Intro
Si vous n'avez pas trop dormi ces dernières années, vous avez bien entendu entendu parler des transformateurs - l'architecture du canonique Attention est tout ce dont vous avez besoin . Pourquoi les transformateurs sont-ils si bons? Par exemple, ils évitent la récurrence, ce qui leur permet de créer efficacement une représentation des données dans laquelle de nombreuses informations contextuelles peuvent être insérées, ce qui affecte positivement la capacité de générer des textes et la capacité inégalée de transférer l'apprentissage.
Transformers a lancé une avalanche de travaux sur la modélisation du langage - une tâche dans laquelle le modèle sélectionne le mot suivant, en tenant compte des probabilités des mots précédents, c'est-à-dire apprendre p(x)où se trouve le xjeton actuel. Comme vous pouvez le deviner, cette tâche ne nécessite aucun marquage, et vous pouvez donc y utiliser d'énormes tableaux de texte non annotés. Un modèle de langage déjà formé peut générer du texte, si bien que les auteurs refusent parfois de présenter des modèles formés .
Mais que se passe-t-il si nous voulons ajouter des «plumes» à la génération de texte? Par exemple, effectuez une génération conditionnelle en définissant un thème ou en contrôlant d'autres attributs. Une telle forme nécessite déjà une probabilité conditionnelle p(x|a), où aest l'attribut souhaité. Intéressant? Allons sous la coupe!
Les auteurs de l' article proposent une approche simple (et donc Plug and Play) et élégante de la génération conditionnelle, en utilisant un modèle de langage pré-formé lourd (ci-après LM) et plusieurs classificateurs simples, échantillonnant ainsi à partir d'une distribution de vues p(x|a) ∝ p(a|x)p(x). Il convient de noter que le LM d'origine n'est en aucun cas modifié. Les auteurs proposent deux formes de classificateurs, appelés modèles d'attributs dans l'article: BoW pour le contrôle du sujet et un classificateur linéaire pour le contrôle de la tonalité. Les auteurs font une analyse assez détaillée de leurs contributions clés, en comparant les idées et les approches de leur méthode avec d'autres articles. Un des points les plus importants est la facilité d'approche, et ici, peut-être, regardez cette plaque:
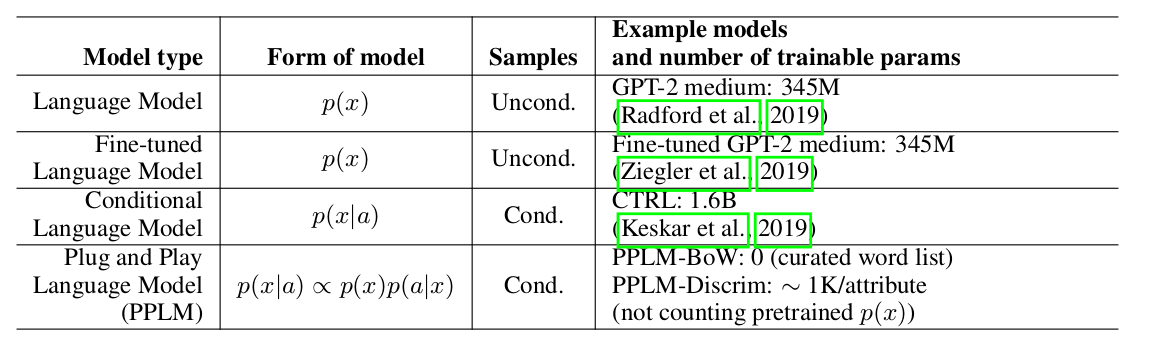
on peut voir que le PPLM surpasse tous les concurrents en termes de nombre de paramètres.
Décodage pondéré 2.0
Uber weighted decoding: , . , , . , . , , , .
Uber : , LM, . , , , ( , ) . ( perturb_past — , .
? log-likelihood: p(x) a attribute model p(a|x). , backward pass .
log-likelihood? , :
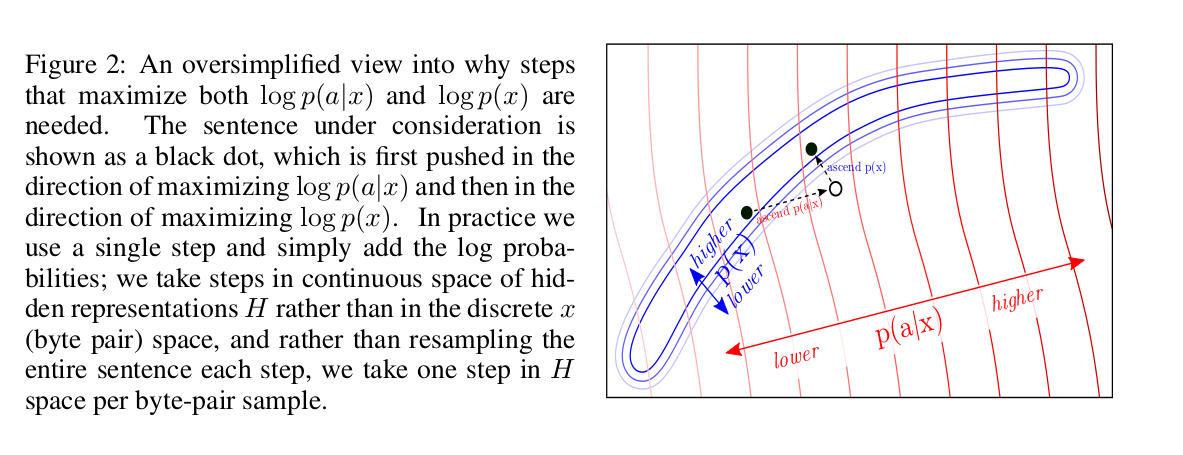
, , LM. , fluency LM.
, :

forward pass LM, p(a|x) — attribute model. backward pass, , attribute model, , . , .
, : “” k k forward backward pass’, n. LM forward pass. , : ( num of iterations=3 gen length=5, ).
, ( colab , ) , , , “the kitten” “military” :
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the "suspected killer" of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — , military. LM :
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named "Lucky," was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
attribute models
, BoW discriminator. :
p_t+1 — LM, w_i — i- .
Discriminator model , BoW, , , , . , .
, LM, LM weighted decoding CTRL (conditional LM). fluency , , perplexity . PPLM :
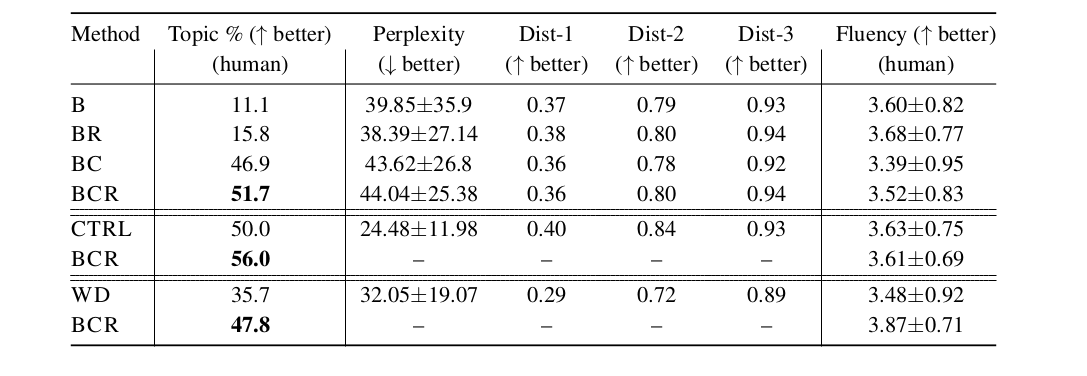
:
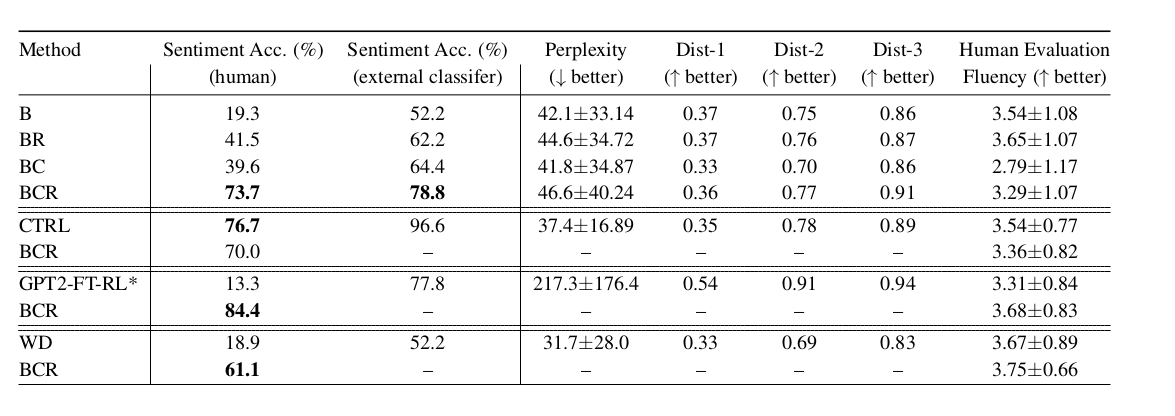
- B — baseline, GPT-2 LM;
- BR — , B,
r , log-likelihood ; - BC — , ;
- BCR — , BC,
r , log-likelihood ; - CTRL — Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned RL ;
- WD — weighted decoding,
p(a|x);
— , LM, . , , - :)