Dans cet article, je vais raconter et montrer un exemple de la façon dont une personne ayant une expérience minimale en science des données a pu collecter des données sur le forum et créer une modélisation thématique des publications en utilisant le modèle LDA, et a révélé des sujets douloureux pour les personnes souffrant d'intolérance cœliaque.L'année dernière, j'avais besoin d'améliorer d'urgence mes connaissances dans le domaine de l'apprentissage automatique. Je suis chef de produit pour la science des données, l'apprentissage automatique et l'IA, ou d'une autre manière chef de produit technique AI / ML. Les compétences en affaires et la capacité de développer des produits, comme c'est généralement le cas dans les projets destinés à des utilisateurs qui ne sont pas dans le domaine technique, ne suffisent pas. Vous devez comprendre les concepts techniques de base de l'industrie du ML et, si nécessaire, être capable d'écrire vous-même un exemple pour démontrer le produit.Depuis environ 5 ans, je développe des projets front-end, développant des applications web complexes sur JS et React, mais je n'ai jamais traité d'apprentissage automatique, d'ordinateurs portables et d'algorithmes. Par conséquent, quand j'ai vu la nouvelle d' Otus qu'ils avaient ouvert un cours expérimental de cinq mois sur l'apprentissage automatique , sans hésitation, j'ai décidé de subir des tests d'essai et j'ai suivi le cours.Pendant cinq mois, chaque semaine, il y avait des conférences de deux heures et des devoirs pour eux. J'y ai appris les bases du ML: divers algorithmes de régression, classifications, ensembles de modèles, renforcement du gradient et même des technologies cloud légèrement affectées. En principe, si vous écoutez attentivement chaque conférence, il y a suffisamment d'exemples et d'explications pour les devoirs. Mais parfois, comme dans tout autre projet de codage, je devais me tourner vers la documentation. Étant donné mon emploi à temps plein, il était très pratique d'étudier, car je pouvais toujours réviser le dossier d'une conférence en ligne.À la fin de la formation de ce cours, tout le monde devait prendre le projet final. L'idée du projet est née tout à fait spontanément, à ce moment-là j'ai commencé une formation en entrepreneuriat à Stanford, où j'ai fait partie de l'équipe qui travaillait sur le projet pour les personnes souffrant d'intolérance cœliaque. Au cours de l'étude de marché, j'étais intéressé de savoir de quels soucis, de quoi ils parlent, de quoi les personnes atteintes de cette fonctionnalité se plaignent.Au fil de l'étude, j'ai trouvé un forum sur celiac.comavec une énorme quantité de matériel sur la maladie cœliaque. Il était évident que faire défiler manuellement et lire plus de 100 000 messages n'était pas pratique. Alors l'idée m'est venue, d'appliquer les connaissances que j'ai reçues dans ce cours: rassembler toutes les questions et commentaires du forum à partir d'un certain sujet et faire de la modélisation thématique avec les mots les plus courants dans chacun d'eux.Étape 1. Collecte de données sur le forum
Le forum se compose de nombreux sujets de différentes tailles. Au total, ce forum compte environ 115 000 sujets et environ un million de messages, avec des commentaires à leur sujet. Je m'intéressais au sous-thème spécifique «Faire face à la maladie cœliaque» , qui signifie littéralement «Faire face à la maladie cœliaque», si en russe, cela signifie plus «continuer à vivre avec un diagnostic de maladie cœliaque et faire face aux difficultés». Ce sous-sujet contient environ 175 000 commentaires.Le téléchargement des données s'est déroulé en deux étapes. Pour commencer, j'ai dû parcourir toutes les pages du sujet et collecter tous les liens vers tous les articles, de sorte qu'à l'étape suivante, je pouvais déjà collecter un commentaire.url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
Comme le forum s'est avéré être assez ancien, j'ai eu beaucoup de chance et le site n'a eu aucun problème de sécurité, donc pour collecter les données, il suffisait d'utiliser la combinaison User-Agent de la fake_useragent , la bibliothèque Beautiful Soup pour travailler avec le balisage html et connaître le nombre de pages:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
Ensuite, téléchargez le DOM HTML de chaque page pour en extraire facilement et facilement des données à l'aide de la bibliothèque BeautifulSoup Python .
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
Pour télécharger les données, j'avais besoin de déterminer les champs nécessaires à l'analyse: trouver les valeurs de ces champs dans le DOM et les enregistrer dans le dictionnaire. Je venais moi-même de l'arrière-plan, donc travailler avec la maison et les objets était trivial pour moi.def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
Au total, j'ai collecté environ 15 450 messages dans ce sujet.coping_posts_info = collect_post_info(coping_pages)
Maintenant, ils pouvaient être transférés vers le DataFrame afin qu'ils se trouvent là magnifiquement, et en même temps les enregistrer dans un fichier csv afin que vous n'ayez pas à attendre à nouveau lorsque les données ont été collectées sur le site si le bloc-notes s'est accidentellement cassé ou j'ai accidentellement redéfini une variable où.df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
Après avoir collecté une collection de messages, j'ai procédé à la collecte des commentaires eux-mêmes.def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
ÉTAPE 2 Analyse des données et modélisation thématique
À l'étape précédente, nous avons collecté des données sur le forum et reçu les données finales sous la forme de 153777 lignes de questions et commentaires.Mais les données collectées ne sont pas intéressantes, donc la première chose que je voulais faire était une analyse très simple: j'ai dérivé des statistiques pour les 30 sujets les plus consultés et les 30 sujets les plus commentés.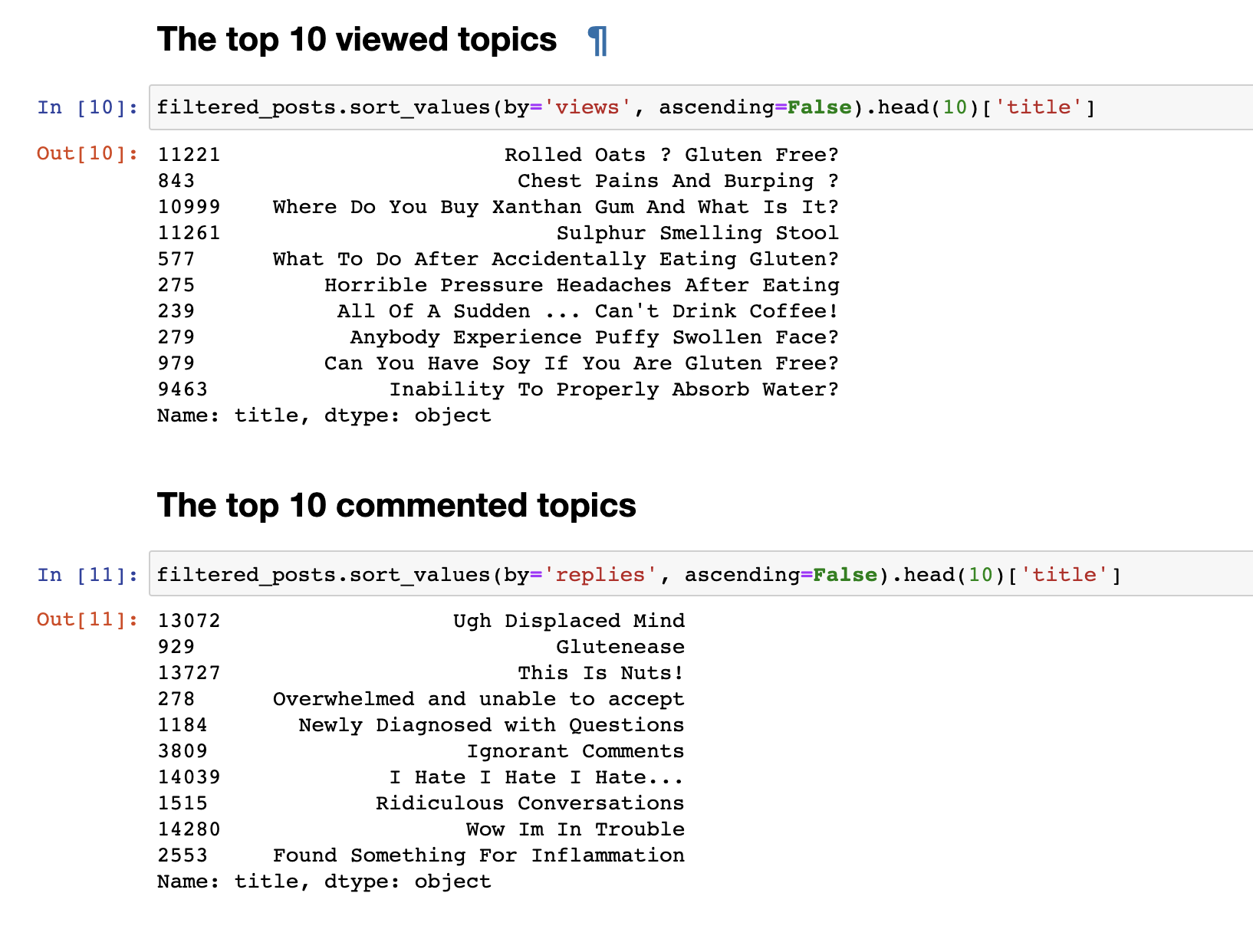 Les publications les plus vues ne coïncidaient pas avec les publications les plus commentées. Les titres des articles commentés, même à première vue, sont visibles. Leurs noms sont plus émotifs: «Je déteste, je déteste, je déteste» ou « Commentaires arrogants» ou «Wow, j'ai des ennuis» . Et les plus regardés ont un format de question: "Puis-je manger du soja?", "Pourquoi ne puis-je pas absorber correctement l'eau?"autre.Nous avons fait une simple analyse de texte. Pour passer directement à une analyse plus complexe, vous devez préparer les données elles-mêmes avant de les soumettre à l'entrée du modèle LDA pour une ventilation par sujet. Pour ce faire, débarrassez-vous des commentaires contenant moins de 30 mots, afin de filtrer les spams et les courts commentaires sans signification. Nous les amenons en minuscules.
Les publications les plus vues ne coïncidaient pas avec les publications les plus commentées. Les titres des articles commentés, même à première vue, sont visibles. Leurs noms sont plus émotifs: «Je déteste, je déteste, je déteste» ou « Commentaires arrogants» ou «Wow, j'ai des ennuis» . Et les plus regardés ont un format de question: "Puis-je manger du soja?", "Pourquoi ne puis-je pas absorber correctement l'eau?"autre.Nous avons fait une simple analyse de texte. Pour passer directement à une analyse plus complexe, vous devez préparer les données elles-mêmes avant de les soumettre à l'entrée du modèle LDA pour une ventilation par sujet. Pour ce faire, débarrassez-vous des commentaires contenant moins de 30 mots, afin de filtrer les spams et les courts commentaires sans signification. Nous les amenons en minuscules.
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
Supprimez les mots vides inutiles pour effacer notre sélection de textestop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
Nous ajoutons également des bigrammes et formons un sac de mots pour mettre en évidence des expressions stables, par exemple, comme gluten_free, support_group et d'autres expressions qui, lorsqu'elles sont regroupées, ont une certaine signification.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Maintenant, nous sommes enfin prêts à former directement le modèle LDA lui-même.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
À la fin de la formation, nous obtenons finalement le résultat des sujets formés. Ce que j'ai joint à la fin de ce post.for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
Comme cela peut être perceptible, les sujets se sont avérés être très différents dans leur contenu les uns des autres. Selon eux, il devient clair de quoi les gens parlent d'intolérance cœliaque. Fondamentalement, sur la nourriture, aller au restaurant, les aliments contaminés avec du gluten, les douleurs terribles, le traitement, aller chez le médecin, la famille, les malentendus et d'autres choses que les gens doivent affronter chaque jour en relation avec leur problème.C'est tout. Merci à tous pour votre attention. J'espère que vous trouverez ce matériel intéressant et utile. Et pourtant, comme je ne suis pas développeur DS, ne jugez pas strictement. S'il y a quelque chose à ajouter ou à améliorer, j'accueille toujours les critiques constructives, écrivez.Pour afficher 30 sujetsAttention, beaucoup d'images