Bonjour, Habr! Aujourd'hui, nous allons parler en détail de points non évidents dans une opération aussi simple en apparence: corriger les distorsions projectives dans l'image. Comme cela arrive souvent dans la vie, nous avons dû choisir ce qui est le plus important: la qualité ou la vitesse. Et pour atteindre un certain équilibre, nous nous sommes souvenus des algorithmes que nous avons activement étudiés dans les années 80-90 dans le cadre de la tâche de rendu des structures, et depuis, nous nous en sommes rarement souvenus dans le cadre du traitement d'images. Si vous êtes intéressé, regardez sous le chat! Le modèle d'appareil photo sténopé, qui dans la pratique apporte également assez bien des caméras rapprochées de téléphones mobiles, nous dit que lorsque la caméra tourne, les images d'un objet plat sont connectées par transformation projective. La vue générale de la transformation projective est la suivante:
Le modèle d'appareil photo sténopé, qui dans la pratique apporte également assez bien des caméras rapprochées de téléphones mobiles, nous dit que lorsque la caméra tourne, les images d'un objet plat sont connectées par transformation projective. La vue générale de la transformation projective est la suivante:
Où matrice de transformation projective, et coordonnées sur la source et les images converties.Conversion d'images géométriques
La transformation d'image projective est l'une des transformations géométriques possibles des images (telles transformations dans lesquelles les points de l'image d'origine vont aux points de l'image finale selon une certaine loi).Pour comprendre comment résoudre le problème de la transformation géométrique d'une image numérique, vous devez considérer le modèle de sa formation à partir d'une image optique sur la matrice de la caméra. Selon G. Wahlberg [1], notre algorithme devrait approximer le processus suivant:- Récupérez l'image optique du numérique.
- Transformation géométrique de l'image optique.
- Échantillonnage de l'image convertie.
Une image optique est fonction de deux variables définies sur un ensemble continu de points. Ce processus est difficile à reproduire directement, car nous devons définir analytiquement le type d'image optique et le traiter. Pour simplifier ce processus, la méthode de mappage inverse est généralement utilisée:- Sur le plan de l'image finale, une grille d'échantillonnage est sélectionnée - les points par lesquels nous évaluerons les valeurs de pixels de l'image finale (cela peut être le centre de chaque pixel, ou peut-être quelques points par pixel).
- En utilisant la transformation géométrique inverse, cette grille est transférée dans l'espace de l'image d'origine.
- Pour chaque échantillon de grille, sa valeur est estimée. Puisqu'il n'apparaît pas nécessairement à un point avec des coordonnées entières, nous avons besoin d'une certaine interpolation de la valeur de l'image, par exemple, une interpolation par des pixels voisins.
- Selon les rapports de la grille, nous estimons les valeurs en pixels de l'image finale.
Ici, l'étape 3 correspond à la restauration de l'image optique et les étapes 1 et 4 correspondent à l'échantillonnage.Interpolation
Ici, nous ne considérerons que les types d'interpolation simples - ceux qui peuvent être représentés comme une convolution de l'image avec le noyau d'interpolation. Dans le contexte du traitement d'image, des algorithmes d'interpolation adaptative qui préservent des limites claires des objets seraient mieux, mais leur complexité de calcul est beaucoup plus élevée et donc nous ne sommes pas intéressés.Nous considérerons les méthodes d'interpolation suivantes:- par le pixel le plus proche
- bilinéaire
- bicubique
- b-spline cubique
- spline hermitienne cubique, 36 points.
L'interpolation a également un paramètre aussi important que la précision. Si nous supposons que l'image numérique a été obtenue par la méthode optique par échantillonnage ponctuel au centre du pixel et croyons que l'image d'origine était continue, alors le filtre passe-bas avec une fréquence de ½ sera une fonction de reconstruction idéale (voir le théorème de Kotelnikov ).Par conséquent, nous comparons les spectres de Fourier de nos noyaux d'interpolation avec un filtre passe-bas (dans les figures sont présentées pour le cas unidimensionnel).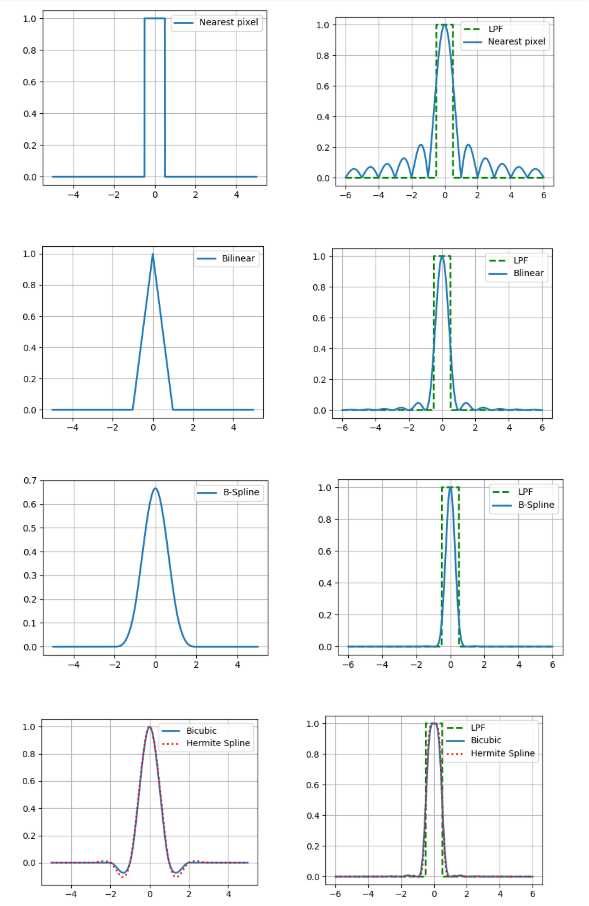 Et quoi, vous pouvez simplement prendre un noyau avec un assez bon spectre et obtenir des résultats relativement précis? En fait non, car nous avons fait deux hypothèses ci-dessus: qu'il y a une valeur de pixel de l'image et la continuité de cette image. Dans le même temps, ni l'un ni l'autre ne fait partie d'un bon modèle de formation d'image, car les capteurs sur la matrice de la caméra ne sont pas ponctuels, et sur l'image, beaucoup d'informations portent les limites des objets - les lacunes. Par conséquent, hélas, il faut comprendre que le résultat de l'interpolation sera toujours différent de l'image optique d'origine.Mais vous devez encore faire quelque chose, nous allons donc décrire brièvement les avantages et les inconvénients de chacune des méthodes considérées d'un point de vue pratique. La façon la plus simple de le voir est de zoomer sur l'image (dans cet exemple, 10 fois).
Et quoi, vous pouvez simplement prendre un noyau avec un assez bon spectre et obtenir des résultats relativement précis? En fait non, car nous avons fait deux hypothèses ci-dessus: qu'il y a une valeur de pixel de l'image et la continuité de cette image. Dans le même temps, ni l'un ni l'autre ne fait partie d'un bon modèle de formation d'image, car les capteurs sur la matrice de la caméra ne sont pas ponctuels, et sur l'image, beaucoup d'informations portent les limites des objets - les lacunes. Par conséquent, hélas, il faut comprendre que le résultat de l'interpolation sera toujours différent de l'image optique d'origine.Mais vous devez encore faire quelque chose, nous allons donc décrire brièvement les avantages et les inconvénients de chacune des méthodes considérées d'un point de vue pratique. La façon la plus simple de le voir est de zoomer sur l'image (dans cet exemple, 10 fois).Interpolation des pixels les plus proches
Le plus simple et le plus rapide, cependant, il conduit à des artefacts puissants.Interpolation bilinéaire
Mieux en qualité, mais nécessite plus de calcul et en plus brouille les frontières des objets.Interpolation bicubique
Encore mieux dans les zones continues, mais à la bordure, il y a un effet de halo (une bande plus sombre le long du bord sombre de la bordure et de la lumière le long de la lumière). Pour éviter cet effet, vous devez utiliser un noyau de convolution non négatif tel qu'une b-spline cubique.Interpolation B-spline
La b-spline a un spectre très étroit, ce qui signifie une forte image de «flou» (mais aussi une bonne réduction du bruit, ce qui peut être utile).Interpolation basée sur une spline cubique Hermite
Une telle spline nécessite une estimation des dérivées partielles dans chaque pixel de l'image. Si pour l'approximation, nous choisissons un schéma de différence à 2 points, alors nous obtenons le noyau de l'interpolation bicubique, nous utilisons donc ici un schéma à 4 points.Nous comparons également ces méthodes en termes de nombre d'accès à la mémoire (le nombre de pixels de l'image d'origine pour l'interpolation en un point) et le nombre de multiplication par point.On peut voir que les 3 dernières méthodes sont beaucoup plus chères en termes de calcul que les 2 premières.Échantillonnage
Il s'agit de l'étape même à laquelle très peu d'attention a été accordée de façon tout à fait injustifiée récemment. La façon la plus simple d'effectuer une transformation d'image projective consiste à évaluer la valeur de chaque pixel de l'image finale par la valeur obtenue en inversant son centre sur le plan de l'image d'origine (en tenant compte de la méthode d'interpolation sélectionnée). Nous appelons cette approche la discrétisation pixel par pixel . Cependant, dans les zones où l'image est compressée, cela peut entraîner des artefacts importants causés par le problème du chevauchement des spectres à une fréquence d'échantillonnage insuffisante.Nous démontrerons clairement les artefacts de compression sur l'échantillon du passeport russe et son champ individuel - lieu de naissance (ville d'Arkhangelsk), compressés à l'aide d'un échantillonnage pixel par pixel ou de l'algorithme FAST, que nous examinerons ci-dessous.On peut voir que le texte de l'image de gauche est devenu illisible. C'est vrai, car nous ne prenons qu'un seul point dans toute une région de l'image source!Puisque nous n'avons pas pu estimer sur un pixel, alors pourquoi ne pas choisir plus d'échantillons par pixel et faire la moyenne des valeurs obtenues? Cette approche est appelée suréchantillonnage . Cela augmente vraiment la qualité, mais en même temps, la complexité de calcul augmente proportionnellement au nombre d'échantillons par pixel.Des méthodes plus efficaces en termes de calcul ont été inventées à la fin du siècle dernier, lorsque l'infographie a résolu le problème du rendu des textures superposées aux objets plats. L'une de ces méthodes est la conversion à l'aide de mip-mapstructure. Mip-map est une pyramide d'images composée de l'image originale elle-même, ainsi que de ses copies réduites de 2, 4, 8 et ainsi de suite. Pour chaque pixel, nous évaluons le degré de compression caractéristique de celui-ci, et conformément à ce degré, nous sélectionnons le niveau souhaité dans la pyramide, comme image source. Il existe différentes façons d'évaluer le niveau approprié de mip-map (voir détails [2]). Ici, nous utiliserons la méthode basée sur l'estimation des dérivées partielles par rapport à la matrice de transformation projective bien connue. Cependant, afin d'éviter les artefacts dans les zones de l'image finale où un niveau de la structure mip-map va à un autre, une interpolation linéaire entre deux niveaux adjacents de la pyramide est généralement utilisée (cela n'augmente pas considérablement la complexité de calcul, car les coordonnées des points aux niveaux voisins sont uniquement connectées).Cependant, la mip-map ne prend pas en compte le fait que la compression d'image peut être anisotrope (allongée dans une certaine direction). Ce problème peut être partiellement résolu par rip-map . Une structure dans laquelle les images compressées fois horizontalement et fois verticalement. Dans ce cas, après avoir déterminé les coefficients de compression horizontale et verticale à un point donné de l'image finale, une interpolation est effectuée entre les résultats de 4 compressés au nombre de fois souhaité de copies de l'image originale. Mais cette méthode n'est pas idéale, car elle ne tient pas compte du fait que la direction de l'anisotropie diffère des directions parallèles aux limites de l'image d'origine.Ce problème peut être partiellement résolu par l' algorithme FAST (Footprint Area Sampled Texturing) [3]. Il combine les idées de mip-map et de suréchantillonnage. Nous estimons le degré de compression sur la base de l'axe de moindre anisotropie et sélectionnons le nombre d'échantillons proportionnellement au rapport des longueurs du plus petit axe au plus grand.Avant de comparer ces approches en termes de complexité de calcul, nous faisons une réserve afin d'accélérer le calcul de la transformation projective inverse, il est rationnel de faire le changement suivant:Où , Est la matrice de la transformation projective inverse. Comme et fonctions d'un argument, nous pouvons les pré-calculer pour un temps proportionnel à la taille linéaire de l'image. Ensuite, pour calculer les coordonnées de l'image inverse d'un point de l'image finale, seulement 1 division et 2 multiplications sont nécessaires. Une astuce similaire peut être effectuée avec des dérivées partielles, qui sont utilisées pour déterminer le niveau dans la structure mip-map ou rip-map.Nous sommes maintenant prêts à comparer les résultats en termes de complexité de calcul.Et comparez visuellement (de gauche à droite, échantillonnage pixel par pixel, suréchantillonnage par 49 échantillons, mip-map, rip-map, FAST).
Expérience
Maintenant, comparons nos résultats expérimentalement. Nous composons un algorithme de transformation projective combinant chacune des 5 méthodes d'interpolation et 5 méthodes de discrétisation (25 options au total). Prenez 20 images de documents recadrés à 512x512 pixels, générez 10 ensembles de 3 matrices de transformation projectives, de sorte que chaque ensemble est généralement équivalent à la transformation identique, et nous comparerons le PSNR entre l'image d'origine et l'image convertie. Rappelons que PSNR estoù c'est le maximum dans l'image d'origine - l'écart type de la finale par rapport à l'original. Plus il y a de PSNR, mieux c'est. Nous mesurerons également le temps de fonctionnement de la conversion projective sur ODROID-XU4 avec un processeur ARM Cortex-A15 (2000 MHz et 2 Go de RAM).Tableau monstrueux avec les résultats:Quelles conclusions peut-on en tirer?
- L'utilisation de l'interpolation par le pixel le plus proche ou l'échantillonnage pixel par pixel se traduit par une mauvaise qualité (cela ressortait clairement des exemples ci-dessus).
- 36 — .
- b- , , .
- Rip-map FAST , 9 ( , ?).
- mip-map b- PSNR , .
Si vous voulez une bonne qualité avec une vitesse pas trop basse, vous devriez considérer l'interpolation bilinéaire en combinaison avec la discrétisation en utilisant mip-map ou FAST. Cependant, s'il est certain que la distorsion projective est très faible, pour augmenter la vitesse, vous pouvez utiliser une discrétisation pixel par pixel associée à une interpolation bilinéaire ou même une interpolation par le pixel le plus proche. Et si vous avez besoin d'une durée d'exécution de haute qualité et pas très limitée, vous pouvez utiliser une interpolation bicubique ou adaptative associée à un suréchantillonnage modéré (par exemple, également adaptative, en fonction du taux de compression local).PS La publication est basée sur le rapport: A. Trusov et E. Limonova, «L'analyse des algorithmes de transformation projective pour la reconnaissance d'images sur les appareils mobiles», ICMV 2019, 11433 éd., Wolfgang Osten, Dmitry Nikolaev, Jianhong Zhou, Ed., SPIE , Jan. 2020, vol. 11433, ISSN 0277-786X, ISBN 978-15-10636-43-9, vol. 11433, 11433 0Y, pp. 1-8, 2020, DOI: 10.1117 / 12.2559732.Liste des sources utilisées- G. Wolberg, Digital image warping, vol. 10662, IEEE computer society press Los Alamitos, CA (1990).
- J. P. Ewins, M. D. Waller, M. White, and P. F. Lister, “Mip-map level selection for texture mapping,” IEEE Transactions on Visualization and Computer Graphics4(4), 317–329 (1998).
- B. Chen, F. Dachille, and A. E. Kaufman, “Footprint area sampled texturing,” IEEE Transactions on Visualizationand Computer Graphics10(2), 230–240 (2004).