Dans les systèmes ERP complexes, de nombreuses entités ont une nature hiérarchique , lorsque des objets homogènes s'alignent dans une arborescence de relations ancêtre-descendant - il s'agit de la structure organisationnelle de l'entreprise (toutes ces branches, départements et groupes de travail), et du catalogue de produits, des zones de travail et de la géographie. points de vente, ... En fait, il n'y a pas une seule sphère de l'automatisation des affaires où au moins une certaine hiérarchie ne serait pas le résultat. Mais même si vous ne travaillez pas «pour les affaires», vous pouvez toujours rencontrer facilement des relations hiérarchiques. Trite, même votre arbre généalogique ou plan d'étage des locaux dans le centre commercial est la même structure. Il existe de nombreuses façons de stocker une telle arborescence dans un SGBD, mais aujourd'hui, nous nous concentrerons sur une seule option:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
Et pendant que vous regardez dans les profondeurs de la hiérarchie, il attend patiemment la façon dont [naïf] vos manières "naïves" de travailler avec une telle structure se révéleront.Analysons les tâches émergentes typiques, leur implémentation en SQL et essayons d'améliorer leurs performances.#1. Quelle est la profondeur du terrier du lapin?
Supposons, pour être précis, que cette structure reflétera la subordination des départements dans la structure de l'organisation: départements, divisions, secteurs, branches, groupes de travail ... peu importe comment vous les appelez.Tout d'abord, nous générons notre «arbre» d'éléments 10KINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
Commençons par la tâche la plus simple - trouver tous les employés qui travaillent dans un secteur spécifique, ou en termes de hiérarchie - pour trouver tous les descendants d'un nœud . Il serait également intéressant d'obtenir la «profondeur» du descendant ... Tout cela peut être nécessaire, par exemple, pour construire une sorte de sélection complexe à partir de la liste des identifiants de ces employés .Tout irait bien s'il n'y avait que quelques niveaux de ces descendants et quantitativement dans une douzaine, mais s'il y a plus de 5 niveaux et qu'il y a déjà des dizaines de descendants, il peut y avoir des problèmes. Voyons comment les options de recherche traditionnelles «en bas de l'arbre» sont écrites (et fonctionnent). Mais d'abord, nous déterminons lequel des nœuds sera le plus intéressant pour notre recherche.Les sous-arbres "les plus profonds" :WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
Les sous-arbres "les plus larges" :...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Pour ces requêtes, nous avons utilisé un JOIN récursif typique :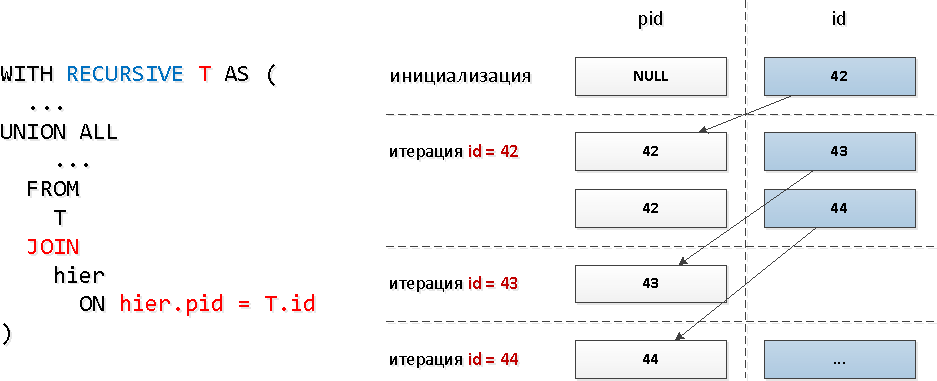 Évidemment, avec ce modèle de requête, le nombre d'itérations coïncidera avec le nombre total de descendants (et il y en a plusieurs dizaines), et cela peut prendre des ressources assez importantes et, par conséquent, du temps.Vérifions le sous-arbre "le plus large":
Évidemment, avec ce modèle de requête, le nombre d'itérations coïncidera avec le nombre total de descendants (et il y en a plusieurs dizaines), et cela peut prendre des ressources assez importantes et, par conséquent, du temps.Vérifions le sous-arbre "le plus large":WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
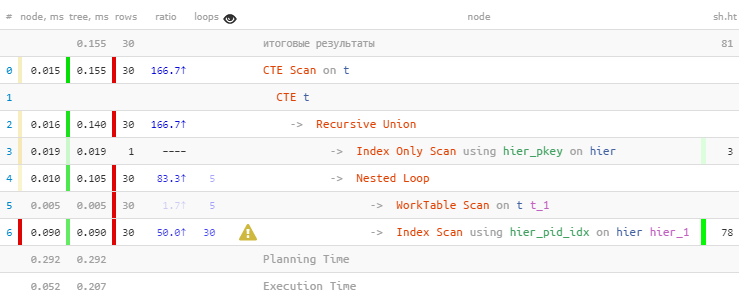 [regardezexpliquez.tensor.ru ] Comme prévu, nous avons trouvé les 30 entrées. Mais ils y ont consacré 60% du temps - car ils ont effectué 30 recherches sur l'index. Et moins - vous le pouvez?
[regardezexpliquez.tensor.ru ] Comme prévu, nous avons trouvé les 30 entrées. Mais ils y ont consacré 60% du temps - car ils ont effectué 30 recherches sur l'index. Et moins - vous le pouvez?Relecture en masse par index
Et pour chaque nœud, devons-nous faire une demande d'index distincte? Il s'avère que non - nous pouvons lire à partir de l'index sur plusieurs touches à la fois avec un seul appel= ANY(array) .Et dans chacun de ces groupes d'identifiants, nous pouvons prendre tous les identifiants trouvés à l'étape précédente par des «nœuds». Autrement dit, à chaque étape suivante, nous rechercherons immédiatement tous les descendants d'un certain niveau à la fois .Mais, par malchance, dans une sélection récursive, vous ne pouvez pas vous référer à vous-même dans une sous-requête , mais nous devons simplement sélectionner en quelque sorte exactement ce qui a été trouvé au niveau précédent ... Il s'avère que vous ne pouvez pas faire une sous-requête à l'ensemble de l'échantillon, mais à son champ spécifique - pouvez. Et ce champ peut également être un tableau - c'est ce que nous devons utiliserANY.Cela semble un peu sauvage, mais sur le diagramme - tout est simple.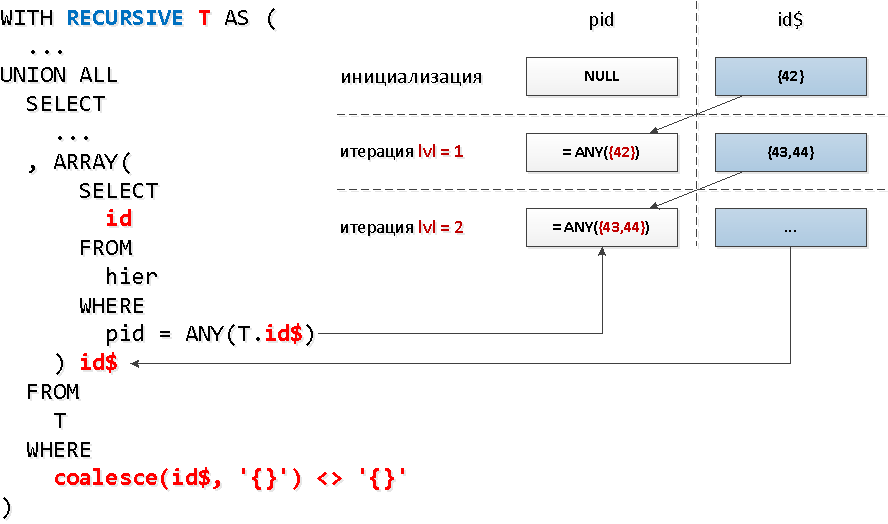
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [regardez expliquez.tensor.ru]Et ici, la chose la plus importante n'est même pas de gagner 1,5 fois dans le temps , mais que nous avons soustrait moins de tampons, car nous n'avons que 5 appels à l'index au lieu de 30!Un bonus supplémentaire est le fait qu'après la dernière version, les identifiants ne seront pas classés par «niveaux».
[regardez expliquez.tensor.ru]Et ici, la chose la plus importante n'est même pas de gagner 1,5 fois dans le temps , mais que nous avons soustrait moins de tampons, car nous n'avons que 5 appels à l'index au lieu de 30!Un bonus supplémentaire est le fait qu'après la dernière version, les identifiants ne seront pas classés par «niveaux».Balise de nœud
La prochaine considération qui contribuera à améliorer la productivité est que les «feuilles» ne peuvent pas avoir d’enfants , c’est-à-dire qu’elles n’ont pas besoin de regarder vers le bas. Dans la formulation de notre tâche, cela signifie que si nous suivons la chaîne des départements et atteignons l'employé, il n'est pas nécessaire de chercher plus loin dans cette branche.Introduisons un champ supplémentaireboolean dans notre table , qui nous dira tout de suite si cette entrée particulière dans notre arbre est un «nœud» - c'est-à-dire , si elle peut avoir des enfants.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
Bien! Il s'avère que seulement un peu plus de 30% de tous les éléments d'arbre ont des descendants.Maintenant, LATERALnous allons appliquer une mécanique légèrement différente - la connexion à la partie récursive , qui nous permettra d'accéder immédiatement aux champs de la "table" récursive, et d'utiliser la fonction d'agrégation avec la condition de filtre par l'attribut du nœud pour réduire le jeu de clés: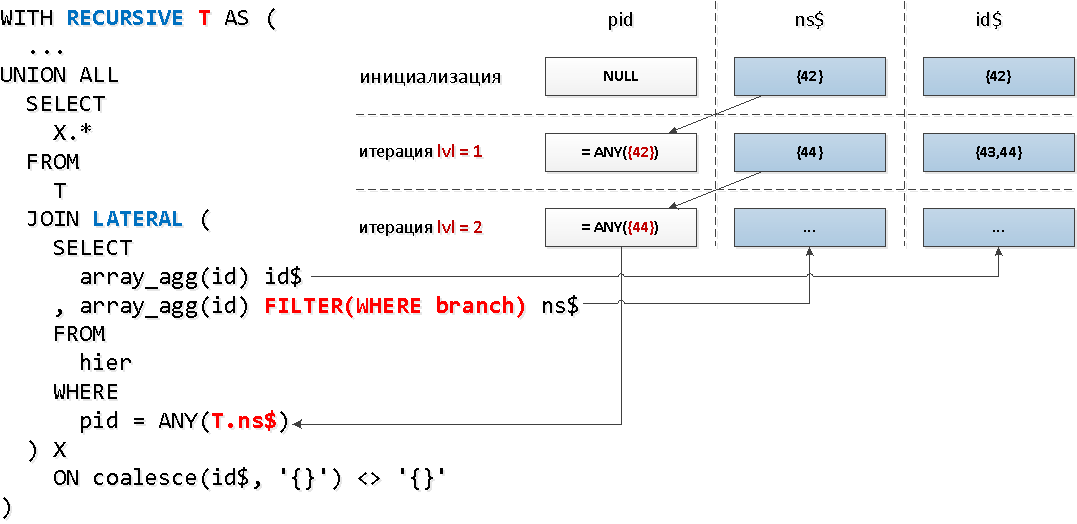
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [regardez expliquez.tensor.ru]Nous avons pu réduire un autre appel à l'indice et avons gagné plus de 2 fois en termes de montant déduit.
[regardez expliquez.tensor.ru]Nous avons pu réduire un autre appel à l'indice et avons gagné plus de 2 fois en termes de montant déduit.# 2 Retour aux sources
Cet algorithme sera utile si vous devez collecter des enregistrements pour tous les éléments «dans l'arborescence», tout en conservant des informations sur la feuille source (et avec quels indicateurs) qui l'a fait tomber dans l'échantillon - par exemple, pour générer un rapport récapitulatif avec agrégation des nœuds.La seconde doit être considérée exclusivement comme une preuve de concept, car la demande est très lourde. Mais s'il domine votre base de données - il vaut la peine d'envisager l'utilisation de telles techniques.Commençons par quelques déclarations simples:- Il est préférable de ne lire le même enregistrement de la base de données qu'une seule fois .
- Les entrées de la base de données sont lues plus efficacement dans un "ensemble" qu'individuellement.
Essayons maintenant de concevoir la requête dont nous avons besoin.Étape 1
Évidemment, lors de l'initialisation de la récursion (où sans elle!) Nous devrons soustraire les enregistrements des feuilles eux-mêmes de l'ensemble des identifiants de source:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
S'il semble étrange à quelqu'un que «l'ensemble» soit stocké dans une chaîne, pas dans un tableau, alors il y a une explication simple. Pour les chaînes, il existe une fonction intégrée de «collage» d'agrégation string_agg, mais pour les tableaux, non. Bien qu'il ne soit pas difficile de le mettre en œuvre vous-même .Étape 2
Maintenant, nous aurions un ensemble d'ID de section qui devront être soustraits davantage. Presque toujours, ils seront dupliqués dans différents enregistrements de l'ensemble source - nous les regrouperions donc tout en conservant les informations sur les feuilles source.Mais ici trois problèmes nous attendent:- La partie "sous-récursive" d'une requête ne peut pas contenir de fonctions d'agrégation c
GROUP BY. - Un appel à une «table» récursive ne peut pas être dans une sous-requête imbriquée.
- Une requête dans la partie récursive ne peut pas contenir un CTE.
Heureusement, tous ces problèmes sont facilement contournés. Commençons par la fin.CTE dans la partie récursive
Ce n'est pas comme ça que ça marche:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
Et donc ça marche, les parenthèses décident!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
Requête imbriquée pour une "table" récursive
Hmm ... Un appel à un CTE récursif ne peut pas être dans une sous-requête. Mais ça peut être à l'intérieur du CTE! Une sous-demande peut déjà faire référence à ce CTE!GROUPE PAR récursivité intérieure
C'est désagréable, mais ... Nous avons aussi un moyen simple de simuler GROUP BY en utilisant DISTINCT ONles fonctions de la fenêtre!SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
Et donc ça marche!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
Nous voyons maintenant pourquoi l'ID numérique s'est transformé en texte - afin qu'ils puissent être collés avec une virgule!Étape 3
Pour la finale, il ne nous reste plus rien:- nous lisons des enregistrements de "sections" sur un ensemble d'ID groupés
- faire correspondre les sections soustraites avec les «ensembles» de feuilles source
- "Développez" la chaîne définie à l'aide de
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
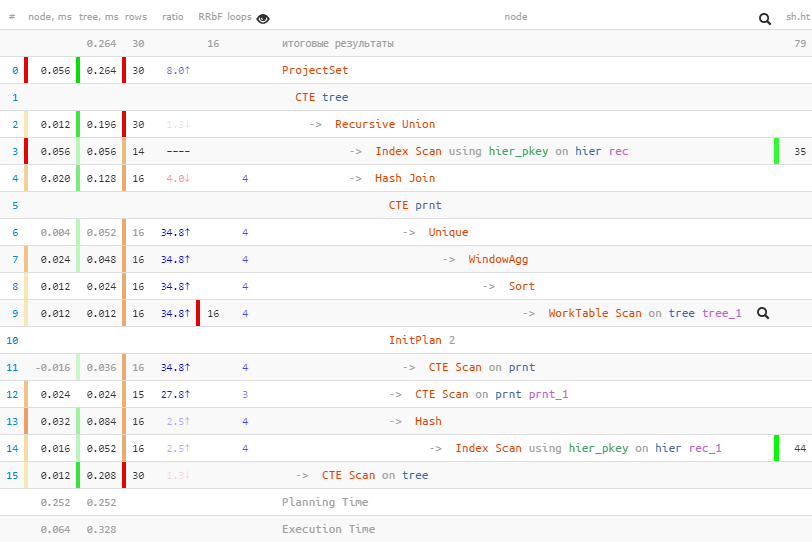 [ explain.tensor.ru]
[ explain.tensor.ru]