Bonjour, je m'appelle Alexander Vasin, je suis développeur backend à Edadil. L'idée de ce matériel a commencé avec le fait que je voulais analyser le travail d'introduction ( Ya.Disk ) dans l'école de développement Yandex Backend . J'ai commencé à décrire toutes les subtilités du choix de certaines technologies, la méthodologie de test ... Il s'est avéré ne pas être du tout une analyse, mais un guide très détaillé sur la façon d'écrire des backends en Python. De l'idée initiale, il n'y avait que des exigences pour le service, sur l'exemple duquel il est pratique de démonter les outils et les technologies. En conséquence, je me suis réveillé sur cent mille caractères. Il fallait tellement de choses pour tout examiner en détail. Ainsi, le programme pour les 100 prochains kilo-octets: comment construire un backend de service, du choix des outils au déploiement. TL; DR: Voici un représentant GitHub avec application, et qui aime les (vrais) longs livres - s'il vous plaît, sous cat.Nous allons développer et tester le service API REST en Python, le placer dans un conteneur Docker léger et le déployer à l'aide d'Ansible.
TL; DR: Voici un représentant GitHub avec application, et qui aime les (vrais) longs livres - s'il vous plaît, sous cat.Nous allons développer et tester le service API REST en Python, le placer dans un conteneur Docker léger et le déployer à l'aide d'Ansible.Vous pouvez implémenter le service API REST de différentes manières à l'aide de différents outils. La solution décrite n'est pas la seule bonne, j'ai choisi la mise en œuvre et les outils en fonction de mon expérience et de mes préférences personnelles.
Qu'est-ce qu'on fait?
Imaginez qu'une boutique de cadeaux en ligne prévoit de lancer une action dans différentes régions. Pour qu'une stratégie de vente soit efficace, une analyse de marché est nécessaire. Le magasin a un fournisseur qui envoie régulièrement (par exemple, par courrier) le déchargement des données avec des informations sur les résidents.Développons un service d'API REST Python qui analysera les données fournies et identifiera la demande de cadeaux de résidents de différents groupes d'âge dans différentes villes par mois.Nous implémentons les gestionnaires suivants dans le service:POST /imports
Ajoute un nouveau téléchargement avec des données;
GET /imports/$import_id/citizens
Renvoie les résidents de la sortie spécifiée;
PATCH /imports/$import_id/citizens/$citizen_id
Modifie les informations sur le résident (et ses proches) dans le déchargement spécifié;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
Nous écrivons donc un service en Python en utilisant des frameworks, des bibliothèques et des SGBD familiers.Dans 4 conférences du cours vidéo, divers SGBD et leurs fonctionnalités sont décrits. Pour ma mise en œuvre, j'ai choisi le SGBD PostgreSQL , qui s'est imposé comme une solution fiable avec une excellente documentation en russe , une forte communauté russe (vous pouvez toujours trouver la réponse à une question en russe), et même des cours gratuits . Le modèle relationnel est assez polyvalent et bien compris par de nombreux développeurs. Bien que la même chose puisse être faite sur n'importe quel SGBD NoSQL, dans cet article, nous considérerons PostgreSQL.L'objectif principal du service - la transmission de données sur le réseau entre la base de données et les clients - n'implique pas une charge importante sur le processeur, mais nécessite la capacité de traiter plusieurs demandes à la fois. Dans 10 conférences considérées comme une approche asynchrone. Il vous permet de servir efficacement plusieurs clients dans le même processus de système d'exploitation (contrairement, par exemple, au modèle de pré-fork utilisé dans Flask / Django, qui crée plusieurs processus pour traiter les demandes des utilisateurs, chacun consomme de la mémoire, mais est inactif la plupart du temps ) Par conséquent, en tant que bibliothèque pour l'écriture du service, j'ai choisi l' aiohttp asynchrone . La 5e conférence du cours vidéo raconte que SQLAlchemy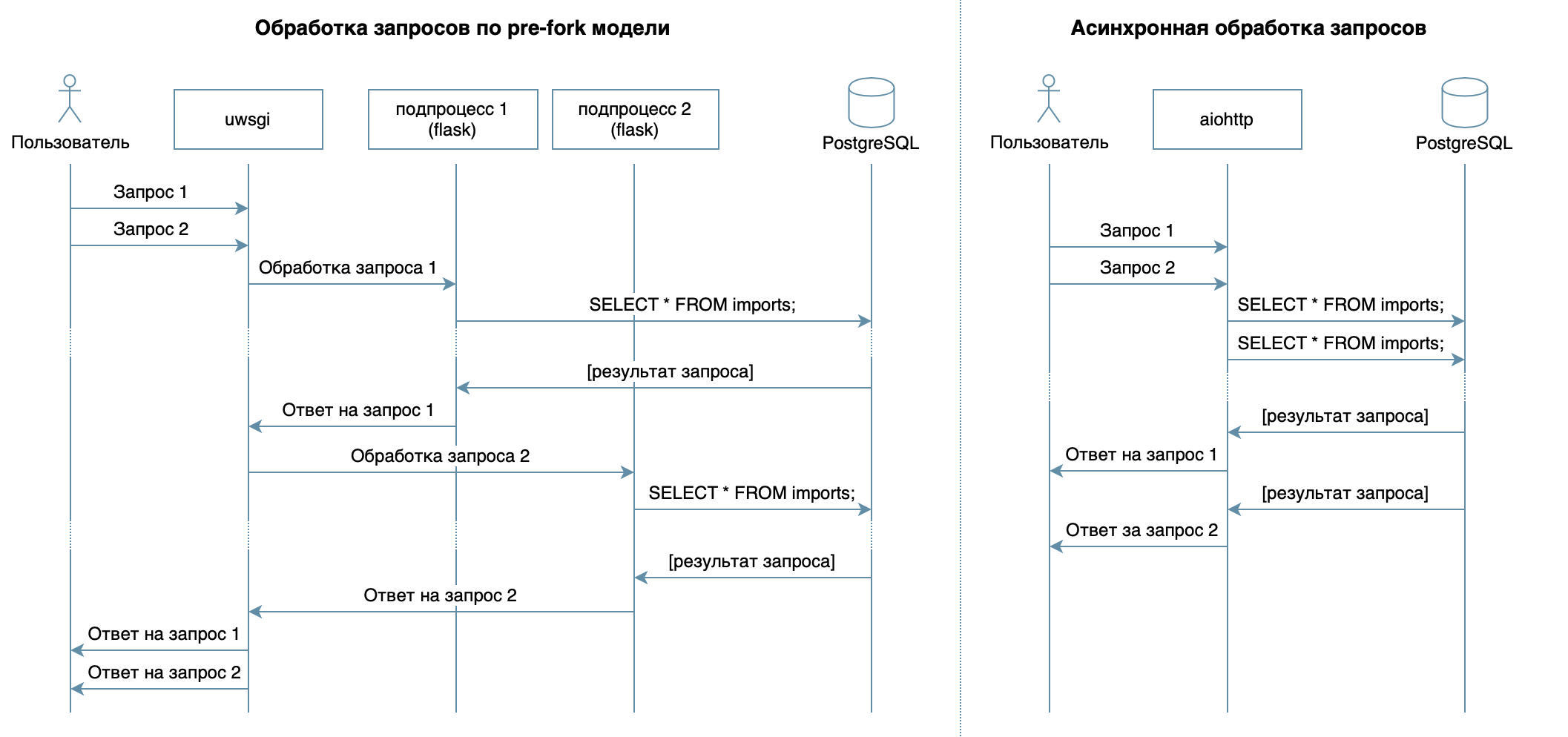 vous permet de décomposer des requêtes complexes en parties, de les réutiliser, de générer des requêtes avec un ensemble dynamique de champs (par exemple, le processeur PATCH permet la mise à jour partielle d'un résident avec des champs arbitraires) et de se concentrer directement sur la logique métier. Le pilote asyncpg peut gérer ces demandes et transférer les données le plus rapidement possible , et asyncpgsa les aidera à se faire des amis .Mon outil préféré pour gérer l'état de la base de données et travailler avec les migrations est Alembic . Au fait, j'en ai récemment parlé à Moscou Python .La logique de validation a été succinctement décrite par les programmes de guimauve (y compris les vérifications des liens familiaux). Utilisation du module aiohttp-specJ'ai lié des gestionnaires et des schémas aiohttp pour la validation des données, et le bonus était de générer de la documentation au format Swagger et de l'afficher dans une interface graphique .Pour les tests d'écriture, j'ai choisi
vous permet de décomposer des requêtes complexes en parties, de les réutiliser, de générer des requêtes avec un ensemble dynamique de champs (par exemple, le processeur PATCH permet la mise à jour partielle d'un résident avec des champs arbitraires) et de se concentrer directement sur la logique métier. Le pilote asyncpg peut gérer ces demandes et transférer les données le plus rapidement possible , et asyncpgsa les aidera à se faire des amis .Mon outil préféré pour gérer l'état de la base de données et travailler avec les migrations est Alembic . Au fait, j'en ai récemment parlé à Moscou Python .La logique de validation a été succinctement décrite par les programmes de guimauve (y compris les vérifications des liens familiaux). Utilisation du module aiohttp-specJ'ai lié des gestionnaires et des schémas aiohttp pour la validation des données, et le bonus était de générer de la documentation au format Swagger et de l'afficher dans une interface graphique .Pour les tests d'écriture, j'ai choisi pytest, plus à ce sujet en 3 conférences .Pour déboguer et profiler ce projet, j'ai utilisé le débogueur PyCharm ( cours 9 ).Dans 7, la conférence décrit comment n'importe quel ordinateur Docker (ou même sur un système d'exploitation différent) peut fonctionner en mode pack sans avoir à ajuster l'environnement d'application pour démarrer et facile à installer / mettre à jour / supprimer l'application sur le serveur.Pour le déploiement, j'ai choisi Ansible. Il vous permet de décrire de manière déclarative l'état souhaité du serveur et de ses services, fonctionne via ssh et ne nécessite pas de logiciel spécial.Développement
J'ai décidé de donner un nom au package Python analyzeret d'utiliser la structure suivante: Dans le fichier,
Dans le fichier, analyzer/__init__.pyj'ai posté des informations générales sur le package: description ( docstring ), version, licence, contacts développeur.Il peut être consulté avec l'aide intégrée$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
Le package a deux points d'entrée - le service API REST ( analyzer/api/__main__.py) et l'utilitaire de gestion d'état de la base de données ( analyzer/db/__main__.py). Les fichiers sont appelés __main__.pypour une raison - tout d'abord, un tel nom attire l'attention, il indique clairement que le fichier est un point d'entrée.Deuxièmement, grâce à cette approche des points d'entrée python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
Pourquoi avez-vous besoin de commencer avec setup.py?
À l'avenir, nous réfléchirons à la façon de distribuer l'application: elle peut être emballée dans une archive zip (ainsi que wheel / egg-), un package rpm, un fichier pkg pour macOS et installé sur un ordinateur distant, une machine virtuelle, MacBook ou Docker- récipient.L'objectif principal du fichier setup.pyest de décrire le package avec l'application pour . Le fichier doit contenir des informations générales sur le package (nom, version, auteur, etc.), mais vous pouvez également y spécifier les modules requis pour le travail, les dépendances «supplémentaires» (par exemple, pour les tests), les points d'entrée (par exemple, les commandes exécutables ) et les exigences de l'interprète. Les plugins Setuptools vous permettent de collecter des artefacts à partir du package décrit. Il existe des plugins intégrés: zip, egg, rpm, paquet macOS. Les plugins restants sont distribués via PyPI: wheel ,distutils/setuptoolsxar , pex .En fin de compte, en décrivant un fichier, nous obtenons de grandes opportunités. C'est pourquoi le développement d'un nouveau projet doit commencer setup.py.Dans la fonction, setup()les modules dépendants sont indiqués par une liste:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Mais j'ai décrit les dépendances dans des fichiers séparés requirements.txtet requirements.dev.txtdont le contenu est utilisé dans setup.py. Il me semble plus flexible, en plus il y a un secret: plus tard, il vous permettra de construire une image Docker plus rapidement. Les dépendances seront définies en tant qu'étape distincte avant d'installer l'application elle-même et lors de la reconstruction du conteneur Docker, il se trouve dans le cache.Pour setup.pypouvoir lire les dépendances des fichiers requirements.txtet requirements.dev.txt, la fonction s'écrit:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
Il est intéressant de noter que setuptoolslorsque la distribution des sources d'assemblage par défaut inclut uniquement les fichiers d'assemblage .py, .c, .cppet .h. Pour un fichier de dépendance requirements.txtet requirements.dev.txtfrapper le sac, ils doivent être clairement spécifiés dans le fichier MANIFEST.in.setup.py entièrementimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Vous pouvez installer le projet en mode développement à l'aide de la commande suivante (en mode éditable, Python n'installera pas le package entier dans un dossier site-packages, mais créera uniquement des liens, donc toutes les modifications apportées aux fichiers du package seront immédiatement visibles):
pip install -e '.[dev]'
pip install -e .
Comment spécifier des versions de dépendances?
C'est formidable lorsque les développeurs travaillent activement sur leurs packages - les bogues y sont activement corrigés, de nouvelles fonctionnalités apparaissent et les commentaires peuvent être obtenus plus rapidement. Mais parfois, les changements dans les bibliothèques dépendantes ne sont pas rétrocompatibles et peuvent entraîner des erreurs dans votre application si vous n'y pensez pas au préalable.Par exemple, pour chaque package dépendant, vous pouvez spécifier une version spécifique aiohttp==3.6.2. Ensuite, l'application sera garantie d'être construite spécifiquement avec les versions des bibliothèques dépendantes avec lesquelles elle a été testée. Mais cette approche a un inconvénient - si les développeurs corrigent un bogue critique dans un package dépendant qui n'affecte pas la compatibilité descendante, ce correctif n'entrera pas dans l'application.Il existe une approche pour le contrôle de version Version sémantique, ce qui suggère de soumettre la version au format MAJOR.MINOR.PATCH:MAJOR - augmente lorsque des modifications incompatibles vers l'arrière sont ajoutées;MINOR - Augmente lors de l'ajout de nouvelles fonctionnalités avec prise en charge de la compatibilité descendante;PATCH - augmente lors de l'ajout de corrections de bogues avec prise en charge de la compatibilité descendante.
Si un paquet dépendant suit cette approche (dont les auteurs sont généralement signalés dans les fichiers README et Changelog), il suffit de fixer la valeur de MAJOR, MINORet de limiter la valeur minimale pour PATCH version: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.Une telle exigence peut être implémentée à l'aide de l'opérateur ~ = . Par exemple, cela aiohttp~=3.6.2permettra à PIP de s'installer pour la aiohttpversion 3.6.3, mais pas 3.7.Si vous spécifiez l'intervalle des versions de dépendance, cela donnera un avantage supplémentaire - il n'y aura pas de conflits de version entre les bibliothèques dépendantes.Si vous développez une bibliothèque qui nécessite un package de dépendance différent, autorisez-le non pas une version spécifique, mais un intervalle. Il sera alors beaucoup plus facile pour les utilisateurs de votre bibliothèque de l'utiliser (tout d'un coup leur application nécessite le même package de dépendance, mais d'une version différente).Le versioning sémantique n'est qu'un accord entre les auteurs et les consommateurs de packages. Cela ne garantit pas que les auteurs écrivent du code sans bogues et ne peuvent pas faire d'erreur dans la nouvelle version de leur package.Base de données
Nous concevons le schéma
La description du gestionnaire POST / imports fournit un exemple de déchargement avec des informations sur les résidents:Exemple de téléchargement{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
La première pensée a été de stocker toutes les informations sur le résident dans une seule table citizens, où la relation serait représentée par un champ relativessous la forme d'une liste d'entiers .Mais cette méthode présente plusieurs inconvénientsGET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
De plus, j'ai décidé de rassembler toutes les données nécessaires au travail sous une troisième forme normale , et la structure suivante a été obtenue:
- Le tableau des importations se compose d'une colonne à incrémentation automatique
import_id. Il est nécessaire de créer une vérification de clé étrangère dans le tableau citizens.
- La table des citoyens stocke des données scalaires sur le résident (tous les champs sauf les informations sur les relations familiales).
Une paire ( import_id, citizen_id) est utilisée comme clé primaire , garantissant l'unicité des résidents citizen_iddans le cadre import_id.
Une clé étrangère citizens.import_id -> imports.import_idgarantit que le champ citizens.import_idcontient uniquement les déchargements existants.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
Cette structure garantit l' intégrité des données à l'aide des outils PostgreSQL , elle vous permet d' obtenir efficacement des résidents avec des proches de la base de données, mais est soumise à une condition de concurrence lors de la mise à jour des informations sur les résidents avec des requêtes compétitives (nous examinerons de plus près la mise en œuvre du gestionnaire PATCH).Décrire le schéma dans SQLAlchemy
Dans le chapitre 5, j'ai expliqué comment créer des requêtes à l'aide de SQLAlchemy, vous devez décrire le schéma de la base de données à l'aide d'objets spéciaux: les tables sont décrites à l'aide sqlalchemy.Tableet liées à un registre sqlalchemy.MetaDataqui stocke toutes les méta-informations sur la base de données. Soit dit en passant, le registre MetaDatapeut non seulement stocker les méta-informations décrites en Python, mais également représenter l'état réel de la base de données sous la forme d'objets SQLAlchemy.Cette fonctionnalité permet également à Alembic de comparer les conditions et de générer automatiquement un code de migration.Soit dit en passant, chaque base de données a son propre schéma de dénomination des contraintes par défaut. Pour que vous ne perdiez pas de temps à nommer de nouvelles contraintes ou à rechercher / rappeler quelle contrainte vous êtes sur le point de supprimer, SQLAlchemy suggère d'utiliser des modèles de dénomination pour les conventions de dénomination . Ils peuvent être définis dans le registre MetaData.Créer un registre MetaData et lui passer des modèles de dénomination
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Si vous spécifiez des modèles de dénomination, Alembic les utilisera lors de la génération automatique des migrations et nommera toutes les contraintes en fonction d'eux. À l'avenir, le registre créé MetaDatasera nécessaire pour décrire les tables:Nous décrivons le schéma de base de données avec des objets SQLAlchemy
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Personnaliser Alembic
Lorsque le schéma de la base de données est décrit, il est nécessaire de générer des migrations, mais pour cela, vous devez d'abord configurer Alembic, qui est également abordé au chapitre 5 .Pour utiliser la commande alembic, vous devez effectuer les étapes suivantes:- Installer le paquet:
pip install alembic - Initialize Alambic:
cd analyzer && alembic init db/alembic.
Cette commande créera un fichier de configuration analyzer/alembic.iniet un dossier analyzer/db/alembicavec le contenu suivant:
env.py- Appelé chaque fois que vous démarrez Alembic. Se connecte au registre Alembic sqlalchemy.MetaDataavec une description de l'état souhaité de la base de données et contient des instructions pour démarrer les migrations.
script.py.mako - le modèle sur la base duquel les migrations sont générées.versions - le dossier dans lequel Alembic recherchera (et générera) les migrations.
- Spécifiez l'adresse de la base de données dans le fichier alembic.ini:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- Spécifiez une description de l'état souhaité de la base de données (registre
sqlalchemy.MetaData) afin qu'Alembic puisse générer automatiquement des migrations:
from analyzer.db import schema
target_metadata = schema.metadata
Alembic est configuré et peut déjà être utilisé, mais dans notre cas, cette configuration présente plusieurs inconvénients:- L'utilitaire
alembicrecherche alembic.inidans le répertoire de travail actuel. Vous alembic.inipouvez spécifier le chemin d'accès à l' argument de ligne de commande, mais cela n'est pas pratique: je veux pouvoir appeler la commande à partir de n'importe quel dossier sans paramètres supplémentaires. - Pour configurer Alembic pour fonctionner avec une base de données spécifique, vous devez modifier le fichier
alembic.ini. Il serait beaucoup plus pratique de spécifier les paramètres de base de données pour la variable d'environnement et / ou un argument de ligne de commande, par exemple --pg-url. - Le nom de l'utilitaire
alembicne correspond pas très bien au nom de notre service (et l'utilisateur peut en fait ne pas avoir du tout Python et ne rien savoir sur Alembic). Il serait beaucoup plus pratique pour l'utilisateur final que toutes les commandes exécutables du service aient un préfixe commun, par exemple analyzer-*.
Ces problèmes sont résolus avec un petit wrapper. analyzer/db/__main__.py:- Alembic utilise un module standard pour traiter les arguments de ligne de commande
argparse. Il vous permet d'ajouter un argument facultatif --pg-urlavec une valeur par défaut à partir d'une variable d'environnement ANALYZER_PG_URL.
Le codeimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
- Le chemin d'accès au fichier
alembic.inipeut être calculé par rapport à l'emplacement du fichier exécutable et non au répertoire de travail actuel de l'utilisateur.
Le codeimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
Lorsque l' utilitaire de gestion de l'état de la base de données est prêt, il peut être enregistré en setup.pytant que commande exécutable avec un nom compréhensible pour l'utilisateur final, par exemple analyzer-db:Enregistrez une commande exécutable dans setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
Après avoir réinstallé le module, un fichier sera généré env/bin/analyzer-dbet la commande analyzer-dbdeviendra disponible:$ pip install -e '.[dev]'
Nous générons des migrations
Pour générer des migrations, deux états sont requis: l'état souhaité (que nous avons décrit avec des objets SQLAlchemy) et l'état réel (la base de données, dans notre cas, est vide).J'ai décidé que le moyen le plus simple d'augmenter Postgres était avec Docker, et pour plus de commodité, j'ai ajouté une commande make postgresqui exécute un conteneur en arrière-plan avec PostgreSQL sur le port 5432:Augmentez PostgreSQL et générez la migration$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
Alembic fait généralement un bon travail de routine pour générer des migrations, mais je voudrais attirer l'attention sur les points suivants:- Les types de données utilisateur spécifiés dans les tables créées sont créés automatiquement (dans notre cas -
gender), mais le code pour les supprimer n'est downgradepas généré. Si vous appliquez, annulez, puis appliquez à nouveau la migration, cela provoquera une erreur car le type de données spécifié existe déjà.
Supprimer le type de données de genre dans la méthode de rétrogradationfrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- Dans la méthode,
downgradecertaines actions peuvent parfois être supprimées (si nous supprimons la table entière, vous ne pouvez pas supprimer ses index séparément):
par exempledef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
Lorsque la migration est fixe et prête, nous l'appliquons:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
application
Avant de commencer à créer des gestionnaires, vous devez configurer l'application aiohttp.Si vous regardez le démarrage rapide aiohttp, vous pouvez écrire quelque chose comme ceciimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
Ce code soulève un certain nombre de questions et présente un certain nombre d'inconvénients:- Comment configurer l'application? Au minimum, vous devez spécifier l'hôte et le port de connexion des clients, ainsi que les informations de connexion à la base de données.
J'aime vraiment résoudre ce problème avec l'aide du module ConfigArgParse: il étend le standard argparseet permet d'utiliser des arguments de ligne de commande, des variables d'environnement (indispensables pour configurer les conteneurs Docker) et même des fichiers de configuration (ainsi que la combinaison de ces méthodes) pour la configuration. En l'utilisant ConfigArgParse, vous pouvez également valider les valeurs des paramètres de configuration d'application.
Un exemple de traitement des paramètres à l'aide de ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
Toutes les réponses de gestionnaire réussies seront renvoyées au format JSON. Il serait également pratique pour les clients de recevoir des informations sur les erreurs sous une forme sérialisée (par exemple, pour voir quels champs n'ont pas passé la validation).La documentation aiohttppropose une méthode json_responsequi prend un objet, le sérialise en JSON et renvoie un nouvel objet aiohttp.web.Responseavec un en-tête Content-Type: application/jsonet des données sérialisées à l'intérieur.Comment sérialiser des données à l'aide de json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Mais il existe un autre moyen: aiohttp vous permet d'enregistrer un sérialiseur arbitraire pour un type spécifique de données de réponse dans le registre aiohttp.PAYLOAD_REGISTRY. Par exemple, vous pouvez spécifier un sérialiseur aiohttp.JsonPayloadpour les objets de type Mapping .Dans ce cas, il suffira que le gestionnaire retourne un objet Responseavec les données de réponse dans le paramètre body. aiohttp trouvera un sérialiseur qui correspond au type de données et sérialisera la réponse.Outre le fait que la sérialisation des objets est décrite en un seul endroit, cette approche est également plus flexible - elle vous permet d'implémenter des solutions très intéressantes (nous considérerons l'un des cas d'utilisation dans le gestionnaire GET /imports/$import_id/citizens).Comment sérialiser des données à l'aide de aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Il est important de comprendre que json_response, par exemple aiohttp.JsonPayload, ils utilisent une méthode standard json.dumpsqui ne peut pas sérialiser des types de données complexes, par exemple, datetime.dateou asyncpg.Record( asyncpgrenvoie des enregistrements de la base de données en tant qu'instances de cette classe). De plus, certains objets complexes peuvent en contenir d'autres: dans un enregistrement de la base de données, il peut y avoir un champ type datetime.date.Les développeurs Python ont résolu ce problème: la méthode json.dumpsvous permet d'utiliser l'argument defaultpour spécifier une fonction qui est appelée lorsqu'il est nécessaire de sérialiser un objet inconnu. La fonction devrait convertir un objet inconnu en un type qui peut sérialiser le module json.Comment étendre JsonPayload pour sérialiser des objets arbitrairesimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
Gestionnaires
aiohttp vous permet d'implémenter des gestionnaires avec des fonctions et classes asynchrones. Les classes sont plus extensibles: premièrement, le code appartenant à un gestionnaire peut être placé à un endroit, et deuxièmement, les classes vous permettent d'utiliser l'héritage pour vous débarrasser de la duplication de code (par exemple, chaque gestionnaire nécessite une connexion à la base de données).Classe de base du gestionnairefrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Comme il est difficile de lire un gros fichier, j'ai décidé de diviser les gestionnaires en fichiers. Les petits fichiers encouragent une faible connectivité et, par exemple, s'il y a des importations en anneau à l'intérieur des gestionnaires, cela signifie que quelque chose ne va pas dans la composition des entités.POST / importations
Le gestionnaire d'entrée reçoit json avec des données sur les résidents. La taille de requête maximale autorisée dans aiohttp est contrôlée par l'option client_max_sizeet est de 2 Mo par défaut . Si la limite est dépassée, aiohttp retournera une réponse HTTP avec un état de 413: Erreur d'entité trop grande demandée.En même temps, le json correct avec les lignes et les nombres les plus longs pèsera ~ 63 mégaoctets, donc les restrictions sur la taille de la demande doivent être étendues.Ensuite, vous devez vérifier et désérialiser les données . S'ils sont incorrects, vous devez renvoyer une réponse HTTP 400: Bad Request.J'avais besoin de deux régimes Marhsmallow. Le premier CitizenSchemavérifie les données de chaque résident individuel et désérialise également la chaîne joyeux anniversaire dans l'objet datetime.date:- Type de données, format et disponibilité de tous les champs obligatoires;
- Manque de champs inconnus;
- La date de naissance doit être indiquée dans le format
DD.MM.YYYYet ne peut avoir aucune signification pour l'avenir; - La liste des proches de chaque résident doit contenir des identifiants uniques des résidents présents dans ce téléchargement.
Le deuxième schéma ImportSchema,, vérifie le déchargement dans son ensemble:citizen_id chaque résident du déchargement doit être unique;- Les liens familiaux doivent être à double sens (si le résident n ° 1 a un résident n ° 2 dans la liste des parents, le résident n ° 2 doit également avoir un parent n ° 1).
Si les données sont correctes, elles doivent être ajoutées à la base de données avec une nouvelle unique import_id.Pour ajouter des données, vous devrez effectuer plusieurs requêtes dans différentes tables. Afin d'éviter des données partiellement partiellement ajoutées dans la base de données en cas d'erreur ou d'exception (par exemple, lorsque vous déconnectez un client qui n'a pas reçu de réponse complète, aiohttp lèvera une exception CancelledError ), vous devez utiliser une transaction .Il est nécessaire d'ajouter des données aux tables par parties , car dans une requête à PostgreSQL, il ne peut y avoir plus de 32 767 arguments. Il y a citizens9 champs dans le tableau . Par conséquent, pour 1 requête, seules 32 767/9 = 3 640 lignes peuvent être insérées dans ce tableau, et en un téléchargement, il peut y avoir jusqu'à 10 000 habitants.GET / importations / $ import_id / citoyens
Le gestionnaire renvoie tous les résidents pour déchargement avec le spécifié import_id. Si le téléchargement spécifié n'existe pas , vous devez renvoyer la réponse HTTP 404: Not Found. Ce comportement semble être courant pour les gestionnaires qui ont besoin d'un déchargement existant, j'ai donc extrait le code de vérification dans une classe distincte.Classe de base pour les gestionnaires avec déchargementsfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
Pour obtenir une liste de parents pour chaque résident, vous devrez effectuer LEFT JOINde table citizensen table relations, en agrégeant le champ relations.relative_idregroupé par import_idet citizen_id.Si le résident n'a pas de parents, il LEFT JOINretournera la relations.relative_idvaleur pour lui sur le terrain NULLet, à la suite de l'agrégation, la liste des parents ressemblera [NULL].Pour corriger cette valeur incorrecte, j'ai utilisé la fonction array_remove .La base de données stocke la date dans un format YYYY-MM-DD, mais nous avons besoin d'un format DD.MM.YYYY.Techniquement, vous pouvez formater la date avec une requête SQL ou du côté Python au moment de la sérialisation de la réponse avec json.dumps(asyncpg renvoie la valeur du champ en birth_datetant qu'instance de la classedatetime.date)J'ai choisi la sérialisation côté Python, étant donné que c'est birth_datele seul objet datetime.datedu projet avec un seul format (voir la section «Sérialisation des données» ).Malgré le fait que le processeur exécute deux requêtes (vérification de l'existence d'un déchargement et d'une demande de liste de résidents), il n'est pas nécessaire d'utiliser une transaction . Par défaut, PostgreSQL utilise le niveau d'isolement, READ COMMITTEDet même au sein d'une transaction, toutes les modifications apportées à d'autres transactions terminées avec succès seront visibles (ajout de nouvelles lignes, modification de celles existantes).Le téléchargement le plus important dans une vue texte peut prendre environ 63 mégaoctets, ce qui est beaucoup, surtout si l'on considère que plusieurs demandes de réception de données peuvent arriver en même temps. Il existe un moyen assez intéressant d'obtenir des données de la base de données à l'aide du curseur et de les envoyer au client en plusieurs parties .Pour ce faire, nous devons implémenter deux objets:- Un objet
SelectQuerytype AsyncIterablequi renvoie des enregistrements de la base de données. Au premier appel, il se connecte à la base de données, ouvre une transaction et crée un curseur; lors d'une nouvelle itération, il renvoie les enregistrements de la base de données. Il est retourné par le gestionnaire.
Code SelectQueryfrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- Un sérialiseur
AsyncGenJSONListPayloadqui peut parcourir les générateurs asynchrones, sérialiser les données d'un générateur asynchrone vers JSON et envoyer des données aux clients en plusieurs parties. Il est enregistré aiohttp.PAYLOAD_REGISTRYcomme sérialiseur d'objets AsyncIterable.
Code AsyncGenJSONListPayloadimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
De plus, dans le gestionnaire, il sera possible de créer un objet SelectQuery, de lui passer une requête SQL et une fonction pour ouvrir la transaction et la renvoyer à Response body:Code gestionnaire
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpil détecte un aiohttp.PAYLOAD_REGISTRYsérialiseur enregistré AsyncGenJSONListPayloadpour les objets de type dans le registre AsyncIterable. Ensuite, le sérialiseur parcourt l'objet SelectQueryet envoie des données au client. Lors du premier appel, l'objet SelectQueryreçoit une connexion à la base de données, ouvre une transaction et crée un curseur; lors d'une nouvelle itération, il recevra les données de la base de données avec le curseur et les renverra ligne par ligne.Cette approche permet de ne pas allouer de mémoire pour la totalité du volume de données à chaque requête, mais elle a une particularité: l'application ne pourra pas renvoyer l'état HTTP correspondant au client en cas d'erreur (après tout, l'état HTTP, les en-têtes ont déjà été envoyés au client et les données sont en cours d'écriture).Lorsqu'une exception se produit, il ne reste plus qu'à se déconnecter. Une exception, bien sûr, peut être sécurisée, mais le client ne pourra pas comprendre exactement quelle erreur s'est produite.D'un autre côté, une situation similaire peut se produire même si le processeur reçoit toutes les données de la base de données, mais le réseau clignote lors de la transmission des données au client - personne n'est à l'abri de cela.PATCH / imports / $ import_id / citoyens / $ citizen_id
Le gestionnaire reçoit l'identifiant du déchargement import_id, le résident citizen_id, ainsi que json avec les nouvelles données sur le résident. Dans le cas d'un déchargement inexistant ou d'un résident , une réponse HTTP doit être retournée 404: Not Found.Les données transmises par le client doivent être vérifiées et désérialisées . S'ils sont incorrects, vous devez renvoyer une réponse HTTP 400: Bad Request. J'ai implémenté un schéma Marshmallow PatchCitizenSchemaqui vérifie:- Le type et le format des données pour les champs spécifiés.
- Date de naissance. Il doit être spécifié dans un format
DD.MM.YYYYet ne peut être significatif à l'avenir. - Une liste des proches de chaque résident. Il doit avoir des identifiants uniques pour les résidents.
L'existence des parents indiqués dans le champ relativesne peut pas être vérifiée séparément: si un relationsrésident inexistant est ajouté à la table, PostgreSQL renvoie une erreur ForeignKeyViolationErrorqui peut être traitée et le statut HTTP peut être retourné 400: Bad Request.Quel statut doit être retourné si le client a envoyé des données incorrectes pour un résident inexistant ou un déchargement ? Il est sémantiquement plus correct de vérifier d'abord l'existence d'un déchargement et d'un résident (s'il n'y en a pas, retour 404: Not Found) et ensuite seulement si le client a envoyé les données correctes (sinon, retour 400: Bad Request). En pratique, il est souvent moins coûteux de vérifier d'abord les données, et seulement si elles sont correctes, d'accéder à la base de données.Les deux options sont acceptables, mais j'ai décidé de choisir une deuxième option moins chère, car dans tous les cas, le résultat de l'opération est une erreur qui n'affecte rien (le client corrigera les données et découvrira ensuite que le résident n'existe pas).Si les données sont correctes, il est nécessaire de mettre à jour les informations sur le résident dans la base de données . Dans le gestionnaire, vous devrez effectuer plusieurs requêtes sur différentes tables. Si une erreur ou une exception se produit, les modifications apportées à la base de données doivent être annulées, de sorte que les requêtes doivent être effectuées dans une transaction .La méthode PATCH vous permet de transférer uniquement certains champs pour un résident.Le gestionnaire doit être écrit de telle manière qu'il ne se bloque pas lors de l'accès aux données que le client n'a pas spécifié et n'exécute pas non plus les requêtes sur les tables dans lesquelles les données n'ont pas changé.Si le client a précisé le champ relatives, il est nécessaire d'obtenir une liste des proches existants. S'il a changé, déterminez les enregistrements de la table qui relativesdoivent être supprimés et ceux à ajouter afin d'aligner la base de données sur la demande du client. Par défaut, PostgreSQL utilise l'isolement des transactions READ COMMITTED. Cela signifie que dans le cadre de la transaction en cours, les modifications seront visibles pour les enregistrements existants (ainsi que les nouveaux) des autres transactions terminées. Cela peut conduire à une condition de concurrence entre les demandes concurrentielles .Supposons qu'il y ait un déchargement avec les résidents#1. #2, #3sans parenté. Le service reçoit deux demandes simultanées de changement de résident n ° 1: {"relatives": [2]}et {"relatives": [3]}. aiohttp créera deux gestionnaires qui recevront simultanément l'état actuel du résident de PostgreSQL.Chaque gestionnaire ne détectera pas une seule relation associée et décidera d'ajouter une nouvelle relation avec le parent spécifié. En conséquence, le résident n ° 1 a le même domaine que les proches [2,3]. Ce comportement ne peut pas être qualifié d'évident. Deux options sont prévues pour décider du résultat de la course: pour terminer uniquement la première demande, et pour la seconde, renvoyer une réponse HTTP
Ce comportement ne peut pas être qualifié d'évident. Deux options sont prévues pour décider du résultat de la course: pour terminer uniquement la première demande, et pour la seconde, renvoyer une réponse HTTP409: Conflict(afin que le client répète la demande), ou pour exécuter les demandes à tour de rôle (la deuxième demande ne sera traitée qu'après la fin de la première).La première option peut être implémentée en activant le mode d'isolementSERIALIZABLE. Si au cours du traitement de la demande, quelqu'un a déjà réussi à modifier et à valider les données, une exception sera levée, qui peut être traitée et le statut HTTP correspondant retourné.L'inconvénient de cette solution - un grand nombre de verrous dans PostgreSQL, SERIALIZABLElèvera une exception, même si les requêtes concurrentielles modifient les enregistrements des résidents de différents déchargements.Vous pouvez également utiliser le mécanisme de verrouillage des recommandations . Si vous obtenez un tel verrouillage import_id, les demandes concurrentielles de différents déchargements pourront s'exécuter en parallèle.Pour traiter les demandes concurrentielles en un seul téléchargement, vous pouvez implémenter le comportement de l'une des options: la fonction pg_try_advisory_xact_lockessaie d'obtenir un verrou etil renvoie le résultat booléen immédiatement (s'il n'était pas possible d'obtenir le verrou - une exception peut être levée), mais il pg_advisory_xact_lockattend que laressource soit disponible pour le blocage (dans ce cas, les requêtes seront exécutées séquentiellement, j'ai opté pour cette option).Par conséquent, le gestionnaire doit renvoyer les informations actuelles sur le résident mis à jour . Il a été possible de nous limiter au retour des données de sa demande au client (puisque nous renvoyons une réponse au client, cela signifie qu'il n'y a eu aucune exception et que toutes les demandes ont été traitées avec succès). Ou - utilisez le mot clé RETURNING dans les requêtes qui modifient la base de données et génèrent une réponse à partir des résultats. Mais ces deux approches ne nous permettraient pas de voir et de tester le cas de la race des États.Il n'y avait aucune exigence de charge élevée pour le service, j'ai donc décidé de demander à nouveau toutes les données sur le résident et de renvoyer au client un résultat honnête de la base de données.GET / importations / $ import_id / citoyens / anniversaires
Le gestionnaire calcule le nombre de cadeaux que chaque résident du déchargement recevra à ses proches (première commande). Le numéro est groupé par mois pour le téléchargement avec le spécifié import_id. Dans le cas d'un téléchargement inexistant , une réponse HTTP doit être retournée 404: Not Found.Il existe deux options de mise en œuvre:- Obtenez des données pour les résidents avec des proches dans la base de données et du côté Python, agrégez les données par mois et générez des listes pour les mois pour lesquels il n'y a pas de données dans la base de données.
- Compilez une requête json dans la base de données et ajoutez des stubs pour les mois manquants.
J'ai opté pour la première option - visuellement, elle semble plus compréhensible et prise en charge. Le nombre d'anniversaires dans un mois donné peut être obtenu en faisant JOINdu tableau avec les liens familiaux ( relations.citizen_id- le résident pour lequel nous considérons les anniversaires des proches) dans le tableau citizens(contenant la date de naissance à partir de laquelle vous souhaitez obtenir le mois).Les valeurs de mois ne doivent pas contenir de zéros en tête. Le mois obtenu à partir du champ birth_dateutilisant la fonction date_partpeut contenir un zéro non significatif. Pour l' enlever, je fis castà integerla requête SQL.Malgré le fait que le gestionnaire doive répondre à deux demandes (vérifier l'existence du déchargement et obtenir des informations sur les anniversaires et les cadeaux), aucune transaction n'est requise .Par défaut, PostgreSQL utilise le mode READ COMMITTED, dans lequel tous les nouveaux enregistrements (ajoutés par d'autres transactions) et existants (modifiés par d'autres transactions) sont visibles dans la transaction en cours une fois qu'ils sont terminés avec succès.Par exemple, si un nouveau téléchargement est ajouté au moment de la réception des données, cela n'affectera pas les données existantes. Si, au moment de la réception des données, une demande de changement de résident est satisfaite, soit les données ne seront pas encore visibles (si la transaction modifiant les données n'est pas terminée), soit la transaction se terminera complètement et toutes les modifications seront immédiatement visibles. L'intégrité obtenue de la base de données ne sera pas violée.GET / imports / $ import_id / towns / stat / percentile / age
Le gestionnaire calcule les 50e, 75e et 99e centiles de l'âge (années entières) des résidents par ville dans l'échantillon avec l'id_import_id spécifié. Dans le cas d'un téléchargement inexistant , une réponse HTTP doit être retournée 404: Not Found.Malgré le fait que le processeur exécute deux requêtes (vérification de l'existence du déchargement et obtention d'une liste de résidents), il n'est pas nécessaire d'utiliser une transaction .Il existe deux options de mise en œuvre:- Obtenez l'âge des résidents à partir de la base de données, regroupés par ville, puis du côté Python, calculez les centiles en utilisant numpy (qui est spécifié comme référence dans la tâche) et arrondissez à deux décimales.
- PostgreSQL: percentile_cont , SQL-, numpy .
La deuxième option nécessite de transférer moins de données entre l'application et PostgreSQL, mais elle n'a pas d'écueil très évident: dans PostgreSQL, l'arrondi est mathématique, ( SELECT ROUND(2.5)renvoie 3), et en Python - comptabilité, à l'entier le plus proche ( round(2.5)retourne 2).Pour tester le gestionnaire, l'implémentation doit être la même dans PostgreSQL et Python (l'implémentation d'une fonction avec arrondi mathématique en Python semble plus facile). Il convient de noter que lors du calcul des centiles, numpy et PostgreSQL peuvent renvoyer des nombres légèrement différents, mais en tenant compte de l'arrondissement, cette différence ne sera pas perceptible.Essai
Que faut-il vérifier dans cette application? Premièrement, que les gestionnaires répondent aux exigences et effectuent le travail requis dans un environnement aussi proche que possible de l'environnement de combat. Deuxièmement, les migrations qui modifient l'état de la base de données fonctionnent sans erreur. Troisièmement, il existe un certain nombre de fonctions auxiliaires qui pourraient également être correctement couvertes par des tests.J'ai décidé d'utiliser le framework pytest en raison de sa flexibilité et de sa facilité d'utilisation. Il offre un mécanisme puissant pour préparer l'environnement aux tests - les luminaires , c'est-à-dire qu'il fonctionne avec un décorateurpytest.mark.fixturedont les noms peuvent être spécifiés par le paramètre du test. Si pytest détecte un paramètre avec un nom de luminaire dans l'annotation de test, il exécutera ce luminaire et transmettra le résultat dans la valeur de ce paramètre. Et si le luminaire est un générateur, le paramètre de test prendra la valeur renvoyée yieldet une fois le test terminé, la deuxième partie du luminaire sera exécutée, ce qui peut effacer les ressources ou fermer les connexions.Pour la plupart des tests, nous avons besoin d'une base de données PostgreSQL. Pour isoler les tests les uns des autres, vous pouvez créer une base de données distincte avant chaque test et la supprimer après l'exécution.Créer une base de données d'appareils pour chaque testimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
Le module sqlalchemy_utils a fait un excellent travail de cette tâche , en tenant compte des caractéristiques des différentes bases de données et pilotes. Par exemple, PostgreSQL ne permet pas l'exécution CREATE DATABASEdans un bloc de transaction. Lors de la création d'une base de données, il sqlalchemy_utilstraduit psycopg2(qui exécute généralement toutes les demandes dans une transaction) en mode de validation automatique.Autre caractéristique importante: si au moins un client est connecté à PostgreSQL, la base de données ne peut pas être supprimée, mais sqlalchemy_utilsdéconnecte tous les clients avant de supprimer la base de données. La base de données sera supprimée avec succès même si un test avec des connexions actives s'y bloque.Nous avons besoin de PostgreSQL dans différents états: pour tester les migrations, nous avons besoin d'une base de données propre, tandis que les gestionnaires exigent que toutes les migrations soient appliquées. Vous pouvez modifier par programme l'état d'une base de données à l'aide des commandes Alembic; elles nécessitent l'objet de configuration Alembic pour les appeler.Créer un objet de configuration de luminaire Alembicfrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Veuillez noter que les appareils alembic_configont un paramètre postgres- pytestpermet non seulement d'indiquer la dépendance du test sur les appareils, mais aussi les dépendances entre appareils.Ce mécanisme vous permet de séparer de manière flexible la logique et d'écrire du code très concis et réutilisable.Gestionnaires
Le test des gestionnaires nécessite une base de données avec des tables et des types de données créés. Pour appliquer des migrations, vous devez appeler par programme la commande de mise à niveau d'Alembic. Pour l'appeler, vous avez besoin d'un objet avec la configuration Alembic, que nous avons déjà défini avec des fixtures alembic_config. La base de données avec migrations ressemble à une entité complètement indépendante, et elle peut être représentée comme un appareil:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
Lorsqu'il y a de nombreuses migrations dans le projet, leur application pour chaque test peut prendre trop de temps. Pour accélérer le processus, vous pouvez créer une base de données avec des migrations une fois , puis l' utiliser comme modèle .En plus de la base de données pour tester les gestionnaires, vous aurez besoin d'une application en cours d'exécution, ainsi que d'un client configuré pour fonctionner avec cette application. Pour rendre l'application facile à tester, j'ai mis sa création dans une fonction create_appqui prend des paramètres à exécuter: une base de données, un port pour l'API REST, et autres.Les arguments pour lancer l'application peuvent également être représentés comme un appareil distinct. Pour les créer, vous devrez déterminer le port libre pour exécuter l'application de test et l'adresse de la base de données temporaire migrée.Pour déterminer le port libre, j'ai utilisé le luminaire aiomisc_unused_portdu package aiomisc.Un appareil standard aiohttp_unused_portconviendrait également, mais il renvoie une fonction pour déterminer les ports libres, tandis qu'il aiomisc_unused_portrenvoie immédiatement le numéro de port. Pour notre application, nous devons déterminer un seul port libre, j'ai donc décidé de ne pas écrire une ligne de code supplémentaire avec un appel aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
Tous les tests avec des gestionnaires impliquent des demandes à l'API REST; travailler directement avec l'application n'est aiohttppas requis. Par conséquent, j'ai créé un appareil qui lance l'application et, en utilisant l'usine, aiohttp_clientcrée et renvoie un client de test standard connecté à l'application aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Maintenant, si vous spécifiez le luminaire dans les paramètres de test api_client, les événements suivants se produisent:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
Les appareils peuvent éviter la duplication de code, mais en plus de préparer l'environnement dans les tests, il y a un autre endroit potentiel où il y aura beaucoup du même code - les demandes d'application.Tout d'abord, en faisant une demande, nous nous attendons à obtenir un certain statut HTTP. Deuxièmement, si l'état correspond à celui attendu, avant de travailler avec les données, vous devez vous assurer qu'elles ont le bon format. Il est facile de faire une erreur ici et d'écrire un gestionnaire qui effectue les calculs corrects et renvoie le résultat correct, mais ne passe pas la validation automatique en raison du format de réponse incorrect (par exemple, oubliez d'envelopper la réponse dans un dictionnaire avec une clé data). Toutes ces vérifications pourraient être effectuées en un seul endroit.Dans le moduleanalyzer.testing J'ai préparé pour chaque gestionnaire une fonction d'aide qui vérifie l'état de HTTP, ainsi que le format de réponse à l'aide de Marshmallow.GET / importations / $ import_id / citoyens
J'ai décidé de commencer avec un gestionnaire qui renvoie des résidents, car il est très utile pour vérifier les résultats d'autres gestionnaires qui modifient l'état de la base de données.Je n'ai intentionnellement pas utilisé de code qui ajoute des données à la base de données du gestionnaire POST /imports, bien qu'il ne soit pas difficile d'en faire une fonction distincte. Le code du gestionnaire a la propriété de changer et s'il y a une erreur dans le code qui s'ajoute à la base de données, il y a une chance que le test cesse de fonctionner comme prévu et implicitement pour les développeurs arrête d'afficher des erreurs.Pour ce test, j'ai défini les ensembles de données de test suivants:- Déchargement avec plusieurs proches. Vérifie que pour chaque résident une liste avec les identifiants des proches sera correctement constituée.
- Déchargement avec un résident sans parents. Vérifie que le champ
relativesest une liste vide (en raison LEFT JOINde la requête SQL, la liste des parents peut être égale [None]). - Déchargement avec un résident qui est un parent de lui-même.
- Déchargement vide. Vérifie que le gestionnaire autorise l'ajout de déchargement vide et ne se bloque pas avec une erreur.
Pour exécuter le même test séparément à chaque téléchargement, j'ai utilisé un autre mécanisme Pytest très puissant - le paramétrage . Ce mécanisme vous permet d'envelopper la fonction de test dans le décorateur pytest.mark.parametrizeet de décrire les paramètres que la fonction de test doit prendre pour chaque cas de test individuel.Comment paramétrer un testimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
Ainsi, le test ajoutera le téléchargement à la base de données, puis, à l'aide d'une demande au gestionnaire, il recevra des informations sur les résidents et comparera le téléchargement de référence avec celui reçu. Mais comment comparez-vous les résidents?Chaque résident se compose de champs scalaires et d'un champ relatives- une liste d'identifiants de parents. Une liste en Python est un type ordonné, et lors de la comparaison de l'ordre des éléments de chaque liste importe, mais lors de la comparaison des listes avec les frères et sœurs, l'ordre ne devrait pas avoir d'importance.Si vous apportez relativesà l'ensemble avant la comparaison, alors lors de la comparaison, cela ne fonctionne pas pour trouver une situation où l'un des habitants sur le terrain relativesa des doublons. Si vous triez la liste avec les identifiants des proches, cela évitera le problème de l'ordre différent des identifiants des proches, mais en même temps détectera les doublons.Lors de la comparaison de deux listes avec des résidents, l'un peut rencontrer un problème similaire: techniquement, l'ordre des résidents dans le déchargement n'est pas important, mais il est important de détecter s'il y a deux résidents avec les mêmes identifiants dans un déchargement et pas dans l'autre. Ainsi, en plus d'organiser la liste avec des proches, les proches de chaque résident doivent organiser les résidents à chaque déchargement.Puisque la tâche de comparer les résidents se posera plus d'une fois, j'ai mis en place deux fonctions: une pour comparer deux résidents, et la seconde pour comparer deux listes avec des résidents:Comparez les résidentsfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
Pour m'assurer que ce gestionnaire ne retourne pas les résidents d'autres déchargements, j'ai décidé d'ajouter un déchargement supplémentaire avec un habitant avant chaque test.POST / importations
J'ai défini les jeux de données suivants pour tester le gestionnaire:- Données correctes, censées être ajoutées avec succès à la base de données.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- Déchargement vide
Le gestionnaire doit prendre en compte un tel cas et ne pas tomber, en essayant d'effectuer une insertion vide dans la table avec les habitants.
- Données avec des erreurs, attendez-vous à une réponse HTTP de 400: Bad Request.
- La date de naissance est incorrecte (futur).
- citizen_id n'est pas unique dans le téléchargement.
- Une parenté est indiquée de manière incorrecte (il n'y a qu'un résident à l'autre, mais il n'y a pas de retour).
- Le résident a un parent inexistant au déchargement.
- Les liens familiaux ne sont pas uniques.
Si le processeur a fonctionné correctement et que les données ont été ajoutées, vous devez ajouter les résidents à la base de données et les comparer avec le déchargement standard. Pour obtenir des résidents, j'ai utilisé le gestionnaire déjà testé GET /imports/$import_id/citizenset, à titre de comparaison, une fonction compare_citizen_groups.PATCH / imports / $ import_id / citoyens / $ citizen_id
La validation des données est à bien des égards similaire à celle décrite dans le gestionnaire POST /importsà quelques exceptions près: il n'y a qu'un seul résident et le client ne peut passer que les champs qu'il souhaite .J'ai décidé d'utiliser les ensembles suivants avec des données incorrectes pour vérifier que le gestionnaire retournera une réponse HTTP 400: Bad request:- Le champ est spécifié, mais a un type et / ou un format de données incorrects
- La date de naissance est incorrecte (heure future).
- Le champ
relativescontient un parent qui n'existe pas dans le déchargement.
Il est également nécessaire de vérifier que le gestionnaire met correctement à jour les informations sur le résident et ses proches.Pour ce faire, créez un téléchargement avec trois habitants, dont deux sont des parents, et envoyez une demande avec de nouvelles valeurs pour tous les champs scalaires et un nouvel identifiant relatif dans le champ relatives.Pour m'assurer que le gestionnaire distingue les résidents de déchargements différents avant le test (et, par exemple, ne change pas les résidents avec les mêmes identifiants d'un autre déchargement), j'ai créé un déchargement supplémentaire avec trois résidents qui ont les mêmes identifiants.Le gestionnaire doit enregistrer les nouvelles valeurs des champs scalaires, ajouter un nouveau parent spécifié et supprimer la relation avec un ancien parent non spécifié. Tous les changements de parenté devraient être bilatéraux. Il ne devrait pas y avoir de changement dans les autres déchargements.Étant donné qu'un tel gestionnaire peut être soumis à des conditions de concurrence (cela a été discuté dans la section Développement), j'ai ajouté deux tests supplémentaires . L'un reproduit le problème avec l'état de race (étend la classe de gestionnaire et supprime le verrou), le second prouve que le problème avec l'état de race n'est pas reproduit.GET / importations / $ import_id / citoyens / anniversaires
Pour tester ce gestionnaire, j'ai sélectionné les jeux de données suivants:- Un déchargement dans lequel un résident a un parent en un mois et deux parents en un autre.
- Déchargement avec un résident sans parents. Vérifie que le gestionnaire n'en tient pas compte dans les calculs.
- Déchargement vide. Vérifie que le gestionnaire n'échouera pas et renverra le dictionnaire correct avec 12 mois dans la réponse.
- Déchargement avec un résident qui est un parent de lui-même. Vérifie qu'un résident achètera un cadeau pour le mois de sa naissance.
Le gestionnaire doit retourner tous les mois dans la réponse, même s'il n'y a pas d'anniversaire au cours de ces mois. Pour éviter les doublons, j'ai créé une fonction à laquelle vous pouvez passer le dictionnaire afin qu'il le complète avec des valeurs pour les mois manquants.Pour m'assurer que le gestionnaire fait la distinction entre les résidents de déchargements différents, j'ai ajouté un déchargement supplémentaire avec deux parents. Si le gestionnaire les utilise par erreur dans les calculs, les résultats seront incorrects et le gestionnaire tombera avec une erreur.GET / imports / $ import_id / towns / stat / percentile / age
La particularité de ce test est que les résultats de son travail dépendent de l'heure actuelle: l'âge des habitants est calculé en fonction de la date du jour. Pour s'assurer que les résultats des tests ne changent pas au fil du temps, la date actuelle, les dates de naissance des résidents et les résultats attendus doivent être enregistrés. Cela facilitera la reproduction de tous les cas de bord, même.Quelle est la meilleure date de correction? Le gestionnaire utilise la fonction PostgreSQL pour calculer l'âge des résidents AGE, qui prend le premier paramètre comme date pour laquelle il est nécessaire de calculer l'âge et le second comme date de base (définie par une constante TownAgeStatView.CURRENT_DATE).Nous remplaçons la date de base dans le gestionnaire par l'heure du testfrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
Pour tester le gestionnaire, j'ai sélectionné les ensembles de données suivants (pour tous les résidents, j'ai indiqué une ville, car le gestionnaire agrège les résultats par ville):- Déchargement avec plusieurs résidents dont l'anniversaire est demain (âge - plusieurs années et 364 jours). Vérifie que le processeur utilise uniquement le nombre d'années complètes dans les calculs.
- Déchargement avec un résident dont l'anniversaire est aujourd'hui (âge - exactement quelques années). Il vérifie le cas régional - l'âge d'un résident dont l'anniversaire est aujourd'hui ne doit pas être calculé comme réduit d'un an.
- Déchargement vide. Le gestionnaire ne doit pas tomber dessus.
La numpyréférence pour le calcul des centiles - avec interpolation linéaire, et les résultats de référence pour les tests que j'ai calculés pour eux.Vous devez également arrondir les valeurs de percentile fractionnaire à deux décimales. Si vous avez utilisé PostgreSQL pour l'arrondi dans le gestionnaire et Python pour le calcul des données de référence, vous remarquerez peut-être que l' arrondi dans Python 3 et PostgreSQL peut donner des résultats différents .par exemple# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
Le fait est que Python utilise l'arrondi de banque au pair le plus proche , et PostgreSQL utilise mathématique (demi-hausse). Si les calculs et l'arrondi sont effectués dans PostgreSQL, il serait correct d'utiliser également l'arrondi mathématique dans les tests.Au début, j'ai décrit des ensembles de données avec des dates de naissance dans un format texte, mais il n'était pas pratique de lire un test dans ce format: chaque fois, je devais calculer l'âge de chaque habitant dans mon esprit afin de me rappeler ce qu'un ensemble de données particulier vérifiait. Bien sûr, vous pouviez vous en sortir avec les commentaires du code, mais j'ai décidé d'aller un peu plus loin et j'ai écrit une fonction age2datequi vous permet de décrire la date de naissance sous forme d'âge: le nombre d'années et de jours.Par exemple, comme ceciimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
Pour m'assurer que le gestionnaire distingue les résidents de déchargements différents, j'ai ajouté un déchargement supplémentaire avec un résident d'une autre ville: si le gestionnaire l'utilise par erreur, une ville supplémentaire apparaîtra dans les résultats et le test se cassera.Un fait intéressant: lorsque j'ai écrit ce test le 29 février 2020, j'ai soudainement cessé de générer des décharges avec les résidents en raison d'un bug dans Faker (2020 est une année bissextile, et d'autres années que Faker a choisies n'étaient pas toujours des années bissextiles aussi) n'était pas le 29 février). N'oubliez pas d'enregistrer les dates et de tester les cas limites!
Migrations
Le code de migration à première vue semble évident et le moins sujet aux erreurs, pourquoi le tester? Il s'agit d'une erreur très dangereuse: les erreurs de migration les plus insidieuses peuvent se manifester au moment le plus inopportun. Même s'ils ne gâchent pas les données, ils peuvent entraîner des temps d'arrêt inutiles.La migration initiale existante dans le projet modifie la structure de la base de données, mais ne modifie pas les données. Quelles erreurs courantes peuvent être protégées contre de telles migrations?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
La plupart de ces erreurs seront détectées par le test d'escalier . Son idée - d'utiliser une seule migration, effectuer systématiquement les méthodes upgrade, downgrade, upgradepour chaque migration. Un tel test suffit à être ajouté au projet une fois, il ne nécessite pas de support et servira fidèlement.Mais si la migration, en plus de la structure, modifiait les données, il faudrait alors écrire au moins un test distinct, en vérifiant que les données changent correctement dans la méthode upgradeet reviennent à l'état initial dans downgrade. Juste au cas où: un projet avec des exemples de tests de différentes migrations , que j'ai préparé pour un rapport sur Alembic à Moscou Python.Assemblée
L'artefact final que nous allons déployer et que nous voulons obtenir à la suite de l'assemblage est une image Docker. Pour construire, vous devez sélectionner l'image de base avec Python. L'image officielle python:latestpèse ~ 1 Go et, si elle est utilisée comme image de base, l'image avec l'application sera énorme. Il existe des images basées sur Alpine OS , dont la taille est beaucoup plus petite. Mais avec un nombre croissant de packages installés, la taille de l'image finale augmentera et, par conséquent, même l'image collectée sur la base d'Alpine ne sera pas si petite. J'ai choisi snakepacker / python comme image de base - elle pèse un peu plus que les images alpines, mais est basée sur Ubuntu, qui propose une vaste sélection de packages et de bibliothèques.Autrementréduire la taille de l'image avec l'application - n'incluez pas dans l'image finale le compilateur, les bibliothèques et les fichiers avec des en-têtes pour l'assemblage, qui ne sont pas nécessaires au fonctionnement de l'application.Pour ce faire, vous pouvez utiliser l' assemblage en plusieurs étapes de Docker:- À l'aide d'une image «lourde»
snakepacker/python:all(~ 1 Go, ~ 500 Mo compressés), créez un environnement virtuel, installez-y toutes les dépendances et le package d'application. Cette image est nécessaire exclusivement pour l'assemblage, elle peut contenir un compilateur, toutes les bibliothèques et fichiers nécessaires avec des en-têtes.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- Nous copions l'environnement virtuel fini dans une image «légère»
snakepacker/python:3.8(~ 100 Mo, compressée ~ 50 Mo), qui ne contient que l'interpréteur de la version requise de Python.
Important: dans un environnement virtuel, des chemins absolus sont utilisés, il doit donc être copié à la même adresse à laquelle il a été assemblé dans le conteneur collecteur.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Pour réduire le temps nécessaire à la création de l'image , les modules dépendants de l'application peuvent être installés avant d'être installés dans l'environnement virtuel. Docker les mettra en cache et ne réinstallera pas s'ils n'ont pas changé.Dockerfile entièrement
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Pour faciliter l'assemblage, j'ai ajouté une commande make uploadqui collecte l'image Docker et la télécharge sur hub.docker.com.Ci
Maintenant que le code est couvert de tests et que nous pouvons construire une image Docker, il est temps d'automatiser ces processus. La première chose qui vous vient à l'esprit: exécutez des tests pour créer des demandes de pool et, lorsque vous ajoutez des modifications à la branche principale, collectez une nouvelle image Docker et téléchargez-la sur le Docker Hub (ou les packages GitHub , si vous n'allez pas distribuer l'image publiquement).J'ai résolu ce problème avec les actions GitHub . Pour ce faire, il a fallu créer un fichier YAML dans un dossier .github/workflowset y décrire un workflow (avec deux tâches: testet publish), que j'ai nommé CI.La tâche testest exécutée à chaque démarrage du workflow CI, à l'aide de servicesrécupère un conteneur avec PostgreSQL, attend qu'il soit disponible et se lance pytestdans le conteneur snakepacker/python:all.La tâche publishn'est exécutée que si les modifications ont été ajoutées à la branche masteret si la tâche testa réussi. Il collecte la distribution source par le conteneur snakepacker/python:all, puis collecte et charge l'image Docker avec docker/build-push-action@v1.Description complète du workflowname: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Maintenant, lorsque vous ajoutez des modifications au maître dans l'onglet Actions sur GitHub, vous pouvez voir le lancement des tests, l'assemblage et le chargement de l'image Docker: Et lors de la création d'une demande de pool dans la branche principale, les résultats de la tâche y seront également affichés
Et lors de la création d'une demande de pool dans la branche principale, les résultats de la tâche y seront également affichés test:
Déployer
Pour déployer l'application sur le serveur fourni, vous devez installer Docker, Docker Compose, démarrer les conteneurs avec l'application et PostgreSQL et appliquer les migrations.Ces étapes peuvent être automatisées à l'aide du système de gestion de configuration d'Ansible. Il est écrit en Python, ne nécessite pas d'agents spéciaux (se connecte directement via ssh), utilise des modèles jinja et permet de décrire de manière déclarative l'état souhaité dans les fichiers YAML. L'approche déclarative vous permet de ne pas penser à l'état actuel du système et aux actions nécessaires pour amener le système à l'état souhaité. Tout ce travail repose sur les épaules des modules Ansible.Ansible vous permet de regrouper les tâches logiquement liées en rôles , puis de les réutiliser. Nous aurons besoin de deux rôles:docker(installe et configure Docker) et analyzer(installe et configure l'application).Le rôledocker ajoute un référentiel avec Docker au système, installe et configure les packages docker-ceet docker-compose.Vous pouvez éventuellement configurer l'API REST pour qu'elle reprenne automatiquement après un redémarrage du serveur. Ubuntu vous permet de résoudre ce problème à l'aide d'un système d'initialisation systemd. Il contrôle des unités représentant diverses ressources (démons, sockets, points de montage et autres). Pour ajouter une nouvelle unité à systemd, vous devez décrire sa configuration dans un fichier .service distinct et placer ce fichier dans l'un des dossiers spéciaux, par exemple, dans /etc/systemd/system. Ensuite, l'unité peut être lancée et activer le chargement automatique pour elle.Paquetdocker-celors de l'installation, il créera automatiquement un fichier avec la configuration de l'unité - il vous suffit de vous assurer qu'il est en cours d'exécution et qu'il s'allume au démarrage du système. Pour Docker Compose docker-compose@.servicesera créé par Ansible. Le symbole @dans le nom indique à systemd que l'unité est un modèle. Cela vous permet de démarrer le service docker-composeavec un paramètre - par exemple, avec le nom de notre service, qui sera remplacé à la place du %ifichier de configuration de l'unité:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
Le rôleanalyzer générera un fichier à partir du modèle docker-compose.ymlà l'adresse /etc/docker/compose/analyzer, enregistrera l'application en tant que service lancé automatiquement systemdet appliquera la migration. Lorsque les rôles sont prêts, vous devez décrire le playbook.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
La liste des hôtes, ainsi que les variables utilisées dans les rôles, peuvent être spécifiées dans le fichier d'inventaire hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
Une fois tous les fichiers Ansible prêts, exécutez-le:$ ansible-playbook -i hosts.ini deploy.yml
À propos des tests de résistance, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

Que peut-on faire d'autre?
Le profilage de l'application a montré qu'environ un quart du temps total d'exécution des requêtes est consacré à la sérialisation et à la désérialisation de JSON: de nombreuses données sont envoyées et reçues du service. Ces processus peuvent être considérablement accélérés à l'aide de la bibliothèque orjson , mais le service devra être un peu préparé - orjsonil ne s'agit pas d'un remplacement direct pour le module standard. jsonHabituellement, la production nécessite plusieurs copies du service pour garantir la tolérance aux pannes et faire face à la charge. Pour gérer un groupe de services, vous avez besoin d'un outil qui indique si une copie du service est "vivante". Ce problème peut être résolu par un gestionnaire /healthqui interroge toutes les ressources nécessaires au travail, dans notre cas, une base de données. SiSELECT 1exécuté en moins d'une seconde, puis le service est vivant. Sinon, vous devez y prêter attention.Lorsqu'une application fonctionne de manière très intensive avec un réseau, uvloop peut augmenter froidement les performances.Un facteur important est la lisibilité du code. Un de mes collègues, Yuri Shikanov, a écrit un module gris combinant plusieurs outils pour la vérification automatique et l'exécution de code, qui est facile à ajouter à un pre-commithook Git, mis en place avec un seul fichier de configuration ou des variables d'environnement. Gray vous permet de trier les importations ( isort ), optimise les expressions python en fonction des nouvelles versions du langage ( pyupgrade ), ajoute des virgules à la fin des appels de fonction, les importations, les listes, etc. (add-trailing-virgule ), ainsi que des guillemets à un seul formulaire ( unifier ).* * *
C'est tout pour moi: nous avons développé, couvert de tests, assemblé et déployé le service, et également effectué des tests de charge.Remerciements
Je voudrais exprimer ma profonde gratitude aux gars qui ont pris le temps de participer à la rédaction de cet article, de revoir le code, de présenter mes idées et commentaires: à Maria Zelenova zelma, Vladimir Solomatin leenr, Anastasia Semenova morkov, Yuri Shikanov dizballanze, Mikhail Shushpanov mishush, Pavel Mosein pavkazzz et surtout à Dmitry Orlov orlovdl.