एक में पिछले लेख, हम ध्यान तंत्र, आधुनिक गहरी लर्निंग मॉडल में एक अत्यंत आम तरीका है कि तंत्रिका मशीन अनुवाद अनुप्रयोगों के प्रदर्शन संकेतक सुधार कर सकते हैं की जांच की। इस लेख में, हम ट्रांसफार्मर को देखेंगे, एक मॉडल जो सीखने की गति को बढ़ाने के लिए ध्यान तंत्र का उपयोग करता है। इसके अलावा, कई कार्यों के लिए, ट्रांसफॉर्मर Google के तंत्रिका मशीन अनुवाद मॉडल को बेहतर बनाते हैं। हालांकि, ट्रांसफॉर्मर का सबसे बड़ा फायदा समानांतर स्थिति में उनकी उच्च दक्षता है। यहां तक कि Google क्लाउड क्लाउड TPU पर काम करते समय एक मॉडल के रूप में ट्रांसफार्मर का उपयोग करने की सिफारिश करता है । आइए यह पता लगाने की कोशिश करें कि मॉडल में क्या है और यह क्या कार्य करता है।
ट्रांसफार्मर मॉडल पहली बार लेख में प्रस्तुत किया गया था ध्यान सभी की आवश्यकता है । TensorFlow पर एक कार्यान्वयन Tensor2Tensor पैकेज के हिस्से के रूप में उपलब्ध है , इसके अलावा, हार्वर्ड के एनएलपी शोधकर्ताओं के एक समूह ने PyTorch पर एक कार्यान्वयन के साथ लेख का एक गाइड एनोटेशन बनाया । इसी मार्गदर्शिका में, हम सबसे सरल और लगातार मुख्य विचारों और अवधारणाओं को बताने की कोशिश करेंगे, जो हमें आशा है कि, इस मॉडल को समझने के लिए उन लोगों की मदद करेंगे जिन्हें विषय क्षेत्र का गहरा ज्ञान नहीं है।
उच्च स्तरीय समीक्षा
आइए मॉडल को एक प्रकार के ब्लैक बॉक्स के रूप में देखें। मशीन अनुवाद अनुप्रयोगों में, यह एक भाषा में एक वाक्य को इनपुट के रूप में स्वीकार करता है और दूसरे में एक वाक्य प्रदर्शित करता है।

, , , .
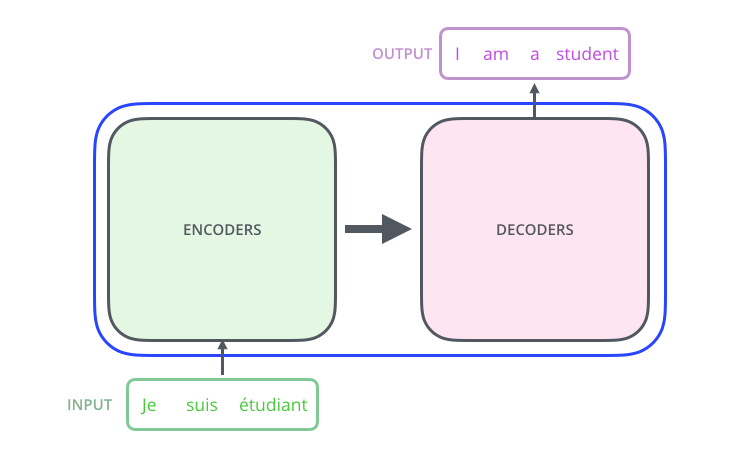
– ; 6 , ( 6 , ). – , .
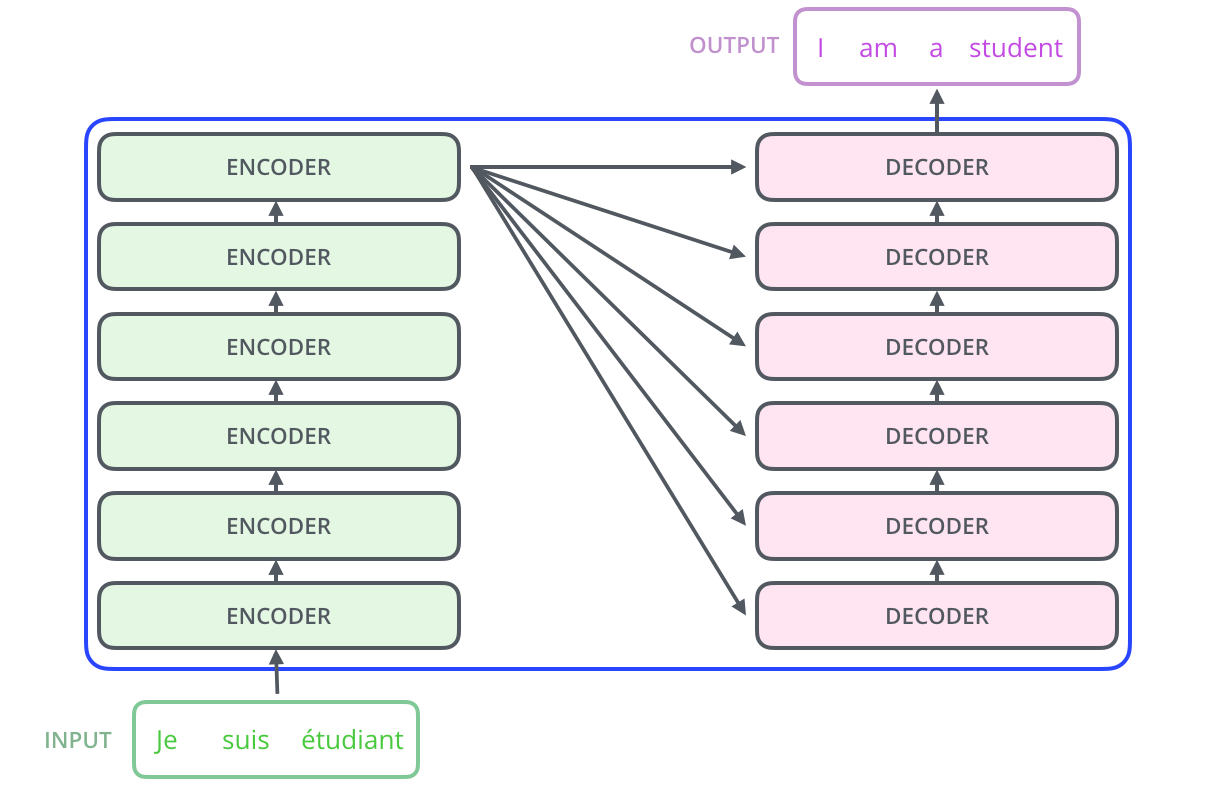
, . :
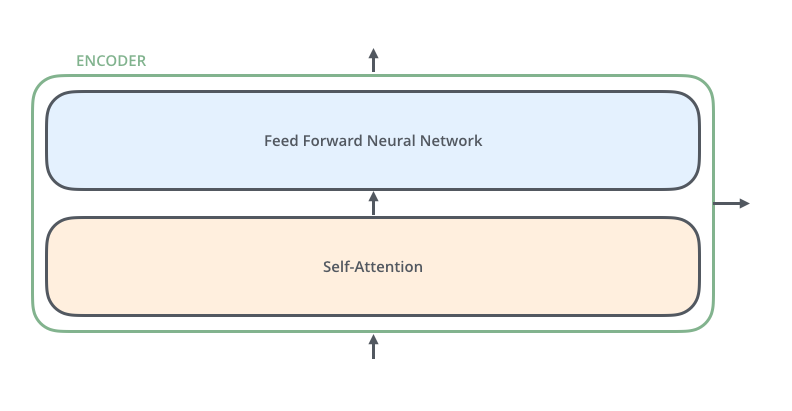
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
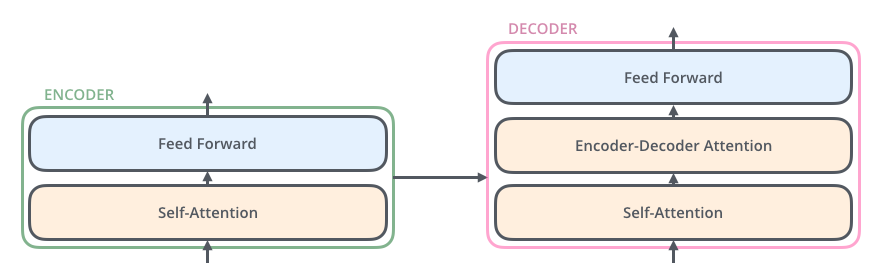
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
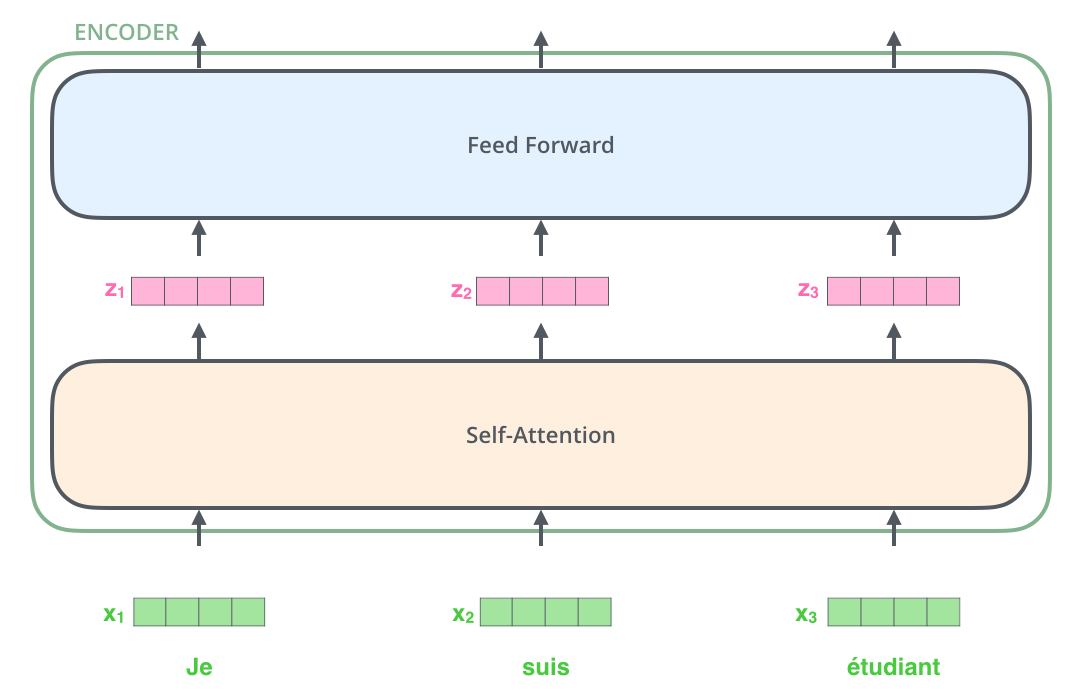
: . , , , .
, .
!
, , – , , , .
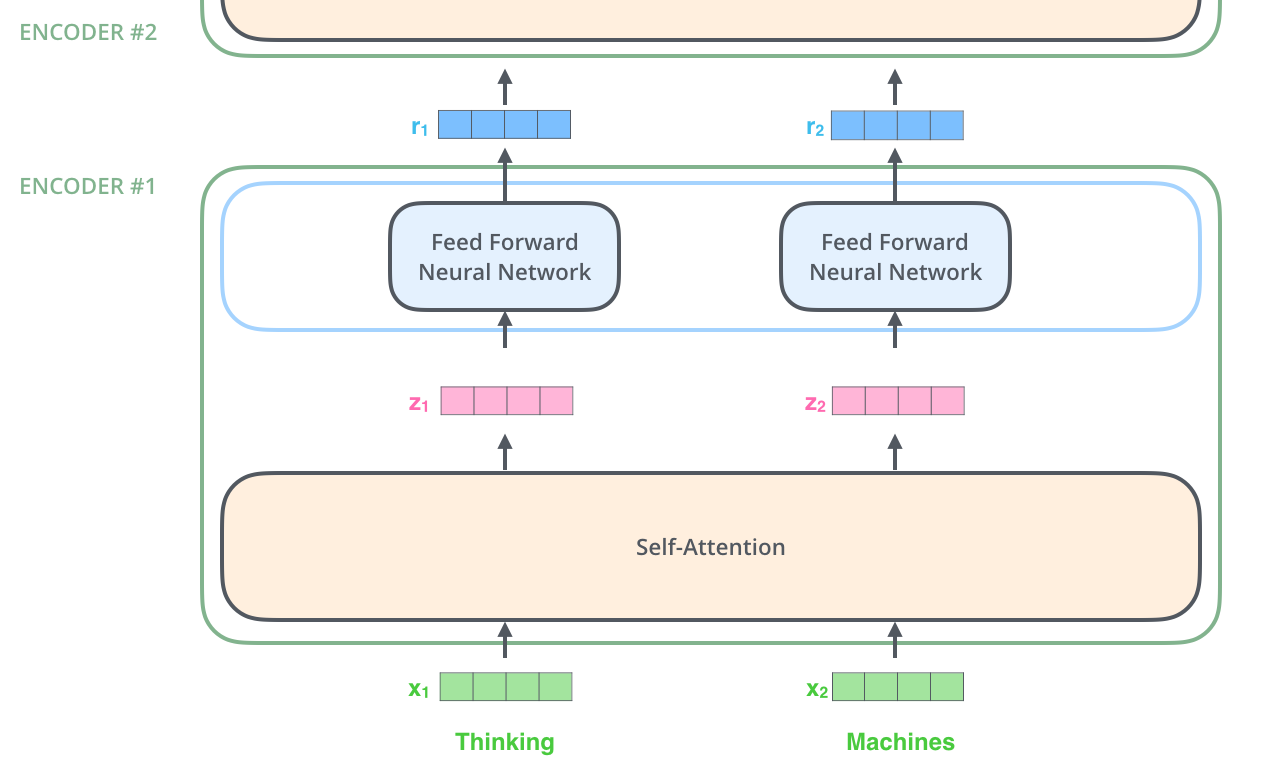
. , .
, « » -, . , «Attention is All You Need». , .
– , :
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
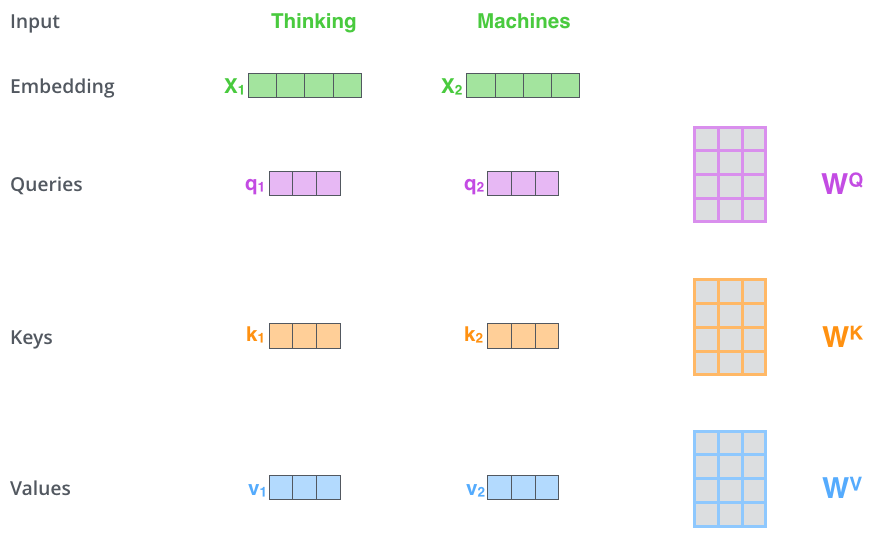
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
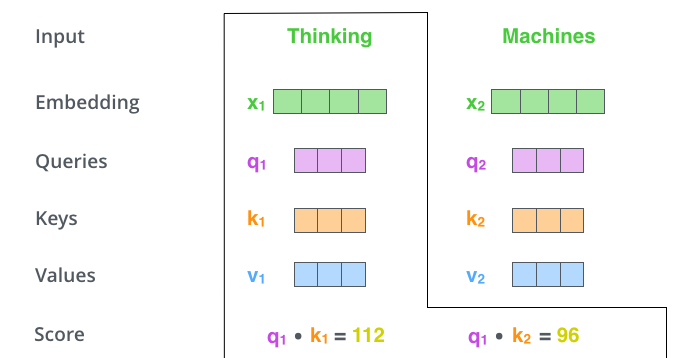
– 8 ( , – 64; , ), (softmax). , 1.
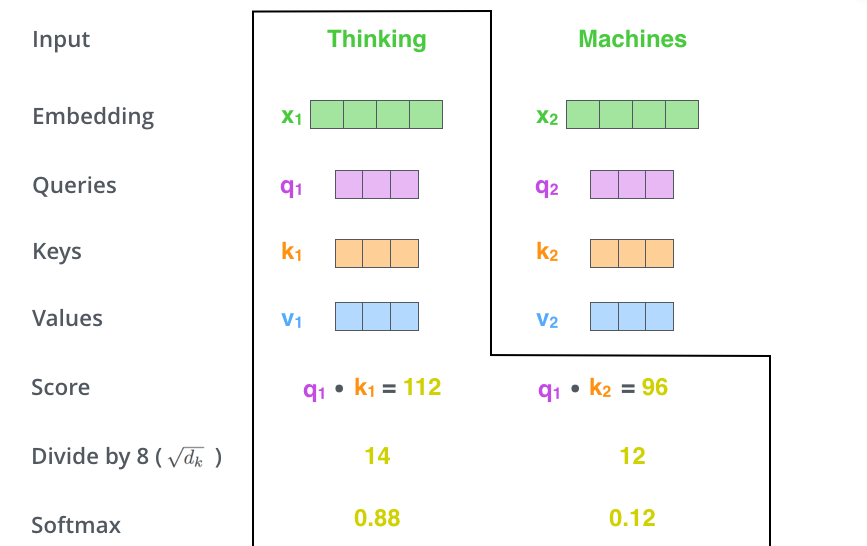
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
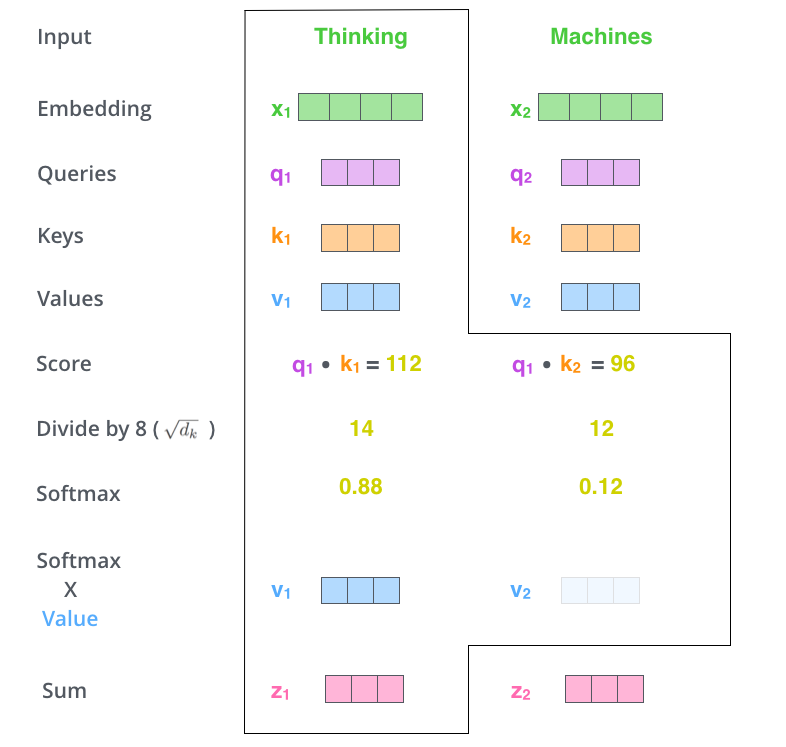
. , . , , . , , .
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
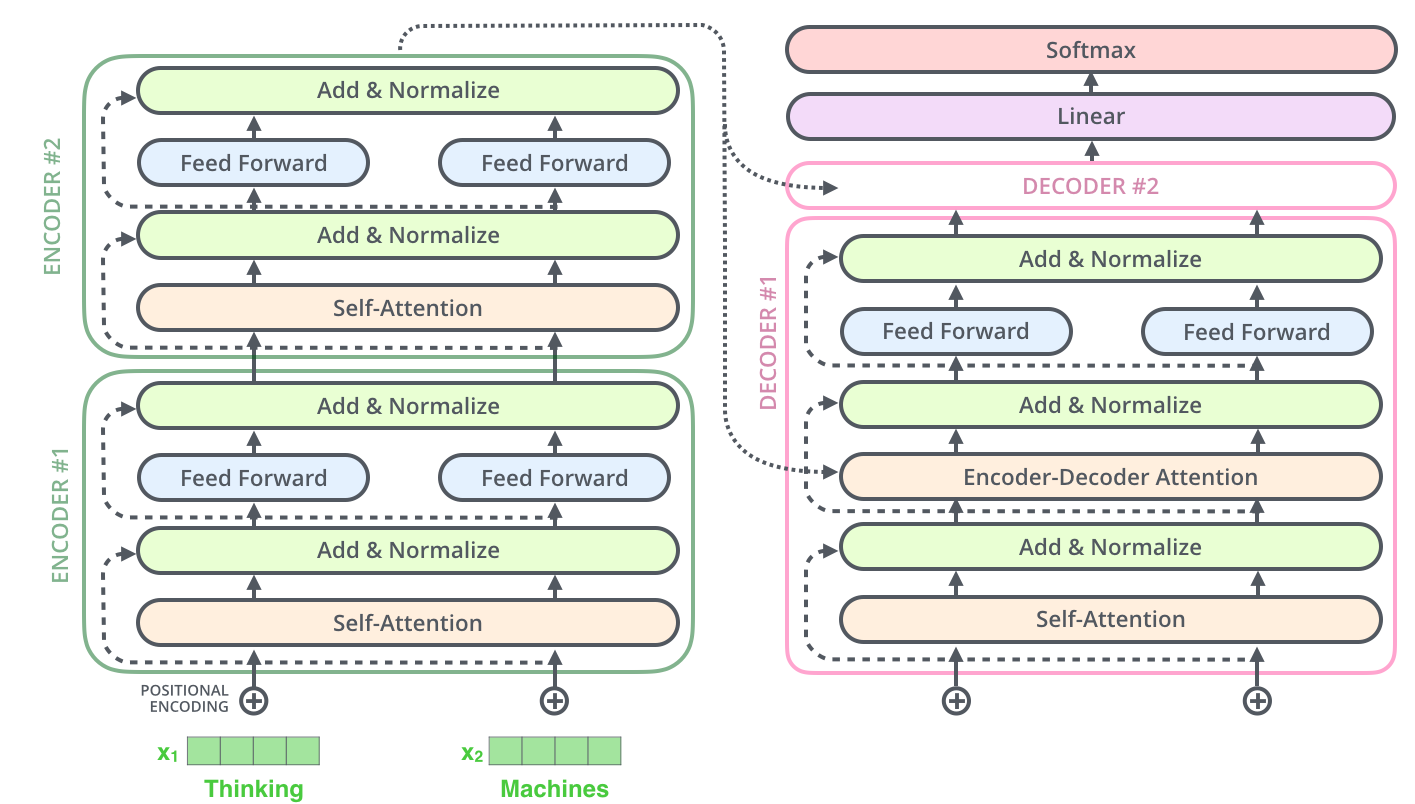
, , 2-6 .
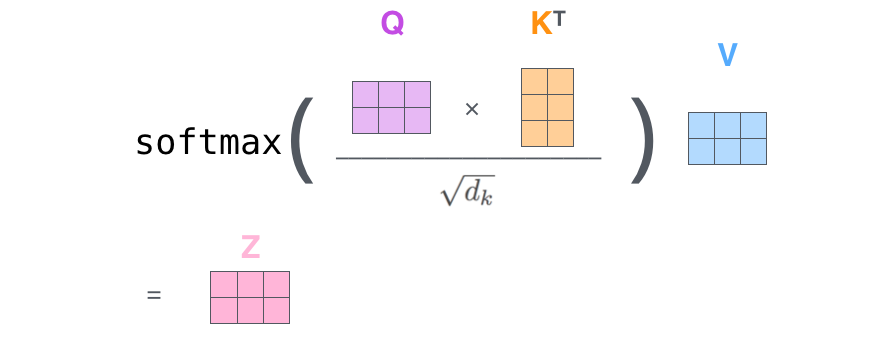
.
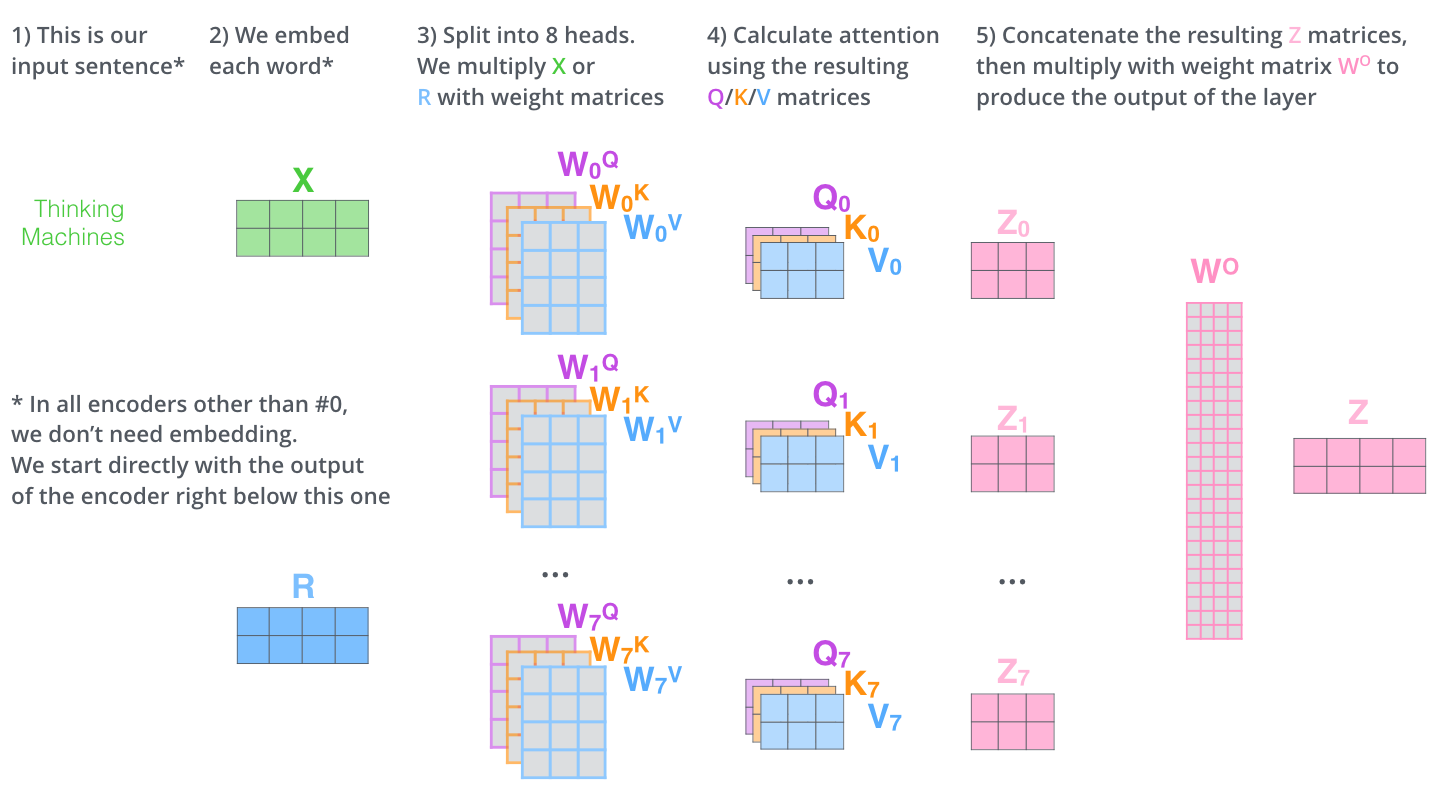
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
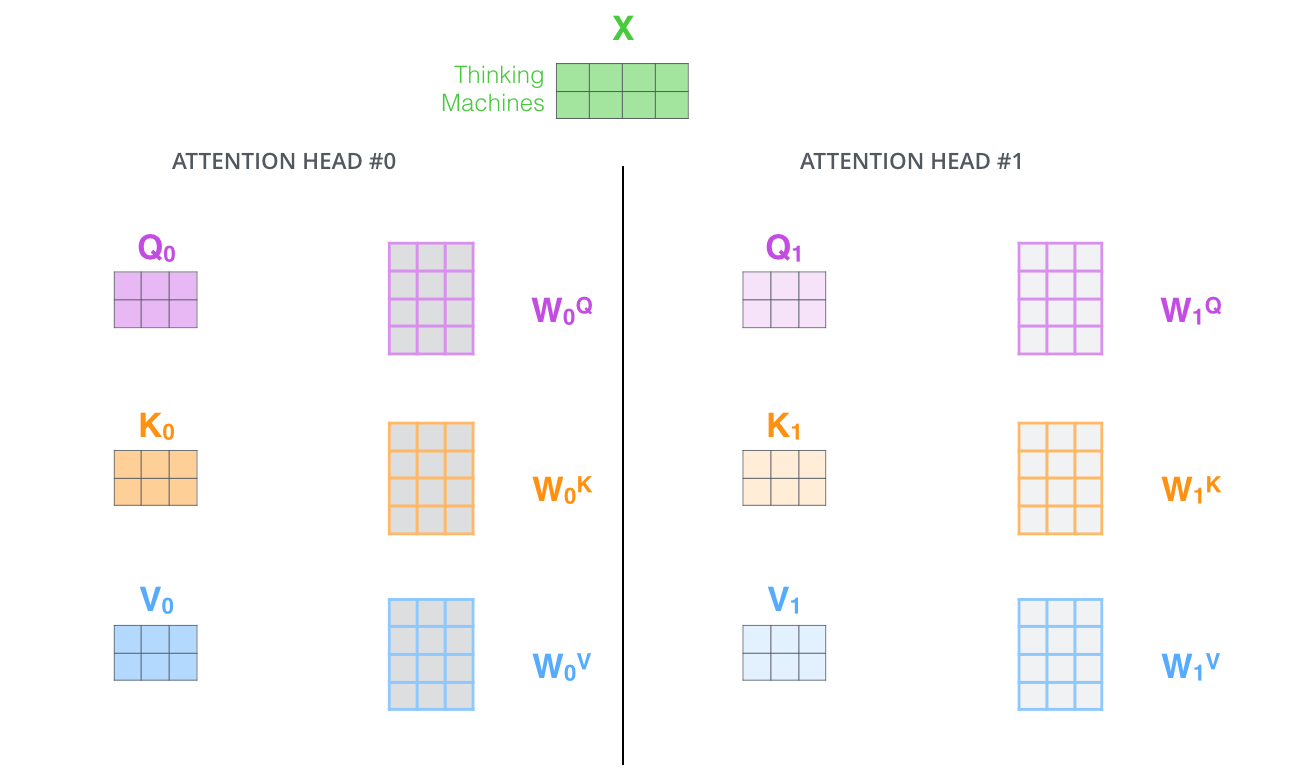
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
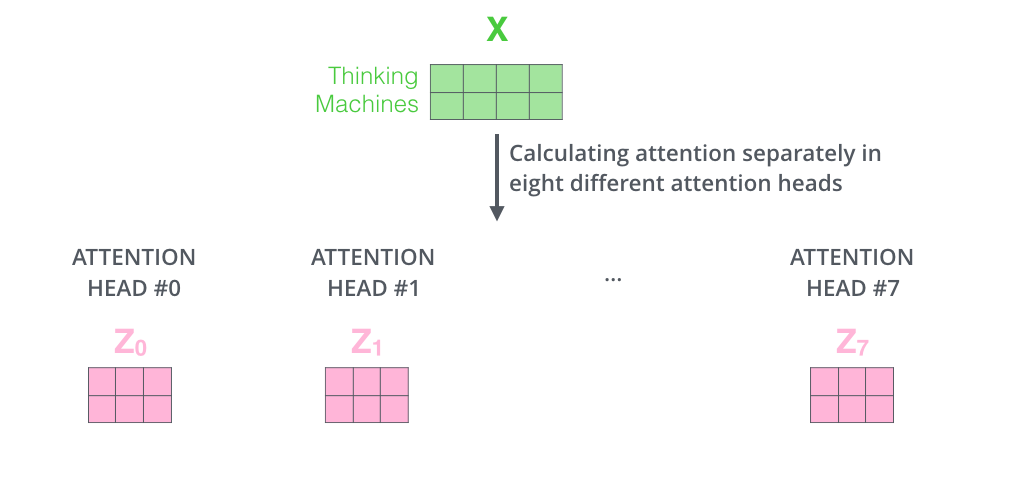
. , 8 – ( ), Z .
? WO.
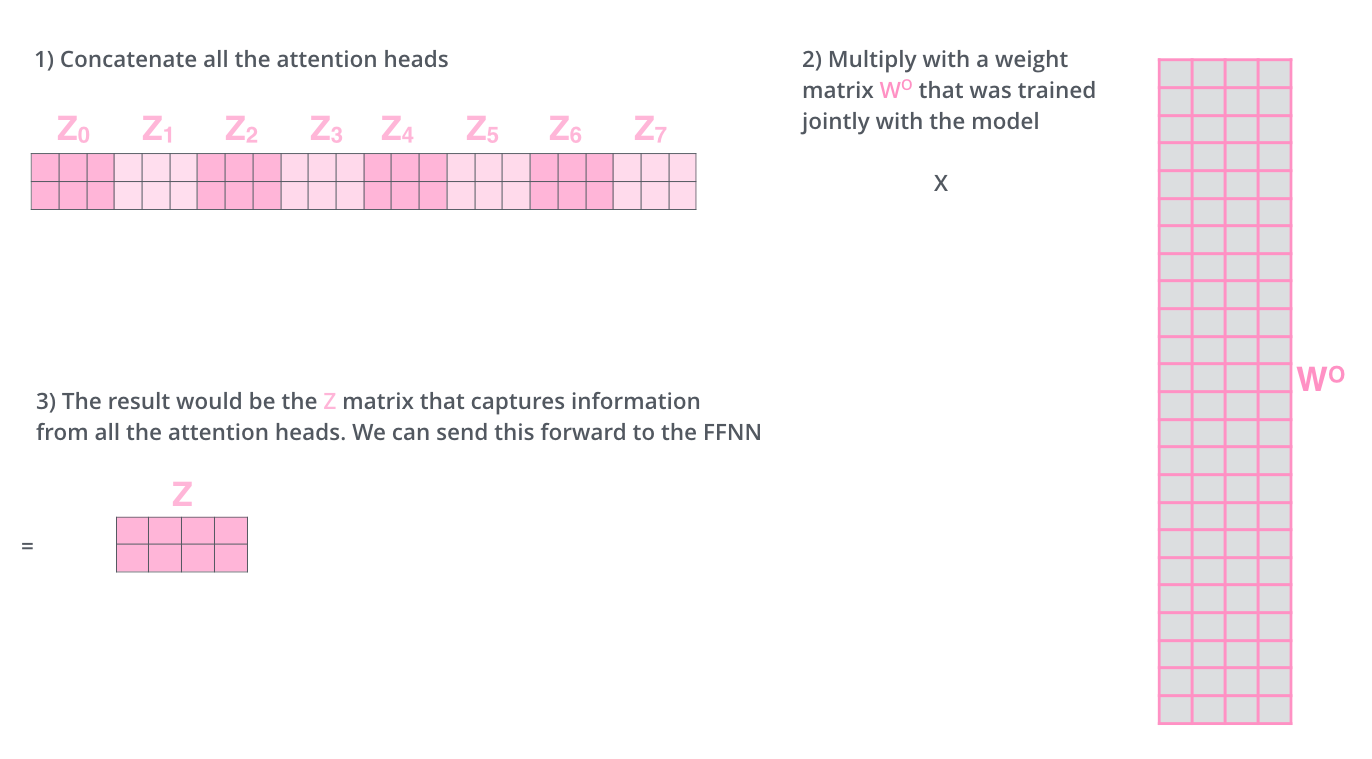
, , . , . , .
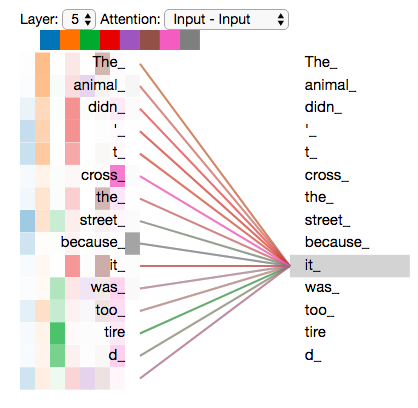
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
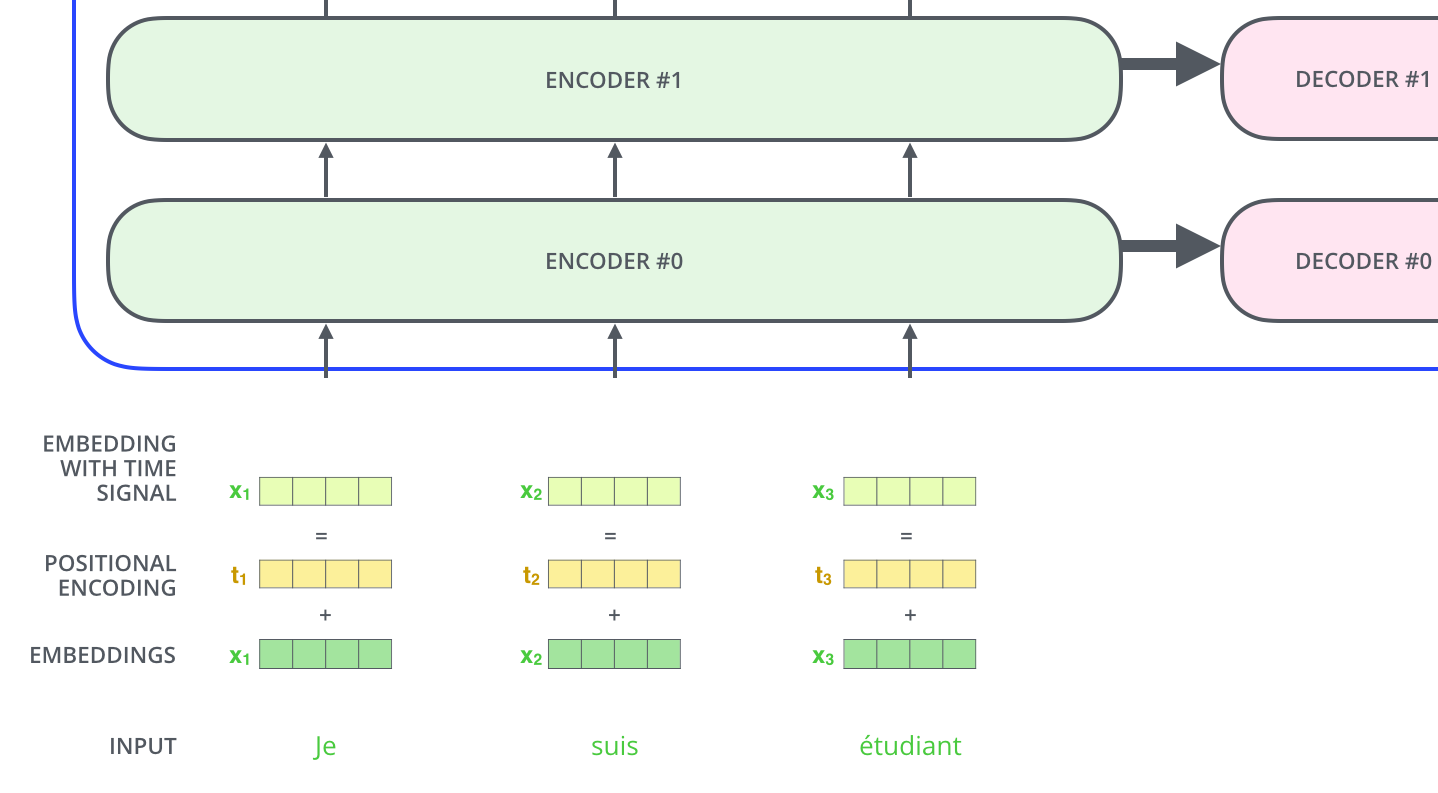
, , , .
, 4, :
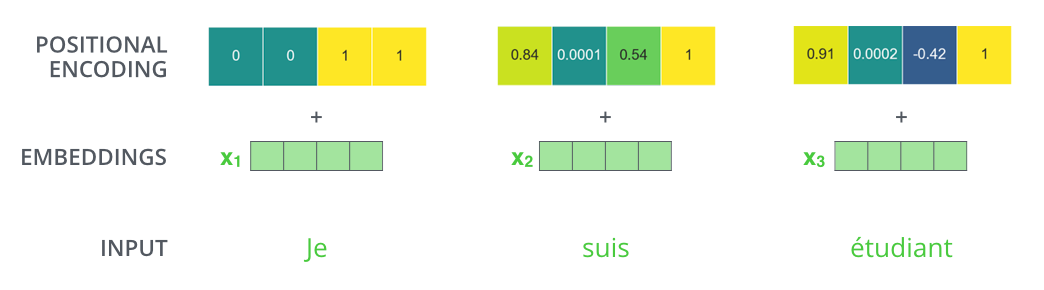
?
: , , , — .. 512 -1 1. , .
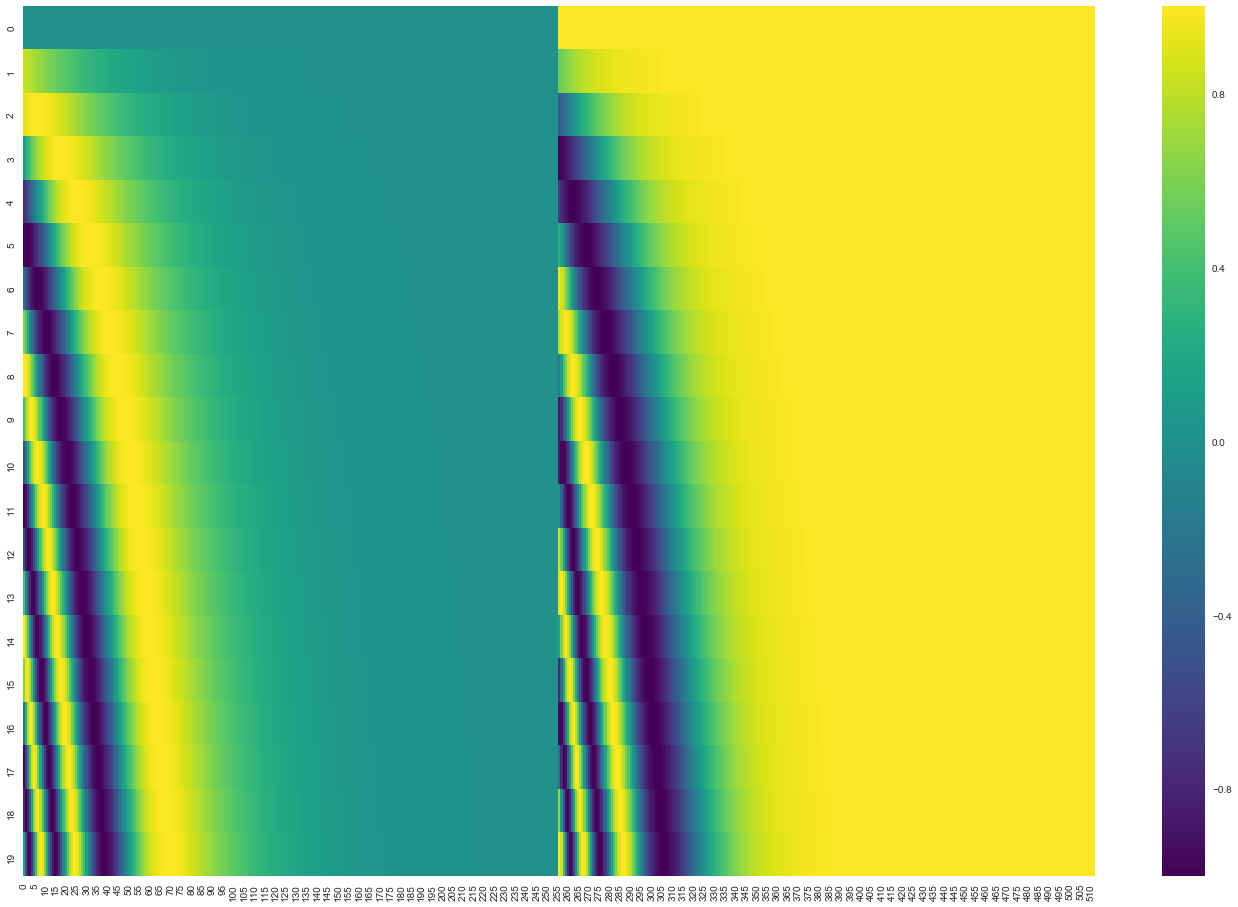
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
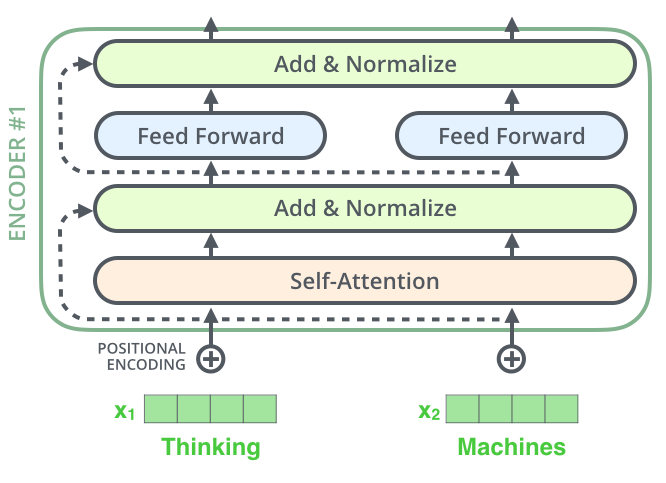
, , :
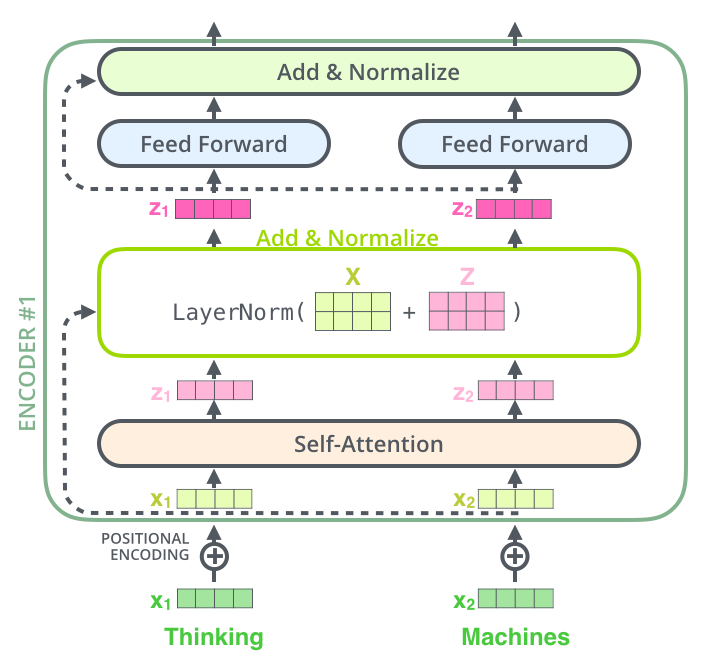
. , :
, , , . , .
. K V. «-» , :
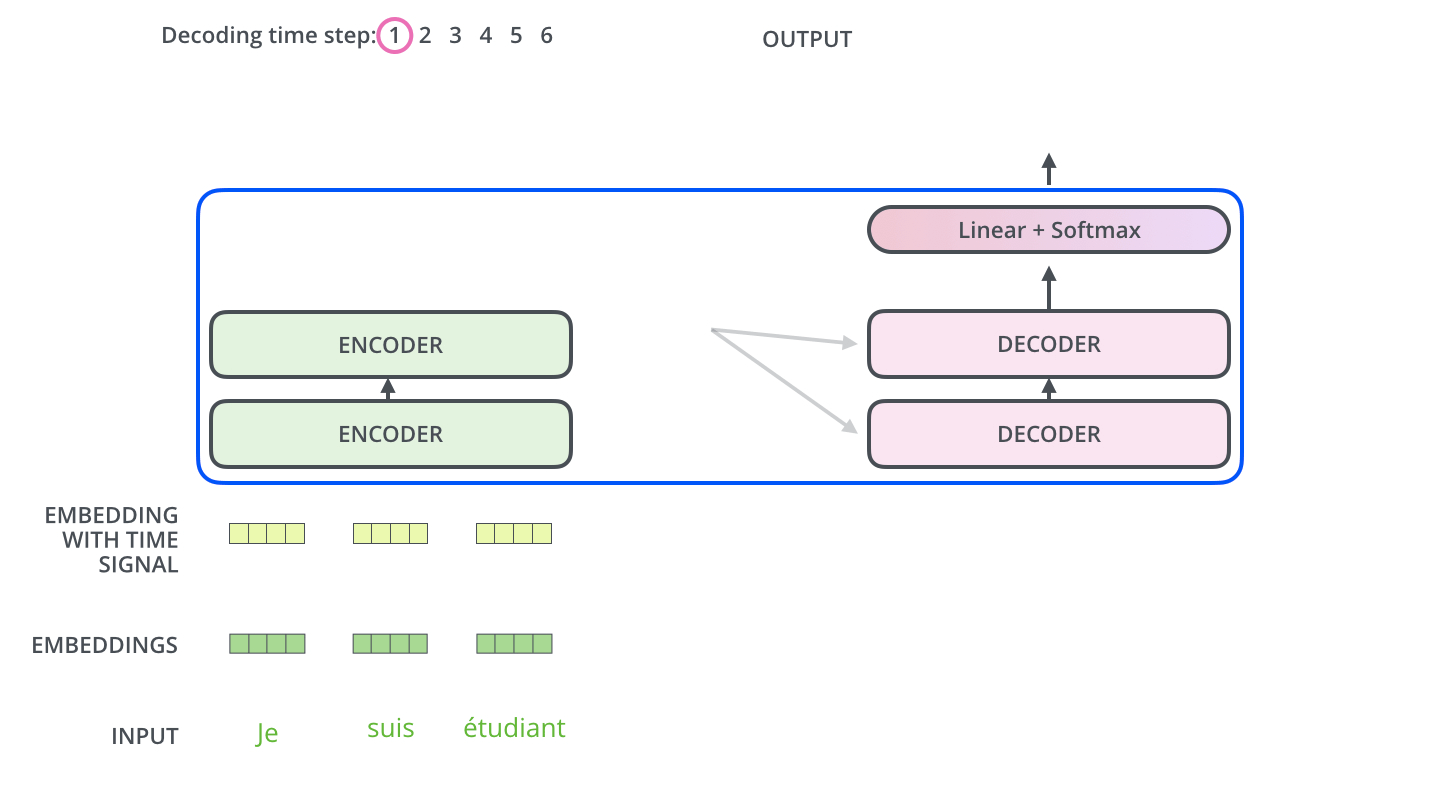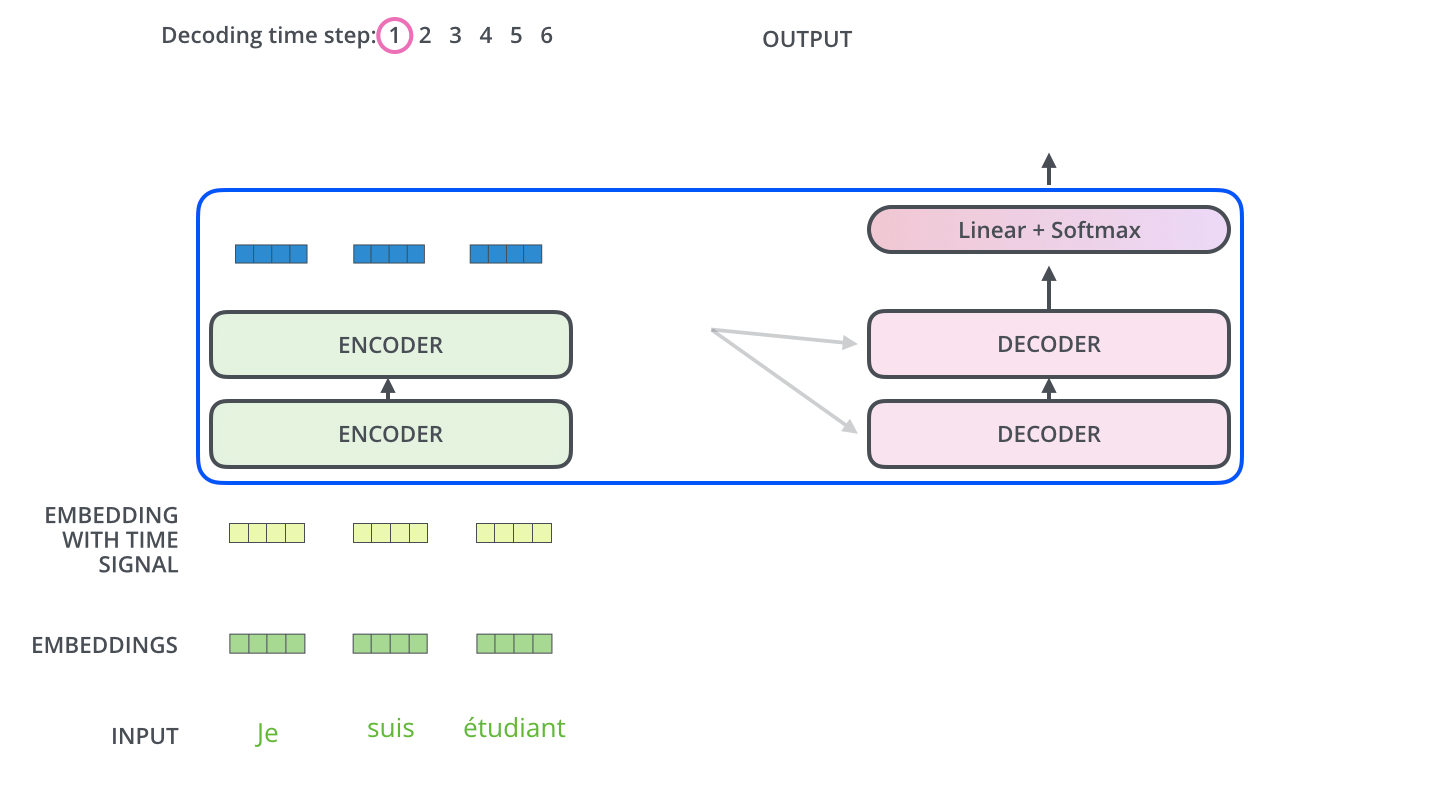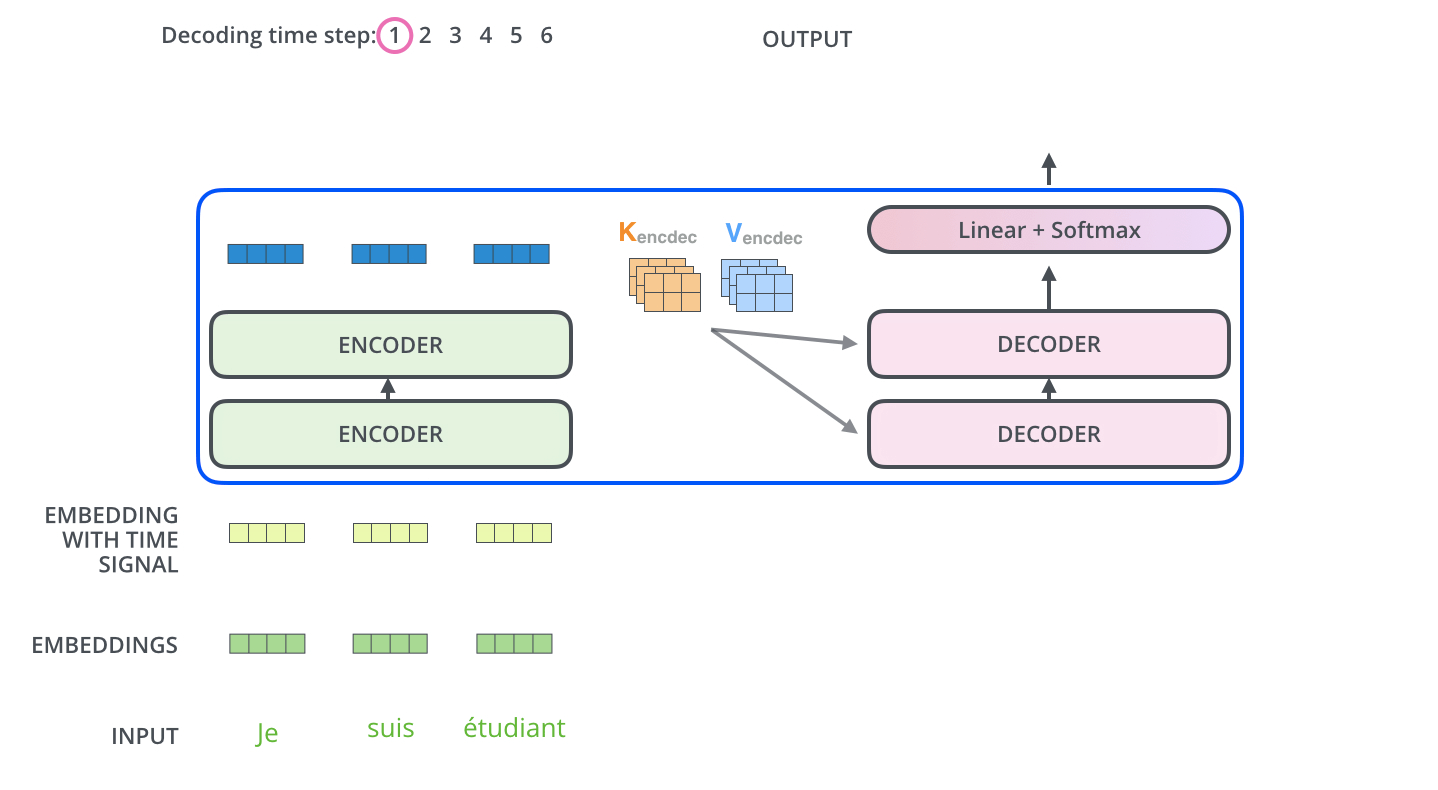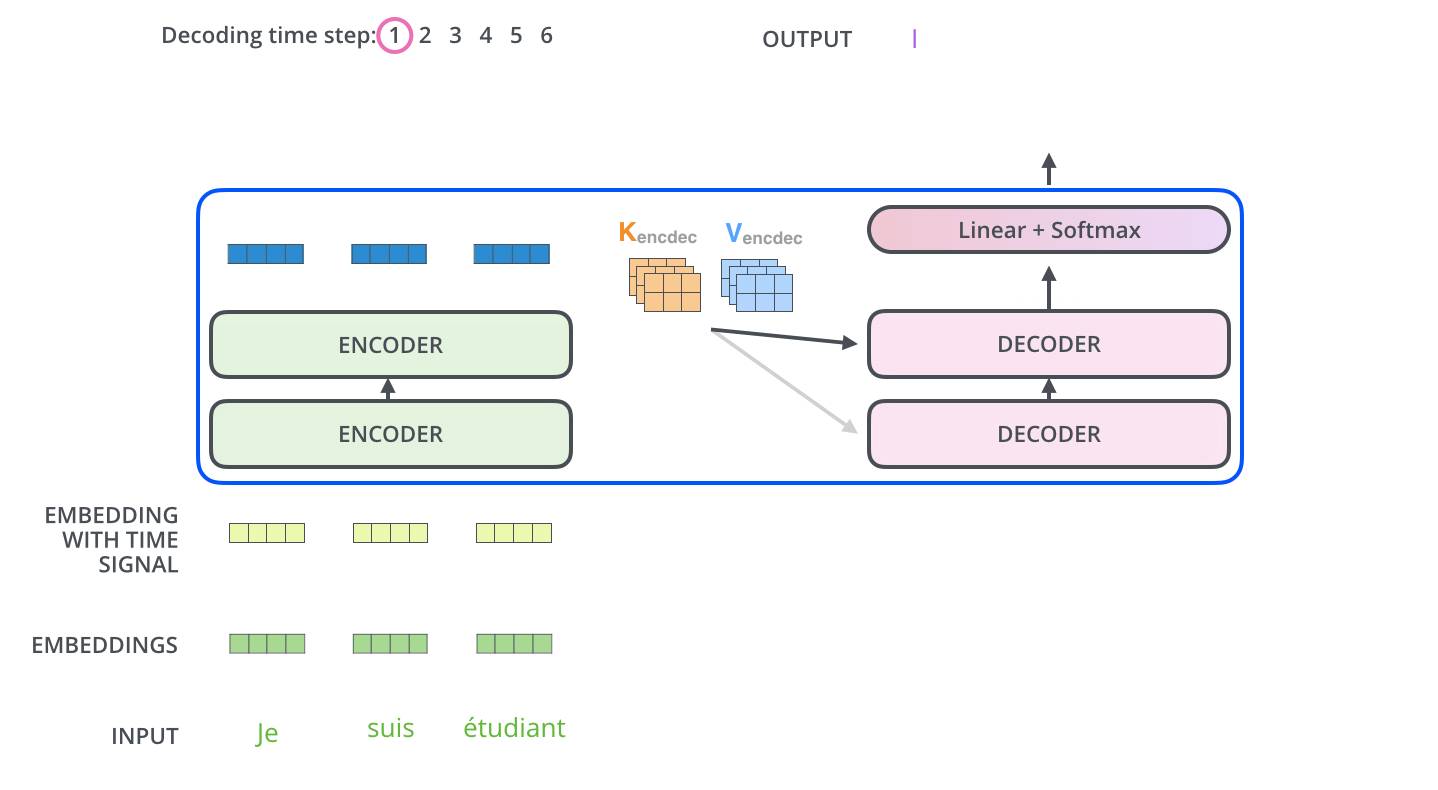
. ( – ).
, , . , , . , , , .
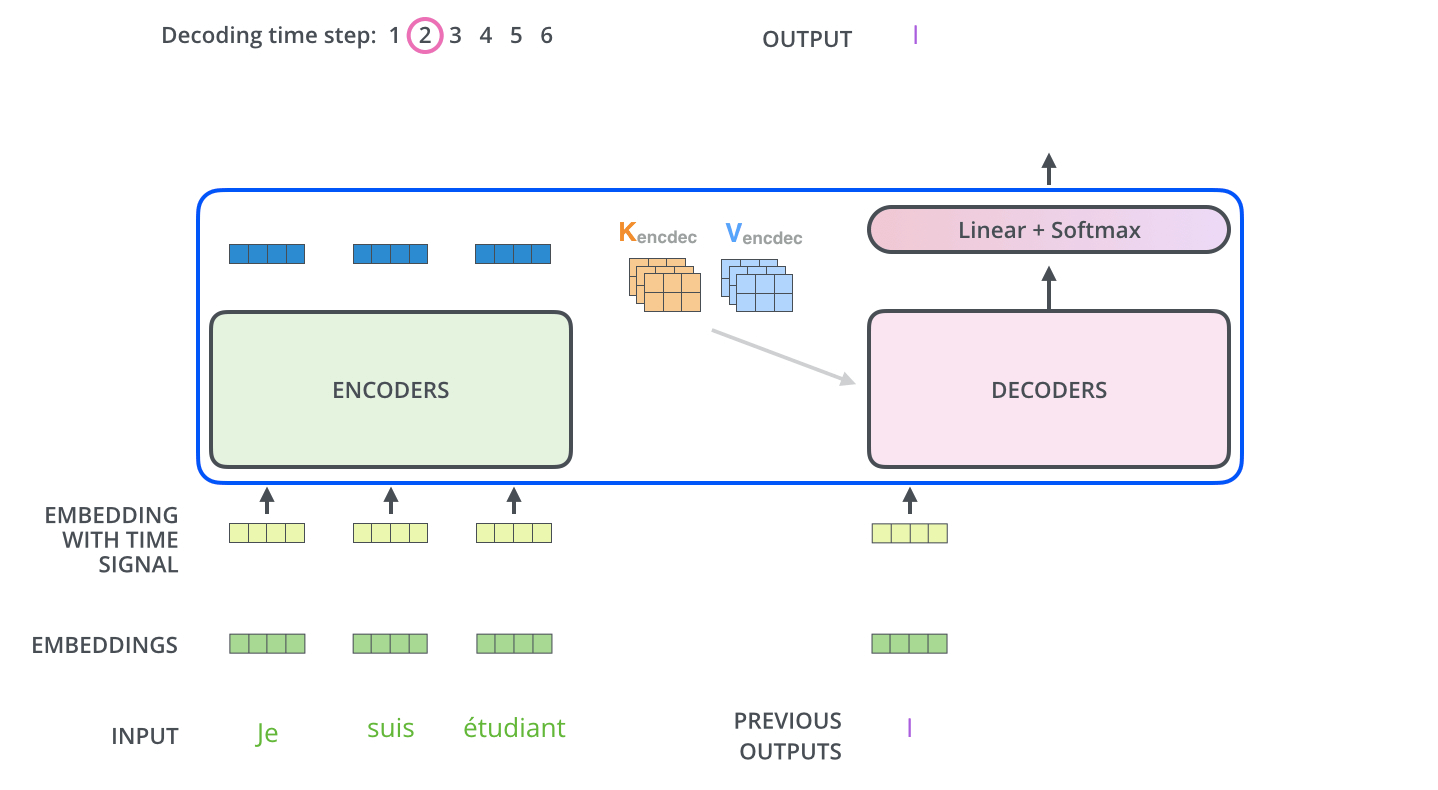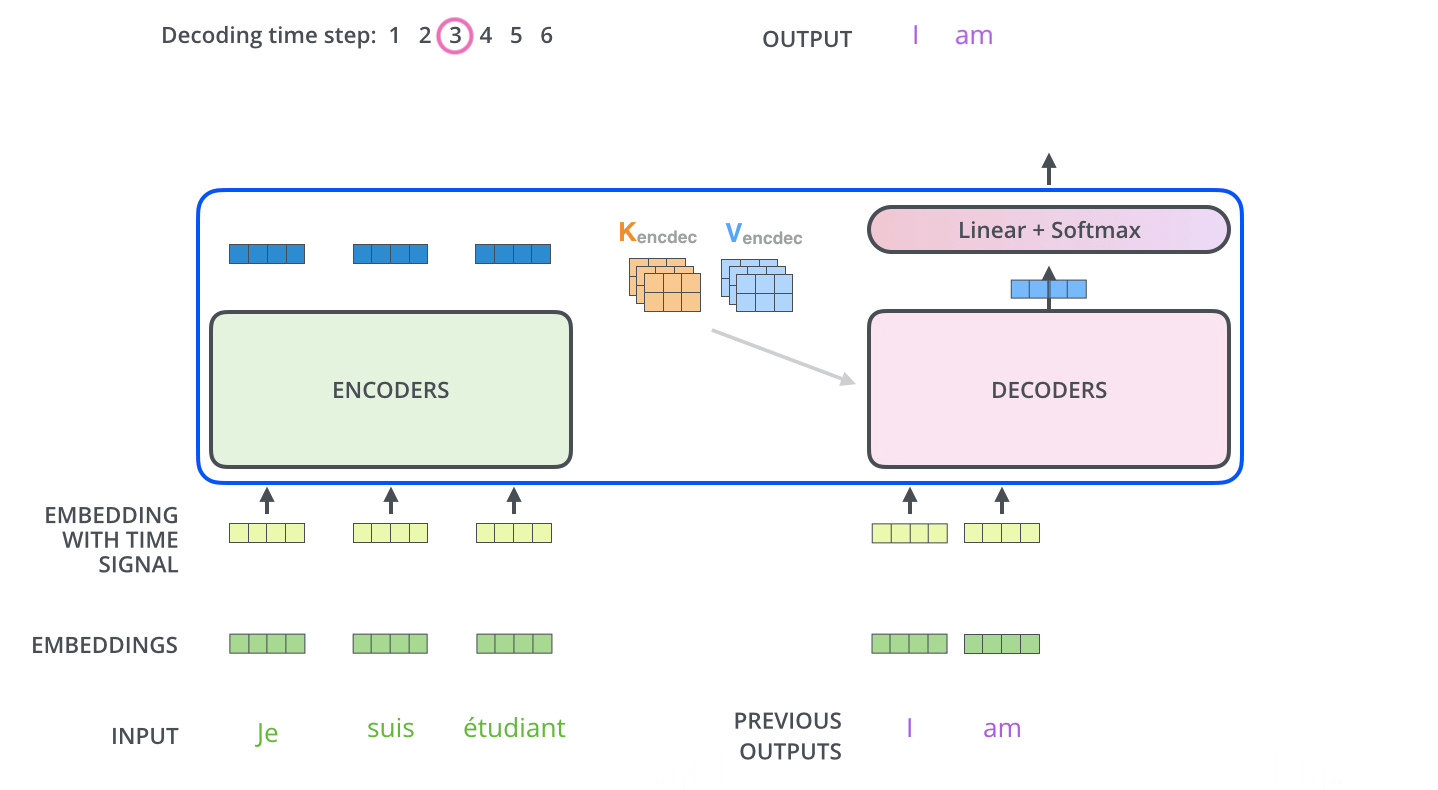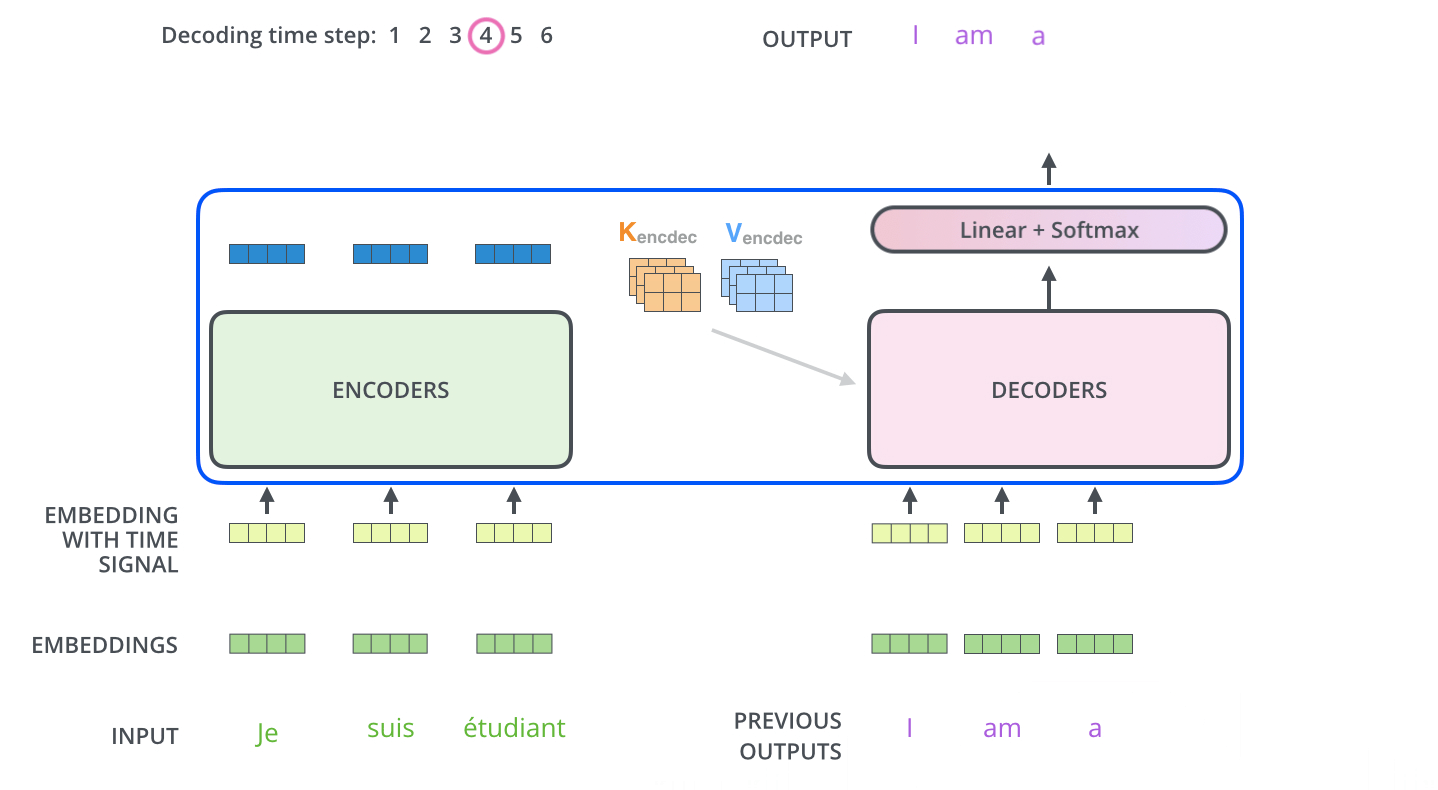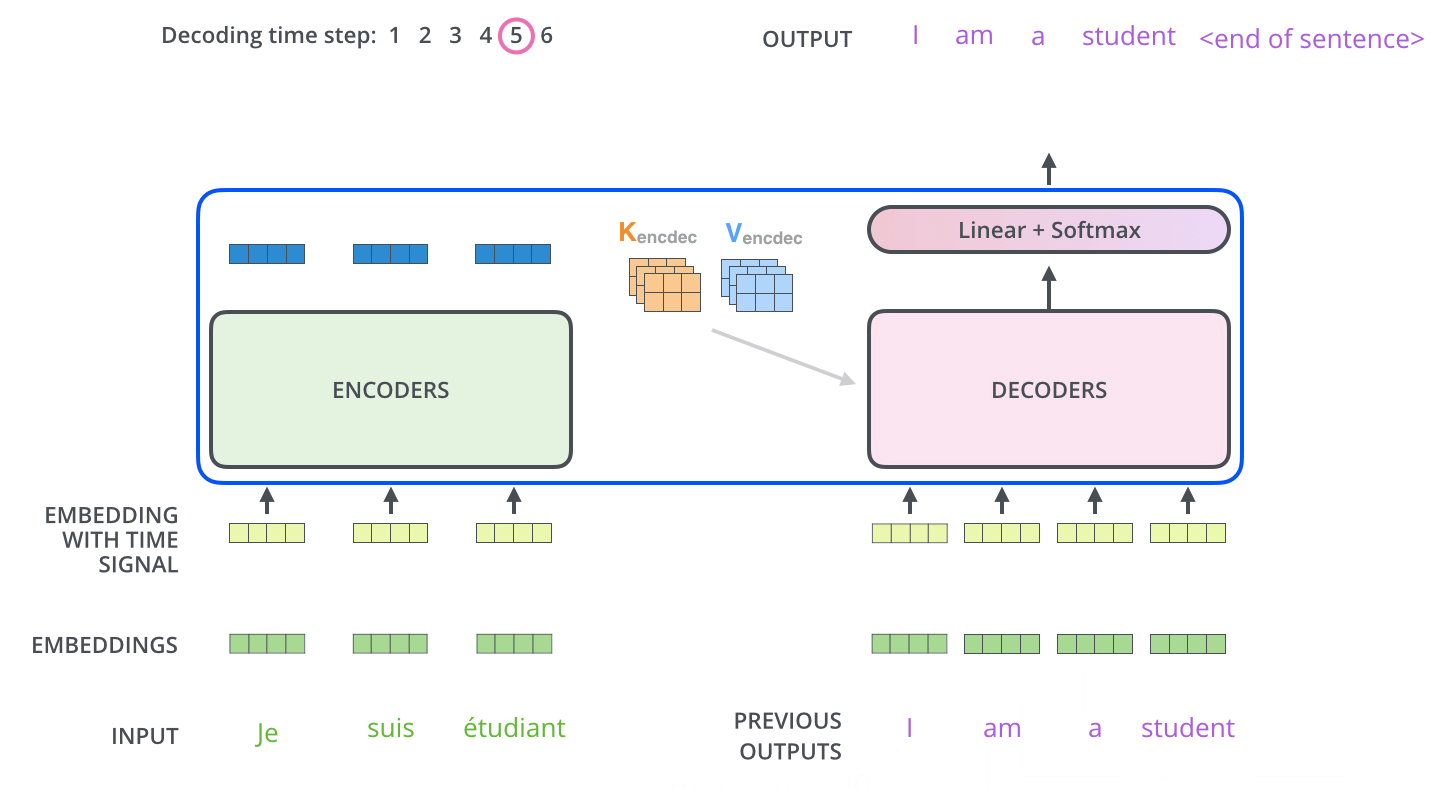
.
. ( –inf) .
«-» , , , , .
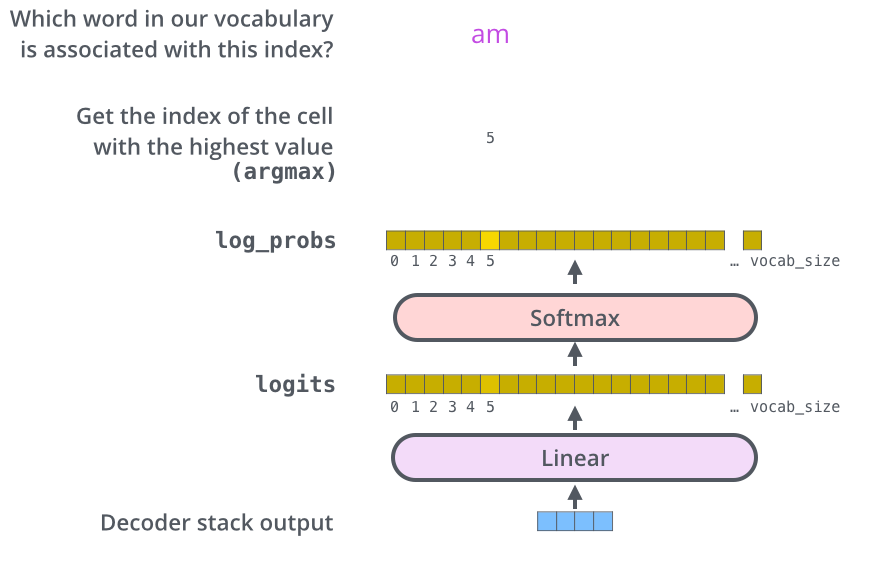
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
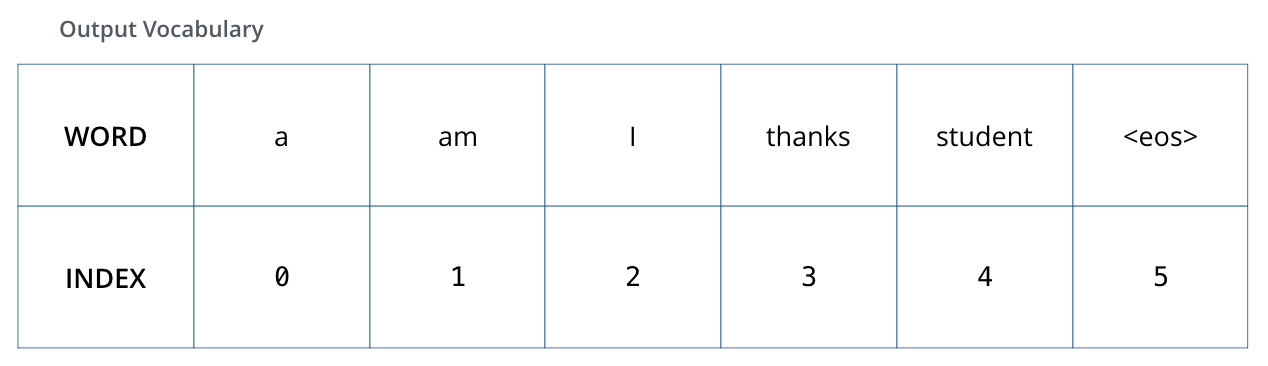
.
, (, one-hot-). , «am», :
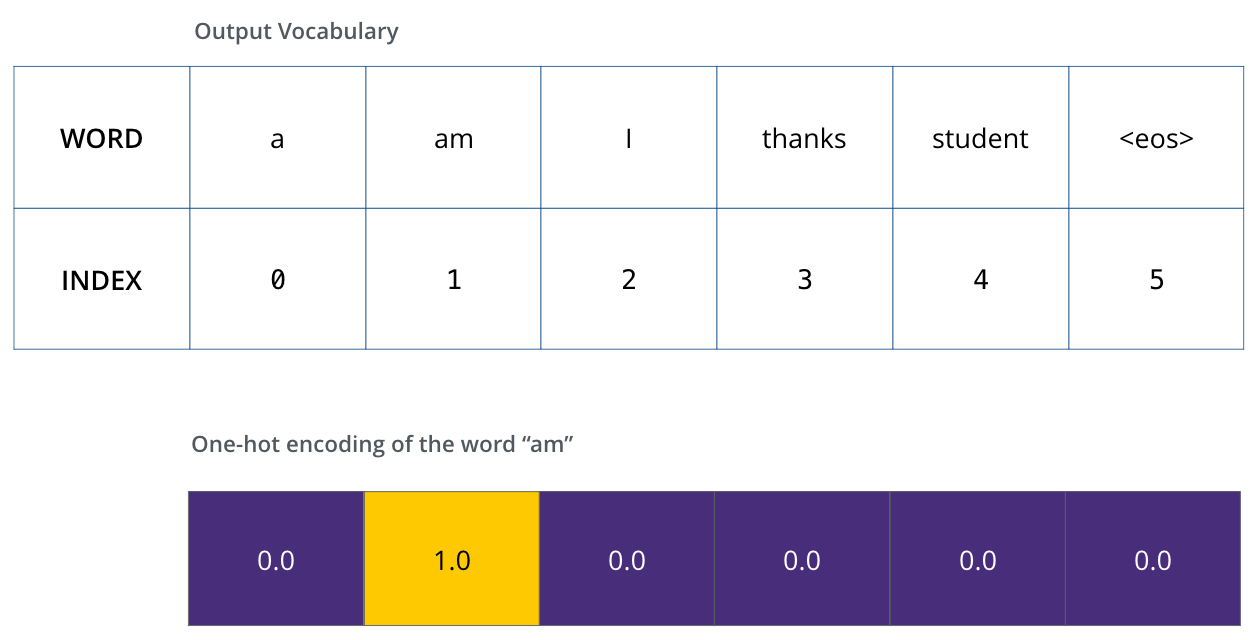
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
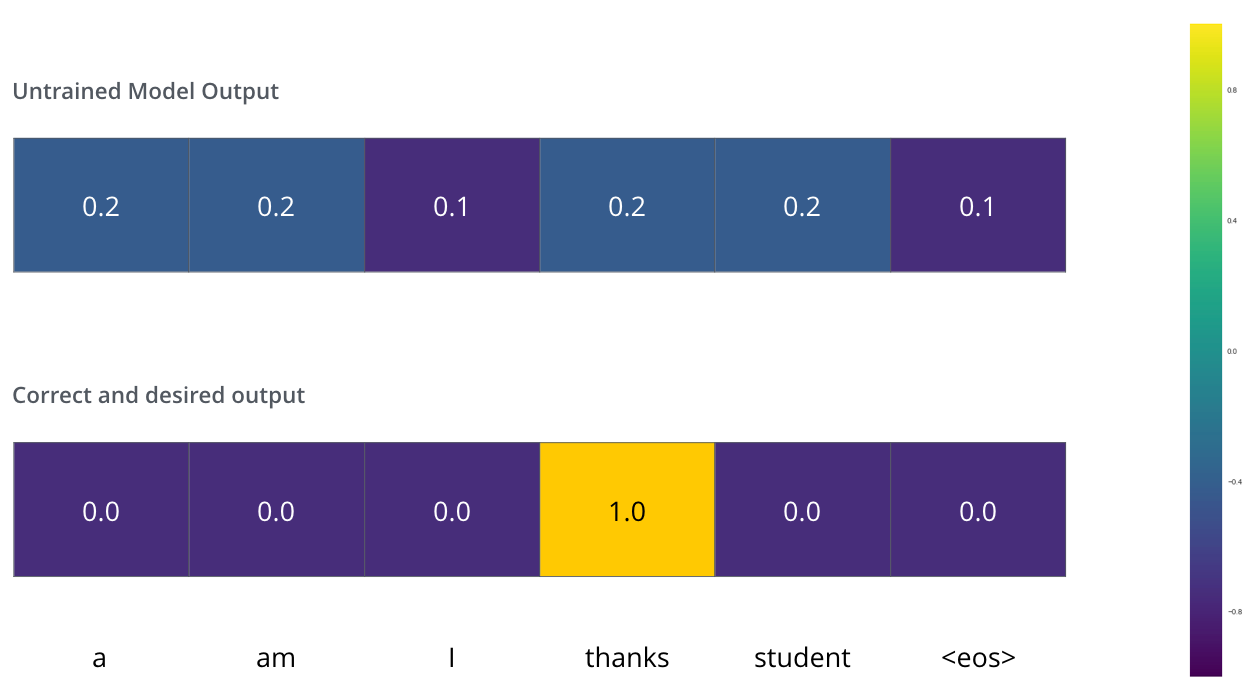
() , /. , , , .
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
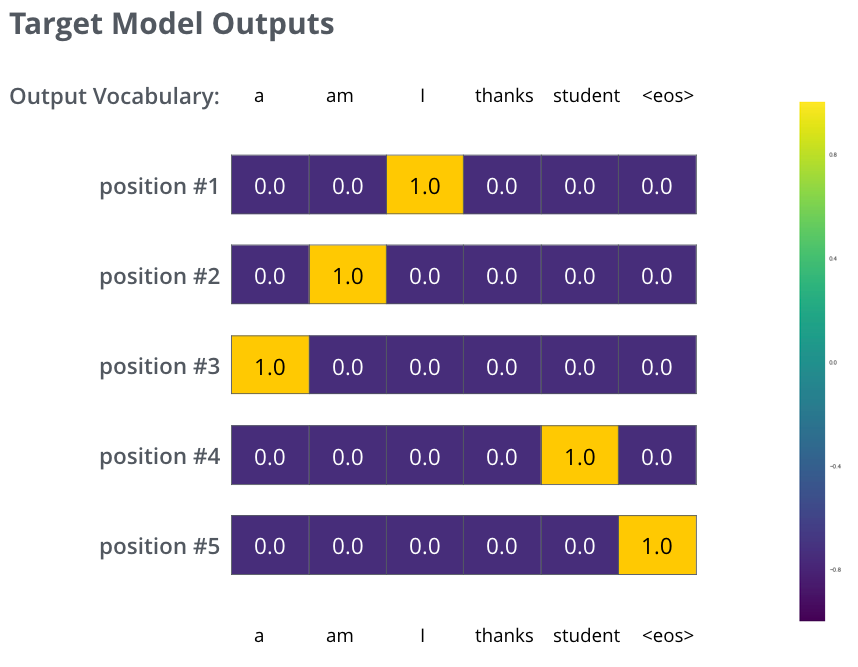
, :
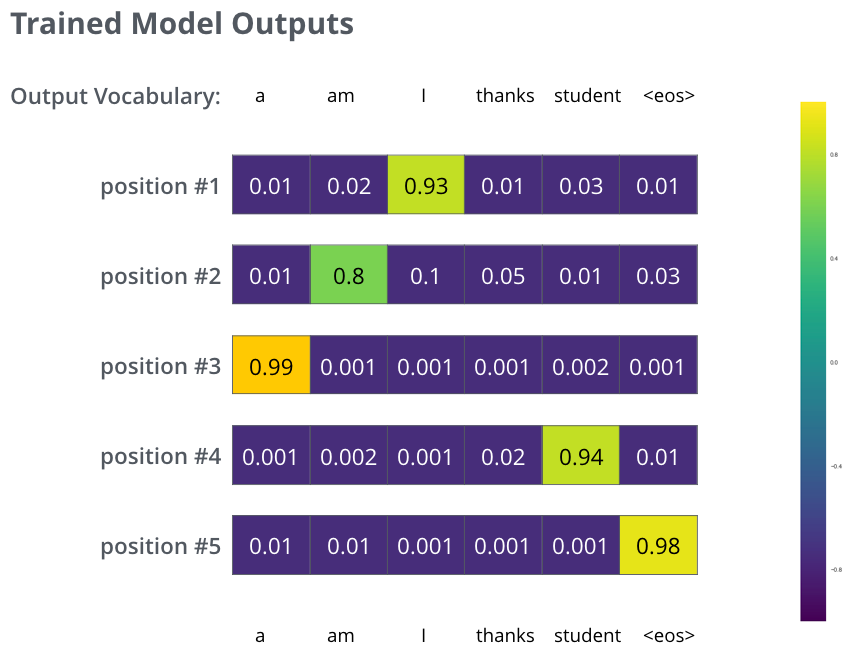
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
लेखक