Dans un article précédent, où j'ai parlé de la surveillance d'une base de données PostgreSQL , il y avait une telle phrase:Agrandir wait- l'application s'est "reposée" sur les verrous de quelqu'un . S'il s'agit d'une anomalie unique passée - une occasion de comprendre la raison d'origine.
Cette situation est l'une des plus désagréables pour le DBA:- à première vue, la base fonctionne
- aucune ressource serveur n'est épuisée
- ... mais certaines demandes "ralentissent"
 Les chances d' attraper les verrous «dans l'instant» sont extrêmement faibles, et elles ne peuvent durer que quelques secondes, mais aggravent le temps d'exécution prévu de la demande des dizaines de fois. Mais vous ne voulez tout simplement pas vous asseoir et voir ce qui se passe en ligne, mais dans un environnement calme pour savoir après
Les chances d' attraper les verrous «dans l'instant» sont extrêmement faibles, et elles ne peuvent durer que quelques secondes, mais aggravent le temps d'exécution prévu de la demande des dizaines de fois. Mais vous ne voulez tout simplement pas vous asseoir et voir ce qui se passe en ligne, mais dans un environnement calme pour savoir après quel développeur punir quel était exactement le problème - qui, avec qui et à cause de quelle ressource de la base de données est entré en conflit.Mais comment? En effet, contrairement à la demande avec son plan, qui permet de comprendre en détail à quoi ont servi les ressources et combien de temps cela a pris, la serrure ne laisse pas de traces aussi évidentes ...Sauf une courte entrée de journal: Mais essayons de l'attraper!process ... still waiting for ...
Nous attrapons le verrou dans le journal
Mais même pour qu'au moins cette ligne apparaisse dans le journal, le serveur doit être correctement configuré:log_lock_waits = 'on'
... et définissez une frontière minimale pour notre analyse:deadlock_timeout = '100ms'
Lorsque le paramètre est activé log_lock_waits, ce paramètre détermine également après quelle heure les messages sur l'attente du blocage seront écrits dans le journal du serveur. Si vous essayez d'étudier les retards causés par les verrous, il est judicieux de le réduire par rapport à la valeur habituelle deadlock_timeout.
Tous les blocages qui n'ont pas le temps de se "délier" pendant cette période seront déchirés. Et voici les verrous «habituels» - déversés dans le journal par plusieurs entrées:2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest DETAIL: Process holding the lock: 38154. Wait queue: 38162.
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest CONTEXT: SQL statement "SELECT pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer )"
PL/pgSQL function inline_code_block line 2 at PERFORM
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest STATEMENT: DO $$ BEGIN
PERFORM pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer );
EXCEPTION
WHEN query_canceled THEN RETURN;
END; $$;
…
2019-03-27 00:06:46.077 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms
Cet exemple montre que nous n'avions que 50 ms entre le moment où le verrou est apparu dans le journal et le moment de sa résolution. Ce n'est que dans cet intervalle que nous pouvons obtenir au moins quelques informations à ce sujet, et plus nous sommes capables de le faire rapidement, plus nous pouvons analyser de verrous.Ici, les informations les plus importantes pour nous sont le PID du processus qui attend le verrou. C'est sur celui-ci que l'on peut comparer les informations entre le log et l'état de la base de données. Et en même temps pour découvrir à quel point une serrure particulière était problématique - c'est-à-dire combien de temps elle "pendait".Pour ce faire, nous n'avons besoin que de quelques RegExp sur l' LOGenregistrement de contenu :const RE_lock_detect = /^process (\d+) still waiting for (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
const RE_lock_acquire = /^process (\d+) acquired (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
Nous arrivons au journal
En fait, cela reste un peu - prendre le journal, apprendre à le surveiller et répondre en conséquence.Nous avons déjà tout pour cela - un analyseur de journaux en ligne et une connexion de base de données pré-activée, dont j'ai parlé dans un article sur notre système de surveillance PostgreSQL :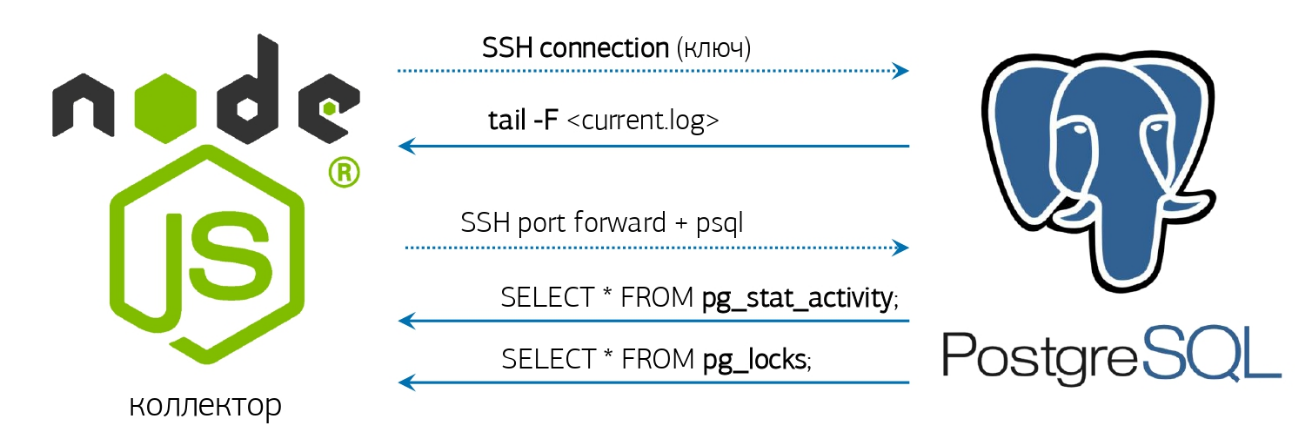 Mais si vous n'avez pas de système similaire déployé, alors ça va, nous ferons tout "Dès la console"!Si la version installée de PostgreSQL 10 et supérieur a de la chance, car il est apparu la fonction pg_current_logfile () , qui donne explicitement le nom du fichier journal actuel. Le récupérer depuis la console sera assez simple:
Mais si vous n'avez pas de système similaire déployé, alors ça va, nous ferons tout "Dès la console"!Si la version installée de PostgreSQL 10 et supérieur a de la chance, car il est apparu la fonction pg_current_logfile () , qui donne explicitement le nom du fichier journal actuel. Le récupérer depuis la console sera assez simple:psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) <> '/' THEN current_setting('data_directory') ELSE '' END || '/' || pg_current_logfile()"
Si la version est soudainement plus jeune - tout se passera, mais un peu plus compliqué:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}'
Nous tail -fobtenons le nom de fichier complet, que nous cédons et qui y apparaîtra 'still waiting for'.Eh bien, dès que quelque chose est apparu dans ce fil, nous appelons ...Demande d'analyse
Hélas, l'objet du blocage dans le journal n'est en aucun cas toujours la ressource à l'origine du conflit. Par exemple, si vous essayez de créer un index du même nom en parallèle, il n'y aura que quelque chose comme ça dans le journal still waiting for ExclusiveLock on transaction 12345.Par conséquent, nous devrons supprimer l'état de tous les verrous de la base de données pour le processus qui nous intéresse. Et l'information uniquement sur une paire de processus (qui a mis le verrou / qui l'attend) n'est pas suffisante, car il existe souvent une «chaîne» d'attentes de ressources différentes entre les transactions:tx1 [resA] -> tx2 [resA]
tx2 [resB] -> tx3 [resB]
...
Classique: "Grand-père pour navet, grand-mère pour grand-père, petite-fille pour grand-mère, ..."Par conséquent, nous écrirons une demande qui nous dira exactement qui est devenu la cause première des problèmes tout au long de la chaîne de serrures pour un PID spécifique:WITH RECURSIVE lm AS (
SELECT
rn
, CASE
WHEN lm <> 'Share' THEN row_number() OVER(PARTITION BY lm <> 'Share' ORDER BY rn)
END rx
, lm || 'Lock' lm
FROM (
SELECT
row_number() OVER() rn
, lm
FROM
unnest(
ARRAY[
'AccessShare'
, 'RowShare'
, 'RowExclusive'
, 'ShareUpdateExclusive'
, 'Share'
, 'ShareRowExclusive'
, 'Exclusive'
, 'AccessExclusive'
]
) T(lm)
) T
)
, lt AS (
SELECT
row_number() OVER() rn
, lt
FROM
unnest(
ARRAY[
'relation'
, 'extend'
, 'page'
, 'tuple'
, 'transactionid'
, 'virtualxid'
, 'object'
, 'userlock'
, 'advisory'
, ''
]
) T(lt)
)
, lmx AS (
SELECT
lr.rn lrn
, lr.rx lrx
, lr.lm lr
, ld.rn ldn
, ld.rx ldx
, ld.lm ld
FROM
lm lr
JOIN
lm ld ON
ld.rx > (SELECT max(rx) FROM lm) - lr.rx OR
(
(lr.rx = ld.rx) IS NULL AND
(lr.rx, ld.rx) IS DISTINCT FROM (NULL, NULL) AND
ld.rn >= (SELECT max(rn) FROM lm) - lr.rn
)
)
, lcx AS (
SELECT DISTINCT
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
pg_locks ld
JOIN
pg_locks lr ON
lr.pid <> ld.pid AND
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) IS NOT DISTINCT FROM (ld.locktype, ld.database, ld.relation, ld.page, ld.tuple, ld.virtualxid, ld.transactionid::text::bigint, ld.classid, ld.objid, ld.objsubid) AND
(lr.granted, ld.granted) = (TRUE, FALSE)
JOIN
lmx ON
(lmx.lr, lmx.ld) = (lr.mode, ld.mode)
WHERE
(ld.pid, ld.granted) = ($1::integer, FALSE)
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN ARRAY[relation::text]
WHEN 'extend' THEN ARRAY[relation::text]
WHEN 'page' THEN ARRAY[relation, page]::text[]
WHEN 'tuple' THEN ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN ARRAY[transactionid::text]
WHEN 'virtualxid' THEN regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN ARRAY[classid::text]
WHEN 'advisory' THEN ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp "locked"
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, (lc.locktype, lc.database, lc.relation, lc.page, lc.tuple, lc.virtualxid, lc.transactionid::text::bigint, lc.classid, lc.objid, lc.objsubid) IS NOT DISTINCT FROM lcx.target "conflict"
FROM
lcx
JOIN
pg_locks lc ON
lc.pid IN (lcx.ldp, lcx.lrp);
Problème n ° 1 - démarrage lent
Comme vous pouvez le voir dans l'exemple du journal, à côté de la ligne signalant l'occurrence d'un verrou ( LOG), il y a 3 autres lignes ( DETAIL, CONTEXT, STATEMENT) rapportant des informations étendues.Tout d'abord, nous avons attendu la formation d'un «package» complet des 4 entrées et ce n'est qu'ensuite que nous nous sommes tournés vers la base de données. Mais nous ne pouvons terminer la formation du package que lorsque le prochain enregistrement (déjà 5ème!) Arrive, avec les détails d'un autre processus, ou par timeout. Il est clair que les deux options provoquent une attente inutile.Pour éliminer ces retards, nous sommes passés au traitement en continu des enregistrements de verrouillage. Autrement dit, nous nous tournons maintenant vers la base de données cible dès que nous avons trié le premier enregistrement et réalisé que c'était le verrou décrit ici.Problème n ° 2 - demande lente
Mais encore, certaines des serrures n'ont pas eu le temps d'être analysées. Ils ont commencé à creuser plus profondément et ont découvert que sur certains serveurs, notre demande d'analyse était exécutée pendant 15 à 20 ms !La raison s'est avérée courante - le nombre total de verrous actifs sur la base, atteignant plusieurs milliers: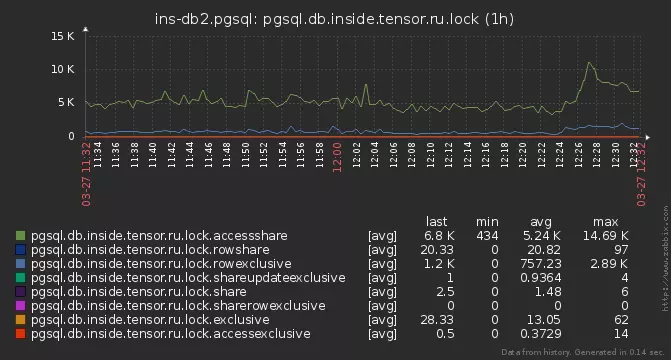
pg_locks
Ici, il convient de noter que les verrous dans PostgreSQL ne sont «stockés» nulle part, mais ne sont présentés que dans la vue système pg_locks , qui est un reflet direct de la fonction pg_lock_status. Et dans notre demande, nous en lisons trois fois ! En attendant, nous lisons ces milliers d'instances de verrouillage, et jetons celles qui ne sont pas liées à notre PID, le verrou lui-même a réussi à "résoudre" ... Lasolution était de "matérialiser" l'état de pg_locks dans le CTE - après cela, vous pouvez le parcourir autant de fois que vous le souhaitez, c'est déjà ne change pas. De plus, après s'être assis sur l'algorithme, il a été possible de tout réduire à seulement deux de ses analyses.Dynamique excessive
Et si même un peu plus près la requête ci-dessus, nous pouvons voir que le CTE lmet lmxnon en aucune façon lié aux données, mais simplement calculer toujours la même définition de matrice "statique" du conflit entre les modes de blocage . Donc, définissons-le simplement comme une qualité VALUES.Problème n ° 3 - voisins
Mais une partie des écluses était encore ignorée. Habituellement, cela s'est produit selon le schéma suivant - quelqu'un a bloqué une ressource populaire, et plusieurs processus l'ont rapidement et rapidement couru ou le long d'une chaîne .En conséquence, nous avons attrapé le premier PID, sommes allés à la base cible (et afin de ne pas le surcharger, nous ne gardons qu'une seule connexion), l'analyse a retourné avec le résultat, a pris le PID suivant ... # 2 est déjà parti!En fait, pourquoi devons-nous accéder à la base de données pour chaque PID séparément, si nous filtrons toujours les verrous de la liste générale dans la demande? Prenons immédiatement la liste complète des processus en conflit directement à partir de la base de données et répartissons leurs verrous sur tous les PID tombés lors de l'exécution de la demande:WITH lm(ld, lr) AS (
VALUES
('AccessShareLock', '{AccessExclusiveLock}'::text[])
, ('RowShareLock', '{ExclusiveLock,AccessExclusiveLock}'::text[])
, ('RowExclusiveLock', '{ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareUpdateExclusiveLock', '{ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareRowExclusiveLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ExclusiveLock', '{RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('AccessExclusiveLock', '{AccessShareLock,RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
)
, locks AS (
SELECT
(
locktype
, database
, relation
, page
, tuple
, virtualxid
, transactionid::text::bigint
, classid
, objid
, objsubid
) target
, *
FROM
pg_locks
)
, ld AS (
SELECT
*
FROM
locks
WHERE
NOT granted
)
, lr AS (
SELECT
*
FROM
locks
WHERE
target::text = ANY(ARRAY(
SELECT DISTINCT
target::text
FROM
ld
)) AND
granted
)
, lcx AS (
SELECT DISTINCT
lr.target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
ld
JOIN
lr
ON lr.pid <> ld.pid AND
lr.target IS NOT DISTINCT FROM ld.target
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN
ARRAY[relation::text]
WHEN 'extend' THEN
ARRAY[relation::text]
WHEN 'page' THEN
ARRAY[relation, page]::text[]
WHEN 'tuple' THEN
ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN
ARRAY[transactionid::text]
WHEN 'virtualxid' THEN
regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN
ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN
ARRAY[classid::text]
WHEN 'advisory' THEN
ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp as locked
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, lc.target IS NOT DISTINCT FROM lcx.target as conflict
FROM
lcx
JOIN
locks lc
ON lc.pid IN (lcx.ldp, lcx.lrp);
Nous avons maintenant le temps d'analyser même les verrous qui n'existent que 1 à 2 ms après être entrés dans le journal.Analyses ça
En fait, pourquoi avons-nous essayé si longtemps? Qu'est-ce que cela nous donne en conséquence? ..type | target | locked | pid | mode | granted | conflict
---------------------------------------------------------------------------------------
relation | {225388639} | f | 216547 | AccessShare | t | f
relation | {423576026} | f | 216547 | AccessShare | t | f
advisory | {225386226,194303167,2} | t | 24964 | Exclusive | f | t
relation | {341894815} | t | 24964 | AccessShare | t | f
relation | {416441672} | f | 216547 | AccessShare | t | f
relation | {225964322} | f | 216547 | AccessShare | t | f
...
Dans cette plaque, les valeurs targetavec un type nous sont utiles relation, car chacune de ces valeurs est un OID d'une table ou d'un index . Il reste maintenant très peu - pour apprendre à interroger la base de données pour les OID qui nous sont encore inconnus, afin de les traduire sous une forme lisible par l'homme:SELECT $1::oid::regclass;
Maintenant, connaissant la «matrice» complète des verrous et tous les objets sur lesquels ils ont été superposés par chacune des transactions, nous pouvons conclure «ce qui s'est passé du tout» , et quelle ressource a causé le conflit, même si la demande était bloquée, nous étions inconnus. Cela peut facilement se produire, par exemple, lorsque le temps d'exécution d'une demande de blocage n'est pas assez long pour accéder au journal, mais que la transaction une fois terminée a été active et a créé des problèmes pendant longtemps.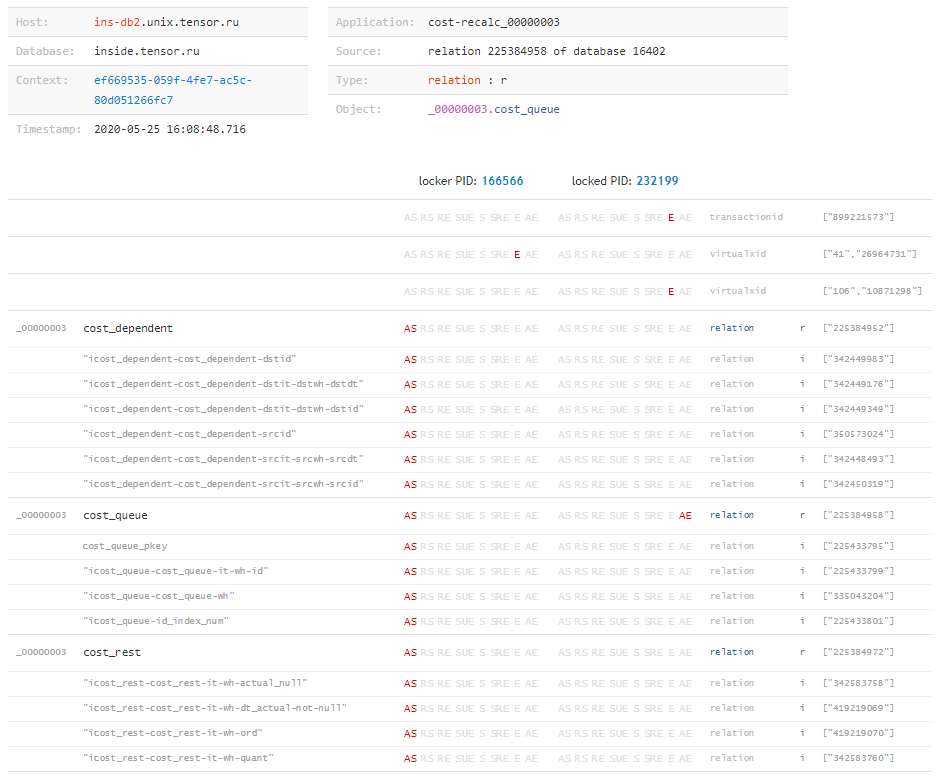 Mais à ce sujet - dans un autre article.
Mais à ce sujet - dans un autre article."Tout seul"
En attendant, nous collecterons la version complète de la «surveillance», qui supprimera automatiquement le statut des verrous de nos archives dès qu'un élément suspect apparaîtra dans le journal:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}' \
| xargs -l -I{} tail -f {} \
| stdbuf -o0 grep 'still waiting for' \
| xargs -l -I{} date '+%Y%m%d-%H%M%S.%N' \
| xargs -l -I{} psql -U postgres postgres -f detect-lock.sql -o {}-lock.log
Et à côté de detect-lock.sqlmettre la dernière demande. Exécutez - et obtenez un tas de fichiers avec le contenu souhaité à l'intérieur:# cat 20200526-181433.331839375-lock.log
type | target | locked | pid | mode | granted | conflict
---------------+----------------+--------+--------+--------------+---------+----------
relation | {279588430} | t | 136325 | RowExclusive | t | f
relation | {279588422} | t | 136325 | RowExclusive | t | f
relation | {17157} | t | 136325 | RowExclusive | t | f
virtualxid | {110,12171420} | t | 136325 | Exclusive | t | f
relation | {279588430} | f | 39339 | RowExclusive | t | f
relation | {279588422} | f | 39339 | RowExclusive | t | f
relation | {17157} | f | 39339 | RowExclusive | t | f
virtualxid | {360,11744113} | f | 39339 | Exclusive | t | f
virtualxid | {638,4806358} | t | 80553 | Exclusive | t | f
advisory | {1,1,2} | t | 80553 | Exclusive | f | t
advisory | {1,1,2} | f | 80258 | Exclusive | t | t
transactionid | {3852607686} | t | 136325 | Exclusive | t | f
extend | {279588422} | t | 136325 | Exclusive | f | t
extend | {279588422} | f | 39339 | Exclusive | t | t
transactionid | {3852607712} | f | 39339 | Exclusive | t | f
(15 rows)
Eh bien, alors - asseyez-vous et analysez ...