Suite de la première partie de l'article «IoT où vous n'avez pas attendu. Développement et tests (partie 1) » ne s'est pas fait attendre. Cette fois, je vais vous dire quelle était l'architecture du projet et quel type de râteau nous avons utilisé lorsque nous avons commencé à tester notre solution.Avertissement: pas une seule poubelle n'a été durement touchée.
Architecture de projet
Nous avons obtenu un projet de microservice typique. La couche de microservices du «niveau inférieur» reçoit les données des appareils et des capteurs, les stocke dans Kafka, après quoi les microservices orientés métier peuvent travailler avec les données reçues de Kafka pour montrer l'état actuel des appareils, construire des analyses et affiner leurs modèles.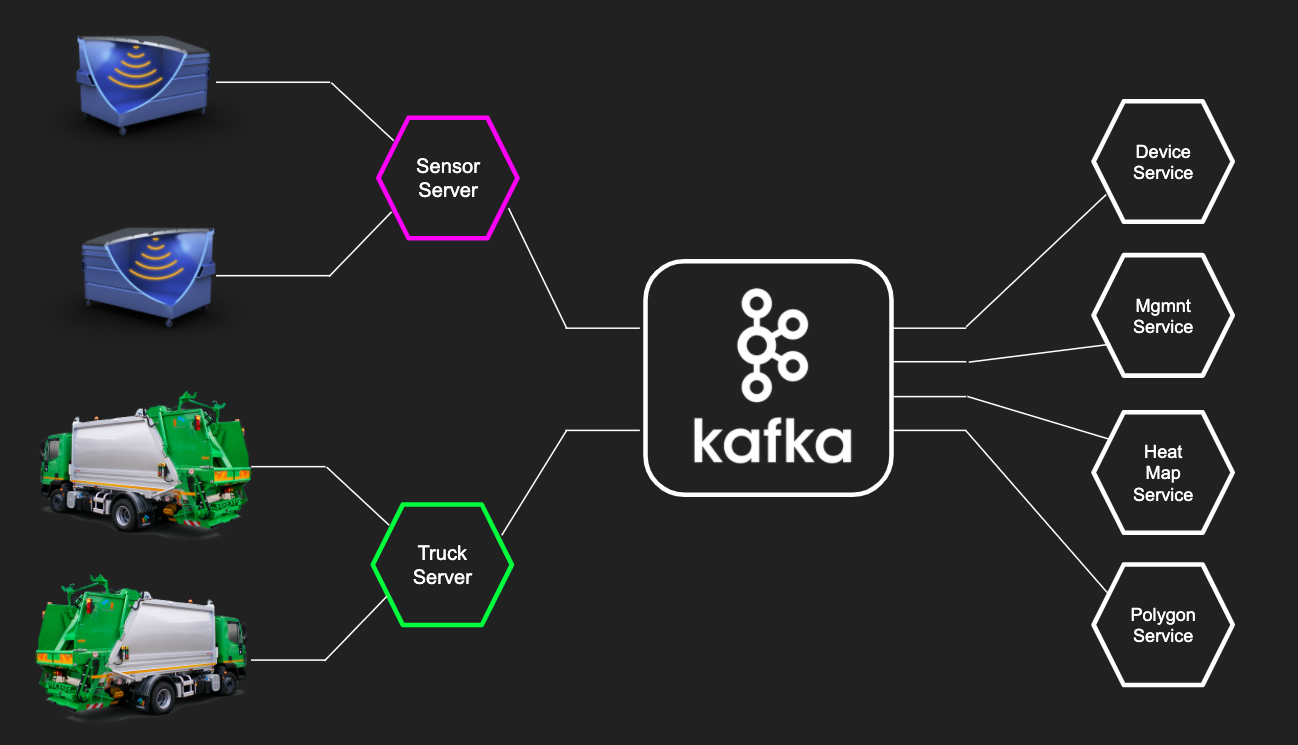 Kafka dans le projet IoT est devenu très cool. Comparé à d'autres systèmes comme RabbitMQ, Kafka présente plusieurs avantages:
Kafka dans le projet IoT est devenu très cool. Comparé à d'autres systèmes comme RabbitMQ, Kafka présente plusieurs avantages:- Travailler avec des flux : les données brutes des capteurs peuvent être traitées pour obtenir un flux. Et avec les flux, vous pouvez configurer de manière flexible ce que vous souhaitez filtrer en eux, et il est facile de faire du streaming (créer de nouveaux flux de données)
- : Kafka , , , . - , - , . , Kafka , . , , , .
Backend
Tout d'abord, jetons un œil au backend qui nous est familier, toute la couche métier de l'application est construite sur la même pile Java et Spring. Pour tester des applications de microservices dans un environnement réel, nous utilisons la bibliothèque de conteneurs de test. Il vous permet de déployer facilement des liaisons externes (Kafka, PostgreSQL, MongoDB, etc.) dans Docker.Tout d'abord, nous élevons le conteneur requis dans Docker, lançons l'application et sur l'instance réelle, nous exécutons déjà des données de test.À propos de la façon exacte dont nous procédons, j'ai parlé en détail au Heisenbug 2019 Piter dans le rapport «Microservice Wars: JUnit Episode 5 - TestContainers Strikes Back»:Regardons un petit exemple de son apparence. Le service de niveau inférieur prend les données des appareils et les envoie à Kafka. Et le service Heat Map de la partie commerciale prend les données de kafka et construit une carte thermique. Testons la réception de données avec le service Heat Map (via Kafka)
Testons la réception de données avec le service Heat Map (via Kafka)@KafkaTestContainer
@SpringBootTest
class KafkaIntegrationTest {
@Autowired
private KafkaTemplate kafkaTemplate;
@Test
void sendTest() {
kafkaTemplate.send(TOPIC_NAME, MEASSAGE_BODY)
}
}
Nous écrivons un test SpringBoot d'intégration régulier, cependant, il diffère par le style d'annotation de la configuration de l'environnement de test. Une annotation est @KafkaTestContainernécessaire pour élever Kafka. Pour l'utiliser, vous devez connecter la bibliothèque:spring-test-kafkaLorsque l'application démarre, Spring démarre et le conteneur Kafka démarre dans Docker. Ensuite, dans le test, nous l'utilisons kafkaTemplate, l'injectons dans le cas de test et envoyons les données à Kafka pour tester la logique de traitement des nouvelles données du sujet.Tout cela se produit sur une instance Kafka normale, pas d'options intégrées, mais uniquement la version qui tourne en production. Le service Heat Map utilise MongoDB comme stockage, et le test de MongoDB semble similaire:
Le service Heat Map utilise MongoDB comme stockage, et le test de MongoDB semble similaire:@MongoDbDataTest
class SensorDataRecordServiceTest {
@Autowired
private SensorDataRecordRepository repository;
@Test
@MongoDataSet(value ="sensor_data.json")
void findSingle() {
var log = repository.findAllByDeviceId("001");
assertThat(log).hasSize(1);
...
}
}
Annotation @MongoDbDataTestlance MongoDB dans Docker de la même manière que Kafka. Une fois l'application lancée, nous pouvons utiliser le référentiel pour travailler avec MongoDB.Pour utiliser cette fonctionnalité dans vos tests, il vous suffit de connecter la bibliothèque:spring-test-mongoSoit dit en passant, il existe de nombreuses autres utilités, par exemple, vous pouvez charger la base de données dans la base de données via l'annotation avant d'exécuter le test, @MongoDataSetcomme dans l'exemple ci-dessus, ou à l'aide de l'annotation, @ExpectedMongoDataSetvérifiez qu'après avoir terminé le scénario de test dans la base de données, l'ensemble de données exact que nous attendons est apparu.Je vais vous en dire plus sur l'utilisation des données de test au Heisenbug 2020 Piter , qui se tiendra en ligne du 15 au 18 juin.
Tester des choses spécifiques à l'IoT
Si la partie métier est un backend typique, le travail avec les données des appareils contenait beaucoup de râteaux et de spécificités liées au matériel.Vous avez un appareil et vous devez l'appairer. Pour cela, vous aurez besoin de documentation. C'est bien quand vous avez un morceau de fer et des quais dessus. Cependant, tout a commencé d'une manière différente: il n'y avait que de la documentation et l'appareil était toujours en route. Nous avons filmé une petite application, qui en théorie aurait dû fonctionner, mais dès que de vrais appareils sont arrivés, nos attentes ont été confrontées à la réalité.Nous pensions que l'entrée serait un format binaire, et l'appareil a commencé à nous lancer un fichier XML. Et sous une forme si difficile, la première règle du projet IoT est née:Ne croyez jamais la documentation!
En principe, les données reçues de l'appareil étaient plus ou moins claires: Time- c'est l'horodatage, DevEUI- l'identifiant de l'appareil, LrrLATet LrrLON- les coordonnées. Mais c'est quoi
Mais c'est quoi payload_hex? Nous voyons 8 chiffres, que peuvent-ils contenir? Est-ce la distance par rapport à la poubelle, la tension du capteur, le niveau du signal, l'angle d'inclinaison, la température ou tous ensemble? À un moment donné, nous pensions que les fabricants chinois de ces appareils connaissaient une sorte d'archivage du Feng Shui et pouvaient emballer tout ce qui était possible en 8 chiffres. Mais si vous regardez ci-dessus, vous pouvez voir que l'heure est écrite sur une ligne régulière et contient 3 fois plus de bits, c'est-à-dire, évidemment, personne n'a enregistré. En conséquence, il s'est avéré que spécifiquement dans ce firmware, la moitié des capteurs de l'appareil sont simplement éteints, et vous devez attendre un nouveau firmware.Pendant qu'ils attendaient, nous avons fait un banc d'essai dans le bureau, qui était en fait une boîte en carton ordinaire. Nous avons attaché l'appareil à son couvercle et jeté tous les objets de bureau dans la boîte. Nous avions également besoin d'une copie d'essai de la voiture du transporteur, et son rôle a été joué par la machine de l'un des développeurs du projet.Maintenant, nous avons vu sur la carte où se trouvaient les boîtes en carton, et nous savions où le développeur voyageait (spoiler: travail à domicile, et personne n'a annulé le bar le vendredi soir). Cependant, le système avec bancs d'essai n'a pas duré longtemps, car il existe de grandes différences par rapport aux conteneurs réels. Par exemple, si nous parlons de l'accéléromètre, nous avons tourné la boîte d'un côté à l'autre et reçu des lectures du capteur, et tout semblait fonctionner. Mais en réalité, il y a certaines limites.
Cependant, le système avec bancs d'essai n'a pas duré longtemps, car il existe de grandes différences par rapport aux conteneurs réels. Par exemple, si nous parlons de l'accéléromètre, nous avons tourné la boîte d'un côté à l'autre et reçu des lectures du capteur, et tout semblait fonctionner. Mais en réalité, il y a certaines limites. Dans les premières versions de l'appareil, l'angle n'était pas mesuré en valeurs absolues, mais en valeurs relatives. Et lorsque la boîte a été plus inclinée que le delta fixé dans le firmware, le capteur a commencé à fonctionner de manière incorrecte ou n'a même pas pu corriger le virage.
Dans les premières versions de l'appareil, l'angle n'était pas mesuré en valeurs absolues, mais en valeurs relatives. Et lorsque la boîte a été plus inclinée que le delta fixé dans le firmware, le capteur a commencé à fonctionner de manière incorrecte ou n'a même pas pu corriger le virage. Bien sûr, toutes ces erreurs ont été corrigées au cours du processus, mais au début, les différences entre la boîte et le conteneur ont posé beaucoup de problèmes. Et nous avons percé le réservoir de tous les côtés, tout en décidant comment placer le capteur dans le conteneur, de sorte que lors du levage du réservoir avec la voiture du transporteur, nous avons enregistré avec précision que les ordures étaient déchargées.En plus du problème avec l'angle d'inclinaison, nous n'avons pas d'abord pris en compte ce que seront les vraies ordures dans le conteneur. Et si nous jetions du polystyrène et des oreillers dans cette boîte, alors en réalité les gens mettent tout dans un récipient, même du ciment et du sable. Et en conséquence, une fois que le capteur a montré que le conteneur était vide, bien qu'en fait il était plein. Il s'est avéré que quelqu'un pendant la réparation a jeté un matériau absorbant le son frais, qui a amorti les signaux du capteur.À ce stade, nous avons décidé de convenir avec le propriétaire du centre d'affaires où se trouve le bureau afin d'installer des capteurs sur ses poubelles. Nous avons équipé le site devant le bureau, et à partir de ce moment, la vie et la vie quotidienne des développeurs du projet ont radicalement changé. Habituellement, au début de la journée de travail, vous voulez boire du café, lire les nouvelles, et ici vous avez toute la bande pleine de déchets, littéralement:
Bien sûr, toutes ces erreurs ont été corrigées au cours du processus, mais au début, les différences entre la boîte et le conteneur ont posé beaucoup de problèmes. Et nous avons percé le réservoir de tous les côtés, tout en décidant comment placer le capteur dans le conteneur, de sorte que lors du levage du réservoir avec la voiture du transporteur, nous avons enregistré avec précision que les ordures étaient déchargées.En plus du problème avec l'angle d'inclinaison, nous n'avons pas d'abord pris en compte ce que seront les vraies ordures dans le conteneur. Et si nous jetions du polystyrène et des oreillers dans cette boîte, alors en réalité les gens mettent tout dans un récipient, même du ciment et du sable. Et en conséquence, une fois que le capteur a montré que le conteneur était vide, bien qu'en fait il était plein. Il s'est avéré que quelqu'un pendant la réparation a jeté un matériau absorbant le son frais, qui a amorti les signaux du capteur.À ce stade, nous avons décidé de convenir avec le propriétaire du centre d'affaires où se trouve le bureau afin d'installer des capteurs sur ses poubelles. Nous avons équipé le site devant le bureau, et à partir de ce moment, la vie et la vie quotidienne des développeurs du projet ont radicalement changé. Habituellement, au début de la journée de travail, vous voulez boire du café, lire les nouvelles, et ici vous avez toute la bande pleine de déchets, littéralement: Lors du test du capteur de température, comme dans le cas de l'accéléromètre, la réalité a présenté de nouveaux scénarios. La valeur seuil de température est assez difficile à choisir pour que nous sachions à temps que le capteur est allumé et que nous ne lui disons pas au revoir. Par exemple, en été, les conteneurs chauffent beaucoup sous le soleil, et fixer une température seuil trop basse est lourd de notifications constantes du capteur. Et si l'appareil brûle vraiment et que quelqu'un commence à l'éteindre, alors vous devez vous préparer pour que le réservoir soit rempli d'eau par le haut, puis quelqu'un le laissera tomber et s'éteindra sur le sol. Dans ce scénario, le capteur ne survivra évidemment pas.
Lors du test du capteur de température, comme dans le cas de l'accéléromètre, la réalité a présenté de nouveaux scénarios. La valeur seuil de température est assez difficile à choisir pour que nous sachions à temps que le capteur est allumé et que nous ne lui disons pas au revoir. Par exemple, en été, les conteneurs chauffent beaucoup sous le soleil, et fixer une température seuil trop basse est lourd de notifications constantes du capteur. Et si l'appareil brûle vraiment et que quelqu'un commence à l'éteindre, alors vous devez vous préparer pour que le réservoir soit rempli d'eau par le haut, puis quelqu'un le laissera tomber et s'éteindra sur le sol. Dans ce scénario, le capteur ne survivra évidemment pas.
Par conséquent, la deuxième règle: lisez la première règle. C'est - ne faites jamais confiance à la documentation.
Ce qui peut être fait? Par exemple, faites de l'ingénierie inverse: nous nous asseyons avec la console, collectons des données, tournons-tournons le capteur, mettons quelque chose devant, essayons d'identifier les modèles. Ainsi, vous pouvez isoler la distance, l'état du conteneur et la somme de contrôle. Cependant, certaines données étaient difficiles à interpréter, car nos fabricants d'appareils chinois aiment apparemment les vélos. Et afin d'emballer un nombre à virgule flottante au format binaire pour interpréter l'angle d'inclinaison, ils ont décidé de prendre deux octets et de diviser par 35. Et dans toute cette histoire, cela nous a beaucoup aidé que la couche inférieure des services travaillant avec des appareils était isolée du haut, et toutes les données ont été versées via kafka, dont les contrats ont été convenus et sécurisés.Cela a beaucoup aidé en termes de développement, car si le niveau inférieur cassait, alors nous avons vu tranquillement les services aux entreprises, car le contrat y est fixé de manière rigide. Par conséquent, cette deuxième règle pour développer des projets IoT est d'isoler les services et d'utiliser les contrats.
Et dans toute cette histoire, cela nous a beaucoup aidé que la couche inférieure des services travaillant avec des appareils était isolée du haut, et toutes les données ont été versées via kafka, dont les contrats ont été convenus et sécurisés.Cela a beaucoup aidé en termes de développement, car si le niveau inférieur cassait, alors nous avons vu tranquillement les services aux entreprises, car le contrat y est fixé de manière rigide. Par conséquent, cette deuxième règle pour développer des projets IoT est d'isoler les services et d'utiliser les contrats.Le rapport était encore beaucoup plus intéressant: simulation, test de charge, et en général, je vous conseille de voir ce rapport.
Dans la troisième partie, je vais parler d'un modèle de simulation, restez à l'écoute!