस | 19x |
16 केबी - Seq | 31.6 जीबी / एस | २.२ जीबी / एस | 14x |
256 KB - Seq | 22.2 जीबी / एस | 1.9 जीबी / एस | 12x |
बड़ा ब्लॉक - रैंड | २.२ जीबी / एस | 0.1 जीबी / एस | 22x |
16 केबी - रैंड | 23.2 जीबी / एस | 1.7 जीबी / एस | 14x |
256 KB - रैंड | 15.2 जीबी / एस | 0.8 जीबी / एस | 19x |
6 सूत्र | मैट्रिक्स 4x4 | unique_ptr | अंतर |
-------------------- | --------------- | ------------ | -------- |
बड़ा ब्लॉक - Seq | 34.4 जीबी / एस | 2.5 जीबी / एस | 14x |
16 केबी - Seq | 154.8 जीबी / एस | 8.0 जीबी / एस | 19x |
256 KB - Seq | 111.6 जीबी / एस | 5.7 जीबी / एस | 20x |
बड़ा ब्लॉक - रैंड | 7.1 जीबी / एस | 0.4 जीबी / एस | 18x |
16 केबी - रैंड | 95.0 GB / s | 7.8 जीबी / एस | 12x |
256 KB - रैंड | 58.3 जीबी / एस | 1.6 जीबी / एस | 36x |पॉइंटर के पीछे के मूल्यों का अनुक्रमिक योग 1 जीबी / एस से कम की गति से किया जाता है। कैश की डबल-स्किप रैंडम एक्सेस स्पीड केवल 0.1 GB / s है।एक पॉइंटर का पीछा करना कोड निष्पादन को 10-20 बार धीमा कर देता है। अपने मित्रों को लिंक की गई सूचियों का उपयोग न करने दें। कृपया कैश के बारे में सोचें।फ्रेम्स के लिए बजट अनुमान
गेम डेवलपर्स के लिए सीपीयू और मेमोरी पर लोड के लिए एक सीमा (बजट) निर्धारित करना आम बात है। लेकिन मैंने कभी बैंडविड्थ बजट नहीं देखा।आधुनिक खेलों में, एफपीएस का विकास जारी है। अब यह 60 एफपीएस पर है। वीआर 90 हर्ट्ज की आवृत्ति पर संचालित होता है। मेरे पास 144 हर्ट्ज गेमिंग मॉनीटर है। यह भयानक है, इसलिए 60 एफपीएस बकवास की तरह लगता है। मैं कभी पुराने मॉनिटर पर नहीं लौटूंगा। Esports और streamers Twitch 240 हर्ट्ज की निगरानी करता है। इस साल, असूस ने सीईएस में एक 360 हर्ट्ज राक्षस पेश किया।मेरे प्रोसेसर की ऊपरी सीमा लगभग 40 GB / s है। यह एक बड़ी संख्या की तरह लगता है! हालांकि, 240 हर्ट्ज की आवृत्ति पर, केवल 167 एमबी प्रति फ्रेम प्राप्त होता है। एक यथार्थवादी एप्लिकेशन 144 हर्ट्ज पर 5 जीबी / एस ट्रैफिक उत्पन्न कर सकता है, जो केवल 69 एमबी प्रति फ्रेम है।यहाँ एक तालिका है जिसमें कुछ संख्याएँ हैं। | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 जीबी / एस | 40 जीबी | 4 जीबी | 1.3 जीबी | 667 एमबी | 444 एमबी | 278 एमबी | 167 एमबी | 111 एमबी |
10 जीबी / एस | 10 जीबी | 1 जीबी | 333 एमबी | 166 एमबी | 111 एमबी | 69 एमबी | 42 एमबी | 28 एमबी |
1 जीबी / एस | 1 जीबी | 100 एमबी | 33 एमबी | 17 एमबी | 11 एमबी | 7 एमबी | 4 एमबी | 3 एमबी |
यह मुझे लगता है कि इस दृष्टिकोण से समस्याओं का आकलन करना उपयोगी है। इससे यह स्पष्ट होता है कि कुछ विचार संभव नहीं हैं। 240 हर्ट्ज तक पहुंचना आसान नहीं है। यह अपने आप नहीं होगा।हर प्रोग्रामर को नंबर पता होना चाहिए (2020)
पिछली सूची पुरानी हो चुकी है। अब इसे 2020 तक अद्यतन करने और अनुपालन करने की आवश्यकता है।यहाँ मेरे घर के कंप्यूटर के लिए कुछ नंबर दिए गए हैं। यह AIDA64, सैंड्रा और मेरे बेंचमार्क का मिश्रण है। आंकड़े पूरी तस्वीर नहीं देते हैं और केवल एक प्रारंभिक बिंदु हैं।विलंबता L1: 1 ns
एल 2 विलंब: 2.5 एन एस
विलंब L3: 10 एन.एस.
RAM विलंबता: 50 ns
(प्रति धागा)
एल 1 बैंड: 210 जीबी / एस
एल 2 बैंड: 80 जीबी / एस
एल 3 बैंड: 60 जीबी / एस
(पूरा सिस्टम)
रैम बैंड: 45 जीबी / एस
एक छोटा, सरल ओपन सोर्स बेंचमार्क बनाना अच्छा होगा। कुछ सी फ़ाइल जो डेस्कटॉप कंप्यूटर, सर्वर, मोबाइल डिवाइस, कंसोल आदि पर चलाई जा सकती हैं, लेकिन मैं ऐसा व्यक्ति नहीं हूं जो इस तरह का टूल लिखता हो।जिम्मेदारी से इनकार
मेमोरी बैंडविड्थ को मापना मुश्किल है। बहुत कठिन। मेरे कोड में संभवतः त्रुटियां हैं। कई बेहिसाब कारक। यदि मेरी तकनीक के लिए आपकी कुछ आलोचना है, तो आप शायद सही हैं।अंततः, मुझे लगता है कि यह सामान्य है। यह लेख मेरे डेस्कटॉप के सटीक प्रदर्शन के बारे में नहीं है। यह एक निश्चित दृष्टिकोण से एक समस्या कथन है। और कुछ मोटे गणितीय गणना करने के तरीके सीखने के बारे में।निष्कर्ष
एक सहकर्मी ने GPU मेमोरी बैंडविड्थ और एप्लिकेशन प्रदर्शन के बारे में मेरे साथ एक दिलचस्प राय साझा की। इसने मुझे आधुनिक कंप्यूटर पर मेमोरी के प्रदर्शन का अध्ययन करने के लिए प्रेरित किया।अनुमानित गणना के लिए, यहां आधुनिक डेस्कटॉप के लिए कुछ नंबर दिए गए हैं:- RAM प्रदर्शन
- ज्यादा से ज्यादा:
45 / - औसतन, लगभग:
5 / - न्यूनतम:
1 /
- L1 / L2 / L3 कैश प्रदर्शन (प्रति कोर)
- अधिकतम (सी सिमड):
210 // 80 //60 / - औसतन, लगभग:
25 // 15 //9 / - न्यूनतम:
13 // 8 //3,5 /
नमूना रेटिंग प्रदर्शन से संबंधित हैं matrix4x4। असली कोड इतना सरल कभी नहीं होगा। लेकिन एक नैपकिन पर गणना के लिए, यह एक उचित प्रारंभिक बिंदु है। आपको अपने प्रोग्राम, मेमोरी इक्विपमेंट और अपने उपकरणों की विशेषताओं के आधार पर इस आंकड़े को समायोजित करने की आवश्यकता है।हालांकि, सबसे महत्वपूर्ण बात समस्याओं के बारे में सोचने का एक नया तरीका है। समस्या को प्रति सेकंड या बाइट्स प्रति फ्रेम में प्रस्तुत करना एक अन्य लेंस है जिसके माध्यम से देखना है। यह सिर्फ मामले में एक उपयोगी उपकरण है।पढ़ने के लिए धन्यवाद।स्रोत
बेंचमार्क C ++पायथन ग्राफdata.jsonआगे का अन्वेषण
यह लेख केवल विषय पर थोड़ा स्पर्श किया गया। मैं शायद इसमें नहीं जाऊंगा। लेकिन अगर उसने किया, तो वह निम्नलिखित पहलुओं में से कुछ को कवर कर सकता है:सिस्टम विनिर्देशों
मेरे घर पीसी पर टेस्ट आयोजित किए गए। केवल स्टॉक सेटिंग्स, कोई ओवरक्लॉकिंग नहीं।- OS: विंडोज 10 v1903 बिल्ड 18362 है
- CPU: Intel i7-8700k @ 3.70 GHz
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 मेगाहर्ट्ज)
- मदरबोर्ड: Asus TUF Z370-Plus गेमिंग