Il arrive que les systèmes soient bogués, ralentissent, tombent en panne. Plus le système est grand, plus il est difficile de trouver la cause. Pour savoir pourquoi quelque chose ne fonctionne pas comme prévu, pour résoudre ou éviter de futurs problèmes, vous devez regarder à l'intérieur. Pour cela, les systèmes doivent posséder la propriété de l' observabilité , qui est obtenue par l'instrumentation au sens large du terme.À HighLoad ++, Peter Zaitsev (Percona) a passé en revue l'infrastructure disponible pour le traçage sous Linux et a parlé de bpfTrace, qui (comme son nom l'indique) offre de nombreux avantages. Nous avons fait une version textuelle du rapport, de sorte qu'il serait pratique pour vous d'examiner les détails et les documents supplémentaires étaient toujours à portée de main.L'instrumentation peut être divisée en deux grands blocs:- Statique , lorsque la collecte d'informations est câblée en code: enregistrement des journaux, des compteurs, de l'heure, etc.
- Dynamique , lorsque le code n'est pas instrumenté par lui-même, mais il est possible de le faire en cas de besoin.
Une autre option de classification est basée sur l'approche de l'enregistrement des données:- Traçage - les événements sont générés si un certain code a fonctionné.
- Échantillonnage - l'état du système est vérifié, par exemple, 100 fois par seconde et il détermine ce qui s'y passe.
L'instrumentation statique existe depuis de nombreuses années et est présente dans presque tout. Sous Linux, de nombreux outils standard comme Vmstat ou top l'utilisent. Ils lisent les données de procfs, où, en gros, différents temporisateurs et compteurs sont écrits à partir du code du noyau.Mais vous ne pouvez pas insérer trop de ces compteurs, vous ne pouvez pas couvrir tout dans le monde avec eux. Par conséquent, l'instrumentation dynamique peut être utile, ce qui vous permet de regarder exactement ce dont vous avez besoin. Par exemple, s'il y a des problèmes avec la pile TCP / IP, vous pouvez aller très loin et demander des détails spécifiques.
Dtrace
DTrace est l'un des premiers frameworks de traçage dynamique connus créés par Sun Microsystems. Il a commencé à être fabriqué en 2001 et, pour la première fois, il a été publié dans Solaris 10 en 2005. L'approche s'est avérée très populaire et est ensuite entrée dans de nombreuses autres distributions.Fait intéressant, DTrace vous permet d'instrumenter à la fois l'espace du noyau et l'espace utilisateur. Vous pouvez mettre des traces sur tous les appels de fonction et donner des instructions spécifiques aux programmes: introduisez des points de trace DTrace spéciaux, qui pour les utilisateurs peuvent être plus compréhensibles que les noms de fonction.Cela était particulièrement important pour Solaris, car il ne s'agit pas d'un système d'exploitation ouvert. Il n'était pas possible de simplement regarder dans le code et de comprendre que le point de trace doit être mis sur une telle fonction comme cela peut maintenant être fait dans le nouveau logiciel Linux open source.L'une des caractéristiques uniques, en particulier à cette époque, de DTrace est que, même si le traçage n'est pas activé, il ne coûte rien . Il fonctionne de telle manière qu'il remplace simplement certaines instructions CPU par un appel DTrace, qui exécute ces instructions lors de son retour.Dans DTrace, l'instrumentation est écrite dans un langage D spécial, similaire à C et Awk.Plus tard DTrace est apparu presque partout sauf Linux: sur MacOS en 2007, sur FreeBSD en 2008, dans NetBSD en 2010. Oracle en 2011 a inclus DTrace dans Oracle Unbreakable Linux. Mais peu de gens utilisent Oracle Linux et DTrace n'est jamais entré dans Linux principal.Fait intéressant, en 2017, Oracle a finalement autorisé DTrace sous GPLv2, ce qui a en principe permis de l'inclure dans Linux principal sans difficultés de licence, mais il était déjà trop tard. A cette époque, Linux avait un bon BPF, qui était principalement utilisé pour la normalisation.DTrace va même être inclus dans Windows; maintenant, il est disponible dans certaines versions de test.Traçage Linux
Qu'est-ce qui est sous Linux au lieu de DTrace? En fait, sous Linux, il y a beaucoup de choses dans la meilleure (ou la pire) manifestation de l'esprit open source, un tas de cadres de traçage différents se sont accumulés au cours de cette période. Par conséquent, déterminer ce qui n'est pas si simple.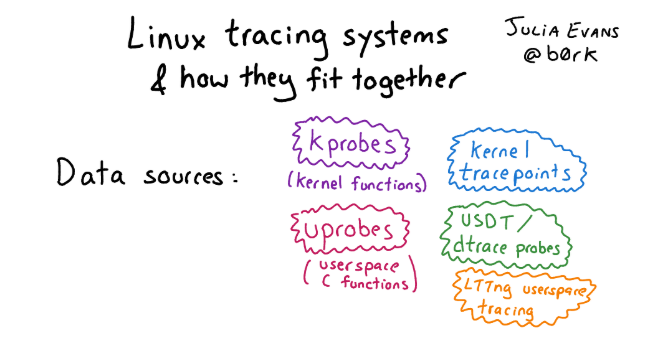 Si vous voulez vous familiariser avec cette variété et êtes intéressé par l'histoire, consultez l' article avec des images et une description détaillée des approches de traçage sous Linux.Si nous parlons de l'infrastructure de traçage sous Linux en général, il y a trois niveaux:
Si vous voulez vous familiariser avec cette variété et êtes intéressé par l'histoire, consultez l' article avec des images et une description détaillée des approches de traçage sous Linux.Si nous parlons de l'infrastructure de traçage sous Linux en général, il y a trois niveaux:- Interface pour l'instrumentation du noyau: Kprobe, Uprobe, sonde Dtrace, etc.
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
Avec tous ces cadres, eBPF est devenu la norme sur Linux ces dernières années. Il s'agit d'un outil plus avancé, très flexible et efficace qui permet presque tout.Qu'est-ce que l'eBPF et d'où vient-il? En fait, eBPF est un filtre de paquets Berkeley étendu, et BPF a été développé en 1992 comme une machine virtuelle pour le filtrage efficace des paquets par un pare-feu. Initialement, il n'avait aucun lien avec la surveillance, l'observabilité ou le traçage.Dans les versions plus modernes, eBPF a été étendu (d'où le mot étendu), en tant que cadre commun pour la gestion des événements . Les versions actuelles sont intégrées au compilateur JIT pour une plus grande efficacité.Différences entre eBPF et BPF classique:- registres ajoutés;
- une pile est apparue;
- Il existe des structures de données supplémentaires (cartes).
 Maintenant, les gens oublient le plus souvent qu'il y avait un ancien BPF, et eBPF est simplement appelé BPF. Dans la plupart des expressions modernes, eBPF et BPF sont une seule et même chose. Par conséquent, l'outil s'appelle bpfTrace et non eBpfTrace.eBPF est inclus dans Linux principal depuis 2014 et est progressivement inclus dans de nombreux outils Linux, y compris Perf, SystemTap, SysDig. Il y a une standardisation.Fait intéressant, le développement est toujours en cours. Les noyaux modernes supportent de mieux en mieux eBPF.
Maintenant, les gens oublient le plus souvent qu'il y avait un ancien BPF, et eBPF est simplement appelé BPF. Dans la plupart des expressions modernes, eBPF et BPF sont une seule et même chose. Par conséquent, l'outil s'appelle bpfTrace et non eBpfTrace.eBPF est inclus dans Linux principal depuis 2014 et est progressivement inclus dans de nombreux outils Linux, y compris Perf, SystemTap, SysDig. Il y a une standardisation.Fait intéressant, le développement est toujours en cours. Les noyaux modernes supportent de mieux en mieux eBPF.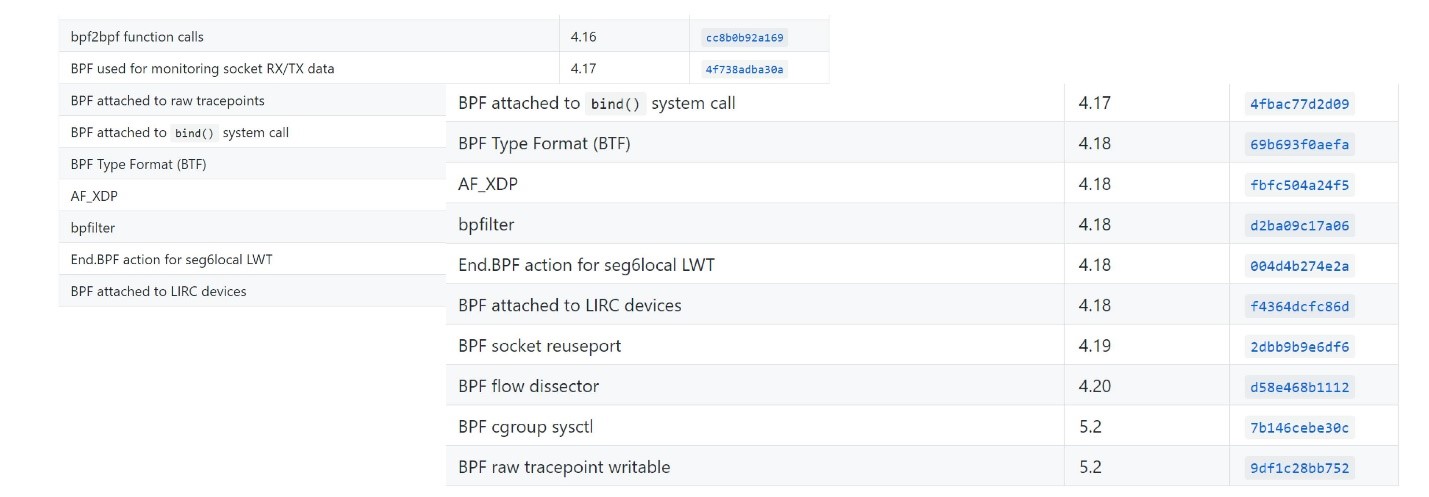 Vous pouvez voir quelles versions modernes du noyau sont apparues ici .
Vous pouvez voir quelles versions modernes du noyau sont apparues ici .Programmes EBPF
Alors qu'est-ce que eBPF et pourquoi est-il intéressant?eBPF est un programme dans son bytecode spécial , qui est inclus directement dans le noyau et effectue le traitement des événements de trace. De plus, le fait qu'il soit fait dans un bytecode spécial permet au noyau d'effectuer une certaine vérification que le code est assez sûr. Par exemple, vérifiez qu'il n'utilise pas de boucles, car la boucle de la section critique du noyau peut bloquer tout le système.Mais cela ne permet pas d'être totalement sécurisé. Par exemple, si vous écrivez un programme eBPF très complexe, l'insérez dans un événement du noyau qui se produit 10 millions de fois par seconde, alors tout peut ralentir beaucoup. Mais en même temps, eBPF est beaucoup plus sûr que l'ancienne approche, lorsque seulement quelques modules du noyau étaient insérés via insmod, et que tout pouvait se trouver dans ces modules. Si quelqu'un a fait une erreur, ou simplement à cause d'une incompatibilité binaire, le noyau entier pourrait tomber.Le code eBPF peut être compilé par LLVM Clang, c'est-à-dire, en gros, utiliser un sous-ensemble de C pour créer des programmes eBPF, ce qui, bien sûr, est assez compliqué. Et il est important que la compilation dépend du noyau: les en-têtes sont utilisés pour comprendre quelles structures sont utilisées et à quoi elles servent, etc. Ce n'est pas très pratique dans le sens où certains modules liés à un noyau spécifique sont toujours fournis ou doivent être recompilés.Le diagramme montre comment fonctionne eBPF. http://www.brendangregg.com/ebpf.htmlL'utilisateur crée un programme eBPF. De plus, le noyau, de son côté, le vérifie et le charge. Après cela, eBPF peut se connecter à divers outils pour les traces, traiter les informations, les enregistrer dans des cartes (structure de données pour le stockage temporaire). Ensuite, le programme utilisateur peut lire des statistiques, recevoir des événements de performance, etc.Il montre quelles fonctionnalités eBPF dans quelles versions de noyaux Linux.
http://www.brendangregg.com/ebpf.htmlL'utilisateur crée un programme eBPF. De plus, le noyau, de son côté, le vérifie et le charge. Après cela, eBPF peut se connecter à divers outils pour les traces, traiter les informations, les enregistrer dans des cartes (structure de données pour le stockage temporaire). Ensuite, le programme utilisateur peut lire des statistiques, recevoir des événements de performance, etc.Il montre quelles fonctionnalités eBPF dans quelles versions de noyaux Linux.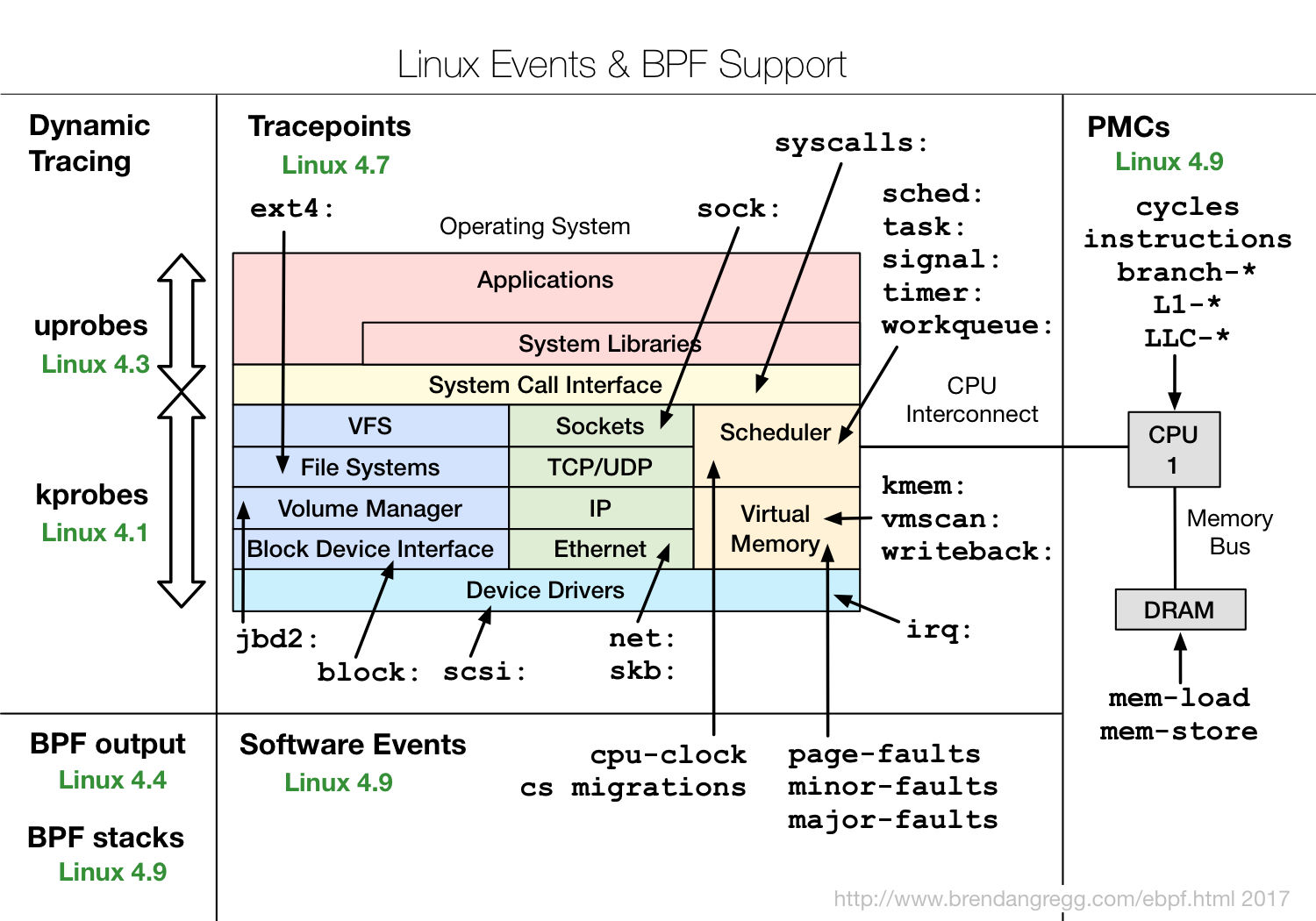 On peut voir que presque tous les sous-systèmes du noyau Linux sont couverts, en plus il y a une bonne intégration avec les données matérielles, eBPF a accès à toutes sortes de prédictions de cache cache ou de branchement, etc.Si vous êtes intéressé par eBPF, consultez le projet IO Visor, il contient la plupart des outils. La société IO Visor est engagée dans leur développement, ils disposeront des dernières versions et d'une très bonne documentation. De plus en plus d'outils eBPF apparaissent sur les distributions Linux, je vous recommande donc de toujours utiliser les dernières versions disponibles.
On peut voir que presque tous les sous-systèmes du noyau Linux sont couverts, en plus il y a une bonne intégration avec les données matérielles, eBPF a accès à toutes sortes de prédictions de cache cache ou de branchement, etc.Si vous êtes intéressé par eBPF, consultez le projet IO Visor, il contient la plupart des outils. La société IO Visor est engagée dans leur développement, ils disposeront des dernières versions et d'une très bonne documentation. De plus en plus d'outils eBPF apparaissent sur les distributions Linux, je vous recommande donc de toujours utiliser les dernières versions disponibles.Performances EBPF
En termes de performances, eBPF est assez efficace. Pour comprendre combien et s'il y a des frais généraux, vous pouvez ajouter une sonde, qui se tord plusieurs fois par seconde, et vérifiez combien de temps il faut pour l'exécuter.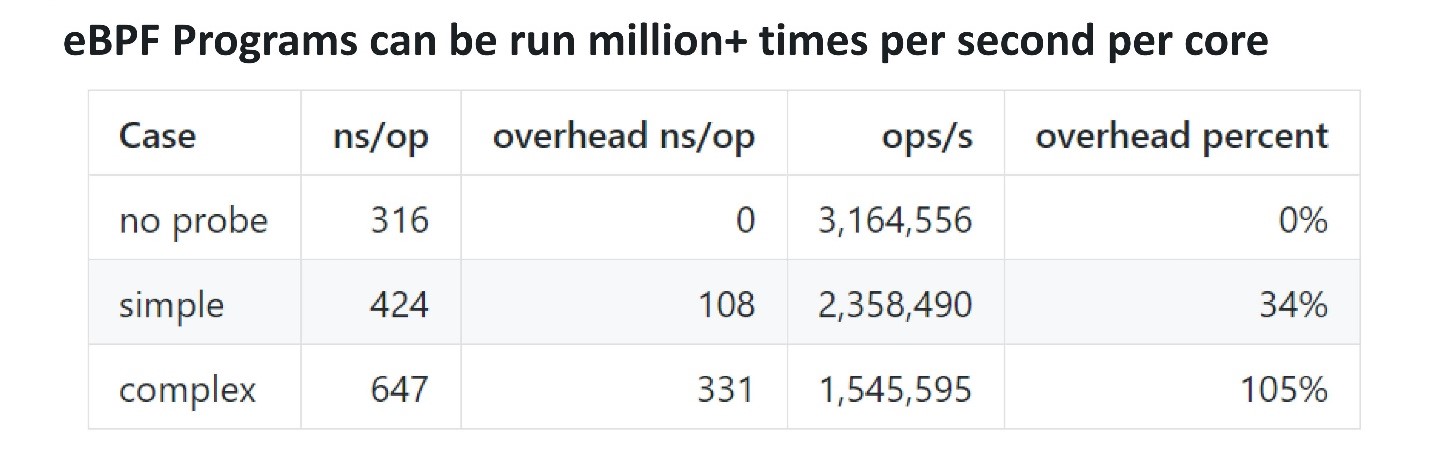 Les gars de Cloudflare ont fait une référence . Une simple sonde eBPF leur a pris environ 100 ns, tandis qu'une sonde plus complexe a pris 300 ns. Cela signifie que même une sonde complexe peut être appelée sur un seul cœur environ 3 millions de fois par seconde. Si la sonde effectue 100 000 ou un million de fois par seconde sur un processeur multicœur, cela n'affectera pas trop les performances.
Les gars de Cloudflare ont fait une référence . Une simple sonde eBPF leur a pris environ 100 ns, tandis qu'une sonde plus complexe a pris 300 ns. Cela signifie que même une sonde complexe peut être appelée sur un seul cœur environ 3 millions de fois par seconde. Si la sonde effectue 100 000 ou un million de fois par seconde sur un processeur multicœur, cela n'affectera pas trop les performances.Frontend pour eBPF
Si vous êtes intéressé par eBPF et le sujet de l'observabilité en général, vous avez probablement entendu parler de Brendan Gregg. Il écrit et parle beaucoup à ce sujet et a fait une si belle image qui montre des outils pour eBPF. Ici, vous pouvez voir que, par exemple, vous pouvez utiliser Raw BPF - il suffit d'écrire du code d'octet - cela donnera une gamme complète de fonctionnalités, mais il sera très difficile de travailler avec. Le BPF brut concerne la façon d'écrire une application Web dans l'assembleur - en principe, c'est possible, mais sans avoir besoin de le faire.Fait intéressant, bpfTrace, d'une part, vous permet d'obtenir presque tout de BCC et de BPF brut, mais il est beaucoup plus facile à utiliser.À mon avis, deux outils sont les plus utiles:
Ici, vous pouvez voir que, par exemple, vous pouvez utiliser Raw BPF - il suffit d'écrire du code d'octet - cela donnera une gamme complète de fonctionnalités, mais il sera très difficile de travailler avec. Le BPF brut concerne la façon d'écrire une application Web dans l'assembleur - en principe, c'est possible, mais sans avoir besoin de le faire.Fait intéressant, bpfTrace, d'une part, vous permet d'obtenir presque tout de BCC et de BPF brut, mais il est beaucoup plus facile à utiliser.À mon avis, deux outils sont les plus utiles:- BCC. Malgré le fait que selon le schéma de Gregg, BCC est complexe, il comprend de nombreuses fonctions prêtes à l'emploi qui peuvent être simplement lancées à partir de la ligne de commande.
- BpfTrace . Il vous permet d'écrire simplement votre propre boîte à outils ou d'utiliser des solutions prêtes à l'emploi.
Vous pouvez imaginer combien il est plus facile d'écrire sur bpfTrace si vous regardez le code du même outil dans deux versions.
DTrace vs bpfTrace
En général, DTrace et bpfTrace sont utilisés pour la même chose. http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlLa différence est qu'il existe également un BCC dans l'écosystème BPF qui peut être utilisé pour des outils complexes. Il n'y a pas d'équivalent BCC dans DTrace, par conséquent, pour créer des boîtes à outils complexes, utilisez généralement le bundle Shell + DTrace.Lors de la création de bpfTrace, il n'y avait aucune tâche pour émuler complètement DTrace. Autrement dit, vous ne pouvez pas prendre un script DTrace et l'exécuter sur bpfTrace. Mais cela n'a pas beaucoup de sens, car la logique des outils de niveau inférieur est assez simple. Il est généralement plus important de comprendre à quels points de trace vous devez vous connecter, et les noms des appels système et ce qu'ils font directement à un bas niveau diffèrent sous Linux, Solaris, FreeBSD. C'est là que la différence surgit.Dans ce cas, bpfTrace est réalisé 15 ans après DTrace. Il a quelques fonctionnalités supplémentaires que DTrace n'a pas. Par exemple, il peut faire des traces de pile.Mais bien sûr, beaucoup est hérité de DTrace. Par exemple, les noms de fonction et la syntaxe sont similaires , mais pas complètement équivalents.Les scripts DTrace et bpfTrace sont proches en taille de code et similaires en complexité et en capacités linguistiques.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlLa différence est qu'il existe également un BCC dans l'écosystème BPF qui peut être utilisé pour des outils complexes. Il n'y a pas d'équivalent BCC dans DTrace, par conséquent, pour créer des boîtes à outils complexes, utilisez généralement le bundle Shell + DTrace.Lors de la création de bpfTrace, il n'y avait aucune tâche pour émuler complètement DTrace. Autrement dit, vous ne pouvez pas prendre un script DTrace et l'exécuter sur bpfTrace. Mais cela n'a pas beaucoup de sens, car la logique des outils de niveau inférieur est assez simple. Il est généralement plus important de comprendre à quels points de trace vous devez vous connecter, et les noms des appels système et ce qu'ils font directement à un bas niveau diffèrent sous Linux, Solaris, FreeBSD. C'est là que la différence surgit.Dans ce cas, bpfTrace est réalisé 15 ans après DTrace. Il a quelques fonctionnalités supplémentaires que DTrace n'a pas. Par exemple, il peut faire des traces de pile.Mais bien sûr, beaucoup est hérité de DTrace. Par exemple, les noms de fonction et la syntaxe sont similaires , mais pas complètement équivalents.Les scripts DTrace et bpfTrace sont proches en taille de code et similaires en complexité et en capacités linguistiques.
bpfTrace
Voyons plus en détail ce qui se trouve dans bpfTrace, comment il peut être utilisé et ce qui est nécessaire pour cela. ConfigurationLinux requise pour utiliser bpfTrace: Pour utiliser toutes les fonctionnalités, vous avez besoin d'une version d'au moins 4.9. BpfTrace vous permet de faire beaucoup de sondes différentes, à commencer par uprobe pour instrumenter un appel de fonction dans une application utilisateur, des sondes de noyau, etc.
Pour utiliser toutes les fonctionnalités, vous avez besoin d'une version d'au moins 4.9. BpfTrace vous permet de faire beaucoup de sondes différentes, à commencer par uprobe pour instrumenter un appel de fonction dans une application utilisateur, des sondes de noyau, etc. Il est intéressant de noter qu'il existe un équivalent de sonde d'urètre pour une fonction de sonde personnalisée. Pour le noyau, la même chose est kprobe et kretprobe. Cela signifie qu'en fait, dans le cadre de suivi, vous pouvez générer des événements lorsque la fonction est appelée et à la fin de cette fonction - ceci est souvent utilisé pour le chronométrage. Vous pouvez également analyser les valeurs renvoyées par la fonction et les regrouper en fonction des paramètres avec lesquels la fonction a été appelée. Si vous interceptez un appel de fonction et que vous y revenez, vous pouvez faire beaucoup de choses intéressantes.À l'intérieur de bpfTrace, cela fonctionne comme ceci: nous écrivons un programme bpf qui est analysé, converti en C, puis traité via Clang, qui génère du code d'octets bpf, après quoi le programme se charge.
Il est intéressant de noter qu'il existe un équivalent de sonde d'urètre pour une fonction de sonde personnalisée. Pour le noyau, la même chose est kprobe et kretprobe. Cela signifie qu'en fait, dans le cadre de suivi, vous pouvez générer des événements lorsque la fonction est appelée et à la fin de cette fonction - ceci est souvent utilisé pour le chronométrage. Vous pouvez également analyser les valeurs renvoyées par la fonction et les regrouper en fonction des paramètres avec lesquels la fonction a été appelée. Si vous interceptez un appel de fonction et que vous y revenez, vous pouvez faire beaucoup de choses intéressantes.À l'intérieur de bpfTrace, cela fonctionne comme ceci: nous écrivons un programme bpf qui est analysé, converti en C, puis traité via Clang, qui génère du code d'octets bpf, après quoi le programme se charge. Le processus est assez difficile, il y a donc des limites. Sur les serveurs puissants, bpfTrace fonctionne bien. Mais faire glisser Clang vers un petit appareil intégré pour comprendre ce qui se passe n'est pas une bonne idée. Ply convient à cela . Bien sûr, il n'a pas toutes les fonctionnalités de bpfTrace, mais il génère directement du bytecode.
Le processus est assez difficile, il y a donc des limites. Sur les serveurs puissants, bpfTrace fonctionne bien. Mais faire glisser Clang vers un petit appareil intégré pour comprendre ce qui se passe n'est pas une bonne idée. Ply convient à cela . Bien sûr, il n'a pas toutes les fonctionnalités de bpfTrace, mais il génère directement du bytecode.Prise en charge Linux
Une version stable de bpfTrace a été publiée il y a environ un an, elle n'est donc pas disponible sur les anciennes distributions Linux. Il est préférable de prendre des packages ou de compiler la dernière version distribuée par IO Visor.Fait intéressant, le dernier Ubuntu LTS 18.04 n'a pas bpfTrace, mais il peut être livré à l'aide du package snap. D'une part, c'est pratique, mais d'autre part, en raison de la façon dont les packages d'accrochage sont créés et isolés, toutes les fonctions ne fonctionneront pas. Pour le traçage du noyau, un package avec snap fonctionne bien; pour le traçage utilisateur, il peut ne pas fonctionner correctement.
Exemple de suivi de processus
Prenons l'exemple le plus simple qui vous permet d'obtenir des statistiques sur les demandes d'E / S:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Ici, nous nous connectons à la fonction vfs_read, à la fois kretprobe et kprobe. En outre, pour chaque ID de thread (tid), c'est-à-dire pour chaque requête, nous suivons le début et la fin de son exécution. Les données peuvent être regroupées non seulement par la totalité de l'ensemble du système, mais également par différents processus. Vous trouverez ci-dessous la sortie IO pour MySQL. La distribution d'E / S bimodale classique est visible. Un grand nombre de requêtes rapides sont des données qui sont lues dans le cache. Le deuxième pic est la lecture des données du disque, où la latence est beaucoup plus élevée.Vous pouvez l'enregistrer en tant que script (l'extension bt est généralement utilisée), écrire des commentaires, la formater et simplement l'utiliser plus loin
La distribution d'E / S bimodale classique est visible. Un grand nombre de requêtes rapides sont des données qui sont lues dans le cache. Le deuxième pic est la lecture des données du disque, où la latence est beaucoup plus élevée.Vous pouvez l'enregistrer en tant que script (l'extension bt est généralement utilisée), écrire des commentaires, la formater et simplement l'utiliser plus loin #bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
Le concept général de la langue est assez simple.- Syntaxe: sélectionnez la sonde à connecter
probe[,probe,...] /filter/ { action }. - Filtre: spécifiez un filtre, par exemple, uniquement des données sur un processus donné d'un Pid donné.
- Action: un mini-programme qui se convertit directement en programme bpf et s'exécute lorsque bpfTrace est appelé.
Plus de détails peuvent être trouvés ici .Outils Bpftrace
BpfTrace possède également une boîte à outils. De nombreux outils assez simples sur BCC sont maintenant implémentés sur bpfTrace. La collection est encore petite, mais il y a quelque chose qui n'est pas dans le BCC. Par exemple, killsnoop vous permet de suivre les signaux causés par kill ().Si vous êtes intéressé à regarder le code bpf, alors dans bpfTrace vous pouvez
La collection est encore petite, mais il y a quelque chose qui n'est pas dans le BCC. Par exemple, killsnoop vous permet de suivre les signaux causés par kill ().Si vous êtes intéressé à regarder le code bpf, alors dans bpfTrace vous pouvez -vvoir le code d'octets généré. Ceci est utile si vous voulez comprendre une sonde lourde ou non. Après avoir regardé le code et avoir juste estimé sa taille (une page ou deux), vous pouvez comprendre à quel point il est compliqué.
Exemple de suivi MySQL
Permettez-moi de vous montrer un exemple de MySQL, comment cela fonctionne. MySQL a une fonction dispatch_commanddans laquelle toutes les exécutions de requêtes MySQL se produisent.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
Je voulais juste connecter une sonde pour imprimer le texte des requêtes qui arrivent à MySQL - une tâche primitive. Vous avez un problème - dit qu'il n'y a pas un tel fichier. Comme pas quand c'est ici:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
Ce ne sont que des surprises avec snap. S'il est défini via snap, il peut y avoir des problèmes au niveau de l'application.Ensuite, j'ai installé via la version apt, un Ubuntu plus récent, redémarré:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
«Il n'y a pas un tel symbole» - comment pas?! Je regarde nms'il existe un tel symbole ou non:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
Il existe un tel symbole, mais comme MySQL est compilé à partir de C ++, le mangling y est utilisé. En fait, le nom actuel de la fonction qui est utilisée dans cette commande, ce qui suit: _Z16dispatch_command19enum_server_commandP3THDPcjbb. Si vous l'utilisez dans une fonction, vous pouvez vous connecter et obtenir le résultat. Dans l'écosystème de la perf, de nombreux outils rendent le démêlage automatique et bpfTrace n'est pas encore capable.Faites également attention au drapeau -Dpour nm. C'est important parce que MySQL, et maintenant de nombreux autres packages, sont livrés sans symboles dynamiques (symboles de débogage) - ils viennent dans d'autres packages. Si vous souhaitez utiliser ces caractères, vous avez besoin d'un drapeau -D, sinon nm ne les verra pas.: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .