Remarque perev. : Bien que cette revue ne prétend pas être le statut d'une comparaison technique soigneusement développée des solutions existantes pour le stockage permanent des données dans Kubernetes, elle peut être un bon point de départ pour les administrateurs qui sont concernés par ce problème. La plus grande attention a été accordée à la solution du Pirée, dont la familiarité profitera non seulement aux amateurs de Linstor, mais également à ceux qui n'ont pas entendu parler de ces projets. Il s'agit d'un aperçu non scientifique des solutions de stockage pour Kubernetes. Énoncé du problème: nécessite la possibilité de créer un volume persistant sur les disques du nœud, dont les données seront enregistrées en cas de dommage ou de redémarrage du nœud.La motivation de cette comparaison est la nécessité de migrer le parc de serveurs de l'entreprise de plusieurs serveurs bare metal dédiés vers le cluster Kubernetes.Mon entreprise est une startup brésilienne Escavador avec d'énormes besoins informatiques (principalement CPU) et un budget très limité. Nous développons des solutions PNL pour structurer les données légales.
Il s'agit d'un aperçu non scientifique des solutions de stockage pour Kubernetes. Énoncé du problème: nécessite la possibilité de créer un volume persistant sur les disques du nœud, dont les données seront enregistrées en cas de dommage ou de redémarrage du nœud.La motivation de cette comparaison est la nécessité de migrer le parc de serveurs de l'entreprise de plusieurs serveurs bare metal dédiés vers le cluster Kubernetes.Mon entreprise est une startup brésilienne Escavador avec d'énormes besoins informatiques (principalement CPU) et un budget très limité. Nous développons des solutions PNL pour structurer les données légales.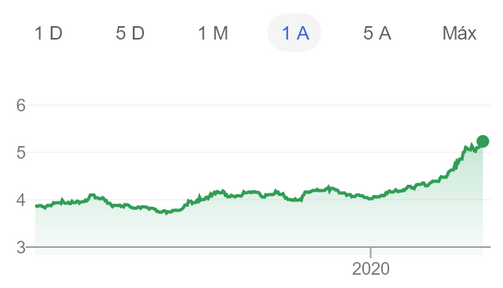 En raison de la crise avec COVID-19, le real brésilien est tombé à un niveau record face au dollar américainNotre monnaie nationale est en fait très sous-estimée, donc le salaire moyen d'un développeur senior n'est que de 2000 USD par mois. Ainsi, nous ne pouvons pas nous permettre le luxe de dépenser des sommes importantes en services cloud. Lors de mes derniers calculs, [grâce à l'utilisation de mes serveurs], nous avons économisé 75% par rapport à ce que je devrais payer pour AWS. En d'autres termes, un autre développeur peut être embauché pour l'argent économisé - je pense que c'est une utilisation beaucoup plus rationnelle des fonds.Inspiré par une série de publications de Vito Botta, j'ai décidé de créer un cluster K8s en utilisant Rancher (et jusqu'ici tout va bien ...). Vito a également effectué une excellente analyse de diverses solutions de stockage. Le vainqueur clair était Linstor (il l'a même distinguéligue spéciale ). Spoiler: Je suis d'accord avec lui.Pendant un certain temps, j'ai suivi le trafic autour de Kubernetes, mais je n'ai décidé que récemment d'y participer. Cela est principalement dû au fait que le fournisseur dispose d'une nouvelle gamme de processeurs Ryzen. Et puis j'ai été très surpris de voir que de nombreuses solutions sont encore en développement ou à l'état immature (notamment pour les clusters bare metal: virtualisation VM, MetalLB, etc.). Les coffres-forts sur le métal nu sont encore à leur stade de maturité, bien qu'ils soient représentés par une multitude de solutions commerciales et Open Source. J'ai décidé de comparer les principales solutions prometteuses et gratuites (tester simultanément un produit commercial afin de comprendre ce que je perds). Gamme de solutions de
En raison de la crise avec COVID-19, le real brésilien est tombé à un niveau record face au dollar américainNotre monnaie nationale est en fait très sous-estimée, donc le salaire moyen d'un développeur senior n'est que de 2000 USD par mois. Ainsi, nous ne pouvons pas nous permettre le luxe de dépenser des sommes importantes en services cloud. Lors de mes derniers calculs, [grâce à l'utilisation de mes serveurs], nous avons économisé 75% par rapport à ce que je devrais payer pour AWS. En d'autres termes, un autre développeur peut être embauché pour l'argent économisé - je pense que c'est une utilisation beaucoup plus rationnelle des fonds.Inspiré par une série de publications de Vito Botta, j'ai décidé de créer un cluster K8s en utilisant Rancher (et jusqu'ici tout va bien ...). Vito a également effectué une excellente analyse de diverses solutions de stockage. Le vainqueur clair était Linstor (il l'a même distinguéligue spéciale ). Spoiler: Je suis d'accord avec lui.Pendant un certain temps, j'ai suivi le trafic autour de Kubernetes, mais je n'ai décidé que récemment d'y participer. Cela est principalement dû au fait que le fournisseur dispose d'une nouvelle gamme de processeurs Ryzen. Et puis j'ai été très surpris de voir que de nombreuses solutions sont encore en développement ou à l'état immature (notamment pour les clusters bare metal: virtualisation VM, MetalLB, etc.). Les coffres-forts sur le métal nu sont encore à leur stade de maturité, bien qu'ils soient représentés par une multitude de solutions commerciales et Open Source. J'ai décidé de comparer les principales solutions prometteuses et gratuites (tester simultanément un produit commercial afin de comprendre ce que je perds). Gamme de solutions de stockage chez CNCF LandscapeMais tout d'abord, je veux vous avertir que je suis nouveau sur les K8.Pour les expériences, 4 travailleurs ont été utilisés avec la configuration suivante: processeur Ryzen 3700X, 64 Go de mémoire ECC, NVMe 2 To. Des repères ont été réalisés en utilisant l'image
stockage chez CNCF LandscapeMais tout d'abord, je veux vous avertir que je suis nouveau sur les K8.Pour les expériences, 4 travailleurs ont été utilisés avec la configuration suivante: processeur Ryzen 3700X, 64 Go de mémoire ECC, NVMe 2 To. Des repères ont été réalisés en utilisant l'image sotoaster/dbench:latest(sur fio) avec le drapeau O_DIRECT.Longhorn
J'ai vraiment aimé Longhorn. Il est entièrement intégré à Rancher et vous pouvez l'installer via Helm en un seul clic. Installation de Longhorn de RancherIl s'agit d'un outil open source avec le statut d'un projet sandbox de la Cloud Native Computing Foundation (CNCF). Son développement est financé par Rancher - une entreprise assez prospère avec un produit [éponyme] bien connu.
Installation de Longhorn de RancherIl s'agit d'un outil open source avec le statut d'un projet sandbox de la Cloud Native Computing Foundation (CNCF). Son développement est financé par Rancher - une entreprise assez prospère avec un produit [éponyme] bien connu. Une excellente interface graphique est également disponible - tout peut être fait à partir de celle-ci. Avec la performance, tout est en ordre. Le projet est toujours en version bêta, ce qui est confirmé par des problèmes sur GitHub.Lors des tests, j'ai lancé un benchmark utilisant 2 répliques et Longhorn 0.8.0:
Une excellente interface graphique est également disponible - tout peut être fait à partir de celle-ci. Avec la performance, tout est en ordre. Le projet est toujours en version bêta, ce qui est confirmé par des problèmes sur GitHub.Lors des tests, j'ai lancé un benchmark utilisant 2 répliques et Longhorn 0.8.0:- Lecture / écriture aléatoire, IOPS: 28,2 k / 16,2 k;
- Bande passante en lecture / écriture: 205 Mb / s / 108 Mb / s;
- Latence moyenne en lecture / écriture (usec): 593,27 / 644,27;
- Lecture / écriture séquentielle: 201 Mb / s / 108 Mb / s;
- Lecture / écriture aléatoire mixte, IOPS: 14,7k / 4904.
Openebs
Ce projet a également le statut de bac à sable CNCF. Avec un grand nombre d'étoiles sur GitHub, cela ressemble à une solution très prometteuse. Dans sa revue, Vito Botta s'est plaint de performances insuffisantes. Voici ce que le PDG de Mayadata lui a répondu :Les informations sont très obsolètes. OpenEBS en supportait 3 auparavant, mais maintenant il prend en charge 4 moteurs, si vous activez le provisionnement dynamique et l'orchestration localPV, qui peuvent s'exécuter à des vitesses NVMe. De plus, le moteur MayaStor est maintenant ouvert et reçoit déjà des critiques positives (bien qu'il ait le statut alpha).
Sur la page du projet OpenEBS, il y a une telle explication sur son statut:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
Il possède de nombreux moteurs, et le dernier semble assez prometteur en termes de performances: «MayaStor - moteur alpha avec NVMe sur Fabrics». Hélas, je ne l'ai pas testé à cause du statut de la version alpha.Lors des tests, la version 1.8.0 a été utilisée sur le moteur jiva. De plus, j'ai précédemment vérifié cStor, mais je n'ai pas enregistré les résultats, qui se sont toutefois révélés légèrement plus lents que jiva. Pour le benchmark, un graphique Helm a été installé avec tous les paramètres par défaut et la classe de stockage, créée de manière standard par Helm ( openebs-jiva-default), a été utilisée. La performance s'est avérée être la pire de toutes les solutions envisagées (je vous serais reconnaissant de me conseiller pour l'améliorer).OpenEBS 1.8.0 avec moteur jiva (3 répliques?):- Lecture / écriture aléatoire, IOPS: 2182/1527;
- Bande passante en lecture / écriture: 65,0 Mb / s / 41,9 Mb / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
Il s'agit d'une solution commerciale gratuite lorsque vous utilisez jusqu'à 110 Go d'espace. Une licence de développeur gratuite peut être obtenue en vous inscrivant via l'interface utilisateur du produit; Il offre jusqu'à 500 Go d'espace. Dans Rancher, il est répertorié comme partenaire, donc l'installation à l'aide de Helm a été facile et sans souci.L'utilisateur se voit offrir un panneau de contrôle de base. Les tests de ce produit ont été limités car il est commercial et ne nous convient pas en valeur. Mais je voulais quand même voir de quels projets commerciaux sont capables.Le test utilise la classe de stockage existante appelée «Fast» (modèle 0.2.19, 1 maître + 0 réplique?). Les résultats ont été incroyables. Ils ont largement dépassé les solutions précédentes.- Lecture / écriture aléatoire, IOPS: 117k / 90,4k;
- Bande passante en lecture / écriture: 2124 Mb / s / 457 Mb / s;
- Latence moyenne en lecture / écriture (usec): 63,44 / 86,52;
- Lecture / écriture séquentielle: 1907 Mb / s / 448 Mb / s;
- Lecture / écriture aléatoire mixte, IOPS: 81,9 k / 27,3 k.
Le Pirée (basé sur Linstor)
Licence: GPLv3Le Vito Botta déjà mentionné a finalement opté pour Linstor, ce qui était une raison supplémentaire d'essayer cette solution. À première vue, le projet semble plutôt étrange. Il n'y a presque pas d'étoiles sur GitHub, un nom inhabituel et il n'existe même pas sur CNCF Landscape. Mais en y regardant de plus près, tout n'est pas si effrayant, car:- DRBD est utilisé comme mécanisme de réplication de base (en fait, il a été développé par les mêmes personnes). Dans le même temps, DRBD 8.x fait partie du noyau Linux officiel depuis plus de 10 ans. Et nous parlons d'une technologie perfectionnée depuis plus de 20 ans.
- Les médias sont contrôlés par LINSTOR, également une technologie mature de la même société. La première version de Linstor-server est apparue sur GitHub en février 2018. Il est compatible avec diverses technologies / systèmes tels que Proxmox, OpenNebula et OpenStack.
- Apparemment, Linbit développe activement le projet, y introduisant constamment de nouvelles fonctionnalités et améliorations. La 10e version de DRBD a toujours le statut alpha , mais elle possède déjà des fonctionnalités uniques, telles que le codage d'effacement (analogue à la fonctionnalité de RAID5 / 6 - environ Transl.) .
- L'entreprise prend certaines mesures pour devenir l'un des projets de la CNCF.
D'accord, le projet semble suffisamment convaincant pour lui confier ses précieuses données. Mais est-il capable de rejouer des alternatives? Jetons un coup d'oeil.Installation
Vito parle d'installer Linstor ici . Cependant, dans les commentaires, l'un des développeurs de Linstor recommande un nouveau projet appelé Piraeus. Si je comprends bien, Le Pirée devient le projet Linbit Open Source, qui combine tout ce qui concerne les K8. L'équipe travaille sur l' opérateur approprié , mais pour l'instant, le Pirée peut être installé à l'aide de ce fichier YAML:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
Attention! Vous récupérez les configurations de mon référentiel personnel. Découvrez le référentiel officiel! J'ai mis à jour la version des images pour résoudre l'erreur qui se produit lors de l'utilisation dans Ubuntu.Le référentiel officiel du Pirée est disponible ici .Vous pouvez également utiliser le référentiel kvaps (il semble encore plus dynamique que le référentiel officiel du Pirée): https://github.com/kvaps/kube-linstor (profitez-en pour dire bonjour à Andreykvaps- environ. perev.) . Tous les nœuds fonctionnent après l'installation
Tous les nœuds fonctionnent après l'installationAdministration
L'administration est effectuée à l'aide de la ligne de commande. L'accès à celui-ci est possible à partir du shell de commande du nœud du contrôleur du Pirée. Le nœud du contrôleur exécute linstor-server. Il s'agit d'une couche d'abstraction sur drbd, capable de gérer l'ensemble du parc de nœuds. La capture d'écran ci-dessous montre quelques commandes utiles pour les tâches les plus populaires, par exemple:
Le nœud du contrôleur exécute linstor-server. Il s'agit d'une couche d'abstraction sur drbd, capable de gérer l'ensemble du parc de nœuds. La capture d'écran ci-dessous montre quelques commandes utiles pour les tâches les plus populaires, par exemple:linstor node list - afficher une liste des nœuds connectés et leur état;linstor volume list - afficher une liste des volumes créés et leur emplacement;linstor node info - montrer les capacités de chaque nœud.
 Commandes Linstor Uneliste complète des commandes est disponible dans la documentation officielle: Guide de l'utilisateur LINSTOR .En cas de situations telles que split brain, drbd est accessible directement via les nœuds.
Commandes Linstor Uneliste complète des commandes est disponible dans la documentation officielle: Guide de l'utilisateur LINSTOR .En cas de situations telles que split brain, drbd est accessible directement via les nœuds.reprise après sinistre
J'ai fait de mon mieux pour supprimer mon cluster, y compris une réinitialisation matérielle sur les nœuds. Mais Linstor était étonnamment tenace.Drbd reconnaît parfaitement un problème appelé split brain. Dans ma situation, le nœud secondaire est tombé hors de la réplication.Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
Les détails peuvent être trouvés dans la documentation officielle de drbd . Le nœud secondaire est tombé hors de la réplication.Dans mon cas, pour résoudre le problème, j'ai supprimé les données secondaires et commencé la synchronisation avec le nœud principal. Comme je préfère les interfaces graphiques, j'ai utilisé l'utilitaire drbdtop pour cela. Avec son aide, vous pouvez surveiller visuellement l'état et exécuter des commandes dans les nœuds.J'avais besoin d'aller dans la console sur le nœud problématique piraues (c'était
Le nœud secondaire est tombé hors de la réplication.Dans mon cas, pour résoudre le problème, j'ai supprimé les données secondaires et commencé la synchronisation avec le nœud principal. Comme je préfère les interfaces graphiques, j'ai utilisé l'utilitaire drbdtop pour cela. Avec son aide, vous pouvez surveiller visuellement l'état et exécuter des commandes dans les nœuds.J'avais besoin d'aller dans la console sur le nœud problématique piraues (c'était worker2-gpu): Aller sur le nœudLà j'ai installé drdbtop. Téléchargez cet utilitaire ici:
Aller sur le nœudLà j'ai installé drdbtop. Téléchargez cet utilitaire ici:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 Exécution de l'utilitaire drbdtopJetez un œil au panneau inférieur. Il y a des commandes qui peuvent être utilisées pour réparer le cerveau divisé:
Exécution de l'utilitaire drbdtopJetez un œil au panneau inférieur. Il y a des commandes qui peuvent être utilisées pour réparer le cerveau divisé: Après cela, les nœuds sont connectés et synchronisés automatiquement.
Après cela, les nœuds sont connectés et synchronisés automatiquement.Comment augmenter la vitesse?
Par défaut, Le Pirée / Linstor / drbd affiche d'excellentes performances (vous pouvez le voir ci-dessous). Les paramètres par défaut sont raisonnables et sûrs. Cependant, la vitesse d'écriture était plutôt faible. Étant donné que les serveurs dans mon cas sont dispersés dans différents centres de données (bien qu'ils soient physiquement relativement proches), j'ai décidé d'essayer de régler leurs performances.Le point de départ de l'optimisation est la définition d'un protocole de réplication. Par défaut, le protocole C est utilisé, qui attend la confirmation d'écriture sur le nœud secondaire distant. Voici une description des protocoles possibles:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
Pour cette raison, dans Linstor, j'utilise également le protocole asynchrone (il prend en charge la réplication synchrone / semi-synchrone / asynchrone). Vous pouvez l'activer avec la commande suivante:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
Le résultat de sa mise en œuvre sera l'activation du protocole asynchrone et une augmentation de la mémoire tampon jusqu'à 1 Mo. C'est relativement sûr. Ou vous pouvez utiliser la commande suivante (elle ignore les vidages de disque et augmente considérablement la mémoire tampon):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
Notez que si le nœud principal tombe en panne, une petite partie des données peut ne pas atteindre les répliques.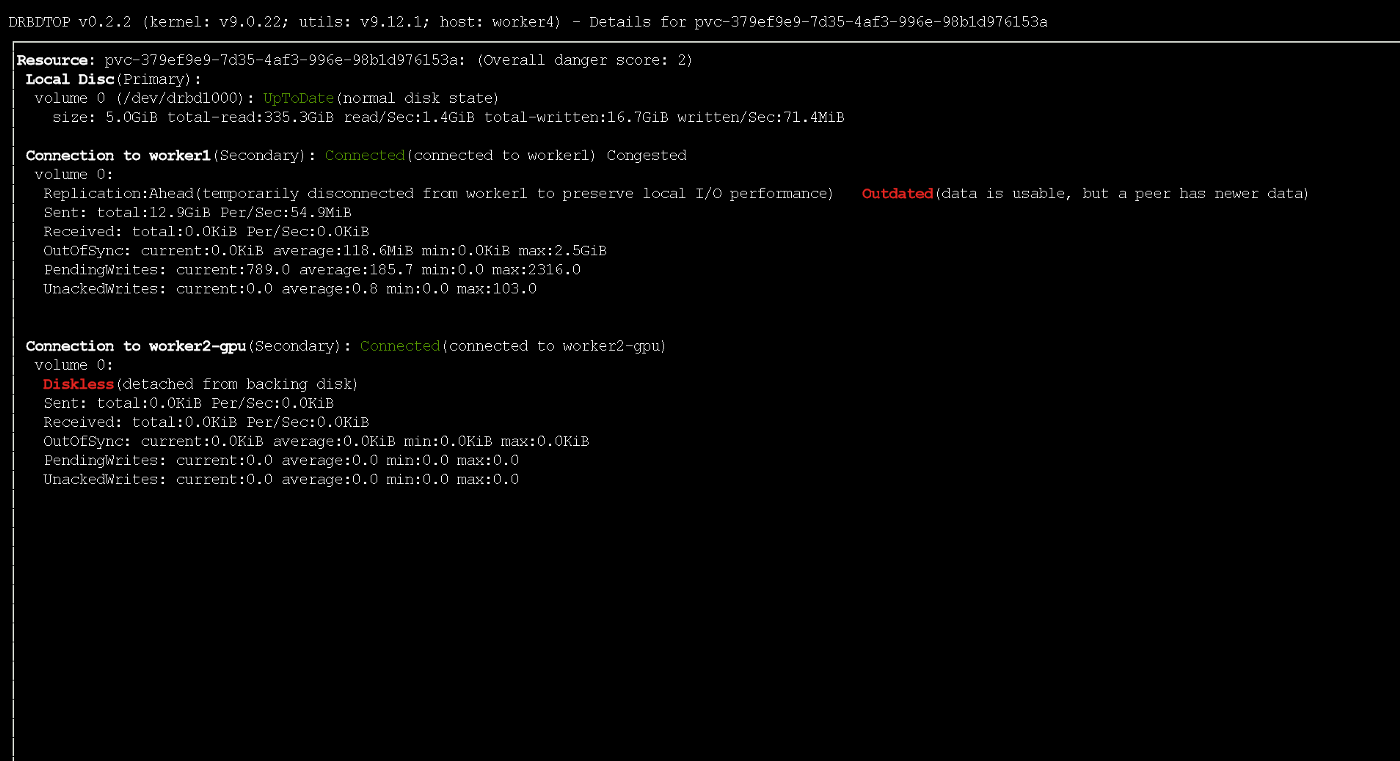 Pendant l'enregistrement actif, le nœud a reçu temporairement un état obsolète à l'aide du protocole ASYNC
Pendant l'enregistrement actif, le nœud a reçu temporairement un état obsolète à l'aide du protocole ASYNCEssai
Tous les repères ont été effectués en utilisant le poste suivant:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
Le délai entre les machines est la suivante: ttl=61 time=0.211 ms. Le débit mesuré entre eux était de 943 Mbps. Tous les nœuds exécutent Ubuntu 18.04. Résultats ( tableau sur sheetsu.com )
Comme le montre le tableau, Le Pirée et StorageOS ont montré les meilleurs résultats. Le leader était le Pirée avec deux répliques et un protocole asynchrone.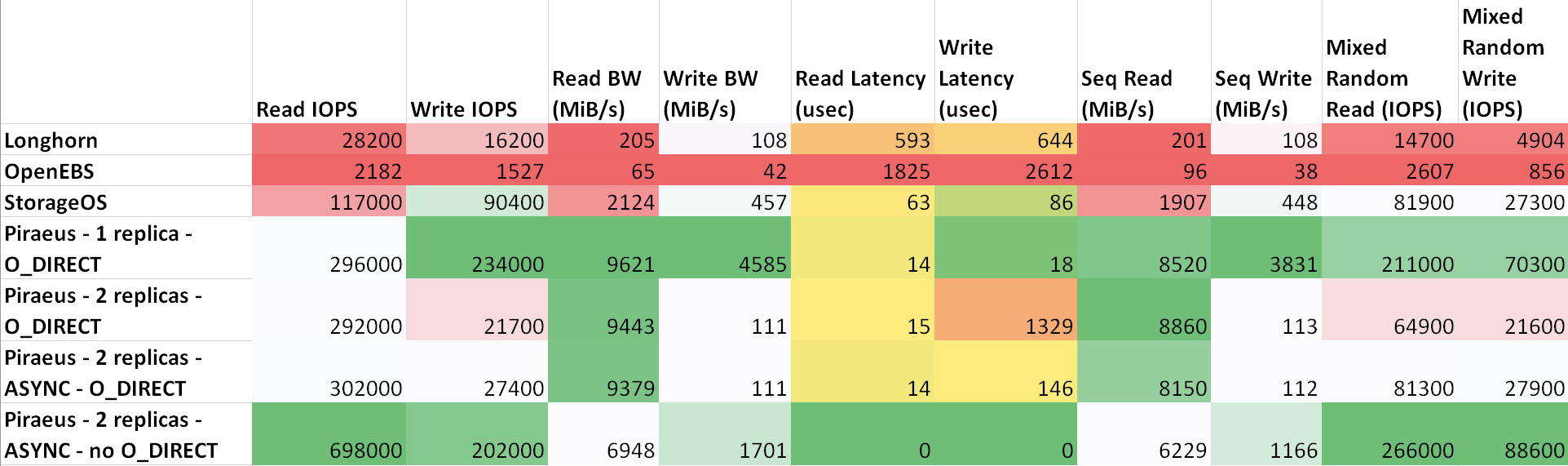
résultats
J'ai fait une comparaison simple et peut-être pas trop correcte de certaines solutions de stockage dans Kubernetes.J'ai surtout aimé Longhorn en raison de sa belle interface graphique et de son intégration avec Rancher. Cependant, les résultats ne sont pas inspirants. De toute évidence, les développeurs se concentrent principalement sur la sécurité et l'exactitude, laissant la vitesse pour plus tard.Depuis quelque temps, j'utilise Linstor / Piraeus dans les environnements de production de certains projets. Jusqu'à présent, tout allait bien: les disques ont été créés et supprimés, les nœuds ont été redémarrés sans temps d'arrêt ...À mon avis, le Pirée est tout à fait prêt à être utilisé en production, mais doit être amélioré. J'ai écrit sur quelques bugs dans le canal du projet dans Slack, mais en réponse, ils m'ont seulement conseillé d'enseigner Kubernetes (et c'est correct, car je ne le comprends toujours pas bien). Après une petite correspondance, j'ai quand même réussi à convaincre les auteurs qu'il y avait un bug dans leur script init. Hier, après avoir mis à jour le noyau et redémarré, le nœud a refusé de démarrer. Il s'est avéré que la compilation du script qui intègre le module drbd dans le noyau a échoué . La restauration de la version précédente du noyau a résolu le problème.En général, c'est tout. Étant donné qu'ils l'ont implémenté au-dessus de drbd, il s'est avéré être une solution très fiable avec d'excellentes performances. En cas de problème, vous pouvez directement contacter la direction de drbd et y remédier. Sur Internet, il existe de nombreuses questions et exemples sur ce sujet.Si j'ai fait quelque chose de mal, si quelque chose peut être amélioré ou si vous avez besoin d'aide, contactez-moi sur Twitter ou sur GitHub .PS du traducteur
Lisez aussi dans notre blog: