
INTRODUCTION
— ,
— ,
:
,
,
,
,
:
, ,
, .
, —
,
— :
,
?
.
Il y a quelques mois, lors d'un événement informatique, j'ai vu le travail de Pandas. Le gars qui a travaillé avec lui n'a rien de particulièrement surprenant. Mais la simple addition de valeurs, le calcul de moyennes, les regroupements ont été effectués si magistralement que, même avec tout mon parti pris pour Python, j'ai été fasciné. Les manipulations ont été effectuées sur des ensembles de données assez décents selon les réparations du capital pour la période qui semble aller de 2004 à 2019. Des centaines de milliers de lignes, mais tout a fonctionné très rapidement.
- , Pandas. , Excel . .
. , , . , , . , , , , . - "barchart race" - " ". , barchart race. , . Barchart race , , , - ,
"" , , . , , . , , . . , , - . :
- , .
- , , - . .
:
. .
: " ". . . - . .
— 20- , , . , - , (, ), , , , .
- , . , 7 , 3 — ( ) 4, 5 — , 6, 7 — . , , , .
:
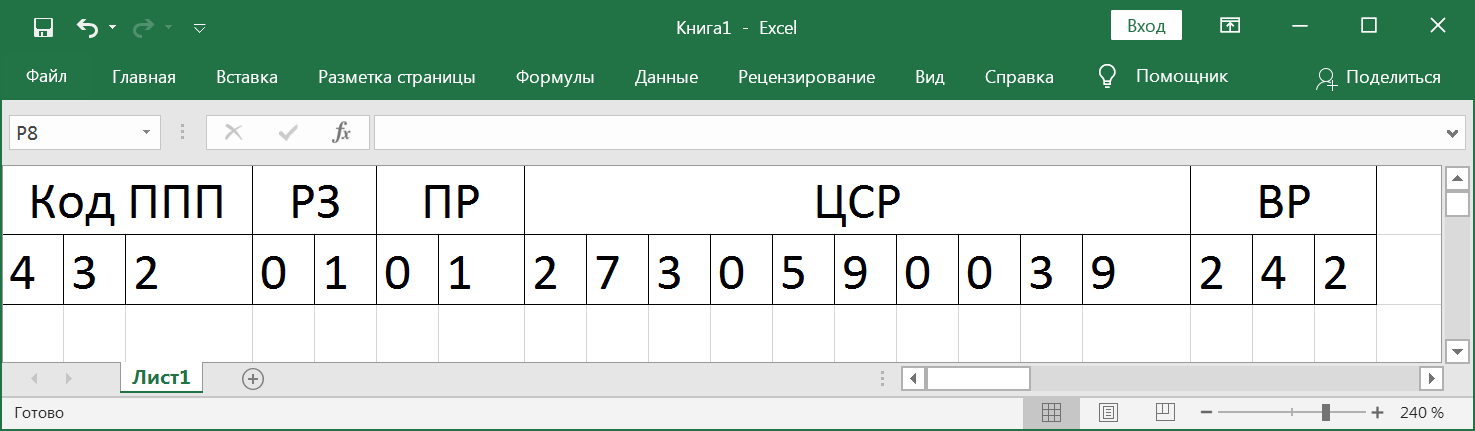
, , .
, . , . . . , , . 3 10 , . . . . 164. .
.
. 0507011, 2002 2019. - 2007 .
, , 2002 2019 .
, 0501 2003 " ", 2006 " ". 01 . 0103 2002 " ", 2005 " () ".
, . , , . 02 , 03 . . , .
. , , 1986 A Manual on Government Finance Statistics (GFSM 1986). https://www.imf.org/external/pubs/ft/gfs/manual/1986/eng/index.htm
, : 2001 2014 . GFSM 2014 .
4 "Functional classification", . Classicifation of the Functions of Government COFOG. - (). , . 4 : 2 — , 3 4 . , . 2002 . , , .
, .
COFOG, COFOG.
, , COFOG , . . , . . , , , " " , 01 ( ) . , , . , . . - . .
: " , -!"
. -
. , outer join . :
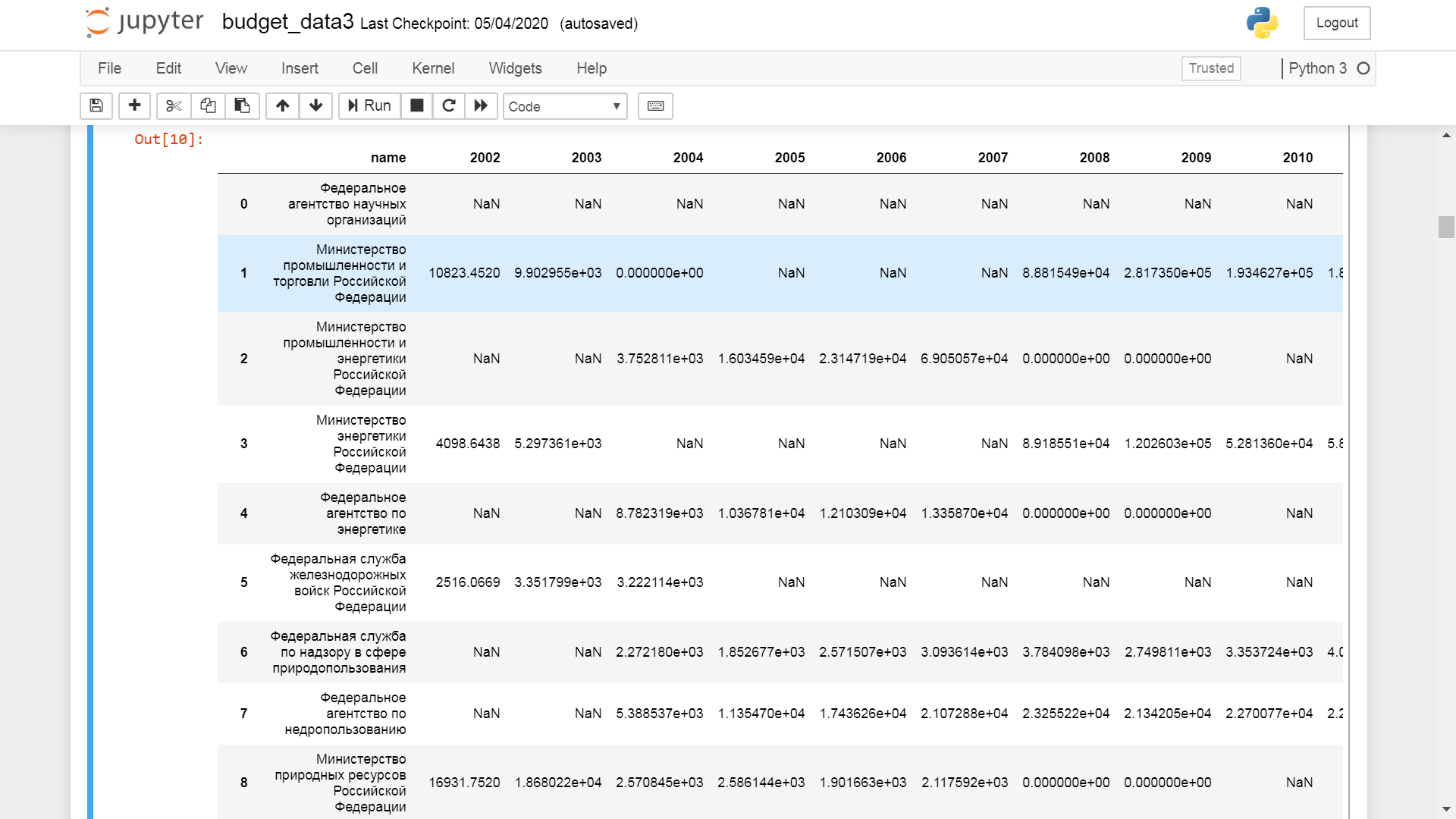
. , . . , . 2002 2019 240 , , . 95 . 2002 240, 17 8 . .
:
html :
https://vneberu.ru/
, , . . .
. ?
1 . 01 , . 0101.
17 , . , 01 , .. " " 01. , 01, . , GFSM 2014, - . , 70310 , , , , , ;
01 , - . . - . - . Pandas, . levenshtein_merge(). join Pandas DataFrame , . , . , , , , pip install Pandas DataFrame. , prepack.
2 , jupyter notebook .
import pandas as pd
import numpy as np
import os, sys
from prepack import prepack as pp
pd.options.display.max_rows = 2000
pd.options.display.max_columns = 200
pd.options.display.max_colwidth = 500
pd.options.display.min_rows = 40
prepack. zip . file-like ,
. pd.read_excel(), excel.
names, files = pp.read_zip("raw_data.zip")
pd.read_excel() , excel .
read_excel excel , .
, . . , .
pp.read_excel(files[0]).iloc[8:13,:]
, . . excel, 1 DataFrame, , .
3 : files, columns, fltr. excel , — , . — , , . 4 . .
, , 0 11 , , , . , . 3 :
8,9,10
df = pp.parse_excels(files, columns=[0,12], fltr={0: 'istext',1: 'isnum'}, header=[8,9,10])
df.head(5)
1 , pickle, prepack 0.4.2 pkl.gz
df.to_csv('raw_data.csv.gz')
pp.save(df, 'raw_data.pkl.gz')
prepack. DataFrame, .
DataFrame, , , . , 3 iloc=True.
, , " " " ", . .
f = pp.df_filter_and(df, {0: 'istext', 1: 'isnum', 2: 'isblank', 3: 'isblank'}, iloc=True)
ppp = df[f]
idx = ppp[' '].index
ppp = ppp.loc[idx,:]
, DataFrame , .
def df_filter(df, fltr):
f = pp.df_filter_and(df, fltr)
res = df[f]
df.drop(res.index, axis=0, inplace=True)
return res
, DataFrame .
, , . , . label . , ,
, .
def df_filter_post_proc(df, fltr, rzpr, label):
df_ = df_filter(df, fltr)
codes = df_[' '].unique()
names = df_[' '].unique()
return {'name': list(names), 'ppp': list(codes), 'rzpr': list(rzpr), 'label': list(label)}
, . , , 1 . . df . , , , . . . , : 1 , . . , .
.
def groups_fill(df, groups):
res = pd.DataFrame([])
for g in groups:
el = groups[g]
ppp = el['ppp']
rzpr = el['rzpr']
label = el['label']
if len(ppp) == 0:
continue
f1 = {' ': ppp}
f2 = {' ': rzpr}
f3 = {' ': 'isblank'}
f4 = {' ': 'isblank'}
m1 = pp.df_filter_or(df, f1)
m2 = pp.df_filter_or(df, f2)
m3 = pp.df_filter_or(df, f3)
m4 = pp.df_filter_or(df, f4)
df1 = df[m1 & m2 & m3 & m4]
df_ = df[m1 & m4]
f5 = {' ': label}
m5 = pp.df_filter_or(df_, f5)
df2 = df_[m5].copy()
df2['idx'] = df2.index
intersect = pd.merge(df1.loc[:,[' ',' ', 'src_filename']],
df2.loc[:,[' ',' ', 'src_filename','idx']],
on=[' ',' ', 'src_filename'], how='inner')
df2_filtered = df2.drop(intersect['idx'], axis=0)
df3 = pd.concat([df1, df2_filtered], axis=0)
v = df3[[' ',
' ',
' ',
'(. .) ',
'src_filename']].copy()
v['name'] = g
res = pd.concat([res, v], axis=0)
return res
.
:
- , .
- 0101 0107 2002 2019 .
- , 0101 0107 . , .
lst = {}
rzpr_base = ['0101','0102','0103','0104','0105','0106','0107']
label_base = [' ',
r'contains=.*(?:.*).*',
r'contains=.*(?: ).*',
r'contains=.*(?: .*).*'
]
f = {' ': r'contains=.*(?: ).*'}
rzpr = ['isblank']
df_slice = df_filter_post_proc(ppp, f, rzpr, label_base)
lst[''] = df_slice
rzpr = ['0101','0102','0103','0104','0105','0106','0107','0201']
f = {' ': r'contains=.*(?:|| |||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
rzpr = ['0101','0102','0103','0104','0105','0106','0107','0201']
f = {' ': r'contains=.*(?:|-| ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:|).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?: | ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?: ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:|||| || ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:|| | |||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] =df_slice
f = {' ': r'contains=.*(?:).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] =df_slice
f = {' ': r'contains=.*(?:|| |).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] =df_slice
f = {' ': r'contains=.*(?:|||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[', '] =df_slice
f = {' ': r'contains=.*(?:| | |||||| | | | | ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[', , , '] = df_slice
f = {' ': r'contains=.*(?:|).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:||||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:||).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:||| | |).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:| | || | | ).*'}
label = label_base.copy()
label = label + [' ',' ']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[', '] = df_slice
f = {' ': r'contains=.*(?:| | | ).*'}
label = label_base.copy()
label = label + [' ']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label)
lst[''] = df_slice
f = {' ': r'contains=.*(?:).*'}
label = label_base.copy()
label = label + [r'contains=.* .*']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:| ).*'}
label = label_base.copy()
label = label + ['- ']
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label)
lst[''] = df_slice
f = {' ': r'contains=.*(?:|).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?: |||| |).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[', , , '] = df_slice
f = {' ': r'contains=.*(?:| |).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:||| | ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?:).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?:[]|).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*(?: | ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*(?: ).*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
f = {' ': r'contains=.*.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[' '] = df_slice
f = {' ': r'contains=.*'}
df_slice = df_filter_post_proc(ppp, f, rzpr_base, label_base)
lst[''] = df_slice
, , .
for group in lst:
el = lst[group]
print(len(el['name']), group, 'ppp:', '|'.join(el['ppp']))
print('', len(ppp))
1 ppp: 308
11 ppp: 125|126|177|464|722|184|187|186|721|185
3 ppp: 160|171|388
23 ppp: 083|316|497|204|048|059|060|077|079|081|093|106|141|151|498|587|086|085|087|096
3 ppp: 258|259|730
2 ppp: 330|333
1 ppp: 305
20 ppp: 056|164|166|409|424|425|591|597|057|058|167|175|054
35 ppp: 075|139|190|226|319|386|401|423|486|494|573|589|677|693|073|074|144|385|595|384|007
3 ppp: 181|205|182
3 ppp: 163|166|167
7 ppp: 092|520|720|723|521|724|100
6 , ppp: 149|154|159|155|157|172
13 , , , ppp: 140|162|165|197|263|161|168|307|142|139|160
1 ppp: 153
6 ppp: 071|156|072|173|321
10 ppp: 020|099|129|306|021|023|101|143|022|725
7 ppp: 029|104|103|107|108|109|110|179
12 ppp: 078|089|128|134|397|201|070|084|088|135|071
0 ppp:
6 ppp: 206|303|352|588|304
10 , ppp: 153|188|415|189|202|192|416|417|180
4 ppp: 434|436|437|438
1 ppp: 322
2 ppp: 318|320
4 ppp: 076|082|080|085
7 , , , ppp: 050|158|049|052|053|169|051
6 ppp: 133|279|132|309|360|069
7 ppp: 054|148|387|055|061|064|056|149
2 ppp: 777
1 ppp: 150
2 ppp: 392|393
1 ppp: 310
5 ppp: 022|350|340|370
5 ppp: 174|091|095|260|380
0 ppp:
3 ppp: 152|302|090
0
lst[' ']
{'name': [' ',
' ',
' , , , ',
' ',
' '],
'ppp': ['174', '091', '095', '260', '380'],
'rzpr': ['0101', '0102', '0103', '0104', '0105', '0106', '0107'],
'label': [' ',
'contains=.*(?:.*).*',
'contains=.*(?: ).*',
'contains=.*(?: .*).*']}
, .
df2 = groups_fill(df,lst)
df2
2970 rows × 6 columns
df3 = df2.loc[:,['(. .) ', 'src_filename', 'name']]
df3.columns = ['value', 'year', 'name']
idx = df3[df3.loc[:,'value'] == ''].index
df3.loc[idx, 'value'] = '0.0'
df3 = df3.astype({'value': 'float64'})
df4 = df3.groupby(['year','name']).sum().reset_index()
def manuscript(df):
res = pd.DataFrame([])
for i in df.index:
n = df.loc[i,'name']
y = df.loc[i,'year']
v = df.loc[i,'value']
res.loc[n,y] = v
res['name'] = res.index
last_idx = res.shape[1] - 1
order = [last_idx]
order = order + list(range(0, last_idx))
res = res.iloc[:,order]
return res
df5 = manuscript(df4)
df5
def prep_data(df):
lst = []
size = df.shape[0]
for i in range(0, size):
row = df.iloc[i,:]
name = row['name']
row_ = row[1:]
for k, y in enumerate(row_.index):
begin = float(row_[k])
try:
end = float(row_[k + 1])
except:
end = float(row_[k])
range_ = end - begin
step = range_ / 10
cur = begin
for n in range(0,10):
last = cur
cur = begin + step * (n+1)
if cur < 0:
cur = 0.0
lst.append({'name': name,
'value': round(cur, 2),
'year': float(str(y) + '.' + str(n)),
'lastValue': round(last, 2),
'rank': 0})
df2 = pd.DataFrame(lst)
df2 = df2.sort_values(by=['year','value'])
df2.reset_index(drop=True, inplace = True)
df2['rank'] = range(1,df2.shape[0]+1)
return df2
data = prep_data(df5)
data
6120 lignes × 5 colonnes
data.to_csv('data_groups.csv', index=False)
Ensuite, vous devez écrire le contenu du fichier csv résultant dans le fichier https://github.com/legale/d3.js-portable/blob/master/barchart-race-ppp-bundle2.html dans la variable csv_string.
Nous regardons la course reçue. Les résultats de la course parlent d'eux-mêmes.
Ici en html:
https://vneberu.ru/barchart-race2.html
Voici une vidéo sur youtube:
Merci de votre attention, bienvenue à commenter.
LIENS
Vous pouvez voir la bibliothèque de pré-pack ici: https://github.com/legale/prepack
Les bundles collectés avec les courses peuvent être téléchargés à partir des liens ci-dessus, mais ici .