L'accès au GPU depuis Java révèle une puissance énorme. Il décrit le fonctionnement du GPU et l'accès à partir de Java.La programmation GPU est un monde exorbitant pour les programmeurs Java. Cela est compréhensible car les tâches Java normales ne conviennent pas au GPU. Cependant, les GPU ont des téraflops de performances, alors explorons leurs capacités.Afin de rendre le sujet accessible, je vais passer un peu de temps à expliquer l'architecture du GPU avec un peu d'histoire qui facilitera une immersion dans la programmation de fer.Une fois que l'on m'a montré les différences entre le GPU et le CPU, je montrerai comment utiliser le GPU dans le monde Java. Enfin, je décrirai les principaux cadres et bibliothèques disponibles pour écrire du code Java et les exécuter sur le GPU, et je donnerai quelques exemples de code.Un peu d'histoire
Le GPU a été popularisé pour la première fois par NVIDIA en 1999. Il s'agit d'un processeur spécial conçu pour traiter les données graphiques avant de les transférer sur l'écran. Dans de nombreux cas, cela permet à certains calculs de décharger le processeur, libérant ainsi des ressources de processeur qui accélèrent ces calculs non chargés. Le résultat est qu'une grande entrée peut être traitée et présentée avec une résolution de sortie plus élevée, ce qui rend la présentation visuelle plus attrayante et la fréquence d'images plus fluide.L'essence du traitement 2D / 3D est principalement dans la manipulation des matrices, ceci peut être contrôlé en utilisant une approche distribuée. Quelle sera une approche efficace pour le traitement d'images? Pour répondre à cela, comparons l'architecture CPU standard (illustrée à la figure 1.) et le GPU.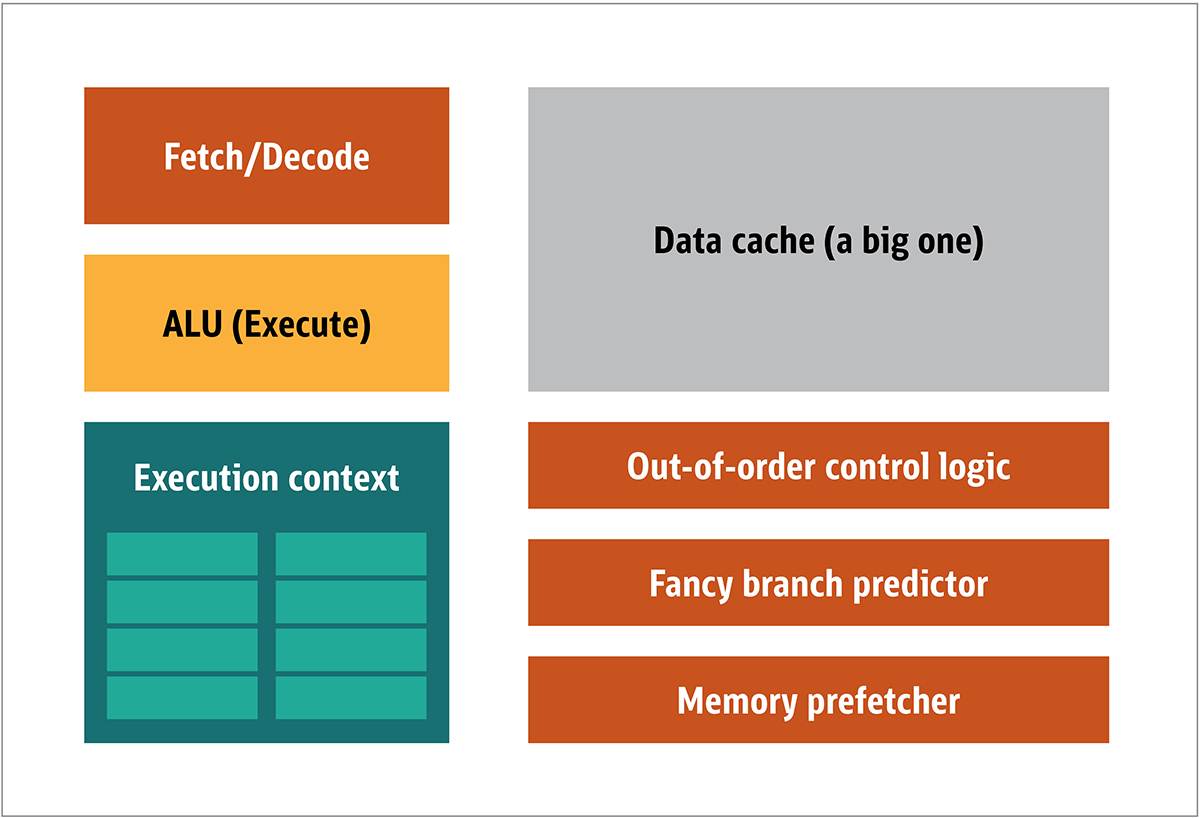 Figure. 1. Blocs d'architecturedu processeur Dans le processeur, les éléments de traitement réels - registres, unité logique arithmétique (ALU) et contextes d'exécution - ne sont que de petites parties de l'ensemble du système. Pour accélérer les paiements irréguliers dans un ordre imprévisible, il existe un cache volumineux, rapide et coûteux; divers types de collectionneurs; et les prédicteurs de branche.Vous n'avez pas besoin de tout cela sur le GPU, car les données sont reçues de manière prévisible et le GPU effectue un ensemble très limité d'opérations sur les données. Ainsi, il est possible de les rendre très petits et un processeur peu coûteux avec une architecture de bloc similaire à celle-ci est représenté sur la Fig. 2.
Figure. 1. Blocs d'architecturedu processeur Dans le processeur, les éléments de traitement réels - registres, unité logique arithmétique (ALU) et contextes d'exécution - ne sont que de petites parties de l'ensemble du système. Pour accélérer les paiements irréguliers dans un ordre imprévisible, il existe un cache volumineux, rapide et coûteux; divers types de collectionneurs; et les prédicteurs de branche.Vous n'avez pas besoin de tout cela sur le GPU, car les données sont reçues de manière prévisible et le GPU effectue un ensemble très limité d'opérations sur les données. Ainsi, il est possible de les rendre très petits et un processeur peu coûteux avec une architecture de bloc similaire à celle-ci est représenté sur la Fig. 2.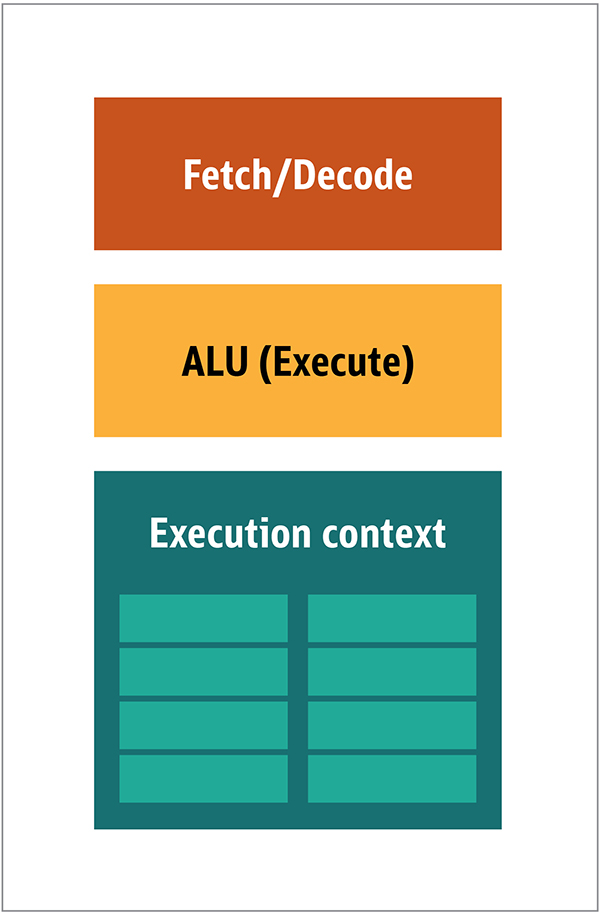 Fig. 2. Architecture de bloc pour un noyau GPU simpleÉtant donné que ces processeurs sont moins chers et que les données traitées en eux-mêmes en morceaux parallèles, il est simple de faire fonctionner plusieurs d'entre eux en parallèle. Il est conçu en référence à plusieurs instructions, plusieurs données ou MIMD (prononcé "mim-dee").La deuxième approche est basée sur le fait que souvent une seule instruction est appliquée à plusieurs éléments de données. C'est ce qu'on appelle une instruction unique, plusieurs données ou SIMD (prononcé «sim-dee»). Dans cette conception, un seul GPU contient plusieurs ALU et contextes d'exécution, de petites zones transférées vers des données de contexte partagées, comme le montre la figure 3.
Fig. 2. Architecture de bloc pour un noyau GPU simpleÉtant donné que ces processeurs sont moins chers et que les données traitées en eux-mêmes en morceaux parallèles, il est simple de faire fonctionner plusieurs d'entre eux en parallèle. Il est conçu en référence à plusieurs instructions, plusieurs données ou MIMD (prononcé "mim-dee").La deuxième approche est basée sur le fait que souvent une seule instruction est appliquée à plusieurs éléments de données. C'est ce qu'on appelle une instruction unique, plusieurs données ou SIMD (prononcé «sim-dee»). Dans cette conception, un seul GPU contient plusieurs ALU et contextes d'exécution, de petites zones transférées vers des données de contexte partagées, comme le montre la figure 3.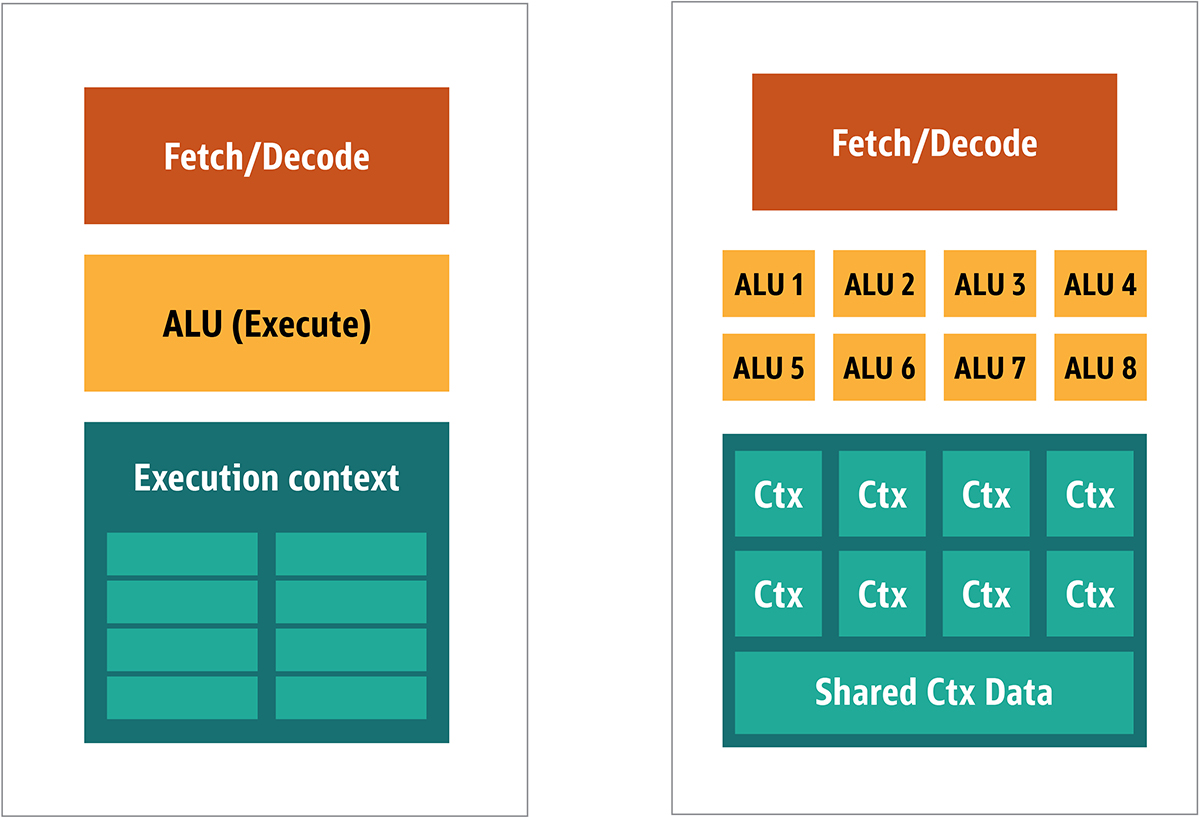 Fig. 3. Comparaison de l'architecture de style MIMD des blocs GPU (de gauche) avec la conception SIMD (de droite)Le mélange des traitements SIMD et MIMD fournit la bande passante maximale que je contournerai. Dans cette conception, vous disposez de plusieurs processeurs SIMD fonctionnant en parallèle, comme dans la figure 4.
Fig. 3. Comparaison de l'architecture de style MIMD des blocs GPU (de gauche) avec la conception SIMD (de droite)Le mélange des traitements SIMD et MIMD fournit la bande passante maximale que je contournerai. Dans cette conception, vous disposez de plusieurs processeurs SIMD fonctionnant en parallèle, comme dans la figure 4. Fig. 4. Travailler plusieurs processeurs SIMD en parallèle; il y a 16 cœurs avec 128 ALU.Comme vous avez un tas de petits processeurs simples, vous pouvez les programmer pour obtenir un effet spécial en sortie.
Fig. 4. Travailler plusieurs processeurs SIMD en parallèle; il y a 16 cœurs avec 128 ALU.Comme vous avez un tas de petits processeurs simples, vous pouvez les programmer pour obtenir un effet spécial en sortie.Exécution de programmes sur le GPU
La plupart des premiers effets graphiques dans les jeux étaient de petits programmes vraiment codés en dur s'exécutant sur le GPU et appliqués aux flux de données du CPU.Cela était évident, même lorsque les algorithmes codés en dur étaient insuffisants, en particulier dans la conception de jeux, où les effets visuels sont l'une des principales directions magiques. En réponse, les grands vendeurs ont ouvert l'accès au GPU, puis des développeurs tiers pouvaient les programmer.Une approche typique consistait à écrire un petit programme appelé shaders dans un langage spécial (généralement une sous-espèce de C) et à les compiler à l'aide de compilateurs spéciaux pour l'architecture souhaitée. Le terme shaders a été choisi parce que les shaders sont souvent utilisés pour contrôler les effets de lumière et d'ombre, mais cela ne signifie pas qu'ils peuvent contrôler d'autres effets spéciaux.Chaque fournisseur de GPU avait son propre langage de programmation et sa propre infrastructure pour créer des shaders pour leur architecture. Sur cette approche, de nombreuses plateformes ont été créées.Les principaux sont:- DirectCompute: langage / API de shader privé de Microsoft qui fait partie de Direct3D, à commencer par DirectX 10.
- AMD FireStream: technologies privées ATI / Radeon dépassées par AMD.
- OpenACC: Multi-Vendor Consortium, Parallel Computing Solution
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
La plupart du temps, travailler avec le GPU est une programmation de bas niveau. Afin de rendre cela un peu plus compréhensible pour les développeurs, pour le codage, plusieurs abstractions ont été fournies. Le plus célèbre est DirectX, de Microsoft, et OpenGL, du groupe Khronos. Ce sont des API pour écrire du code de haut niveau, qui peuvent ensuite être simplifiées pour le GPU, plus sémantiquement, pour le programmeur.Pour autant que je sache, il n'y a pas d'infrastructure Java pour DirectX, mais il existe une bonne solution pour OpenGL. JSR 231 a commencé en 2002 et s'adresse aux programmeurs GPU, mais il a été abandonné en 2008 et ne prend en charge que OpenGL 2.0.La prise en charge d'OpenGL se poursuit dans le projet JOCL indépendant (qui prend également en charge OpenCL) et est disponible pour le public. Ainsi, le célèbre jeu Minecraft a été écrit en utilisant JOCL.GPGPU à venir
Jusqu'à présent, Java et le GPU n'ont eu aucun terrain d'entente, bien qu'ils devraient l'être. Java est souvent utilisé dans les entreprises, dans la science des données et dans le secteur financier, où il y a beaucoup d'informatique et où beaucoup de puissance de calcul est nécessaire. C'est ainsi que l'idée du GPU à usage général (GPGPU) est. L'idée d'utiliser le GPU le long de ce chemin a commencé lorsque les fabricants d'adaptateurs vidéo ont commencé à donner accès au tampon de trame du programme, permettant aux développeurs de lire le contenu. Certains pirates ont déterminé qu'ils pouvaient utiliser toute la puissance du GPU pour l'informatique universelle.La recette était comme ça:- Encodez les données sous forme de tableau raster.
- Écrivez des shaders pour les gérer.
- Envoyez-les tous les deux sur la carte graphique.
- Obtenir le résultat du tampon de trame
- Décodez les données d'une matrice raster.
Ceci est une explication très simple. Je ne sais pas si cela fonctionnera en production, mais cela fonctionne vraiment.Ensuite, de nombreuses études du Stanford Institute ont commencé à simplifier l'utilisation des GPU. En 2005, ils ont créé BrookGPU, qui était un petit écosystème qui comprenait un langage de programmation, un compilateur et un runtime.BrookGPU a compilé des programmes écrits dans le langage de programmation Brook thread, qui était une variante de ANSI C.Il peut cibler OpenGL v1.3 +, DirectX v9 + ou AMD Close to Metal pour le côté serveur, et il fonctionne sur Microsoft Windows et Linux. Pour le débogage, BrookGPU peut également simuler une carte graphique virtuelle sur le CPU.Cependant, cela n'a pas décollé, en raison de l'équipement disponible à l'époque. Dans le monde GPGPU, vous devez copier des données sur l'appareil (dans ce contexte, l'appareil fait référence au GPU et à l'appareil sur lequel il se trouve), attendez que le GPU calcule les données, puis recopiez les données dans le programme de contrôle. Cela crée beaucoup de retards. Et au milieu des années 2000, lorsque le projet était en développement actif, ces retards ont également exclu l'utilisation intensive du GPU pour l'informatique de base.Cependant, de nombreuses entreprises ont vu l'avenir de cette technologie. Plusieurs développeurs d'adaptateurs vidéo ont commencé à fournir aux GPGPU leurs technologies propriétaires, et d'autres alliances formées ont fourni des modèles de programmation moins basiques et polyvalents qui fonctionnaient sur une grande quantité de matériel.Maintenant que je vous ai tout dit, examinons les deux technologies informatiques GPU les plus réussies - OpenCL et CUDA - voyez également comment Java fonctionne avec elles.OpenCL et Java
Comme les autres packages d'infrastructure, OpenCL fournit une implémentation de base en C. Elle est techniquement disponible à l'aide de Java Native Interface (JNI) ou Java Native Access (JNA), mais cette approche sera trop difficile pour la plupart des développeurs.Heureusement, ce travail a déjà été effectué par plusieurs bibliothèques: JOCL, JogAmp et JavaCL. Malheureusement, JavaCL est devenu un projet mort. Mais le projet JOCL est vivant et très adapté. Je vais l'utiliser pour les exemples suivants.Mais je dois d'abord expliquer ce qu'est OpenCL. J'ai mentionné plus tôt qu'OpenCL fournit un modèle très basique adapté à la programmation de toutes sortes de périphériques - pas seulement les GPU et les CPU, mais même les processeurs DSP et FPGA.Regardons l'exemple le plus simple: les vecteurs de pliage sont probablement l'exemple le plus brillant et le plus simple. Vous avez deux tableaux de nombres pour l'addition et un pour le résultat. Vous prenez un élément du premier tableau et un élément du deuxième tableau, puis vous mettez la somme dans le tableau des résultats, comme le montre la Fig. 5.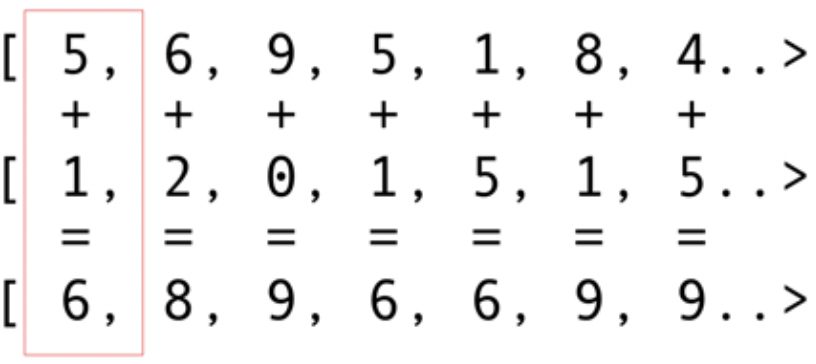 Fig. 5. Ajout des éléments de deux tableaux et stockage de la somme dans le tableau résultantComme vous pouvez le voir, l'opération est très cohérente et néanmoins distribuée. Vous pouvez pousser chaque opération d'ajout dans différents GPU principaux. Cela signifie que si vous avez 2048 cœurs, comme sur le Nvidia 1080, vous pouvez effectuer 2048 opérations d'addition en même temps. Cela signifie que les téraflops potentiels de puissance informatique vous attendent ici. Ce code pour un tableau de 10 millions de numéros est tiré du site Web de JOCL:
Fig. 5. Ajout des éléments de deux tableaux et stockage de la somme dans le tableau résultantComme vous pouvez le voir, l'opération est très cohérente et néanmoins distribuée. Vous pouvez pousser chaque opération d'ajout dans différents GPU principaux. Cela signifie que si vous avez 2048 cœurs, comme sur le Nvidia 1080, vous pouvez effectuer 2048 opérations d'addition en même temps. Cela signifie que les téraflops potentiels de puissance informatique vous attendent ici. Ce code pour un tableau de 10 millions de numéros est tiré du site Web de JOCL:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
Ce code n'est pas comme le code Java, mais il l'est. Je vais expliquer le code plus loin; n'y consacrez pas beaucoup de temps maintenant, car je parlerai brièvement de solutions complexes.Le code sera documenté, mais faisons une petite procédure pas à pas. Comme vous pouvez le voir, le code est très similaire au code en C. Ceci est normal car JOCL est juste OpenCL. Au début, voici du code dans la ligne, et ce code est la partie la plus importante: il est compilé en utilisant OpenCL puis envoyé à la carte vidéo, où il est exécuté. Ce code est appelé noyau. Ne confondez pas ce terme avec OC Kernel; Ceci est le code de l'appareil. Ce code est écrit dans un sous-ensemble de C.Après le noyau vient le code Java pour installer et configurer le périphérique, diviser les données et créer les tampons de mémoire appropriés pour les données résultantes.Pour résumer: voici le «code hôte», qui est généralement une liaison de langage (dans notre cas, en Java), et le «code périphérique». Vous mettez toujours en évidence ce qui fonctionnera sur l'hôte et ce qui devrait fonctionner sur l'appareil, car l'hôte contrôle l'appareil.Le code précédent doit montrer l'équivalent GPU de "Hello World!" Comme vous pouvez le voir, la majeure partie est énorme.N'oublions pas les fonctionnalités SIMD. Si votre appareil prend en charge l'extension SIMD, vous pouvez accélérer le code arithmétique. Pour un exemple, regardons le code de multiplication de la matrice du noyau. Ce code est dans une simple ligne Java dans l'application.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Techniquement, ce code fonctionnera sur des éléments de données qui ont été installés pour vous par le framework OpenCL, avec les instructions que vous avez appelées dans la partie préparatoire.Si votre carte vidéo prend en charge les instructions SIMD et peut traiter un vecteur de quatre nombres à virgule flottante, de petites optimisations peuvent transformer le code précédent en ce qui suit:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
Avec ce code, vous pouvez doubler les performances.Cool. Vous venez d'ouvrir le GPU pour le monde Java! Mais en tant que développeur Java, voulez-vous vraiment faire tout ce sale boulot, avec du code C, et travailler avec des détails de si bas niveau? Je ne veux pas. Mais maintenant que vous avez une certaine connaissance de l'utilisation du GPU, examinons une autre solution différente du code JOCL que je viens de présenter.CUDA et Java
CUDA est la solution de Nvidia à ce problème de programmation. CUDA fournit de nombreuses autres bibliothèques prêtes à l'emploi pour les opérations GPU standard, telles que les matrices, les histogrammes et même les réseaux de neurones profonds. Une liste de bibliothèques est déjà apparue avec un tas de solutions toutes faites. Tout cela provient du projet JCuda:- JCublas: tout pour les matrices
- JCufft: Transformation de Fourier rapide
- JCurand: Tout pour les nombres aléatoires
- JCusparse: matrices rares
- JCusolver: factorisation des nombres
- JNvgraph: tout pour les graphiques
- JCudpp: bibliothèque CUDA de données parallèles primitives et quelques algorithmes de tri
- JNpp: traitement d'image GPU
- JCudnn: bibliothèque de réseaux de neurones profonds
J'envisage d'utiliser JCurand, qui génère des nombres aléatoires. Vous pouvez l'utiliser à partir du code Java sans autre langage spécial du noyau. Par exemple:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
Il utilise un GPU pour créer un grand nombre de nombres aléatoires de très haute qualité, basés sur des mathématiques très solides.Dans JCuda, vous pouvez également écrire du code CUDA générique et l'appeler à partir de Java en appelant un fichier JAR dans votre chemin de classe. Voir la documentation JCuda pour de bons exemples.Restez au-dessus du code de bas niveau
Tout a l'air génial, mais il y a trop de code, trop d'installation, trop de langages différents pour tout exécuter. Existe-t-il un moyen d'utiliser le GPU au moins partiellement?Et si vous ne voulez pas penser à tout cela OpenCL, CUDA et à d'autres choses inutiles? Et si vous voulez seulement programmer en Java et ne pas penser à tout ce qui n'est pas évident? Le projet Aparapi peut vous aider. Aparapi est basé sur une «API parallèle». Je pense que c'est une partie d'Hibernate pour la programmation GPU qui utilise OpenCL sous le capot. Jetons un coup d'œil à un exemple d'addition vectorielle.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Voici du code Java pur (extrait de la documentation d'Aparapi), ici et là aussi, vous pouvez voir un certain terme Kernel et getGlobalId. Vous devez toujours comprendre comment programmer le GPU, mais vous pouvez utiliser l'approche GPGPU d'une manière plus similaire à Java. De plus, Aparapi fournit un moyen facile d'utiliser le contexte OpenGL à la couche OpenCL - permettant ainsi aux données de rester complètement sur la carte graphique - et ainsi d'éviter les problèmes de latence de la mémoire.Si vous avez besoin de faire beaucoup de calculs indépendants, regardez Aparapi. Il existe de nombreux exemples d'utilisation du calcul parallèle.De plus, il existe un projet appelé TornadoVM - il transfère automatiquement les calculs appropriés du CPU au GPU, offrant ainsi une optimisation de masse prête à l'emploi.résultats
Il existe de nombreuses applications où les GPU peuvent apporter certains avantages, mais on pourrait dire qu'il y a encore des obstacles. Cependant, Java et le GPU peuvent faire de grandes choses ensemble. Dans cet article, je n'ai abordé que ce vaste sujet. J'avais l'intention de montrer diverses options de haut et de bas niveau pour accéder au GPU à partir de Java. L'exploration de ce domaine offrira d'énormes avantages en termes de performances, en particulier pour les tâches complexes qui nécessitent plusieurs calculs pouvant être effectués en parallèle.Lien source