L'informatique parallèle fascine par l'inattendu de son comportement. Mais le comportement conjoint des processus ne peut pas être imprévisible. Ce n'est que dans ce cas qu'il peut être étudié et compris dans ses caprices. La simultanéité multithread moderne est unique. Dans un sens littéral. Et c'est toute sa mauvaise essence. L'essence qui peut et doit être influencée. L'essence, qui aurait dû, dans le bon sens, avoir longtemps changé ...Bien qu'il existe une autre option. Il n'est pas nécessaire de changer quoi que ce soit et / ou d'influencer quelque chose. Qu'il y ait multithreading et coroutines, que ce soit ... et programmation automatique parallèle (AP). Laissez-les rivaliser et, si nécessaire et possible, complétez-vous. En ce sens, le parallélisme moderne a au moins un plus - il vous permet de le faire.Eh bien, rivalisons!?1. De série à parallèle
Envisagez de programmer l'équation arithmétique la plus simple:C2 = A + B + A1 + B1; (1)Soit des blocs qui implémentent des opérations arithmétiques simples. Dans ce cas, les blocs de sommation sont suffisants. Une idée claire et précise du nombre de blocs, de leur structure et des relations entre eux donne du riz. 1. Et sur la Fig. 2. la configuration du milieu VKP (a) est donnée pour résoudre l'équation (1).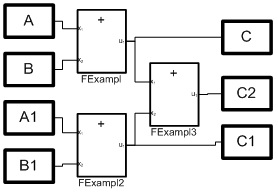 Fig. 1. Modèle structurel des processusMais le diagramme structurel de la figure 1 correspond à un système de trois équations:= A + B;C1 = A1 + B; (2)C2 = C + C1;En même temps (2), il s'agit d'une implémentation parallèle de l'équation (1), qui est un algorithme de sommation d'un tableau de nombres, également connu sous le nom d'algorithme de doublage. Ici, le tableau est représenté par quatre nombres A, B, A1, B1, les variables C et C1 sont des résultats intermédiaires et C2 est la somme du tableau.
Fig. 1. Modèle structurel des processusMais le diagramme structurel de la figure 1 correspond à un système de trois équations:= A + B;C1 = A1 + B; (2)C2 = C + C1;En même temps (2), il s'agit d'une implémentation parallèle de l'équation (1), qui est un algorithme de sommation d'un tableau de nombres, également connu sous le nom d'algorithme de doublage. Ici, le tableau est représenté par quatre nombres A, B, A1, B1, les variables C et C1 sont des résultats intermédiaires et C2 est la somme du tableau.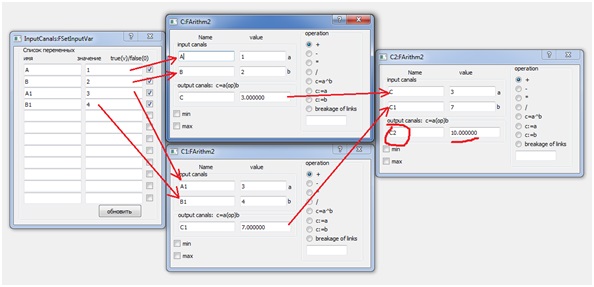 Fig.2. Type de boîtes de dialogue pour la configuration de trois processus parallèles.
Fig.2. Type de boîtes de dialogue pour la configuration de trois processus parallèles.
Les fonctionnalités d'implémentation incluent la continuité de son fonctionnement, lorsque tout changement dans les données d'entrée conduit à un recomptage du résultat. Après avoir modifié les données d'entrée, il faudra deux cycles d'horloge et lorsque les blocs seront connectés en série, le même effet sera obtenu en trois cycles d'horloge. Et plus la matrice est grande, plus le gain de vitesse est important.2. La concurrence comme problème
Ne soyez pas surpris si vous serez appelé de nombreux arguments en faveur de l'une ou l'autre solution parallèle, mais en même temps ils resteront silencieux sur les problèmes possibles qui sont complètement absents dans la programmation séquentielle ordinaire. La raison principale de l'interprétation similaire du problème de la mise en œuvre correcte du parallélisme. Ils en disent le moins sur elle. S'ils le disent du tout. Nous y reviendrons dans la partie relative à l'accès parallèle aux données.Tout processus peut être représenté comme autant d'étapes consécutives indivisibles. Pour de nombreux processus, à chacune de ces étapes, les actions appartenant à tous les processus sont exécutées simultanément. Et ici, nous pouvons très bien rencontrer un problème qui se manifeste dans l'exemple élémentaire suivant.Supposons qu'il existe deux processus parallèles qui correspondent au système d'équations suivant:c = a + b; (3)a = b + c;Supposons que les variables a, b, c reçoivent les valeurs initiales 1, 1, 0. Nous pouvons nous attendre à ce que le protocole de calcul pour les cinq étapes soit le suivant:a b c
1.000 1.000 0.000
1.000 1.000 2.000
3.000 1.000 2.000
3.000 1.000 4.000
5.000 1.000 4.000
5.000 1.000 6.000
Lors de sa formation, nous sommes partis du fait que les opérateurs sont exécutés en parallèle (simultanément) et au sein d'une mesure discrète (étape). Pour les instructions en boucle, ce sera une itération de la boucle. Nous pouvons également supposer que dans le processus de calcul, les variables ont des valeurs fixées au début d'une mesure discrète, et leur changement se produit à sa fin. Ceci est tout à fait cohérent avec la situation réelle, quand cela prend un certain temps pour terminer l'opération. Il est souvent associé à un retard inhérent à un bloc donné.Mais, très probablement, vous obtiendrez quelque chose comme ce protocole: a b c
1.000 1.000 0.000
3.000 1.000 2.000
5.000 1.000 4.000
7.000 1.000 6.000
9.000 1.000 8.000
11.000 1.000 10.000
Il équivaut au travail d'un processus exécutant deux instructions consécutives dans un cycle:c = a + b; a = b + c; (4)Mais il peut arriver que l'exécution des déclarations soit exactement l'inverse, et alors le protocole sera le suivant: a b c
1.000 1.000 0.000
1.000 1.000 2.000
3.000 1.000 4.000
5.000 1.000 6.000
7.000 1.000 8.000
9.000 1.000 10.000
Dans la programmation multi-thread, la situation est encore pire. En l'absence de synchronisation des processus, il est non seulement difficile de prévoir la séquence de lancement des opérateurs, mais leur travail sera également interrompu n'importe où. Tout cela ne peut qu'affecter les résultats du travail commun des opérateurs.Dans le cadre de la technologie AP, le travail avec des variables de processus communes est autorisé simplement et correctement. Ici, le plus souvent, aucun effort particulier n'est nécessaire pour synchroniser les processus et travailler avec les données. Mais il sera nécessaire de distinguer les actions qui seront considérées conditionnellement instantanées et indivisibles, ainsi que de créer des modèles de processus automatiques. Dans notre cas, les actions seront des opérateurs de sommation, et des automates à transitions cycliques seront responsables de leur lancement.Le listing 1 montre le code d'un processus qui implémente l'opération sum. Son modèle est une machine à états finis (voir figure 3) avec un état et une transition de boucle inconditionnelle, pour laquelle la seule action y1, ayant effectué l'opération de sommation de deux variables, place le résultat dans le troisième. Fig.3. Modèle automatisé de l'opération de sommation
Fig.3. Modèle automatisé de l'opération de sommationListing 1. Implémentation d'un processus automate pour une opération de somme#include "lfsaappl.h"
class FSumABC :
public LFsaAppl
{
public:
LFsaAppl* Create(CVarFSA *pCVF) { Q_UNUSED(pCVF)return new FSumABC(nameFsa); }
bool FCreationOfLinksForVariables();
FSumABC(string strNam);
CVar *pVarA;
CVar *pVarB;
CVar *pVarC;
CVar *pVarStrNameA;
CVar *pVarStrNameB;
CVar *pVarStrNameC;
protected:
void y1();
};
#include "stdafx.h"
#include "FSumABC.h"
static LArc TBL_SumABC[] = {
LArc("s1", "s1","--", "y1"),
LArc()
};
FSumABC::FSumABC(string strNam):
LFsaAppl(TBL_SumABC, strNam, nullptr, nullptr)
{ }
bool FSumABC::FCreationOfLinksForVariables() {
pVarA = CreateLocVar("a", CLocVar::vtBool, "variable a");
pVarB = CreateLocVar("b", CLocVar::vtBool, "variable c");
pVarC = CreateLocVar("c", CLocVar::vtBool, "variable c");
pVarStrNameA = CreateLocVar("strNameA", CLocVar::vtString, "");
string str = pVarStrNameA->strGetDataSrc();
if (str != "") { pVarA = pTAppCore->GetAddressVar(pVarStrNameA->strGetDataSrc().c_str(), this); }
pVarStrNameB = CreateLocVar("strNameB", CLocVar::vtString, "");
str = pVarStrNameB->strGetDataSrc();
if (str != "") { pVarB = pTAppCore->GetAddressVar(pVarStrNameB->strGetDataSrc().c_str(), this); }
pVarStrNameC = CreateLocVar("strNameC", CLocVar::vtString, "");
str = pVarStrNameC->strGetDataSrc();
if (str != "") { pVarC = pTAppCore->GetAddressVar(pVarStrNameC->strGetDataSrc().c_str(), this); }
return true;
}
void FSumABC::y1() {
pVarC->SetDataSrc(this, pVarA->GetDataSrc() + pVarB->GetDataSrc());
}
Important, voire plutôt nécessaire, voici l'utilisation des variables d'environnement du CPSU. Leurs «propriétés d'ombre» assurent l'interaction correcte des processus. De plus, l'environnement vous permet de changer le mode de son fonctionnement, à l'exclusion de l'enregistrement des variables dans la mémoire fantôme intermédiaire. Une analyse des protocoles obtenus dans ce mode nous permet de vérifier la nécessité d'utiliser des variables fantômes.3. Et les coroutines? ...
Ce serait bien de savoir comment les coroutines représentées par le langage Kotlin feront face à la tâche. Prenons comme modèle de solution le programme considéré dans la discussion de [1]. Il a une structure qui se réduit facilement à l'aspect recherché. Pour ce faire, remplacez-y les variables logiques par un type numérique et ajoutez une autre variable, et au lieu d'opérations logiques, nous utiliserons l'opération de sommation. Le code correspondant est indiqué dans la liste 2.Listing 2. Programme de sommation parallèle de Kotlinimport kotlinx.coroutines.*
suspend fun main() =
coroutineScope {
var a = 1
var b = 1
var c = 0;
withContext(Dispatchers.Default) {
for (i in 0..4) {
var res = listOf(async { a+b }, async{ b+c }).map { it.await() }
c = res[0]
a = res[1]
println("$a, $b, $c")
}
}
}
Il n'y a aucune question sur le résultat de ce programme, car il correspond exactement au premier des protocoles ci-dessus.Cependant, la conversion du code source n'était pas aussi évident que cela puisse paraître, car Il semblait naturel d'utiliser le fragment de code suivant:listOf(async { = a+b }, async{ = b+c })
Comme le montrent les tests (cela peut être fait en ligne sur le site Web de Kotlin - kotlinlang.org/#try-kotlin ), son utilisation conduit à un résultat complètement imprévisible, qui change également d'un lancement à l'autre. Et seule une analyse plus approfondie du programme source a conduit au code correct.Un code qui contient une erreur du point de vue du fonctionnement du programme, mais qui est légitime du point de vue de la langue, fait craindre pour la fiabilité des programmes dessus. Cette opinion peut probablement être contestée par les experts de Kotlin. Néanmoins, la facilité de se tromper, qui ne peut s'expliquer uniquement par un manque de compréhension de la «programmation coroutine», pousse néanmoins constamment à de telles conclusions.4. Machines d'événement dans Qt
Plus tôt, nous avons établi qu'un automate d'événement n'est pas un automate dans sa définition classique. Il est bon ou mauvais, mais dans une certaine mesure, la machine événementielle est toujours un parent des machines classiques. Est-ce éloigné, proche, mais il faut en parler directement pour qu'il n'y ait pas de fausses idées à ce sujet. Nous avons commencé à en parler dans [2], mais tous pour continuer. Nous allons maintenant le faire en examinant d'autres exemples d'utilisation de machines d'événements dans Qt.Bien entendu, un automate d'événement peut être considéré comme le cas dégénéré d'un automate classique à durée de cycle indéfinie et / ou variable associée à un événement. La possibilité d'une telle interprétation a été montrée dans un article précédent lors de la résolution d'un seul et, de plus, d'un exemple assez spécifique (voir détails [2]). Ensuite, nous essaierons d'éliminer cet écart.La bibliothèque Qt associe uniquement les transitions machine aux événements, ce qui constitue une sérieuse limitation. Par exemple, dans le même langage UML, une transition est associée non seulement à un événement appelé événement initiateur, mais également à une condition de protection - une expression logique calculée après la réception de l'événement [3]. Dans Matlab, la situation est atténuée de plus en sons comme ceci: « si le nom de l'événement n'est pas spécifié, la transition se produit lorsque tout événement se produit » [4]. Mais ici et là, la cause profonde de la transition est le ou les événements. Mais qu'en est-il s'il n'y a pas d'événements?S'il n'y a pas d'événements, alors ... vous pouvez essayer de les créer. Listing 3 et figure 4 montrent comment procéder, en utilisant le descendant de la classe d'automate LFsaAppl de l'environnement VKPa comme "wrapper" de l'événement Qt-class. Ici, l'action y2 avec une périodicité du temps discret de l'espace automate envoie un signal initiant le début de la transition de l'automate Qt. Ce dernier, à l'aide de la méthode s0Exited, démarre l'action y1, qui implémente l'opération de sommation. Notez que la machine événementielle est créée par l'action y3 strictement après avoir vérifié l'initialisation des variables locales de la classe LFsaAppl. Fig.4. Combinaison de machines classiques et événementielles
Fig.4. Combinaison de machines classiques et événementielles
Listing 3. Implémentation d'un modèle de sommation avec un automate d'événements#include "lfsaappl.h"
class QStateMachine;
class QState;
class FSumABC :
public QObject,
public LFsaAppl
{
Q_OBJECT
...
protected:
int x1();
void y1(); void y2(); void y3(); void y12();
signals:
void GoState();
private slots:
void s0Exited();
private:
QStateMachine * machine;
QState * s0;
};
#include "stdafx.h"
#include "FSumABC.h"
#include <QStateMachine>
#include <QState>
static LArc TBL_SumABC[] = {
LArc("st", "st","^x1", "y12"),
LArc("st", "s1","x1", "y3"),
LArc("s1", "s1","--", "y2"),
LArc()
};
FSumABC::FSumABC(string strNam):
QObject(),
LFsaAppl(TBL_SumABC, strNam, nullptr, nullptr)
{ }
...
int FSumABC::x1() { return pVarA&&pVarB&&pVarC; }
void FSumABC::y1() {
pVarC->SetDataSrc(this, pVarA->GetDataSrc() + pVarB->GetDataSrc());
}
void FSumABC::y2() { emit GoState(); }
void FSumABC::y3() {
s0 = new QState();
QSignalTransition *ps = s0->addTransition(this, SIGNAL(GoState()), s0);
connect (s0, SIGNAL(entered()), this, SLOT(s0Exited()));
machine = new QStateMachine(nullptr);
machine->addState(s0);
machine->setInitialState(s0);
machine->start();
}
void FSumABC::y12() { FInit(); }
void FSumABC::s0Exited() { y1(); }
Ci-dessus, nous avons implémenté une machine très simple. Ou, plus précisément, une combinaison d'automates classiques et d'événements. Si l'implémentation précédente de la classe FSumABC est remplacée par celle créée, il n'y aura tout simplement aucune différence dans l'application. Mais pour les modèles plus complexes, les propriétés limitées des automates événementiels commencent à se manifester pleinement. Au minimum, déjà en train de créer un modèle. Le listing 4 montre l'implémentation du modèle de l'élément AND-NOT sous la forme d'un automate d'événement (pour plus de détails sur le modèle d'automate utilisé de l'élément AND-NOT, voir [2]).Listing 4. Implémenter un modèle d'élément ET NON par une machine événementielle#include <QObject>
class QStateMachine;
class QState;
class MainWindow;
class ine : public QObject
{
Q_OBJECT
public:
explicit ine(MainWindow *parent = nullptr);
bool bX1, bX2, bY;
signals:
void GoS0();
void GoS1();
private slots:
void s1Exited();
void s0Exited();
private:
QStateMachine * machine;
QState * s0;
QState * s1;
MainWindow *pMain{nullptr};
friend class MainWindow;
};
#include "ine.h"
#include <QStateMachine>
#include <QState>
#include "mainwindow.h"
#include "ui_mainwindow.h"
ine::ine(MainWindow *parent) :
QObject(parent)
{
pMain = parent;
s0 = new QState();
s1 = new QState();
s0->addTransition(this, SIGNAL(GoS1()), s1);
s1->addTransition(this, SIGNAL(GoS0()), s0);
connect (s0, SIGNAL(entered()), this, SLOT(s0Exited()));
connect (s1, SIGNAL(entered()), this, SLOT(s1Exited()));
machine = new QStateMachine(nullptr);
machine->addState(s0);
machine->addState(s1);
machine->setInitialState(s1);
machine->start();
}
void ine::s1Exited() {
bY = !(bX1&&bX2);
pMain->ui->checkBoxY->setChecked(bY);
}
void ine::s0Exited() {
bY = !(bX1&&bX2);
pMain->ui->checkBoxY->setChecked(bY);
}
Il devient clair que les automates d'événements dans Qt sont strictement basés sur les automates de Moore. Cela limite les capacités et la flexibilité du modèle, les actions ne sont associées qu'aux états. Par conséquent, par exemple, il est impossible de distinguer entre deux transitions de l'état 0 à 1 pour l'automate représenté sur la Fig. 4 dans [2].Bien sûr, pour implémenter les Miles, vous pouvez utiliser la procédure bien connue pour passer aux machines Moore. Mais cela conduit à une augmentation du nombre d'états et élimine l'association simple, visuelle et utile des états du modèle avec le résultat de ses actions. Par exemple, après de telles transformations, l'état unique de la sortie du modèle 1 de [2] doit comparer deux états de l'automate Moore.Sur un modèle plus complexe, les problèmes liés aux conditions de transition commencent à apparaître avec évidence. Pour les contourner pour l'implémentation logicielle de l'élément AND-NOT considéré, une analyse de l'état des canaux d'entrée a été intégrée dans la boîte de dialogue de contrôle du modèle, comme indiqué dans le Listing 5.Listing 5. Boîte de dialogue de contrôle des éléments NAND#include "mainwindow.h"
#include "ui_mainwindow.h"
#include "ine.h"
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
pine = new ine(this);
connect(this, SIGNAL(GoState0()), pine, SIGNAL(GoS0()));
connect(this, SIGNAL(GoState1()), pine, SIGNAL(GoS1()));
}
MainWindow::~MainWindow()
{
delete ui;
}
void MainWindow::on_checkBoxX1_clicked(bool checked)
{
bX1 = checked;
pine->bX1 = bX1;
bY = !(bX1&&bX2);
if (!(bX1&&bX2)) emit GoState0();
else emit GoState1();
}
void MainWindow::on_checkBoxX2_clicked(bool checked)
{
bX2 = checked;
pine->bX2 = bX2;
bY = !(bX1&&bX2);
if (!(bX1&&bX2)) emit GoState0();
else emit GoState1();
}
En somme, tout ce qui précède complique clairement le modèle et crée des problèmes de compréhension de son travail. En outre, ces solutions locales peuvent ne pas fonctionner lorsque vous envisagez des compositions à partir de celles-ci. Un bon exemple dans ce cas serait une tentative de créer un modèle RS-trigger (pour plus de détails sur un modèle d'automate à deux composants d'un RS-trigger voir [5]). Cependant, le plaisir du résultat obtenu sera livré aux fans de machines événementielles. Si ... à moins, bien sûr, qu'ils réussissent;)5. Fonction quadratique et ... papillon?
Il est pratique de représenter les données d'entrée comme un processus parallèle externe. Au-dessus, il y avait la boîte de dialogue pour gérer le modèle d'un élément AND-NOT. De plus, le taux de changement des données peut affecter de manière significative le résultat. Pour le confirmer, nous considérons le calcul de la fonction quadratique y = ax² + bx + c, que nous implémentons sous la forme d'un ensemble de blocs fonctionnant en parallèle et interagissant.Le graphique d'une fonction quadratique a la forme d'une parabole. Mais la parabole représentée par le mathématicien et la parabole que l'oscilloscope, par exemple, affichera, à proprement parler, ne correspondra jamais. La raison en est que le mathématicien pense souvent en catégories instantanées, estimant qu'un changement dans la quantité d'entrée conduit immédiatement au calcul de la fonction. Mais dans la vraie vie, ce n'est pas du tout vrai. L'apparence du graphique de fonction dépendra de la vitesse de la calculatrice, du taux de changement des données d'entrée, etc. etc. Oui, et les programmes eux-mêmes pour la vitesse peuvent différer les uns des autres. Ces facteurs affecteront la forme de la fonction, sous la forme de laquelle, dans une certaine situation, il sera difficile de deviner la parabole. Nous en serons convaincus davantage.Ainsi, nous ajoutons au bloc sommateur les blocs de multiplication, division et exponentiation. Avec un tel ensemble, nous pouvons «collecter» des expressions mathématiques de toute complexité. Mais nous pouvons également avoir des «cubes» qui implémentent des fonctions plus complexes. Fig.5. la mise en œuvre d'une fonction quadratique est représentée en deux versions - multi-bloc (voir flèche avec une étiquette - 1, et aussi Fig. 6) et une variante d'un bloc (sur la Fig. 5 flèche avec une étiquette 2). Fig.5. Deux options pour implémenter la fonction quadratique
Fig.5. Deux options pour implémenter la fonction quadratique Fig.6. Modèle structurel pour calculer une fonction quadratiqueCelui de la fig.5. elle semble "floue" (voir flèche marquée 3), lorsqu'elle est correctement agrandie (voir graphiques (tendances), marquée 4), elle est convaincue que la matière n'est pas dans les propriétés graphiques. Ceci est le résultat de l'influence du temps sur le calcul des variables: la variable y1 est la valeur de sortie de la variante multibloc (couleur rouge du graphique) et la variable y2 est la valeur de sortie de la variante monobloc (couleur noire). Mais ces deux graphiques sont différents des "graphiques abstraits" [y2 (t), x (t-1)] (vert). Cette dernière est construite pour la valeur de la variable y2 et la valeur de la variable d'entrée retardée d'un cycle d'horloge (voir la variable avec le nom x [t-1]).Ainsi, plus le taux de variation de la fonction d'entrée x (t) est élevé, plus «l'effet de flou» sera fort et plus les graphiques y1, y2 seront éloignés du graphique [y2 (t), x (t-1)]. Le "défaut" détecté peut être utilisé à vos propres fins. Par exemple, rien ne nous empêche d'appliquer un signal sinusoïdal à l'entrée. Nous considérerons une option encore plus compliquée, lorsque le premier coefficient de l'équation change également de manière similaire. Le résultat de l'expérience montre un écran du milieu VKPa, montré sur la Fig. 7.
Fig.6. Modèle structurel pour calculer une fonction quadratiqueCelui de la fig.5. elle semble "floue" (voir flèche marquée 3), lorsqu'elle est correctement agrandie (voir graphiques (tendances), marquée 4), elle est convaincue que la matière n'est pas dans les propriétés graphiques. Ceci est le résultat de l'influence du temps sur le calcul des variables: la variable y1 est la valeur de sortie de la variante multibloc (couleur rouge du graphique) et la variable y2 est la valeur de sortie de la variante monobloc (couleur noire). Mais ces deux graphiques sont différents des "graphiques abstraits" [y2 (t), x (t-1)] (vert). Cette dernière est construite pour la valeur de la variable y2 et la valeur de la variable d'entrée retardée d'un cycle d'horloge (voir la variable avec le nom x [t-1]).Ainsi, plus le taux de variation de la fonction d'entrée x (t) est élevé, plus «l'effet de flou» sera fort et plus les graphiques y1, y2 seront éloignés du graphique [y2 (t), x (t-1)]. Le "défaut" détecté peut être utilisé à vos propres fins. Par exemple, rien ne nous empêche d'appliquer un signal sinusoïdal à l'entrée. Nous considérerons une option encore plus compliquée, lorsque le premier coefficient de l'équation change également de manière similaire. Le résultat de l'expérience montre un écran du milieu VKPa, montré sur la Fig. 7. Fig. 7. Résultats de la simulation avec un signal d'entrée sinusoïdalL'écran en bas à gauche montre le signal fourni aux entrées de réalisations d'une fonction quadratique. Au-dessus se trouvent les graphiques des valeurs de sortie y1 et y2. Les graphiques sous forme d '«ailes» sont des valeurs tracées en deux coordonnées. Ainsi, à l'aide de diverses réalisations de la fonction quadratique, nous avons dessiné la moitié du «papillon». Dessiner un tout est une question de technologie ...Mais les paradoxes du parallélisme ne s'arrêtent pas là. En figue. La figure 8 montre les tendances du changement «inverse» de la variable indépendante x. Ils passent déjà à gauche du graphe "abstrait" (ce dernier, notons-le, n'a pas changé de position!).
Fig. 7. Résultats de la simulation avec un signal d'entrée sinusoïdalL'écran en bas à gauche montre le signal fourni aux entrées de réalisations d'une fonction quadratique. Au-dessus se trouvent les graphiques des valeurs de sortie y1 et y2. Les graphiques sous forme d '«ailes» sont des valeurs tracées en deux coordonnées. Ainsi, à l'aide de diverses réalisations de la fonction quadratique, nous avons dessiné la moitié du «papillon». Dessiner un tout est une question de technologie ...Mais les paradoxes du parallélisme ne s'arrêtent pas là. En figue. La figure 8 montre les tendances du changement «inverse» de la variable indépendante x. Ils passent déjà à gauche du graphe "abstrait" (ce dernier, notons-le, n'a pas changé de position!). Figure. 8. Le type de graphiques avec changement linéaire direct et inverse du signal d'entréeDans cet exemple, l'erreur «double» du signal de sortie par rapport à sa valeur «instantanée» devient apparente. Et plus le système informatique est lent ou plus la fréquence du signal est élevée, plus l'erreur est importante. Une onde sinusoïdale est un exemple de changement direct et inverse d'un signal d'entrée. Pour cette raison, les «ailes» de la figure 4 ont pris cette forme. Sans l'effet «d'erreur en arrière», ils seraient deux fois plus étroits.
Figure. 8. Le type de graphiques avec changement linéaire direct et inverse du signal d'entréeDans cet exemple, l'erreur «double» du signal de sortie par rapport à sa valeur «instantanée» devient apparente. Et plus le système informatique est lent ou plus la fréquence du signal est élevée, plus l'erreur est importante. Une onde sinusoïdale est un exemple de changement direct et inverse d'un signal d'entrée. Pour cette raison, les «ailes» de la figure 4 ont pris cette forme. Sans l'effet «d'erreur en arrière», ils seraient deux fois plus étroits.6. Contrôleur PID adaptatif
Prenons un exemple de plus sur lequel les problèmes considérés sont présentés. En figue. La figure 9 montre la configuration du support VKP (a) lors de la modélisation d'un contrôleur PID adaptatif. Un schéma de principe est également illustré dans lequel le contrôleur PID est représenté par une unité nommée PID. Au niveau de la boîte noire, elle est similaire à l'implémentation monobloc précédemment considérée d'une fonction quadratique.Le résultat de la comparaison des résultats du calcul du modèle de contrôleur PID dans un certain package mathématique et du protocole obtenu à partir des résultats de la simulation dans l'environnement VKP (a) est illustré sur la figure 10, où le graphique rouge représente les valeurs calculées et le graphique bleu représente le protocole. La raison de leur non-concordance est que le calcul dans le cadre du progiciel mathématique, comme le montre une analyse plus approfondie, correspond au fonctionnement séquentiel des objets lorsqu'ils établissent pour la première fois le contrôleur PID et s'arrêtent, puis le modèle de l'objet, etc. dans la boucle. L'environnement VKPa implémente / modélise le fonctionnement parallèle d'objets en fonction de la situation réelle, lorsque le modèle et l'objet fonctionnent en parallèle. Fig.9. Mise en œuvre du contrôleur PID
Fig.9. Mise en œuvre du contrôleur PID Fig.10. Comparaison des valeurs calculées avec les résultats de simulation du contrôleur PIDComme, comme nous l'avons déjà annoncé, il existe dans VKP (a) un mode de simulation du fonctionnement séquentiel des blocs structurels, il n'est pas difficile de vérifier l'hypothèse d'un mode de calcul séquentiel du contrôleur PID. En changeant le mode de fonctionnement du support en série, nous obtenons la coïncidence des graphiques, comme le montre la figure 11.
Fig.10. Comparaison des valeurs calculées avec les résultats de simulation du contrôleur PIDComme, comme nous l'avons déjà annoncé, il existe dans VKP (a) un mode de simulation du fonctionnement séquentiel des blocs structurels, il n'est pas difficile de vérifier l'hypothèse d'un mode de calcul séquentiel du contrôleur PID. En changeant le mode de fonctionnement du support en série, nous obtenons la coïncidence des graphiques, comme le montre la figure 11. Fig.11. Fonctionnement séquentiel du contrôleur PID et de l'objet de contrôle
Fig.11. Fonctionnement séquentiel du contrôleur PID et de l'objet de contrôle
7. Conclusions
Dans le cadre du CPSU (a), le modèle de calcul confère aux programmes des propriétés caractéristiques des vrais objets "vivants". D'où l'association figurative avec les «mathématiques vivantes». Comme le montre la pratique, nous, dans les modèles, sommes simplement obligés de prendre en compte ce qui ne peut être ignoré dans la vie réelle. Dans le calcul parallèle, c'est principalement le temps et la finitude des calculs. Bien sûr, sans oublier l'adéquation du modèle mathématique [automatique] à l'un ou l'autre objet «vivant».Il est impossible de combattre ce qui ne peut être vaincu. Il est temps. Cela n'est possible que dans un conte de fées. Mais il est logique d'en tenir compte et / ou même de l'utiliser à vos propres fins. Dans la programmation parallèle moderne, ignorer le temps entraîne de nombreux problèmes difficiles à contrôler et détectés - course aux signaux, processus de blocage, problèmes de synchronisation, etc. etc. La technologie VKP (a) est largement exempte de tels problèmes simplement parce qu'elle inclut un modèle en temps réel et prend en compte la finitude des processus informatiques. Il contient ce que la plupart de ses analogues sont simplement ignorés.En conclusion. Les papillons sont des papillons, mais vous pouvez, par exemple, envisager un système d'équations de fonctions quadratiques et linéaires. Pour ce faire, il suffit d'ajouter au modèle déjà créé un modèle de fonction linéaire et un processus qui contrôle leur coïncidence. La solution sera donc trouvée par modélisation. Elle ne sera probablement pas aussi précise qu'analytique, mais elle sera obtenue plus simplement et plus rapidement. Et dans de nombreux cas, c'est plus que suffisant. Et trouver une solution analytique est, en règle générale, souvent une question ouverte.Dans le cadre de ce dernier, les AVM ont été rappelés. Pour ceux qui ne sont pas à jour ou qui ont oublié, - les ordinateurs analogiques. Les principes structurels sont en général de nombreux, et l'approche pour trouver une solution.application
1) Vidéo : youtu.be/vf9gNBAmOWQ2) Archive d'exemples : github.com/lvs628/FsaHabr/blob/master/FsaHabr.zip .3) Archive des bibliothèques de dll Qt nécessaires version 5.11.2 : github.com/lvs628/FsaHabr/blob/master/QtDLLs.zipDes exemples sont développés dans l'environnement Windows 7. Pour les installer, ouvrez l'archive d'exemples et si vous n'avez pas Qt installé ou la version actuelle de Qt est différente de la version 5.11.2, puis ouvrez en plus l'archive Qt et écrivez le chemin d'accès aux bibliothèques dans la variable d'environnement Path. Ensuite, exécutez \ FsaHabr \ VCPaMain \ release \ FsaHabr.exe et utilisez la boîte de dialogue pour sélectionner le répertoire de configuration d'un exemple, par exemple, \ FsaHabr \ 9.ParallelOperators \ Heading1 \ Pict1.C2 = A + B + A1 + B1 \ (voir aussi vidéo).Commentaire. Au premier démarrage, au lieu de la boîte de dialogue de sélection de répertoire, une boîte de dialogue de sélection de fichier peut apparaître. Nous sélectionnons également le répertoire de configuration et certains fichiers qu'il contient, par exemple, vSetting.txt. Si la boîte de dialogue de sélection de configuration n'apparaît pas du tout, avant de commencer, supprimez le fichier ConfigFsaHabr.txt dans le répertoire où se trouve le fichier FsaHabr.exe.
Afin de ne pas répéter la sélection de configuration dans la boîte de dialogue «noyau: espaces automatiques» (elle peut être ouverte à l'aide de l'élément de menu: Outils FSA / Gestion de l'espace / Gestion), cliquez sur le bouton «mémoriser le chemin du répertoire» et décochez «afficher la boîte de dialogue de sélection de configuration au démarrage ". À l'avenir, pour sélectionner une configuration différente, ce choix devra être défini à nouveau.Littérature
1. NPS, convoyeur, calcul automatique, et encore ... coroutines. [Ressource électronique], Mode d'accès: habr.com/en/post/488808 gratuit. Yaz. russe (date du traitement 22.02.2020).2. Les machines automatiques sont-elles un événement? [Ressource électronique], Mode d'accès: habr.com/en/post/483610 gratuit. Yaz. russe (date du traitement 22.02.2020).3. BUCH G., RAMBO J., JACOBSON I. UML. Manuel d'utilisation. Deuxième édition. IT Academy: Moscou, 2007 .-- 493 p.4. Rogachev G.N. Stateflow V5. Manuel d'utilisation. [Ressource électronique], Mode d'accès: bourabai.kz/cm/stateflow.htm gratuit. Yaz. russe (date de diffusion 10.04.2020).5.Modèle de calcul parallèle [Ressource électronique], Mode d'accès: habr.com/en/post/486622 gratuit. Yaz. russe (date de diffusion 04/11/2020).