 Quiconque rencontre l'apprentissage automatique comprend que cela nécessite une puissance de calcul importante. Dans cet article, nous allons essayer d'appliquer l'algorithme développé au MIT pour compresser un réseau de neurones, ce qui réduira la dimension des poids du modèle entraîné et conduira à la fois à un apprentissage plus rapide et à un lancement plus rapide du modèle.Les réseaux de neurones se sont révélés être un excellent outil pour résoudre une grande variété de tâches, mais, malheureusement, leur utilisation nécessite une puissance de calcul importante, qui n'est peut-être pas encore dans une petite entreprise. Il existe de nombreux types de compression des réseaux de neurones qui peuvent être divisés en matériel, bas niveau et mathématiques, mais cet article discutera de la méthode développée au MIT en 2019 et travaillant directement avec le réseau de neurones lui-même.Cette méthode est appelée «l'hypothèse du ticket gagnant». En termes généraux, cela ressemble à ceci: Tout réseau de neurones entièrement connecté avec des poids initialisés de manière aléatoire contient un sous-réseau avec les mêmes poids, et un tel sous-réseau formé séparément peut être égal en précision au réseau d'origine.Une preuve formelle et un article complet peuvent être trouvés ici . Nous sommes intéressés par la possibilité d'application pratique. En bref, l'algorithme est le suivant:
Quiconque rencontre l'apprentissage automatique comprend que cela nécessite une puissance de calcul importante. Dans cet article, nous allons essayer d'appliquer l'algorithme développé au MIT pour compresser un réseau de neurones, ce qui réduira la dimension des poids du modèle entraîné et conduira à la fois à un apprentissage plus rapide et à un lancement plus rapide du modèle.Les réseaux de neurones se sont révélés être un excellent outil pour résoudre une grande variété de tâches, mais, malheureusement, leur utilisation nécessite une puissance de calcul importante, qui n'est peut-être pas encore dans une petite entreprise. Il existe de nombreux types de compression des réseaux de neurones qui peuvent être divisés en matériel, bas niveau et mathématiques, mais cet article discutera de la méthode développée au MIT en 2019 et travaillant directement avec le réseau de neurones lui-même.Cette méthode est appelée «l'hypothèse du ticket gagnant». En termes généraux, cela ressemble à ceci: Tout réseau de neurones entièrement connecté avec des poids initialisés de manière aléatoire contient un sous-réseau avec les mêmes poids, et un tel sous-réseau formé séparément peut être égal en précision au réseau d'origine.Une preuve formelle et un article complet peuvent être trouvés ici . Nous sommes intéressés par la possibilité d'application pratique. En bref, l'algorithme est le suivant:- Nous créons un modèle, initialisons au hasard ses paramètres
- Apprentissage d'un réseau d'itérations j
- Nous supprimons les paramètres réseau qui ont la plus petite valeur (la tâche la plus simple consiste à définir une valeur de seuil)
- Nous remettons les paramètres restants à leurs valeurs initiales, nous obtenons le sous-réseau dont nous avons besoin.
En théorie, cet algorithme doit être répété le nième nombre d'étapes, mais pour un exemple nous n'effectuerons qu'une seule itération. Créez un réseau simple entièrement connecté à l'aide de tensorflow et Keras:import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(300, activation='relu'),
keras.layers.Dense(150, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='SGD',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
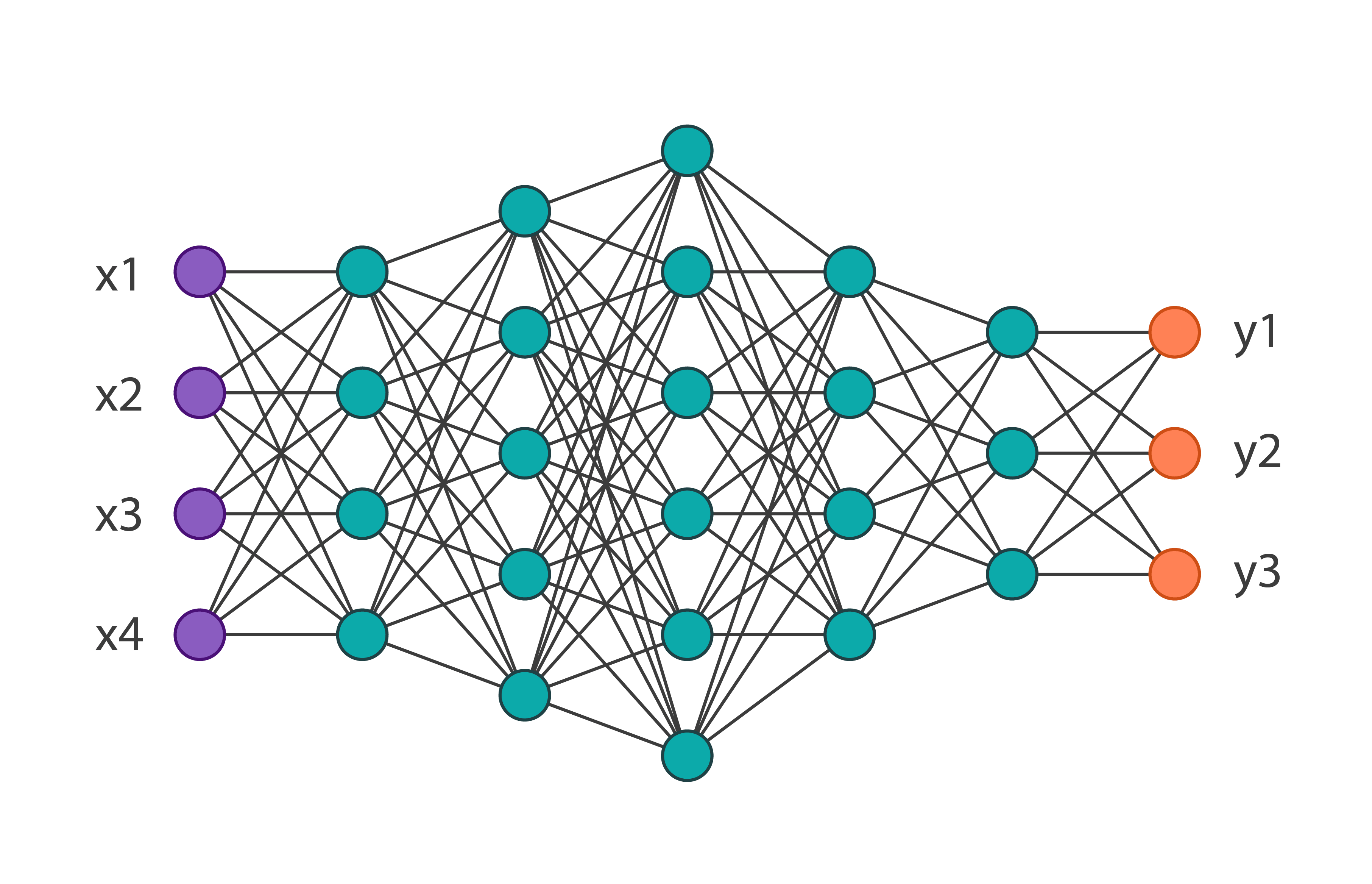
Nous obtiendrons l'architecture de réseau suivante: Et nous la formerons sur l'ensemble de données de la mode MNIST de 60 000 images. Sa précision sur les données de vérification sera égale à 0,8594. Nous appliquons aux paramètres d'itération du réseau 1 de cet algorithme. En code, cela ressemble à ceci:
Et nous la formerons sur l'ensemble de données de la mode MNIST de 60 000 images. Sa précision sur les données de vérification sera égale à 0,8594. Nous appliquons aux paramètres d'itération du réseau 1 de cet algorithme. En code, cela ressemble à ceci:
threshold = 0.001
weights = model.weights
weights = np.asarray(weights)
first_h_layer_weights = weights[1]
second_h_layer_weights = weights[3]
def delete_from_layers(one_d_array, threshold):
index = []
for i in range(one_d_array.shape[0]):
if abs(one_d_array[i]) <= threshold:
index.append(i)
new_layer = np.delete(one_d_array, index)
return new_layer
new_layer_weights = delete_from_layers(second_h_layer_weights, threshold)
Ainsi, après avoir exécuté ce code, nous nous débarrasserons des poids pratiquement inutilisés. Deux choses méritent d'être notées: dans cet exemple, le seuil a été choisi empiriquement et cet algorithme ne peut pas être appliqué aux poids des couches d'entrée et de sortie.Après avoir reçu de nouveaux poids, il est nécessaire de redéfinir le modèle d'origine, en supprimant l'excédent. En conséquence, nous obtenons: Vous pouvez remarquer que le nombre total de paramètres a diminué de près de 2 fois, ce qui signifie que lors de la formation du premier réseau, plus de la moitié des paramètres étaient tout simplement inutiles. Dans le même temps, la précision du sous-réseau est de 0,8555, ce qui est un peu inférieur à celui du réseau principal. Bien sûr, cet exemple est indicatif, généralement le réseau peut être réduit de 10 à 20% du nombre initial de paramètres. Ici, même sans appliquer cet algorithme, il est clair que l'architecture d'origine a été choisie trop lourde.En conclusion, nous pouvons dire que cette technique n'est pas bien développée pour le moment, et dans les tâches réelles, une tentative d'optimiser les poids du modèle de cette manière ne peut que rallonger le processus d'apprentissage, mais l'algorithme lui-même a beaucoup de potentiel.
Vous pouvez remarquer que le nombre total de paramètres a diminué de près de 2 fois, ce qui signifie que lors de la formation du premier réseau, plus de la moitié des paramètres étaient tout simplement inutiles. Dans le même temps, la précision du sous-réseau est de 0,8555, ce qui est un peu inférieur à celui du réseau principal. Bien sûr, cet exemple est indicatif, généralement le réseau peut être réduit de 10 à 20% du nombre initial de paramètres. Ici, même sans appliquer cet algorithme, il est clair que l'architecture d'origine a été choisie trop lourde.En conclusion, nous pouvons dire que cette technique n'est pas bien développée pour le moment, et dans les tâches réelles, une tentative d'optimiser les poids du modèle de cette manière ne peut que rallonger le processus d'apprentissage, mais l'algorithme lui-même a beaucoup de potentiel.