Salut tout le monde, je m'appelle Fedor Indukaev, je travaille comme analyste chez Yandex. Aujourd'hui, je veux vous parler de la tâche de visualiser les ensembles qui se croisent et du package Python open source que j'ai créé pour le résoudre. Au cours de ce processus, nous apprendrons comment les diagrammes de Venn et d'Euler diffèrent, nous familiariserons avec le service de distribution des commandes et toucherons tangentiellement à un domaine scientifique comme la bioinformatique. Nous passerons du simple au plus complexe. Aller!De quoi s'agit-il et pourquoi est-il nécessaire?
Presque tous ceux qui étaient engagés dans une analyse exploratoire des données ont dû chercher au moins une fois une réponse à des questions de ce type:- Il existe un ensemble de données avec plusieurs variables binaires indépendantes. Lesquels d'entre eux se retrouvent souvent ensemble?
- Il existe plusieurs tables avec des objets de même nature qui ont des ID. Comment les ensembles d'ID de différentes tables sont-ils liés - soit chaque table a son propre ID, soit la même dans toutes les tables, soit les ensembles diffèrent, mais seulement légèrement?
- Il existe plusieurs espèces. Quels organismes possèdent des ensembles similaires de gènes ou de protéines?
- Comment tracer comme un graphique à secteurs si les catégories se chevauchent? (Certes, cela ne devient pas un problème pour tout le monde: voir les pourcentages dans la figure ci-dessous.)
Toutes ces questions peuvent être réduites à la même formulation. Cela ressemble à ceci: quelques ensembles finis sont donnés, se croisant peut-être, et nous devons évaluer leur position relative - c'est-à-dire comprendre comment exactement ils se croisent.Nous nous concentrerons sur les visualisations et les outils logiciels pour aider à résoudre ce problème.diagrammes de Venn
Ces dessins avec deux ou trois cercles, je pense, sont familiers à tous et ne nécessitent pas d'explication:Une caractéristique du diagramme de Venn est qu'il est statique. Les chiffres y sont égaux et situés symétriquement. La figure montre toutes les intersections possibles, même si la plupart d'entre elles sont en fait vides. Ces diagrammes conviennent pour illustrer des concepts abstraits ou des ensembles dont les dimensions exactes sont inconnues ou sans importance. Les informations de base ici ne sont pas contenues dans le calendrier, mais dans les signatures.
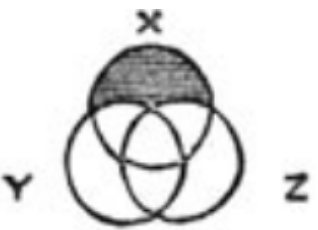 C'est ainsi qu'ils ont été conçus par John Venn, mathématicien et philosophe anglais. Dans son article de 1880il a proposé des diagrammes pour afficher graphiquement des propositions logiques. Par exemple, l'énoncé «tout X est soit Y soit Z» donne un diagramme à droite (illustration tirée de l'article original). La zone qui ne satisfait pas à l'énoncé est ombrée de noir: les X qui ne sont ni Y ni Z. Le message principal de l'article est que les dessins statiques sans varier la forme et la disposition des figures sont mieux adaptés à la logique que les diagrammes d'Euler dynamiques, qui sont discutés ira ci-dessous.Il est clair que dans l'analyse des données, la portée des diagrammes de Venn est limitée. Ils ne donnent que des informations qualitatives, mais non quantitatives et ne reflètent ni la taille ni même le vide des intersections. Si cela ne vous arrête pas, vous avez à votre disposition le paquet venn , qui construit de tels diagrammes pour ensembles. Pour chaque il y a une ou deux images typiques, et seules les signatures différeront:Si nous voulons quelque chose de plus dynamique en fonction des données, vous devriez faire attention à une autre approche: les diagrammes d'Euler.
C'est ainsi qu'ils ont été conçus par John Venn, mathématicien et philosophe anglais. Dans son article de 1880il a proposé des diagrammes pour afficher graphiquement des propositions logiques. Par exemple, l'énoncé «tout X est soit Y soit Z» donne un diagramme à droite (illustration tirée de l'article original). La zone qui ne satisfait pas à l'énoncé est ombrée de noir: les X qui ne sont ni Y ni Z. Le message principal de l'article est que les dessins statiques sans varier la forme et la disposition des figures sont mieux adaptés à la logique que les diagrammes d'Euler dynamiques, qui sont discutés ira ci-dessous.Il est clair que dans l'analyse des données, la portée des diagrammes de Venn est limitée. Ils ne donnent que des informations qualitatives, mais non quantitatives et ne reflètent ni la taille ni même le vide des intersections. Si cela ne vous arrête pas, vous avez à votre disposition le paquet venn , qui construit de tels diagrammes pour ensembles. Pour chaque il y a une ou deux images typiques, et seules les signatures différeront:Si nous voulons quelque chose de plus dynamique en fonction des données, vous devriez faire attention à une autre approche: les diagrammes d'Euler.Graphiques d'Euler
Contrairement aux diagrammes de Venn, la forme et la position des figures sur le plan sont choisies ici pour montrer la relation des ensembles ou des concepts. Si une intersection est vide, les chiffres ne se chevauchent pas autant que possible, comme dans la figure sur les plantes et les animaux.Veuillez noter que le dessin sur la question dans la conférence est différent des deux autres. Il est important non seulement la position des figures, mais aussi la taille des intersections - tout l'humour y est enfermé.Cette idée peut être utilisée pour notre tâche. Prenez deux ou trois ensembles et dessinez des cercles avec des zones proportionnelles à la taille de ces ensembles. Et puis nous essaierons d'arranger les cercles sur le plan afin que les zones de chevauchement soient également proportionnelles à la taille des intersections.C'est exactement ce que fait le package (malgré son nom)matplotlib-venn : dessiner deux ensembles avec des proportions exactes est facile. Mais déjà à trois heures, la méthode peut échouer. Supposons, par exemple, que l'un des trois ensembles soit exactement l'intersection des deux autres:L'image ne semble pas bonne, une zone étrange est apparue avec le numéro 0. Mais il n'y a rien à surprendre, car l'intersection de deux cercles ne peut pas être représentée comme un cercle.Et voici un exemple encore plus déprimant: deux ensembles et leur différence symétrique (union moins intersection):Cela s'est avéré être quelque chose de complètement étrange: faites attention au nombre de zéros!Le premier exemple peut toujours être enregistré si nous prenons des rectangles au lieu de cercles (l'intersection des rectangles est également un rectangle), tandis que le second nécessite au moins des formes non convexes. Eh bien, plus de trois ensembles, ce package ne prend pas en charge en principe.Je ne connais pas d'autres outils publics pour Python qui développent l'approche Euler-Venn, et l'histoire de mes propres expériences ira plus loin. Mais avant de continuer, je vais faire une petite digression pour expliquer pourquoi j'ai même pris la tâche de visualiser des décors.
deux ensembles avec des proportions exactes est facile. Mais déjà à trois heures, la méthode peut échouer. Supposons, par exemple, que l'un des trois ensembles soit exactement l'intersection des deux autres:L'image ne semble pas bonne, une zone étrange est apparue avec le numéro 0. Mais il n'y a rien à surprendre, car l'intersection de deux cercles ne peut pas être représentée comme un cercle.Et voici un exemple encore plus déprimant: deux ensembles et leur différence symétrique (union moins intersection):Cela s'est avéré être quelque chose de complètement étrange: faites attention au nombre de zéros!Le premier exemple peut toujours être enregistré si nous prenons des rectangles au lieu de cercles (l'intersection des rectangles est également un rectangle), tandis que le second nécessite au moins des formes non convexes. Eh bien, plus de trois ensembles, ce package ne prend pas en charge en principe.Je ne connais pas d'autres outils publics pour Python qui développent l'approche Euler-Venn, et l'histoire de mes propres expériences ira plus loin. Mais avant de continuer, je vais faire une petite digression pour expliquer pourquoi j'ai même pris la tâche de visualiser des décors.Quelques mots sur l'API pour construire des itinéraires optimaux
Comme je l'ai dit, notre département s'occupe du routage Yandex. L'un de nos services aide les magasins en ligne, les services de livraison et toute entreprise dont l'activité comprend la logistique à construire des itinéraires optimaux pour le transport.Les clients interagissent avec le service en envoyant des demandes d'API. Chaque demande contient une liste de commandes (points de livraison) avec coordonnées, intervalles de livraison, etc., ainsi qu'une liste de machines qui doivent livrer des commandes. Notre algorithme digère toutes ces données et produit des itinéraires optimaux en tenant compte des embouteillages, de la capacité des voitures et bien plus encore.Nous avons des centaines, pas des millions de clients, comme les services B2C populaires de Yandex. Par conséquent, le bonheur de chaque client est particulièrement important pour nous, en plus, il est possible de lui accorder plus d'attention et de plonger plus profondément dans ses tâches. Pour cela, en particulier, il est utile d'avoir des outils pour vous aider à comprendre quelles demandes le client nous envoie.Je vais vous donner un exemple. Supposons que, en une journée, 24 demandes aient été reçues de Romashka. Cela peut signifier que:- Ils travaillent à travers le pays et ont construit 24 itinéraires pour 24 entrepôts.
- Il n'y a qu'un seul entrepôt, mais le client reçoit constamment de nouvelles commandes. Pour les prendre en compte, vous devez mettre à jour les itinéraires toutes les heures.
- Les demandes du client sont formées avec une erreur à cause de laquelle il n'a pas pu obtenir une bonne solution à une seule tâche 24 fois de suite.
A priori, on ne sait pas vraiment ce qui s'est réellement passé. Mais si nous pouvons comparer rapidement 24 ensembles d'ID de commande, la situation deviendra immédiatement claire. S'ils ne se croisent pas du tout - c'est le premier cas (24 entrepôts). Si les ensembles circulent de l'un à l'autre, le second (mise à jour programmée des itinéraires). Eh bien, 24 ensembles presque identiques sont un signe possible que le client a besoin d'aide.Simplifiez la tâche: des cercles aux rayures
Pendant un certain temps, j'ai utilisé le paquet matplotlib-venn, mais la restriction des ensembles «deux ans et demi», bien sûr, était frustrante. En réfléchissant à différentes approches du problème, j'ai décidé d'essayer de passer des cercles et généralement des primitives bidimensionnelles à des rayures horizontales unidimensionnelles. Les intersections peuvent alors être représentées verticalement superposées comme ceci:Les dimensions linéaires sont mieux perçues par l'œil que les carrés, la trigonométrie complexe n'est pas nécessaire pour la construction et l'espacement des ensembles le long de l'axe Y rend le graphique moins surchargé. De plus, notre premier exemple infructueux (deux ensembles et leur intersection comme troisième) s'améliore de lui-même:Le problème avec la différence symétrique est toujours là. Mais nous le traiterons comme Alexandre le Grand avec le nœud gordien: coupons, si nécessaire, l'un des ensembles en deux parties:L'ensemble rouge est représenté en deux bandes au lieu d'une, mais il n'y a rien de mal à cela. Les deux sont à la même hauteur et ont la même couleur, de sorte que leur unité est bien lue visuellement.Il est facile de vérifier que de cette manière, avec le respect exact des proportions, trois ensembles quelconques peuvent être représentés. Ainsi, le problème pour égal à 2 ou 3 peut être considéré comme résolu.Un autre avantage de cette approche est qu'elle est facile à appliquer à n'importe quel nombre d'ensembles, ce que nous ferons très bientôt. Il suffit de résoudre non pas un, mais un nombre arbitraire de sauts de ligne. Mais d'abord, un peu de combinatoire simple.Un peu d'arithmétique
Regardons le diagramme de Venn avec trois cercles et calculons combien de zones les cercles se divisent:Chaque zone est déterminée selon qu'elle se trouve à l'intérieur ou à l'extérieur de chacun des trois cercles, mais la zone externe est superflue. Total nous obtenons . D'autres emplacements des trois cercles peuvent donner moins de zones jusqu'à 1, lorsque tous les cercles coïncident.En transférant cet argument des cercles aux ensembles, nous obtenons que tout ensembles ne se cassent pas plus de ces pièces élémentaires. Il est important que chacune de ces pièces soit entièrement incluse ou non entièrement incluse dans aucun de ces ensembles. Dans nos nouveaux diagrammes, les colonnes sont de telles pièces élémentaires.Plus d'ensembles!
Donc, nous voulons généraliser ces régimes au cas :Pour ensembles, nous obtenons une grille avec lignes et colonnes, comme nous venons de le calculer. Il reste à parcourir chaque ligne et à remplir les cellules correspondant aux parties élémentaires incluses dans cet ensemble.Pour illustrer, prenez un exemple de modèle à cinq ensembles:programming_languages = {'python', 'r', 'c', 'c++', 'java', 'julia'}
geographic_places = {'java', 'buffalo', 'turkey', 'moscow'}
letters = {'a', 'r', 'c', 'i', 'z'}
human_names = {'robin', 'julia', 'alice', 'bob', 'conrad'}
animals = {'python', 'buffalo', 'turkey', 'cat', 'dog', 'robin'}
En agissant comme décrit ci-dessus, nous obtenons la figure suivante:Il se lit mal: il y a trop de lacunes dans les lignes, tous les ensembles sont coupés en chou. Mais comme nous n'aimons pas les pauses, pourquoi ne pas définir directement la tâche de les minimiser? Après tout, l'ordre des colonnes est insignifiant, rien ne nous empêche de les réorganiser comme nous voulons. Nous arrivons à ce problème: trouver une permutation des colonnes d'une matrice donnée de zéros et de celles avec un nombre minimum d'écarts entre les unités dans les lignes.Comme on m'a dit plus tard, c'est pratiquement la tâche d'un vendeur itinérant dans la métrique Hamming ; c'est NP-complet . S'il y a peu de colonnes (disons pas plus de 12), alors vous pouvez trouver la permutation nécessaire par une recherche exhaustive, sinon vous devez recourir à certaines heuristiques.Nous appliquons un algorithme simple et gourmand. Appelons la similitude de deux colonnes le nombre de positions auxquelles les valeurs de ces colonnes coïncident. Prenez les deux colonnes les plus similaires, assemblez-les. Ensuite, nous allons construire avec impatience la séquence des deux côtés de cette paire. Parmi les colonnes restantes, nous trouvons celle qui ressemble le plus à l'une des deux, attachez-la - et ainsi de suite avec le reste des colonnes.Voici les chiffres avant et après l'application de l'algorithme:C'est devenu beaucoup mieux. C'est à ce stade que j'ai senti que quelque chose d'utile allait sortir. Après avoir expérimenté, j'ai remarqué que l'algorithme a tendance à coller aux minima locaux. Il a été possible de bien traiter cela avec une simple randomisation: nous parasitons légèrement la similitude des colonnes, exécutons l'algorithme, répétons 1000 fois, choisissons la meilleure des 1000 solutions.Le résultat est déjà tout à fait un outil de travail, mais vous pouvez y ajouter des informations plus utiles. J'ai fait deux graphiques supplémentaires: les tailles des ensembles originaux sont indiquées à droite, et celle du haut pour chaque intersection montre le nombre de nos ensembles dans lesquels elle se trouve. En fait, ce n'est rien de plus que la somme de notre matrice binaire en lignes (à droite) et en colonnes (en haut):J'ai également ajouté l'option de classer les ensembles eux-mêmes (c'est-à-dire les lignes) selon le même principe que les colonnes: en minimisant le nombre de ruptures. En conséquence, des ensembles similaires sont regroupés:Application au travail
Naturellement, tout d'abord, j'ai commencé à utiliser le nouvel outil pour la tâche pour laquelle il a été créé: examiner les demandes des clients pour notre API. Les résultats m'ont plu. Ainsi, par exemple, la journée de travail d'un des clients ressemblait. Chaque ligne est une demande adressée à l'API (plusieurs ID des commandes qui y sont incluses), et la signature au milieu est l'heure d'envoi des demandes:Toute la journée à la vue. À 10h49, une logistique client avec un intervalle de 23 secondes a envoyé deux demandes identiques avec 129 commandes. De 11 h 25 à 15 h 53, il y a eu trois demandes avec un ensemble différent de 152 commandes. À 16 h 43, une troisième demande unique est arrivée avec 114 commandes. Pour résoudre cette demande, le logisticien a ensuite appliqué quatre modifications manuelles (cela peut être fait via notre interface utilisateur).Et voici à quoi ressemble une journée idéale: toutes les tâches indépendantes ont été résolues une fois, aucune correction ou sélection de paramètres n'a été requise:Et voici un exemple d'un client envoyant des demandes toutes les 15-30 minutes pour prendre en compte les commandes reçues en temps réel:Même sur 50 ensembles, l'algorithme a clairement révélé la structure cachée dans les données. Vous pouvez voir comment les anciennes commandes ont été supprimées des demandes et remplacées par de nouvelles lors de leur exécution.En un mot, j'ai complètement réussi à clore mon besoin de travail avec l'outil créé.Banane pour l'échelle (pas vraiment)
Pendant que j'étudiais les approches existantes, je suis tombé plusieurs fois sur un dessin de la revue Nature , qui compare les génomes du bananier et de cinq autres plantes:Remarquez comment les tailles des régions sont liées aux 13 et 149 éléments (indiqués par des flèches): la seconde est plusieurs fois plus petite. Il n'est donc pas question de proportionnalité.Bien sûr, je voulais essayer ces données, mais le résultat ne m'a pas plu:Le graphique semble désordonné. La raison en est que, premièrement, presque toutes les intersections (62 sur 63 possibles) ne sont pas vides, et deuxièmement, leurs tailles diffèrent de trois ordres de grandeur. En conséquence, les annotations numériques deviennent très encombrées.Pour rendre mon outil pratique pour de telles données, j'ai ajouté plusieurs paramètres. L'un vous permet d'aligner partiellement les largeurs de colonne, l'autre masque les annotations si la largeur de colonne est inférieure à une valeur spécifiée.Cette option est assez bien lue, mais pour cela, j'ai dû sacrifier la proportionnalité exacte de la taille.En fin de compte, en faisant attention au domaine de la bioinformatique, j'avais raison. J'ai posté un article sur mon outil sur Reddit en r / visualisation , r / datascience et r / bioinformatique , c'est dans ce dernier qu'il a été le mieux reçu, les critiques étaient vraiment enthousiastes.Conversion de produits
En fin de compte, j'ai réalisé que c'était un bon outil qui pouvait être utile à beaucoup. Par conséquent, l'idée est née de le transformer en un package open source complet. Bien sûr, le consentement des dirigeants était nécessaire, mais les gars non seulement ne me dérangeaient pas, mais me soutenaient également, pour lequel je les remercie beaucoup.Travaillant principalement le week-end, j'ai commencé à apporter progressivement le code à la commercialisation, à écrire des tests et à gérer le système de packages en Python. Il s'agit de mon premier projet de ce type, il a donc fallu plusieurs mois.Trouver une bonne réputation était aussi une tâche difficile, et je m'en suis mal sortie. Nom sélectionné (super venn) ne peut pas être qualifié de réussi, car tout le sel des diagrammes de Venn est dans leur nature statique, mais, au contraire, j'ai essayé de montrer avec précision les dimensions réelles. Mais quand je m'en suis rendu compte, le projet était déjà publié et il était trop tard pour changer de nom.Analogues
Bien sûr, je n'étais pas le premier à utiliser cette approche de la visualisation des décors: l'idée, en général, se trouve à la surface. Il existe deux applications Web similaires en accès libre: RainBio et Linear Diagram Generator , la seconde utilise exactement le même principe que le mien. (Les auteurs ont également écrit un article sur 40 pages , qui comparait expérimentalement ce qui est mieux perçu - lignes horizontales ou verticales, fines ou épaisses, etc. Il me semblait même que l'article était primordial pour eux, et l'outil lui-même n'était qu'un ajout .)Pour comparer ces deux applications avec mon package, nous utilisons à nouveau l'exemple avec des mots. Vous pouvez décider par vous-même quelle option est plus lisible et informative.RainbioGénérateur de diagramme linéairesupervennD'autres approches
On ne peut que mentionner le projet UpSet , qui existe en tant qu'application web et packages pour R et Python. Le principe de base peut être compris en regardant l'affichage des données du génome de la banane. Le graphique est rogné à droite, seules 30 intersections sur 62 sont affichées:Fait intéressant, si vous utilisez supervenn pour trier les colonnes par largeur et les rendre identiques en utilisant l'option d'alignement de largeur, vous obtiendrez presque la même chose, bien que ce ne soit pas immédiatement perceptible. Il ne manque que des lignes verticales avec des tailles d'intersection, au lieu d'elles, il n'y a que des chiffres en bas du graphique:Lors de l'écriture de ce texte, j'ai essayé d'utiliser la version Python d'UpSet, mais j'ai constaté que le package n'avait pas été mis à jour depuis 2016, la documentation ne décrit en aucune façon le format d'entrée et le scénario de test se bloque avec une erreur. La version Web fonctionne, elle a de nombreuses fonctions auxiliaires utiles, mais travailler avec elle est assez difficile en raison de la manière compliquée de saisir des données.Enfin, un aperçu intéressant des techniques de visualisation d'ensemble est disponible en ligne . Tous ne sont pas implémentés comme des outils logiciels. Voici quelques photos pour attirer votre attention:J'étais particulièrement intéressé par la méthode des ensembles de bulles (ligne du bas), qui vous permet d'afficher de petits ensembles au-dessus d'une disposition donnée d'éléments sur un plan. Cela peut être pratique, par exemple, lorsque les éléments sont attachés à l'axe du temps (a) ou à la carte (b). Jusqu'à présent, cette méthode n'a été implémentée qu'en Java et JavaScript (les liens sont sur la page des auteurs), et ce serait génial si quelqu'un entreprenait de la porter sur Python.J'ai envoyé des lettres avec une brève description du projet aux auteurs d'Upset et de la revue et j'ai reçu de bonnes critiques. Deux d'entre eux ont même promis d'inclure supervenn dans leurs conférences sur la visualisation des décors.Conclusion
Si vous souhaitez utiliser le package, il est disponible sur GitHub et dans PyPI: pip install supervenn . Je serai reconnaissant pour tout commentaire sur le code et l'utilisation du package, pour les idées et les critiques. Je serai particulièrement heureux de lire les recommandations sur la façon d'améliorer l'algorithme de permutation de colonnes pour les grands , et des conseils sur la façon d'écrire des tests pour les fonctions de cartographie.Merci pour l'attention!Références
1. John Venn. Sur la représentation schématique et mécanique des propositions et des raisonnements . The London, Edinburgh and Dublin Philosophical Magazine, juillet 1880.2. J.-B. Lamy et R. Tsopra. RainBio: Visualisation proportionnelle de grands ensembles en biologie . Transactions IEEE sur la visualisation et l'infographie, doi: 10.1109 / TVCG.2019.2921544.3. Peter Rodgers, Gem Stapleton et Peter Chapman. Visualisation des ensembles avec des diagrammes linéaires . ACM Transactions on Computer Human Interaction 22 (6) pp. 27: 1-27: 39 septembre 2015. doi: 10.1145 / 2810012.4. Alexander Lex, Nils Gehlenborg, Hendrik Strobelt, Romain Vuillemot, Hanspeter PfisterUpSet: Visualisation des ensembles d'intersection. Transactions IEEE sur la visualisation et l'infographie (InfoVis'14), 2014.5. Bilal Alsallakh, Luana Micallef, Wolfgang Aigner, Helwig Hauser, Silvia Miksch et Peter Rodgers. L'état de l'art de la visualisation d'ensemble . Forum d'infographie. Volume 00 (2015), numéro 0 pp. 1–27 10.1111 / cgf.12722.6. Christopher Collins, Gerald Penn et Sheelagh Carpendale. Ensembles de bulles: révélation des relations entre les ensembles et les isocontours par rapport aux visualisations existantes . IEEE Trans. sur la visualisation et l'infographie (Proc. de la Conf. IEEE sur la visualisation de l'information), vol. 15, iss. 6, pp. 1009−1016, 2009.