D'un éditeur de blog Google: vous êtes-vous déjà demandé comment les ingénieurs de Google Cloud Technical Solutions (TSE) gèrent vos appels au support technique? La responsabilité des ingénieurs du support technique de TSE est de détecter et de résoudre les sources de problèmes identifiés par les utilisateurs. Certains de ces problèmes sont assez simples, mais parfois vous rencontrez un appel nécessitant l'attention de plusieurs ingénieurs à la fois. Dans cet article, l'un des employés de TSE nous parlera d'un problème très délicat de sa pratique récente - le cas de paquets DNS manquants. Au cours de cette histoire, nous verrons comment les ingénieurs ont réussi à résoudre la situation et quelles nouvelles choses ils ont apprises au cours de l'élimination de l'erreur. Nous espérons que cette histoire vous parlera non seulement d'un bogue profondément enraciné, mais qu'elle vous permettra également de comprendre les processus qui se produisent lors de la soumission d'une demande de prise en charge de Google Cloud. Le dépannage est à la fois une science et un art. Tout commence par la construction d'une hypothèse sur la cause du comportement non standard du système, après quoi il est testé pour sa résistance. Cependant, avant de formuler une hypothèse, nous devons clairement identifier et formuler avec précision le problème. Si la question vous semble trop vague, vous devez tout analyser correctement; c'est "l'art" du dépannage.Dans le contexte de Google Cloud, ces processus sont parfois compliqués, car Google Cloud a du mal à garantir la confidentialité de ses utilisateurs. Pour cette raison, les ingénieurs TSE n'ont ni accès à l'édition de vos systèmes, ni la possibilité d'afficher les configurations aussi largement que les utilisateurs. Par conséquent, pour tester l'une de nos hypothèses, nous (ingénieurs) ne pouvons pas modifier rapidement le système.Certains utilisateurs croient que nous allons tout réparer comme si les mécaniciens du service automobile et nous envoyaient simplement l'identifiant de la machine virtuelle, alors qu'en réalité le processus se déroule dans un format de conversation: collecte d'informations, génération et confirmation (ou réfutation) d'hypothèses, et, finalement, résolution les problèmes reposent sur la communication avec le client.
Le dépannage est à la fois une science et un art. Tout commence par la construction d'une hypothèse sur la cause du comportement non standard du système, après quoi il est testé pour sa résistance. Cependant, avant de formuler une hypothèse, nous devons clairement identifier et formuler avec précision le problème. Si la question vous semble trop vague, vous devez tout analyser correctement; c'est "l'art" du dépannage.Dans le contexte de Google Cloud, ces processus sont parfois compliqués, car Google Cloud a du mal à garantir la confidentialité de ses utilisateurs. Pour cette raison, les ingénieurs TSE n'ont ni accès à l'édition de vos systèmes, ni la possibilité d'afficher les configurations aussi largement que les utilisateurs. Par conséquent, pour tester l'une de nos hypothèses, nous (ingénieurs) ne pouvons pas modifier rapidement le système.Certains utilisateurs croient que nous allons tout réparer comme si les mécaniciens du service automobile et nous envoyaient simplement l'identifiant de la machine virtuelle, alors qu'en réalité le processus se déroule dans un format de conversation: collecte d'informations, génération et confirmation (ou réfutation) d'hypothèses, et, finalement, résolution les problèmes reposent sur la communication avec le client.Question à l'examen
Aujourd'hui, nous avons une histoire avec une bonne fin. L'une des raisons de la solution réussie du cas proposé est une description très détaillée et précise du problème. Ci-dessous vous pouvez voir une copie du premier ticket (édité, afin de cacher des informations confidentielles): Ce message a beaucoup d'informations utiles pour nous:
Ce message a beaucoup d'informations utiles pour nous:- VM spécifiée
- Le problème est indiqué - DNS ne fonctionne pas
- Il est indiqué où le problème se manifeste - VM et conteneur
- Les étapes que l'utilisateur a suivies pour identifier le problème sont indiquées.
L'appel a été enregistré comme «P1: Impact critique - Service inutilisable en production», ce qui signifie un suivi constant de la situation 24h / 24 et 7j / 7 selon le schéma «Follow the Sun» (le lien peut être lu plus en détail sur les priorités des appels des utilisateurs ), avec transmission par une équipe d'assistance technique à l'autre à chaque décalage de fuseau horaire. En fait, au moment où le problème a atteint notre équipe à Zurich, elle a réussi à faire le tour du monde. À ce moment, l'utilisateur a pris des mesures pour réduire les conséquences, cependant, il avait peur d'une répétition de la situation sur la production, car la raison principale n'était toujours pas trouvée.Au moment où le billet est arrivé à Zurich, nous disposions déjà des informations suivantes:- Contenu
/etc/hosts - Contenu
/etc/resolv.conf - Conclusion
iptables-save - Le
ngrepfichier pcap compilé par la commande
Avec ces données, nous étions prêts à entamer la phase «d'investigation» et de dépannage.Nos premiers pas
Tout d'abord, nous avons vérifié les journaux et l'état du serveur de métadonnées et nous nous sommes assurés qu'il fonctionne correctement. Le serveur de métadonnées répond avec l'adresse IP 169.254.169.254 et, entre autres, est responsable du contrôle des noms de domaine. Nous avons également vérifié que le pare-feu fonctionne correctement avec VM et ne bloque pas les paquets.C'était un problème étrange: le test nmap a réfuté notre hypothèse principale sur la perte de paquets UDP, nous avons donc mentalement déduit plusieurs autres options et façons de les vérifier:- Les paquets disparaissent-ils sélectivement? => Vérifier les règles iptables
- Le MTU est-il trop petit ? => Vérifier la sortie
ip a show - Le problème affecte-t-il uniquement les paquets UDP ou TCP? => Éloignez-vous
dig +tcp - Les paquets de recherche générés sont-ils retournés? => Éloignez-vous
tcpdump - Les libdns fonctionnent-ils correctement? => Partez
stracepour vérifier le transfert de paquets dans les deux sens
Ici, nous décidons de téléphoner à l'utilisateur pour le dépannage en direct.Lors de l'appel, nous parvenons à vérifier plusieurs choses:- Après plusieurs vérifications, nous excluons les règles iptables de la liste des raisons.
- Nous vérifions les interfaces réseau et les tables de routage, et revérifions le MTU
- Nous constatons que
dig +tcp google.com(TCP) fonctionne comme il se doit, mais dig google.com(UDP) ne fonctionne pas - Après avoir
tcpdumpexécuté pendant que cela fonctionne dig, nous constatons que les paquets UDP sont retournés - Nous courons
strace dig google.comet voyons comment creuser correctement les appels sendmsg()et recvms(), cependant, le second est interrompu par un timeout
Malheureusement, le changement est sur le point de se terminer et nous sommes obligés de transférer le problème au fuseau horaire suivant. L'appel, cependant, a suscité l'intérêt de notre équipe, et un collègue suggère de créer le paquet DNS source avec le module Python scrapy.from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())
Ce fragment crée un paquet DNS et envoie la demande au serveur de métadonnées.L'utilisateur exécute le code, la réponse DNS est renvoyée et l'application le reçoit, ce qui confirme l'absence de problème au niveau du réseau.Après le prochain "tour du monde", l'appel revient à notre équipe, et je le traduis complètement sur moi-même, pensant qu'il sera plus pratique pour l'utilisateur si l'appel cesse de tourner d'un endroit à l'autre.En attendant, l'utilisateur s'engage à fournir un instantané de l'image système. C'est une très bonne nouvelle: la possibilité de tester le système vous-même accélère considérablement le dépannage, car vous n'avez plus besoin de demander à l'utilisateur d'exécuter des commandes, de m'envoyer des résultats et de les analyser, je peux tout faire moi-même!Des collègues commencent à m'envoyer un peu. Au déjeuner, nous discutons de l'appel, mais personne n'a la moindre idée de ce qui se passe. Heureusement, l'utilisateur lui-même a déjà pris des mesures d'atténuation et n'est pas pressé, nous avons donc le temps de préparer le problème. Et puisque nous avons une image, nous pouvons effectuer tous les tests qui nous intéressent. Bien!Revenir en arrière
L'une des questions les plus fréquemment posées lors d'un entretien avec un ingénieur système est: "Que se passe-t-il lorsque vous envoyez une requête ping à www.google.com ?" La question est chic, car le candidat doit être décrit du shell à l'espace utilisateur, au cœur du système et plus loin au réseau. Je souris: parfois les questions d'entrevue sont également utiles dans la vraie vie ...Je décide d'appliquer cette question eychar au problème actuel. En gros, lorsque vous essayez de déterminer le nom DNS, les événements suivants se produisent:- L'application appelle la bibliothèque système, par exemple libdns
- libdns vérifie la configuration système du serveur DNS qu'il doit utiliser (dans le diagramme, c'est 169.254.169.254, serveur de métadonnées)
- libdns utilise des appels système pour créer un socket UDP (SOKET_DGRAM) et envoyer des paquets UDP avec une requête DNS dans les deux sens
- À l'aide de l'interface sysctl, vous pouvez configurer la pile UDP au niveau du noyau
- Le noyau interagit avec le matériel pour transmettre des paquets sur le réseau via une interface réseau
- L'hyperviseur intercepte et transmet le paquet au serveur de métadonnées lorsqu'il entre en contact avec lui
- Le serveur de métadonnées détermine le nom DNS par sa sorcellerie et renvoie la réponse de la même manière
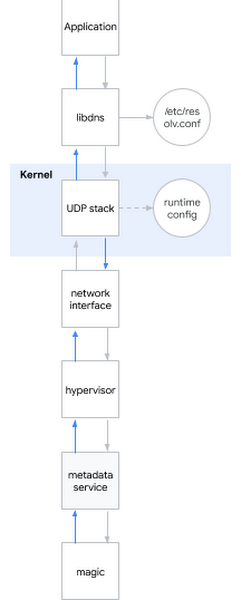 Permettez-moi de vous rappeler quelles hypothèses nous avons déjà réussi à considérer:Hypothèse: bibliothèques cassées
Permettez-moi de vous rappeler quelles hypothèses nous avons déjà réussi à considérer:Hypothèse: bibliothèques cassées- Test 1: exécutez strace dans le système, vérifiez que dig provoque les appels système corrects
- Résultat: les appels système corrects sont appelés
- Test 2: via Srapy pour vérifier si nous pouvons déterminer les noms contournant les bibliothèques système
- Résultat: nous pouvons
- Test 3: exécutez rpm –V sur le package libdns et les fichiers de bibliothèque md5sum
- Résultat: le code de la bibliothèque est complètement identique au code du système d'exploitation qui fonctionne
- Test 4: montez l'image du système racine de l'utilisateur sur la machine virtuelle sans ce comportement, exécutez chroot, voyez si DNS fonctionne
- Résultat: DNS fonctionne correctement
Conclusion basée sur des tests: le problème n'est pas dans les bibliothèquesHypothèse: il y a une erreur dans les paramètres DNS- Test 1: vérifiez tcpdump et voyez si les paquets DNS sont envoyés et retournés correctement après l'exécution de dig
- Résultat: les paquets sont transmis correctement
- Test 2: revérifiez sur le serveur
/etc/nsswitch.confet/etc/resolv.conf - Résultat: tout est correct
Conclusion basée sur les tests: le problème n'est pas dans l' hypothèse de configuration DNS: le noyau est endommagé- Test: installez un nouveau noyau, vérifiez la signature, redémarrez
- Résultat: comportement similaire
Conclusion basée sur des tests: le noyau n'est pas endommagéHypothèse: comportement incorrect du réseau utilisateur (ou de l'interface réseau de l'hyperviseur)- Test 1: vérifiez les paramètres du pare-feu
- Résultat: le pare-feu transmet les paquets DNS sur l'hôte et GCP
- Test 2: intercepter le trafic et suivre l'exactitude du transfert et du retour des requêtes DNS
- Résultat: tcpdump accuse réception des paquets de retour par l'hôte
Conclusion basée sur des tests: le problème n'est pas dans le réseauHypothèse: le serveur de métadonnées ne fonctionne pas- Test 1: recherchez les anomalies dans les journaux du serveur de métadonnées
- Résultat: il n'y a aucune anomalie dans les journaux
- Test 2: contournez le serveur de métadonnées via
dig @8.8.8.8 - Résultat: l'autorisation est violée même sans utiliser de serveur de métadonnées
Conclusion basée sur les tests: le problème n'est pas dans le serveur de métadonnéesBottom line: nous avons testé tous les sous - systèmes à l' exception des paramètres d'exécution!Plonger dans les paramètres d'exécution du noyau
Pour configurer le runtime du noyau, vous pouvez utiliser les options de ligne de commande (grub) ou l'interface sysctl. J'ai regardé dedans /etc/sysctl.confet je pense seulement, j'ai trouvé quelques paramètres personnalisés. Me sentant comme si j'avais saisi quelque chose, j'ai rejeté tous les paramètres non réseau ou non TCP, restant des paramètres de la montagne net.core. Ensuite, je me suis tourné vers l'endroit où la machine virtuelle a les autorisations d'hôte et j'ai commencé à appliquer l'un après l'autre, l'un après l'autre les paramètres avec une machine virtuelle cassée, jusqu'à ce que j'atteigne le criminel:net.core.rmem_default = 2147483647
La voici, une configuration qui brise le DNS! J'ai trouvé un instrument du crime. Mais pourquoi cela se produit-il? J'avais encore besoin d'un motif.La définition de la taille de base de la mémoire tampon des paquets DNS s'effectue via net.core.rmem_default. Une valeur typique varie quelque part au sein de 200 Ko, mais si votre serveur reçoit beaucoup de paquets DNS, vous pouvez augmenter la taille du tampon. Si le tampon est plein au moment où un nouveau paquet arrive, par exemple, parce que l'application ne le traite pas assez rapidement, alors vous commencerez à perdre des paquets. Notre client a correctement augmenté la taille du tampon car il craignait la perte de données, car il utilisait l'application pour collecter des métriques via des paquets DNS. La valeur qu'il a définie était le maximum possible: 2 31 -1 (si vous définissez 2 31 , le noyau retournera «ARGUMENT INVALIDE»).Du coup, j'ai compris pourquoi nmap et scapy fonctionnaient correctement: ils utilisaient des sockets raw! Les sockets brutes sont différentes des sockets ordinaires: elles fonctionnent en contournant les iptables, et elles ne sont pas mises en mémoire tampon!Mais pourquoi «un tampon trop grand» cause-t-il des problèmes? Cela ne fonctionne évidemment pas comme prévu.À ce stade, j'ai pu reproduire le problème sur plusieurs cœurs et plusieurs distributions. Le problème s'est déjà manifesté dans le noyau 3.x et se manifeste désormais également dans le noyau 5.x.En effet, au démarragesysctl -w net.core.rmem_default=$((2**31-1))
DNS a cessé de fonctionner.J'ai commencé à rechercher des valeurs de travail via un simple algorithme de recherche binaire et j'ai constaté que le système fonctionnait avec 2147481343, mais ce nombre était un ensemble de nombres sans signification pour moi. J'ai invité le client à essayer ce numéro, et il a répondu que le système fonctionnait avec google.com, mais qu'il donnait toujours une erreur avec d'autres domaines, alors j'ai continué mon enquête.J'ai installé dropwatch , un outil que j'aurais dû utiliser auparavant: il montre où exactement le paquet se trouve dans le noyau. La fonction était coupable udp_queue_rcv_skb. J'ai téléchargé les sources du noyau et ajouté plusieurs fonctions printk pour suivre où le paquet se trouve spécifiquement. J'ai rapidement trouvé la bonne conditionif, et pendant un certain temps le regarda simplement, car c'est alors que tout s'est finalement réuni dans une image entière: 2 31 -1, un nombre sans signification, un domaine inactif ... C'était un morceau de code dans __udp_enqueue_schedule_skb:if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;
Remarque:rmem a le type intsize est de type u16 (int 16 bits non signé) et stocke la taille du paquetsk->sk_rcybuf est de type int et stocke la taille du tampon, qui par définition est égale à la valeur de net.core.rmem_default
À l' sk_rcvbufapproche de 2 31 , l'addition de la taille du paquet peut entraîner un débordement d'entier . Et comme il s'agit d'un entier, sa valeur devient négative, donc la condition devient vraie alors qu'elle devrait être fausse (plus d'informations à ce sujet peuvent être trouvées par référence ).L'erreur est corrigée de manière triviale: en lançant sur unsigned int. J'ai appliqué le correctif et redémarré le système, après quoi le DNS a recommencé à fonctionner.Goût de la victoire
J'ai transmis mes résultats au client et envoyé le correctif du noyau LKML . Je suis satisfait: chaque pièce du puzzle s'est réunie en un seul ensemble, je peux expliquer précisément pourquoi nous avons observé ce que nous avons observé, et surtout, nous avons pu trouver une solution au problème en travaillant ensemble!Il convient de reconnaître que le cas s'est avéré rare, et heureusement, de tels appels complexes sont rarement reçus de la part des utilisateurs de notre part.
