Une fois, un collègue a partagé ses réflexions sur l'API pour les clusters de calcul distribué, et j'ai répondu en plaisantant: "De toute évidence, une API idéale serait un simple appel telefork()pour que votre processus se réveille sur chaque machine du cluster, renvoyant la valeur de l'ID d'instance." Mais au final, cette idée a pris possession de moi. Je ne pouvais pas comprendre pourquoi il est si stupide et simple, beaucoup plus simple que n'importe quelle API pour le travail à distance, et pourquoi les systèmes informatiques ne semblent pas en être capables. J'ai également semblé comprendre comment cela peut être mis en œuvre, et j'avais déjà un bon nom, qui est la partie la plus difficile de tout projet. J'ai donc commencé à travailler.Au cours du premier week-end, il a fait un prototype de base, et le deuxième week-end a apporté une démo qui pourraitÀ quoi cela ressemble-t-il
J'ai implémenté le code en tant que bibliothèque Rust, mais théoriquement, vous pouvez envelopper le programme dans l'API C, puis exécuter les liaisons FFI pour téléporter même le processus Python. L'implémentation ne comprend que 500 lignes de code (plus 200 lignes de commentaires):use telefork::{telefork, TeleforkLocation};
fn main() {
let args: Vec<String> = std::env::args().collect();
let destination = args.get(1).expect("expected arg: address of teleserver");
let mut stream = std::net::TcpStream::connect(destination).unwrap();
match telefork(&mut stream).unwrap() {
TeleforkLocation::Child(val) => {
println!("I teleported to another computer and was passed {}!", val);
}
TeleforkLocation::Parent => println!("Done sending!"),
};
}
J'ai également écrit une aide appelée yoyotéléforks au serveur, effectue la fermeture transmise, puis téléfonctionne. Cela crée l'illusion que vous pouvez facilement exécuter un morceau de code sur un serveur distant, par exemple, avec une puissance de traitement beaucoup plus grande.
let scene = create_scene();
let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height];
telefork::yoyo(destination, || {
render_scene(&scene, width, height, &mut backbuffer);
});
save_png_file(width, height, &backbuffer);
Anatomie du processus Linux
Voyons à quoi ressemble le processus sous Linux (sur lequel le système d'exploitation hôte mère s'exécute telefork):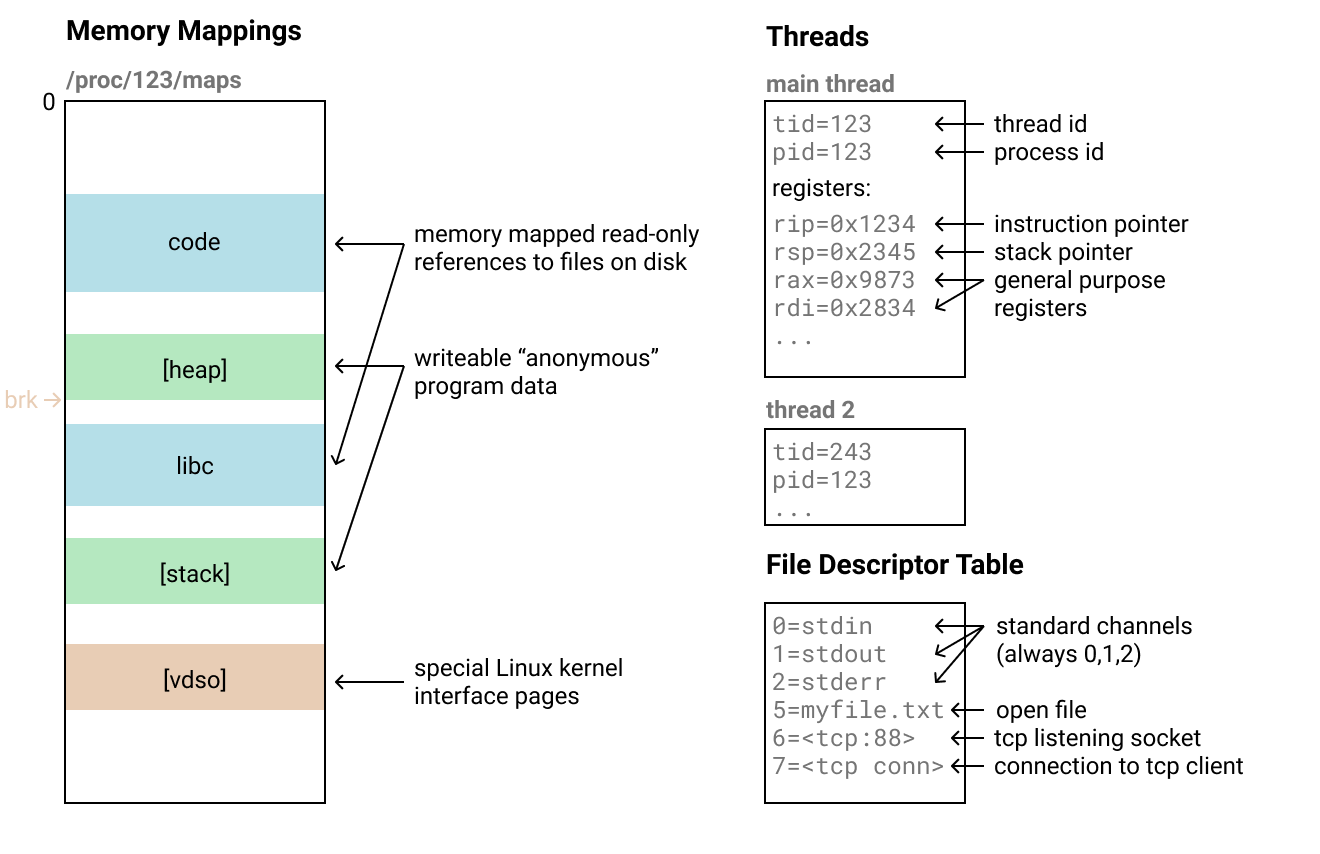
- (memory mappings): , . «» 4 .
/proc/<pid>/maps. , , .
- : , . , , - , , , . , .
- : , . - , . , , , TCP-, .
- . stdin/stdout/stderr, 0, 1 2.
- , , , .
- Divers : certaines autres parties de l'état du processus varient en termes de complexité de réplication. Mais dans la plupart des cas, ils n'ont pas d'importance, par exemple, brk (pointeur de tas). Certains d'entre eux ne peuvent être restaurés qu'à l'aide de trucs étranges ou d'appels système spéciaux comme PR_SET_MM_MAP , ce qui complique la récupération.
Ainsi, l'implémentation de base teleforkpeut se faire avec un simple mappage de la mémoire et des registres des threads principaux. Cela devrait être suffisant pour les programmes simples qui effectuent principalement des calculs sans interagir avec les ressources du système d'exploitation, tels que les fichiers (en principe, pour la téléportation, il suffit d'ouvrir le fichier dans le système et de le fermer avant d'appeler telefork).Comment télé-exécuter un processus
Je n'étais pas le premier à penser à recréer des processus sur une autre machine. Ainsi, le débogueur d'enregistrement et de débogage rr fait des choses très similaires . J'ai envoyé quelques questions à l'auteur de ce programme @rocallahan , et il m'a parlé du système CRIU pour la migration «à chaud» de conteneurs entre hôtes. CRIU peut transférer le processus Linux vers un autre système, prend en charge la récupération de toutes sortes de descripteurs de fichiers et d'autres états, cependant, le code est vraiment complexe et utilise de nombreux appels système qui nécessitent des assemblages de noyau spéciaux et des autorisations root. En utilisant le lien de la page wiki CRIU, j'ai trouvé DMTCP créé pour des instantanés de tâches distribuées sur des superordinateurs afin qu'elles puissent être redémarrées plus tard, et ce programmeLe code s'est avéré plus simple .Ces exemples ne m'ont pas forcé à abandonner les tentatives d'implémentation de mon propre système, car ce sont des programmes extrêmement complexes qui nécessitent des exécuteurs et une infrastructure spéciaux, et je voulais implémenter la téléportation de processus la plus simple possible en tant qu'appel de bibliothèque. J'ai donc étudié les fragments du code source rr, CRIU, DMTCP, et quelques exemples de ptrace - et mis au point ma propre procédure telefork. Ma méthode fonctionne à sa manière, c'est un méli-mélo de techniques diverses.Pour téléporter un processus, vous devez effectuer certains travaux dans le processus d'origine qui appelle telefork, et certains travaux du côté de l'appel de fonction, qui reçoit le processus de streaming sur le serveur et le recrée à partir du flux (fonctiontelepad) Ils peuvent se produire en même temps, mais toute sérialisation peut également être effectuée avant le téléchargement, par exemple, en le déposant dans un fichier, puis en le téléchargeant.Voici un aperçu simplifié des deux processus. Si vous voulez comprendre en détail, je vous suggère de lire le code source . Il est contenu dans un fichier et étroitement commenté pour être lu dans l'ordre et comprendre comment tout fonctionne.Soumettre un processus en utilisant telefork
La fonction teleforkreçoit un flux avec une capacité d'écriture, par lequel elle transfère la totalité de l'état de son processus.- «» . , , . fork .
- .
/proc/<pid>/maps , . proc_maps crate.
- . DMTCP, , , . ,
[vdso], , , .
- . , , process_vm_readv , .
- Registres de transfert . J'utilise l'option
PTRACE_GETREGSpour l'appel système ptrace . Il vous permet d'obtenir toutes les valeurs du registre du processus enfant. Ensuite, je les écris simplement dans un message sur la chaîne.
Exécution d'appels système dans un processus enfant
Pour transformer le processus cible en une copie du processus entrant, vous devrez forcer le processus à exécuter un tas d'appels système sur lui-même, sans accès à aucun code, car nous avons tout supprimé. Nous effectuons des appels système à distance à l'aide de ptrace , un appel système universel pour manipuler et vérifier d'autres processus:- syscall. syscall , . ,
process_vm_readv [vdso] , , , syscall Linux, . , [vdso].
- ,
PTRACE_SETREGS. syscall, rax Linux, rdi, rsi, rdx, r10, r8, r9.
- Faites un pas en utilisant le paramètre
PTRACE_SINGLESTEPpour exécuter la commande syscall.
- Lisez les registres avec
PTRACE_GETREGSpour restaurer la valeur de retour syscall et voyez si elle a réussi.
Acceptation du processus dans telepad
En utilisant ceci et les primitives déjà décrites, nous pouvons recréer le processus:- Démarrez un processus enfant figé . Semblable à l'envoi, mais cette fois, nous avons besoin d'un processus enfant que nous pouvons manipuler pour le transformer en un clone du processus transféré.
- Vérifiez les cartes d'allocation de mémoire . Cette fois, nous devons connaître toutes les cartes d'allocation de mémoire existantes afin de les supprimer et faire de la place pour le processus entrant.
- . ,
munmap.
- .
mremap, .
- .
mmap , process_vm_writev .
- .
PTRACE_SETREGS , , rax. raise(SIGSTOP), . , telepad.
- Une valeur arbitraire est utilisée pour que le serveur telefork puisse transférer le descripteur de fichier de la connexion TCP que le processus a entré et peut renvoyer des données ou, dans le cas
yoyo, se téléporter vers la même connexion.
- Redémarrez le processus avec le nouveau contenu à l'aide de
PTRACE_DETACH.
Une mise en œuvre plus compétente
Certaines parties de mon implémentation telefork ne sont pas parfaitement conçues. Je sais comment les réparer, mais dans la forme actuelle, j'aime le système, et parfois ils sont vraiment difficiles à réparer. Voici quelques exemples intéressants:- (vDSO).
mremap vDSO , DMTCP, , . vDSO, . - , CPU glibc vDSO . , vDSO, syscall, rr, vDSO vDSO .
brk . DMTCP, , brk , brk . , , — PR_SET_MM_MAP, .
- . Rust « », , FS GS, , , -
glibc pid tid, . CRIU, PID TID .
- . , , , / , / FUSE. , TCP-, DMTCP CRIU ,
perf_event_open.
- .
fork() Unix , , .
Je pense que vous avez déjà compris qu'avec les bonnes interfaces de bas niveau, vous pouvez implémenter des choses folles qui semblaient impossibles à quelqu'un. Voici quelques réflexions sur la façon de développer les idées de base de la téléfonction. Bien qu'une grande partie de ce qui précède puisse probablement être entièrement implémentée uniquement sur un noyau complètement nouveau ou fixe:- Telfork de cluster . La première source d'inspiration pour la téléforche a été l'idée de diffuser un processus sur toutes les machines d'un cluster informatique. Il peut même s'avérer implémenter des méthodes de multidiffusion UDP ou d'égal à égal pour accélérer la distribution sur l'ensemble du cluster. Vous souhaitez probablement également disposer de primitives de communication.
- . CRIU , -
userfaultfd. , SIGSEGV mmap. , , — .
- ! , .
userfaultfd userfaultfd, , , MESI, . , , . — , . , , , . : syscall, -, syscall, . , . , , , . , , . , , ( , ) , .
Je l'aime beaucoup, car voici un exemple de l'une de mes techniques préférées - plonger dans une couche d'abstraction moins connue, qui remplit relativement facilement ce que nous pensions être presque impossible. La téléportation de calculs peut sembler impossible ou très difficile. Vous pourriez penser que cela nécessiterait des méthodes telles que la sérialisation de l'état entier, la copie de l'exécutable binaire sur la machine distante et son lancement à cet endroit avec des indicateurs de ligne de commande spéciaux pour recharger l'état. Mais non, tout est beaucoup plus simple. Sous votre langage de programmation préféré se trouve une couche d'abstraction où vous pouvez choisir un sous-ensemble assez simple de fonctions - et au cours du week-end, implémentez la téléportation de la plupart des calculs purs dans n'importe quel langage de programmation dans 500 lignes de code. je pensequ'une telle plongée à un autre niveau d'abstraction mène souvent à des solutions plus simples et plus universelles. Un autre de mes projets comme celui-ci estNumderline .À première vue, ces projets semblent être des hacks extrêmes, et dans une large mesure, ils le sont. Ils font des choses comme personne ne s'y attend, et quand ils cassent, ils le font au niveau d'abstraction, auquel des programmes similaires ne devraient pas fonctionner - par exemple, vos descripteurs de fichiers disparaissent mystérieusement. Mais parfois, vous pouvez définir correctement le niveau d'abstraction et encoder toutes les situations possibles, de sorte qu'à la fin, tout fonctionnera de manière fluide et magique. Je pense que les bons exemples ici sont rr (bien que telefork ait réussi à le mettre à sac) et la migration vers le cloud des machines virtuelles en temps réel (en fait, telefork au niveau de l'hyperviseur).J'aime aussi présenter ces choses comme des idées de façons alternatives de travailler sur les systèmes informatiques. Pourquoi nos API de calcul en cluster sont-elles tellement plus compliquées qu'un simple programme qui traduit des fonctions en cluster? Pourquoi la programmation du système réseau est-elle tellement plus compliquée que le multithread? Bien sûr, vous pouvez donner toutes sortes de bonnes raisons, mais elles sont généralement basées sur la difficulté de faire un exemple de systèmes existants. Ou peut-être avec la bonne abstraction ou avec un effort suffisant, tout fonctionnera facilement et de manière transparente? Fondamentalement, il n'y a rien d'impossible.
