Dans Uchi.ru, nous essayons de déployer même de petites améliorations avec le test A / B, il y en avait plus de 250 au cours de cette année académique. Le test A / B est un puissant outil de test de changement, sans lequel il est difficile d'imaginer le développement normal d'un produit Internet. Dans le même temps, malgré l'apparente simplicité, de graves erreurs peuvent être commises lors du test A / B tant au stade de la conception de l'expérience que lors de la synthèse des résultats. Dans cet article, je parlerai de certains aspects techniques du test: comment nous déterminons la période de test, résumons et comment éviter les résultats erronés lorsque les tests sont terminés tôt et lors du test de plusieurs hypothèses à la fois. Un schéma de test A / B typique pour nous (et pour beaucoup) ressemble à ceci:
Un schéma de test A / B typique pour nous (et pour beaucoup) ressemble à ceci:- Nous développons une fonctionnalité, mais avant de la déployer à l'ensemble du public, nous voulons nous assurer qu'elle améliore la métrique cible, par exemple, l'engagement.
- Nous déterminons la période de lancement du test.
- Nous divisons au hasard les utilisateurs en deux groupes.
- Nous montrons à un groupe la version du produit avec des fonctionnalités (groupe expérimental), l'autre - l'ancienne (contrôle).
- Dans le processus, nous surveillons la métrique afin d'arrêter un test particulièrement infructueux à temps.
- Une fois le test expiré, nous comparons la métrique dans les groupes expérimental et témoin.
- Si la métrique dans le groupe expérimental est statistiquement significativement meilleure que dans le groupe témoin, nous déployons la fonctionnalité testée. S'il n'y a pas de signification statistique, nous terminons le test avec un résultat négatif.
Tout semble logique et simple, le diable, comme toujours, dans les détails.Signification statistique, critères et erreurs
Il y a un élément de caractère aléatoire dans tout test A / B: les métriques de groupe dépendent non seulement de leur fonctionnalité, mais aussi de ce que les utilisateurs y ont entré et de leur comportement. Pour tirer des conclusions fiables sur la supériorité d'un groupe, vous devez collecter suffisamment d'observations dans le test, mais même dans ce cas, vous n'êtes pas à l'abri des erreurs. Ils se distinguent par deux types:- Une erreur du premier type se produit si nous fixons la différence entre les groupes, bien qu'en réalité elle n'existe pas. Le texte contiendra également un terme équivalent - un résultat faussement positif. L'article est consacré à de telles erreurs.
- Une erreur du deuxième type se produit si nous corrigeons l'absence de différence, bien qu'elle le soit.
Avec un grand nombre d'expériences, il est important que la probabilité d'une erreur du premier type soit faible. Il peut être contrôlé à l'aide de méthodes statistiques. Par exemple, nous voulons que la probabilité d'une erreur du premier type dans chaque expérience ne dépasse pas 5% (ce n'est qu'une valeur pratique, vous pouvez en prendre une autre pour vos propres besoins). Ensuite, nous prendrons des expériences à un niveau de signification de 0,05:- Il existe un test A / B avec le groupe témoin A et le groupe expérimental B. Le but est de vérifier que le groupe B diffère du groupe A dans certaines mesures.
- Nous formulons l'hypothèse statistique nulle: les groupes A et B ne diffèrent pas et les différences observées s'expliquent par le bruit. Par défaut, nous pensons toujours qu'il n'y a pas de différence tant que le contraire n'est pas prouvé.
- Nous vérifions l'hypothèse avec une règle mathématique stricte - un critère statistique, par exemple, le critère de l'élève.
- En conséquence, nous obtenons la valeur de p. Il se situe dans la plage de 0 à 1 et signifie la probabilité de voir la différence actuelle ou plus extrême entre les groupes, à condition que l'hypothèse nulle soit vraie, c'est-à-dire en l'absence de différence entre les groupes.
- La valeur de p est comparée à un niveau de signification de 0,05. S'il est plus grand, nous acceptons l'hypothèse nulle qu'il n'y a pas de différences, sinon nous pensons qu'il existe une différence statistiquement significative entre les groupes.
Une hypothèse peut être testée avec un critère paramétrique ou non paramétrique. Les paramètres paramétriques reposent sur les paramètres de la distribution de l'échantillon d'une variable aléatoire et ont plus de puissance (ils font moins souvent des erreurs de deuxième type), mais ils imposent des exigences sur la distribution de la variable aléatoire à l'étude.Le test paramétrique le plus courant est le test de Student. Pour deux échantillons indépendants (cas de test A / B), il est parfois appelé critère de Welch. Ce critère fonctionne correctement si les quantités étudiées sont distribuées normalement. Il peut sembler que sur des données réelles, cette exigence n'est presque jamais satisfaite, mais en fait, le test nécessite une distribution normale des moyennes des échantillons, pas les échantillons eux-mêmes. En pratique, cela signifie que le critère peut être appliqué si vous avez beaucoup d'observations dans votre test (des dizaines à des centaines) et qu'il n'y a pas de queues très longues dans les distributions. La nature de la distribution des observations initiales est sans importance. Le lecteur peut vérifier indépendamment que le critère de Student fonctionne correctement même sur des échantillons générés à partir de Bernoulli ou de distributions exponentielles.Parmi les critères non paramétriques, le critère de Mann-Whitney est populaire. Il doit être utilisé si vos échantillons sont très petits ou ont de grandes valeurs aberrantes (la méthode compare les médianes, donc elle résiste aux valeurs aberrantes). De plus, pour que le critère fonctionne correctement, les échantillons doivent avoir peu de valeurs correspondantes. En pratique, nous n'avons jamais eu à appliquer des critères non paramétriques, dans nos tests nous utilisons toujours le critère étudiant.Le problème des tests d'hypothèses multiples
Le problème le plus évident et le plus simple: si dans le test, en plus du groupe témoin, il y en a plusieurs expérimentaux, résumer les résultats avec un niveau de signification de 0,05 entraînera une augmentation multiple de la proportion d'erreurs du premier type. En effet, à chaque application du critère statistique, la probabilité d'une erreur du premier type sera de 5%. Avec le nombre de groupes et niveau de signification la probabilité qu'un groupe expérimental gagne par hasard est:
Par exemple, pour trois groupes expérimentaux, nous obtenons 14,3% au lieu des 5% attendus. Le problème est résolu par la correction de Bonferroni pour les tests d'hypothèses multiples: il vous suffit de diviser le niveau de signification par le nombre de comparaisons (c'est-à-dire les groupes) et de travailler avec. Pour l'exemple ci-dessus, le niveau de signification, compte tenu de la modification, sera de 0,05 / 3 = 0,0167 et la probabilité d'au moins une erreur du premier type sera acceptable de 4,9%.Méthode Hill - Bonferroni— , , , .
p-value ,
:
P-value
. , p-value
, . - , . ( , ) p-value, . A/B- — , — .
À strictement parler, les comparaisons de groupes selon différentes mesures ou sections du public sont également sujettes au problème des tests multiples. Formellement, il est assez difficile de prendre en compte tous les contrôles, car leur nombre est difficile à prévoir à l'avance et parfois ils ne sont pas indépendants (surtout quand il s'agit de différentes métriques, pas de tranches). Il n'y a pas de recette universelle, comptez sur le bon sens et rappelez-vous que si vous vérifiez beaucoup de tranches en utilisant différentes mesures, alors dans n'importe quel test, vous pouvez voir un résultat statistiquement significatif. Ainsi, il faut faire attention, par exemple, à l'augmentation significative de la rétention du cinquième jour des nouveaux utilisateurs mobiles des grandes villes.Problème de voyance
Un cas particulier de test d'hypothèses multiples est le problème de l'aperçu. Le fait est que la valeur de p pendant le test peut tomber accidentellement en dessous du niveau de signification accepté. Si vous surveillez attentivement l'expérience, vous pouvez saisir ce moment et vous tromper sur la signification statistique.Supposons que nous nous éloignions de la configuration de test décrite au début de l'article et décidions de faire le point à un niveau de signification de 5% chaque jour (ou juste plus d'une fois pendant le test). En résumé, je comprends que le test est positif si la valeur p est inférieure à 0,05, et sa continuation sinon. Avec cette stratégie, la part des résultats faussement positifs sera proportionnelle au nombre de contrôles et atteindra le premier mois 28%. Une telle différence énorme semble contre-intuitive, c'est pourquoi nous nous tournons vers la méthodologie des tests A / A, qui est indispensable pour le développement de schémas de tests A / B.L'idée d'un test A / A est simple: simuler un grand nombre de tests A / B sur des données aléatoires avec un regroupement aléatoire. Il n'y a évidemment aucune différence entre les groupes, vous pouvez donc estimer avec précision la proportion d'erreurs du premier type dans votre schéma de test A / B. Le gif ci-dessous montre comment la valeur de p change par jour pour quatre de ces tests. Un niveau de signification égal à 0,05 est indiqué par une ligne en pointillés. Lorsque la valeur de p tombe en dessous, nous colorons le tracé de test en rouge. Si à ce moment les résultats du test étaient résumés, il serait considéré comme réussi.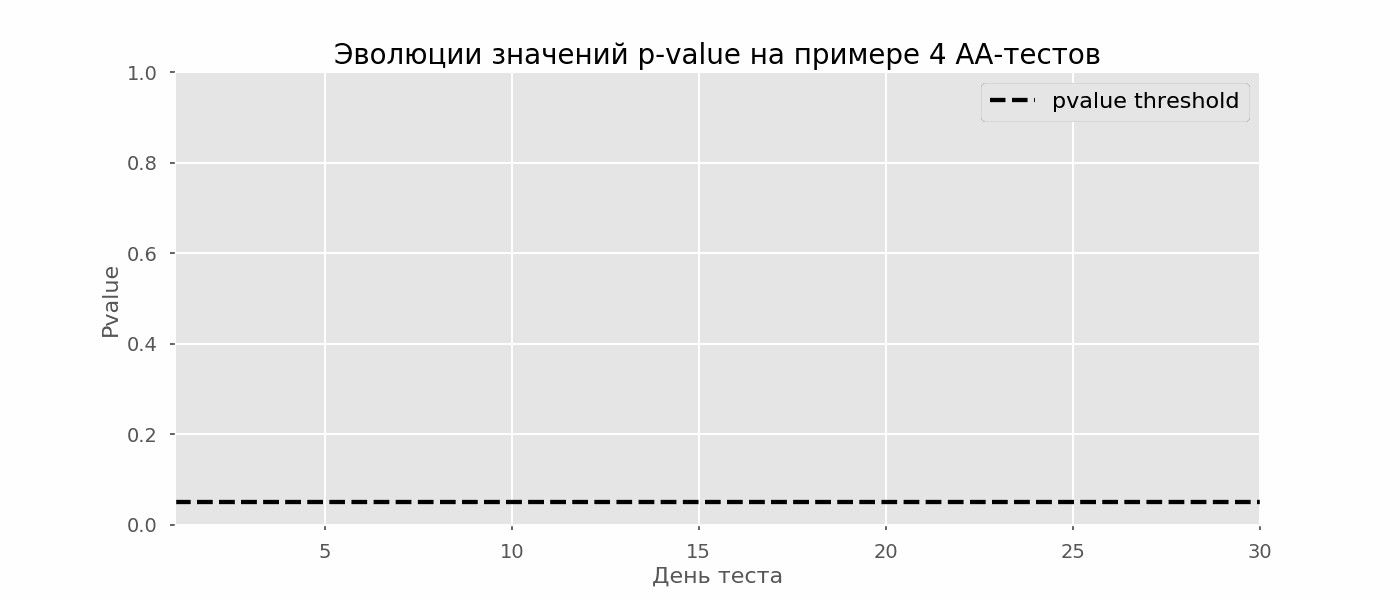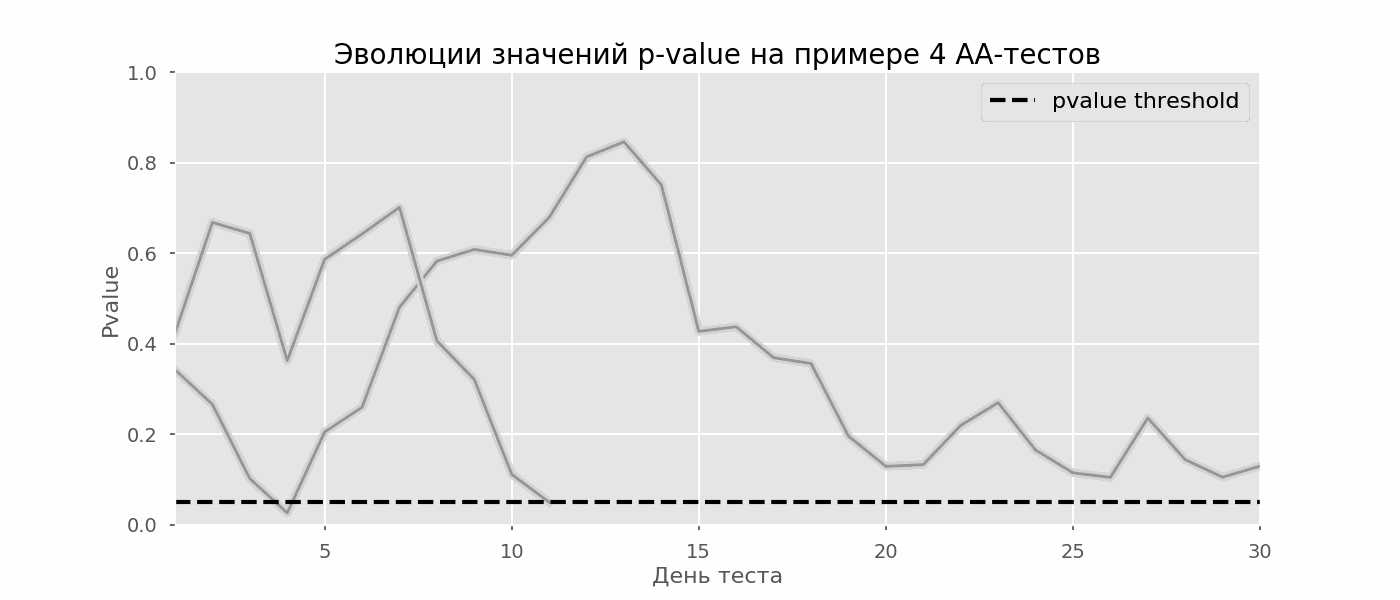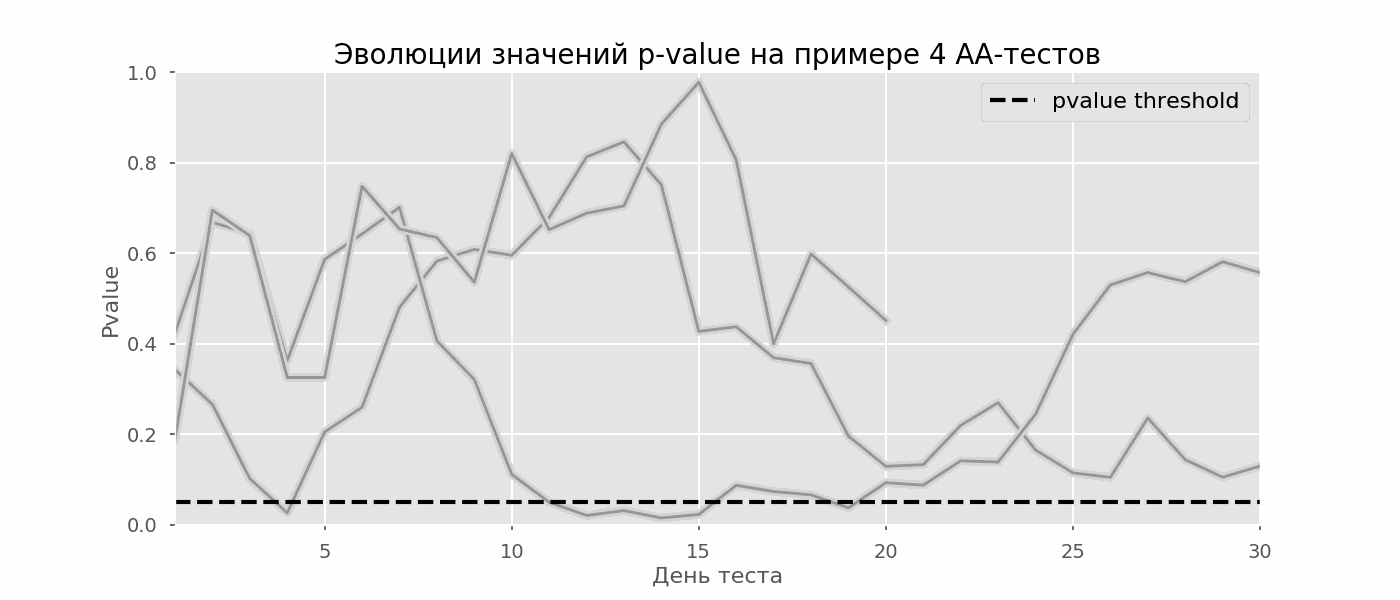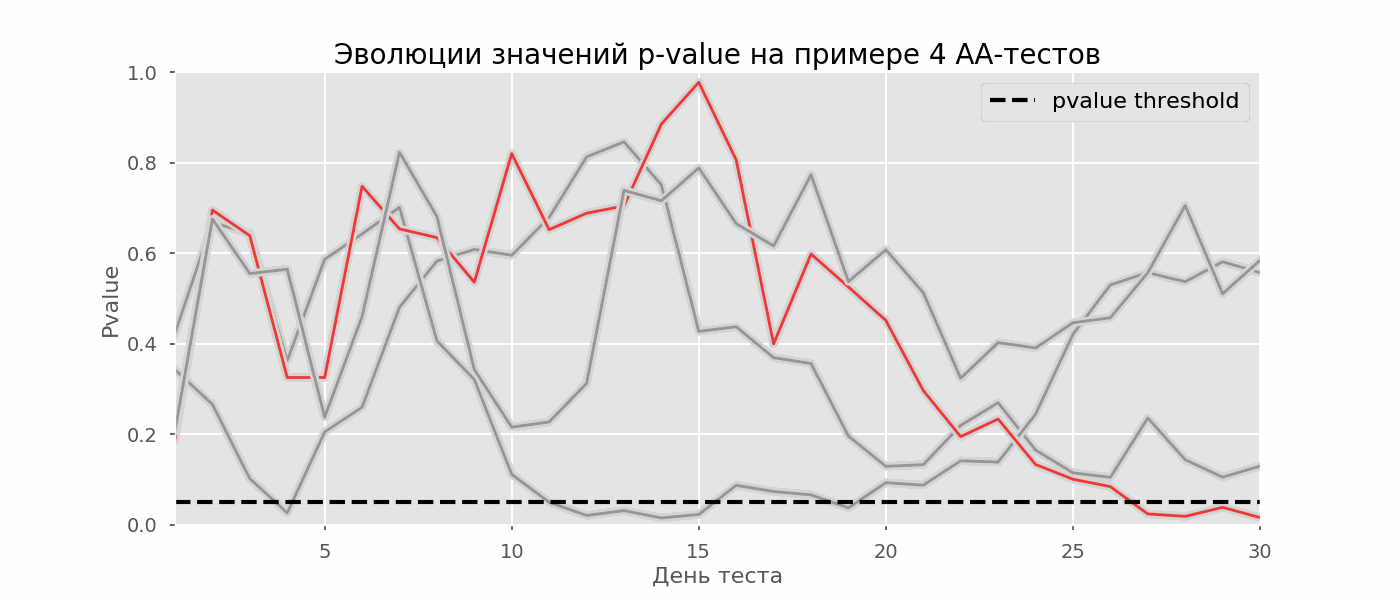 De même, nous calculons 10 000 tests A / A pendant un mois et comparons les fractions de résultats faussement positifs dans le schéma avec un résumé à la fin du trimestre et tous les jours. Pour plus de clarté, voici les horaires d'errance par jour de la valeur p pour les 100 premières simulations. Chaque ligne est la valeur de p d'un test, les trajectoires des tests sont surlignées en rouge, ce qui est finalement considéré à tort comme réussi (le plus petit est le mieux), la ligne en pointillés est la valeur de p requise pour reconnaître le test comme réussi.
De même, nous calculons 10 000 tests A / A pendant un mois et comparons les fractions de résultats faussement positifs dans le schéma avec un résumé à la fin du trimestre et tous les jours. Pour plus de clarté, voici les horaires d'errance par jour de la valeur p pour les 100 premières simulations. Chaque ligne est la valeur de p d'un test, les trajectoires des tests sont surlignées en rouge, ce qui est finalement considéré à tort comme réussi (le plus petit est le mieux), la ligne en pointillés est la valeur de p requise pour reconnaître le test comme réussi.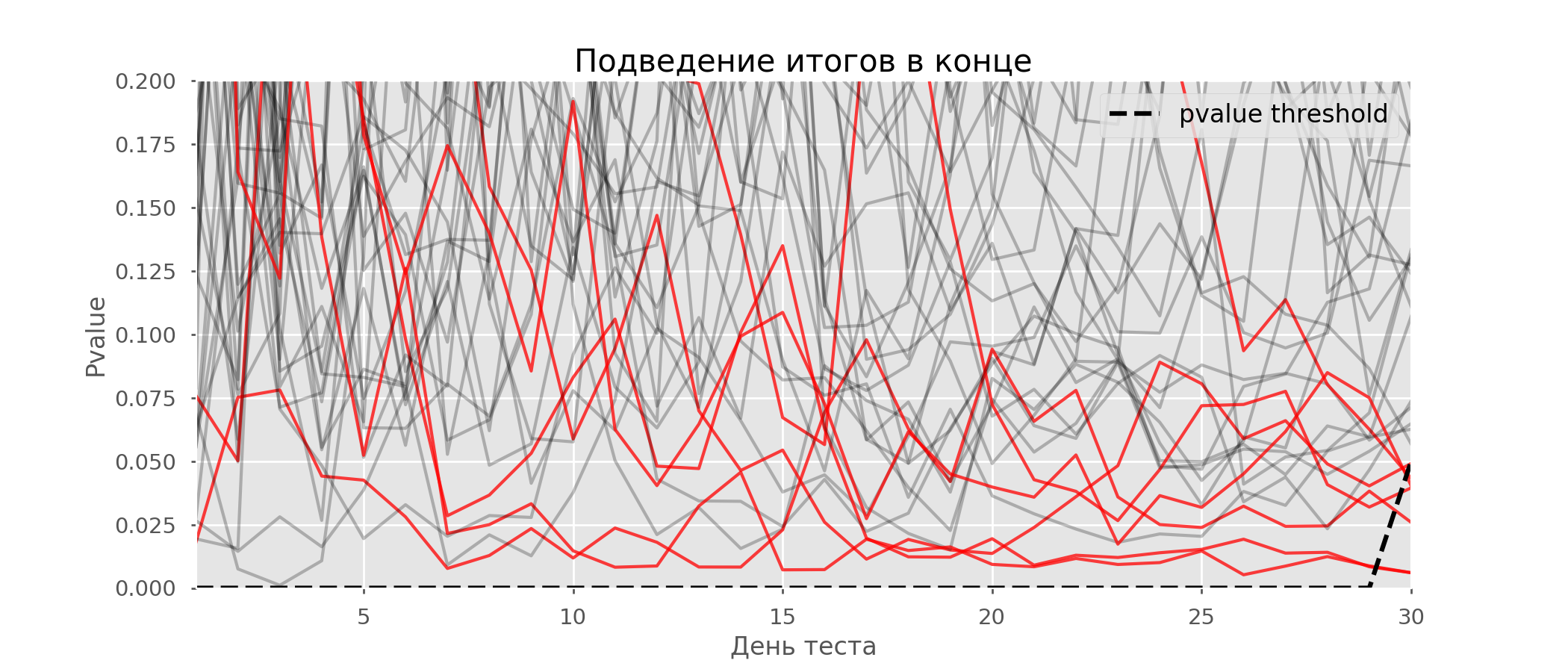 Sur le graphique, vous pouvez compter 7 tests faussement positifs, et au total, sur 10 000, 502, soit 5%. Il convient de noter que la valeur de p de nombreux tests au cours des observations est tombée en dessous de 0,05, mais à la fin des observations a dépassé le niveau de signification. Maintenant, évaluons le schéma de test avec un débriefing tous les jours:
Sur le graphique, vous pouvez compter 7 tests faussement positifs, et au total, sur 10 000, 502, soit 5%. Il convient de noter que la valeur de p de nombreux tests au cours des observations est tombée en dessous de 0,05, mais à la fin des observations a dépassé le niveau de signification. Maintenant, évaluons le schéma de test avec un débriefing tous les jours: Il y a tellement de lignes rouges que rien n'est clair. Nous redessinerons en cassant les lignes de test dès que leur valeur p atteindra une valeur critique: il
Il y a tellement de lignes rouges que rien n'est clair. Nous redessinerons en cassant les lignes de test dès que leur valeur p atteindra une valeur critique: il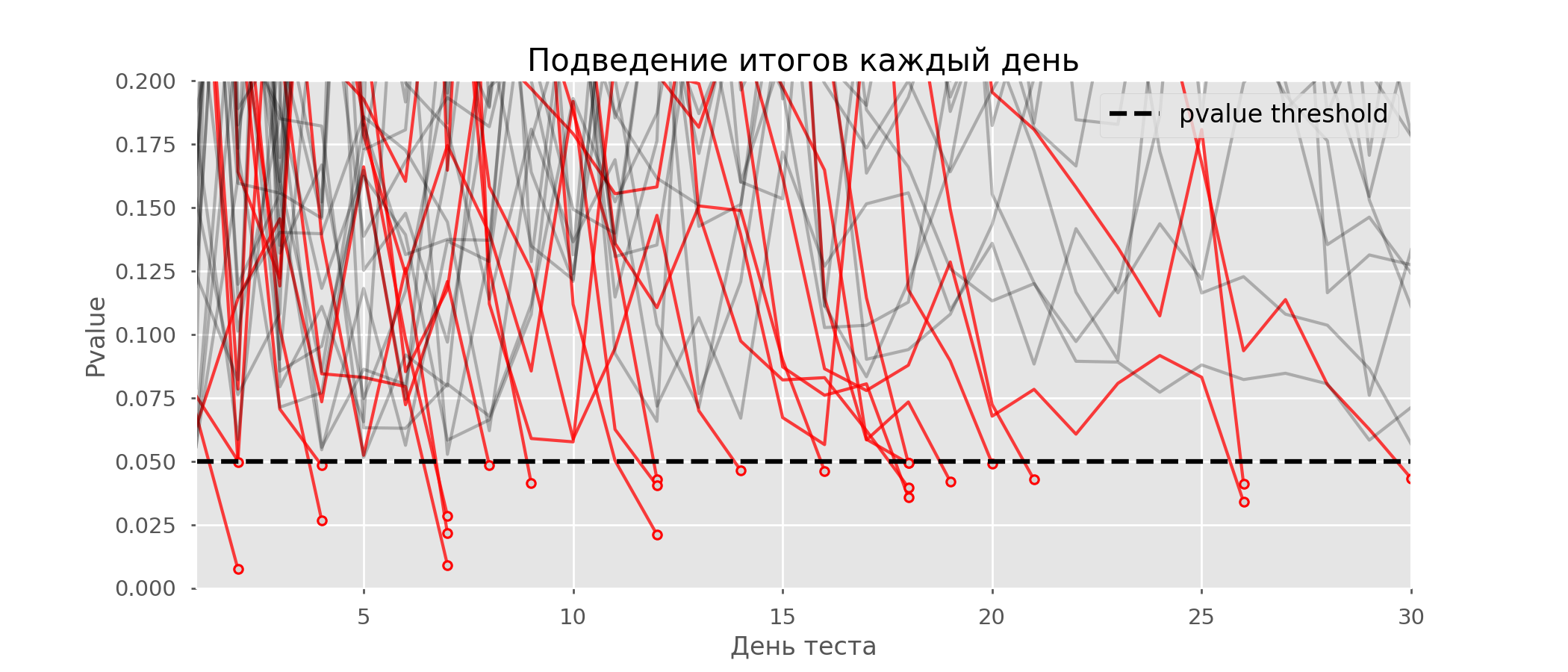 y aura 2813 tests de faux positifs sur 10 000, soit 28%. Il est clair qu'un tel système n'est pas viable.Bien que le problème de l'aperçu soit un cas particulier de tests multiples, cela ne vaut pas la peine d'appliquer des corrections standard (Bonferroni et autres) car elles se révéleront trop conservatrices. Le graphique ci-dessous montre le pourcentage de faux positifs en fonction du nombre de groupes testés (ligne rouge) et du nombre de peeps (ligne verte).
y aura 2813 tests de faux positifs sur 10 000, soit 28%. Il est clair qu'un tel système n'est pas viable.Bien que le problème de l'aperçu soit un cas particulier de tests multiples, cela ne vaut pas la peine d'appliquer des corrections standard (Bonferroni et autres) car elles se révéleront trop conservatrices. Le graphique ci-dessous montre le pourcentage de faux positifs en fonction du nombre de groupes testés (ligne rouge) et du nombre de peeps (ligne verte).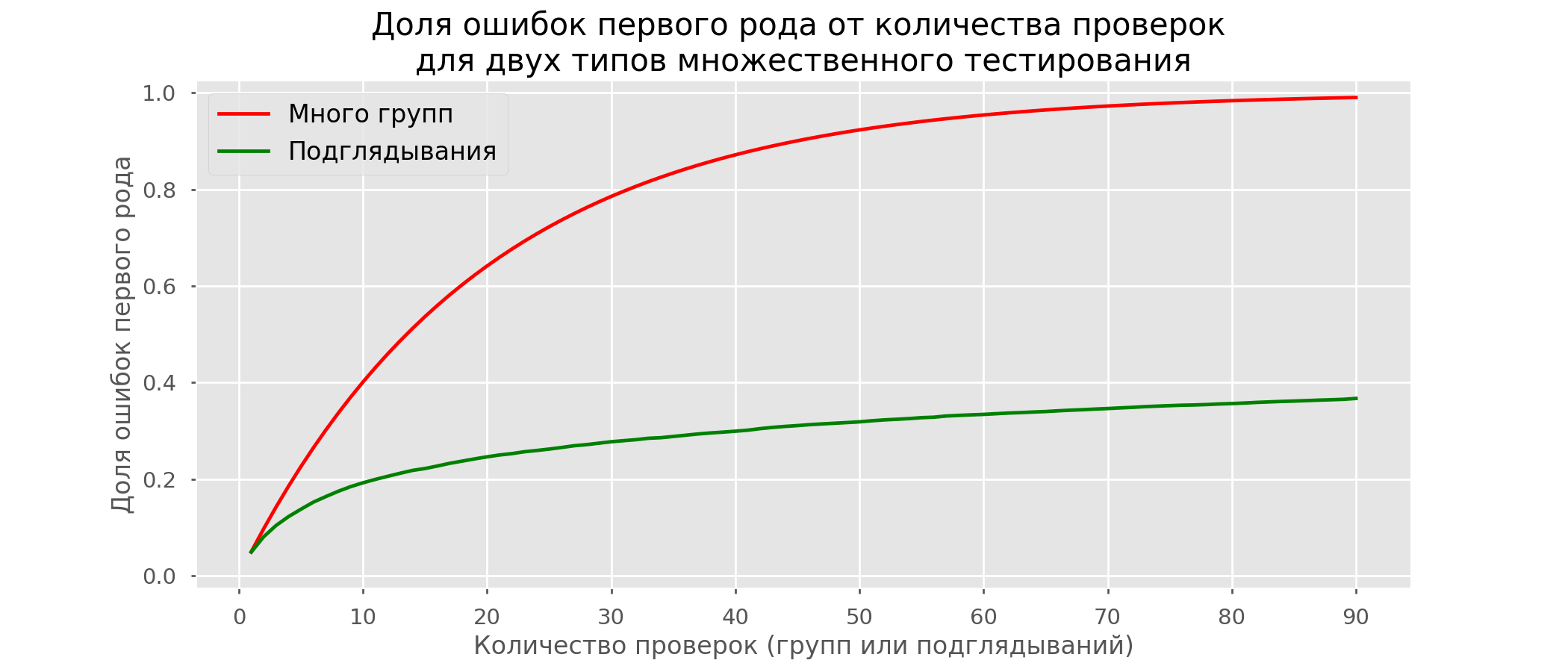 Bien qu'à l'infini et en lorgnant on s'approche de 1, la proportion d'erreurs croît beaucoup plus lentement. En effet, les comparaisons dans ce cas ne sont plus indépendantes.
Bien qu'à l'infini et en lorgnant on s'approche de 1, la proportion d'erreurs croît beaucoup plus lentement. En effet, les comparaisons dans ce cas ne sont plus indépendantes.Approche bayésienne et problème du voyeur Premières méthodes de test
Il existe des options de test qui vous permettent de passer le test prématurément. Je vais en parler deux: avec un niveau de signification constant (correction Pocock) et dépendant du nombre de peeps (correction O'Brien-Fleming). À strictement parler, pour les deux corrections, vous devez connaître à l'avance la période de test maximale et le nombre de contrôles entre le début et la fin du test. De plus, les contrôles devraient avoir lieu à des intervalles de temps approximativement égaux (ou à des quantités égales d'observations).Pocock
La méthode consiste à résumer chaque jour les résultats des tests, mais avec un niveau de signification réduit (plus strict). Par exemple, si nous savons que nous ne ferons pas plus de 30 vérifications, le niveau de signification doit être fixé à 0,006 (sélectionné en fonction du nombre de coups d'œil utilisant la méthode de Monte Carlo, c'est-à-dire empiriquement). Dans notre simulation, nous obtenons 4% de faux positifs - apparemment, le seuil pourrait être augmenté. Malgré l'apparente naïveté, certaines grandes entreprises utilisent cette méthode particulière. C'est très simple et fiable si vous prenez des décisions sur des mesures sensibles et sur beaucoup de trafic. Par exemple, dans Avito, par défaut , le niveau de signification est défini sur 0,005 .
Malgré l'apparente naïveté, certaines grandes entreprises utilisent cette méthode particulière. C'est très simple et fiable si vous prenez des décisions sur des mesures sensibles et sur beaucoup de trafic. Par exemple, dans Avito, par défaut , le niveau de signification est défini sur 0,005 .O'Brien-Fleming
Dans cette méthode, le niveau de signification varie en fonction du numéro de vérification. Il est nécessaire de déterminer à l'avance le nombre d'étapes (ou de peeps) dans le test et de calculer le niveau de signification pour chacune d'entre elles. Plus tôt nous essaierons de terminer le test, plus les critères seront rigoureux. Seuils statistiques des étudiants (y compris la valeur à la dernière étape ) correspondant au niveau de signification souhaité dépendent du numéro de vérification (prend des valeurs de 1 au nombre total de contrôles inclus) et sont calculés selon la formule obtenue empiriquement:
Code de cotesfrom sklearn.linear_model import LinearRegression
from sklearn.metrics import explained_variance_score
import matplotlib.pyplot as plt
total_steps = [
2, 3, 4, 5, 6, 8, 10, 15, 20, 25, 30, 50, 60
]
last_z = [
1.969, 1.993, 2.014, 2.031, 2.045, 2.066, 2.081,
2.107, 2.123, 2.134, 2.143, 2.164, 2.17
]
features = [
[1/t, 1/t**0.5] for t in total_steps
]
lr = LinearRegression()
lr.fit(features, last_z)
print(lr.coef_)
print(lr.intercept_)
print(explained_variance_score(lr.predict(features), last_z))
total_steps_extended = np.arange(2, 80)
features_extended = [ [1/t, 1/t**0.5] for t in total_steps_extended ]
plt.plot(total_steps_extended, lr.predict(features_extended))
plt.scatter(total_steps, last_z, s=30, color='black')
plt.show()
Les niveaux de signification pertinents sont calculés par le percentile distribution standard correspondant à la valeur des statistiques des élèves :perc = scipy.stats.norm.cdf(Z)
pval_thresholds = (1 − perc) * 2
Sur les mêmes simulations, cela ressemble à ceci: les résultats faussement positifs étaient de 501 sur 10 000, soit les 5% attendus. Veuillez noter que le niveau de signification n'atteint pas une valeur de 5% même à la fin, car ces 5% devraient être "étalés" sur tous les contrôles. Dans l'entreprise, nous utilisons cette correction même si nous effectuons un test avec la possibilité d'un arrêt précoce. Vous pouvez lire sur le même et d'autres amendements ici .
les résultats faussement positifs étaient de 501 sur 10 000, soit les 5% attendus. Veuillez noter que le niveau de signification n'atteint pas une valeur de 5% même à la fin, car ces 5% devraient être "étalés" sur tous les contrôles. Dans l'entreprise, nous utilisons cette correction même si nous effectuons un test avec la possibilité d'un arrêt précoce. Vous pouvez lire sur le même et d'autres amendements ici .Méthode optimiséeOptimizely , , . , . , . O'Brien-Fleming’a .
Calculatrice de test A / B
Les spécificités de notre produit sont telles que la distribution de toute métrique varie considérablement en fonction de l'audience du test (par exemple, le numéro de classe) et la période de l'année. Par conséquent, il ne sera pas possible d'accepter les règles pour la date de fin du test dans l'esprit de «le test se terminera lorsque 1 million d'utilisateurs seront saisis dans chaque groupe» ou «le test se terminera lorsque le nombre de tâches résolues atteindra 100 millions». Autrement dit, cela fonctionnera, mais dans la pratique, pour cela, il sera nécessaire de prendre en compte trop de facteurs:- quelles classes entrent dans le test;
- le test est distribué aux enseignants ou aux élèves;
- temps de l'année académique;
- test pour tous les utilisateurs ou seulement pour les nouveaux.
Cependant, dans nos schémas de test A / B, vous devez toujours fixer la date de fin à l'avance. Pour prévoir la durée du test, nous avons développé une application interne - calculatrice de test A / B. En fonction de l'activité des utilisateurs du segment sélectionné au cours de l'année écoulée, l'application calcule la période pendant laquelle le test doit être exécuté afin de fixer de manière significative le soulèvement en X% par la métrique sélectionnée. La correction pour plusieurs tests est également prise en compte automatiquement et des niveaux de signification de seuil sont calculés pour un arrêt de test précoce.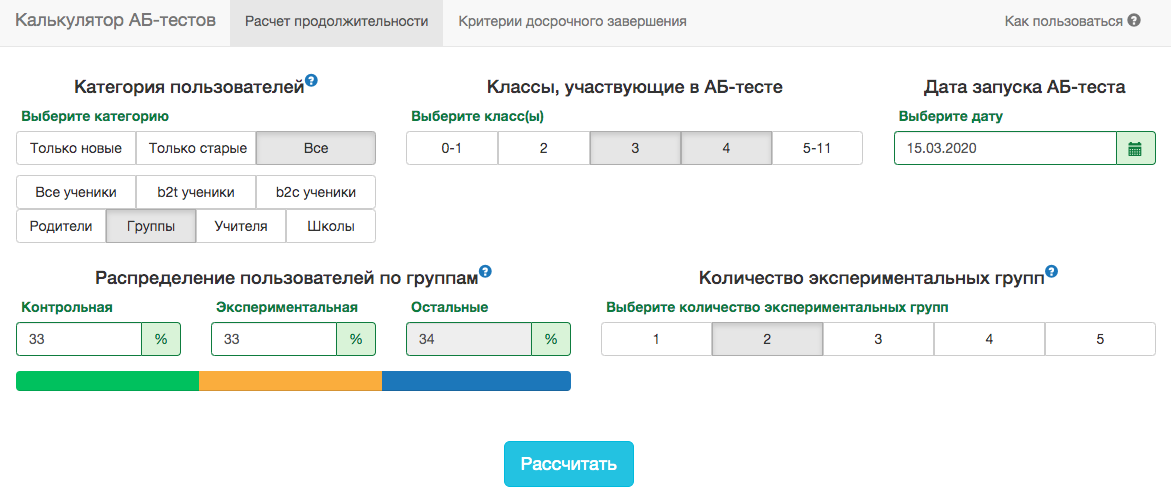 Toutes les métriques sont calculées au niveau des objets de test. Si la métrique est le nombre de problèmes résolus, alors dans le test au niveau de l'enseignant, ce sera la somme des problèmes résolus par ses élèves. Puisque nous utilisons le critère de l'étudiant, nous pouvons pré-calculer les agrégats nécessaires au calculateur pour toutes les tranches possibles. Pour chaque jour depuis le début du test, vous devez connaître le nombre de personnes dans le test, la valeur moyenne de la métrique et sa variance . Fixation des parts du groupe de contrôlegroupe expérimental et gain attendu du test en pourcentage, vous pouvez calculer les valeurs attendues des statistiques des élèves et la valeur de p correspondante pour chaque jour du test:
Toutes les métriques sont calculées au niveau des objets de test. Si la métrique est le nombre de problèmes résolus, alors dans le test au niveau de l'enseignant, ce sera la somme des problèmes résolus par ses élèves. Puisque nous utilisons le critère de l'étudiant, nous pouvons pré-calculer les agrégats nécessaires au calculateur pour toutes les tranches possibles. Pour chaque jour depuis le début du test, vous devez connaître le nombre de personnes dans le test, la valeur moyenne de la métrique et sa variance . Fixation des parts du groupe de contrôlegroupe expérimental et gain attendu du test en pourcentage, vous pouvez calculer les valeurs attendues des statistiques des élèves et la valeur de p correspondante pour chaque jour du test:
Ensuite, il est facile d'obtenir des valeurs de p pour chaque jour:pvalue = (1 − scipy.stats.norm.cdf(ttest_stat_value)) * 2
Connaissant la valeur de p et le niveau de signification, en tenant compte de toutes les corrections pour chaque jour du test, pour n'importe quelle durée du test, vous pouvez calculer le soulèvement minimum qui peut être détecté (dans la littérature anglaise - MDE, effet détectable minimal). Après cela, il est facile de résoudre le problème inverse - pour déterminer le nombre de jours requis pour identifier le soulèvement attendu.Conclusion
En conclusion, je souhaite rappeler les principaux messages de l'article:- Si vous comparez les valeurs moyennes de la métrique en groupes, très probablement, le critère Étudiant vous conviendra. L'exception est des tailles d'échantillon extrêmement petites (des dizaines d'observations) ou des distributions métriques anormales (en pratique, je ne les ai pas vues).
- S'il y a plusieurs groupes dans le test, utilisez les corrections pour les tests d'hypothèses multiples. La correction de Bonferroni la plus simple fera l'affaire.
- .
- . .
- . , , , , O'Brien-Fleming.
- A/B-, A/A-.
Malgré tout ce qui précède, les affaires et le bon sens ne devraient pas souffrir au nom de la rigueur mathématique. Parfois, il est possible de déployer des fonctionnalités pour tout ce qui n'a pas montré une augmentation significative du test, certains changements se produisent inévitablement sans test du tout. Mais si vous effectuez des centaines de tests par an, leur analyse précise est particulièrement importante. Sinon, il existe un risque que le nombre de tests faussement positifs soit comparable à des tests vraiment utiles.