Rebonjour. Aujourd'hui, nous poursuivons la série de traductions en prévision du début du cours de base «Mathématiques pour la science des données» .
Dans un article récent , nous avons expliqué comment créer un détecteur d'anomalies dans Power BI en y intégrant PyCaret et aider les analystes et les analystes de données à ajouter l'apprentissage automatique aux rapports et aux tableaux de bord sans trop d'effort.Dans cet article, nous verrons comment effectuer une analyse de cluster à l'aide de PyCaret et Power BI. Si vous n'avez jamais entendu parler de PyCaret auparavant, vous pouvez commencer à en prendre connaissance ici .Ce que nous allons discuter dans le guide d'aujourd'hui:- Qu'est-ce que le clustering? Types de clustering.
- Apprendre sans professeur et implémenter un modèle de clustering dans Power BI.
- Analyse des résultats et visualisation des informations sur le tableau de bord.
- Comment déployer un modèle de clustering en production dans Power BI?
Avant que nous commencions ...
Si vous avez déjà utilisé Python auparavant, vous avez probablement déjà Anaconda sur votre ordinateur. Sinon, vous pouvez télécharger la distribution Anaconda à partir de Python 3.7 ou supérieur à partir d'ici .Configuration de l'environnement
Avant de commencer à utiliser les fonctionnalités d'apprentissage automatique PyCaret dans Power BI, vous devez créer un environnement virtuel et l'installer dans celui-ci pycaret. Pour ce faire, nous devons effectuer trois étapes:Étape 1 - Créer un environnement virtuelOuvrez l'invite de commande Anaconda et entrez ce qui suit:conda create --name myenv python=3.7
Étape 2 - Installer PyCaretExécutez la commande suivante à l'invite de commande Anaconda:pip install pycaret
L'installation peut prendre de 15 à 20 minutes. Si vous rencontrez des problèmes lors de l'installation, vous pouvez vous familiariser avec leur solution sur notre page sur GitHub .Étape 3 - Indiquez dans Power BI où Python est installé.L'environnement virtuel créé doit être associé à Power BI. Vous pouvez le faire en utilisant les paramètres globaux dans Power BI Desktop (Fichier -> Options -> Global -> Scripting Python). L'environnement Anaconda est placé dans le répertoire par défaut:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
Qu'est-ce que le clustering?
Le clustering est une méthode de division des données en groupes selon des caractéristiques similaires. Ces groupes peuvent être utiles pour étudier des données, identifier des modèles et analyser des sous-ensembles de données. Le regroupement des données permet d'identifier les structures de données sous-jacentes, ce qui est utile dans de nombreux secteurs. Voici quelques utilisations courantes du clustering en entreprise:- Segmentation de la clientèle marketing.
- Analyse du comportement des consommateurs pour les promotions et remises.
- Identification des géoclusters lors d'une épidémie, comme par exemple COVID-19.
Types de clustering
Étant donné la nature subjective des tâches de clustering, il existe différents algorithmes qui conviennent mieux pour résoudre certains types de tâches. Chaque algorithme a ses propres caractéristiques et justification mathématique, qui sous-tendent la distribution des grappes.Dans le didacticiel d'aujourd'hui, nous parlons de l'analyse de cluster dans Power BI à l'aide d'une bibliothèque Python appelée PyCaret et nous n'entrerons pas dans les mathématiques. Aujourd'hui, nous utiliserons la méthode k-means - l'une des méthodes d'enseignement les plus simples et les plus populaires sans professeur. Vous pouvez trouver plus d'informations sur la méthode k-means ici .
Aujourd'hui, nous utiliserons la méthode k-means - l'une des méthodes d'enseignement les plus simples et les plus populaires sans professeur. Vous pouvez trouver plus d'informations sur la méthode k-means ici .Contexte d'affaires
Dans ce guide, nous utiliserons un ensemble de données prédéfini provenant de la base de données Global Health Expenditure de l'Organisation mondiale de la santé. Il contient les dépenses de santé en pourcentage du PIB national pour plus de 200 pays de 2000 à 2017.Notre tâche consiste à trouver des modèles et des groupes dans ces données en utilisant la méthode k-means.Les données peuvent être trouvées ici .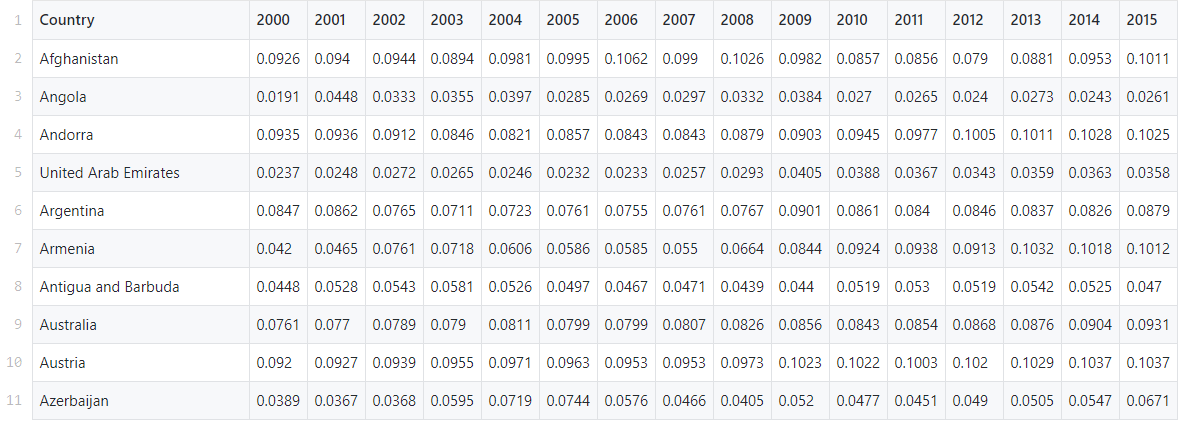
Alors commençons
Maintenant que vous avez configuré l'environnement Anaconda, installé PyCaret, vous comprenez les bases de l'analyse de cluster et le contexte commercial, il est temps de passer aux choses sérieuses.1. Acquisition de données
La première étape consiste à importer l'ensemble de données dans Power BI Desktop. Vous pouvez télécharger des données à l'aide du connecteur Web. (Power BI Desktop → Get Data → From Web ). Lien vers le fichier csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .
Lien vers le fichier csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .2. Formation modèle
Pour apprendre le modèle de clustering dans Power BI, nous devons exécuter un script Python dans l'éditeur de requête Power ( éditeur de requête Power → Transformer → Exécuter le script Python ). Utilisez le code suivant comme script:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 Nous avons ignoré la colonne «Pays» de l' ensemble en utilisant le paramètre
Nous avons ignoré la colonne «Pays» de l' ensemble en utilisant le paramètre ignore_features. Il existe de nombreuses raisons pour lesquelles vous devrez peut-être exclure certaines colonnes afin de mieux former le modèle d'apprentissage automatique.PyCaret vous permet de masquer les colonnes inutiles au lieu de les supprimer, car vous pourriez en avoir besoin à l'avenir pour une analyse plus approfondie. Par exemple, pour le moment, nous ne voulions pas utiliser «Pays» pour la formation et avons transmis cette colonne à ignore_features.PyCaret propose 8 algorithmes d'apprentissage automatique prêts à l'emploi.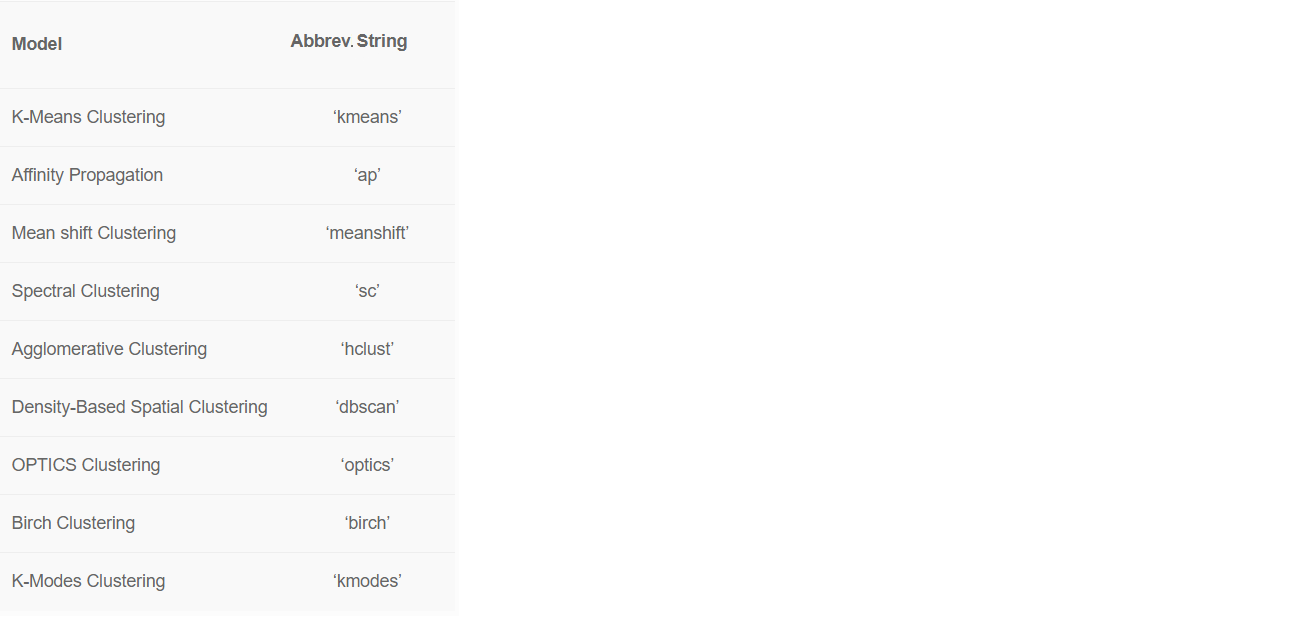 Par défaut, PyCaret forme le modèle de clustering k-means sur quatre clusters. Mais les valeurs par défaut peuvent être facilement modifiées:
Par défaut, PyCaret forme le modèle de clustering k-means sur quatre clusters. Mais les valeurs par défaut peuvent être facilement modifiées:- Pour modifier le type de modèle, utilisez le paramètre de modèle dans
get_clusters(). - Pour modifier le nombre de clusters, utilisez l'option
num_clusters.
Par exemple, voici comment vous pouvez regrouper k-means en 6 clusters.from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
Conclusion: une
 autre colonne avec une étiquette de cluster est ajoutée à l'ensemble de données d'origine. Ensuite, toutes les valeurs de la colonne année sont utilisées pour normaliser les données et visualiser davantage dans Power BI.Voici à quoi ressemblera le résultat final dans Power BI.
autre colonne avec une étiquette de cluster est ajoutée à l'ensemble de données d'origine. Ensuite, toutes les valeurs de la colonne année sont utilisées pour normaliser les données et visualiser davantage dans Power BI.Voici à quoi ressemblera le résultat final dans Power BI.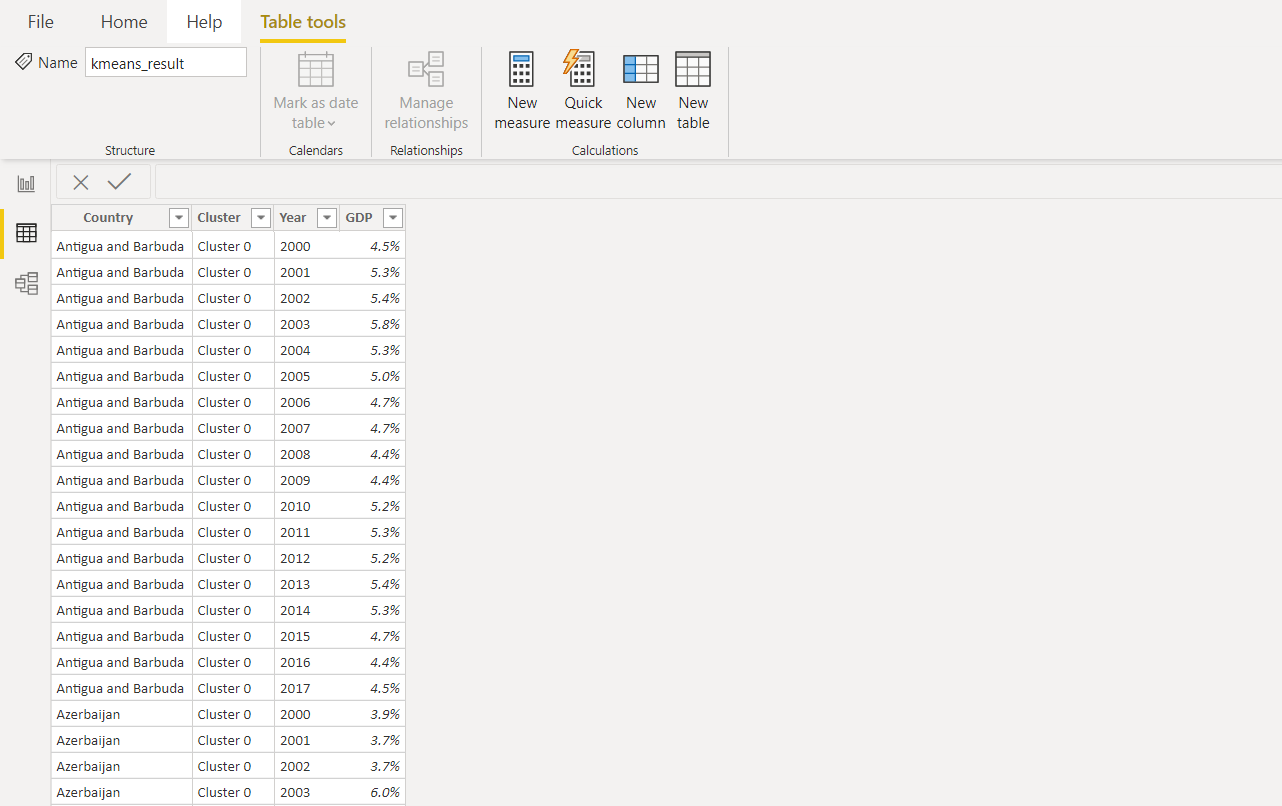
3. Tableau de bord
Lorsque vous avez des étiquettes de cluster dans Power BI, vous pouvez les visualiser dans le tableau de bord dans Power BI pour l'analyse: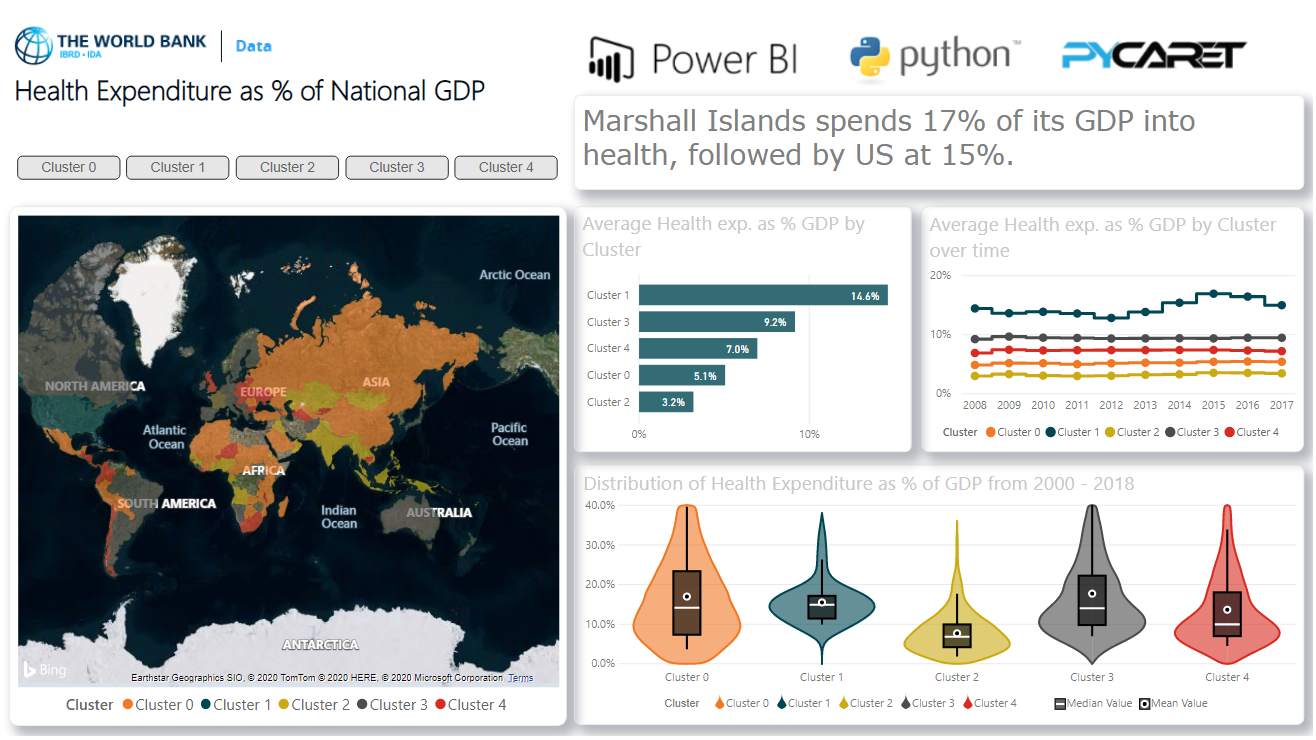
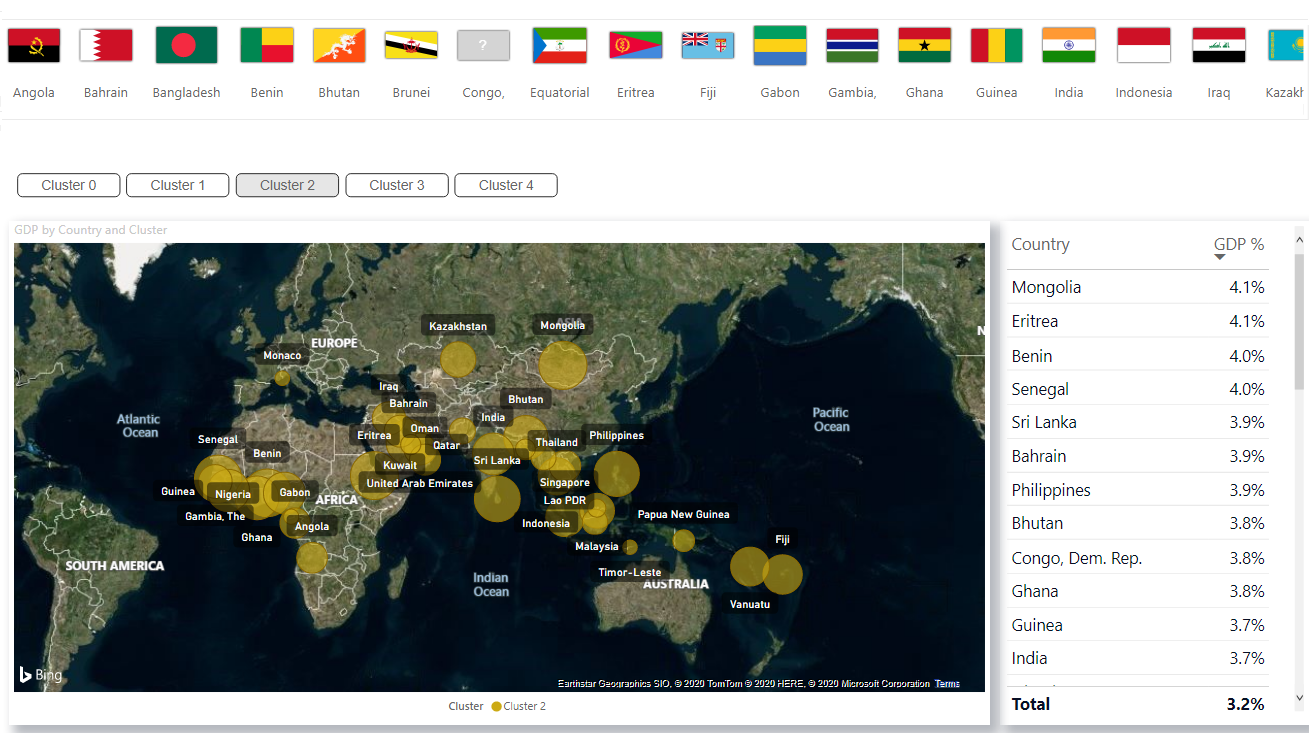 vous pouvez télécharger le fichier PBIX et l'ensemble de données à partir de GitHub .
vous pouvez télécharger le fichier PBIX et l'ensemble de données à partir de GitHub .Mise en œuvre du clustering
Ci-dessus, nous avons démontré l'implémentation de clustering la plus simple dans Power BI. Je note que cette méthode entraîne le modèle de clustering chaque fois qu'un ensemble de données est mis à jour dans Power BI. Cela peut être un problème pour les raisons suivantes:- Lorsque le modèle est formé à nouveau sur les nouvelles données, les étiquettes de cluster peuvent changer (c'est-à-dire que si auparavant certains points de données ont été attribués au premier cluster, puis une nouvelle formation, ils peuvent être affectés au deuxième cluster);
- Vous ne voudrez pas passer plusieurs heures à chaque fois la formation du modèle.
Un moyen plus efficace d'implémenter le clustering dans Power BI au lieu de réapprendre encore et encore est d'utiliser un modèle pré-formé pour créer des étiquettes de cluster.Formation des premiers modèles
Vous pouvez utiliser n'importe quel environnement de développement intégré (IDE) ou ordinateur portable pour entraîner le modèle. Dans cet exemple, nous avons formé le modèle de clustering dans Visual Studio Code.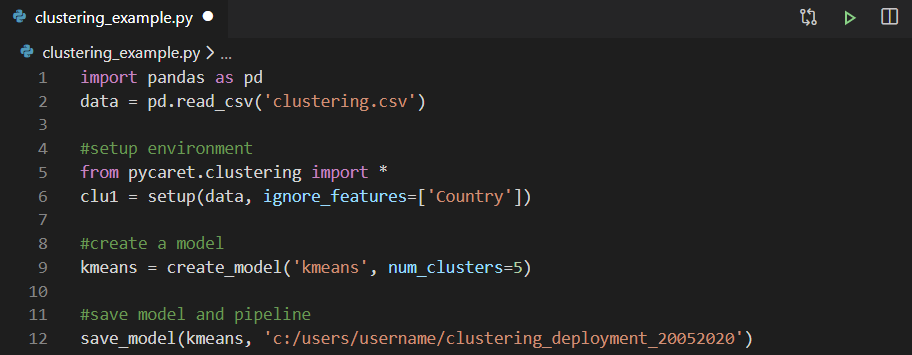 Ensuite, le modèle formé est enregistré en tant que fichier de pickle et importé dans Power Query pour générer des étiquettes de cluster.
Ensuite, le modèle formé est enregistré en tant que fichier de pickle et importé dans Power Query pour générer des étiquettes de cluster. Si vous souhaitez en savoir plus sur la mise en œuvre de l'analyse de cluster dans le bloc-notes Jupyter avec PyCaret, regardez cette vidéo de deux minutes.
Si vous souhaitez en savoir plus sur la mise en œuvre de l'analyse de cluster dans le bloc-notes Jupyter avec PyCaret, regardez cette vidéo de deux minutes.Utilisation du modèle pré-formé
Exécutez le code ci-dessous pour générer des balises à partir du modèle pré-formé:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
Le résultat sera le même que celui que nous avons observé précédemment. La seule différence est que lors de l'utilisation du modèle pré-formé, les balises seront générées sur la base du nouvel ensemble de données utilisant l'ancien modèle, et non sur le modèle qui a été recyclé.Travailler avec le service Power BI
Après avoir téléchargé le fichier .pbix sur le service Power BI, vous devrez suivre quelques étapes supplémentaires pour garantir une intégration en douceur du pipeline d'apprentissage automatique dans votre pipeline de données. Les étapes seront les suivantes:- Activez la mise à jour planifiée de l'ensemble de données - cela vous permettra de planifier la mise à jour du classeur avec votre ensemble de données à l'aide d'un script Python, consultez la section Configuration de l'actualisation planifiée , qui contient également des informations sur Personal Gateway.
- Installez Personal Gateway - vous aurez besoin d'une Personal Gateway, qui doit être installée dans le même répertoire où Python est installé. Le service Power BI doit avoir accès à l'environnement Python. Ici, vous pouvez en savoir plus sur l'installation et la configuration de Personal Gateway.
Si vous voulez en savoir plus sur l'analyse des clusters, vous pouvez vous familiariser avec notre guide dans ce cahier .
Prenez le cap.