Ou la bonne vieille programmation dynamique sans ces réseaux de neurones.Il y a un an et demi, il m'est arrivé de participer à un concours d'entreprise (à des fins de divertissement) en écrivant un bot pour le jeu Lode Runner. Il y a 20 ans, j'ai résolu avec diligence tous les problèmes de programmation dynamique dans le cours correspondant, mais j'ai pratiquement tout oublié et je n'avais aucune expérience en programmation de robots de jeu. Je devais me souvenir de peu de temps, expérimenter en déplacement et marcher indépendamment sur le râteau. Mais, tout d'un coup, tout s'est très bien passé, alors j'ai décidé de systématiser le matériel et de ne pas noyer le lecteur avec matan.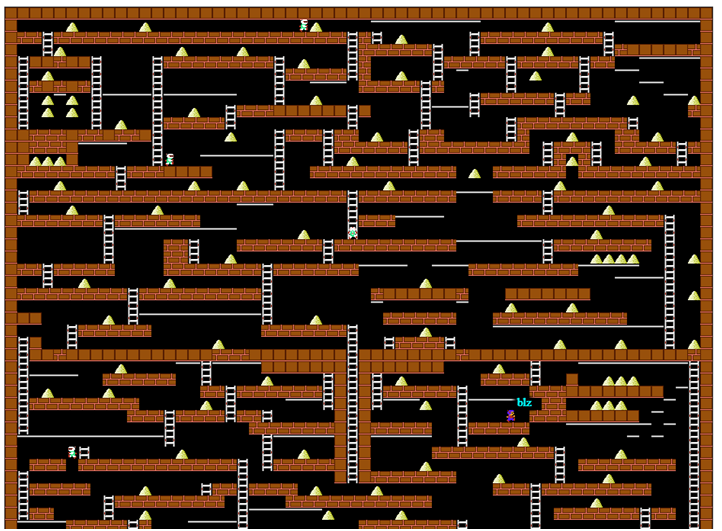 Écran de jeu du serveur de projet CodenjoyPour commencer, nous décrirons un peu les règles du jeu : le joueur se déplace horizontalement le long du sol ou à travers des tuyaux, sait monter et descendre les escaliers, tombe s'il n'y a pas de sol sous lui. Il peut également percer un trou à gauche ou à droite de lui-même, mais toutes les surfaces ne peuvent pas être percées - conditionnellement, un plancher «en bois» est possible, et le béton - non.Les monstres courent après le joueur, tombent dans les trous coupés et y meurent. Mais le plus important, le joueur doit collecter de l'or, pour le premier or collecté, il reçoit 1 point de profit, pour le N-ème, il reçoit N points. Après la mort, le profit total reste, mais pour le premier or, ils donnent à nouveau 1 point. Cela suggère que l'essentiel est de rester en vie aussi longtemps que possible, et de collecter de l'or est en quelque sorte secondaire.Comme il y a des endroits sur la carte que le joueur ne peut pas sortir de lui-même, un suicide gratuit a été introduit dans le jeu, ce qui a placé le joueur au hasard quelque part, mais a en fait interrompu tout le jeu - le suicide n'a pas interrompu la croissance de la valeur de l'or trouvé. Mais nous n'abuserons pas de cette fonctionnalité.Tous les exemples du jeu seront donnés dans un affichage simplifié, qui a été utilisé dans les journaux du programme:
Écran de jeu du serveur de projet CodenjoyPour commencer, nous décrirons un peu les règles du jeu : le joueur se déplace horizontalement le long du sol ou à travers des tuyaux, sait monter et descendre les escaliers, tombe s'il n'y a pas de sol sous lui. Il peut également percer un trou à gauche ou à droite de lui-même, mais toutes les surfaces ne peuvent pas être percées - conditionnellement, un plancher «en bois» est possible, et le béton - non.Les monstres courent après le joueur, tombent dans les trous coupés et y meurent. Mais le plus important, le joueur doit collecter de l'or, pour le premier or collecté, il reçoit 1 point de profit, pour le N-ème, il reçoit N points. Après la mort, le profit total reste, mais pour le premier or, ils donnent à nouveau 1 point. Cela suggère que l'essentiel est de rester en vie aussi longtemps que possible, et de collecter de l'or est en quelque sorte secondaire.Comme il y a des endroits sur la carte que le joueur ne peut pas sortir de lui-même, un suicide gratuit a été introduit dans le jeu, ce qui a placé le joueur au hasard quelque part, mais a en fait interrompu tout le jeu - le suicide n'a pas interrompu la croissance de la valeur de l'or trouvé. Mais nous n'abuserons pas de cette fonctionnalité.Tous les exemples du jeu seront donnés dans un affichage simplifié, qui a été utilisé dans les journaux du programme: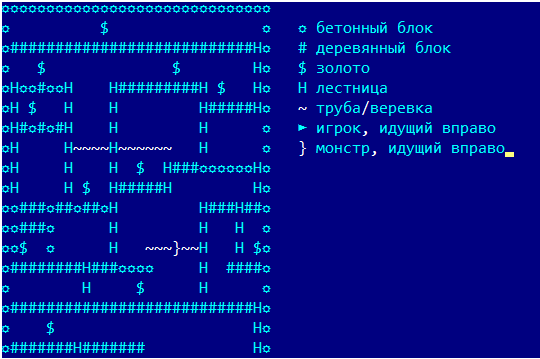
Un peu de théorie
Pour implémenter le bot en utilisant une sorte de mathématiques, nous devons définir une fonction objective qui décrit les réalisations du bot et lui trouver des actions qui le maximisent. Par exemple, pour la collecte d'or, nous obtenons +100, pour la mort -100500, donc aucune collecte d'or ne tuera la mort possible.Une question distincte, et sur quoi exactement déterminons-nous la fonction objective, c'est-à-dire Quel est l'état du jeu? Dans le cas le plus simple, les coordonnées du joueur suffisent, mais dans le nôtre tout est beaucoup plus compliqué:- coordonnées du joueur
- les coordonnées de tous les trous percés par tous les joueurs
- les coordonnées de tout l'or sur la carte (ou les coordonnées de l'or récemment mangé)
- les coordonnées de tous les autres joueurs
Ça a l'air effrayant. Par conséquent, simplifions un peu la tâche et jusqu'à ce que nous nous souvenions de l'or que nous mangeons (nous y reviendrons plus tard), nous ne nous souviendrons pas non plus des coordonnées des autres joueurs et monstres.Ainsi, l'état actuel du jeu est le suivant:- coordonnées du joueur
- coordonnées de tous les puits
Les actions des joueurs changent d'état d'une manière compréhensible:- Les commandes de mouvement modifient l'une des coordonnées correspondantes
- L'équipe de creusage de puits ajoute un nouveau puits
- Faire tomber un joueur sans support réduit la coordonnée verticale
- L'inaction du joueur debout sur le support ne change pas l'état
Maintenant, nous devons comprendre comment maximiser la fonction elle-même. L'une des méthodes classiques vénérables pour calculer le jeu N avance est la programmation dynamique. Il est impossible de se passer de formules, je vais donc les donner sous une forme simplifiée. Vous devrez d'abord introduire beaucoup de notation.Par souci de simplicité, nous conserverons le rapport de temps du mouvement actuel, c.-à-d. le mouvement actuel est t = 0.Nous dénotons l'état du jeu au cours de t par.Beaucoup de dénotera toutes les actions valides du bot (dans un état spécifique, mais pour plus de simplicité nous n'écrirons pas l'index d'état), via nous désignons une action spécifique sur le parcours t (nous omettons l'index).état Sous l'influence entre en état .Gagner lorsque l'action a est en état nous le désignons comme . Lors du calcul, nous supposons que si nous avons mangé de l'or, alors il est égal à G = 100, s'ils sont morts, alors D = -100500, sinon 0.Soitil s'agit de la fonction de gain pour le jeu optimal d'un bot qui est dans l'état x au temps t. Il nous suffit ensuite de trouver une action qui maximise.Maintenant, nous écrivons la première formule, qui est très importante et en même temps presque correcte:
Ou pour un moment arbitraire
Cela semble assez maladroit, mais le sens est simple - la solution optimale pour le mouvement actuel consiste en la solution optimale pour le mouvement suivant et le gain dans le mouvement actuel. C'est le principe d'optimalité formulé de manière tortueuse par Bellman. Nous ne savons rien des valeurs optimales à l'étape 1, mais si nous les connaissions, nous trouverions une action qui maximise la fonction en itérant simplement sur toutes les actions du bot. La beauté des relations de récurrence est que nous pouvons trouver, en lui appliquant le principe d'optimalité, en l'exprimant exactement dans la même formule par . Nous pouvons également facilement exprimer la fonction de paiement à n'importe quelle étape.Il semblerait que le problème soit résolu, mais ici nous sommes confrontés au problème que si à chaque étape nous devions trier 6 actions de joueurs, alors à l'étape N de récursivité nous devions trier 6 ^ N options, qui pour N = 8 est déjà un nombre assez décent ~ 1,6 millions de cas. D'un autre côté, nous avons des microprocesseurs gigahertz qui n'ont rien à faire, et il semble qu'ils feront complètement face à la tâche, et nous leur limiterons la profondeur de recherche avec exactement 8 mouvements.Et donc, notre horizon de planification est de 8 mouvements, mais où obtenir les valeurs? Et ici, nous venons juste avec l'idée que nous sommes en mesure d'analyser en quelque sorte les perspectives du poste, et de lui attribuer une certaine valeur en fonction de leurs plus hautes considérations. Laisser êtreoù ceci est fonction de la stratégie, dans la version la plus simple, ce n'est qu'une matrice à partir de laquelle nous sélectionnons la valeur en fonction des coordonnées géométriques du bot. On peut dire que les 8 premiers coups c'était une tactique, puis la stratégie commence. En fait, personne ne nous restreint dans le choix d'une stratégie, et nous y reviendrons plus tard, mais pour l'instant, afin de ne pas devenir comme un hibou d'une anecdote sur les lièvres et les hérissons, passons à la tactique.Schéma général
Et donc, nous avons décidé de l'algorithme. À chaque étape, nous résolvons le problème d'optimisation, trouvons l'action optimale pour l'étape, la terminons, après quoi le jeu passe à l'étape suivante.Il est nécessaire de résoudre un nouveau problème à chaque étape, car à chaque cours du jeu la tâche change un peu, du nouvel or apparaît, quelqu'un mange quelqu'un, les joueurs bougent ...Mais ne pensez pas que notre ingénieux algorithme peut tout prévoir. Après avoir résolu le problème d'optimisation, vous devez absolument ajouter un gestionnaire qui vérifiera les situations désagréables:- Bot en place depuis longtemps
- Marche continue gauche-droite
- Manque de revenus trop longtemps
Tout cela peut nécessiter un changement radical de stratégie, un suicide ou une autre action en dehors du cadre de l'algorithme d'optimisation. La nature de ces situations peut être différente. Parfois, les contradictions entre la stratégie et la tactique conduisent au gel du bot en place à un point qui lui semble stratégiquement important, qui a été découvert par d'anciens botanistes appelés Buridanov Donkey. Vos adversaires peuvent geler et fermer votre courte route vers l'or convoité - nous traiterons de tout cela plus tard.
Vos adversaires peuvent geler et fermer votre courte route vers l'or convoité - nous traiterons de tout cela plus tard.La lutte contre la procrastination
Prenons le cas simple lorsqu'un or se trouve à droite du bot et qu'il n'y a plus de cellules d'or dans un rayon de 8. Quelle étape le bot prendra-t-il, guidé par notre formule? En fait - absolument aucun. Par exemple, toutes ces solutions donnent exactement le même résultat même pour trois coups:- pas à gauche - pas à droite - pas à droite
- pas à droite - inaction - inaction
- inaction - inaction - pas à droite
Les trois options donnent un gain égal à 100, le bot peut choisir l'option avec inaction, à l'étape suivante résoudre à nouveau le même problème, choisir à nouveau l'inaction ... Et rester immobile pour toujours. Nous devons modifier la formule de calcul des gains afin de stimuler le bot à agir le plus tôt possible:
nous avons multiplié le gain futur à l'étape suivante par le «coefficient d'inflation» E, qui doit être choisi inférieur à 1. Nous pouvons expérimenter en toute sécurité avec des valeurs de 0,95 ou 0,9. Mais ne le choisissez pas trop petit, par exemple, avec une valeur de E = 0,5, l'or mangé au 8ème coup n'apportera que 0,39 points.Et donc, nous avons redécouvert le principe du «Ne remettez pas à demain ce que vous pouvez manger aujourd'hui».sécurité
Récolter de l'or est certes une bonne chose, mais vous devez toujours penser à la sécurité. Nous avons deux tâches:- Apprenez au bot à creuser des trous si le monstre est dans une position appropriée
- Apprenez au bot à fuir les monstres
Mais nous ne disons pas au bot quoi faire, nous définissons la valeur de la fonction de profit et l'algorithme d'optimisation choisira les étapes appropriées. Un problème distinct est que nous ne calculons pas exactement où un monstre peut être sur un mouvement particulier. Par conséquent, pour simplifier, nous supposons que les monstres sont en place et nous n'avons tout simplement pas besoin de les approcher.S'ils commencent à nous approcher, le bot lui-même commencera à s'enfuir, car il sera condamné à une amende pour être trop proche d'eux (sorte d'auto-isolement). Et donc, nous introduisons deux règles:- Si nous arrivons au monstre à une distance d et d <= 3, alors une amende de 100 500 * (4-d) / 4 nous est imposée
- Si le monstre est venu assez près, est sur la même ligne que nous et qu'il y a un trou entre nous, alors nous obtenons un profit P
Le concept de "approché le monstre à distance d" nous le dévoilerons un peu plus tard, mais pour l'instant, passons à la stratégie.On fait le tour des graphiques
Mathématiquement, le problème du contournement optimal de l'or est un problème résolu depuis longtemps par un vendeur ambulant, dont la solution n'est pas un plaisir. Mais avant de résoudre de tels problèmes, vous devez penser à une question simple - mais comment trouvez-vous la distance entre deux points dans le jeu? Ou sous une forme légèrement plus utile: pour un or donné et pour tout point sur la carte, trouvez le nombre minimum de coups pour lesquels le joueur atteindra le point d'or. Pendant un certain temps, nous oublierons de creuser des trous et de sauter dedans, nous ne laisserons que des mouvements naturels pour 1 cellule. Seulement, nous marcherons dans la direction opposée - de l'or et à travers la carte.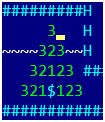 Dans la première étape, nous sélectionnons toutes les cellules à partir desquelles nous pouvons entrer dans l'or en un seul mouvement et les affectons à 1. Dans la deuxième étape, nous sélectionnons toutes les cellules à partir desquelles nous tombons en une seule étape et les affectons à 2. L'image montre le cas pour 3 étapes. Essayons maintenant de tout écrire formellement, sous une forme adaptée à la programmation.Nous aurons besoin:
Dans la première étape, nous sélectionnons toutes les cellules à partir desquelles nous pouvons entrer dans l'or en un seul mouvement et les affectons à 1. Dans la deuxième étape, nous sélectionnons toutes les cellules à partir desquelles nous tombons en une seule étape et les affectons à 2. L'image montre le cas pour 3 étapes. Essayons maintenant de tout écrire formellement, sous une forme adaptée à la programmation.Nous aurons besoin:- La distance du tableau numérique bidimensionnel [x, y], dans laquelle nous allons stocker le résultat. Initialement, pour les coordonnées or, il contient 0, pour les points restants -1.
- Le tableau oldBorder, dans lequel nous allons stocker les points à partir desquels nous nous déplacerons, initialement il a un point avec des coordonnées or
- Array newBorder, dans lequel nous allons stocker les points trouvés dans l'étape en cours
- Pour chaque point p de oldBorder, nous trouvons tous les points p_a, à partir desquels nous pouvons atteindre p en une seule étape (plus précisément, nous faisons simplement tous les pas possibles de p dans la direction opposée, par exemple, en volant vers le haut en l'absence de soutien) et la distance [p_a] = - 1
- Nous plaçons chacun de ces points p_a dans le tableau newBorder, à distance [p_a] nous écrivons le nombre d'itérations
- Une fois tous les points terminés:
- Échangez les tableaux de oldBorder et newBorder, après quoi nous effaçons newBorder
- Si oldBorder est vide, terminez l'algorithme, sinon passez à l'étape 1.
Même chose en pseudo code:iter=1;
newBorder.clear();
distance.fill(-1);
distance[gold]=0;
oldBorder.push(gold);
while(oldBorder.isNotEmpty()) {
for (p: oldBorder){
for (p_a: backMove(p)) {
if (distance[p_a]==-1) {
newBorder.push(p_a);
distance[p_a]=iter;
}
}
}
Swap(newBorder, oldBorder);
newBorder.clear();
iter++;
}
À la sortie de l'algorithme, nous aurons une carte des distances avec la valeur de la distance de chaque point de l'ensemble du champ du jeu à l'or. De plus, pour les points à partir desquels l'or est inaccessible, la valeur de la distance est -1. Les mathématiciens appellent une telle promenade autour du terrain de jeu (qui forme un graphique avec des sommets aux points du terrain et des bords reliant les sommets accessibles en un seul mouvement) «parcourez le graphique en largeur». Si nous implémentions la récursivité, plutôt que deux tableaux de bordures, cela s'appellerait «faire le tour du graphe en profondeur», mais comme la profondeur peut être assez importante (plusieurs centaines), je vous conseille d'éviter les algorithmes récursifs lors de la traversée des graphes.Le véritable algorithme sera un peu plus compliqué en creusant un trou et en y sautant - il s'avère qu'en 4 mouvements, nous déplaçons une cellule latéralement et deux vers le bas (car nous nous déplaçons dans la direction opposée, puis vers le haut), mais une légère modification de l'algorithme résout le problème.J'ai complété l'image avec des chiffres, y compris en tenant compte du fait de creuser un trou et de sauter dedans: qu'est-ce que cela nous rappelle?
qu'est-ce que cela nous rappelle? L'odeur d'or! Et notre bot ira pour cette odeur, comme Rocky pour le fromage (mais en même temps, il ne perd pas son cerveau et esquive les monstres, et creuse même des trous pour eux). Faisons de lui une simple stratégie gourmande:
L'odeur d'or! Et notre bot ira pour cette odeur, comme Rocky pour le fromage (mais en même temps, il ne perd pas son cerveau et esquive les monstres, et creuse même des trous pour eux). Faisons de lui une simple stratégie gourmande:- Pour chaque or, nous construisons une carte des distances et trouvons la distance jusqu'au joueur.
- Choisissez l'or le plus proche du joueur et prenez sa carte pour calculer la stratégie
- Pour chaque cellule de la carte, notons d sa distance à l'or, puis la valeur stratégique
Où il s'agit d'une valeur imaginaire de l'or, il est souhaitable qu'il soit évalué plusieurs fois moins que le présent, et il s'agit d'un coefficient d'inflation <1, car plus l'or imaginaire est éloigné, moins il est cher. Le rapport des coefficients E etconstitue un problème non résolu du millénaire et laisse place à la créativité.Ne pensez pas que notre bot ira toujours à l'or le plus proche. Supposons que nous ayons un or à gauche à une distance de 5 cellules, puis vide, et à droite deux or à une distance de 6 et 7. Étant donné que le véritable or est plus précieux que prévu, le bot ira à droite.Avant de passer à des stratégies plus intéressantes, nous allons apporter une autre amélioration. Dans le jeu, la gravité tire le joueur vers le bas et il ne peut que monter les escaliers. Ainsi, l'or qui est plus élevé devrait être évalué plus haut. Si la hauteur est indiquée à partir de la ligne supérieure, vous pouvez multiplier la valeur de l'or (avec la coordonnée verticale y) par. Pour le coefficient le nouveau terme «taux d'inflation vertical» a été inventé, du moins il n'est pas utilisé par les économistes et reflète bien l'essence.Stratégies compliquées
Avec un or trié, vous devez faire quelque chose avec tout l'or, et je ne voudrais pas attirer les mathématiques lourdes. Il existe une solution très élégante, simple et incorrecte (au sens strict) - si un or crée un «champ» de valeur autour de lui, ajoutons simplement tous les champs de valeur de toutes les cellules contenant de l'or dans une matrice et utilisons-le comme stratégie. Oui, ce n'est pas une solution optimale, mais plusieurs unités d'or à distance moyenne peuvent être plus précieuses qu'une unité proche.Cependant, une nouvelle solution crée de nouveaux problèmes - une nouvelle matrice de valeurs peut contenir des maxima locaux, près desquels il n'y a pas d'or. Parce que notre bot peut y entrer et ne veut pas sortir, cela signifie que nous devons ajouter un gestionnaire qui vérifie que le bot est au maximum local de la stratégie et reste en place en fonction des résultats du déplacement. Et maintenant, nous avons un outil pour combattre les gels - annulez cette stratégie par N mouvements et revenez temporairement à la stratégie de l'or le plus proche.C'est assez drôle de voir comment un bot coincé change de stratégie et commence à descendre en continu, mangeant tout l'or le plus proche, aux étages inférieurs de la carte, le bot reprend ses esprits et essaie de grimper. Une sorte de Dr Jekyll et M. Hyde.La stratégie n'est pas d'accord avec la tactique
Ici, notre bot arrive à l'or sous le sol: il tombe déjà dans l'algorithme d'optimisation, il reste à faire 3 pas à droite, à faire un trou à droite et à sauter dedans, puis la gravité fera tout par elle-même. Quelque chose comme ça:
il tombe déjà dans l'algorithme d'optimisation, il reste à faire 3 pas à droite, à faire un trou à droite et à sauter dedans, puis la gravité fera tout par elle-même. Quelque chose comme ça: Mais le bot se fige sur place. Le débogage a montré qu'il n'y avait pas d'erreur: le bot a décidé que la stratégie optimale était d'attendre un mouvement, puis de suivre l'itinéraire spécifié et de prendre de l'or à la dernière étape analysée. Dans le premier cas, il reçoit un gain de l'or reçu et un gain de l'or imaginaire (lors de la dernière itération analysée, il se trouve juste dans la cellule où se trouvait l'or), et dans le second - uniquement de l'or réel (bien qu'un tour plus tôt), mais le gain il n'y a plus de stratégie, car la place sous l'or est pourrie et peu prometteuse. Eh bien, au prochain coup, il décide à nouveau de faire une pause d'un coup, nous avons déjà réglé ces problèmes.J'ai dû modifier la stratégie - puisque nous avons mémorisé tout l'or qui a été mangé au stade de l'analyse, en soustrayant les cartes de valeur de l'or mangé de la matrice totale de valeur stratégique, ainsi, la stratégie a pris en compte la réalisation de tactiques (il était possible de calculer la valeur différemment - en ajoutant des matrices uniquement pour or entier, mais c'est plus compliqué sur le plan informatique, car il y a beaucoup plus d'or sur la carte que nous ne pouvons en manger en 8 coups).Mais cela n'a pas mis fin à nos tourments. Supposons que la matrice de valeur stratégique ait un maximum local et que le bot s'en soit approché pendant 7 mouvements. Le bot va-t-il y geler? Non, car pour toute route dans laquelle le bot atteint le maximum local en 8 coups, la victoire sera la même. Bonne vieille procrastination. La raison en est que le gain stratégique ne dépend pas du moment où nous nous trouvons dans la cellule. La première chose qui vient à l'esprit est d'amender le bot pour un simple, mais cela n'aide en rien de marcher insensé à gauche / à droite. Il est nécessaire de traiter la cause profonde - de prendre en compte le gain stratégique à chaque tour (comme la différence entre la valeur stratégique des états nouveaux et actuels), en la réduisant au fil du temps d'un facteur.Ceux. introduire un terme supplémentaire dans l'expression pour gagner:
Mais le bot se fige sur place. Le débogage a montré qu'il n'y avait pas d'erreur: le bot a décidé que la stratégie optimale était d'attendre un mouvement, puis de suivre l'itinéraire spécifié et de prendre de l'or à la dernière étape analysée. Dans le premier cas, il reçoit un gain de l'or reçu et un gain de l'or imaginaire (lors de la dernière itération analysée, il se trouve juste dans la cellule où se trouvait l'or), et dans le second - uniquement de l'or réel (bien qu'un tour plus tôt), mais le gain il n'y a plus de stratégie, car la place sous l'or est pourrie et peu prometteuse. Eh bien, au prochain coup, il décide à nouveau de faire une pause d'un coup, nous avons déjà réglé ces problèmes.J'ai dû modifier la stratégie - puisque nous avons mémorisé tout l'or qui a été mangé au stade de l'analyse, en soustrayant les cartes de valeur de l'or mangé de la matrice totale de valeur stratégique, ainsi, la stratégie a pris en compte la réalisation de tactiques (il était possible de calculer la valeur différemment - en ajoutant des matrices uniquement pour or entier, mais c'est plus compliqué sur le plan informatique, car il y a beaucoup plus d'or sur la carte que nous ne pouvons en manger en 8 coups).Mais cela n'a pas mis fin à nos tourments. Supposons que la matrice de valeur stratégique ait un maximum local et que le bot s'en soit approché pendant 7 mouvements. Le bot va-t-il y geler? Non, car pour toute route dans laquelle le bot atteint le maximum local en 8 coups, la victoire sera la même. Bonne vieille procrastination. La raison en est que le gain stratégique ne dépend pas du moment où nous nous trouvons dans la cellule. La première chose qui vient à l'esprit est d'amender le bot pour un simple, mais cela n'aide en rien de marcher insensé à gauche / à droite. Il est nécessaire de traiter la cause profonde - de prendre en compte le gain stratégique à chaque tour (comme la différence entre la valeur stratégique des états nouveaux et actuels), en la réduisant au fil du temps d'un facteur.Ceux. introduire un terme supplémentaire dans l'expression pour gagner:
la valeur de la fonction objectif sur ce dernier est généralement considérée comme nulle: . Étant donné que le gain est amorti à chaque mouvement en multipliant par un coefficient, cela fera gagner un gain stratégique plus rapide à notre bot et éliminera le problème observé.Stratégie non testée
Je n'ai pas testé cette stratégie dans la pratique, mais elle semble prometteuse.- Puisque nous connaissons toutes les distances entre les points d'or et les distances entre l'or et le joueur, nous pouvons trouver la chaîne joueur-N de cellules d'or (où N est petit, par exemple 5 ou 6) avec la plus courte longueur. Même la recherche de temps la plus simple suffit.
- Sélectionnez le premier or de cette chaîne et utilisez son champ de valeur comme matrice de stratégie.
Dans ce cas, il est souhaitable de rapprocher le coût du réel et le coût de l'or imaginaire afin que le bot ne se précipite pas dans le sous-sol vers l'or le plus proche.Améliorations finales
Après avoir appris à "s'étendre" sur la carte, faisons une "propagation" similaire de chaque monstre pour plusieurs mouvements et trouvons toutes les cellules dans lesquelles le monstre peut se retrouver, ainsi que le nombre de mouvements pour lesquels il le fera. Cela permettra au joueur de ramper à travers le tuyau au-dessus de la tête du monstre en toute sécurité.Et le dernier moment - lors du calcul de la stratégie et de la valeur imaginaire de l'or, nous n'avons pas pris en compte la position des autres joueurs, simplement en les «effaçant» lors de l'analyse de la carte. Il s'avère que des obus suspendus individuels peuvent bloquer l'accès à des régions entières, donc un gestionnaire supplémentaire a été ajouté - pour suivre les adversaires gelés et les remplacer par des blocs de béton pendant l'analyse.Caractéristiques d'implémentation
Étant donné que l'algorithme principal est récursif, nous devons être en mesure de changer rapidement les objets d'état et de les remettre à leur origine pour une modification ultérieure. J'ai utilisé java, un langage avec garbage collection, essayer des millions de changements liés à la création d'objets de courte durée peut provoquer plusieurs garbage collections en un tour de jeu, ce qui peut être fatal en termes de vitesse. Par conséquent, il faut être extrêmement prudent dans les structures de données utilisées, je n'ai utilisé que des tableaux et des listes. Eh bien, ou utilisez le projet Valgala à vos risques et périls :)Code source et serveur de jeux
Le code source peut être trouvé ici sur le github . Ne jugez pas strictement, beaucoup a été fait à la hâte. Le serveur de jeu codenjoy fournira l'infrastructure pour lancer des bots et surveiller le jeu. Au moment de la création, la révision était pertinente, la révision 1.0.26 a été utilisée.Vous pouvez démarrer le serveur avec la ligne suivante:call mvn -DMAVEN_OPTS=-Xmx1024m -Dmaven.test.skip=true clean jetty:run-war -Dcontext=another-context -Ploderunner
Le projet lui-même est extrêmement curieux, propose des jeux pour tous les goûts.Conclusion
Si vous avez lu tout cela jusqu'au bout sans préparation préalable et tout compris, alors vous êtes un type rare.