 Les deux dernières années de mon temps libre, j'ai fait du triathlon. Ce sport est très populaire dans de nombreux pays du monde, en particulier aux États-Unis, en Australie et en Europe. Gagner actuellement une popularité rapide en Russie et dans les pays de la CEI. Il s'agit d'impliquer des amateurs, pas des professionnels. Contrairement à la simple natation dans la piscine, au vélo et au jogging le matin, le triathlon implique de participer à des compétitions et de se préparer systématiquement pour eux, même sans être un professionnel. Certes, parmi vos amis, il y a déjà au moins un «homme de fer» ou quelqu'un qui prévoit d'en devenir un. Massivité, une variété de distances et de conditions, trois sports en un - tout cela a le potentiel de former une grande quantité de données. Chaque année, plusieurs centaines de compétitions de triathlon ont lieu dans le monde, auxquelles participent plusieurs centaines de milliers de personnes.Les compétitions sont organisées par plusieurs organisateurs. Chacun d'eux, bien sûr, publie les résultats à part entière. Mais pour les athlètes de Russie et de certains pays de la CEI, l'équipetristats.ru recueille tous les résultats en un seul endroit - sur son site Web du même nom. Cela rend très pratique la recherche de résultats, aussi bien les vôtres que vos amis et rivaux, ou même vos idoles. Mais pour moi, cela a également permis d'analyser un grand nombre de résultats par programme. Résultats publiés sur trilife: lire .Ce fut mon premier projet de ce type, car ce n'est que récemment que j'ai commencé à faire l'analyse de données en principe, ainsi qu'à utiliser python. Par conséquent, je veux vous parler de la mise en œuvre technique de ce travail, d'autant plus que dans le processus, diverses nuances sont apparues, nécessitant parfois une approche particulière. Il s'agira de la mise au rebut, de l'analyse, des types et formats de casting, de la restauration de données incomplètes, de la création d'un échantillon représentatif, de la visualisation, de la vectorisation et même du calcul parallèle.Le volume s'est avéré important, j'ai donc tout divisé en cinq parties afin de pouvoir doser les informations et me rappeler par où commencer après la pause.Avant de poursuivre, il est préférable de lire d'abord mon article avec les résultats de l'étude, car ici décrit essentiellement la cuisine pour sa création. Cela prend 10-15 minutes.As-tu lu? Alors allons-y!
Les deux dernières années de mon temps libre, j'ai fait du triathlon. Ce sport est très populaire dans de nombreux pays du monde, en particulier aux États-Unis, en Australie et en Europe. Gagner actuellement une popularité rapide en Russie et dans les pays de la CEI. Il s'agit d'impliquer des amateurs, pas des professionnels. Contrairement à la simple natation dans la piscine, au vélo et au jogging le matin, le triathlon implique de participer à des compétitions et de se préparer systématiquement pour eux, même sans être un professionnel. Certes, parmi vos amis, il y a déjà au moins un «homme de fer» ou quelqu'un qui prévoit d'en devenir un. Massivité, une variété de distances et de conditions, trois sports en un - tout cela a le potentiel de former une grande quantité de données. Chaque année, plusieurs centaines de compétitions de triathlon ont lieu dans le monde, auxquelles participent plusieurs centaines de milliers de personnes.Les compétitions sont organisées par plusieurs organisateurs. Chacun d'eux, bien sûr, publie les résultats à part entière. Mais pour les athlètes de Russie et de certains pays de la CEI, l'équipetristats.ru recueille tous les résultats en un seul endroit - sur son site Web du même nom. Cela rend très pratique la recherche de résultats, aussi bien les vôtres que vos amis et rivaux, ou même vos idoles. Mais pour moi, cela a également permis d'analyser un grand nombre de résultats par programme. Résultats publiés sur trilife: lire .Ce fut mon premier projet de ce type, car ce n'est que récemment que j'ai commencé à faire l'analyse de données en principe, ainsi qu'à utiliser python. Par conséquent, je veux vous parler de la mise en œuvre technique de ce travail, d'autant plus que dans le processus, diverses nuances sont apparues, nécessitant parfois une approche particulière. Il s'agira de la mise au rebut, de l'analyse, des types et formats de casting, de la restauration de données incomplètes, de la création d'un échantillon représentatif, de la visualisation, de la vectorisation et même du calcul parallèle.Le volume s'est avéré important, j'ai donc tout divisé en cinq parties afin de pouvoir doser les informations et me rappeler par où commencer après la pause.Avant de poursuivre, il est préférable de lire d'abord mon article avec les résultats de l'étude, car ici décrit essentiellement la cuisine pour sa création. Cela prend 10-15 minutes.As-tu lu? Alors allons-y!Partie 1. Gratter et analyser
Éléments fournis
: site Web tristats.ru . Il existe deux types de tableaux qui nous intéressent. Il s'agit en fait d'un tableau récapitulatif de toutes les courses et d'un protocole des résultats de chacune d'elles.
 La tâche numéro un consistait à obtenir ces données par programme et à les enregistrer pour un traitement ultérieur. Il se trouve qu'à ce moment-là, j'étais nouveau dans les technologies Web et que je ne savais donc pas immédiatement comment procéder. J'ai commencé en conséquence avec ce que je savais - regardez le code de la page. Cela peut être fait en utilisant le bouton droit de la souris ou la touche F12 .
La tâche numéro un consistait à obtenir ces données par programme et à les enregistrer pour un traitement ultérieur. Il se trouve qu'à ce moment-là, j'étais nouveau dans les technologies Web et que je ne savais donc pas immédiatement comment procéder. J'ai commencé en conséquence avec ce que je savais - regardez le code de la page. Cela peut être fait en utilisant le bouton droit de la souris ou la touche F12 . Le menu dans Chrome contient deux options: Afficher le code de la page et Afficher le code . Pas la division la plus évidente. Naturellement, ils donnent des résultats différents. Celui qui affiche le code, c'est exactement la même chose que F12 - la représentation html directement textuelle de ce qui est affiché dans le navigateur est élément par élément.
Le menu dans Chrome contient deux options: Afficher le code de la page et Afficher le code . Pas la division la plus évidente. Naturellement, ils donnent des résultats différents. Celui qui affiche le code, c'est exactement la même chose que F12 - la représentation html directement textuelle de ce qui est affiché dans le navigateur est élément par élément.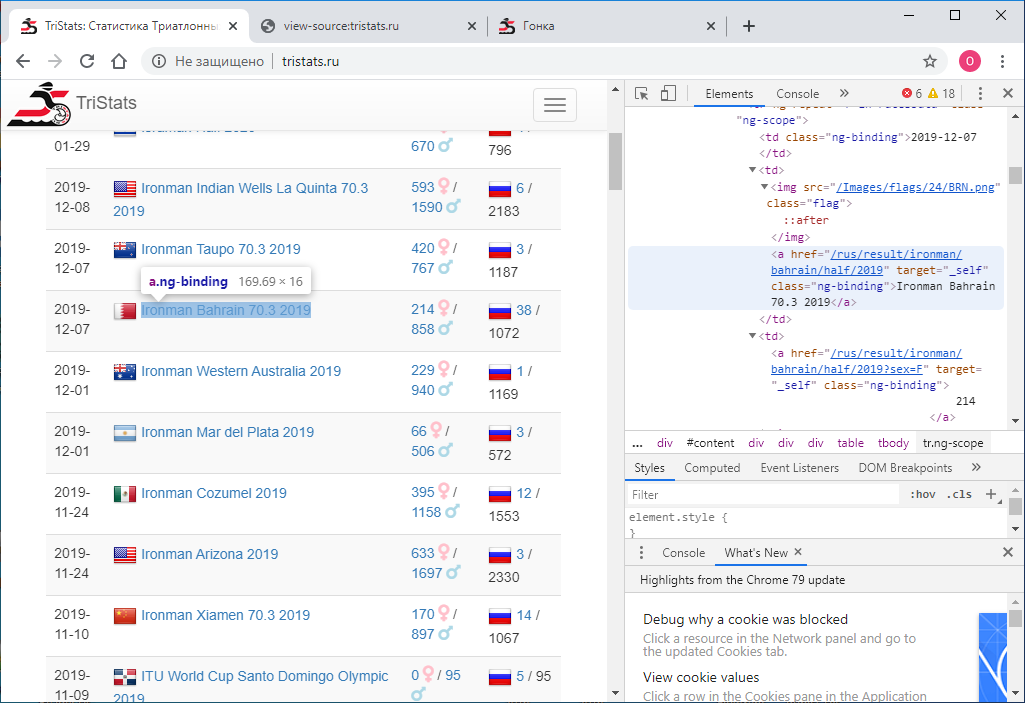 À son tour, l' affichage du code de la page donne le code source de la page. Aussi html , mais il n'y a pas de données, seulement les noms des scripts JS qui les déchargent. D'accord.
À son tour, l' affichage du code de la page donne le code source de la page. Aussi html , mais il n'y a pas de données, seulement les noms des scripts JS qui les déchargent. D'accord. Maintenant, nous devons comprendre comment utiliser python pour enregistrer le code de chaque page dans un fichier texte distinct. J'essaye ceci:
Maintenant, nous devons comprendre comment utiliser python pour enregistrer le code de chaque page dans un fichier texte distinct. J'essaye ceci:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
Et je reçois ... le code source. Mais j'ai besoin du résultat de son exécution. Après avoir étudié, cherché et demandé autour, j'ai réalisé que j'avais besoin d'un outil pour automatiser les actions du navigateur, par exemple, le sélénium . Je l'ai mis. Et aussi ChromeDriver pour travailler avec Google Chrome . Ensuite, je l'ai utilisé comme suit:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
Ce code lance une fenêtre de navigateur et ouvre une page dedans à l'url spécifiée. En conséquence, nous obtenons déjà du code html avec les données souhaitées. Mais il y a un hic. Le résultat est seulement 100 inscriptions, et le nombre total de courses est presque de 2000. Comment? Le fait est qu'au départ, seules les 100 premières entrées sont affichées dans le navigateur, et seulement si vous faites défiler tout en bas de la page, les 100 suivantes sont chargées, etc. Par conséquent, il est nécessaire d'implémenter le défilement par programmation. Pour ce faire, utilisez la commande:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Et à chaque défilement, nous vérifierons si le code de la page chargée a changé ou non. S'il n'a pas changé, nous vérifierons la fiabilité plusieurs fois, par exemple 10, puis la page entière est chargée et vous pouvez arrêter. Entre les parchemins, nous fixons le délai à une seconde afin que la page ait le temps de se charger. (Même si elle n'a pas le temps, nous avons une réserve - encore neuf secondes).Et le code complet ressemblera à ceci:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
Nous avons donc un fichier html avec un tableau récapitulatif de toutes les races. Besoin de l'analyser. Pour ce faire, utilisez la bibliothèque lxml .from lxml import html
On trouve d'abord toutes les lignes du tableau. Pour déterminer le signe d'une chaîne, il suffit de regarder le fichier html dans un éditeur de texte. Il peut s'agir, par exemple, «tr ng-repeat = 'r in racesData' class = 'ng-scope'» ou d'un fragment qui ne se trouve plus dans aucune balise.
Il peut s'agir, par exemple, «tr ng-repeat = 'r in racesData' class = 'ng-scope'» ou d'un fragment qui ne se trouve plus dans aucune balise.with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
nous commençons ensuite le cadre de données pandas et chaque élément de chaque ligne du tableau est écrit dans ce cadre de données.import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
Afin de comprendre où chaque élément spécifique est caché, il vous suffit de regarder le code html de l'un des éléments de nos lignes dans le même éditeur de texte.<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
Le moyen le plus simple de naviguer en code dur pour les enfants ici est qu'il n'y en a pas beaucoup.for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Voici le résultat: Enregistrez ce bloc de données dans un fichier. J'utilise des cornichons , mais ça pourrait être csv , ou autre chose.import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
À ce stade, toutes les données sont de type chaîne. Nous nous convertirons plus tard. La chose la plus importante dont nous avons besoin maintenant est des liens. Nous les utiliserons pour gratter les protocoles de toutes les races. Nous le faisons à l'image et à la manière dont cela a été fait pour le tableau croisé dynamique. Dans le cycle de toutes les courses pour chacune, nous allons ouvrir la page par référence, faire défiler et obtenir le code de la page. Dans le tableau récapitulatif, nous avons des informations sur le nombre total de participants à la course - total, nous allons l'utiliser pour comprendre jusqu'à quel point vous devez continuer à faire défiler. Pour ce faire, nous allons directement en train de gratter chaque page déterminer le nombre d'enregistrements dans le tableau et le comparer avec la valeur attendue du total. Dès qu'il est égal, nous avons défilé jusqu'à la fin et vous pouvez passer à la prochaine course. Nous avons également défini un délai d'expiration de 60 secondes. A mangé pendant ce temps, on n'arrive pas au total , on passe à la prochaine course. Le code de page sera enregistré dans un fichier. Nous allons enregistrer les fichiers de toutes les courses dans un dossier et les nommer par le nom des courses, c'est-à-dire par la valeur dans la colonne des événements du tableau récapitulatif. Pour éviter un conflit de noms, il est nécessaire que toutes les races aient des noms différents dans le tableau croisé dynamique. Vérifiez ça:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
C'est un long processus. Mais lorsque tout est mis en place et que ce mécanisme lourd commence à tourner, en ajoutant des fichiers de données les uns après les autres, une sensation d'excitation agréable vient. Seuls environ trois protocoles sont chargés par minute, très lentement. Laissé tourner pour la nuit. Cela a pris environ 10 heures. Le matin, la plupart des protocoles ont été téléchargés. Comme cela se produit généralement lorsque vous travaillez avec un réseau, quelques-uns échouent. Les a rapidement repris avec une deuxième tentative. Nous avons donc 1 922 fichiers avec une capacité totale de près de 3 Go. Cool! Mais la gestion de près de 300 courses s'est terminée par un temps mort. Que se passe-t-il? Vérifiez de manière sélective, il s'avère qu'en effet la valeur totale du tableau croisé dynamique et le nombre d'entrées dans le protocole de course que nous avons vérifié peuvent ne pas coïncider. C'est triste, car il n'est pas clair quelle est la raison de cet écart. Soit cela est dû au fait que tout le monde ne finira pas, soit à une sorte de bogue dans la base de données. En général, le premier signal d'imperfection des données. Dans tous les cas, nous vérifions ceux dans lesquels le nombre d'entrées est de 100 ou 0, ce sont les candidats les plus suspects. Il y en avait huit. Téléchargez-les à nouveau sous contrôle strict. Soit dit en passant, dans deux d'entre eux, il y a en fait 100 entrées.Eh bien, nous avons toutes les données. Nous passons à l'analyse. Encore une fois, dans un cycle, nous allons parcourir chaque course, lire le fichier et enregistrer le contenu dans un pandas DataFrame . Nous allons combiner ces trames de données dans un dict , dans lequel les noms des courses sont les clés - c'est-à-dire les valeurs d' événement du tableau croisé dynamique ou les noms des fichiers avec le code html des pages de course, ils coïncident.
Nous avons donc 1 922 fichiers avec une capacité totale de près de 3 Go. Cool! Mais la gestion de près de 300 courses s'est terminée par un temps mort. Que se passe-t-il? Vérifiez de manière sélective, il s'avère qu'en effet la valeur totale du tableau croisé dynamique et le nombre d'entrées dans le protocole de course que nous avons vérifié peuvent ne pas coïncider. C'est triste, car il n'est pas clair quelle est la raison de cet écart. Soit cela est dû au fait que tout le monde ne finira pas, soit à une sorte de bogue dans la base de données. En général, le premier signal d'imperfection des données. Dans tous les cas, nous vérifions ceux dans lesquels le nombre d'entrées est de 100 ou 0, ce sont les candidats les plus suspects. Il y en avait huit. Téléchargez-les à nouveau sous contrôle strict. Soit dit en passant, dans deux d'entre eux, il y a en fait 100 entrées.Eh bien, nous avons toutes les données. Nous passons à l'analyse. Encore une fois, dans un cycle, nous allons parcourir chaque course, lire le fichier et enregistrer le contenu dans un pandas DataFrame . Nous allons combiner ces trames de données dans un dict , dans lequel les noms des courses sont les clés - c'est-à-dire les valeurs d' événement du tableau croisé dynamique ou les noms des fichiers avec le code html des pages de course, ils coïncident.rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
Partie 2. Casting et formatage des types
Nous avons donc téléchargé toutes les données et les avons placées dans les trames de données. Cependant, toutes les valeurs sont de type str . Cela s'applique à la date, aux résultats, à l'emplacement et à tous les autres paramètres. Tous les paramètres doivent être convertis dans les types appropriés.Commençons par le tableau croisé dynamique.date et l'heure
événement , loc et lien seront laissés tels quels. date convertie en pandas datetime comme suit:rs['date'] = pd.to_datetime(rs['date'])
Les autres sont convertis en un type entier:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
Tout s'est bien passé, aucune erreur n'est survenue. Donc tout va bien - sauf:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
Maintenant, les trames de données de course. Étant donné que toutes les races sont plus pratiques et plus rapides à traiter en même temps, et pas une à la fois, nous les collecterons dans un grand bloc de données ar (abrégé pour tous les enregistrements ) en utilisant la méthode concat .ar = pd.concat(rd)
ar contient 1 416 365 entrées.Convertissez maintenant place et place en groupe en une valeur entière.ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
Ensuite, nous traitons les colonnes avec des valeurs temporaires. Nous les moulerons dans le type Timedelta des pandas . Mais pour que la conversion réussisse, vous devez préparer correctement les données. Vous pouvez voir que certaines valeurs inférieures à une heure vont sans spécifier le conseil. Besoin de l'ajouter.for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Maintenant, les temps, les chaînes restantes, ressemblent à ceci: Convertir en Timedelta :for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
Sol
Passez. Vérifiez que dans la colonne sexe il n'y a que les valeurs de M et F :ar['sex'].unique()
Out: ['M', 'F', '']
En fait, il y a toujours une chaîne vide, c'est-à-dire que le sexe n'est pas spécifié. Voyons combien de tels cas:len(ar[ar['sex'] == ''])
Out: 2538
Pas tant que ça, c'est bien. À l'avenir, nous essaierons de réduire encore cette valeur. En attendant, laissez la colonne sexe telle quelle sous forme de lignes. Nous enregistrerons le résultat avant de passer à des transformations plus sérieuses et risquées. Afin de maintenir la continuité entre les fichiers, nous transformons la trame de données combinée ar en dictionnaire de trames de données rd :for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
Soit dit en passant, en raison de la conversion des types de certaines colonnes, la taille des fichiers est passée de 367 Ko à 295 Ko pour le tableau croisé dynamique et de 251 Mo à 168 Mo pour les protocoles de course.Code postal
Voyons maintenant le pays.ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412 valeurs uniques.Fondamentalement, un pays est indiqué par un code alphabétique à trois chiffres en majuscules. Mais apparemment, pas toujours. En fait, il existe une norme internationale ISO 3166 , dans laquelle pour tous les pays, y compris même ceux qui n'existent plus, les codes à trois et à deux chiffres correspondants sont prescrits. Pour python, l' une des implémentations de cette norme peut être trouvée dans le paquet pycountry . Voici comment ça fonctionne:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Ainsi, nous allons vérifier tous les codes à trois chiffres, conduisant à des majuscules, qui donnent une réponse dans countries.get (...) et historical_countries.get (...) :valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Il y en avait 190 sur 412, soit moins de la moitié.Pour les 222 restants (nous désignons leur liste par tofix ), nous créerons un dictionnaire de correspondance de correctifs , dans lequel la clé sera le nom d'origine et la valeur sera un code à trois chiffres selon la norme ISO.tofix = list(set(ar['country'].unique()) - set(valid_a3))
Tout d'abord, vérifiez les codes à deux chiffres avec pycountry.countries.get (alpha_2 = ...) , ce qui conduit à des majuscules:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Ensuite, les noms complets via pycountry.countries.get (nom = ...), pycountry.countries.get (common_name = ...) , les menant à la forme str.title () :for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Ainsi, nous réduisons le nombre de valeurs non reconnues à 190. Encore beaucoup: vous remarquerez peut-être qu'il existe encore de nombreux codes à trois chiffres, mais ce n'est pas un ISO. Et alors? Il s'avère qu'il existe une autre norme - olympique . Malheureusement, son implémentation n'est pas incluse dans pycountry et vous devez chercher autre chose. La solution a été trouvée sous la forme d'un fichier csv sur datahub.io . Placez le contenu de ce fichier dans un DataFrame pandas appelé cdf . ioc - Comité olympique international (CIO)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Parmi les codes à trois chiffres de tofix, 82 IOC correspondants ont été trouvés. Ajoutez-les à notre dictionnaire correspondant.for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
Il reste 108 valeurs brutes. Ils sont terminés manuellement, se tournant parfois vers Google pour obtenir de l'aide. Mais même le contrôle manuel ne résout pas complètement le problème. Il reste 49 valeurs qui sont déjà impossibles à interpréter. La plupart de ces valeurs ne sont probablement que des erreurs de données.{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
Ces clés auront une chaîne vide dans le dictionnaire correspondant.for cc in unfixed:
fix[cc] = ''
Enfin, nous ajoutons aux codes du dictionnaire correspondants qui sont valides mais écrits en minuscules.for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
Il est maintenant temps d'appliquer les remplacements trouvés. Pour enregistrer les données initiales de comparaison plus loin, copier le pays colonne à cru du pays . Ensuite, en utilisant le dictionnaire de correspondance créé, nous corrigeons les valeurs de la colonne pays qui ne correspondent pas à ISO.for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
Ici, bien sûr, on ne peut pas se passer de vectorisation, le tableau compte près d'un million et demi de lignes. Mais selon le dictionnaire, nous faisons un cycle, mais comment d'autre? Vérifiez le nombre d'enregistrements modifiés:len(ar[ar['country'] != ar['country raw']])
Out: 315955
c'est-à-dire plus de 20% du total.ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
Il s'agit du nombre d'enregistrements sans pays ou avec un pays informel. Le nombre de pays uniques est passé de 412 à 250. Les voici: Désormais, il n'y a plus d'écart. Nous enregistrons le résultat dans un nouveau fichier details2.pkl , après avoir reconverti la trame de données combinée en un dictionnaire de trames de données, comme cela a été fait précédemment.['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Emplacement
Rappelons maintenant que la mention des pays figure également dans le tableau croisé dynamique, dans la colonne loc . Il doit également être ramené à un aspect standard. Voici une histoire légèrement différente: ni l'ISO ni les codes olympiques ne sont visibles. Tout est décrit sous une forme assez libre. La ville, le pays et les autres composants de l'adresse sont répertoriés avec une virgule et dans un ordre aléatoire. Quelque part en premier lieu, quelque part en dernier. pycountry n'aidera pas ici. Et il y a beaucoup de records - pour la course de 1922 525 emplacements uniques (dans sa forme originale). Mais ici, un outil approprié a été trouvé. C'est la géopie , à savoir le géolocalisateur Nominatim . Cela fonctionne comme ceci:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
Sur demande, sous une forme aléatoire, il donne une réponse structurée - adresse et coordonnées. Si vous définissez la langue, comme ici - l'anglais, alors ce qu'elle peut - se traduira. Tout d'abord, nous avons besoin du nom standard du pays pour une traduction ultérieure dans le code ISO. Il prend juste la dernière place dans la propriété d' adresse . Étant donné que le géolocalisateur envoie une demande au serveur à chaque fois, ce processus n'est pas rapide et prend 500 minutes pour 500 enregistrements. De plus, il arrive que la réponse ne vienne pas. Dans ce cas, une deuxième demande aide parfois. Dans ma première réponse, je n'ai pas reçu 130 demandes. La plupart d'entre eux ont été traités avec deux nouvelles tentatives. Cependant, 34 noms n'ont pas été traités, même par plusieurs nouvelles tentatives. Les voici:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
On peut voir que dans beaucoup, il y a une double mention du pays, et cela interfère en fait. En général, j'ai dû traiter manuellement ces noms restants et les adresses standard ont été obtenues pour tous. De plus, à partir de ces adresses, j'ai sélectionné un pays et j'ai écrit ce pays dans une nouvelle colonne du tableau croisé dynamique. Comme, comme je l'ai dit, travailler avec geopy n'est pas rapide, j'ai décidé d'enregistrer immédiatement les coordonnées de l'emplacement - latitude et longitude. Ils seront utiles plus tard pour la visualisation sur la carte. Après cela, en utilisant pyco.countries.get (name = '...'). Alpha_3 a recherché le pays par son nom et lui a attribué un code à trois chiffres.Distance
Une autre action importante qui doit être effectuée sur le tableau croisé dynamique consiste à déterminer la distance pour chaque course. Cela nous est utile pour calculer les vitesses à l'avenir. Dans le triathlon, il y a quatre distances principales - sprint, olympique, semi-fer et fer. Vous pouvez voir que dans les noms des courses, il y a généralement une indication de la distance - ce sont Sprint , Olympic , Half , Full Words . De plus, différents organisateurs ont leurs propres désignations de distances. La moitié de l'Ironman, par exemple, est désignée comme 70,3 - par le nombre de miles de distance, l'Olympic - 5150 par le nombre de kilomètres (51,5), et le fer peut être désigné comme Fullou, en général, comme un manque d'explication - par exemple, Ironman Arizona 2019 . Ironman - il est fer! Dans Challenge, la distance du fer est désignée comme longue et la distance semi- fer est désignée comme moyenne . Notre IronStar russe signifie plein comme 226 , et moitié comme 113 - par le nombre de kilomètres, mais généralement les mots plein et demi sont également présents. Appliquez maintenant toutes ces connaissances et marquez toutes les races conformément aux mots-clés présents dans les noms.sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
En rsd, il s'est avéré 1 925 records, soit trois de plus que le nombre total de courses, donc certains tombaient sous deux critères. Regardons-les:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
Nous ferons de même avec l'intersection Ironman Dun Laoghaire Full Swim 70.3 2019 Voici le meilleur temps à 4h00. C'est typique de la moitié. Supprimez l'enregistrement avec l'index 85 des pleins .fulls.drop(85)
Nous allons maintenant noter les informations de distance dans le bloc de données principal et voir ce qui s'est passé:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
Et découvrez nos problèmes, ambigus:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Les groupes d'âge
Revenons maintenant aux protocoles de course.Nous avons déjà analysé le sexe, le pays et les résultats du participant, et les avons amenés à une forme standard. Mais il restait encore deux colonnes - le groupe et, en fait, le nom lui-même. Commençons par les groupes. Dans le triathlon, il est habituel de diviser les participants par groupes d'âge. Un groupe de professionnels se distingue également souvent. En fait, le décalage est dans chacun de ces groupes séparément - les trois premières places de chaque groupe sont attribuées. En groupe, la qualification est sélectionnée pour les championnats, par exemple sur Konu.Combinez tous les enregistrements et voyez quels groupes existent généralement.rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
Il s'est avéré qu'il y avait un grand nombre de groupes - 581. Une centaine de personnes sélectionnées au hasard ressemble à ceci: Voyons quels sont les plus nombreux:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Vous pouvez voir que ce sont des groupes de cinq ans, séparément pour les hommes et séparément pour les femmes, ainsi que les groupes professionnels MPRO et FPRO .Notre norme sera donc:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
Cet ensemble couvre près de 95% de tous les finisseurs.Bien sûr, nous ne pourrons pas amener tous les groupes à cette norme. Mais nous recherchons ceux qui leur sont similaires et en donnons au moins une partie. Tout d'abord, nous allons mettre en majuscule et supprimer les espaces. Voici ce qui s'est passé: convertissez-les en nos standards.['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Maintenant, nous appliquons notre transformation au cadre de données principal ar , mais enregistrons d'abord les valeurs de groupe d' origine dans la nouvelle colonne brute de groupe .ar['group raw'] = ar['group']
Dans la colonne groupe , nous ne laissons que les valeurs conformes à notre norme.Nous pouvons maintenant apprécier nos efforts:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Juste un peu au niveau d'un million et demi. Mais vous ne le saurez pas avant d’essayer.Les 10 sélectionnés ressemblent à ceci: Enregistrez la nouvelle version du bloc de données, après l'avoir reconvertie dans le dictionnaire rd .pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
Nom
Maintenant, prenons soin des noms. Voyons sélectivement 100 noms de races différentes:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
C'est compliqué. Il existe une variété d'options pour les entrées: Prénom Nom de famille, Nom de famille Prénom, Nom de famille, Prénom, Nom de famille, Prénom , etc. Autrement dit, un ordre différent, un registre différent, quelque part il y a un séparateur - une virgule. Il existe également de nombreux protocoles dans lesquels va cyrillique. Il n'y a pas non plus d'uniformité, et de tels formats peuvent être trouvés: «Nom Prénom», «Prénom Nom», «Prénom Second prénom Nom», «Nom Prénom Deuxième prénom». Bien qu'en fait, le deuxième prénom se trouve également dans l'orthographe latine. Et ici, en passant, un autre problème se pose - la translittération. Il convient également de noter que même en l'absence de deuxième prénom, l'enregistrement peut ne pas être limité à deux mots. Par exemple, pour les Hispaniques, le nom plus le nom de famille se compose généralement de trois ou quatre mots. Les Néerlandais ont le préfixe Van, les Chinois et les Coréens ont également des noms composés généralement de trois mots. En général, vous devez en quelque sorte démêler tout ce rébus et le normaliser au maximum. En règle générale, au sein d'une course, le format du nom est le même pour tout le monde, mais même ici, il y a des erreurs que nous ne traiterons pas. Commençons par stocker les valeurs existantes dans le nouveau nom de colonne raw :ar['name raw'] = ar['name']
La grande majorité des protocoles sont en latin, donc la première chose que je voudrais faire est la translittération. Voyons quels caractères peuvent être inclus dans le nom du participant.set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Qu'y a-t-il seulement! En plus des lettres et des espaces réels, il y a encore un tas de différents personnages bizarres. Parmi ceux-ci, la période «.», Le tiret «-» et l'apostrophe «» peuvent être considérés comme valides, c'est-à-dire non présents par erreur. De plus, il a été remarqué que dans de nombreux noms et prénoms allemands et norvégiens, il y a un point d'interrogation «?». Apparemment, ils remplacent les caractères de l'alphabet latin étendu - «?», «A», «o», «u»,? Voici quelques exemples: La virgule, bien qu'elle se produise très souvent, n'est qu'un séparateur, adopté à certaines races, elle tombera donc également dans la catégorie des inacceptables. Les chiffres ne doivent pas non plus apparaître dans les noms.Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Nous supprimerons temporairement tous ces caractères pour savoir combien d'entrées ils sont présents:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
Il existe 2 184 enregistrements de ce type, soit seulement 0,15% du nombre total - très peu. Jetons un coup d'œil à 100 d'entre eux:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
En conséquence, après de nombreuses recherches, il a été décidé: de remplacer tous les caractères alphabétiques, ainsi qu'un espace, un trait d'union, une apostrophe et un point d'interrogation, par une virgule, un point et un symbole et des espaces '\ xa0', et de remplacer tous les autres caractères par une chaîne vide, c'est-à-dire, supprimez simplement.ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
Ensuite, débarrassez-vous des espaces supplémentaires:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
Voyons ce qui se passe:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
Il y en a 3 429. Cela ressemble à ceci: Notre objectif de ramener les noms à la même norme est de faire en sorte que les mêmes noms se ressemblent, mais diffèrent de différentes manières. Dans le cas de noms composés uniquement de points d'interrogation, ils ne diffèrent que par le nombre de caractères, mais cela ne donne pas la pleine confiance que les noms avec le même numéro sont vraiment les mêmes. Par conséquent, nous les remplaçons tous par une chaîne vide et ne seront pas pris en compte à l'avenir.ar.loc[qmon.index, 'name'] = ''
Le nombre total d'entrées où le nom est la chaîne vide est de 3 454. Pas tellement - nous survivrons. Maintenant que nous nous sommes débarrassés des caractères inutiles, nous pouvons procéder à la translittération. Pour ce faire, mettez d'abord tout en minuscules afin de ne pas faire de double travail.ar['name'] = ar['name'].str.lower()
Ensuite, créez un dictionnaire:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
Il comprenait également des lettres de ce que l'on appelle l'alphabet cyrillique étendu - «є», «і», «ў» , qui sont utilisées dans les langues biélorusse et ukrainienne, ainsi que la lettre grecque «µ» . Appliquez la transformation:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
Maintenant, à partir de la minuscule de travail, nous allons tout traduire dans le format familier, où le prénom et le nom commencent par une majuscule:ar['name'] = ar['name'].str.title()
Voyons ce qui se passe.ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Tout est correct. En conséquence, les corrections ont touché 1 253 882 ou 89% des enregistrements, le nombre de noms uniques est passé de 660 207 à 599 186, soit 61 000, soit près de 10%. Hou la la! Enregistrez dans un nouveau fichier, après avoir converti l'union des enregistrements ar dans le dictionnaire de protocole rd .pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
Maintenant, nous devons rétablir l'ordre. Autrement dit, tous les enregistrements devraient ressembler à - Prénom Nom de famille ou Nom de famille Prénom . Lequel est à déterminer. Certes, en plus du nom et du prénom, certains protocoles contiennent également des prénoms. Et il peut arriver que la même personne soit écrite différemment dans différents protocoles - quelque part avec un deuxième prénom, quelque part sans. Cela interférera avec son identification, essayez donc de supprimer le deuxième prénom. Les patronymes pour les hommes ont généralement la terminaison «vih» et pour les femmes - «vna» . Mais il y a des exceptions. Par exemple - Ilyich, Ilyinichna, Nikitich, Nikitichna. Certes, il existe très peu d'exceptions de ce type. Comme déjà indiqué, le format des noms au sein d'un même protocole peut être considéré comme permanent. Par conséquent, pour vous débarrasser des patronymes, vous devez trouver la race dans laquelle ils sont présents. Pour ce faire, recherchez le nombre total de fragments "vich" et "vna" dans le nom de la colonneet les comparer avec le nombre total d'entrées dans chaque protocole. Si ces nombres sont proches, alors il y a un deuxième prénom, sinon non. Il n'est pas raisonnable de rechercher une conformité stricte, même dans les courses où les prénoms sont enregistrés, par exemple, les étrangers peuvent participer, et ils seront enregistrés sans lui. Il arrive aussi que le participant oublie ou ne veuille pas indiquer son deuxième prénom. D'autre part, il existe également des noms de famille se terminant par "vich", il y en a beaucoup au Bélarus et dans d'autres pays avec les langues du groupe slave. De plus, nous avons fait de la translittération. Il était possible de faire cette analyse avant la translittération, mais il y a alors une chance de manquer un protocole dans lequel il y a des prénoms, mais au départ il est déjà en latin. Alors tout va bien.Nous allons donc rechercher tous les protocoles dans lesquels le nombre de fragments «vich» et «vna» dans la colonnenom représente plus de 50% du nombre total d'entrées dans le protocole.wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
Il existe 29 protocoles de ce type et il est intéressant de noter que si au lieu de 50% nous prenons 20% ou vice versa 70%, le résultat ne changera pas, il en sera de même 29. Nous avons donc fait le bon choix. En conséquence, moins de 20% - l'effet des noms de famille, plus de 70% - l'effet des enregistrements individuels sans prénoms. Après avoir vérifié le pays à l'aide d'un tableau croisé dynamique, il s'est avéré que 25 d'entre eux étaient en Russie, 4 en Abkhazie. Continuons. Nous ne traiterons que les enregistrements à trois composants, c'est-à-dire ceux où il y a (vraisemblablement) un nom de famille, un prénom, un deuxième prénom.sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
La majorité de ces enregistrements est de 86%. Maintenant ceux dans lesquels les trois composants sont divisés en colonnes nom0, nom1, nom2 :for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
Voici à quoi ressemble l'un des protocoles: Ici, en particulier, il est clair que l'enregistrement des deux composants n'a pas été traité. Maintenant, pour chaque protocole, vous devez déterminer quelle colonne a un deuxième prénom. Il n'y a que deux options - nom1, nom2 , car il ne peut pas être en premier lieu. Une fois déterminé, nous recueillerons déjà un nouveau nom sans lui.for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
Vous devez maintenant mettre les noms dans le même ordre. Autrement dit, il est nécessaire que dans tous les protocoles, le nom suivi en premier du nom de famille, ou vice versa - d'abord le nom de famille, puis le prénom, également dans tous les protocoles. Cela dépend de quoi de plus, nous allons maintenant le découvrir. La situation est légèrement compliquée par le fait que le nom complet peut comprendre plus de deux mots, même après avoir supprimé le deuxième prénom.ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
Nombre de mots dans un nom Nombre d'enregistrements Part d'enregistrements (%) Bien sûr, la grande majorité (91%) sont deux mots - juste un nom et un nom de famille. Mais les entrées de trois et quatre mots sont également très nombreuses. Regardons la nationalité de ces enregistrements:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
Eh bien, en premier lieu, l'Espagne, en deuxième - le Mexique, un pays hispanique, plus loin que les États-Unis, où il y a aussi historiquement beaucoup d'Hispaniques. Le Brésil et les Philippines sont également des noms espagnols (et portugais). Le Danemark, les Pays-Bas, l'Allemagne, l'Afrique du Sud, l'Italie, la Belgique et la France sont une autre affaire, il y a simplement parfois une sorte de préfixe au nom de famille, donc il y a plus de deux mots. Dans tous ces cas, cependant, le nom lui-même se compose généralement d'un mot et le nom de famille de deux, trois. Bien sûr, il existe des exceptions à cette règle, mais nous ne les traiterons plus. Tout d'abord, pour chaque protocole, vous devez déterminer le type de commande: nom-prénom ou vice versa. Comment faire? L'idée suivante m'est venue à l'esprit: premièrement, la variété des noms de famille est généralement beaucoup plus grande que la variété des noms. Il devrait en être ainsi même dans le cadre d'un protocole. Deuxièmement,la longueur du prénom est généralement inférieure à la longueur du nom de famille (même pour les noms de famille non composites). Nous utiliserons une combinaison de ces critères pour déterminer la commande préliminaire.Sélectionnez le premier et le dernier mot du nom complet:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
Convertissez à nouveau le bloc de données ar combiné dans le dictionnaire rd afin que les nouvelles colonnes nwin, ns0, ns tombent dans le bloc de données de chaque race. Ensuite, nous déterminons le nombre de protocoles avec l'ordre «Prénom Nom» et le nombre de protocoles avec l'ordre inverse selon notre critère. Nous ne considérerons que les entrées dont le nom complet se compose de deux mots. Dans le même temps, enregistrez le nom (prénom) dans une nouvelle colonne:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
Il s'est avéré ce qui suit: l'ordre Prénom Nom - 244 protocoles, l'ordre Nom Prénom - 1 508 protocoles.En conséquence, nous aboutirons au format le plus courant. La somme s'est avérée inférieure au montant total, car nous avons vérifié le respect de deux critères à la fois, et même avec une stricte inégalité. Il existe des protocoles dans lesquels un seul des critères est rempli, ou c'est possible, mais il est peu probable que l'égalité ait lieu. Mais cela n'a absolument aucune importance puisque le format est défini.Maintenant, en supposant que nous avons déterminé la commande avec une précision suffisamment élevée, sans oublier qu'elle n'est pas exacte à 100%, nous utiliserons ces informations. Trouvez les noms les plus populaires dans la colonne Prénom :vc = ar['first name'].value_counts()
prenez ceux qui se sont rencontrés plus d'une centaine de fois:pfn=vc[vc>100]
il y en avait 1 673. Voici les cent premiers, classés par ordre décroissant de popularité: Maintenant, en utilisant cette liste, nous allons parcourir tous les protocoles et comparer où il y a plus de correspondances - dans le premier mot du nom ou dans le dernier. Nous ne considérerons que les noms de deux mots. S'il y a plus de correspondances avec le dernier mot, alors l'ordre est correct, si avec le premier, cela signifie le contraire. De plus, ici, nous sommes déjà plus confiants, vous pouvez donc utiliser ces connaissances, et nous ajouterons une liste de noms de leur prochain protocole à la liste initiale de noms populaires à chaque passage. Nous pré-trions les protocoles par la fréquence d'occurrence des noms de la liste initiale afin d'éviter les erreurs aléatoires et préparons une liste plus complète pour les protocoles dans lesquels il y a peu de correspondances et qui seront traités vers la fin du cycle.['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
Il y avait 235 protocoles. C'est à peu près la même chose que ce qui s'est passé dans la première approximation (244). Pour être sûr, j'ai regardé sélectivement les trois premiers enregistrements de chacun, en m'assurant que tout était correct. Vérifiez également que la première étape du tri a donné 36 fausses entrées du nom de classe Nom et 2 fausses du nom de classe Nom . J'ai regardé les trois premiers disques de chacun, en effet, la deuxième étape a parfaitement fonctionné. Maintenant, en fait, il reste à corriger ces protocoles où le mauvais ordre est trouvé:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
Ici, dans la division, nous avons limité le nombre de pièces en utilisant le paramètre n . La logique est la suivante: un nom est un mot, le premier d'un nom complet. Tout le reste est un nom de famille (peut comprendre plusieurs mots). Échangez-les.Maintenant, nous nous débarrassons des colonnes inutiles et économisons:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
Vérifiez le résultat. Une douzaine d'enregistrements fixes aléatoires: Au total, 108 000 enregistrements ont été corrigés. Le nombre de noms complets uniques est passé de 598 à 547 000. Bien! Une fois le formatage terminé.Partie 3. Récupération de données incomplètes
Passez maintenant à la récupération des données manquantes. Et il y en a.Pays
Commençons par le pays. Recherchez tous les enregistrements dans lesquels le pays n'est pas indiqué:arnc = ar[ar['country'] == '']
Il y en a 3 221, dont 10 au hasard:nnc = arnc['name'].unique()
Le nombre de noms uniques parmi les enregistrements sans pays est de 3 051. Voyons si ce nombre peut être réduit.Le fait est que dans le triathlon, les gens se limitent rarement à une seule course, ils participent généralement à des compétitions périodiquement, plusieurs fois par saison, d'année en année, s'entraînant constamment. Par conséquent, pour de nombreux noms dans les données, il y a très probablement plus d'un enregistrement. Pour restaurer les informations sur le pays, essayez de trouver des enregistrements du même nom parmi ceux dans lesquels le pays est indiqué.arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
Il y en avait 2 236, soit près des trois quarts. Maintenant, pour chaque nom de cette liste, vous devez déterminer le pays par les enregistrements où il se trouve. Mais il arrive que le même nom se retrouve dans plusieurs enregistrements et dans différents pays. Il s'agit soit de l'homonyme, soit de la personne qui a déménagé. Par conséquent, nous traitons d'abord ceux où tout est unique.fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
Fabriqué en boucle. Mais, franchement, cela fonctionne pendant longtemps - environ trois minutes. S'il y avait un ordre de grandeur de plus d'entrées, vous devriez probablement trouver une implémentation vectorielle. Il y avait 2 013 entrées, soit 90% du potentiel.Les noms pour lesquels différents pays peuvent apparaître dans différents enregistrements, prennent le pays qui apparaît le plus souvent.if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
Ainsi, des correspondances ont été trouvées pour 2 208 noms, soit 99% de tous les noms potentiels. Nous appliquons ces correspondances:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
Sol
Comme dans le cas des pays, il existe des enregistrements dans lesquels le sexe du participant n'est pas indiqué.ar[ar['sex'] == '']
Il y en a 2 538. Relativement peu, mais encore une fois, essayez d'en faire encore moins. Enregistrez les valeurs d'origine dans une nouvelle colonne.ar['sex raw'] =ar['sex']
Contrairement aux pays où nous avons récupéré des informations par nom à partir d'autres protocoles, tout est un peu plus compliqué ici. Le fait est que les données sont pleines d'erreurs et il existe de nombreux noms (total 2 101) avec des marques des deux sexes.arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
Il y en a 633. Il semblerait que cela soit tout à fait possible, juste un protocole séparément pour les femmes, séparément pour les hommes. Mais le fait est que presque tous ces protocoles contiennent des groupes d'âge des deux sexes (les groupes d'âge masculins commencent par la lettre M , féminin - par la lettre F ). Par exemple: Il est prévu que le nom du groupe d'âge commence par la lettre M pour les hommes et par la lettre F pour les femmes. Dans les deux exemples précédents, malgré les erreurs dans la colonne sexe'ITU World Cup Tiszaujvaros Olympic 2002'
, le nom du groupe semblait toujours décrire correctement le sexe du membre. Sur la base de plusieurs exemples, nous supposons que le groupe est indiqué correctement et que le sexe peut être indiqué par erreur. Recherchez toutes les entrées dont la première lettre du nom du groupe ne correspond pas au sexe. Nous prendrons le nom initial du groupe de groupes brut , car pendant la normalisation de nombreux enregistrements ont été laissés sans groupe, mais maintenant nous n'avons besoin que de la première lettre, donc la norme n'est pas importante.ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
Il existe 26 161 enregistrements de ce type. Eh bien, corrigeons le sexe en fonction du nom du groupe d'âge:ar.loc[grncs.index, 'sex'] = grncs['grflc']
Regardons le résultat: bien. Combien d'enregistrements sont maintenant laissés sans sexe?ar[(ar['sex'] == '')&(ar['name'] != '')]
Il s'avère exactement un! Eh bien, le groupe n'est pas vraiment indiqué, mais, apparemment, c'est une femme. Emily est un prénom féminin, outre ce participant (ou son homonyme) terminé un an plus tôt, et dans ce protocole, le sexe et le groupe sont indiqués. Restaurer ici manuellement * et continuer.ar.loc[arns.index, 'sex'] = 'F'
Maintenant, tous les enregistrements sont de sexe.* En général, bien sûr, c'est mal de le faire - avec des exécutions répétées, si quelque chose dans la chaîne change avant, par exemple, dans la conversion de nom, alors il peut y avoir plus d'un enregistrement sans sexe, et tous ne seront pas féminins, une erreur se produira. Par conséquent, vous devez soit insérer une logique lourde pour rechercher un participant avec le même nom et le même sexe dans d'autres protocoles, par exemple pour restaurer un pays et comment le tester, ou, afin de ne pas compliquer inutilement, ajouter à cette logique une vérification qu'un seul enregistrement est trouvé et le nom est tel ou tel, sinon lancez une exception qui arrêtera tout l'ordinateur portable, vous pouvez remarquer une déviation du plan et intervenir.if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
Il semblerait que cela puisse se calmer. Mais le fait est que les corrections sont basées sur l'hypothèse que le groupe est indiqué correctement. Et c'est effectivement le cas. Presque toujours. Presque. Pourtant, plusieurs incohérences ont été accidentellement constatées, alors essayons maintenant de toutes les déterminer, enfin, ou autant que possible. Comme déjà mentionné, dans le premier exemple, c'est précisément le fait que le sexe ne correspondait pas au nom sur la base de ses propres idées sur les noms masculins et féminins qui nous gardait.Trouvez tous les noms sur les enregistrements masculins et féminins. Ici, le nom est compris comme le nom et non le nom complet, c'est-à-dire sans nom, ce qu'on appelle le prénom en anglais .ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
Au total, 32 508 noms masculins sont répertoriés. Voici les 50 plus populaires:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
Moins de femmes - 14 423. Le plus populaire: Bon, il semble logique. Voyons s'il y a des intersections.['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
Il y a. Et il y en a 2 811. Examinons-les de plus près. Pour commencer, nous découvrons combien d'enregistrements avec ces noms:armfn = ar[ar['fn'].isin(mffn)]
Il y en a 725 562. C'est la moitié! C'est étonnant! Il y a près de 37 000 noms uniques, mais la moitié des enregistrements ont un total de 2 800. Voyons quels sont ces noms, qui sont les plus populaires. Pour ce faire, créez un nouveau bloc de données où ces noms seront des indices:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
Nous calculons le nombre d'enregistrements masculins et féminins avec chacun d'eux.df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
Tout va bien. Mais si vous vérifiez le nom d' Andrea , il donne également une femelle , ce qui n'est pas entièrement vrai. Certes, il existe une issue. Si vous regardez la propriété names du détecteur, alors toute l'ambiguïté y devient visible.d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
Ouais, c'est-à-dire que get_gender vous donne juste l'option la plus probable, mais en réalité cela peut être beaucoup plus compliqué. Vérifiez les autres noms:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
C'est-à-dire que la liste des noms pour chaque nom correspond à une ou plusieurs paires clé-valeur, où la clé - c'est le sexe: masculin, FEMELLE, majoritairement masculin, majoritairement féminin et andy , et la valeur - la liste des valeurs du pays correspondant: 1,2,3 ... .. 9ABC . Les pays sont:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
Je n'ai pas bien compris ce que signifient spécifiquement les significations alphanumériques ou leur absence dans la liste. Mais ce n'était pas important, car j'ai décidé de me limiter à n'utiliser que les noms qui ont une interprétation sans ambiguïté. C'est-à-dire, pour lequel il n'y a qu'une seule paire clé-valeur et la clé est soit mâle soit femelle . Pour chaque nom de notre base de données, écrivez son interprétation du genre-devineur :df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
Il s'est avéré 1150 noms. Voici les plus populaires qui ont déjà été discutées ci-dessus: Eh bien, pas mal. Appliquez maintenant cette logique à tous les enregistrements.all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
7 071 noms masculins et 5 054 femmes trouvés. Appliquez la transformation:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
Nous regardons le résultat:ar[ar['sex']!=ar['sex raw']]
Correction de 30 352 entrées (avec la correction par le nom du groupe). Comme d'habitude, 10 au hasard: Maintenant que nous sommes sûrs d'avoir correctement identifié le sexe, nous alignerons également les groupes standard. Voyons où ils ne correspondent pas:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4 248 entrées. Remplacez la première lettre:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
C'est tout, avec la récupération de données incomplètes.Mise à jour du bulletin
Il reste à mettre à jour le tableau récapitulatif avec des données actualisées sur le nombre d'hommes et de femmes, etc.rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
Partie 4. Échantillonnage
Maintenant, le triathlon est très populaire. Au cours de la saison, il existe de nombreuses compétitions ouvertes auxquelles participent un grand nombre d'athlètes, principalement des amateurs. Mais ce ne fut pas toujours ainsi. Il y a des enregistrements dans nos données depuis 1990. En parcourant tristats.ru, j'ai remarqué qu'il y a beaucoup plus de courses ces dernières années, et très peu au cours des premières. Mais maintenant que nos données ont été préparées, vous pouvez les regarder de plus près.Période de dix ans
Comptez le nombre de courses et de finisseurs chaque année:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
 On peut voir que le nombre de courses et de participants au début de la période et à la fin est tout simplement incommensurable. Une augmentation significative du nombre total de courses commence en 2011, tandis que le nombre de départs en Russie augmente également. De plus, une augmentation du nombre de participants a été observée en 2009. Cela peut indiquer un intérêt accru parmi les participants, c'est-à-dire une demande accrue, après quoi l'offre a augmenté deux ans plus tard, c'est-à-dire le nombre de mises en chantier. Cependant, n'oubliez pas que les données peuvent ne pas être complètes et certaines, et peut-être de nombreuses races manquent. Y compris en raison du fait que le projet de collecte de ces données n'a commencé qu'en 2010, ce qui peut également expliquer le bond significatif du graphique en ce moment même. Y compris donc, pour une analyse plus approfondie, j'ai décidé de prendre les 10 dernières années. C'est une période assez longue,afin de suivre les tendances sur plusieurs années, bien que suffisamment court pour ne pas y arriver, principalement des compétitions professionnelles des années 90 et du début des années 2000.
On peut voir que le nombre de courses et de participants au début de la période et à la fin est tout simplement incommensurable. Une augmentation significative du nombre total de courses commence en 2011, tandis que le nombre de départs en Russie augmente également. De plus, une augmentation du nombre de participants a été observée en 2009. Cela peut indiquer un intérêt accru parmi les participants, c'est-à-dire une demande accrue, après quoi l'offre a augmenté deux ans plus tard, c'est-à-dire le nombre de mises en chantier. Cependant, n'oubliez pas que les données peuvent ne pas être complètes et certaines, et peut-être de nombreuses races manquent. Y compris en raison du fait que le projet de collecte de ces données n'a commencé qu'en 2010, ce qui peut également expliquer le bond significatif du graphique en ce moment même. Y compris donc, pour une analyse plus approfondie, j'ai décidé de prendre les 10 dernières années. C'est une période assez longue,afin de suivre les tendances sur plusieurs années, bien que suffisamment court pour ne pas y arriver, principalement des compétitions professionnelles des années 90 et du début des années 2000.rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 Soit dit en passant, 84% des courses et 94% des finisseurs ont chuté.
Soit dit en passant, 84% des courses et 94% des finisseurs ont chuté.Début amateur
Ainsi, la grande majorité des participants aux départs sélectionnés sont des athlètes amateurs, donc de bonnes statistiques peuvent être obtenues auprès d'eux. Honnêtement, cela a été d'un grand intérêt pour moi, puisque je participe moi-même à de tels départs, mais au niveau c'est très loin des champions olympiques. Cependant, des compétitions professionnelles ont évidemment eu lieu au cours de la période sélectionnée. Afin de ne pas mélanger les indicateurs pour les courses amateurs et professionnelles, il a été décidé de retirer ces dernières de la considération. Comment les identifier? Par vitesse. Nous les calculons. À l'une des premières étapes de la préparation des données, nous avons déjà déterminé quel type de distance était sur chaque course - sprint, olympique, demi, fer. Pour chacun d'eux, le kilométrage des étapes est clairement défini - natation, vélo et course à pied. C'est 0,75 + 20 + 5 pour le sprint, 1,5 + 40 + 10 pour les Olympiques, 1,9 + 90 + 21,1 pour la moitié et 3.8 + 180 + 42,2 pour le fer. Bien sûr, en fait, pour tout type, les chiffres réels peuvent varier conditionnellement d'une course à l'autre jusqu'à un pour cent, mais il n'y a aucune information à ce sujet, nous supposerons donc que tout était exact.rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
Nous calculons les vitesses moyennes et maximales pour chaque course. Le maximum ici fait référence à la vitesse moyenne de l'athlète qui a remporté la première place.for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 Eh bien, vous pouvez voir que l'essentiel des vitesses se sont regroupées en tas entre environ 15 km / h et 30 km / h, mais il existe un certain nombre de valeurs complètement «cosmiques». Trier par vitesse moyenne et voir combien d'entre eux:
Eh bien, vous pouvez voir que l'essentiel des vitesses se sont regroupées en tas entre environ 15 km / h et 30 km / h, mais il existe un certain nombre de valeurs complètement «cosmiques». Trier par vitesse moyenne et voir combien d'entre eux:rs = rs.sort_values(by='vavg')
 Ici, nous avons changé l'échelle et nous pouvons estimer la plage plus précisément. Pour des vitesses moyennes, elle est d'environ 17 km / h à 27 km / h, pour un maximum - de 18 km / h à 32 km / h. De plus, il y a des «queues» avec des vitesses moyennes très basses et très élevées. Les vitesses basses correspondent très probablement à des compétitions extrêmes telles que Norseman , et les vitesses élevées peuvent être dans le cas d'une natation annulée, où au lieu d'un sprint il y avait un super sprint, ou simplement des données erronées. Un autre point important est le pas en douceur dans la zone 1200 le long de l'axe X, et des valeurs plus élevées de la vitesse moyenne après celle-ci. Là, vous pouvez voir une différence significativement plus petite entre les vitesses moyenne et maximale que dans les deux premiers tiers du graphique. Apparemment, c'est une compétition professionnelle. Pour les distinguer plus clairement, nous calculons le rapport vitesse maximale / moyenne. Dans les compétitions professionnelles où il n'y a pas de personnes au hasard et où tous les participants ont un niveau de condition physique très élevé, ce ratio doit être minimal.
Ici, nous avons changé l'échelle et nous pouvons estimer la plage plus précisément. Pour des vitesses moyennes, elle est d'environ 17 km / h à 27 km / h, pour un maximum - de 18 km / h à 32 km / h. De plus, il y a des «queues» avec des vitesses moyennes très basses et très élevées. Les vitesses basses correspondent très probablement à des compétitions extrêmes telles que Norseman , et les vitesses élevées peuvent être dans le cas d'une natation annulée, où au lieu d'un sprint il y avait un super sprint, ou simplement des données erronées. Un autre point important est le pas en douceur dans la zone 1200 le long de l'axe X, et des valeurs plus élevées de la vitesse moyenne après celle-ci. Là, vous pouvez voir une différence significativement plus petite entre les vitesses moyenne et maximale que dans les deux premiers tiers du graphique. Apparemment, c'est une compétition professionnelle. Pour les distinguer plus clairement, nous calculons le rapport vitesse maximale / moyenne. Dans les compétitions professionnelles où il n'y a pas de personnes au hasard et où tous les participants ont un niveau de condition physique très élevé, ce ratio doit être minimal.rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 Sur ce graphique, le premier trimestre ressort très clairement: le rapport vitesse maximale / moyenne est petit, vitesse moyenne élevée, petit nombre de participants. Il s'agit d'un concours professionnel. Le pas sur la courbe verte se situe aux alentours de 1,2. Nous ne laisserons que des enregistrements avec une valeur de rapport supérieure à 1,2 dans notre échantillon.
Sur ce graphique, le premier trimestre ressort très clairement: le rapport vitesse maximale / moyenne est petit, vitesse moyenne élevée, petit nombre de participants. Il s'agit d'un concours professionnel. Le pas sur la courbe verte se situe aux alentours de 1,2. Nous ne laisserons que des enregistrements avec une valeur de rapport supérieure à 1,2 dans notre échantillon.rs = rs[rs['vmdbva'] > 1.2]
Nous supprimons également les enregistrements à des vitesses basses et élevées atypiques. Dans Quels sont les «records du monde» de triathlon pour chaque distance? publié des temps record de dépassement de distances différentes pour 2019. Si vous les comptez à des vitesses moyennes, vous pouvez voir qu'elle ne peut pas dépasser 33 km / h même pour les plus rapides. Nous allons donc considérer les protocoles où les vitesses moyennes sont plus élevées, invalides et les retirer de la considération.rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
Voici ce qui reste:
 Maintenant, tout semble assez homogène et ne soulève pas de questions. À la suite de toute cette sélection, nous avons perdu 777 des protocoles de 1922, soit 40%. Dans le même temps, le nombre total de finisseurs n'a pas diminué autant - de seulement 13%.Il reste donc 1 145 courses avec 1 231 772 arrivées. Cet échantillon est devenu le matériau de mon analyse et de ma visualisation.
Maintenant, tout semble assez homogène et ne soulève pas de questions. À la suite de toute cette sélection, nous avons perdu 777 des protocoles de 1922, soit 40%. Dans le même temps, le nombre total de finisseurs n'a pas diminué autant - de seulement 13%.Il reste donc 1 145 courses avec 1 231 772 arrivées. Cet échantillon est devenu le matériau de mon analyse et de ma visualisation.Partie 5. Analyse et visualisation
Dans ce travail, l'analyse et la visualisation proprement dites étaient les parties les plus simples. La pointe de l'iceberg, dont la partie sous-marine n'était que la préparation des données. L'analyse, en fait, était une simple opération arithmétique sur la série pandas , calculant des moyennes, filtrant - tout cela est fait par les outils élémentaires pandas et le code ci-dessus est plein d'exemples. À son tour, la visualisation a été principalement effectuée à l'aide du matplotlib le plus standard . Terrain utilisé , bar, tarte . Dans certains endroits, cependant, j'ai dû bricoler avec les signatures des axes, dans le cas des dates et des pictogrammes, mais ce n'est pas quelque chose qui appelle une description détaillée ici. La seule chose qui mérite d'être évoquée est la présentation des géodonnées. Au moins ce n'est pasmatplotlib .Géodonnées
Pour chaque course, nous avons des informations sur le lieu. Au tout début, en utilisant geopy, nous avons calculé les coordonnées de chaque emplacement. De nombreuses courses ont lieu chaque année au même endroit. Un outil très pratique pour rendre les géodonnées en python est le folium . Voici comment ça fonctionne:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
Et nous obtenons une carte interactive directement dans l'ordinateur portable Jupiter. Passons maintenant à nos données. Tout d'abord, nous allons commencer une nouvelle colonne à partir d'une combinaison de nos coordonnées:
Passons maintenant à nos données. Tout d'abord, nous allons commencer une nouvelle colonne à partir d'une combinaison de nos coordonnées:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
Les coordonnées uniques de coords sont 291. Et les emplacements uniques loc sont 324, ce qui signifie que certains noms sont légèrement différents, tout en même temps , ils correspondent au même point. Ce n'est pas effrayant, nous considérerons l'unicité par coords . Nous calculons le nombre d'événements qui se sont écoulés sur toute la durée de chaque emplacement (avec des coordonnées uniques):vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
Créez maintenant une carte et ajoutez-y des marqueurs sous forme de cercles, dont le rayon dépendra du nombre d'événements organisés sur l'emplacement. Ajoutez des marqueurs avec un nom d'emplacement aux marqueurs.m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
Terminé. Vous pouvez voir le résultat:
Progrès des participants
En fait, en plus de guider, le travail sur un autre calendrier était également non trivial. Ceci est le dernier graphique de progression des participants. Le voici: Analysons-le, en même temps je donnerai le code de rendu, comme exemple d'utilisation de matplotlib :
Analysons-le, en même temps je donnerai le code de rendu, comme exemple d'utilisation de matplotlib :fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
Maintenant, comment les données ont été calculées pour lui. Tout d'abord, vous avez dû choisir les noms des participants qui ont terminé au moins deux courses, des années civiles différentes et qui en même temps ne sont pas des professionnels.Tout d'abord, pour chaque protocole, remplissez une nouvelle colonne appelée date , qui indiquera la date de la course. Nous aurons également besoin d'un an à partir de cette date, nous ferons la colonne année . Puisque nous allons analyser la vitesse de chaque athlète par rapport à la vitesse moyenne de la course, nous calculons immédiatement cette vitesse dans la nouvelle colonne vproc - la vitesse en pourcentage de la moyenne.for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
Voici à quoi ressemblent maintenant les protocoles: Ensuite, combinez tous les protocoles en une seule trame de données.' Sprint 2019'ar = pd.concat(rd)
Pour chaque participant, nous ne laisserons qu'une seule inscription par année civile:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
Ensuite, à partir de tous les noms uniques de ces entrées, nous trouvons ceux qui se produisent au moins deux fois:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
il y en a 219 890. Supprimons les noms des pro-athlètes de cette liste:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
Ainsi que les noms des athlètes qui ont commencé à se produire avant 2010. Pour ce faire, téléchargez les données enregistrées avant l'échantillonnage au cours des 10 dernières années. Placez-les dans les objets rsa (résumé des courses tous) et rda (détails de la course tous).rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
Et enfin, nous trouvons des noms qui se produisent plus d'une fois le même jour. Ainsi, nous minimisons la présence d'homonymes complets dans notre échantillon.namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
Il reste donc 198 075 noms. Dans l'ensemble de données, nous sélectionnons uniquement les enregistrements avec les noms trouvés:ars = ar[ar['name'].isin(names)]
Maintenant, pour chaque record, vous devez déterminer à quelle année de la carrière de l'athlète il correspond - la première, la deuxième, la troisième ou la dixième. Nous faisons une boucle par tous les noms et calculons.ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
Voici un exemple de ce qui s'est passé: Apparemment, les homonymes sont toujours restés. C'est attendu, mais pas effrayant, car nous ferons la moyenne de tout, et il ne devrait pas y en avoir autant. Ensuite, nous construisons des tableaux pour le graphique:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
Voilà, il y a une base: maintenant, pour le décorer avec des points qui correspondent à des résultats spécifiques, nous allons sélectionner 1000 noms aléatoires et construire des tableaux avec les résultats pour eux.
maintenant, pour le décorer avec des points qui correspondent à des résultats spécifiques, nous allons sélectionner 1000 noms aléatoires et construire des tableaux avec les résultats pour eux.names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
Ajoutez une boucle pour créer des graphiques à partir de cet échantillon aléatoire.for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
Maintenant, tout est prêt: en général, ce n'est pas difficile. Mais il y a un problème. Pour calculer l'expérience exp dans un cycle, tous les noms, qui sont près de 200 000, prennent huit heures. J'ai dû déboguer l'algorithme sur de petits échantillons, puis exécuter le calcul pour la nuit. En principe, cela peut être fait une fois, mais si vous trouvez une sorte d'erreur ou si vous voulez changer quelque chose, et que vous devez le recompter à nouveau, cela commence à se fatiguer. Et donc, quand j'allais publier un rapport dans la soirée, il s'est avéré qu'il fallait encore tout raconter. Attendre jusqu'au matin ne faisait pas partie de mes plans, et j'ai commencé à chercher un moyen d'accélérer le calcul. Décidé de paralléliser.Trouvé quelque part un moyen de le faire avec le multitraitement. Pour travailler sous Windows, nous devions mettre la logique principale de chaque tâche parallèle dans un fichier workers.py distinct :
en général, ce n'est pas difficile. Mais il y a un problème. Pour calculer l'expérience exp dans un cycle, tous les noms, qui sont près de 200 000, prennent huit heures. J'ai dû déboguer l'algorithme sur de petits échantillons, puis exécuter le calcul pour la nuit. En principe, cela peut être fait une fois, mais si vous trouvez une sorte d'erreur ou si vous voulez changer quelque chose, et que vous devez le recompter à nouveau, cela commence à se fatiguer. Et donc, quand j'allais publier un rapport dans la soirée, il s'est avéré qu'il fallait encore tout raconter. Attendre jusqu'au matin ne faisait pas partie de mes plans, et j'ai commencé à chercher un moyen d'accélérer le calcul. Décidé de paralléliser.Trouvé quelque part un moyen de le faire avec le multitraitement. Pour travailler sous Windows, nous devions mettre la logique principale de chaque tâche parallèle dans un fichier workers.py distinct :import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
La procédure est transférée à une partie des noms de noms , la partie datafreyma ar uniquement avec ces noms et le numéro de série des tâches parallèles - num . Les calculs sont écrits dans la trame de données et, à la fin, la trame de données est écrite dans le fichier. Dans l'ordinateur portable qui appelle ce travailleur , nous préparons les arguments en conséquence:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
Nous commençons le calcul parallèle:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
Et à la fin, nous lisons les résultats des fichiers et collectons les morceaux dans l'ensemble du bloc de données:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
Ainsi, il a été possible d'obtenir une accélération de 40 fois, et au lieu de 8 heures pour terminer le calcul en 11 minutes et publier un rapport ce soir-là. En même temps, j'ai appris à paralléliser en python , je pense que cela sera utile. Ici, l'accélération s'est avérée être encore plus que 8 fois le nombre de cœurs, car chaque tâche utilisait une petite trame de données, ce qui rend la recherche plus rapide. En principe, les calculs séquentiels pourraient être accélérés de cette façon, mais la question est: comment devinez-vous?Cependant, je ne pouvais pas me calmer et même après la publication, je réfléchissais constamment à la façon de faire le calcul en utilisant la vectorisation, c'est-à-dire les opérations sur des colonnes entières du cadre de données de la série pandas. De tels calculs sont d'un ordre de grandeur plus rapides que tous les cycles parallélisés, même sur un superamas. Et est venu avec. Il s'avère que pour que chaque nom trouve l'année du début d'une carrière, il faut au contraire - pour chaque année trouver les participants qui ont commencé. Pour ce faire, vous devez d'abord déterminer tous les noms de la première année à partir de notre échantillon, c'est-à-dire 2010. Par conséquent, nous traitons tous les enregistrements portant ces noms en utilisant cette année. Ensuite, nous prenons l'année suivante - 2011.Encore une fois, nous trouvons tous les noms avec des entrées cette année, mais nous n'en prenons que des non transformés, c'est-à-dire ceux qui n'ont pas été rencontrés en 2010 et qui sont traités en les utilisant en 2011. Et ainsi de suite pour le reste de l'année. Le même cycle, mais pas deux cent mille itérations, mais neuf au total.for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
Ce cycle se réalise en quelques secondes seulement. Et le code s'est avéré beaucoup plus concis.Conclusion
Enfin, beaucoup de travail a été accompli. Pour moi, il s'agissait en fait du premier projet du genre. Quand je l'ai pris, l'objectif principal était de m'exercer à utiliser python et ses bibliothèques. Cette tâche est plus que terminée. Et les résultats eux-mêmes étaient assez présentables. Quelles conclusions ai-je tirées pour moi-même à la fin?Premièrement: les données sont imparfaites. Cela est probablement vrai pour presque toutes les tâches d'analyse. Même s'ils sont complètement structurés, et cela se produit souvent différemment, vous devez être prêt à les bricoler avant de commencer à calculer les caractéristiques et à rechercher des tendances - trouver des erreurs, des valeurs aberrantes, des écarts par rapport aux normes, etc.Deuxièmement:Toute tâche a une solution. Cela ressemble plus à un slogan, mais c'est souvent le cas. C'est juste que cette solution n'est peut-être pas si évidente et ne réside pas dans les données elles-mêmes, mais en dehors de la boîte, pour ainsi dire. À titre d'exemple - le traitement des noms des participants décrits ci-dessus, ou le raclage de sites Web.Troisièmement: la connaissance du domaine est cruciale. Cela permettra de mieux préparer les données, de supprimer les données manifestement invalides ou non standard, d'éviter les erreurs d'interprétation, d'utiliser des informations qui ne sont pas dans les données, par exemple les distances dans ce projet, de présenter les résultats sous la forme acceptée dans la communauté, tout en évitant des conclusions stupides et incorrectes.Quatrièmement: travailler en pythonIl existe un riche ensemble d'outils. Parfois, il semble que cela vaut la peine de penser à quelque chose, vous commencez à chercher - cela existe déjà. C'est tout simplement génial! Un grand merci aux créateurs pour cette contribution, en particulier pour les outils qui ont été utiles ici: sélénium pour le grattage, pycountry pour déterminer le code pays selon la norme ISO, codes pays (datahub) pour les codes olympiques, geopy pour déterminer les coordonnées à l'adresse, folium - pour la visualisation des géodonnées, le genre-devineur - pour l'analyse des noms, le multitraitement - pour le calcul parallèle, matplotlib , numpy et bien sûr les pandas - sans cela, il n'y a nulle part où aller.Cinquièmement: la vectorisation est notre tout. Il est extrêmement important de pouvoir utiliser les outils pandas intégrés , c'est très efficace. Je suppose que, dans la plupart des cas, lorsque le nombre d'enregistrements est mesuré à partir de dizaines de milliers, cette compétence devient simplement nécessaire.Sixième:La manipulation des données est une mauvaise idée. Il est nécessaire d'essayer de minimiser toute intervention manuelle - d'une part, elle n'est pas mise à l'échelle, c'est-à-dire que lorsque la quantité de données augmente plusieurs fois, le temps de traitement manuel augmentera à des valeurs inacceptables, et d'autre part, la répétabilité sera mauvaise - vous oublierez quelque chose, vous ferez une erreur quelque part . Tout est uniquement programmatique, si quelque chose sort du standard général pour une solution logicielle, eh bien, ça va, vous pouvez sacrifier une partie des données, il y aura toujours plus d'avantages.Septième:Le code doit être conservé en état de marche. Il semblerait que cela pourrait être plus évident! En fait, lorsqu'il s'agit de code pour votre propre usage, dont le but est de publier les résultats de ce code, tout n'est pas si strict ici. J'ai travaillé dans les ordinateurs portables Jupiter, et cet environnement, à mon avis, n'a tout simplement pas à créer de produits logiciels intégrés. Il est configuré pour un lancement ligne par ligne, par morceaux, cela a ses avantages - il est rapide: développement, débogage et exécution en même temps. Mais la tentation est souvent trop grande juste pour éditer une ligne et obtenir rapidement un nouveau résultat, au lieu de le dupliquer ou de l'envelopper en def. Bien sûr, une telle tentation doit être évitée. Il faut viser un bon code, même «pour soi», du moins parce que même pour un travail d'analyse, le lancement se fait plusieurs fois, et investir du temps au début sera sûrement payant à l'avenir. Et vous pouvez ajouter des tests, même sur des ordinateurs portables, sous la forme de vérifications de paramètres critiques et de levées d'exceptions - c'est très utile.Huitième: épargnez plus souvent. À chaque étape, j'ai enregistré une nouvelle version du fichier. Au total, ils se sont avérés être environ 10. C'est pratique, car lorsqu'une erreur est détectée, elle permet de déterminer rapidement à quel stade elle s'est produite. De plus, j'ai enregistré les données source dans les colonnes marquées brutes - cela vous permet de vérifier rapidement le résultat et de voir l'écart.Neuvième:Il faut mesurer l'investissement de temps et le résultat. À certains endroits, j'ai mis très longtemps à restaurer les données, qui représentent une fraction d'un pour cent du total. En fait, cela n'avait aucun sens, il fallait juste les jeter, et c'est tout. Et je le ferais si c'était un projet commercial, pas une auto-formation. Cela vous permettrait d'obtenir le résultat beaucoup plus rapidement. Le principe de Pareto fonctionne ici - 80% du résultat est atteint en 20% du temps.Et la dernière:Le travail sur de tels projets élargit considérablement les horizons. Volontiers, vous apprenez quelque chose de nouveau - par exemple, les noms de pays étranges - comme les îles Pitcairn, que le code ISO pour la Suisse est CHE, du latin "Confoederatio Helvetica", quel est le nom espagnol, eh bien, en fait, sur le triathlon lui-même - records, leurs propriétaires, lieux de courses, histoire des événements, etc.Peut-être assez. C'est tout. Merci à tous ceux qui ont lu jusqu'au bout!