Bonjour à tous! Comme vous le savez déjà, chez SE, nous sommes engagés dans la reconnaissance de texte (et pas seulement) sur différents documents. Aujourd'hui, nous aimerions parler d'un autre problème lors de la reconnaissance de texte sur des arrière-plans complexes - la reconnaissance des espaces. En général, nous parlerons du nom sur les cartes bancaires, mais d'abord, un exemple avec un "fantôme" de la lettre. Comme vous pouvez le voir, ici, à droite de D, les distorsions et l'arrière-plan ont formé un assez clair. De plus, si vous montrez cette cellule séparément de tout le reste, la personne (ou réseau de neurones) dira sûrement qu'il y a une lettre.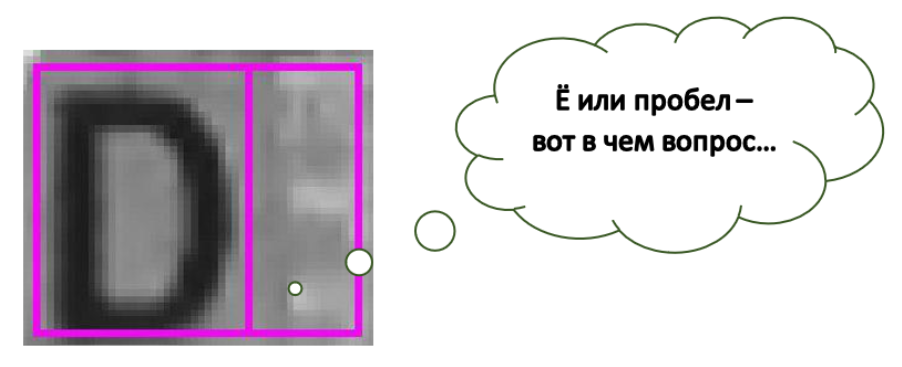 Comme vous pouvez le voir sur l'image, nous travaillons sur l'image originale avec des arrière-plans complexes, donc nos espaces sont très divers. Ils viennent dans des motifs, des logos et parfois du texte. Par exemple, VISA ou MAESTRO sur des cartes. Et nous nous intéressons à ces «espaces complexes», et pas seulement aux rectangles blancs. Et dans nos systèmes, nous considérons précisément des rectangles de symboles coupés séparément [1].
Comme vous pouvez le voir sur l'image, nous travaillons sur l'image originale avec des arrière-plans complexes, donc nos espaces sont très divers. Ils viennent dans des motifs, des logos et parfois du texte. Par exemple, VISA ou MAESTRO sur des cartes. Et nous nous intéressons à ces «espaces complexes», et pas seulement aux rectangles blancs. Et dans nos systèmes, nous considérons précisément des rectangles de symboles coupés séparément [1].Et quelle est la difficulté?
Un espace est un symbole sans signes spéciaux. Sur des arrière-plans complexes, comme dans une image, un espace coupé séparément peut être difficile à distinguer même pour une personne.D'un autre côté, par essence, un espace est différent des autres personnages. Si ABIA est reconnu dans le nom au lieu de ASIA, il y a une chance de le corriger avec un post-traitement. Mais, si une IA survient, il est peu probable que quelque chose aide.Méthodes non utilisées par nous
Souvent, les espaces sont filtrés à l'aide de statistiques calculées à partir de l'image. Par exemple, considérez la valeur absolue moyenne du gradient dans l'image ou la variance des intensités des pixels et divisez les images en espaces et lettres par la valeur de seuil. Cependant, comme le montrent les graphiques, ces méthodes ne conviennent pas aux images grises avec des arrière-plans complexes. Et en raison de la corrélation explicite des valeurs, même une combinaison de ces méthodes ne fonctionnera pas.La binarisation préférée de tous n'aidera pas non plus. Par exemple, dans cette image:Alors, comment améliorer la reconnaissance?
Puisqu'une personne a besoin d'un environnement d'un espace pour la voir, il est logique que le réseau affiche au moins deux caractères voisins. Nous ne voulons pas augmenter la contribution du réseau de reconnaissance, qui, en général, fonctionne bien (et reconnaît de nombreuses lacunes). Nous aurons donc un autre réseau - plus simple. Le nouveau réseau prédira ce qu'il y a dans l'image: deux espaces, deux lettres, un espace et une lettre, ou une lettre et un espace. En conséquence, un tel réseau est utilisé conjointement avec un réseau de reconnaissance. L'image montre les architectures utilisées: à gauche, l'architecture du réseau de reconnaissance, à droite, l'architecture du réseau proposé. Le réseau de reconnaissance fonctionne sur une image à un caractère et la nouvelle fonctionne sur une image à double largeur contenant deux caractères adjacents.Un examen?
Pour les tests, nous avions 4 320 lignes avec des noms contenant 130 149 caractères, dont 68 246 espaces. Pour commencer, nous avons deux méthodes. La méthode de base: nous coupons une chaîne en caractères et reconnaissons chaque caractère individuellement. Nouvelle méthode: nous avons également coupé une chaîne de caractères, trouvé tous les espaces avec un nouveau réseau et reconnu les caractères restants comme normaux. Le tableau montre que la qualité de reconnaissance des espaces, ainsi que la qualité globale, augmente, mais la qualité de reconnaissance des lettres s'affaisse légèrement.Cependant, notre réseau central reconnaît également les espaces (bien que pire que nous le souhaiterions). Et nous pouvons essayer d'en profiter. Regardons les erreurs des deux méthodes. Et aussi - sur la qualité de la nouvelle méthode basée sur les erreurs de base et vice versa.Pour la méthode de base:Pour la nouvelle méthode:D'après les trois derniers tableaux, on peut voir que pour améliorer le système, il vaut la peine d'utiliser une combinaison équilibrée de notations de réseau. Dans le même temps, la qualité caractère par caractère est intéressante, mais ligne par ligne est plus intéressante.Conclusion
L'espace - un gros problème sur le chemin de la qualité à 100% de la reconnaissance des documents =) L'exemple des espaces montre clairement combien il est important de regarder non seulement les caractères individuels, mais aussi leurs combinaisons. Cependant, ne saisissez pas immédiatement de l'artillerie lourde et découvrez des réseaux géants qui traitent des chaînes entières. Parfois, un autre petit réseau suffit.Ce message a été rédigé à l'aide de documents provenant d'un rapport de la Conférence européenne sur la modélisation ECMS 2015 (Bulgarie, Varna): Sheshkus, A. & Arlazarov, VL (2015). Détection de symboles spatiaux sur fond complexe à l'aide d'un contexte visuel.Liste des sources utilisées1. YS Chernyshova, AV Sheshkus et VV Arlazarov, «Cadre CNN en deux étapes pour la reconnaissance des lignes de texte dans les images capturées par une caméra», IEEE Access, vol. 8, pp. 32587-32600, 2020, DOI: 10.1109 / ACCESS.2020.2974051.