Je vais vous expliquer tout de suite le titre de l'article. Initialement, il était prévu de donner de bons conseils fiables sur l'accélération de l'utilisation de la réflexion en utilisant un exemple simple mais réaliste, mais lors de l'analyse comparative, il s'est avéré que la réflexion ne fonctionne pas aussi lentement que je le pensais, LINQ fonctionne plus lentement que ce dont on rêvait dans les cauchemars. Mais au final, il s'est avéré que j'ai également fait une erreur dans les mesures ... Détails de cette histoire de vie sous la coupe et dans les commentaires. Étant donné que l'exemple est tout à fait quotidien et mis en œuvre en principe, comme c'est généralement le cas dans l'entreprise, il s'est avéré être assez intéressant, comme il me semble, une démonstration de la vie: il n'y avait aucun effet notable sur la vitesse du sujet principal de l'article en raison de la logique externe: Moq, Autofac, EF Core, etc. "Cerclage".J'ai commencé mon travail sous l'impression de cet article: Pourquoi la réflexion est lenteComme vous pouvez le voir, l'auteur suggère d'utiliser des délégués compilés au lieu d'invoquer directement des méthodes de type réflexion comme un excellent moyen d'accélérer considérablement l'application. Il y a, bien sûr, une émission d'IL, mais je voudrais l'éviter, car c'est la façon la plus laborieuse de terminer la tâche, qui est lourde d'erreurs.Étant donné que j'ai toujours adhéré à une opinion similaire sur la vitesse de réflexion, je n'avais pas l'intention de jeter un doute particulier sur les conclusions de l'auteur.Je rencontre souvent l'usage naïf de la réflexion dans une entreprise. Le type est pris. Les informations de propriété sont prises. La méthode SetValue est appelée et tout le monde est content. La valeur a volé dans le champ cible, tout le monde est content. Les gens qui sont très intelligents - les sinistres et les chefs d'équipe - écrivent leurs extensions sur l'objet, en se basant sur une implémentation aussi naïve de mappeurs "universels" d'un type dans un autre. L'essence de ceci est généralement: nous prenons tous les champs, nous prenons toutes les propriétés, itérons sur eux: si les noms des membres de type coïncident, nous exécutons SetValue. Nous interceptons périodiquement des exceptions sur les échecs où l'un des types n'a pas trouvé de propriété, mais il existe également une issue qui permet d'obtenir des performances. Essayez / attrapez.J'ai vu des gens réinventer des analyseurs et des cartographes sans être pleinement armés d'informations sur la façon dont les vélos ont été inventés avant de fonctionner. J'ai vu des gens cacher leurs implémentations naïves derrière des stratégies, derrière des interfaces, derrière des injections, comme si cela excusait les bacchanales suivantes. De telles implémentations, j'ai tourné le nez. En fait, je n'ai pas mesuré la fuite réelle de performances, et si possible, j'ai simplement changé la mise en œuvre pour une mise en œuvre plus «optimale», si mes mains se touchaient. Parce que les premières mesures, qui sont discutées ci-dessous, j'ai été sérieusement gênée.Je pense que beaucoup d'entre vous, lors de la lecture de Richter ou d'autres idéologues, ont émis l'affirmation assez juste que la réflexion dans le code est un phénomène qui a un effet très négatif sur les performances des applications.L'appel à réflexion oblige le CLR à faire le tour de l'assemblée à la recherche de la bonne, à remonter ses métadonnées, à les analyser, etc. De plus, la réflexion lors de la traversée de séquence conduit à l'allocation d'une grande quantité de mémoire. On passe la mémoire, le CLR découvre le HZ et se fige en course. Cela devrait être sensiblement lent, croyez-moi. Les énormes quantités de mémoire des serveurs de production modernes ou des machines cloud n'économisent pas les délais de traitement élevés. En fait, plus il y a de mémoire, plus il y a de chances que vous NOUS INDIQUEREZ comment fonctionne le HZ. La réflexion est, en théorie, un chiffon rouge supplémentaire pour lui.Néanmoins, nous utilisons tous à la fois des conteneurs IoC et des mappeurs de dates, dont le principe est également basé sur la réflexion, cependant, des questions sur leurs performances ne se posent généralement pas. Non, pas parce que l'introduction de dépendances et l'abstraction de modèles de contexte limité externe sont des choses tellement nécessaires que nous devons en tout cas sacrifier les performances. Tout est plus simple - cela n'affecte vraiment pas considérablement les performances.Le fait est que les cadres les plus courants basés sur la technologie de la réflexion utilisent toutes sortes de trucs pour travailler de manière plus optimale. Il s'agit généralement d'un cache. Il s'agit généralement d'expressions et de délégués compilés à partir de l'arborescence d'expressions. Le même mappeur automatique conserve un dictionnaire compétitif en dessous, comparant les types avec des fonctions qu'ils peuvent se convertir les uns aux autres sans appeler la réflexion.Comment y parvient-on? En fait, cela n'est pas différent de la logique que la plateforme elle-même utilise pour générer du code JIT. Lorsque vous appelez une méthode pour la première fois, elle se compile (et, oui, ce processus n'est pas rapide), avec les appels suivants, le contrôle est transféré vers la méthode déjà compilée et il n'y aura pas de baisses de performances spéciales.Dans notre cas, vous pouvez également utiliser la compilation JIT, puis utiliser le comportement compilé avec les mêmes performances que ses homologues AOT. Dans ce cas, des expressions nous seront utiles.Brièvement, nous pouvons formuler le principe en question comme suit: Lerésultat final de la réflexion doit être mis en cache sous la forme d'un délégué contenant une fonction compilée. Il est également judicieux de mettre en cache tous les objets nécessaires avec des informations sur les types dans les champs de votre type qui sont stockés en dehors des objets - le travailleur.Il y a de la logique là-dedans. Le bon sens nous dit que si quelque chose peut être compilé et mis en cache, alors cela devrait être fait.À l'avenir, il faut dire que le cache dans le travail avec la réflexion a ses avantages, même si vous n'utilisez pas la méthode proposée pour compiler des expressions. En fait, je ne fais que répéter ici les thèses de l'auteur de l'article auquel je fais référence plus haut.Maintenant sur le code. Regardons un exemple qui est basé sur ma douleur récente que j'ai dû affronter dans la production sérieuse d'une organisation de crédit sérieuse. Toutes les entités sont fictives pour que personne ne devine.Il y a une certaine entité. Que ce soit Contact. Il existe des lettres avec un corps normalisé, à partir desquelles l'analyseur et l'hydrateur créent ces mêmes contacts. Une lettre est arrivée, nous l'avons lue, démonté les paires clé-valeur, créé un contact, enregistré dans la base de données.C'est élémentaire. Supposons qu'un contact ait le nom, l'âge et le numéro de contact de la propriété. Ces données sont transmises dans une lettre. En outre, l'entreprise souhaite que le support puisse ajouter rapidement de nouvelles clés pour mapper les propriétés des entités aux paires dans le corps de la lettre. Dans le cas où quelqu'un a imprimé dans le modèle ou si avant la publication, il serait nécessaire de commencer de toute urgence la cartographie à partir d'un nouveau partenaire, en l'adaptant au nouveau format. Ensuite, nous pouvons ajouter une nouvelle corrélation de mappage en tant que correctif de données bon marché. Autrement dit, un exemple de vie.Nous implémentons, créons des tests. Travaux.Je ne donnerai pas le code: il y avait beaucoup de sources, et elles sont disponibles sur GitHub par le lien à la fin de l'article. Vous pouvez les télécharger, les torturer au-delà de toute reconnaissance et les mesurer, car cela affecterait votre cas. Je ne donnerai que le code de deux méthodes modèles qui distinguent l'hydrateur, qui aurait dû être rapide de l'hydrateur, qui aurait dû être lent.La logique est la suivante: la méthode modèle reçoit les paires formées par la logique de l'analyseur de base. Le niveau LINQ est un analyseur et la logique de base de l'hydrateur, faisant une demande au contexte db et faisant correspondre les clés avec des paires de l'analyseur (pour ces fonctions, il existe un code sans LINQ pour comparaison). Ensuite, les paires sont transférées vers la méthode d'hydratation principale et les valeurs des paires sont définies sur les propriétés correspondantes de l'entité.«Fast» (préfixe rapide dans les benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Comme nous pouvons le voir, une collection statique avec des setters de propriétés est utilisée - des lambdas compilés qui appellent l'entité setter. Généré par le code suivant: static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
En général, c'est clair. Nous parcourons les propriétés, créons des délégués pour ceux qui appellent les setters et les enregistrons. Ensuite, nous appelons si nécessaire."Slow" (préfixe lent dans les repères): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Ici, nous parcourons immédiatement les propriétés et appelons directement SetValue.Pour plus de clarté et comme référence, j'ai implémenté une méthode naïve qui écrit les valeurs de leurs paires de corrélation directement dans les champs d'entité. Le préfixe est Manual.Maintenant, nous prenons BenchmarkDotNet et nous étudions la productivité. Et du coup ... (le spoiler n'est pas le bon résultat, les détails sont ci-dessous)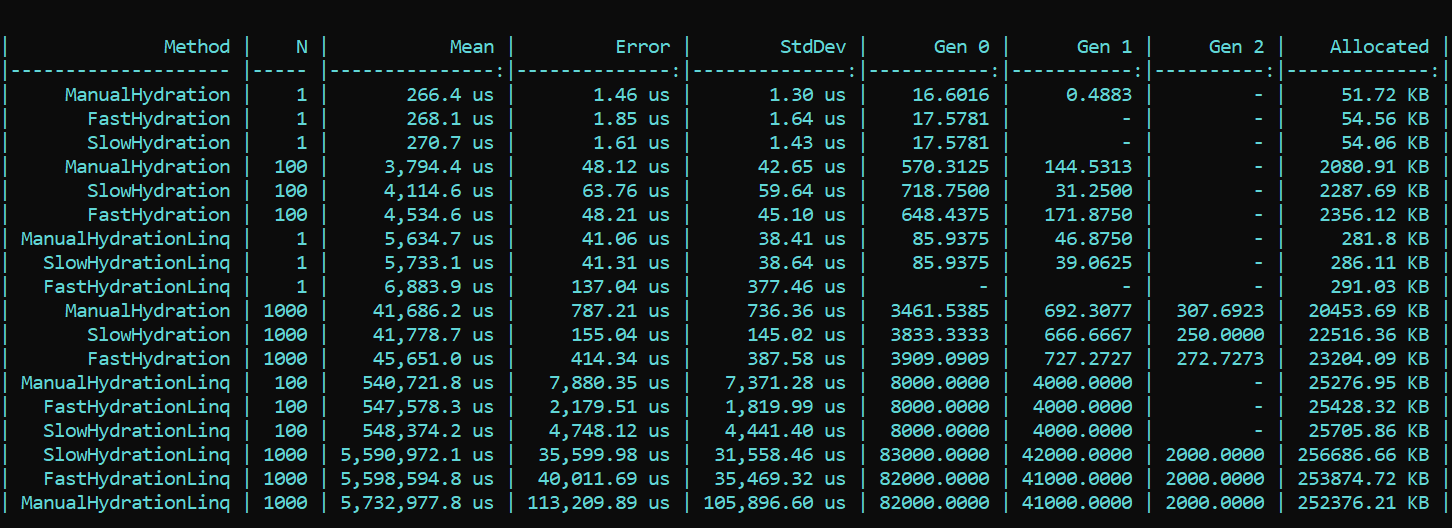 Que voyons-nous ici? Les méthodes qui portent triomphalement le préfixe rapide se révèlent plus lentes dans presque toutes les passes que les méthodes avec le préfixe lent. Cela est vrai pour l'allocation et pour la vitesse. D'un autre côté, l'implémentation belle et élégante de la cartographie utilisant des méthodes LINQ conçues à cet effet, au contraire, gruge considérablement les performances. La différence de commandes. La tendance ne change pas avec un nombre de passes différent. La différence n'est que dans l'échelle. Avec LINQ 4 à 200 fois plus lent, il y a plus de débris à peu près à la même échelle.MIS À JOURJe n'en croyais pas mes yeux, mais plus important encore, ni mes yeux ni mon code n'ont été crus par notre collègue - Dmitry Tikhonov 0x1000000. Après avoir revérifié ma solution, il a brillamment découvert et signalé une erreur que j'ai manquée en raison d'un certain nombre de changements dans la mise en œuvre. Après avoir corrigé le bogue trouvé dans la configuration de Moq, tous les résultats se sont mis en place. Selon les résultats du nouveau test, la tendance principale ne change pas - LINQ affecte la performance est encore plus forte que la réflexion. Cependant, il est agréable de ne pas travailler en vain avec la compilation d'expressions, et le résultat est visible à la fois dans l'allocation et dans l'exécution. La première exécution, lorsque les champs statiques sont initialisés, est naturellement plus lente dans la méthode «rapide», mais la situation change encore.Voici le résultat du nouveau test:
Que voyons-nous ici? Les méthodes qui portent triomphalement le préfixe rapide se révèlent plus lentes dans presque toutes les passes que les méthodes avec le préfixe lent. Cela est vrai pour l'allocation et pour la vitesse. D'un autre côté, l'implémentation belle et élégante de la cartographie utilisant des méthodes LINQ conçues à cet effet, au contraire, gruge considérablement les performances. La différence de commandes. La tendance ne change pas avec un nombre de passes différent. La différence n'est que dans l'échelle. Avec LINQ 4 à 200 fois plus lent, il y a plus de débris à peu près à la même échelle.MIS À JOURJe n'en croyais pas mes yeux, mais plus important encore, ni mes yeux ni mon code n'ont été crus par notre collègue - Dmitry Tikhonov 0x1000000. Après avoir revérifié ma solution, il a brillamment découvert et signalé une erreur que j'ai manquée en raison d'un certain nombre de changements dans la mise en œuvre. Après avoir corrigé le bogue trouvé dans la configuration de Moq, tous les résultats se sont mis en place. Selon les résultats du nouveau test, la tendance principale ne change pas - LINQ affecte la performance est encore plus forte que la réflexion. Cependant, il est agréable de ne pas travailler en vain avec la compilation d'expressions, et le résultat est visible à la fois dans l'allocation et dans l'exécution. La première exécution, lorsque les champs statiques sont initialisés, est naturellement plus lente dans la méthode «rapide», mais la situation change encore.Voici le résultat du nouveau test: Conclusion: lors de l'utilisation de la réflexion dans une entreprise, le recours à des astuces n'est pas particulièrement nécessaire - LINQ engloutira plus fortement les performances. Cependant, dans les méthodes très chargées nécessitant une optimisation, on peut conserver la réflexion sous la forme d'initialiseurs et de compilateurs délégués, qui fourniront alors une logique «rapide». Vous pouvez ainsi conserver la flexibilité de la réflexion et la rapidité de l'application.Un code avec un benchmark est disponible ici. Tout le monde peut revérifier mes mots:HabraReflectionTestsPS: le code utilise IoC dans les tests, et la conception explicite dans les benchmarks. Le fait est que dans l'implémentation finale, je cloisonne tous les facteurs qui peuvent affecter les performances et faire du bruit.PPS: Merci à Dmitry Tikhonov @ 0x1000000pour détecter mon erreur dans la configuration Moq, qui a affecté les premières mesures. Si l'un des lecteurs a suffisamment de karma, aimez-le, s'il vous plaît. L'homme s'est arrêté, l'homme a lu, l'homme a revérifié et a indiqué une erreur. Je pense que cela mérite le respect et la sympathie.PPPS: merci à ce lecteur méticuleux qui est allé au fond du style et du design. Je suis pour l'uniformité et la commodité. La diplomatie de la présentation laisse beaucoup à désirer, mais j'ai pris en compte les critiques. Je demande la coquille.
Conclusion: lors de l'utilisation de la réflexion dans une entreprise, le recours à des astuces n'est pas particulièrement nécessaire - LINQ engloutira plus fortement les performances. Cependant, dans les méthodes très chargées nécessitant une optimisation, on peut conserver la réflexion sous la forme d'initialiseurs et de compilateurs délégués, qui fourniront alors une logique «rapide». Vous pouvez ainsi conserver la flexibilité de la réflexion et la rapidité de l'application.Un code avec un benchmark est disponible ici. Tout le monde peut revérifier mes mots:HabraReflectionTestsPS: le code utilise IoC dans les tests, et la conception explicite dans les benchmarks. Le fait est que dans l'implémentation finale, je cloisonne tous les facteurs qui peuvent affecter les performances et faire du bruit.PPS: Merci à Dmitry Tikhonov @ 0x1000000pour détecter mon erreur dans la configuration Moq, qui a affecté les premières mesures. Si l'un des lecteurs a suffisamment de karma, aimez-le, s'il vous plaît. L'homme s'est arrêté, l'homme a lu, l'homme a revérifié et a indiqué une erreur. Je pense que cela mérite le respect et la sympathie.PPPS: merci à ce lecteur méticuleux qui est allé au fond du style et du design. Je suis pour l'uniformité et la commodité. La diplomatie de la présentation laisse beaucoup à désirer, mais j'ai pris en compte les critiques. Je demande la coquille.