Le clustering est une chose tellement magique: il transforme une grande quantité de données non structurées en un ensemble potentiellement visible de clusters, dont l'analyse nous permet de tirer des conclusions sur le contenu de ces données.
Il existe de nombreuses applications pour les méthodes de clustering. Par exemple, nous regroupons les requêtes de recherche afin d'augmenter la capacité de généralisation des algorithmes de classement: toutes les statistiques calculées à partir d'un groupe de requêtes similaires sont plus fiables que les mêmes statistiques calculées pour une requête distincte. Le clustering vous permet d'améliorer la qualité des requêtes avec des formulations rarement rencontrées. Un autre exemple clair est Yandex.News, qui génère automatiquement des reportages.
En 2013, j'ai eu la chance de participer au développement d'un algorithme de clustering très complexe. Il fallait regrouper des centaines de milliers d'objets de très haute qualité et le faire rapidement: en quelques dizaines de secondes sur une même machine. La première étape a été de construire un système d'évaluation de la qualité, et dans cet article, j'en parlerai.

, , , .
, : , , , /- . , . — .
1.
, . .
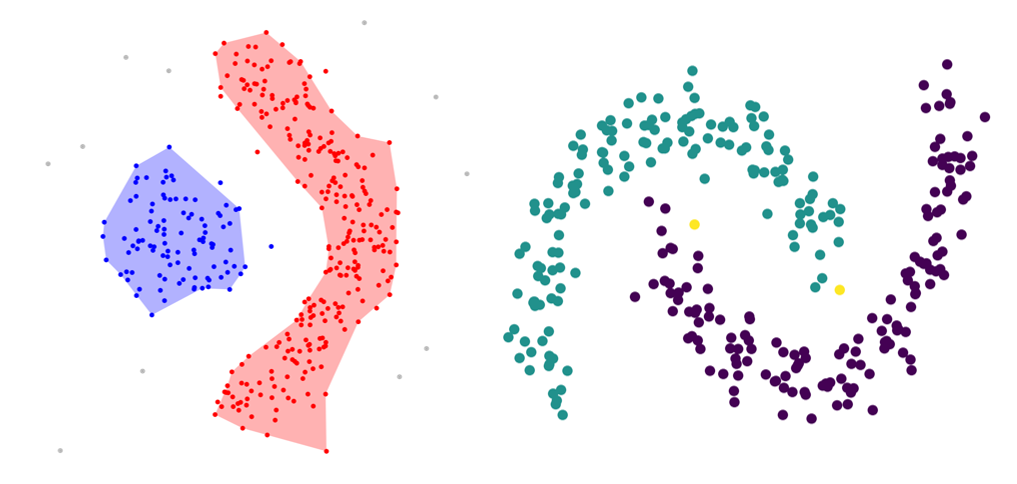
, . Amigo et. al, 2009. A comparison of Extrinsic Clustering Evaluation Metrics based on Formal Constraints , , .
1.1. Cluster Homogeneity,

.
1.2. Cluster Completeness,
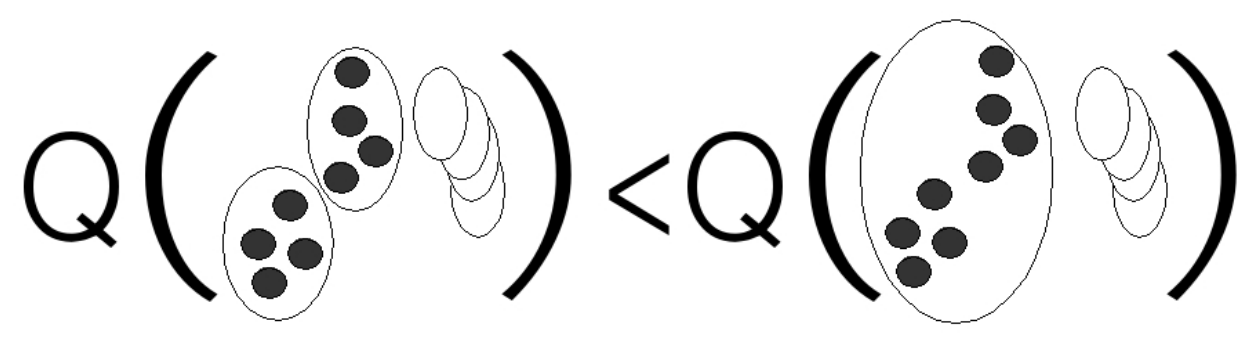
, . .
1.3. Rag Bag
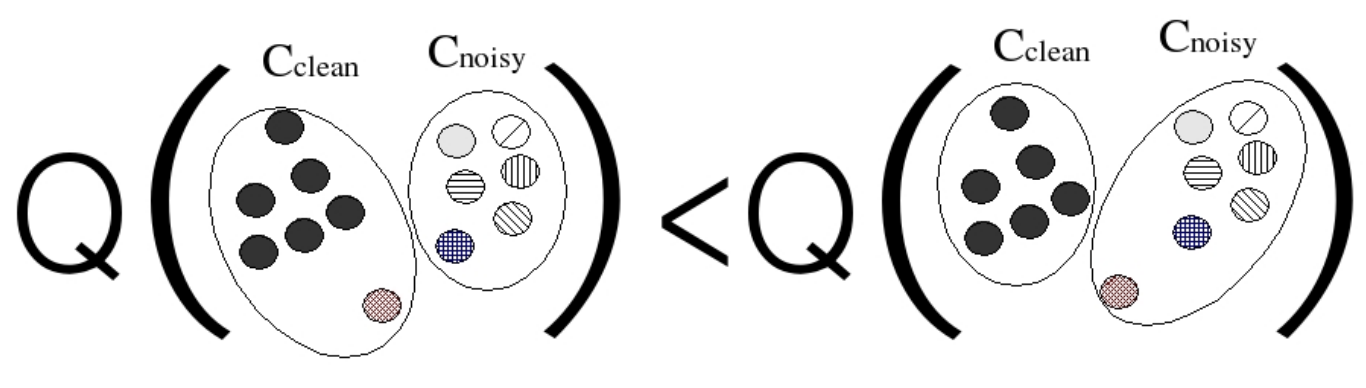
: , , («»), . , , , .
, . , . «» : , .
1.4. Size vs Quantity

.
2.
.
D = { d 1 , . . . , d N }. . , E ⊆ 2 D — ,
∀ e 1 , e 2 ∈ E : ( e 1 ∩ e 2 ≠ ∅ ) ⇔ ( e 1 = e 2 )
: . , .
, : T = { t 1 , . . . , t n } C={c1,...,cm}. t(d) c(d) , , , d.
2.1. , ()
. , . , .
. 3 («»), 3 («») 2 («»). : «» , «» «».

8⋅8=64 , :
— 3⋅3+3⋅3+2⋅2=22 ;
— 64−22=42 .
«» «» , - «» .
, :
— TP=18 ;
— FP=6 , ;
— TN=36 ;
— FN=4 , .
, :
P=TP/(TP+FP)=0.75
R=TP/(TP+FN)=0.82
F1=2PRP+R=0.78
, : .
. , : .
pairwise- — . - pairwise- .
2.2. ,
:
P(c,t)=|c∩t||c|
R(c,t)=|c∩t||t|
: «» (y) «» (v). 25 10 . 25/35, — 10/35. . , 30 12 , 25/30, — 10/12.

: , . :
P ( c , t ) = R ( t , c )
F-:
F 1 ( c , t ) = 2 ⋅ P ( c , t ) ⋅ R ( c , t )P ( c , t ) + R ( c , t )
. «» , Purity:
Purity=m∑i=1|ci|mmax1≤j≤nP(ci,tj)
, :
IversePurity=n∑j=1|tj|nmax1≤i≤mP(ci,tj)
Purity , . IversePurity — . , ? , . :
|c2|≈|t2|≫|t1|≫|c1|
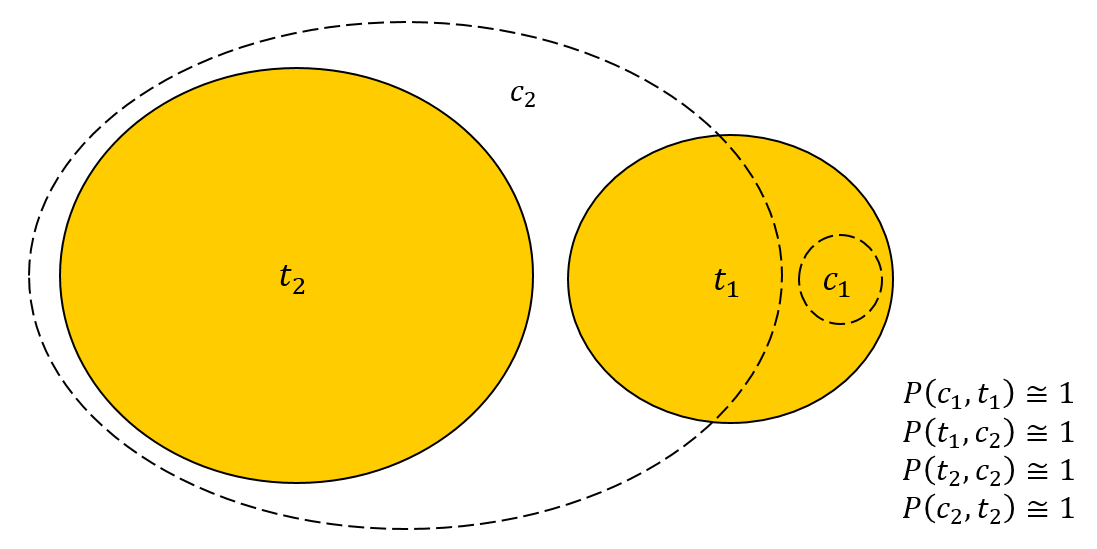
|c2|=1000, |c1|=2, |t1|=20, |t2|=982. c1 t1, :
|c1∩t1|=2,|c1∩t2|=0,
|c2∩t1|=18,|c2∩t2|=982
:
P(c1,t1)=|c1∩t1|/|c1|=2/2=1
P(c2,t2)=|c2∩t2|/|c2|=982/1000=0.982
P(t1,c2)=|t1∩c2|/|t1|=18/20=0.9
P(t2,c2)=|c2∩t2|/|t2|=982/982=1
, Purity InversePurity . :
Purity=0.9982
IversePurity=0.9823
, t1 . , . . Purity t1 c1, InversePurity — c2. !
F-:
F=n∑j=1|tj|nmax1≤i≤mF(ci,tj)
, , . , , , .
2.3. BCubed-
. , . , , ? ?
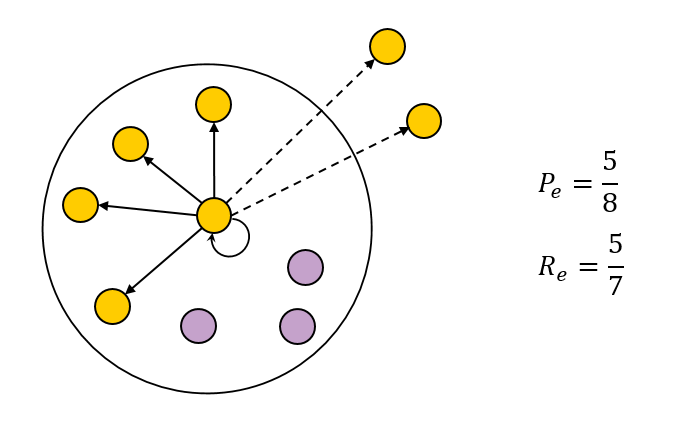
, BCubed- . :
BCP(d)=|c(d)∩t(d)||c(d)|
BCR(d)=|c(d)∩t(d)||t(d)|
:
BCP=1N∑d∈DBCP(d)
BCR=1N∑d∈DBCR(d)
BCubed Precision Cluster Homogeneity Rag Bag, BCubed Recall — Cluster Completeness Size vs Quantity. — F- — :
BCF=2⋅BCP⋅BCRBCP+BCR
3.
, . , .
, , . D={a,b,c,d,e,f,g,h,i} , t1={a,b,c,d,e} t2={f,g,h,i} («» «» ).
: c1={a,b,c,d,g}, c2={e,f,h,i}.

3.1. BCubed
BCubed- :
BCP(ti)=1|ti|∑d∈tiBCP(d)
BCR(ti)=1|ti|∑d∈tiBCR(d)
:
BCP(a)=BCP(b)=BCP(c)=BCP(d)=|t1∩c1||c1|=0.8,BCP(e)=|t1∩c2||c2|=0.25
BCP(f)=BCP(h)=BCP(i)=|t2∩c2||c2|=0.75,BCP(g)=|t2∩c1||c1|=0.2
:
BCP(t1)=BCP(a)+BCP(b)+BCP(c)+BCP(d)+BCP(e)5=4⋅0.8+0.255=0.69
BCP(t2)=BCP(f)+BCP(g)+BCP(h)+BCP(i)4=3⋅0.75+0.24=0.6125
:
BCR(a)=BCR(b)=BCR(c)=BCR(d)=|t1∩c1||t1|=0.8,BCR(e)=|t1∩c2||t1|=0.2
BCR(f)=BCR(h)=BCR(i)=|t2∩c2||t2|=0.75,BCP(g)=|t2∩c1||t2|=0.25
BCR(t1)=BCR(a)+BCR(b)+BCR(c)+BCR(d)+BCR(e)5=4⋅0.8+0.25=0.68
BCR(t2)=BCR(f)+BCR(g)+BCR(h)+BCR(i)4=3⋅0.75+0.254=0.625
BCP BCR :
BCP=BCP(t1)+BCP(t2)2=0.65125
BCR=BCR(t1)+BCR(t2)2=0.6525
.
3.2. Expected Cluster Completeness
. , , , , - .
— F- — . , ? .
, , «». . — . : , , .
— :
f:C→T
f (cluster completeness):
CCf(t)=maxc∈f−1(t)|c∩t||t|
:
CCf(T)=1T∑t∈TCCf(t)
— , f. : .
. , f(c)=t,
P(f(c)=t)=P(c,t)=|c∩t||c|
f :
P(f)=∏c∈C|c∩f(c)||c|
:
ECC(t)=∑f:C→TP(f)⋅CCf(t)
:
ECC=1|T|∑t∈TECC(t)
:
ECC=∑f:C→TP(f)⋅CCf(T)
. t c1, c2, ..., ck, :
|t∩c1|≥|t∩c2|≥...≥|t∩ck|
c1 t
P(f(c1)=t)=|c1∩t||c1|
R(c1,t)=|c1∩t||t|
, , . R(c1,t).
c1 , p(c2,t) t c2. R(c2,t). , ,
P(c1,t)⋅R(c1,t)+P(c2,t)⋅R(c2,t)⋅(1−P(c1,t))+...
ECC . sortedMatchings , , . Precision() Recall() . :
double ExpectedClusterCompleteness(const TMatchings& sortedMatchings) {
double expectedClusterCompleteness = 0.;
double probability = 1.;
for (const TMatching& matching : sortedMatchings) {
expectedClusterCompleteness += matching.Recall() * matching.Precision() * probability;
probability *= 1. - matching.Precision();
}
return expectedClusterCompleteness;
}
, F1-, !
ECC , 3. t1 c1, t2 — c2. :
ECC(t1)=R(c1,t2)⋅P(c1,t1)+R(c2,t1)⋅P(c2,t1)⋅(1−P(c1,t1))
ECC(t1)=0.82+0.2⋅0.25⋅(1−0.8)=0.65
ECC(t2)=R(c2,t2)⋅P(c2,t2)+R(c1,t2)⋅P(c1,t2)⋅(1−P(c2,t2))
ECC(t2)=0.752+0.25⋅0.2⋅(1−0.75)=0.575
, :
ECC=ECC(t1)+ECC(t2)2=0.6125
4.
, 3, C++ MIT GitHub. Linux, Windows.
:
git clone https://github.com/yandex/cluster_metrics/ .
cmake .
cmake --build .
, 3. !
./cluster_metrics samples/sample_markup.tsv samples/sample_clusters.tsv
ECC 0.61250 (0.61250)
BCP 0.65125 (0.65125)
BCR 0.65250 (0.65250)
BCF1 0.65187 (0.65187)
«» , , . , , . , , . — .
5. ,
, , , .
. , , . , , :

: , . , , . , , , — . — ECC!
, , — . .
, , , . .
, , , ECC! ECC - , , , 100% . .
, 1 . : — .

Cluster Completeness
, , . , Cluster Homogeneity, Cluster Completeness, Rag Bag , Size vs Quantity .
, : , , , .
, 3, , .
, , : . , , .