NiFi gagne de plus en plus en popularité et avec chaque nouvelle version, il obtient de plus en plus d'outils pour travailler avec les données. Néanmoins, il peut être nécessaire d'avoir votre propre outil pour résoudre un problème spécifique. Apache Nifi a plus de 300 processeurs dans son package de base. Processeur Nifi Il s'agit de la principale pierre angulaire de la création de flux de données dans l'écosystème NiFi. Les processeurs fournissent une interface à travers laquelle NiFi donne accès au fichier de flux, à ses attributs et à son contenu. Son propre processeur personnalisé économisera de l'énergie, du temps et l'attention de l'utilisateur, car au lieu de nombreux éléments de processeur simples, un seul sera affiché dans l'interface et un seul sera exécuté (enfin, ou combien vous écrivez). Comme les processeurs standard, un processeur personnalisé vous permet d'effectuer diverses opérations et de traiter le contenu d'un fichier de flux. Aujourd'hui, nous allons parler des outils standard pour étendre les fonctionnalités.
Il s'agit de la principale pierre angulaire de la création de flux de données dans l'écosystème NiFi. Les processeurs fournissent une interface à travers laquelle NiFi donne accès au fichier de flux, à ses attributs et à son contenu. Son propre processeur personnalisé économisera de l'énergie, du temps et l'attention de l'utilisateur, car au lieu de nombreux éléments de processeur simples, un seul sera affiché dans l'interface et un seul sera exécuté (enfin, ou combien vous écrivez). Comme les processeurs standard, un processeur personnalisé vous permet d'effectuer diverses opérations et de traiter le contenu d'un fichier de flux. Aujourd'hui, nous allons parler des outils standard pour étendre les fonctionnalités.ExecuteScript
ExecuteScript est un processeur universel conçu pour implémenter la logique métier dans un langage de programmation (Groovy, Jython, Javascript, JRuby). Cette approche vous permet d'obtenir rapidement les fonctionnalités souhaitées. Pour fournir l'accès aux composants NiFi dans un script, il est possible d'utiliser les variables suivantes:Session : une variable de type org.apache.nifi.processor.ProcessSession. La variable vous permet d'effectuer des opérations avec un fichier de flux, telles que create (), putAttribute () et Transfer (), ainsi que read () et write ().Contexte : org.apache.nifi.processor.ProcessContext. Il peut être utilisé pour obtenir les propriétés du processeur, les relations, les services de contrôleur et StateManager.REL_SUCCESS : Relation "succès".REL_FAILURE : Relation d' échecPropriétés dynamiques : les propriétés dynamiques définies dans ExecuteScript sont transmises au moteur de script en tant que variables, définies en tant que PropertyValue. Cela vous permet d'obtenir la valeur de la propriété, de convertir la valeur dans le type de données approprié, par exemple, logique, etc.Pour l'utiliser, il suffit de sélectionner Script Engineet de spécifier l'emplacement du fichier Script Fileavec notre script ou le script lui-même Script Body.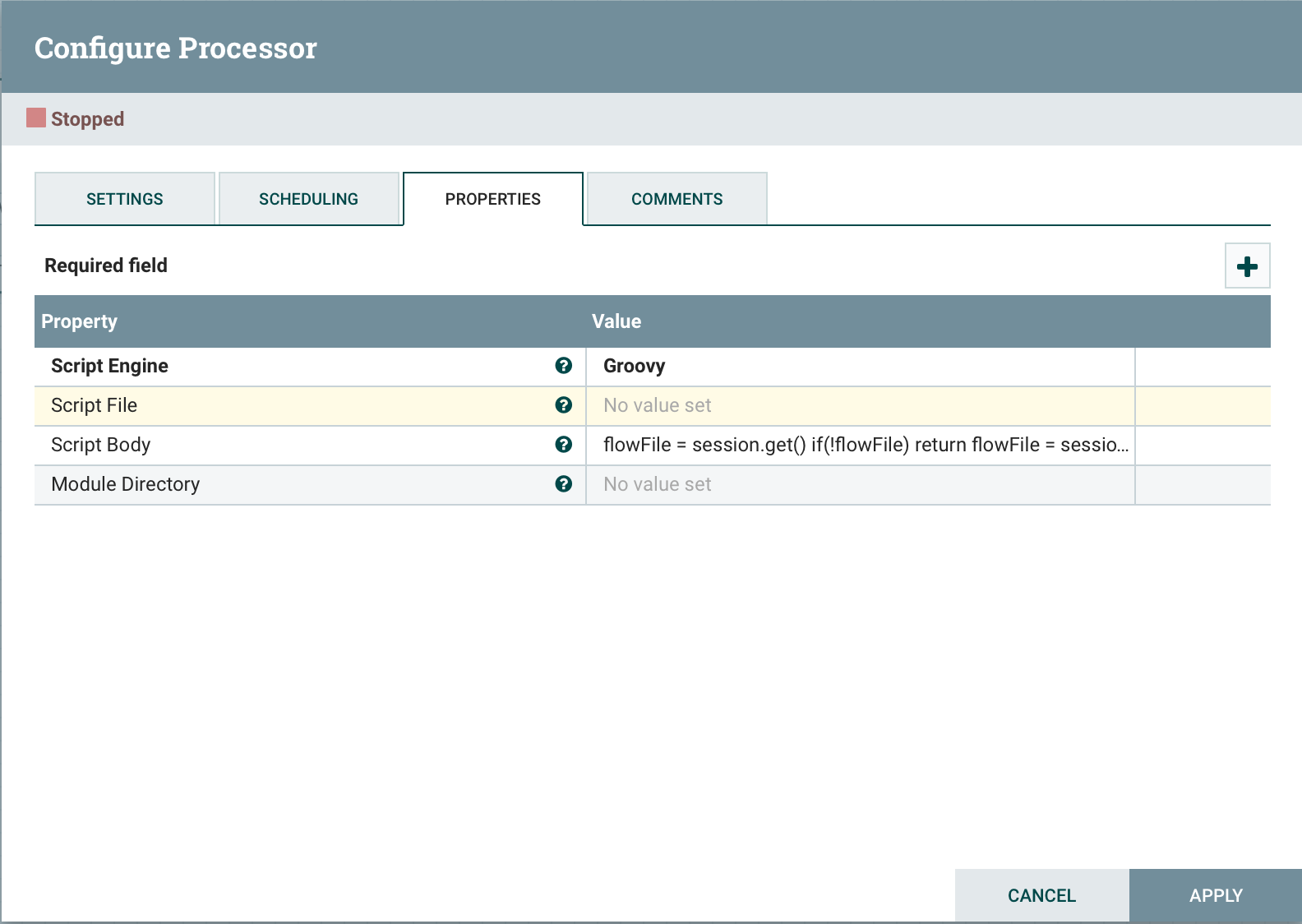 Voyons quelques exemples:obtenir un fichier de flux de la file d'attente
Voyons quelques exemples:obtenir un fichier de flux de la file d'attenteflowFile = session.get()
if(!flowFile) return
Générer un nouveau FlowFileflowFile = session.create()
// Additional processing here
Ajouter un attribut à FlowFileflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Extraire et traiter tous les attributs.flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Enregistreurlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
Vous pouvez utiliser des fonctionnalités avancées dans ExecuteScript, vous trouverez plus d'informations à ce sujet dans l'article ExecuteScript Cookbook.ExecuteGroovyScript
ExecuteGroovyScript a les mêmes fonctionnalités qu'ExecuteScript, mais au lieu d'un zoo de langages valides, vous ne pouvez en utiliser qu'un seul - groovy. Le principal avantage de ce processeur est son utilisation plus pratique des services de service. En plus de l'ensemble standard de variables Session, Context, etc. Vous pouvez définir des propriétés dynamiques avec le préfixe CTL et SQL. À partir de la version 1.11, la prise en charge de RecordReader et Record Writer est apparue. Toutes les propriétés sont HashMap, qui utilise le "Nom du service" comme clé, et la valeur est un objet spécifique en fonction de la propriété:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
Cette information facilite déjà la vie. nous pouvons regarder dans les sources ou trouver de la documentation pour une classe particulière.Utilisation de la base de donnéesSi nous définissons la propriété SQL.DB et lions DBCPService, nous accéderons à la propriété à partir du code. SQL.DB.rows('select * from table') Le processeur accepte automatiquement une connexion du service dbcp avant l'exécution et traite la transaction. Les transactions de base de données sont automatiquement annulées lorsqu'une erreur se produit et sont validées en cas de succès. Dans ExecuteGroovyScript, vous pouvez intercepter les événements de démarrage et d'arrêt en implémentant les méthodes statiques appropriées.
Le processeur accepte automatiquement une connexion du service dbcp avant l'exécution et traite la transaction. Les transactions de base de données sont automatiquement annulées lorsqu'une erreur se produit et sont validées en cas de succès. Dans ExecuteGroovyScript, vous pouvez intercepter les événements de démarrage et d'arrêt en implémentant les méthodes statiques appropriées.import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
Un autre processeur intéressant. Pour l'utiliser, vous devez déclarer une classe qui implémente l'interface implements et définir une variable de processeur. Vous pouvez définir n'importe quel PropertyDescriptor ou Relation, également accéder au ComponentLog parent et définir les méthodes void onScheduled (contexte ProcessContext) et void onStopped (contexte ProcessContext). Ces méthodes seront appelées lorsqu'un événement de démarrage planifié se produit en NiFi (onScheduled) et lorsqu'il s'arrête (onScheduled).class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
La logique doit être implémentée dans la méthode void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
Il n'est pas nécessaire de décrire toutes les méthodes déclarées dans l'interface, alors contournons une classe abstraite dans laquelle nous déclarons la méthode suivante:abstract void executeScript(ProcessContext context, ProcessSession session)
La méthode que nous appelleronsvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Maintenant, nous déclarons une classe successeur BaseGroovyProcessoret décrivons notre executeScript, nous ajoutons également Relation RELSUCCESS et RELFAILURE.import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
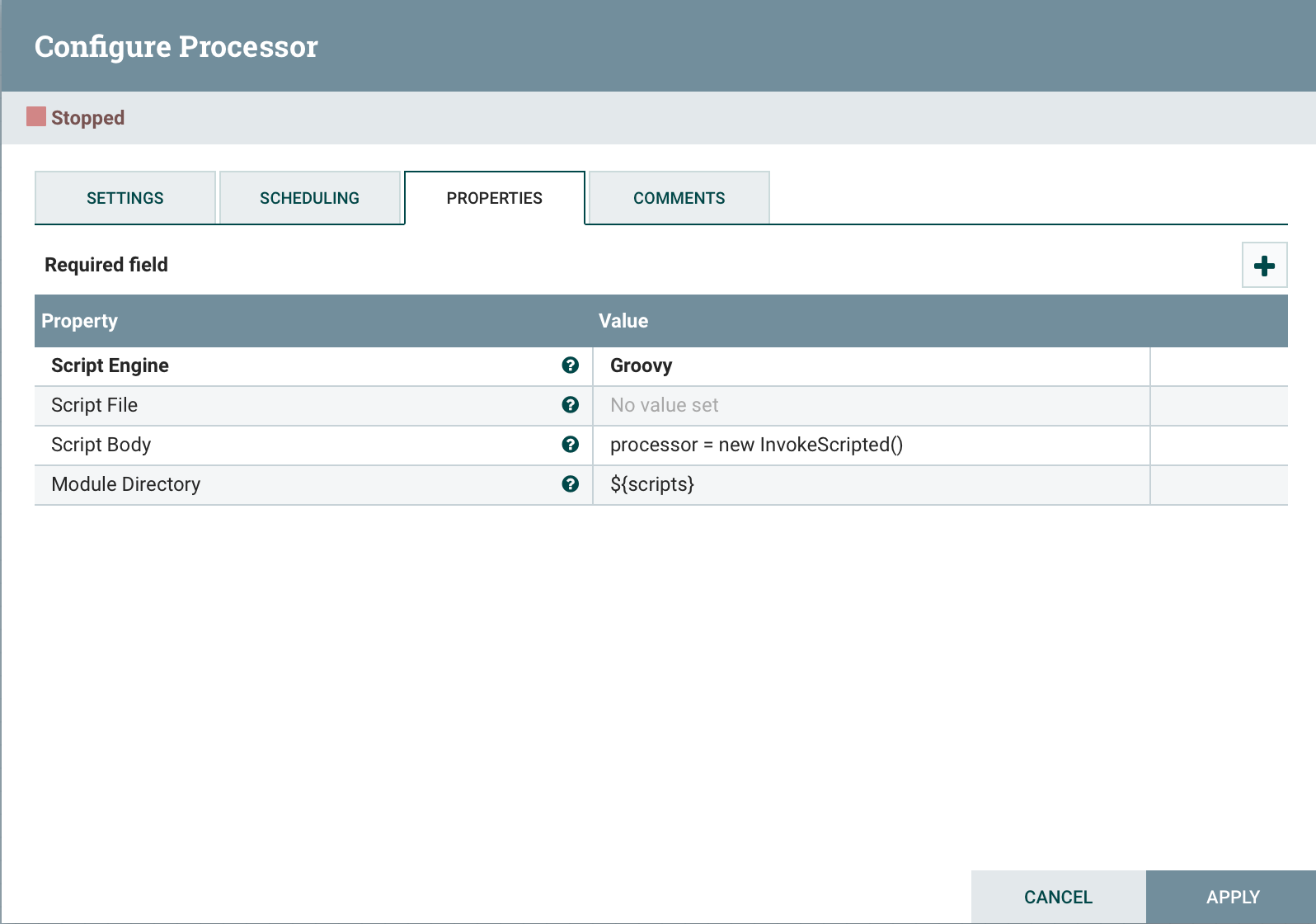 Ajoutez à la fin du code.
Ajoutez à la fin du code. processor = new InvokeScripted()Cette approche est similaire à la création d'un processeur personnalisé.Conclusion
La création d'un processeur personnalisé n'est pas la chose la plus simple - pour la première fois, vous devrez travailler dur pour le comprendre, mais les avantages de cette action sont indéniables.Article préparé par l'équipe de gestion des données de Rostelecom