 L'effet des tables et des index de ballonnement (ballonnement) est largement connu et n'est pas seulement présent dans Postgres. Il existe des moyens de le traiter «prêt à l'emploi» comme VACUUM FULL ou CLUSTER, mais ils verrouillent les tables pendant le fonctionnement et ne peuvent donc pas toujours être utilisés.L'article contiendra un peu de théorie sur la façon dont le ballonnement se produit, comment y faire face, sur les contraintes différées et les problèmes qu'ils posent à l'utilisation de l'extension pg_repack.Cet article est basé sur ma présentation à PgConf.Russia 2020.
L'effet des tables et des index de ballonnement (ballonnement) est largement connu et n'est pas seulement présent dans Postgres. Il existe des moyens de le traiter «prêt à l'emploi» comme VACUUM FULL ou CLUSTER, mais ils verrouillent les tables pendant le fonctionnement et ne peuvent donc pas toujours être utilisés.L'article contiendra un peu de théorie sur la façon dont le ballonnement se produit, comment y faire face, sur les contraintes différées et les problèmes qu'ils posent à l'utilisation de l'extension pg_repack.Cet article est basé sur ma présentation à PgConf.Russia 2020.Pourquoi le ballonnement se produit
Postgres est basé sur le modèle multi-version ( MVCC ). Son essence est que chaque ligne du tableau peut avoir plusieurs versions, tandis que les transactions ne voient pas plus d'une de ces versions, mais pas nécessairement la même. Cela permet à plusieurs transactions de fonctionner simultanément et de n'avoir pratiquement aucun effet les unes sur les autres.Évidemment, toutes ces versions doivent être stockées. Postgres fonctionne avec la mémoire page par page et la page est la quantité minimale de données pouvant être lues ou écrites sur le disque. Regardons un petit exemple pour comprendre comment cela se produit.Supposons que nous ayons une table dans laquelle nous avons ajouté plusieurs enregistrements. Dans la première page du fichier où la table est stockée, de nouvelles données sont apparues. Ce sont des versions en direct de chaînes qui sont disponibles pour d'autres transactions après une validation (pour plus de simplicité, nous supposerons que le niveau d'isolement de lecture validée).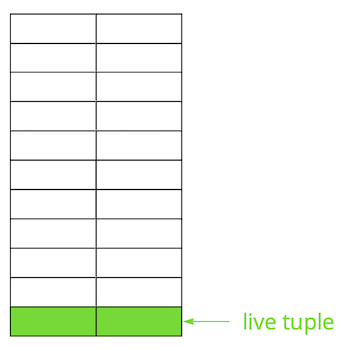 Ensuite, nous avons mis à jour l'une des entrées et marqué ainsi l'ancienne version comme non pertinente.
Ensuite, nous avons mis à jour l'une des entrées et marqué ainsi l'ancienne version comme non pertinente.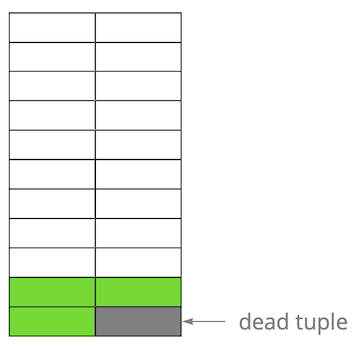 Étape par étape, en mettant à jour et en supprimant la version des lignes, nous avons obtenu une page dans laquelle environ la moitié des données sont des «ordures». Ces données ne sont visibles par aucune transaction.
Étape par étape, en mettant à jour et en supprimant la version des lignes, nous avons obtenu une page dans laquelle environ la moitié des données sont des «ordures». Ces données ne sont visibles par aucune transaction.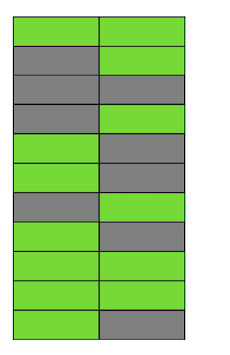 Postgres dispose d'un mécanisme à VIDE, qui nettoie les versions non pertinentes et libère de l'espace pour les nouvelles données. Mais s'il n'est pas configuré de manière suffisamment agressive ou s'il est occupé à travailler dans d'autres tables, alors les «données indésirables» restent et nous devons utiliser des pages supplémentaires pour les nouvelles données.Donc, dans notre exemple, à un moment donné, le tableau comprendra quatre pages, mais il ne contiendra que la moitié des données en direct. Par conséquent, lors de l'accès à la table, nous lirons beaucoup plus de données que nécessaire.
Postgres dispose d'un mécanisme à VIDE, qui nettoie les versions non pertinentes et libère de l'espace pour les nouvelles données. Mais s'il n'est pas configuré de manière suffisamment agressive ou s'il est occupé à travailler dans d'autres tables, alors les «données indésirables» restent et nous devons utiliser des pages supplémentaires pour les nouvelles données.Donc, dans notre exemple, à un moment donné, le tableau comprendra quatre pages, mais il ne contiendra que la moitié des données en direct. Par conséquent, lors de l'accès à la table, nous lirons beaucoup plus de données que nécessaire.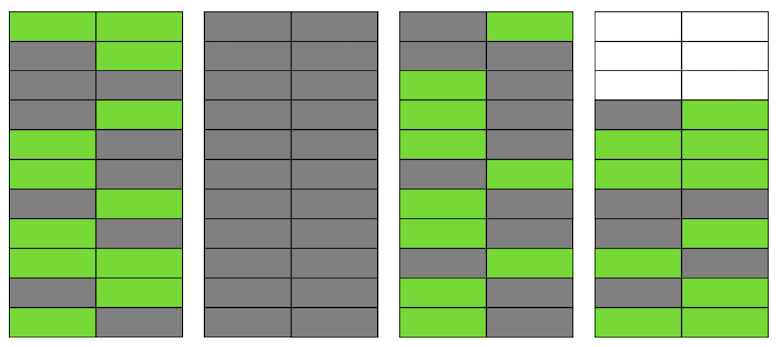 Même si VACUUM supprime désormais toutes les versions non pertinentes des chaînes, la situation ne s'améliorera pas de façon spectaculaire. Nous aurons de l'espace libre dans les pages ou même des pages entières pour les nouvelles lignes, mais nous continuerons à lire plus de données que nécessaire.Soit dit en passant, si une page complètement vierge (la seconde dans notre exemple) se trouvait à la fin du fichier, alors VACUUM pourrait la couper. Mais maintenant, elle est au milieu, donc rien ne peut être fait avec elle.
Même si VACUUM supprime désormais toutes les versions non pertinentes des chaînes, la situation ne s'améliorera pas de façon spectaculaire. Nous aurons de l'espace libre dans les pages ou même des pages entières pour les nouvelles lignes, mais nous continuerons à lire plus de données que nécessaire.Soit dit en passant, si une page complètement vierge (la seconde dans notre exemple) se trouvait à la fin du fichier, alors VACUUM pourrait la couper. Mais maintenant, elle est au milieu, donc rien ne peut être fait avec elle.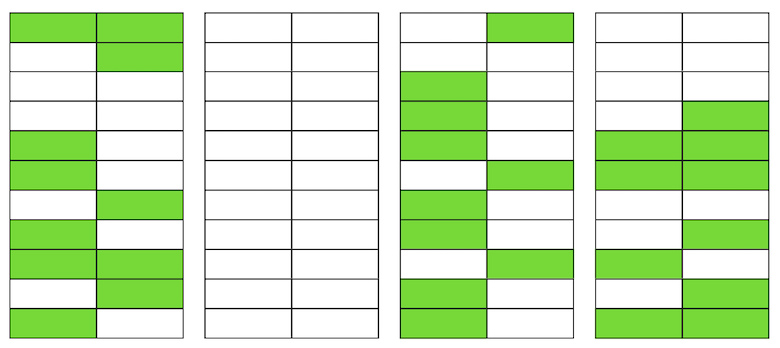 Lorsque le nombre de ces pages vierges ou très plates devient important, ce qui est appelé ballonnement, il commence à affecter les performances.Tout ce qui est décrit ci-dessus est la mécanique de l'occurrence de ballonnement dans les tableaux. Dans les index, cela se produit de la même manière.
Lorsque le nombre de ces pages vierges ou très plates devient important, ce qui est appelé ballonnement, il commence à affecter les performances.Tout ce qui est décrit ci-dessus est la mécanique de l'occurrence de ballonnement dans les tableaux. Dans les index, cela se produit de la même manière.Dois-je un ballonnement?
Il existe plusieurs façons de déterminer si vous avez un ballonnement. L'idée de la première est d'utiliser des statistiques Postgres internes, qui contiennent des informations approximatives sur le nombre de lignes dans les tableaux, le nombre de lignes «live», etc. Sur Internet, vous pouvez trouver de nombreuses variantes de scripts prêts à l'emploi. Nous avons pris comme base un script des experts PostgreSQL, qui peut évaluer les tables de gonflement ainsi que les index de toast et de btree de ballonnement. D'après notre expérience, son erreur est de 10-20%.Une autre façon est d'utiliser l'extension pgstattuple , qui vous permet de regarder à l'intérieur des pages et d'obtenir des valeurs de ballonnement estimées et précises. Mais dans le deuxième cas, vous devez scanner la table entière.Une petite valeur de ballonnement, jusqu'à 20%, nous considérons acceptable. Il peut être considéré comme un analogue de fillfactor pour les tableaux et les index . À 50% et plus, des problèmes de performances peuvent commencer.Façons de faire face au ballonnement
Il existe plusieurs façons de traiter les ballonnements hors de la boîte à Postgres, mais ils sont loin d'être toujours adaptés à tout le monde.Réglez AUTOVACUUM pour éviter les ballonnements . Et plus précisément, pour le maintenir à un niveau acceptable pour vous. Cela semble être le conseil du «capitaine», mais en réalité ce n'est pas toujours facile à réaliser. Par exemple, vous développez activement des modifications régulières du schéma de données ou une sorte de migration de données se produit. Par conséquent, votre profil de charge peut changer fréquemment et, en règle générale, il peut être différent pour différentes tables. Cela signifie que vous devez constamment travailler un peu en avant de la courbe et ajuster AUTOVACUUM au profil changeant de chaque table. Mais il est évident que ce n'est pas facile.Une autre raison courante pour laquelle AUTOVACUUM n'a pas le temps de traiter les tables est la présence de longues transactions qui l'empêchent d'effacer les données car elles sont disponibles pour ces transactions. La recommandation ici est également évidente - se débarrasser des transactions suspendues et minimiser le temps des transactions actives. Mais si la charge de votre application est un hybride OLAP et OLTP, vous pouvez en même temps avoir de nombreuses mises à jour fréquentes et de courtes demandes, ainsi que de longues opérations - par exemple, la création d'un rapport. Dans une telle situation, il convient de penser à répartir la charge sur différentes bases, ce qui permettra un réglage plus fin de chacune d'entre elles.Un autre exemple - même si le profil est uniforme, mais la base de données est sous une charge très élevée, même l'AUTOVACUUM le plus agressif peut ne pas faire face, et un ballonnement se produira. La mise à l'échelle (verticale ou horizontale) est la seule solution.Mais qu'en est-il de la situation lorsque vous avez configuré AUTOVACUUM, mais le ballonnement continue de croître.Commande VACUUM FULLreconstruit le contenu des tables et des index et n'y laisse que des données pertinentes. Pour éliminer les ballonnements, cela fonctionne parfaitement, mais lors de son exécution, un verrou exclusif sur la table (AccessExclusiveLock) est capturé, ce qui ne permettra pas les requêtes sur cette table, même les sélections. Si vous pouvez vous permettre d'arrêter votre service ou une partie de celui-ci pendant un certain temps (de plusieurs dizaines de minutes à plusieurs heures, selon la taille de la base de données et de votre matériel), cette option est la meilleure. Malheureusement, nous n'avons pas le temps d'exécuter VACUUM FULL pendant la maintenance planifiée, donc cette méthode ne nous convient pas.Commande CLUSTERil reconstruit également le contenu des tables, comme le fait VACUUM FULL, en même temps il vous permet de spécifier l'index selon lequel les données seront physiquement ordonnées sur le disque (mais à l'avenir, l'ordre n'est pas garanti). Dans certaines situations, il s'agit d'une bonne optimisation pour un certain nombre de requêtes - avec la lecture de plusieurs enregistrements par index. L'inconvénient de la commande est le même que celui de VACUUM FULL - elle verrouille la table pendant le fonctionnement.La commande REINDEX est similaire aux deux précédentes, mais reconstruit un index spécifique ou tous les index de la table. Les verrous sont légèrement plus faibles: ShareLock sur la table (empêche les modifications, mais vous permet de sélectionner) et AccessExclusiveLock sur l'index reconstructible (bloque les requêtes utilisant cet index). Cependant, dans la version 12 de Postgres, le paramètre CONCURRENTLY, qui vous permet de reconstruire l'index sans bloquer l'ajout, la modification ou la suppression parallèles d'enregistrements.Dans les versions antérieures de Postgres, vous pouvez obtenir un résultat similaire à REINDEX CONCURRENTLY avec CREATE INDEX CONCURRENTLY . Il vous permet de créer un index sans blocage strict (ShareUpdateExclusiveLock, qui n'interfère pas avec les requêtes parallèles), puis de remplacer l'ancien index par un nouveau et de supprimer l'ancien index. Cela élimine les index de ballonnement sans interférer avec votre application. Il est important de considérer que lors de la reconstruction des index, il y aura une charge supplémentaire sur le sous-système de disque.Ainsi, s'il existe des moyens pour les index d'éliminer le gonflement «à chaud», alors pour les tables il n'y en a pas. Ici, diverses extensions externes entrent en jeu : pg_repack(anciennement pg_reorg), pgcompact , pgcompacttable et autres. Dans le cadre de cet article, je ne les comparerai pas et ne parlerai que de pg_repack, que, après quelques raffinements, nous utilisons chez nous.Fonctionnement de pg_repack
Supposons que nous ayons une table très normale pour nous - avec des index, des restrictions et, malheureusement, avec des ballonnements. La première étape est que pg_repack crée une table de journal pour stocker les données sur toutes les modifications pendant le fonctionnement. Le déclencheur répliquera ces modifications à chaque insertion, mise à jour et suppression. Ensuite, une table est créée qui est similaire à la structure d'origine, mais sans index et restrictions, afin de ne pas ralentir le processus d'insertion des données.Ensuite, pg_repack transfère les données de l'ancienne à la nouvelle table, filtrant automatiquement toutes les lignes non pertinentes, puis crée des index pour la nouvelle table. Pendant l'exécution de toutes ces opérations, les modifications sont accumulées dans la table des journaux.L'étape suivante consiste à transférer les modifications dans la nouvelle table. La migration est effectuée en plusieurs itérations, et lorsqu'il reste moins de 20 entrées dans la table des journaux, pg_repack capture un verrou strict, transfère les dernières données et remplace l'ancienne table par la nouvelle dans les tables système Postgres. Il s'agit du seul et très court moment où vous ne pouvez pas travailler avec la table. Après cela, l'ancienne table et la table avec les journaux sont supprimées et l'espace est libéré dans le système de fichiers. Le processus est terminé.En théorie, tout a l'air bien, qu'en pratique? Nous avons testé pg_repack sans charge et sous charge, nous avons vérifié son fonctionnement en cas d'arrêt prématuré (en d'autres termes, Ctrl + C). Tous les tests étaient positifs.Nous sommes allés au prod - et puis tout s'est mal passé comme prévu.La première crêpe sur prod
Sur le premier cluster, nous avons reçu une erreur concernant la violation d'une restriction unique:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Cette restriction avait le nom généré automatiquement index_16508 - il a été créé par pg_repack. Par les attributs inclus dans sa composition, nous avons déterminé «notre» restriction, qui lui correspond. Le problème s'est avéré que ce n'est pas une restriction tout à fait ordinaire, mais une contrainte différée , c'est-à-dire sa vérification est effectuée plus tard que la commande sql, ce qui entraîne des conséquences inattendues.Contraintes différées: pourquoi sont-elles nécessaires et comment fonctionnent-elles?
Un peu de théorie sur les contraintes différées.Prenons un exemple simple: nous avons une table de référence de voiture avec deux attributs - le nom et l'ordre de la voiture dans le répertoire.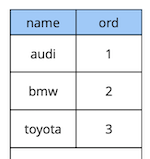
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Disons que nous devions échanger les première et deuxième voitures. La solution "au front" est de mettre à jour la première valeur à la seconde, et la seconde à la première:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Mais lors de l'exécution de ce code, nous attendons probablement une violation de la contrainte, car l'ordre des valeurs dans la table est unique:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
Comment faire autrement? Première option: ajoutez un remplacement supplémentaire de la valeur par une commande dont il est garanti qu'elle n'existe pas dans le tableau, par exemple, «-1». En programmation, cela s'appelle «échanger les valeurs de deux variables à travers la troisième». Le seul inconvénient de cette méthode est la mise à jour supplémentaire.Deuxième option: reconcevoir la table pour utiliser un type de données à virgule flottante pour la valeur de commande au lieu d'entiers Ensuite, lors de la mise à jour de la valeur de 1, par exemple, à 2,5, le premier enregistrement «se lèvera» automatiquement entre le deuxième et le troisième. Cette solution fonctionne, mais il existe deux limitations. Premièrement, cela ne fonctionnera pas pour vous si la valeur est utilisée quelque part dans l'interface. Deuxièmement, selon la précision du type de données, vous aurez un nombre limité d'insertions possibles avant de recalculer les valeurs de tous les enregistrements.Troisième option: reporter la restriction afin qu'elle ne soit vérifiée qu'au moment de la validation:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
Étant donné que la logique de notre demande initiale garantit que toutes les valeurs sont uniques au moment de la validation, elle réussira.L'exemple ci-dessus est, bien sûr, très synthétique, mais il révèle l'idée. Dans notre application, nous utilisons des contraintes différées pour implémenter une logique responsable de la résolution des conflits tout en travaillant simultanément avec des objets widgets communs sur la carte. L'utilisation de telles restrictions nous permet de rendre le code d'application un peu plus facile.En général, selon le type de contrainte dans Postgres, il existe trois niveaux de granularité pour les vérifier: niveau de ligne, transaction et expression.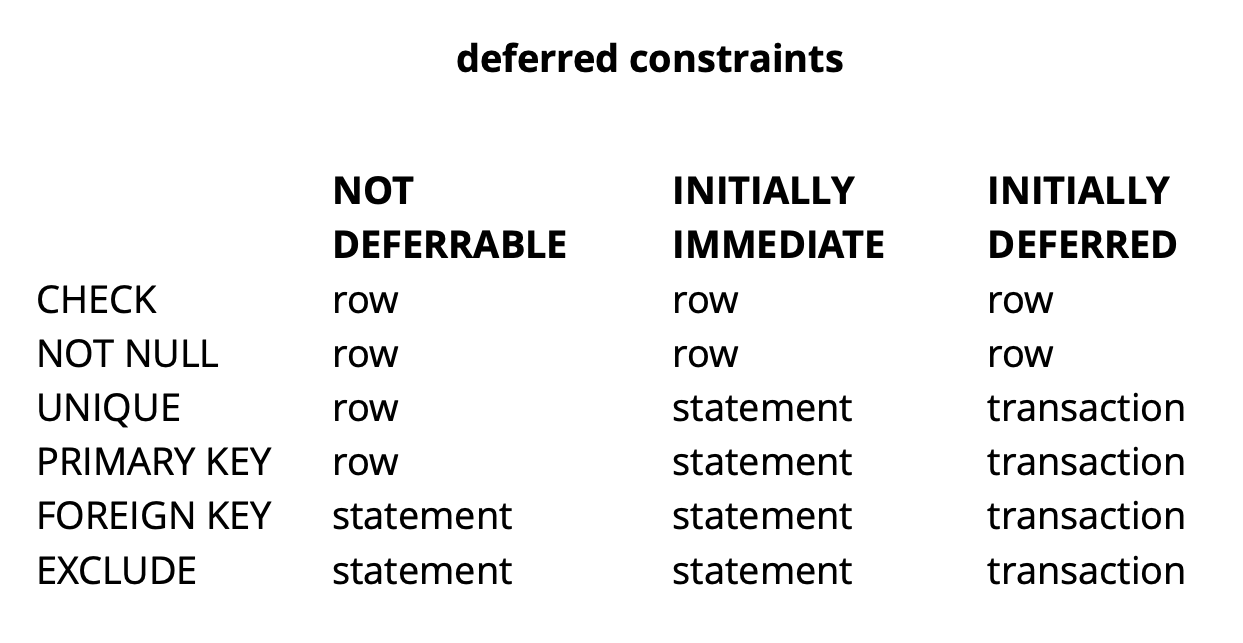 Source: begriffsCHECK et NOT NULL sont toujours vérifiés au niveau de la ligne, pour d'autres restrictions, comme le montre le tableau, il existe différentes options. En savoir plus ici .Pour résumer brièvement, les restrictions en attente dans certaines situations donnent un code plus lisible et moins de commandes. Cependant, vous devez payer pour cela en compliquant le processus de débogage, car le moment où l'erreur s'est produite et le moment où vous l'avez découvert sont séparés dans le temps. Un autre problème possible est que le planificateur ne peut pas toujours construire le plan optimal si une contrainte retardée est impliquée dans la demande.
Source: begriffsCHECK et NOT NULL sont toujours vérifiés au niveau de la ligne, pour d'autres restrictions, comme le montre le tableau, il existe différentes options. En savoir plus ici .Pour résumer brièvement, les restrictions en attente dans certaines situations donnent un code plus lisible et moins de commandes. Cependant, vous devez payer pour cela en compliquant le processus de débogage, car le moment où l'erreur s'est produite et le moment où vous l'avez découvert sont séparés dans le temps. Un autre problème possible est que le planificateur ne peut pas toujours construire le plan optimal si une contrainte retardée est impliquée dans la demande.Raffinement pg_repack
Nous avons compris quelles sont les restrictions en attente, mais comment sont-elles liées à notre problème? Rappelez-vous l'erreur que nous avons précédemment reçue:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Il se produit au moment de la copie des données de la table des journaux vers la nouvelle table. Ça a l'air bizarre parce que les données de la table de journal sont validées avec les données de la table d'origine. S'ils satisfont aux contraintes de la table d'origine, comment peuvent-ils violer les mêmes contraintes dans la nouvelle?Il s'est avéré que la racine du problème réside dans l'étape précédente de pg_repack, qui ne crée que des index, mais pas de restrictions: l'ancienne table avait une contrainte unique et la nouvelle créait un index unique à la place. Il est important de noter ici que si la restriction est normale et non différée, alors l'index unique créé à sa place est équivalent à cette restriction, car Les contraintes uniques Postgres sont implémentées en créant un index unique. Mais dans le cas d'une contrainte différée, le comportement n'est pas le même, car l'index ne peut pas être différé et est toujours vérifié au moment de l'exécution de la commande sql.Ainsi, l'essence du problème réside dans le «report» de la vérification: dans la table d'origine, il se produit au moment de la validation, et dans la nouvelle - au moment de l'exécution de la commande sql. Nous devons donc nous assurer que les contrôles sont effectués de la même manière dans les deux cas: soit toujours différés, soit toujours immédiatement.Alors, quelles idées avions-nous?
Il est important de noter ici que si la restriction est normale et non différée, alors l'index unique créé à sa place est équivalent à cette restriction, car Les contraintes uniques Postgres sont implémentées en créant un index unique. Mais dans le cas d'une contrainte différée, le comportement n'est pas le même, car l'index ne peut pas être différé et est toujours vérifié au moment de l'exécution de la commande sql.Ainsi, l'essence du problème réside dans le «report» de la vérification: dans la table d'origine, il se produit au moment de la validation, et dans la nouvelle - au moment de l'exécution de la commande sql. Nous devons donc nous assurer que les contrôles sont effectués de la même manière dans les deux cas: soit toujours différés, soit toujours immédiatement.Alors, quelles idées avions-nous?Créer un index similaire à différé
La première idée est d'effectuer les deux contrôles en mode immédiat. Cela peut donner lieu à plusieurs faux déclencheurs positifs de la restriction, mais s'il y en a peu, cela ne devrait pas affecter le travail des utilisateurs, car pour eux, de tels conflits sont une situation normale. Ils se produisent, par exemple, lorsque deux utilisateurs commencent à modifier simultanément le même widget et que le client du deuxième utilisateur n'a pas le temps d'obtenir des informations indiquant que le widget est déjà verrouillé pour modification par le premier utilisateur. Dans cette situation, le serveur refuse le deuxième utilisateur et son client annule les modifications et bloque le widget. Un peu plus tard, lorsque le premier utilisateur a terminé la modification, le second recevra des informations indiquant que le widget n'est plus verrouillé et pourra répéter son action.
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
Sur l'environnement de test, nous n'avons reçu que quelques erreurs attendues. Succès! Nous avons de nouveau lancé pg_repack sur le prod et obtenu 5 erreurs sur le premier cluster en une heure de travail. C'est un résultat acceptable. Cependant, déjà sur le deuxième cluster, le nombre d'erreurs a augmenté plusieurs fois et nous avons dû arrêter pg_repack.Pourquoi est-ce arrivé? La probabilité d'une erreur dépend du nombre d'utilisateurs travaillant simultanément avec les mêmes widgets. Apparemment, à ce moment-là, avec les données stockées sur le premier cluster, il y avait beaucoup moins de changements de concurrence que sur les autres, c'est-à-dire nous étions juste «chanceux».L'idée n'a pas fonctionné. À ce moment, nous avons vu deux autres options de solution: réécrire notre code d'application pour abandonner les restrictions en attente, ou «apprendre» à pg_repack à travailler avec elles. Nous avons choisi le second.Remplacer les index dans une nouvelle table par des contraintes différées de la table source
Le but de la révision était évident - si la table d'origine a une contrainte différée, alors pour la nouvelle, vous devez créer une telle contrainte, pas un index.Pour tester nos modifications, nous avons écrit un test simple:- table avec restriction différée et un enregistrement;
- insérer des données dans la boucle qui entrent en conflit avec l'enregistrement existant;
- faire une mise à jour - les données ne sont plus en conflit;
- engager le changement.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
La version originale de pg_repack s'est toujours écrasée lors de la première insertion, la version révisée a fonctionné sans erreur. Bien.Nous allons au prod et encore une fois nous obtenons une erreur dans la même phase de copie des données de la table de log dans la nouvelle:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Situation classique: tout fonctionne sur des environnements de test, mais pas sur prod?!APPLY_COUNT et la jonction de deux lots
Nous avons commencé à analyser le code littéralement ligne par ligne et avons trouvé un point important: les données sont transférées de la table journal vers la nouvelle avec des lots, la constante APPLY_COUNT indiquait la taille des lots:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
Le problème est que les données de la transaction d'origine, dans lesquelles plusieurs opérations peuvent potentiellement violer la restriction, peuvent être transférées à la jonction de deux lots pendant le transfert - la moitié des équipes seront engagées dans le premier match et l'autre dans le second. Et voici notre chance: si les équipes du premier lot ne violent rien, alors tout va bien, mais si elles violent - une erreur se produit.APPLY_COUNT est égal à 1000 entrées, ce qui explique pourquoi nos tests ont réussi - ils ne couvraient pas le cas de «jonction de lots». Nous avons utilisé deux commandes - insérer et mettre à jour, donc exactement 500 transactions de deux équipes ont toujours été placées dans le lot et nous n'avons rencontré aucun problème. Après avoir ajouté la deuxième mise à jour, notre modification a cessé de fonctionner:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Ainsi, la tâche suivante consiste à s'assurer que les données de la table source qui ont changé dans une transaction tombent dans la nouvelle table également dans la même transaction.Refus de boucher
Et encore une fois, nous avions deux solutions. Tout d'abord: abandonnons complètement le traitement par lots et effectuons le transfert de données en une seule transaction. En faveur de cette solution était sa simplicité - les changements de code requis étaient minimes (au fait, dans les anciennes versions alors pg_reorg fonctionnait exactement de cette façon). Mais il y a un problème - nous créons une transaction longue, et cela, comme cela a été dit plus haut, constitue une menace pour l'émergence d'un nouveau ballonnement.La deuxième solution est plus compliquée, mais probablement plus correcte: créez une colonne dans la table des journaux avec l'identifiant de la transaction qui a ajouté les données à la table. Ensuite, lors de la copie des données, nous pourrons les regrouper par cet attribut et nous assurer que les modifications associées seront transférées ensemble. Un lot sera formé de plusieurs transactions (ou d'une grande) et sa taille variera en fonction de la quantité de données modifiées dans ces transactions. Il est important de noter que puisque les données des différentes transactions tombent dans la table des journaux dans un ordre aléatoire, il ne sera pas possible de les lire séquentiellement, comme c'était le cas auparavant. seqscan pour chaque demande filtrée par tx_id est trop cher, vous avez besoin d'un index, mais cela ralentira la méthode en raison de la surcharge de sa mise à jour. En général, comme toujours, vous devez sacrifier quelque chose.Nous avons donc décidé de commencer par la première option, plus simple. Premièrement, il fallait comprendre si une transaction longue serait un vrai problème. Étant donné que le principal transfert de données de l'ancienne table vers la nouvelle se produit également dans une longue transaction, la question s'est transformée en «combien allons-nous augmenter cette transaction?» La durée de la première transaction dépend principalement de la taille de la table. La durée du nouveau dépend du nombre de modifications accumulées dans la table pendant le transfert de données, c'est-à-dire de l'intensité de la charge. L'exécution de pg_repack s'est produite pendant la charge minimale sur le service et la quantité de changement était incomparablement petite par rapport à la taille de table d'origine. Nous avons décidé de ne pas tenir compte de l'heure de la nouvelle transaction (à titre de comparaison, c'est en moyenne 1 heure et 2-3 minutes).Les expériences ont été positives. Fonctionnant également sur prod. Pour plus de clarté, une image de la taille de l'une des bases après l'exécution: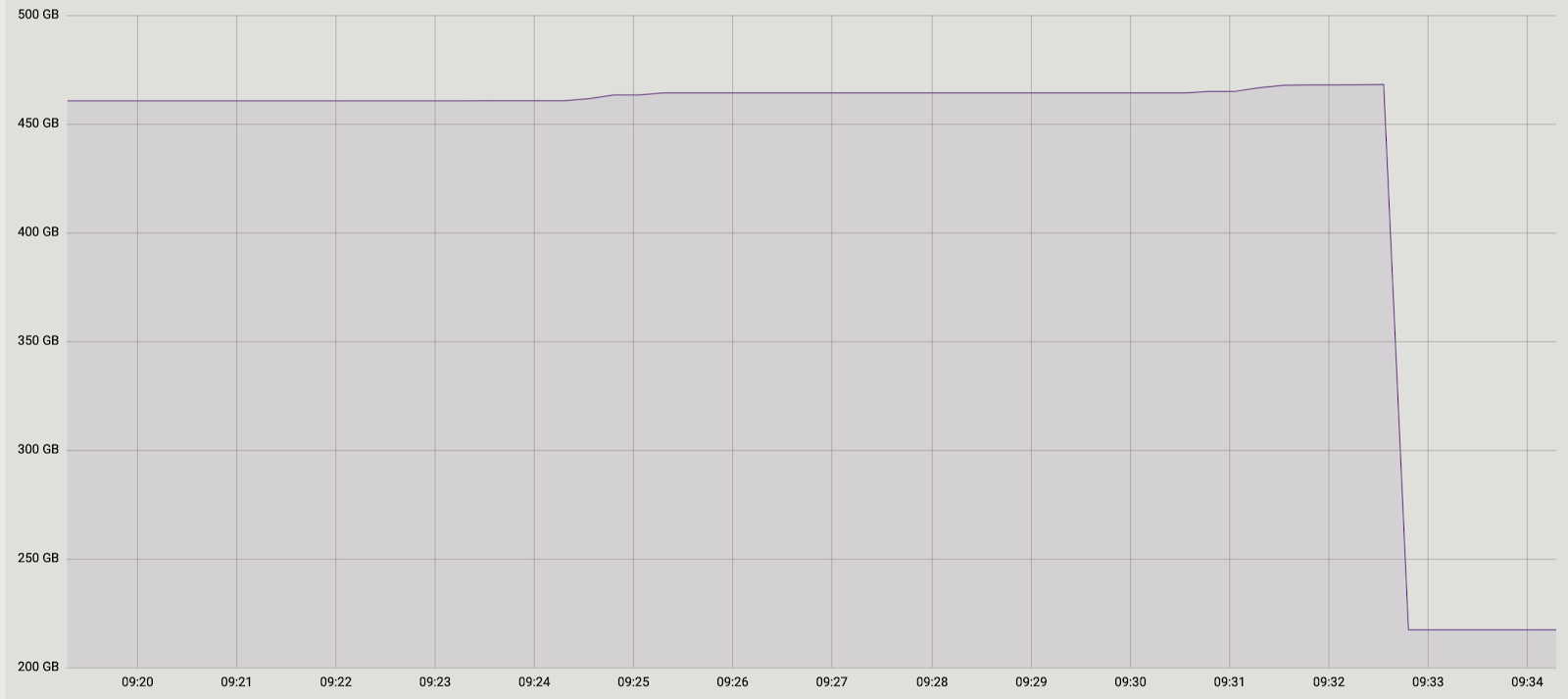 Puisque cette solution nous convenait parfaitement, nous n'avons pas essayé d'implémenter la seconde, mais nous envisageons d'en discuter avec les développeurs d'extensions. Malheureusement, notre révision actuelle n'est pas encore prête à être publiée, car nous n'avons résolu le problème qu'avec des restrictions uniques en attente, et pour un correctif complet, il est nécessaire de prendre en charge d'autres types. Nous espérons pouvoir le faire à l'avenir.Peut-être avez-vous une question, pourquoi nous sommes-nous impliqués dans cette histoire avec l'achèvement de pg_repack, et n'avons-nous pas, par exemple, utilisé ses analogues? À un moment donné, nous y avons également pensé, mais l'expérience positive de l'utiliser plus tôt, sur des tables sans restrictions en attente, nous a motivés à essayer de comprendre l'essence du problème et de le résoudre. De plus, pour utiliser d'autres solutions, il faut également du temps pour effectuer des tests, nous avons donc décidé que nous essaierions d'abord de résoudre le problème, et si nous réalisions que nous ne pouvions pas le faire dans un délai raisonnable, nous commencerions alors à envisager des analogues.
Puisque cette solution nous convenait parfaitement, nous n'avons pas essayé d'implémenter la seconde, mais nous envisageons d'en discuter avec les développeurs d'extensions. Malheureusement, notre révision actuelle n'est pas encore prête à être publiée, car nous n'avons résolu le problème qu'avec des restrictions uniques en attente, et pour un correctif complet, il est nécessaire de prendre en charge d'autres types. Nous espérons pouvoir le faire à l'avenir.Peut-être avez-vous une question, pourquoi nous sommes-nous impliqués dans cette histoire avec l'achèvement de pg_repack, et n'avons-nous pas, par exemple, utilisé ses analogues? À un moment donné, nous y avons également pensé, mais l'expérience positive de l'utiliser plus tôt, sur des tables sans restrictions en attente, nous a motivés à essayer de comprendre l'essence du problème et de le résoudre. De plus, pour utiliser d'autres solutions, il faut également du temps pour effectuer des tests, nous avons donc décidé que nous essaierions d'abord de résoudre le problème, et si nous réalisions que nous ne pouvions pas le faire dans un délai raisonnable, nous commencerions alors à envisager des analogues.résultats
Ce que nous pouvons recommander sur la base de notre propre expérience:- Surveillez votre ballonnement. Sur la base des données de surveillance, vous pouvez comprendre dans quelle mesure l'autovacuum est configuré.
- Réglez AUTOVACUUM pour maintenir le ballonnement à un niveau raisonnable.
- bloat “ ”, . – .
- – , .