Cet article a été traduit avant le cours de développeur Python .
La narration est l'une des compétences les plus importantes pour les professionnels de l'analyse de données. Pour communiquer des idées et le faire de manière convaincante, vous devez établir une communication efficace. Dans cet article, nous présenterons 5 méthodes de visualisation qui vont au-delà de la compréhension classique et peuvent rendre votre Data Story plus esthétique et plus beau. Nous travaillerons avec la bibliothèque graphique Plotly en Python (elle est également disponible en R), qui vous permet de créer des diagrammes animés et interactifs avec un minimum d'effort.Ce qui est bon à Plotly
Les graphiques complot peuvent être facilement intégrés dans divers environnements: ils fonctionnent bien dans les blocs-notes jupyter, ils peuvent être intégrés dans un site Web, et ils sont également entièrement intégrés à Dash - un excellent outil pour créer des tableaux de bord et des applications analytiques.Commençons
Si vous n'avez pas déjà installé complotement, vous pouvez le faire avec la commande suivante:pip install plotly
Super, maintenant vous pouvez continuer!1. Animations
Notre travail est souvent lié à des données temporelles, par exemple, lorsque nous considérons l'évolution d'une métrique particulière. L'animation en mode graphique est un outil génial qui permet de refléter l'évolution des données au fil du temps avec une seule ligne de code.
import plotly.express as px
from vega_datasets import data
df = data.disasters()
df = df[df.Year > 1990]
fig = px.bar(df,
y="Entity",
x="Deaths",
animation_frame="Year",
orientation='h',
range_x=[0, df.Deaths.max()],
color="Entity")
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
title_text='Evolution of Natural Disasters',
showlegend=False)
fig.update_xaxes(title_text='Number of Deaths')
fig.update_yaxes(title_text='')
fig.show()
Presque n'importe quel graphique peut être animé si vous avez une variable qui vous aide à filtrer par le temps. Exemple d'animation de nuage de points:import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(
df,
x="gdpPercap",
y="lifeExp",
animation_frame="year",
size="pop",
color="continent",
hover_name="country",
log_x=True,
size_max=55,
range_x=[100, 100000],
range_y=[25, 90],
)
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)')
2. Graphiques Sunburst
Les graphiques Sunburst sont un excellent moyen de visualiser un groupe par opération . Si vous souhaitez diviser la quantité de données disponible en une ou plusieurs variables catégorielles, utilisez le graphique sunburst.Supposons que nous devions obtenir la distribution des pourboires par sexe et heure. Ainsi, nous pouvons utiliser le groupe par opérateur deux fois et visualiser facilement les données reçues afin de ne pas voir la sortie de table habituelle.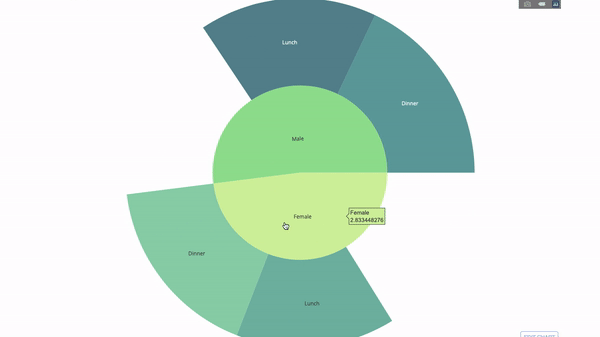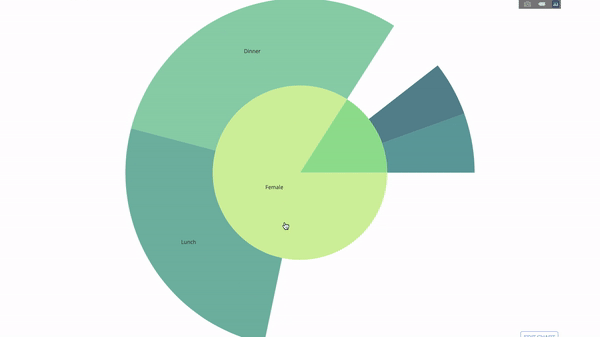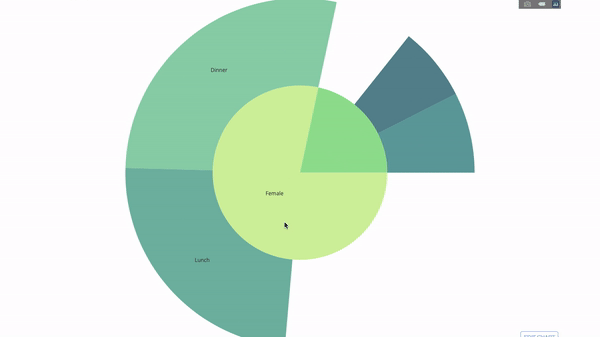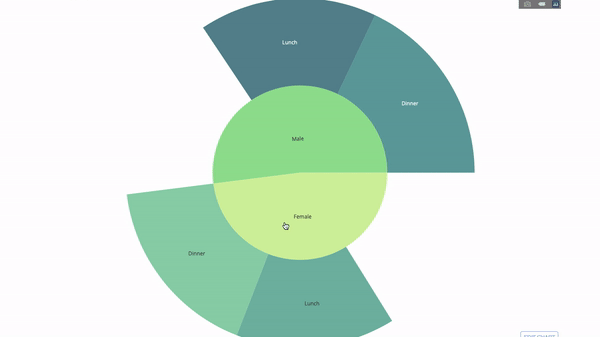 Le diagramme est interactif, vous pouvez cliquer sur les catégories et visualiser chaque catégorie individuellement. Tout ce que vous avez à faire est de décider de ces catégories, de réfléchir à la hiérarchie entre elles (argument
Le diagramme est interactif, vous pouvez cliquer sur les catégories et visualiser chaque catégorie individuellement. Tout ce que vous avez à faire est de décider de ces catégories, de réfléchir à la hiérarchie entre elles (argumentparentsdans le code) et attribuez les valeurs appropriées, qui dans notre cas seront la sortie du groupe par les opérateurs .import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
Ajoutons maintenant un autre niveau de hiérarchie: pour ce faire, nous ajouterons le résultat d'un autre groupe par , à partir duquel nous obtiendrons trois catégories supplémentaires.
pour ce faire, nous ajouterons le résultat d'un autre groupe par , à partir duquel nous obtiendrons trois catégories supplémentaires.import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri ', 'Sat ', 'Sun ', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
3. Catégories parallèles
Un autre bon moyen de visualiser les relations entre les catégories est avec ce tableau de catégories parallèle. Vous pouvez faire glisser, sélectionner et obtenir des valeurs lors de vos déplacements, ce qui est idéal pour les présentations.
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df['Genre_id'] = df.Major_Genre.factorize()[0]
fig = px.parallel_categories(
df,
dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'],
color="Genre_id",
color_continuous_scale=px.colors.sequential.Emrld,
)
fig.show()
4. Coordonnées parallèles
Un diagramme de coordonnées parallèles est une version développée du graphique ci-dessus. Ici, chaque partie du graphique reflète une observation. Il s'agit d'un bon outil pour détecter les valeurs aberrantes (flux uniques isolés du reste des données), les grappes, les tendances et les données redondantes (par exemple, si deux variables ont les mêmes valeurs pour toutes les observations, elles se situeront sur une ligne horizontale, ce qui indique la présence de redondance).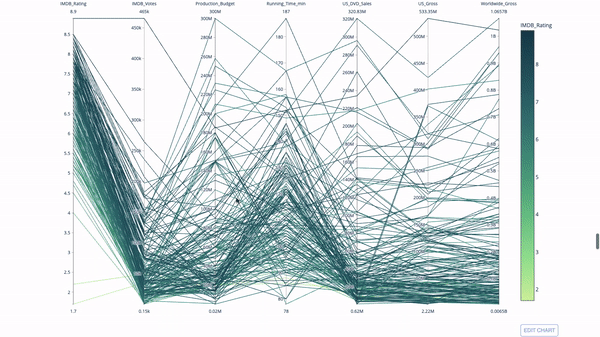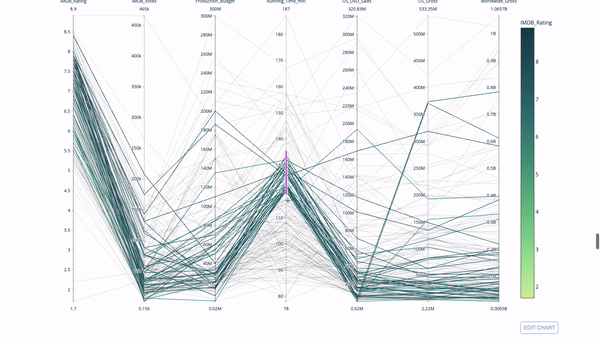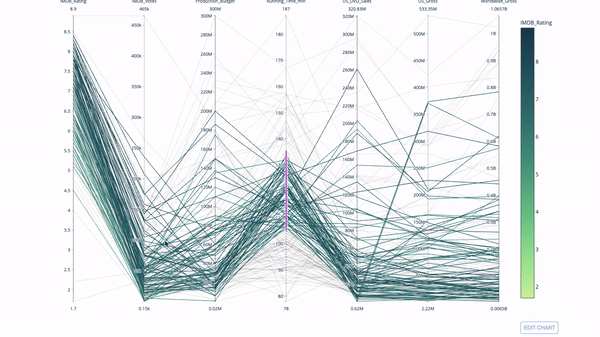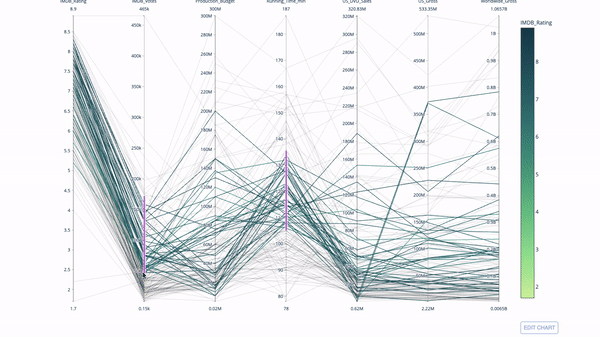
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df['Genre_id'] = df.Major_Genre.factorize()[0]
fig = px.parallel_coordinates(
df,
dimensions=[
'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min',
'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales'
],
color='IMDB_Rating',
color_continuous_scale=px.colors.sequential.Emrld)
fig.show()
5. Graphiques, capteurs et indicateurs
 Des diagrammes de capteurs sont nécessaires pour l'esthétique. Ils sont un bon moyen de signaler les indicateurs de réussite ou de performance et de les relier à votre objectif.
Des diagrammes de capteurs sont nécessaires pour l'esthétique. Ils sont un bon moyen de signaler les indicateurs de réussite ou de performance et de les relier à votre objectif. Les indicateurs seront très utiles dans le contexte des affaires et du conseil. Ils complètent les effets visuels avec du texte qui capte l'attention du public et diffuse des indicateurs de croissance au public.
Les indicateurs seront très utiles dans le contexte des affaires et du conseil. Ils complètent les effets visuels avec du texte qui capte l'attention du public et diffuse des indicateurs de croissance au public.import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
title = {'text': "Success Metric"},
mode = "number+delta",
value = 300,
delta = {'reference': 160}))
fig.show()
fig = go.Figure(go.Indicator(
title = {'text': "Success Metric"},
mode = "delta",
value = 40,
delta = {'reference': 160}))
fig.show()
C'est tout!
J'espère que vous trouverez quelque chose d'utile pour vous. Restez à la maison, soyez en sécurité, travaillez de manière productive.
En savoir plus sur le cours.