salut!Dans cet article, je vais vous expliquer comment créer une page dans Atlassian Confluence avec une table dont les données proviendront d'une requête REST.Nous allons créer une page dans Confluence avec un tableau qui contiendra les données du projet dans Jira. Nous obtiendrons ces données de Jira en utilisant la méthode de projet de l'API REST Jira standard.Vous pouvez regarder la vidéo de cet article ici .Installer des scripts d'alimentation pour Confluence
Nous effectuerons un appel à l'API Jira REST à l'aide du plugin Power Scripts for Confluence . Il s'agit d'un plugin gratuit, donc cette solution ne vous coûtera rien.Eh bien, la première chose que nous devons faire est d'installer le plugin Power Scripts pour Confluence dans notre Confluence. Des instructions détaillées sur la façon de procéder peuvent être trouvées ici .Écrire un script
Maintenant, allez à l'élément de menu engrenage -> Gérer les applications -> SIL Manager. Créez le fichier getProjects.sil avec le code suivant:
Créez le fichier getProjects.sil avec le code suivant:struct Project {
string key;
string name;
string projectTypeKey;
}
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
Project [] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
runnerLog(projects);
return projects;
Modifiez l'adresse de host.docker.internal : 8080 / à l'adresse de votre instance Jira.Exécutez le script pour vérifier que les données sont sélectionnées dans Jira: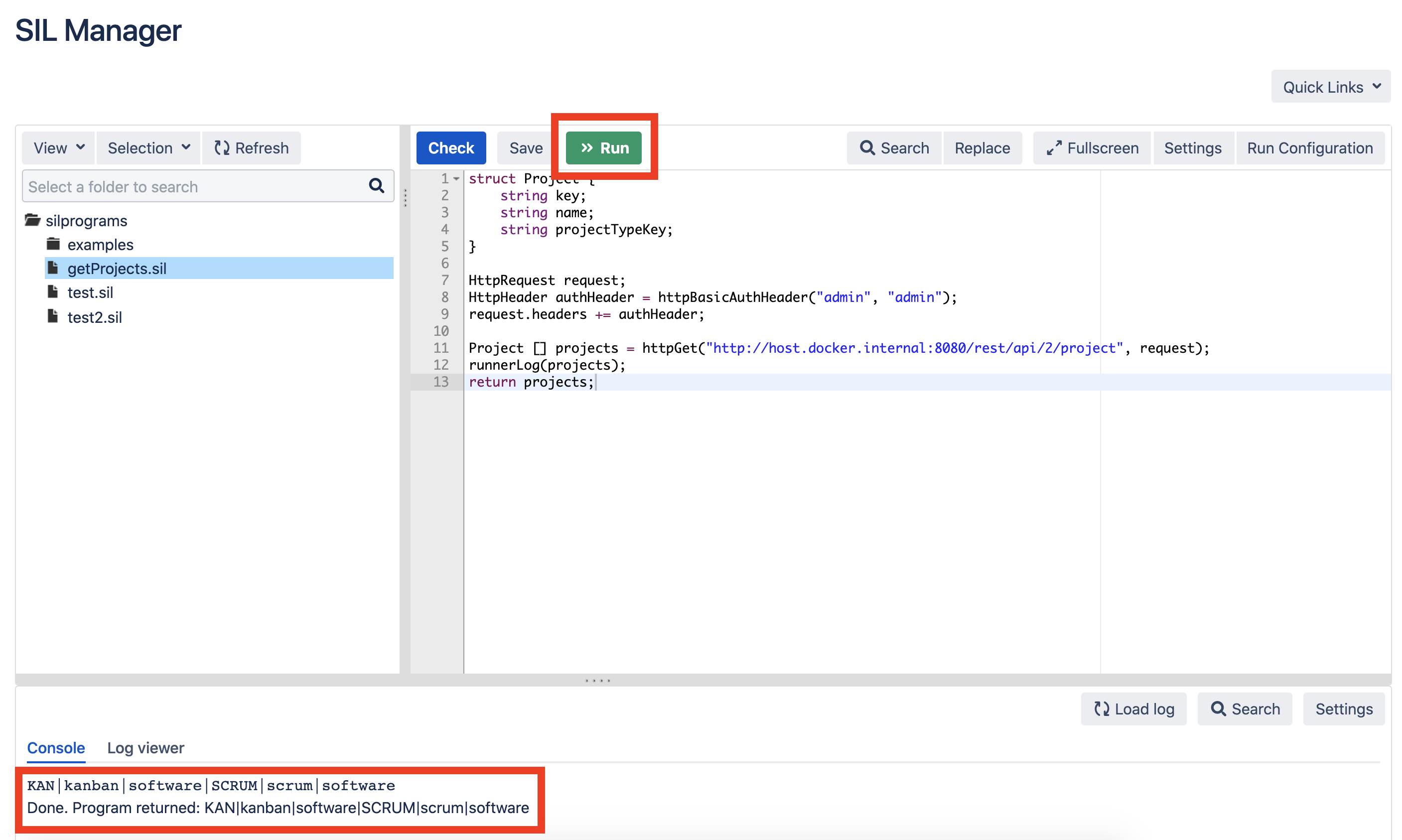
Créer une page dans Confluence
Créez maintenant une page dans Confluence avec la macro de table SIL . Dans le champ des scripts, entrez le nom de notre script getProjects.sil: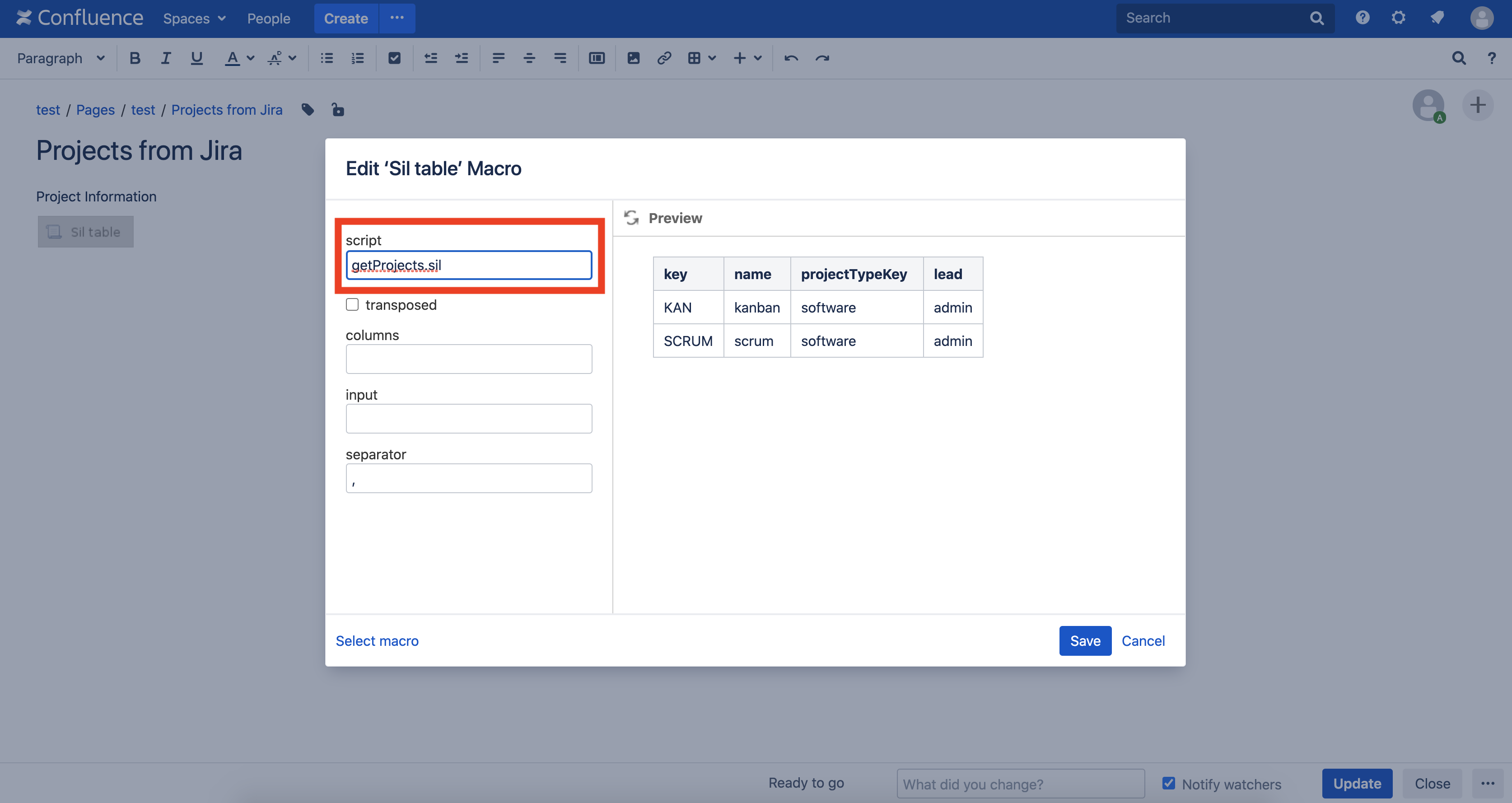 Publiez la page et vous verrez ce résultat:
Publiez la page et vous verrez ce résultat: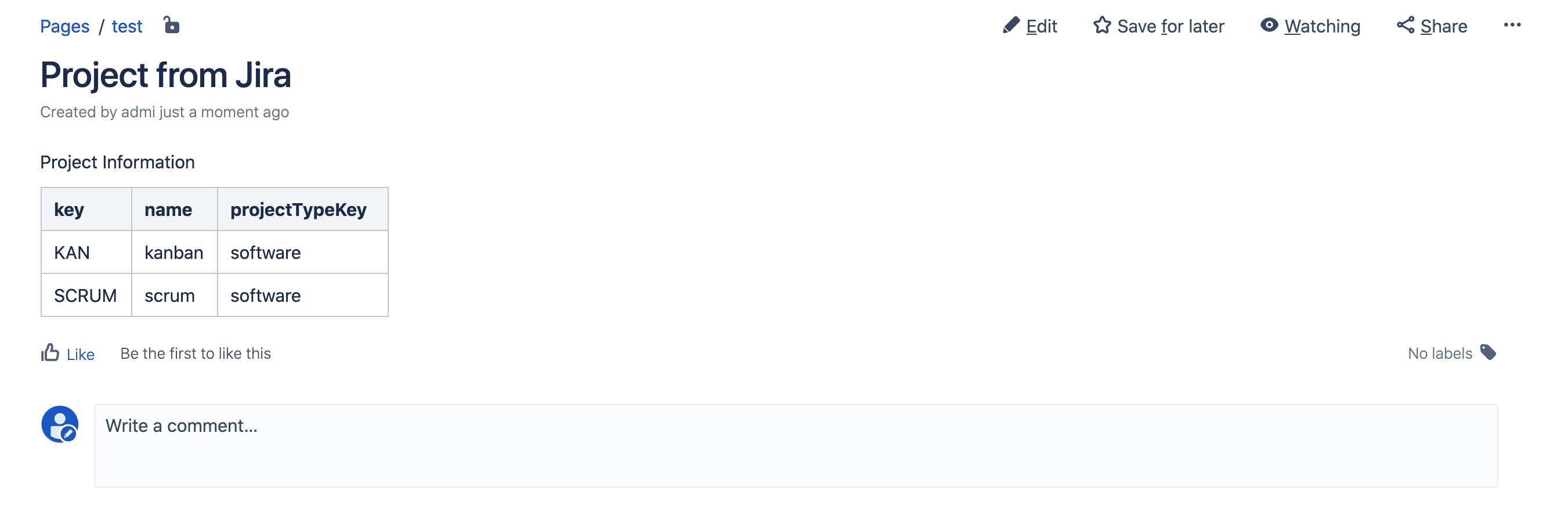
Compliquons la tâche
Ajoutez la fonctionnalité suivante au tableau:- afficher des informations sur le chef de projet
- donner aux champs des noms plus compréhensibles et de préférence en russe
Tout d'abord, apportez des modifications au script getProjects.sil.En même temps, nous refactorisons un peu.Voici ce que fera notre script:- obtenir des données de projet de Jira via un appel à l'API REST Jira
- nous convertissons les données du projet reçues en une vue tabulaire
- imprimer le résultat
Voici à quoi cela ressemble dans le code:Project [] projects = getProjectData();
TableRow [] tableRows = convertProjectDataToTableData(projects);
return tableRows;
Précisons maintenant comment nous obtenons les données du projet:- créer une demande
- créer un en-tête dans la demande avec des informations sur l'utilisateur qui reçoit des données de Jira
- Ajoutez le paramètre expand à notre requête. Nous devons sélectionner des données sur le chef de projet, mais dans la réponse par défaut, il n'y a pas de telles données. Par conséquent, nous devons dire à Jira que nous voulons voir les données sur le chef de projet dans la réponse. Pour cela, le paramètre expand est utilisé.
- nous satisfaisons la demande
- renvoyer des données
Mais les mots se sont transformés en code:function getProjectData() {
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
HttpQueryParam param = httpCreateParameter("expand", "description,lead,url,projectKeys");
request.parameters += param;
Project[] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
return projects;
}
Définissons maintenant les structures de données pour nos projets.Voici la réponse que la méthode du projet renvoie de l'API Jira REST (j'ai supprimé les données inutiles pour rendre la réponse plus courte et donc plus lisible):[
{
"key":"KAN",
"lead":{
"name":"admin",
"displayName":"Alexey Matveev",
},
"name":"kanban",
"projectTypeKey":"software"
},
{
"key":"SCRUM",
"description":"",
"lead":{
"name":"admin",
"displayName":"Alexey Matveev",
},
"name":"scrum",
"projectTypeKey":"software"
}
]
Comme nous pouvons le voir, les valeurs des champs key, name et projectTypeKey sont définies au premier niveau de notre json. Mais pour le champ principal, au lieu de la valeur, nous voyons json. Et ce json contient déjà les valeurs des champs name et displayName. Par conséquent, nous créons d'abord une structure pour json dans le champ lead (Lead):struct Lead {
string name;
string displayName;
}
Nous sommes maintenant prêts à créer la structure pour le premier niveau de notre json (Projet):struct Project {
string key;
string name;
string projectTypeKey;
Lead lead;
}
Mais le problème est que la macro de table SIL ne peut fonctionner qu'avec json avec un niveau d'imbrication, nous devons donc convertir notre structure avec deux niveaux d'imbrication (Project) en une structure avec un niveau d'imbrication (structure plate). Mais d'abord, créez une structure plate (TableRow):struct TableRow {
string key;
string name;
string projectTypeKey;
string lead;
string leadDisplayName;
}
Et maintenant, nous allons écrire une fonction pour convertir les données de la structure Project en structure TableRow:function convertProjectDataToTableData(Project [] projectData) {
TableRow [] tableRows;
for (Project project in projectData) {
TableRow tableRow;
tableRow.key = project.key;
tableRow.name = project.name;
tableRow.projectTypeKey = project.projectTypeKey;
tableRow.lead = project.lead.name;
tableRow.leadDisplayName = project.lead.displayName;
tableRows = arrayAddElement(tableRows, tableRow);
}
return tableRows;
}
Tout. Le script est prêt!Voici le code final getProjects.sil:struct Lead {
string name;
string displayName;
}
struct Project {
string key;
string name;
string projectTypeKey;
Lead lead;
}
struct TableRow {
string key;
string name;
string projectTypeKey;
string lead;
string leadDisplayName;
}
function getProjectData() {
HttpRequest request;
HttpHeader authHeader = httpBasicAuthHeader("admin", "admin");
request.headers += authHeader;
HttpQueryParam param = httpCreateParameter("expand", "description,lead,url,projectKeys");
request.parameters += param;
string pp = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
runnerLog(pp);
Project[] projects = httpGet("http://host.docker.internal:8080/rest/api/2/project", request);
return projects;
}
function convertProjectDataToTableData(Project [] projectData) {
TableRow [] tableRows;
for (Project project in projectData) {
TableRow tableRow;
tableRow.key = project.key;
tableRow.name = project.name;
tableRow.projectTypeKey = project.projectTypeKey;
tableRow.lead = project.lead.name;
tableRow.leadDisplayName = project.lead.displayName;
tableRows = arrayAddElement(tableRows, tableRow);
}
return tableRows;
}Project [] projects = getProjectData();
TableRow [] tableRows = convertProjectDataToTableData(projects);
return tableRows;
Maintenant, nous actualisons la page dans Confluence et voyons que nos données sur le chef de projet sont remontées: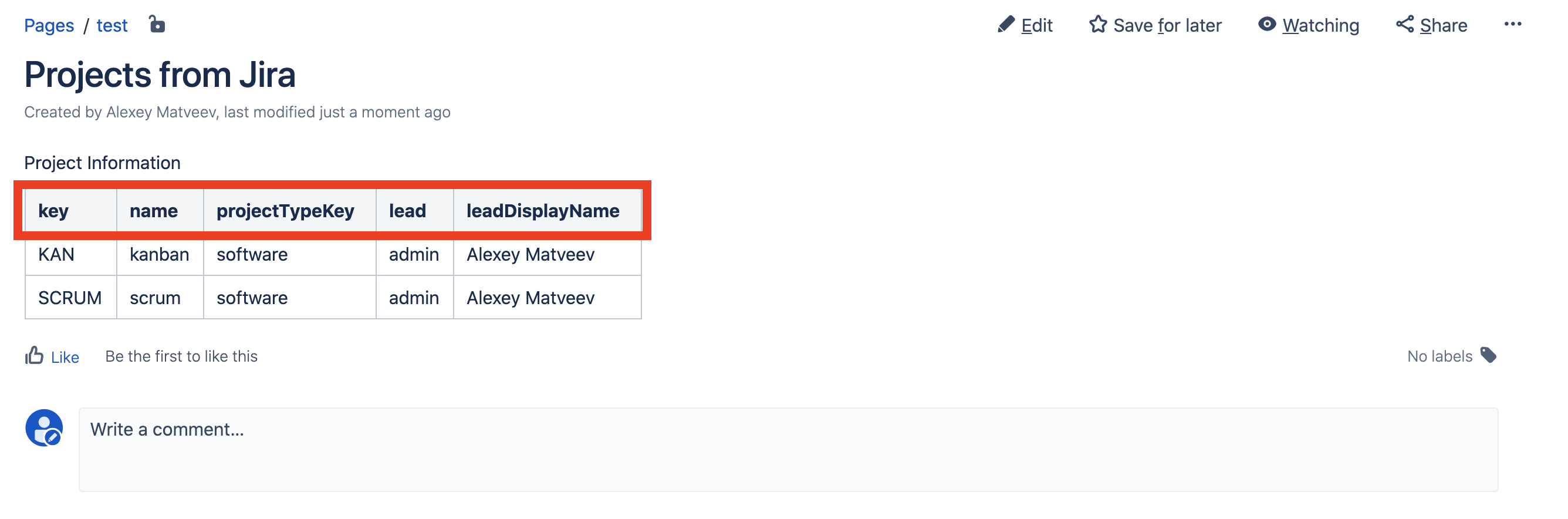 Mais les noms des colonnes sont un peu obscurs. Donnons de plus beaux noms.Nous éditons la page, éditons la macro de table SIL et saisissons «Clé du projet, nom du projet, type de projet, chef de projet, nom du chef de projet» dans le champ des colonnes:
Mais les noms des colonnes sont un peu obscurs. Donnons de plus beaux noms.Nous éditons la page, éditons la macro de table SIL et saisissons «Clé du projet, nom du projet, type de projet, chef de projet, nom du chef de projet» dans le champ des colonnes: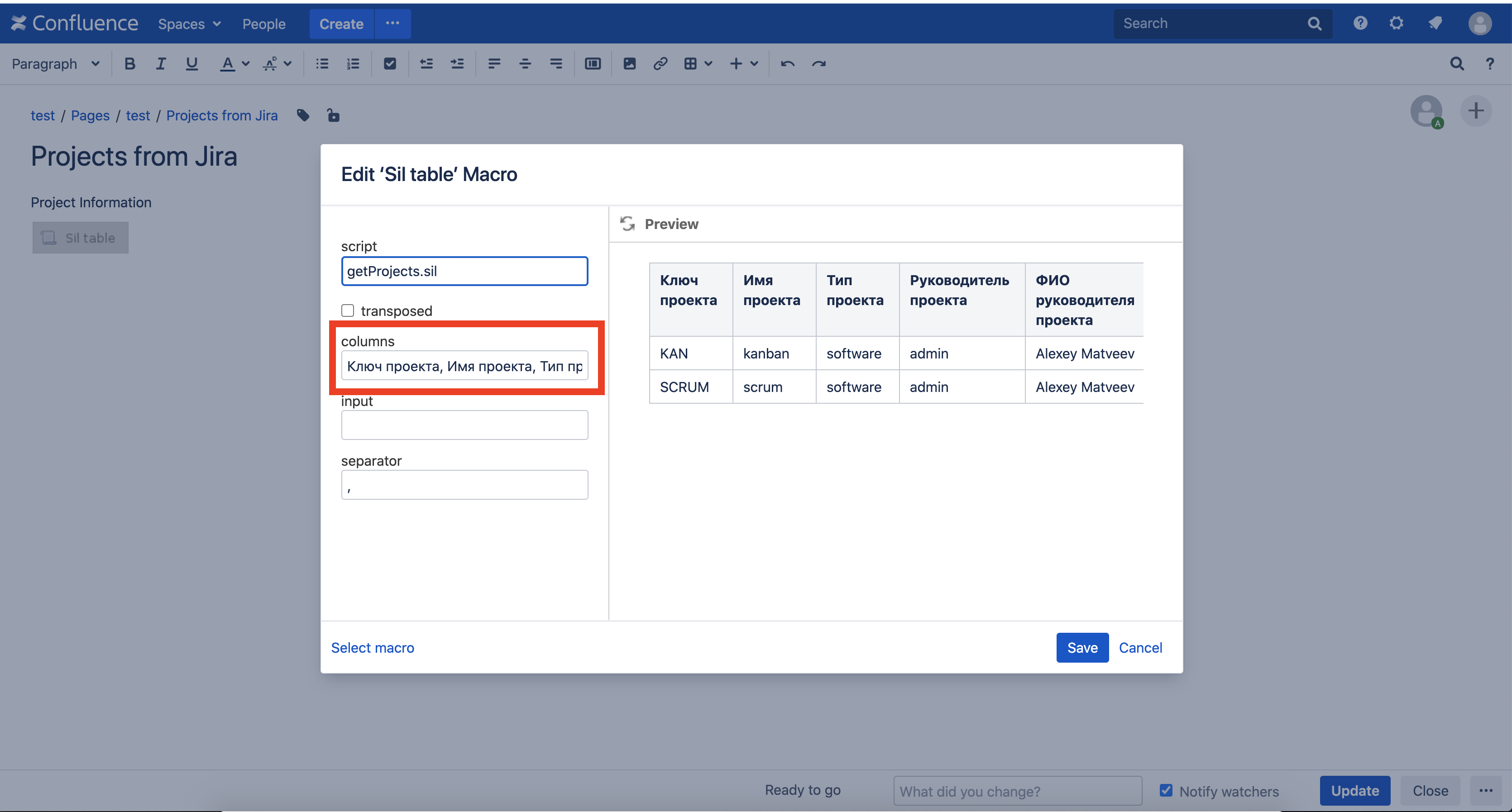 Enregistrez la page et voici le résultat:
Enregistrez la page et voici le résultat: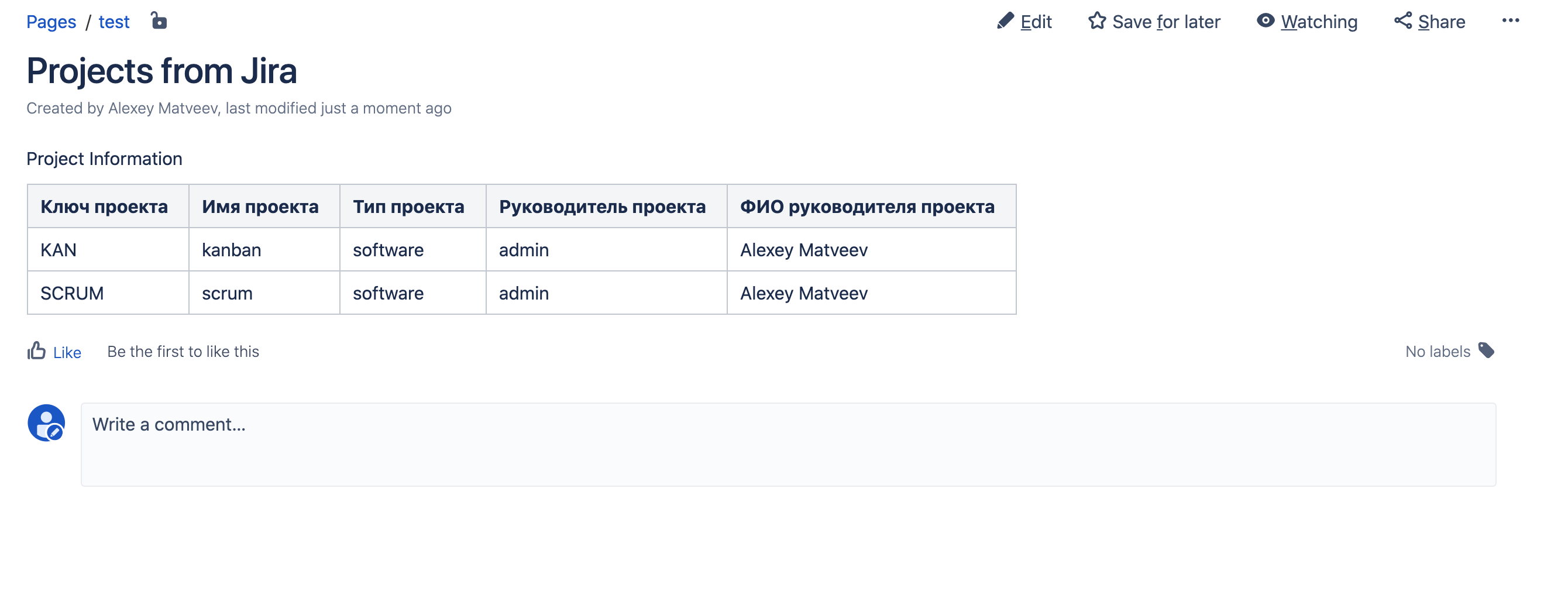 tout s'est avéré!
tout s'est avéré!