 Bonjour, habrozhiteli! Paul et Harvey Daytels offrent un nouveau regard sur Python et utilisent une approche unique pour résoudre rapidement les problèmes auxquels sont confrontés les informaticiens modernes.À votre disposition plus de cinq cents tâches réelles - des fragments à 40 grands scénarios et exemples avec une implémentation complète. IPython avec Jupyter Notebooks vous permet d'apprendre rapidement les idiomes de programmation Python modernes. Les chapitres 1 à 5 et des fragments des chapitres 6 à 7 fourniront des exemples clairs de résolution des problèmes d'intelligence artificielle des chapitres 11 à 16. Vous en apprendrez plus sur le traitement du langage naturel, l'analyse des émotions sur Twitter, l'informatique cognitive IBM Watson, l'apprentissage automatique avec un enseignant en problèmes de classification et de régression, l'apprentissage automatique sans enseignant en clustering, la reconnaissance de formes avec l'apprentissage profond et les réseaux de neurones convolutionnels, les réseaux de neurones récurrents, les grands les données de Hadoop, Spark et NoSQL, IoT, etc. Vous travaillerez (directement ou indirectement) avec des services cloud, notamment Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, etc.
Bonjour, habrozhiteli! Paul et Harvey Daytels offrent un nouveau regard sur Python et utilisent une approche unique pour résoudre rapidement les problèmes auxquels sont confrontés les informaticiens modernes.À votre disposition plus de cinq cents tâches réelles - des fragments à 40 grands scénarios et exemples avec une implémentation complète. IPython avec Jupyter Notebooks vous permet d'apprendre rapidement les idiomes de programmation Python modernes. Les chapitres 1 à 5 et des fragments des chapitres 6 à 7 fourniront des exemples clairs de résolution des problèmes d'intelligence artificielle des chapitres 11 à 16. Vous en apprendrez plus sur le traitement du langage naturel, l'analyse des émotions sur Twitter, l'informatique cognitive IBM Watson, l'apprentissage automatique avec un enseignant en problèmes de classification et de régression, l'apprentissage automatique sans enseignant en clustering, la reconnaissance de formes avec l'apprentissage profond et les réseaux de neurones convolutionnels, les réseaux de neurones récurrents, les grands les données de Hadoop, Spark et NoSQL, IoT, etc. Vous travaillerez (directement ou indirectement) avec des services cloud, notamment Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, etc.9.12.2. Lecture de fichiers CSV dans la collection DataFrame de la bibliothèque pandas
Les sections «Introduction à la science des données» des deux chapitres précédents ont présenté les bases du travail avec les pandas. Nous allons maintenant montrer les outils pandas pour télécharger des fichiers CSV, puis effectuer les opérations d'analyse de données de base.Jeux de données
Dans des exemples pratiques de science des données, divers ensembles de données libres et ouverts seront utilisés pour démontrer les concepts de l'apprentissage automatique et du traitement du langage naturel. Une grande variété d'ensembles de données gratuits est disponible sur Internet. Le référentiel Rdatasets populaire contient des liens vers plus de 1 100 jeux de données CSV gratuits. Ces kits étaient à l'origine fournis avec le langage de programmation R pour simplifier l'étude et le développement de programmes statistiques, mais ils ne sont pas liés au langage R. Maintenant, ces jeux de données sont disponibles sur GitHub à l' adresse :https://vincentarelbundock.imtqy.com/Rdatasets/ datasets.htmlCe référentiel est si populaire qu'il existe un module pydataset conçu spécifiquement pour accéder aux Rdatasets. Pour obtenir des instructions sur l'installation de pydataset et l'accès aux ensembles de données, accédez à:https://github.com/iamaziz/PyDataset
Une autre excellente source d'ensembles de données:https://github.com/awesomedata/awesome-public-datasetsL'un des ensembles de données d'apprentissage automatique couramment utilisés pour les débutants est l'ensemble de données sur le crash du Titanic, qui répertorie tous les passagers et s'ils ont survécu lorsque le Titanic est entré en collision avec un iceberg et a coulé du 14 au 15 avril 1912. Nous utiliserons cet ensemble pour montrer comment charger un ensemble de données, afficher ses données et dériver des statistiques descriptives. D'autres ensembles de données populaires seront explorés dans les chapitres d'exemple de science des données plus loin dans ce livre.Utilisation de fichiers CSV locauxPour charger un ensemble de données CSV dans un DataFrame, vous pouvez utiliser la fonction read_csv de la bibliothèque pandas. L'extrait de code suivant télécharge et affiche le fichier CSV accounts.csv créé précédemment dans ce chapitre:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
L'argument names spécifie les noms de colonne du DataFrame. Sans cet argument, read_csv considère que la première ligne du fichier CSV contient une liste de noms de colonnes séparés par des virgules.Pour enregistrer les données DataFrame dans un fichier CSV, appelez la méthode to_csv de la collection DataFrame:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
L'index d'argument clé = False signifie que les noms de ligne (0–4 sur le côté gauche de la sortie DataFrame dans le fragment [3]) ne doivent pas être écrits dans le fichier. La première ligne du fichier résultant contient les noms des colonnes:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3. Lecture de l'ensemble de données sur les catastrophes du Titanic
L'ensemble de données Titanic en cas de catastrophe est l'un des ensembles de données d'apprentissage automatique les plus populaires et est disponible dans de nombreux formats, y compris CSV.Téléchargez le Titanic Disaster Dataset à l'URL
Si vous avez une URL représentant un ensemble de données au format CSV, vous pouvez le charger dans un DataFrame avec la fonction read_csv - disons depuis GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
Affichage de certaines lignes de l'ensemble de données sur les catastrophes du Titanic L'ensemble de donnéescontient plus de 1 300 lignes, chaque ligne représente un passager. Selon Wikipédia, il y avait environ 1317 passagers à bord et 815 d'entre eux sont morts1. Pour les ensembles de données volumineux, seules les 30 premières lignes sont affichées lors de la sortie du DataFrame, puis les points de suspension «...» et les 30 dernières lignes sont affichés. Pour économiser de l'espace, nous allons examiner les cinq premières et dernières lignes en utilisant les méthodes head et tail de la collection DataFrame. Les deux méthodes renvoient cinq lignes par défaut, mais le nombre de lignes affichées peut être passé dans l'argument:In [3]: pd.set_option ('precision', 2) # Format pour les valeurs à virgule flottanteRemarque: pandas ajuste la largeur de chaque colonne en fonction de la valeur la plus large du nom de la colonne ou de la colonne (selon celle qui a la plus grande largeur); dans la colonne d'âge de la ligne 1305 est NaN - un signe d'une valeur manquante dans l'ensemble de données.Définition des noms de colonneLe nom de la première colonne de l'ensemble de données semble plutôt étrange ('Sans nom: 0'). Ce problème peut être résolu en personnalisant les noms de colonne. Remplacez «Sans nom: 0» par «nom» et réduisez «classe passager» à «classe»:

9.12.4. Analyse de données simple en utilisant l'ensemble de données sur les catastrophes du Titanic comme exemple
Nous allons maintenant utiliser des pandas pour effectuer une simple analyse de données en utilisant à titre d'exemple certaines caractéristiques des statistiques descriptives. Lorsque vous appelez describe pour une collection DataFrame qui contient à la fois des colonnes numériques et non numériques, describe calcule les caractéristiques statistiques pour les colonnes numériques uniquement - dans ce cas, uniquement pour la colonne d'âge: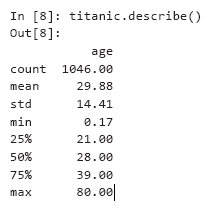 Notez les différences de nombre (1046) et le nombre de lignes de données dans l'ensemble de données (1309 - lors de l'appel de la queue, l'index de la dernière ligne était 1308). Seules 1046 lignes de données (valeur de comptage) contenaient une valeur d'âge. Le reste des résultats manquait et était marqué avec NaN, comme dans la ligne 1305. Lors des calculs, la bibliothèque pandas ignore les données manquantes (NaN) par défaut. Pour 1046 passagers ayant un âge valide, l'âge moyen (attente) était de 29,88 ans. Le plus jeune passager (min) n'avait que deux mois (0,17 * 12 donne 2,04) et le plus âgé (max) avait 80 ans. L'âge médian était de 28 ans (indiqué par un quartile de 50%). Le quartile de 25 pour cent décrit l'âge médian dans la première moitié des passagers (classé par âge),et le quartile à 75% est la médiane de la seconde moitié des passagers.Supposons que vous souhaitiez calculer des statistiques sur les passagers survivants. Nous pouvons comparer la colonne survivante avec la valeur «oui» pour obtenir une nouvelle collection Series avec des valeurs Vrai / Faux, puis utiliser la description pour décrire les résultats:
Notez les différences de nombre (1046) et le nombre de lignes de données dans l'ensemble de données (1309 - lors de l'appel de la queue, l'index de la dernière ligne était 1308). Seules 1046 lignes de données (valeur de comptage) contenaient une valeur d'âge. Le reste des résultats manquait et était marqué avec NaN, comme dans la ligne 1305. Lors des calculs, la bibliothèque pandas ignore les données manquantes (NaN) par défaut. Pour 1046 passagers ayant un âge valide, l'âge moyen (attente) était de 29,88 ans. Le plus jeune passager (min) n'avait que deux mois (0,17 * 12 donne 2,04) et le plus âgé (max) avait 80 ans. L'âge médian était de 28 ans (indiqué par un quartile de 50%). Le quartile de 25 pour cent décrit l'âge médian dans la première moitié des passagers (classé par âge),et le quartile à 75% est la médiane de la seconde moitié des passagers.Supposons que vous souhaitiez calculer des statistiques sur les passagers survivants. Nous pouvons comparer la colonne survivante avec la valeur «oui» pour obtenir une nouvelle collection Series avec des valeurs Vrai / Faux, puis utiliser la description pour décrire les résultats:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
Pour les données non numériques, décrire affiche diverses caractéristiques des statistiques descriptives:- count - le nombre total d'éléments dans le résultat;
- unique - le nombre de valeurs uniques (2) en conséquence - Vrai (le passager a survécu) ou Faux (le passager est décédé);
- top - la valeur la plus souvent rencontrée en conséquence;
- freq - le nombre d'occurrences de la valeur top.
9.12.5. Graphique à barres de l'âge des passagers
La visualisation est un bon moyen de mieux connaître les données. Pandas contient de nombreux outils de visualisation intégrés basés sur Matplotlib. Pour les utiliser, activez d'abord la prise en charge de Matplotlib dans IPython:In [10]: %matplotlib
L'histogramme montre clairement la distribution des données numériques sur une plage de valeurs. La méthode hist de la collection DataFrame analyse automatiquement les données de chaque colonne numérique et crée l'histogramme correspondant. Pour afficher les histogrammes de chaque colonne numérique de données, appelez hist pour votre collection DataFrame:In [11]: histogram = titanic.hist()
L'ensemble de données sur les catastrophes du Titanic ne contient qu'une seule colonne numérique de données, de sorte que le graphique affiche un histogramme pour la répartition par âge. Pour les jeux de données avec plusieurs colonnes numériques, hist crée un histogramme distinct pour chaque colonne numérique.»Plus d'informations sur le livre peuvent être trouvées sur le site Web de l' éditeur» Contenu» Extraitpour Khabrozhiteley 25% de réduction sur les coupons - PythonLors du paiement de la version papier du livre (date de sortie - 5 juin ), un livre électronique est envoyé par e-mail.