Une traduction de l'article a été préparée avant le début du cours «Développeur C # ASP.NET Core» .
C # est un excellent langage et le .NET Framework est également très bon. Une frappe forte en C # permet de réduire le nombre d'erreurs que vous pouvez provoquer, par rapport à d'autres langages. De plus, sa conception intuitive générale aide beaucoup, par rapport à quelque chose comme JavaScript (où vrai est faux ). Cependant, chaque langue a son propre rake qui est facile à suivre, ainsi que des idées erronées sur le comportement attendu de la langue et de l'infrastructure. J'essaierai de décrire en détail certaines de ces erreurs.1. Je ne comprends pas l'exécution retardée (paresseuse)
Je pense que les développeurs expérimentés connaissent ce mécanisme .NET, mais cela peut surprendre des collègues moins avertis. En un mot, les méthodes / opérateurs qui retournent IEnumerable<T>yieldpour retourner chaque résultat ne sont pas exécutés dans la ligne de code qui les appelle réellement - ils sont exécutés lorsque la collection résultante est accessible d'une manière ou d'une autre *. Notez que la plupart des expressions LINQ retournent finalement leurs résultats avec rendement .À titre d'exemple, considérons le test unitaire flagrant ci-dessous.[TestMethod]
[ExpectedException(typeof(ArgumentNullException))]
public void Ensure_Null_Exception_Is_Thrown()
{
var result = RepeatString5Times(null);
}
[TestMethod]
[ExpectedException(typeof(InvalidOperationException))]
public void Ensure_Invalid_Operation_Exception_Is_Thrown()
{
var result = RepeatString5Times("test");
var firstItem = result.First();
}
private IEnumerable<string> RepeatString5Times(string toRepeat)
{
if (toRepeat == null)
throw new ArgumentNullException(nameof(toRepeat));
for (int i = 0; i < 5; i++)
{
if (i == 3)
throw new InvalidOperationException("3 is a horrible number");
yield return $"{toRepeat} - {i}";
}
}
Ces deux tests échoueront. Le premier test échouera, car le résultat n'est utilisé nulle part, donc le corps de la méthode ne sera jamais exécuté. Le deuxième test échouera pour une autre raison, un peu plus banale. Nous obtenons maintenant le premier résultat de l'appel de notre méthode pour nous assurer qu'elle s'exécute réellement. Cependant, le mécanisme d'exécution différée quittera la méthode dès qu'il le pourra - dans ce cas, nous n'avons utilisé que le premier élément, donc, dès que nous passons la première itération, la méthode arrête son exécution (donc i == 3 ne sera jamais vrai).L'exécution différée est en fait un mécanisme intéressant, en particulier parce qu'elle facilite la chaîne de requêtes LINQ, ne récupérant les données que lorsque votre requête est prête à être utilisée.2. , Dictionary ,
C'est particulièrement désagréable, et je suis sûr que quelque part j'ai du code qui repose sur cette hypothèse. Lorsque vous ajoutez des éléments à la liste List<T>Dictionary<TKey,TValue>
secondevar dict = new Dictionary<string, object>();
dict.Add("first", new object());
dict.Add("second", new object());
dict.Remove("first");
dict.Add("third", new object());
foreach (var entry in dict)
{
Console.WriteLine(entry.Key);
}
Ne me crois pas? Vérifiez ici en ligne vous-même .3. Ne prenez pas en compte la sécurité du débit
Le multithreading est excellent, s'il est correctement implémenté, vous pouvez améliorer considérablement les performances de votre application. Cependant, dès que vous entrez dans le multithreading, vous devez être très, très prudent avec les objets que vous allez modifier, car vous pouvez commencer à rencontrer des erreurs apparemment aléatoires si vous n'êtes pas assez prudent.Autrement dit, de nombreuses classes de base dans la bibliothèque .NET ne sont pas thread-safe.- Cela signifie que Microsoft ne garantit pas que vous pouvez utiliser cette classe en parallèle en utilisant plusieurs threads. Ce ne serait pas un gros problème si vous pouviez trouver immédiatement des problèmes associés à cela, mais la nature du multithreading implique que tous les problèmes qui surviennent sont très instables et imprévisibles - très probablement, aucune exécution ne produira le même résultat.Par exemple, considérons ce bloc de code qui utilise un langage simple mais pas thread-safe List<T>var items = new List<int>();
var tasks = new List<Task>();
for (int i = 0; i < 5; i++)
{
tasks.Add(Task.Run(() => {
for (int k = 0; k < 10000; k++)
{
items.Add(i);
}
}));
}
Task.WaitAll(tasks.ToArray());
Console.WriteLine(items.Count);
Ainsi, nous ajoutons des nombres de 0 à 4 à la liste 10 000 fois chacun, ce qui signifie que la liste devrait finalement contenir 50 000 éléments. Devrais-je? Eh bien, il y a une petite chance que ce sera finalement - mais voici les résultats de 5 de mes différents lancements:28191
23536
44346
40007
40476
Vous pouvez le vérifier vous-même en ligne ici .En fait, cela est dû au fait que la méthode Add n'est pas atomique, ce qui implique que le thread peut interrompre la méthode, ce qui peut finalement redimensionner le tableau pendant qu'un autre thread est en train d'ajouter ou d'ajouter un élément avec le même index comme l'autre fil. L'exception IndexOutOfRange m'est venue plusieurs fois, probablement parce que la taille du tableau a changé lors de son ajout. Alors qu'est-ce qu'on fait ici? Nous pouvons utiliser le mot clé lock pour nous assurer qu'un seul thread peut ajouter un élément (Add) à la liste à la fois, mais cela peut considérablement affecter les performances. Microsoft, étant des gens sympas, propose de superbes collections quiIls sont thread-safe et hautement optimisés en termes de performances. J'ai déjà publié un article décrivant comment vous pouvez les utiliser .4. Utilisation abusive (différée) du chargement dans LINQ
Le chargement différé est une excellente fonctionnalité pour LINQ to SQL et LINQ to Entities (Entity Framework), qui vous permet de charger des lignes de table liées selon vos besoins. Dans l'un de mes autres projets, j'ai une table «Modules» et une table «Résultats» avec une relation un-à-plusieurs (un module peut avoir plusieurs résultats).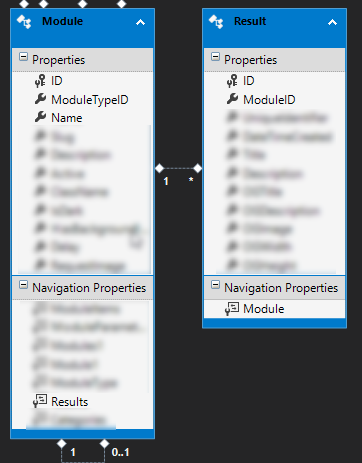 Lorsque je veux obtenir un module spécifique, je ne veux certainement pas que Entity Framework renvoie tous les résultats de la table Modules! Par conséquent, il est assez intelligent pour exécuter une requête pour obtenir des résultats uniquement lorsque j'en ai besoin. Ainsi, le code ci-dessous exécutera 2 requêtes - une pour obtenir le module, et l'autre pour obtenir les résultats (pour chaque module),
Lorsque je veux obtenir un module spécifique, je ne veux certainement pas que Entity Framework renvoie tous les résultats de la table Modules! Par conséquent, il est assez intelligent pour exécuter une requête pour obtenir des résultats uniquement lorsque j'en ai besoin. Ainsi, le code ci-dessous exécutera 2 requêtes - une pour obtenir le module, et l'autre pour obtenir les résultats (pour chaque module),using (var db = new DBEntities())
{
var modules = db.Modules;
foreach (var module in modules)
{
var moduleType = module.Results;
}
}
Mais que faire si j'ai des centaines de modules? Cela signifie qu'une requête SQL distincte pour la réception des enregistrements de résultats sera exécutée pour chaque module! Évidemment, cela mettra à rude épreuve le serveur et ralentira considérablement votre application. Dans Entity Framework, la réponse est très simple - vous pouvez spécifier qu'il inclut un ensemble spécifique de résultats dans votre requête. Voir le code modifié ci-dessous, où une seule requête SQL sera exécutée, qui inclura chaque module et chaque résultat pour ce module (combinés en une seule requête, que Entity Framework affiche intelligemment dans votre modèle),using (var db = new DBEntities())
{
var modules = db.Modules.Include(b => b.Results);
foreach (var module in modules)
{
var moduleType = module.Results;
}
}
5. Je ne comprends pas comment LINQ to SQL / Entity Frameworks traduit les requêtes
Puisque nous avons abordé le sujet LINQ, je pense qu'il vaut la peine de mentionner à quel point votre code s'exécutera différemment s'il se trouve dans une requête LINQ. Expliquant à un niveau élevé, tout votre code dans une requête LINQ est traduit en SQL à l'aide d' expressions - cela semble évident, mais il est très, très facile d'oublier le contexte dans lequel vous vous trouvez et, finalement, d'introduire des problèmes dans votre base de code. Ci-dessous, j'ai compilé une liste pour décrire certains obstacles typiques que vous pouvez rencontrer.La plupart des appels de méthode ne fonctionneront pas.Imaginez donc que vous ayez la requête ci-dessous pour séparer le nom de tous les modules par deux points et capturer la deuxième partie.var modules = from m in db.Modules
select m.Name.Split(':')[1];
Vous obtiendrez une exception dans la plupart des fournisseurs LINQ - il n'y a pas de traduction SQL pour la méthode Split, certaines méthodes peuvent être prises en charge, par exemple, l'ajout de jours à une date, mais tout dépend de votre fournisseur.Ceux qui fonctionnent peuvent produire des résultats inattendus ...Prenez l'expression LINQ ci-dessous (je n'ai aucune idée pourquoi vous feriez cela en pratique, mais imaginez simplement que c'est une demande raisonnable).int modules = db.Modules.Sum(a => a.ID);
Si vous avez des lignes dans la table des modules, elle vous donnera la somme des identifiants. Sonne bien! Mais que se passe-t-il si vous l'exécutez à l'aide de LINQ to Objects à la place? Nous pouvons le faire en convertissant la collection de modules en une liste avant d'exécuter notre méthode Sum.int modules = db.Modules.ToList().Sum(a => a.ID);
Choc, horreur - cela fera exactement la même chose! Cependant, que se passe-t-il si vous n'avez pas de lignes dans la table des modules? LINQ to Objects renvoie 0 et la version Entity Framework / LINQ to SQL lève une exception InvalidOperationException , qui indique qu'elle ne peut pas convertir «int?» en "int" ... tel. Cela est dû au fait que lorsque vous exécutez SUM dans SQL pour un ensemble vide, NULL est renvoyé au lieu de 0 - par conséquent, il essaie plutôt de renvoyer un entier nullable. Voici quelques conseils pour résoudre ce problème si vous rencontrez un tel problème .Sachez quand vous avez juste besoin d'utiliser le bon vieux SQL.Si vous exécutez une demande extrêmement complexe, votre demande traduite peut finir par ressembler à quelque chose de craché, dévorée encore et encore. Malheureusement, je n'ai aucun exemple à démontrer, mais à en juger par l'opinion dominante, j'aime vraiment utiliser les vues imbriquées, ce qui fait de la maintenance du code un cauchemar.De plus, si vous rencontrez des goulots d'étranglement de performances, il vous sera difficile de les corriger car vous n'avez pas de contrôle direct sur le SQL généré. Soit le faire en SQL, soit le déléguer à l'administrateur de la base de données, si vous ou votre entreprise en avez un!6. Arrondi incorrect
Maintenant, quelque chose d'un peu plus simple que les paragraphes précédents, mais je l'ai toujours oublié et je me suis retrouvé avec des erreurs désagréables (et, si cela est lié aux finances, un directeur de palme / gène en colère).Le .NET Framework inclut une excellente méthode statique dans la classe Math appelée Round , qui prend une valeur numérique et l'arrondit à la décimale spécifiée. Cela fonctionne parfaitement la plupart du temps, mais que faire lorsque vous essayez d'arrondir 2,25 à la première décimale? Je suppose que vous vous attendez probablement à ce qu'il arrondisse à 2,3 - c'est ce à quoi nous sommes tous habitués, non? Eh bien, dans la pratique, il s'avère que .NET utilise l' arrondi bancairequi arrondit l'exemple donné à 2.2! Cela est dû au fait que les banquiers sont arrondis au nombre pair le plus proche si le nombre est au «milieu». Heureusement, cela peut facilement être remplacé par la méthode Math.Round.Math.Round(2.25,1, MidpointRounding.AwayFromZero)
7. Horrible classe «DBNull»
Cela peut provoquer des souvenirs désagréables pour certains - ORM nous cache cette saleté, mais si vous plongez dans le monde d'ADO.NET nu (SqlDataReader et autres), vous rencontrerez DBNull.Value.Je ne suis pas sûr à 100% de la raison pour laquelleLes valeurs NULL de la base de données sont traitées comme suit (veuillez commenter ci-dessous si vous le savez!), Mais Microsoft a décidé de les présenter avec un type spécial DBNull (avec un champ statique Value). Je peux donner un des avantages de ceci - vous n'obtiendrez aucune NullReferenceException désagréable lors de l'accès à un champ de base de données qui est NULL. Cependant, vous devez non seulement prendre en charge la méthode secondaire de vérification des valeurs NULL (ce qui est facile à oublier, ce qui peut entraîner de graves erreurs), mais vous perdez l'une des excellentes fonctionnalités de C # qui vous aident à travailler avec null. Qu'est-ce qui pourrait être aussi simple quereader.GetString(0) ?? "NULL";
ce qui finit par devenir ...reader.GetString(0) != DBNull.Value ? reader.GetString(0) : "NULL";
Pouah.Remarque
Ce ne sont que quelques-uns des «râteaux» non triviaux que j'ai rencontrés dans .NET - si vous en savez plus, j'aimerais vous entendre ci-dessous.
ASP.NET Core: